(B站TinyML 教程学习笔记)C24 - 音频分类入门+C25 - 音频数据采集+C26 - 音频特征提取
0:07 音频分类简介
- 音频分类是机器学习中非常实用的应用。
- 本质:让机器“听懂声音”。
- 不仅能识别人类能听到的声音,还能配合超人类听觉范围的麦克风。
0:27 智能音箱中的嵌入式AI
智能音箱工作流程
例如:
- Amazon 的 Echo
工作方式:
- 单片机持续监听唤醒词(Wake Word)
- 识别到“Alexa”后
- 才把后续语音上传服务器
- 云端进行复杂自然语言处理(NLP)
本地运行内容
设备本地只运行:
- 较小的关键词检测模型
云端运行:
- 大型语音理解模型
1:35 音频分类的应用
1. 智能语音助手
- Alexa
- Siri
- Google Assistant
2. 动物声音识别
例如:
- 野生动物追踪
- 大象监测
3. 安防系统
识别:
- 玻璃破碎声
- 敲门声
- 异常声音
3:37 数字音频采样
音频采样
单片机:
- 每隔固定时间测量一次电压
形成:
- 数字音频
4:17 采样率(Sampling Rate)
例子:
- 每62.5微秒采样一次
采样率:
fs=16000 Hz(取倒数)
即:
- 16kHz
4:28 重要原则
训练数据采样率必须与部署设备一致
