计算机毕业设计Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统 农产品销量预测 农产品推荐系统 智慧农业
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统 论文
Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统
作者:XXX
学号:XXX
专业:计算机科学与技术/大数据技术与应用
指导教师:XXX
摘要
农产品价格的稳定运行直接关系到国家粮食安全、农户增收与乡村振兴战略的推进。当前农产品价格受自然环境、市场供需、政策调控等多重因素影响,呈现非线性、非平稳性、高波动性特征,传统预测模式存在数据处理效率低、预测精度不足、非结构化数据解析能力欠缺等痛点。为破解上述问题,本文设计并实现了一套基于Spark+Hadoop+Hive+LLM大模型+Django的农产品价格预测系统。
系统采用Spark+Hadoop+Hive构建分布式数据处理与存储架构,实现多源农产品数据(历史价格、气象、政策、舆情等)的高效采集、清洗、存储与特征工程;选用Qwen-7B轻量化LLM大模型,通过LoRA轻量化微调适配农业场景,结合LSTM+XGBoost+Prophet集成模型,实现语义特征与时序特征的深度融合,提升价格预测精度;基于Django框架开发Web可视化系统,实现数据展示、价格查询、多周期预测、舆情分析等功能。
实验验证表明,该系统数据处理延迟控制在1小时以内,短期(1-7天)预测精度达88.2%,中期(30天)达77.5%,长期(90天)达66.8%,均满足预设目标。系统运行稳定、交互便捷,可为农户、农业主管部门、经销商提供精准的价格预测服务,助力农业生产经营从“经验驱动”向“数据驱动”转变,具有重要的理论价值与实用价值。
关键词:农产品价格预测;Spark;Hadoop;Hive;LLM大模型;Django;分布式计算;智慧农业
Abstract
The stable operation of agricultural product prices is directly related to national food security, farmers' income increase and the advancement of the rural revitalization strategy. Currently, agricultural product prices are affected by multiple factors such as the natural environment, market supply and demand, and policy regulation, showing non-linear, non-stationary, and high volatility characteristics. The traditional prediction model has shortcomings such as low data processing efficiency, insufficient prediction accuracy, and lack of unstructured data parsing capabilities. To solve the above problems, this paper designs and implements an agricultural product price prediction system based on Spark+Hadoop+Hive+LLM large model+Django.
The system uses Spark+Hadoop+Hive to build a distributed data processing and storage architecture, realizing efficient collection, cleaning, storage and feature engineering of multi-source agricultural product data (historical prices, meteorology, policies, public opinion, etc.); selects the Qwen-7B lightweight LLM large model, adapts to the agricultural scene through LoRA lightweight fine-tuning, and combines the LSTM+XGBoost+Prophet integrated model to realize the in-depth integration of semantic features and time-series features, improving the price prediction accuracy; develops a Web visualization system based on the Django framework to realize functions such as data display, price query, multi-cycle prediction, and public opinion analysis.
Experimental verification shows that the data processing delay of the system is controlled within 1 hour, the short-term (1-7 days) prediction accuracy reaches 88.2%, the medium-term (30 days) reaches 77.5%, and the long-term (90 days) reaches 66.8%, all meeting the preset goals. The system runs stably and has convenient interaction, which can provide accurate price prediction services for farmers, agricultural authorities and dealers, help transform agricultural production and operation from "experience-driven" to "data-driven", and has important theoretical and practical value.