例如:
- 手机录音 (采样):44.1kHz
- Arduino(部署):16kHz
则需要在特征提取前:
- 将采样数据降低到16kHz
5:10 位深度(Bit Depth)
位深度作用
决定:
- 每个采样值精度
5:18 4位量化
4位只能表示:
即:
- 16个电平
问题:
- 音频失真严重
6:17 常见音频位深度
- 8位:最低可接受
- 16位:常见
- 32位/浮点:更高精度
Arduino项目:
- 通常16位
6:40 重要原则
训练数据位深度:
- 应匹配部署设备
建议:
- 用与目标设备相似的麦克风采集数据
8:09 关键词识别项目
目标:
- 创建自己的关键词识别系统
设备:
- 手机
- Arduino
都可以
8:25 Google Speech Commands 数据集
Google 语音命令数据集:
- 几十个单词
- 每个单词数千样本
用途:
- 初学机器学习
- 扩充数据集
9:10 关键词分类系统设计
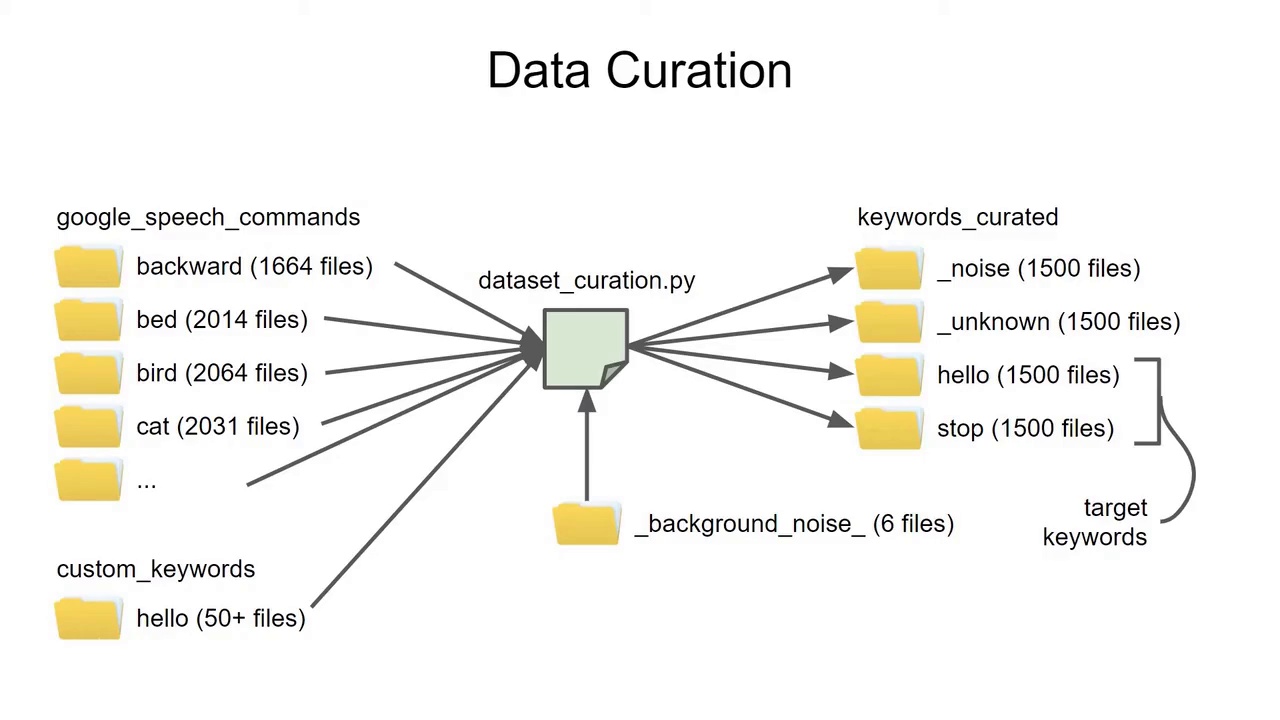
三个类别
1. Noise(噪声)
背景噪音
2. Unknown(未知)
不是目标词的其它词
3. Keywords(关键词)
目标单词
9:24 为什么不能识别所有单词
因为:
- MCU资源有限
- 神经网络不能太大
10:13 数据增强(Data Augmentation)
常见方法
1. 混入背景噪音
例如:
- 交通噪音
- 办公室噪音
2. 改变位置
让单词:
- 不总出现在固定时间点
3. 调整
- 音量
- 音调
11:26 音频样本必须统一
所有样本必须:
- 采样率一致
- 位深度一致
- 长度一致
11:33 示例
1秒音频:
- 16kHz
- 16位
则共有:
16000个16位的音频样本
12:00 自动处理
脚本会自动统一样本:
- 裁剪
- 补零
- 降采样
- 调整位深度
12:27 Google Colab 环境
使用:
Google Colab
优点:
- 不用本地安装环境
- 后台运行Linux
13:24 数据集配置
设置:
- 每类1500样本
- 长度1秒
- 16kHz
- 16位
15:09 创建自定义关键词样本集
建议
包含不同:
- 声音
- 年龄
- 性别
- 口音
提高泛化能力
15:27 录音建议
至少录:
- 50次关键词
15:59 使用 Audacity 切片(也可以使用脚本自动截取样本)
Audacity
导出格式:
- WAV
- 16位PCM
16:33 数据增强技巧
让关键词:
- 出现在不同时间位置
避免模型:
- 只记住固定位置
17:43 Edge Impulse 项目
Edge Impulse
步骤:
- 创建项目
- 获取API Key
- 上传新增关键词数据集
18:20 关键词来源限制
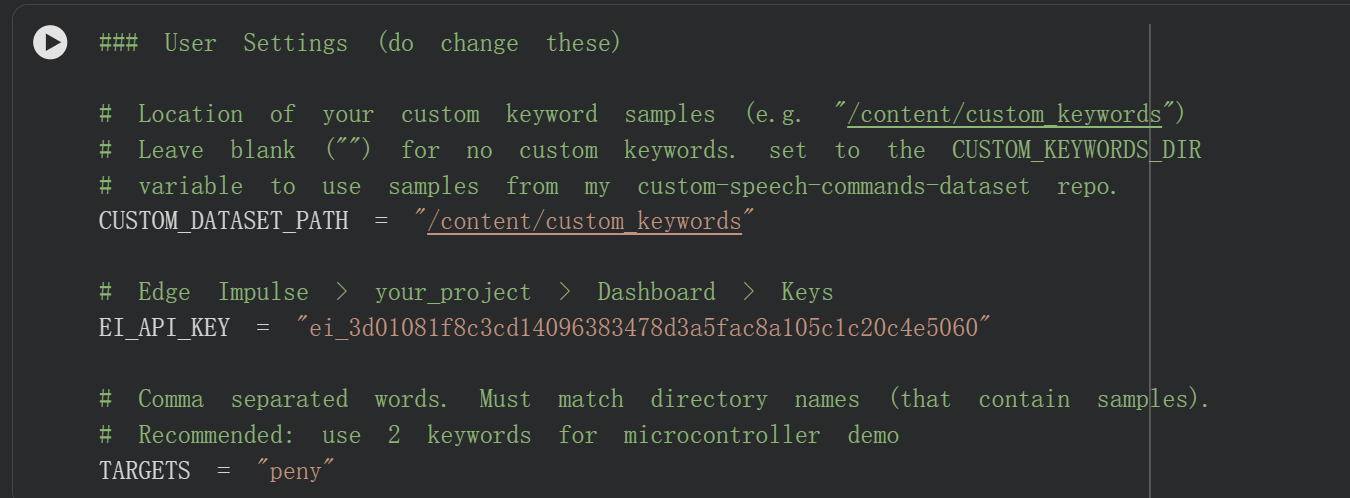
关键词必须来自:
- Google数据集
或 - 自定义数据集
18:39 多关键词问题
关键词越多:
- 输出节点越多
- 模型越大
- 推理越慢
可能:
- MCU跑不动
20:47 特征提取
为什么不能直接用原始音频
模型可能学到:
- 音量
- 位置
而不是:
- 真正语音特征
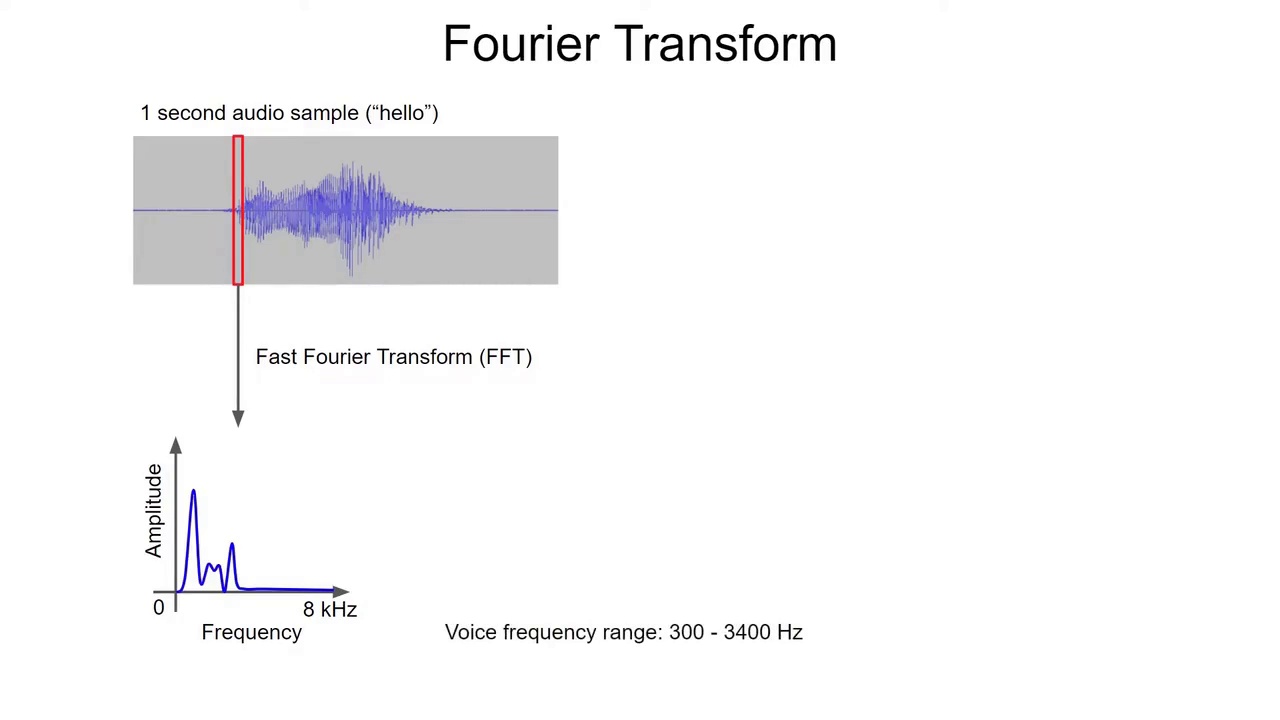
21:23 傅里叶变换(Fourier Transform)
核心思想:
任何周期信号都能表示为:
- 多个正弦波叠加
- 傅里叶变换就像一个“声音棱镜”,把这些混在一起的不同频率成分分离出来,让你看到这段声音里哪些频率的分量更强、占主导
FFT
快速傅里叶变换:
- 快速计算频率成分
22:45 频谱图(Spectrogram)
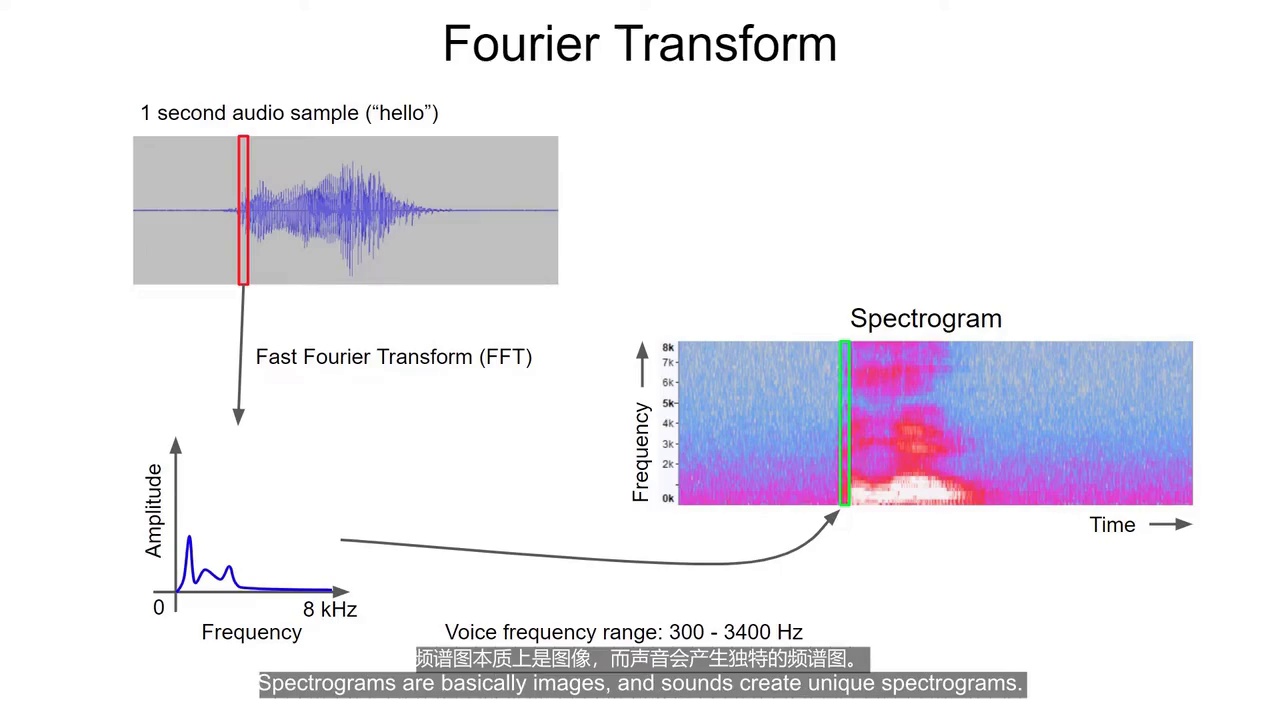
频谱图三维信息:
- X轴:时间
- Y轴:频率
- Z轴:强度(颜色表示)
本质:
- 声音图像
23:24 频谱图适合什么
适合:
- 玻璃破碎
- 敲门
- 动物声音
但:
- 人类语音还需要进一步处理
23:47 奈奎斯特采样定理

意思:
采样率必须超过最高频率的2倍
24:49 混叠(Aliasing)
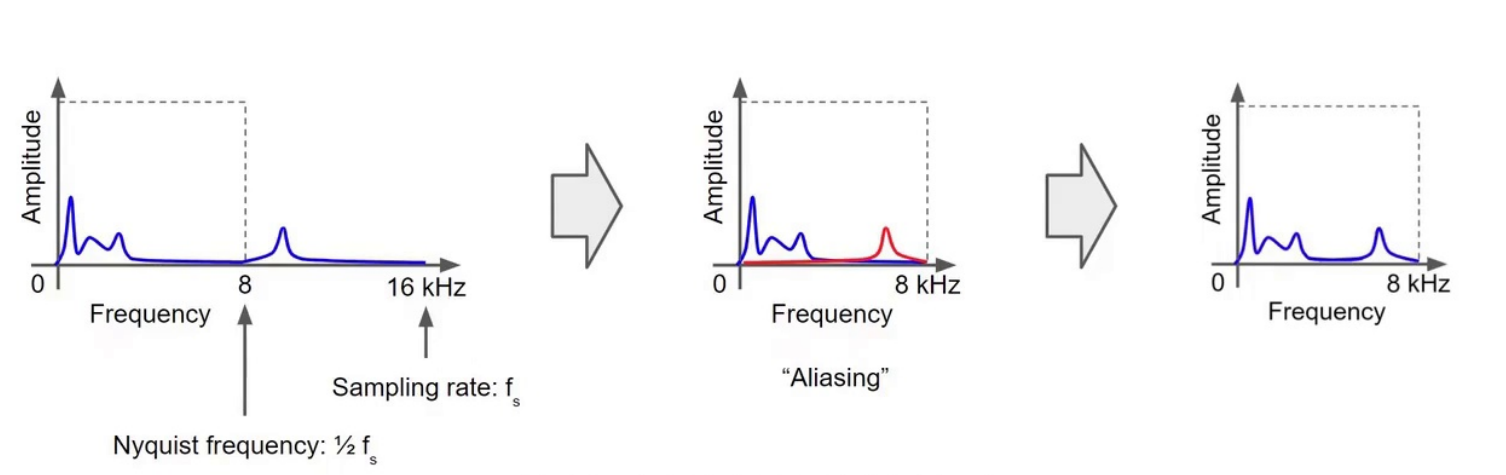
超过奈奎斯特频率:
- 高频会“折叠”
- 产生错误频率
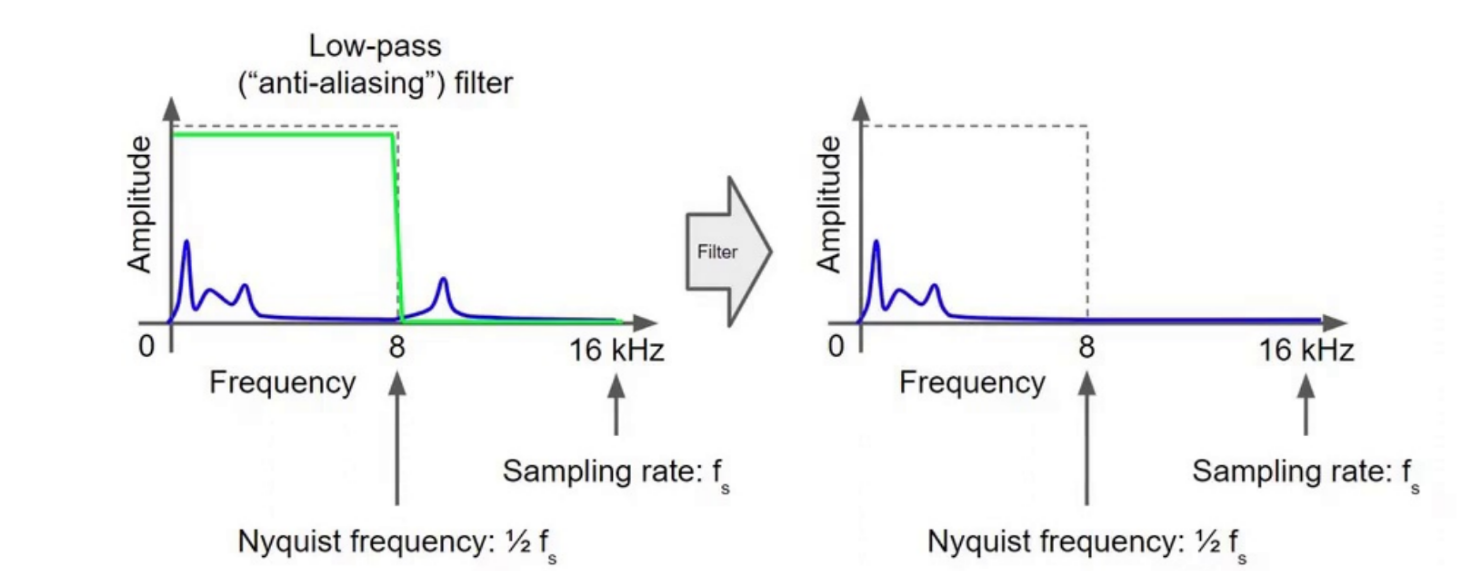
25:12 抗混叠滤波器
解决方案:
- 低通滤波器
作用:
- 去除高频
- 防止混叠
26:34 MFCC(梅尔频率倒谱系数)
语音识别经典特征。
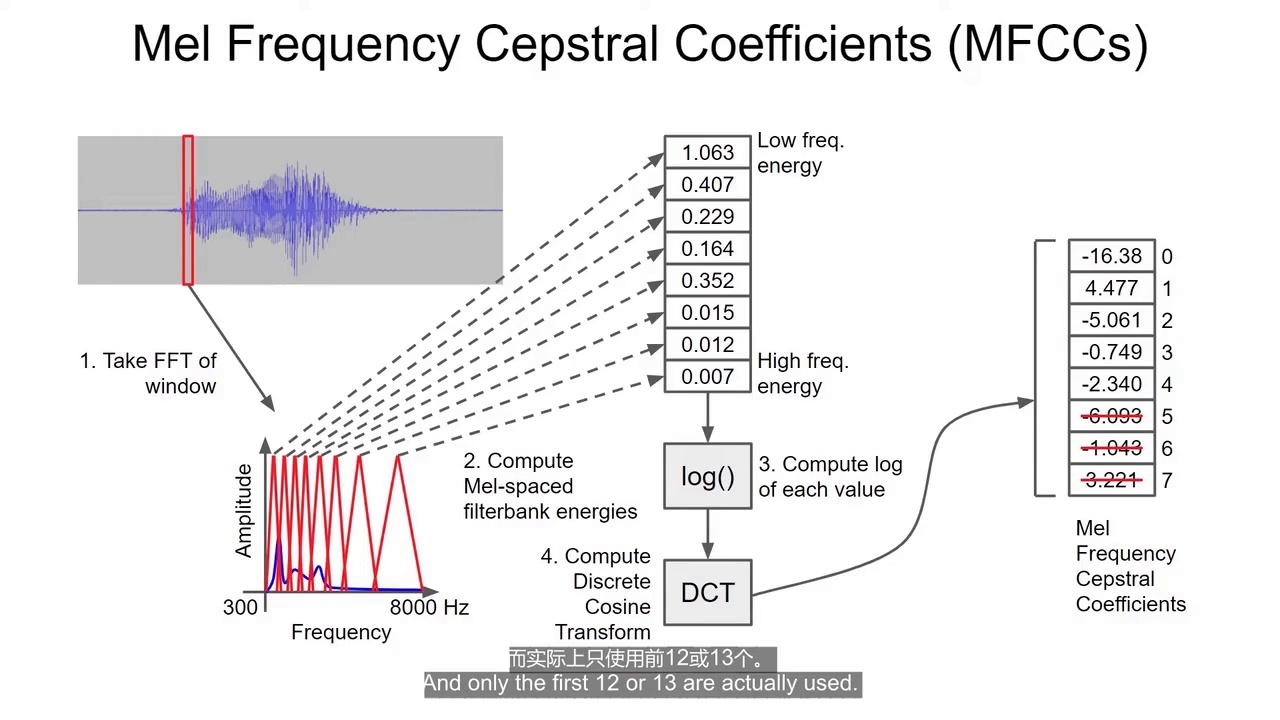
29:01 滑动窗口MFCC
方法:
- 取窗口
- 计算MFCC
- 滑动窗口
- 重复计算
最终形成:
- 类似图像的二维特征
29:38 MFCC优势
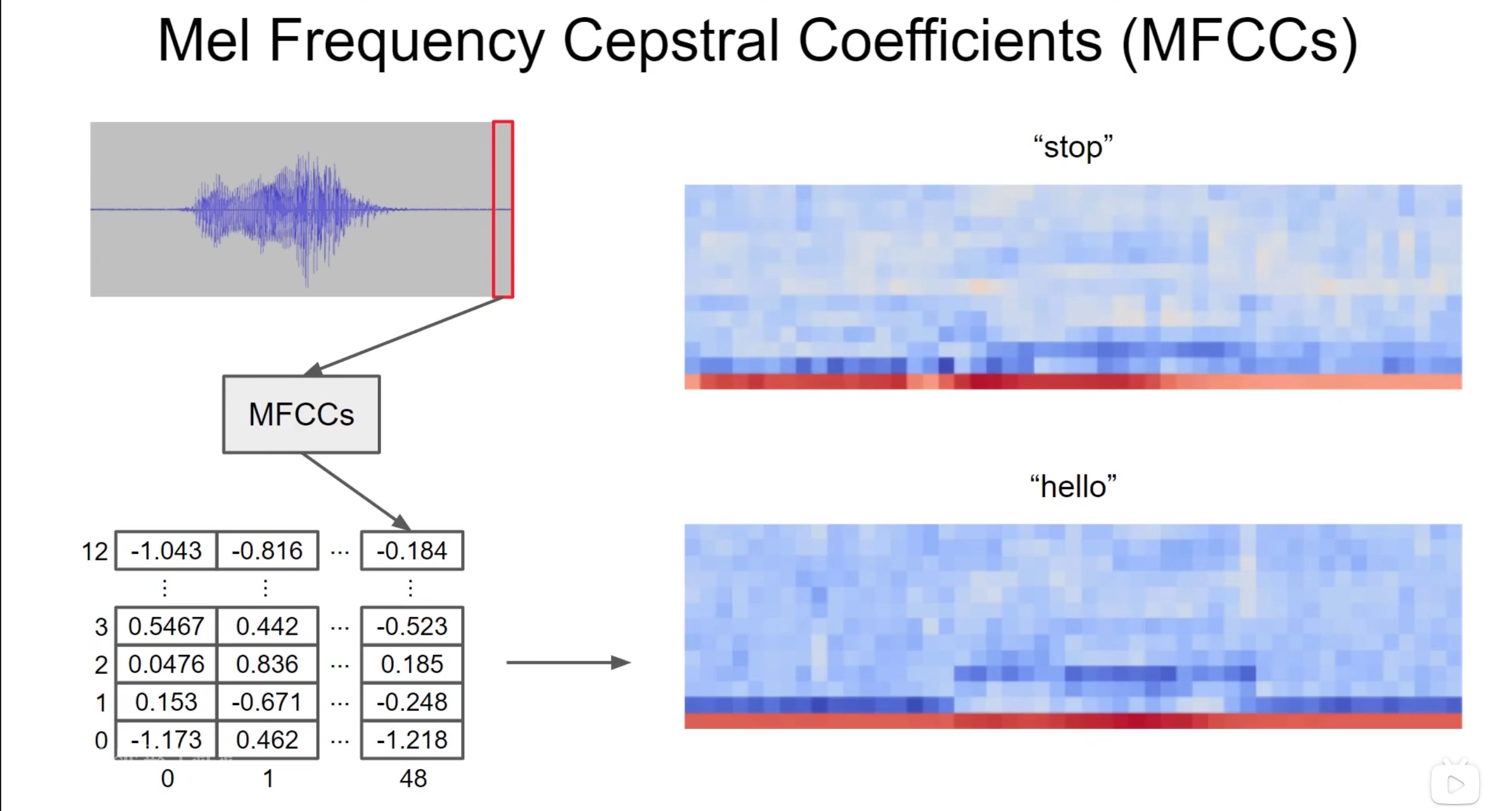
不同单词:
- 会产生不同MFCC图案
因此:
- 更容易分类
1. 在Edge Impulse创建 Impulse
进入 Edge Impulse 的 Impulse Design(Impulse设计) 页面:
-