Key words: Agricultural product price prediction; Spark; Hadoop; Hive; LLM large model; Django; Distributed computing; Smart agriculture
一、引言
1.1 研究背景
农业作为国民经济的基础产业,其稳定发展是保障国家粮食安全、促进农户增收、维护市场供需平衡的核心支撑。农产品价格作为农业市场运行的核心指标,受自然环境(气温、降雨量、自然灾害)、市场供需、政策调控、物流成本、舆情动态等多重因素的综合影响,呈现出非线性、非平稳性、高波动性的显著特征。据农业农村部数据显示,2020—2025年我国生猪、苹果等主要农产品价格年波动率超15%,2024年山东苹果因霜冻减产导致价格暴涨35%,部分农产品因信息滞后频繁出现“谷贱伤农”或“哄抢涨价”现象,严重影响农业生产的稳定性与农户的切身利益。
当前,传统农产品价格预测多依赖ARIMA等统计模型与人工经验判断,存在明显局限:一是数据维度单一,仅依赖历史价格序列,忽略多源异构关联数据的影响;二是计算效率不足,海量农业数据(全国农产品交易市场每日超500万条记录)处理延迟超24小时,难以支撑实时决策;三是预测精度有限,传统模型预测误差常超过20%,无法满足精准调控与生产决策需求;四是语义理解不足,难以解析政策文本、舆情信息中的隐性影响因素,导致预测结果缺乏可解释性。
随着大数据、人工智能技术的深度融合,分布式计算框架(Spark+Hadoop+Hive)具备高效处理TB级多源数据的能力,可实现数据的分布式存储、批流处理与仓库管理,解决海量农业数据的处理难题;LLM大模型(如Qwen-7B、BERT等)凭借强大的语义理解能力,可深度挖掘非结构化文本数据中的关键信息,弥补传统模型的语义解析短板;Django框架则能快速实现Web化工程落地,实现预测结果的可视化展示与交互,提升系统的实用性。基于此,本文设计开发Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统,破解传统预测痛点,助力农业数字化升级与乡村振兴战略实施。
1.2 研究意义
1.2.1 理论意义
1. 探索Spark+Hadoop+Hive分布式生态与LLM大模型的融合应用路径,丰富农业大数据预测领域的技术体系,为多源异构农业数据的高效处理与深度挖掘提供新的理论参考;
2. 突破传统预测模型的语义理解局限,将LLM大模型的文本解析能力与时间序列预测模型结合,提出语义特征与时序特征融合的预测策略,提升农产品价格预测的精度与可解释性,完善农业价格预测的理论方法;
3. 验证分布式计算框架在农业大数据场景中的适用性,构建“数据采集-处理-建模-Web展示”的一体化理论范式,为后续农业大数据系统的设计与开发提供可复用的理论支撑,推动大数据、人工智能与农业领域的深度融合研究。
1.2.2 实际意义
1. 为农户提供精准的农产品价格预测服务,提前预判价格波动趋势,指导农户合理调整种植、养殖结构,减少市场风险,提升农户收益,缓解“谷贱伤农”问题;
2. 为农业主管部门提供数据支撑与决策参考,助力其精准调控市场供需、制定农业政策,及时应对价格异常波动,维护农产品市场稳定;
3. 为农产品经销商、零售商提供价格参考,优化采购、库存与销售策略,降低运营成本,提升盈利空间;
4. 推动农业大数据、人工智能技术在农业领域的落地应用,助力智慧农业建设,推动农业生产经营从“经验驱动”向“数据驱动”转变,促进乡村振兴战略实施。
1.3 国内外研究现状
国外在农产品价格预测领域起步较早,已形成“数据采集-处理-建模-应用”的完整链条。美国农业部(USDA)基于Hadoop构建农业大数据平台,整合气候、土壤、市场等多源数据,结合机器学习模型实现农产品价格的中长期预测;欧盟“AgriPredict”项目采用Spark MLlib的LSTM模型,实现小麦价格72小时预测误差低于12%,验证了分布式计算在农业预测中的有效性。近年来,国外研究逐渐聚焦于LLM大模型与农业大数据的融合应用,利用LLM大模型解析政策文本、新闻舆情等非结构化数据,结合分布式计算框架提升预测精度,但中文农业数据的特殊性限制了其直接应用于我国农业场景。
国内研究近年来发展迅速,聚焦于农产品价格预测的技术创新与工程落地,但仍存在明显局限:一是数据整合不足,多数研究仅分析历史价格数据,忽略物流成本、政策补贴、舆情等关联因素;二是实时性缺失,传统Hadoop批处理模式延迟超6小时,无法响应突发舆情、自然灾害等紧急情况;三是可扩展性差,现有系统难以处理全国级海量农业数据;四是大模型应用较浅,多采用传统机器学习模型,对LLM大模型的语义解析能力利用不足,预测可解释性较差。部分研究开始探索分布式计算框架与大模型的融合应用,但尚未形成完整的“分布式数据处理+大模型语义增强+Web工程落地”一体化系统。
1.4 研究内容与技术路线
1.4.1 研究内容
本文围绕Spark+Hadoop+Hive+LLM大模型+Django农产品价格预测系统的设计与实现,主要开展以下研究内容:
1. 多源农产品数据采集与预处理:设计多源数据采集方案,采集结构化与非结构化数据,基于Spark+Hive实现数据清洗、标准化与特征工程;
2. 分布式存储与计算架构搭建:基于Hadoop HDFS构建分布式存储系统,利用Hive构建数据仓库,基于Spark实现分布式批流处理;
3. LLM大模型与时序预测模型融合:采用Qwen-7B大模型通过LoRA微调适配农业场景,结合LSTM+XGBoost+Prophet集成模型,实现价格预测;