窗口大小(Window size)设置为:
-
1000 ms
-
-
原因:
-
因为我们的语音样本长度本身就是 1 秒。
-
2. 添加处理模块(Processing Block)
点击:
-
Add a processing block
系统会推荐:
-
MFCC
-
Spectrogram(频谱图)
由于当前处理的是 语音数据,因此选择:
-
MFCC
然后点击添加。
3. 添加学习模块(Learning Block)
接着添加:
-
Neural Network(神经网络)
注意:
虽然 MFCC 处理后的结果看起来很像图片,
但这里:
-
不使用 Transfer Learning(迁移学习)
-
而是使用普通神经网络进行训练。
最后:
-
点击
Save Impulse
4. MFCC 参数设置
进入 MFCC 页面后,可以看到以下参数。
(1)MFCC 系数数量
使用:
-
13 个 MFCC 系数
作用:
-
用来提取语音的重要频率特征。
简单理解:
MFCC 会把声音转换成一组“声音特征数字”。
(2)窗口大小(Frame Size)
设置:
-
20 ms
含义:
-
将语音切成很多 20ms 的小片段分别分析。
因为:
-
人的声音在极短时间内变化不大,
-
所以适合分帧处理。
(3)窗口重叠(Frame Stride)
默认:
-
无重叠
即:
-
一个窗口结束后,
-
下一个窗口直接开始。
(4)FFT 参数
FFT(快速傅里叶变换)用于:
-
把声音从时域转换到频域。
也就是:
-
分析声音中有哪些频率成分。
(5)低频过滤
低频截止:
-
300 Hz
意思:
-
300Hz 以下的声音会被过滤掉。
原因:
这些低频对语音识别帮助不大,
例如:
-
环境震动
-
风噪
-
电流声
(6)高频设置
高频设置为:
-
0
但实际上表示:
-
使用尼奎斯特频率(Nyquist Frequency)
对于当前样本:
-
最大频率为
8000 Hz
(7)预加重滤波(Pre-emphasis)
在计算 MFCC 前:
系统会先增强高频部分。
作用:
-
放大语音中的高频信息。
因为:
语音中的很多关键特征存在于高频区域,
这样通常会提高识别效果。
5. 生成特征(Generate Features)
进入:
-
Generate Features
点击:
-
Generate features
系统会开始:
-
计算所有音频的 MFCC 特征。
需要等待几分钟。
6. 特征浏览器(Feature Explorer)
生成完成后:
会看到一个 3D 图。
为什么是 3D 图?
因为:
原始 MFCC 数据维度非常高。
这里:
-
总共有 637 个维度。
人类无法直接观察这么高维的数据。
所以 Edge Impulse 会:
-
将高维数据压缩到 3D 空间中显示。
7. UMAP 降维算法
Edge Impulse 使用:
-
UMAP 算法
把高维 MFCC 数据:
-
降低到 3 个维度。
UMAP 的作用(通俗理解)
UMAP 会:
-
分析不同声音特征之间的相似度。
如果:
-
两个声音很像,
那么:
-
在图中距离会很近。
如果:
-
两个声音差异很大,
那么:
-
在图中会距离很远。
8. 如何观察特征图
可以拖动 3D 图观察。
重点:
看不同类别的数据:
-
是否形成明显分组。
例如:
-
“yes” 聚成一团
-
“no” 聚成另一团
9. 为什么分组很重要?
如果不同类别:
-
分离明显,
说明:
-
特征提取效果很好。
也意味着:
-
神经网络更容易学习分类。
最终:
-
模型识别准确率通常会更高。
10. 当前阶段总结
整个流程:
音频
→ MFCC特征提取
→ 得到高维特征
→ UMAP降维可视化
→ 观察类别是否分离
→ 训练神经网络
核心思想
机器学习本质上就是:
-
“让不同类别的数据尽可能分开”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)