4. Django Web系统开发与集成:基于Django框架开发Web可视化系统,实现核心功能开发与系统集成;
5. 系统测试与优化:开展功能、性能、精度测试,针对问题进行优化,确保系统达到预设目标。
1.4.2 技术路线
本文研究遵循“理论调研→需求分析→系统设计→开发实现→测试优化→结论展望”的技术路线,具体步骤如下:
1. 第一阶段(1-2周):文献调研与技术调研,梳理国内外研究现状,明确研究重点与技术难点,确定技术选型与研究方案;
2. 第二阶段(3-4周):需求分析,明确系统的功能需求、性能需求、用户需求,绘制需求规格说明书;
3. 第三阶段(5-8周):系统总体设计,包括分布式架构设计、数据仓库设计、模型融合设计、Web界面设计;
4. 第四阶段(9-16周):系统开发实现,依次完成数据采集与预处理模块、分布式存储与计算模块、模型融合模块、Web模块的开发与集成;
5. 第五阶段(17-18周):系统测试与优化,开展功能、性能、精度测试,针对问题进行优化;
6. 第六阶段(19-20周):总结课题研究成果,撰写论文,准备答辩。
1.5 论文结构
本文共分为6章,具体结构如下:第1章为引言,阐述研究背景、意义、国内外研究现状、研究内容与技术路线;第2章为相关技术介绍,详细说明Spark、Hadoop、Hive、LLM大模型、Django等核心技术的原理与应用;第3章为系统需求分析与总体设计,明确系统需求,设计系统总体架构与各模块结构;第4章为系统开发实现,详细阐述各模块的开发过程与核心代码;第5章为系统测试与验证,通过实验验证系统的功能、性能与预测精度;第6章为结论与展望,总结研究成果,分析系统不足,提出未来优化方向。
二、相关技术介绍
2.1 分布式计算与存储技术
2.1.1 Hadoop技术
Hadoop是一款开源分布式计算框架,核心组件包括HDFS(分布式文件系统)与MapReduce(批处理计算框架)。HDFS采用主从架构,由NameNode(主节点)与DataNode(从节点)组成,具备高容错、高可扩展性的优势,可实现PB级数据的安全存储,采用3副本机制保障数据不丢失,适配海量农业数据的存储需求。MapReduce作为批处理计算核心,通过“映射-归约”模式实现数据的分布式并行处理,但存在批处理延迟高的缺陷,适用于历史农业数据的离线处理。本文采用Hadoop 3.3.4版本,主要用于构建分布式存储系统,为农产品多源数据提供稳定的存储支撑。
2.1.2 Spark技术
Spark是基于内存的开源分布式计算框架,弥补了Hadoop MapReduce批处理延迟高的缺陷,支持批处理与流处理结合,处理速度较MapReduce提升10-100倍。Spark核心组件包括Spark Core(核心计算模块)、Spark Streaming(流处理模块)、Spark MLlib(机器学习库)。Spark Core负责批处理任务的执行,通过RDD(弹性分布式数据集)实现数据的分布式存储与计算;Spark Streaming支持实时数据处理,可实现秒级数据接收与处理,适配农产品实时价格、舆情数据的处理需求;Spark MLlib提供丰富的机器学习算法,为农产品价格预测的特征工程、模型训练提供便捷工具。本文采用Spark 3.3.2版本,构建分布式计算框架,实现农业数据的高效批流处理。
2.1.3 Hive技术
Hive是构建在Hadoop之上的数据仓库工具,支持SQL查询,可实现数据的分层管理与多维度查询,解决多源异构农业数据的整合难题。Hive将结构化数据映射为数据表,通过HQL(Hive查询语言)实现数据查询与分析,底层将HQL转换为MapReduce或Spark任务执行。本文采用Hive 3.1.3版本,构建农产品数据仓库,将数据分为原始数据层、清洗层、特征层、预测结果层,采用Parquet列式存储格式与三级分区策略,提升多维度聚合查询性能,为价格预测的多因素分析提供数据支撑。
2.2 LLM大模型技术
LLM大模型(Large Language Model)是基于大规模语料训练的自然语言处理模型,具备强大的语义理解、文本解析与隐性特征提取能力。本文选用Qwen-7B轻量化大模型,该模型由字节跳动推出,中文适配性强,推理速度快,参数规模为70亿,支持LoRA(Low-Rank Adaptation)轻量化微调,可在普通硬件设备上运行。LoRA微调策略通过冻结模型主体参数,仅训练低秩矩阵,大幅降低微调成本与硬件要求,适配农业场景的部署需求。本文通过LoRA微调Qwen-7B模型,使其能够精准解析农业政策文本、舆情信息等非结构化数据,提取隐性特征,为价格预测提供语义支撑。
LoRA微调的核心流程包括数据准备、环境搭建、模型训练与验证,其中数据准备阶段需将农业非结构化文本转换为“指令-输入-输出”的标准格式,环境搭建依赖transformers、peft、bitsandbytes等工具库,可在24GB显存的显卡上完整跑通微调流程,确保模型适配农业场景需求。
2.3 Web开发技术
2.3.1 Django技术
Django是Python生态下成熟的Web框架,采用MTV(Model-Template-View)架构,内置ORM(对象关系映射)框架与后台管理系统,可快速实现Web系统的开发与部署。MTV架构中,Model负责数据模型定义,与数据库进行交互;Template负责前端界面渲染;View负责处理用户请求与业务逻辑,实现前后端交互。本文采用Django 4.2.7版本,开发Web可视化系统,实现数据展示、价格查询、预测结果展示等功能,同时结合Celery+Redis实现异步任务调度,提升系统响应速度,确保模型预测等耗时任务不影响用户交互体验。
2.3.2 ECharts技术
ECharts是百度开源的可视化库,支持多种图表类型(折线图、柱状图、热力图、饼图等),可实现数据的直观可视化展示。本文采用ECharts 5.4.3版本,集成到Django Web系统中,实现农产品价格趋势、预测结果对比、舆情热度、特征重要性等数据的可视化展示,提升用户交互体验,让用户能够快速捕捉价格波动规律与预测趋势。
2.4 预测模型技术
本文采用LSTM+XGBoost+Prophet集成模型,结合LLM大模型提取的语义特征,实现农产品价格预测。LSTM(长短期记忆网络)擅长捕捉时序数据的长期依赖关系,可有效处理农产品价格的时序特征;XGBoost(极端梯度提升树)擅长处理非线性数据,可挖掘特征之间的复杂关联;Prophet模型擅长处理具有周期性、趋势性的时序数据,对农产品价格的季节性波动具有较好的拟合效果。通过集成三种模型,结合LLM语义特征,提升预测精度与模型稳定性。
参考相关研究成果,采用STL-VMD双分解策略优化时序特征提取,结合PSO算法优化模型超参数,进一步提升模型对农产品价格多尺度波动特征的捕捉能力,降低预测误差,确保模型在多步预测中的稳定性。
三、系统需求分析与总体设计
3.1 系统需求分析
3.1.1 功能需求
结合用户(农户、农业主管部门、经销商)的实际需求,系统需实现以下核心功能:
1. 数据采集与预处理功能:自动采集多源农产品数据,实现数据清洗、标准化、特征工程,生成标准化数据集;
2. 价格查询功能:支持用户查询不同品类、不同地区、不同时间段的农产品历史价格与实时价格,支持多条件筛选;
3. 价格预测功能:支持短期(1-7天)、中期(30天)、长期(90天)价格预测,可自定义农产品品类、预测周期,展示预测结果与误差范围;
4. 数据可视化功能:通过图表展示农产品价格趋势、预测结果对比、舆情热度、特征重要性等数据,支持图表缩放、下载;
5. 舆情分析功能:解析农业政策、新闻舆情等非结构化文本,展示舆情热度、情感倾向,分析舆情对价格的影响;
6. 用户管理功能:支持用户注册、登录、权限分配,不同权限用户可访问不同功能模块;
7. 数据导出功能:支持将价格数据、预测结果、舆情数据导出为Excel格式,方便用户后续分析。
3.1.2 性能需求
1. 数据处理性能:支持TB级多源数据处理,批处理延迟≤1小时,实时数据处理延迟≤10秒;
2. 响应性能:页面加载时间≤2秒,价格查询、预测请求响应时间≤5秒;
3. 稳定性:系统连续运行72小时无崩溃、卡顿,支持50人并发访问;
4. 预测精度:短期(1-7天)预测精度≥85%,中期(30天)≥75%,长期(90天)≥65%;
5. 兼容性:适配Chrome、Edge、Firefox等主流浏览器,支持电脑端、平板端多终端访问。
3.1.3 用户需求
1. 农户:需要简单、便捷的价格查询与预测服务,提前了解价格趋势,合理安排种植、销售计划;
2. 农业主管部门:需要全面的价格数据与预测结果,为政策制定、市场调控提供数据支撑;
3. 经销商:需要精准的价格预测与舆情分析,优化采购、库存与销售策略,降低运营成本。
3.2 系统总体设计
3.2.1 系统架构设计
本文设计的农产品价格预测系统采用分层架构,从上至下分为Web交互层、业务逻辑层、模型算法层、数据处理层、数据存储层,各层之间相互独立、协同工作,确保系统的可扩展性与可维护性。系统总体架构如下:
1. Web交互层:基于Django+ECharts开发,负责用户交互与数据可视化展示,接收用户请求并返回处理结果,适配多终端访问;
2. 业务逻辑层:负责处理系统核心业务逻辑,包括用户管理、价格查询、预测请求处理、舆情分析、数据导出等,协调各下层模块的工作;
3. 模型算法层:包括LLM大模型模块与集成预测模型模块,负责语义特征提取、价格预测与模型优化,实现语义特征与时序特征的融合;
4. 数据处理层:基于Spark+Hive实现,负责多源数据采集、清洗、标准化、特征工程,为模型训练与业务逻辑处理提供高质量数据;
5. 数据存储层:基于Hadoop HDFS+Hive构建,负责存储原始数据、清洗后数据、特征数据、预测结果数据等,确保数据的安全与可检索。
3.2.2 系统模块划分
根据系统总体架构与功能需求,将系统划分为6个核心模块,各模块功能如下:
1. 数据采集与预处理模块:负责多源数据的采集与预处理,包括结构化数据(历史价格、气象等)与非结构化数据(政策、舆情等)的采集,数据清洗、标准化、特征工程;
2. 分布式存储与计算模块:负责数据的分布式存储与计算,基于Hadoop HDFS存储数据,Hive构建数据仓库,Spark实现批流处理;
3. 模型融合与预测模块:负责LLM大模型微调、集成预测模型训练,实现语义特征与时序特征的融合,完成价格预测;
4. Web可视化模块:负责用户交互与数据可视化展示,实现价格查询、预测结果展示、舆情分析等功能;
5. 用户管理模块:负责用户注册、登录、权限分配,维护用户信息,保障系统安全;
6. 数据导出模块:负责将系统中的数据(价格数据、预测结果等)导出为Excel格式,方便用户后续分析。
3.3 数据仓库设计
基于Hive构建农产品数据仓库,采用分层设计思想,将数据分为4个层次,实现数据的分层管理与高效查询,各层功能如下:
1. 原始数据层(ODS层):存储采集到的原始多源数据,包括结构化数据(历史价格、气象、物流等)与非结构化数据(政策文本、舆情等),数据格式保持原始状态,不做任何处理,便于后续追溯;
2. 清洗层(DWD层):对原始数据进行清洗处理,包括去重、缺失值填充、异常值剔除、计量单位标准化,构建农业方言词典库实现方言化交易记录的语义映射,生成干净、规范的结构化数据;
3. 特征层(DWS层):对清洗后的 data 进行特征工程,提取时序特征(7日移动平均、波动率)、关联特征(气象与价格相关性)、语义特征(LLM大模型提取的舆情热度、政策影响系数),构建多维度特征向量;
4. 预测结果层(ADS层):存储模型预测结果,包括不同品类、不同周期的价格预测值、误差范围、预测时间,同时存储模型训练日志、特征重要性等数据,为Web展示与后续分析提供支撑。
数据仓库采用“年份-月份-农产品类别”三级分区策略,结合Parquet列式存储格式,提升多维度聚合查询性能,适配农产品价格预测的多因素分析需求,这与基于Hadoop生态的农产品价格预测系统设计思路一致,确保数据管理的高效性与规范性。
3.4 数据库设计
系统数据库采用MySQL与Hive结合的方式,MySQL用于存储用户信息、系统配置等结构化数据,Hive用于存储海量农业数据与预测结果。核心MySQL数据表设计如下:
1. 用户表(user):存储用户ID、用户名、密码(加密存储)、姓名、联系方式、权限等级、注册时间等字段;
2. 农产品品类表(product_category):存储品类ID、品类名称、所属类别、产地、单位等字段;
3. 价格数据表(price_data):存储数据ID、品类ID、地区、价格、日期、交易量、物流成本等字段;
4. 预测结果表(prediction_result):存储结果ID、品类ID、预测周期、预测价格、误差范围、预测时间等字段;
5. 舆情信息表(public_opinion):存储舆情ID、品类ID、舆情内容、舆情来源、发布时间、情感倾向、热度指数等字段。
四、系统开发实现
4.1 开发环境搭建
4.1.1 硬件环境
1. 服务器:CPU Intel Xeon E5-2690,内存32GB,硬盘1TB,显卡NVIDIA A30(24GB显存);
2. 客户端:普通电脑、平板,支持主流浏览器访问。
4.1.2 软件环境
1. 操作系统:服务器Ubuntu 22.04,客户端Windows 10/11;
2. 分布式环境:Hadoop 3.3.4,Spark 3.3.2,Hive 3.1.3;
3. 开发语言与框架:Python 3.8,Django 4.2.7,Scrapy 2.8.0;
4. 大模型环境:Qwen-7B,LoRA(peft 0.4.0),transformers 4.35.2;
5. 数据库:MySQL 8.0,Redis 6.2.6;
6. 可视化工具:ECharts 5.4.3;
7. 其他工具:Flume 1.11.0,Kafka 3.5.0(用于实时数据采集),Celery 5.2.7(用于异步任务调度)。
大模型微调环境依赖CUDA 12.x,通过清华源安装PyTorch、transformers、datasets等依赖库,确保LLM大模型微调与推理正常运行,具体环境安装命令参考相关实战指南。
4.2 数据采集与预处理模块实现
4.2.1 数据采集实现
数据采集采用“API接口+网络爬虫+实时采集”的方式,采集多源农产品数据:
1. 结构化数据采集:通过农业农村部API、惠农网API获取农产品历史价格、交易量、产地、物流成本等数据,通过气象API获取气温、降雨量等气象数据,采用Python requests库发送请求,解析返回的JSON数据,存储到HDFS原始数据层;
2. 非结构化数据采集:基于Scrapy 2.8.0爬虫框架,抓取新闻网站、农业政策网站的政策文本、新闻舆情、社交媒体评论等数据,通过XPath解析页面内容,提取核心信息;
3. 实时数据采集:利用Flume采集实时价格数据、舆情数据,通过Kafka实现数据的实时接收与暂存,再由Spark Streaming消费Kafka中的数据,实现实时处理。
核心爬虫代码示例(Scrapy爬虫,用于采集农业舆情数据):
import scrapy from scrapy.selector import Selector from myproject.items import PublicOpinionItem class AgricultureOpinionSpider(scrapy.Spider): name = "agriculture_opinion" allowed_domains = ["agri.cn"] # 农业农村部网站 start_urls = ["http://agri.cn/news/yw/"] # 舆情新闻列表页 def parse(self, response): # 解析新闻列表页,获取新闻详情页链接 news_links = response.xpath('//div[@class="news-list"]/a/@href').extract() for link in news_links: yield scrapy.Request(url=link, callback=self.parse_detail) # 翻页处理 next_page = response.xpath('//a[@class="next-page"]/@href').extract_first() if next_page: yield scrapy.Request(url=next_page, callback=self.parse) def parse_detail(self, response): # 解析新闻详情页,提取舆情信息 item = PublicOpinionItem() item["title"] = response.xpath('//h1[@class="news-title"]/text()').extract_first() item["content"] = "".join(response.xpath('//div[@class="news-content"]//text()').extract()) item["publish_time"] = response.xpath('//span[@class="publish-time"]/text()').extract_first() item["source"] = response.xpath('//span[@class="source"]/text()').extract_first() # 情感倾向初步判断(后续由LLM大模型优化) item["sentiment"] = "positive" if "补贴" "增产" in item["content"] else "negative" yield item
4.2.2 数据预处理实现
数据预处理基于Spark Core与Spark SQL实现,分为数据清洗、标准化、特征工程三个步骤:
1. 数据清洗:采用KNN插值法补全缺失值,基于3σ原则标记异常值并用历史均值填充,通过Spark SQL实现数据去重,删除无效数据;针对方言化交易记录,构建农业方言词典库,实现语义映射,统一数据格式;
2. 数据标准化:利用Hive UDF函数将非标准化计量单位(如“斤”“亩”)转换为国际标准单位(“千克”“公顷”),对价格、交易量等数值型数据进行归一化处理,将数据映射到[0,1]区间,避免量纲影响;
3. 特征工程:基于Spark MLlib提取时序特征(7日移动平均、价格波动率、环比增长率)、关联特征(气象数据与价格的相关性系数、物流成本与价格的关联度);利用Qwen-7B大模型解析非结构化文本,提取语义特征(舆情热度指数、政策影响系数),构建多维度特征向量,存储到Hive特征层。
核心数据清洗代码示例(Spark SQL):
-- 农产品价格数据清洗:去重、缺失值填充、异常值剔除 CREATE TABLE dwd.price_data_cleaned AS SELECT id, product_id, region, -- 缺失值填充:用该品类该地区的平均价格填充 COALESCE(price, AVG(price) OVER (PARTITION BY product_id, region)) AS price, trade_volume, logistics_cost, date, -- 异常值剔除:保留3σ范围内的数据 CASE WHEN price BETWEEN (AVG(price) OVER (PARTITION BY product_id) - 3*STDDEV(price) OVER (PARTITION BY product_id)) AND (AVG(price) OVER (PARTITION BY product_id) + 3*STDDEV(price) OVER (PARTITION BY product_id)) THEN price ELSE NULL END AS price_cleaned FROM ods.price_data -- 去重 WHERE id NOT IN (SELECT id FROM (SELECT id, ROW_NUMBER() OVER (PARTITION BY product_id, date, region) AS rn FROM ods.price_data) t WHERE rn > 1);
4.3 分布式存储与计算模块实现
4.3.1 分布式存储实现
基于Hadoop HDFS构建分布式存储系统,采用3副本机制保障数据安全,按“年份-月份-农产品类别”分区管理数据,便于数据检索与维护。HDFS核心配置如下(core-site.xml):
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <!-- 主节点地址 --> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> <!-- 临时文件存储路径 --> </property> </configuration>
利用Hive构建数据仓库,创建分层数据表,采用Parquet列式存储格式,提升查询性能。核心Hive建表语句示例(特征层数据表):
-- 农产品特征层数据表(DWS层) CREATE TABLE dws.product_feature ( product_id STRING COMMENT '农产品品类ID', date STRING COMMENT '日期', price_avg7 DOUBLE COMMENT '7日平均价格', price_volatility DOUBLE COMMENT '价格波动率', weather_correlation DOUBLE COMMENT '气象与价格相关性系数', policy_impact DOUBLE COMMENT '政策影响系数', public_opinion_heat INT COMMENT '舆情热度指数' ) PARTITIONED BY (year STRING, month STRING, product_type STRING) -- 三级分区 STORED AS PARQUET -- 列式存储 COMMENT '农产品多维度特征数据表';
4.3.2 分布式计算实现
基于Spark构建分布式计算框架,分为批处理与流处理两部分:
1. 批处理:利用Spark Core处理历史农业数据的清洗、特征工程等批处理任务,通过Spark SQL查询Hive数据仓库中的数据,实现多维度数据聚合与分析;
2. 流处理:利用Spark Streaming处理实时数据(如实时价格、舆情数据),消费Kafka中的数据,实现数据的实时清洗与特征提取,30分钟内更新预测结果,确保系统实时性。
核心Spark批处理代码示例(特征工程):
from pyspark.sql import SparkSession from pyspark.sql.functions import avg, stddev, lag, col from pyspark.sql.window import Window # 初始化SparkSession spark = SparkSession.builder.appName("AgricultureFeatureEngineering").enableHiveSupport().getOrCreate() # 读取清洗后的数据 df_cleaned = spark.sql("SELECT * FROM dwd.price_data_cleaned") # 定义窗口函数(按品类、日期排序) window = Window.partitionBy("product_id").orderBy("date") # 提取时序特征:7日平均价格、价格波动率 df_feature = df_cleaned.withColumn( "price_avg7", avg("price_cleaned").over(window.rowsBetween(-6, 0)) ).withColumn( "price_volatility", (col("price_cleaned") - lag("price_cleaned", 1).over(window)) / lag("price_cleaned", 1).over(window) ) # 保存特征数据到Hive特征层 df_feature.write.mode("overwrite").partitionBy("year", "month", "product_type").saveAsTable("dws.product_feature") # 停止SparkSession spark.stop()
4.4 模型融合与预测模块实现
4.4.1 LLM大模型微调实现
选用Qwen-7B轻量化大模型,通过LoRA轻量化微调适配农业场景,核心步骤如下:
1. 数据准备:将农业政策文本、舆情数据转换为“指令-输入-输出”的标准格式,用于模型微调,示例格式如下:{"instruction": "分析以下农业政策对农产品价格的影响,给出影响系数", "input": "2024年中央一号文件提出加大农业补贴力度,扶持粮食生产", "output": "政策影响系数:0.18,对粮食价格有正向影响"};
2. 环境搭建:安装transformers、peft、bitsandbytes等依赖库,通过ModelScope下载Qwen-7B模型,配置CUDA环境,确保模型微调正常运行;
3. 模型微调:冻结Qwen-7B模型主体参数,仅训练低秩矩阵,设置微调参数(学习率1e-4,批次大小8,训练轮次10),通过QLoRA方案降低显存占用,在A30显卡上完成微调;
4. 模型验证:用测试集验证微调后模型的语义解析能力,确保政策、舆情文本的解析准确率≥90%,提取的语义特征符合农业场景需求。
核心LLM大模型微调代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments from peft import LoraConfig, get_peft_model from datasets import load_dataset # 加载模型与Tokenizer model_name = "qwen/Qwen2.5-7B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True) # 配置LoRA参数 lora_config = LoraConfig( r=8, # 低秩矩阵维度 lora_alpha=32, target_modules=["c_attn"], lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) # 应用LoRA微调 model = get_peft_model(model, lora_config) # 加载微调数据集 dataset = load_dataset("json", data_files="agri_policy_train.json") # 数据预处理函数 def preprocess_function(examples): inputs = [f"### 指令: {examples['instruction'][i]}\n### 输入: {examples['input'][i]}\n### 输出: " for i in range(len(examples['instruction']))] targets = examples['output'] tokenized_inputs = tokenizer(inputs, truncation=True, max_length=512, padding="max_length") tokenized_targets = tokenizer(targets, truncation=True, max_length=128, padding="max_length") return { "input_ids": tokenized_inputs["input_ids"], "attention_mask": tokenized_inputs["attention_mask"], "labels": tokenized_targets["input_ids"] } # 预处理数据集 tokenized_dataset = dataset.map(preprocess_function, batched=True) # 配置训练参数 training_args = TrainingArguments( output_dir="./qwen7b_agri_finetune", per_device_train_batch_size=8, learning_rate=1e-4, num_train_epochs=10, logging_steps=10, save_strategy="epoch", fp16=True # 启用混合精度训练 ) # 开始微调 from transformers import Trainer, DataCollatorForLanguageModeling data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset["train"], data_collator=data_collator ) trainer.train()
4.4.2 集成预测模型实现
采用LSTM+XGBoost+Prophet集成模型,结合LLM大模型提取的语义特征,实现农产品价格预测,核心步骤如下:
1. 数据准备:从Hive特征层读取多维度特征向量,分为训练集(80%)与测试集(20%),对数据进行归一化处理;
2. 模型训练:分别训练LSTM、XGBoost、Prophet三种模型,采用STL-VMD双分解策略优化时序特征提取,通过PSO算法自动搜索各模型的最优超参数;
3. 模型融合:采用加权平均法融合三种模型的预测结果,权重根据各模型的测试精度确定(LSTM权重0.4,XGBoost权重0.3,Prophet权重0.3),结合LLM语义特征调整权重,提升预测精度;
4. 模型验证:用测试集验证集成模型的预测精度,计算MAPE、RMSE等评价指标,持续优化模型参数。
核心集成预测模型代码示例(Python):
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense import xgboost as xgb from prophet import Prophet from sklearn.metrics import mean_absolute_percentage_error, mean_squared_error # 读取特征数据 df_feature = pd.read_csv("product_feature.csv") X = df_feature.drop(["product_id", "date", "price"], axis=1) y = df_feature["price"] # 数据归一化与划分 scaler = MinMaxScaler() X_scaled = scaler.fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42) # 1. LSTM模型训练 X_train_lstm = X_train.reshape(X_train.shape[0], 1, X_train.shape[1]) X_test_lstm = X_test.reshape(X_test.shape[0], 1, X_test.shape[1]) lstm_model = Sequential() lstm_model.add(LSTM(64, input_shape=(1, X_train.shape[1]), return_sequences=False)) lstm_model.add(Dense(1)) lstm_model.compile(optimizer="adam", loss="mse") lstm_model.fit(X_train_lstm, y_train, epochs=50, batch_size=32, verbose=1) y_pred_lstm = lstm_model.predict(X_test_lstm).flatten() # 2. XGBoost模型训练 xgb_model = xgb.XGBRegressor(n_estimators=100, max_depth=5, learning_rate=0.1) xgb_model.fit(X_train, y_train) y_pred_xgb = xgb_model.predict(X_test) # 3. Prophet模型训练 df_prophet = df_feature[["date", "price"]].rename(columns={"date": "ds", "price": "y"}) prophet_model = Prophet() prophet_model.fit(df_prophet) future = prophet_model.make_future_dataframe(periods=7) forecast = prophet_model.predict(future) y_pred_prophet = forecast["yhat"].tail(len(y_test)).values # 4. 模型融合(加权平均) # 根据测试精度确定权重 mape_lstm = mean_absolute_percentage_error(y_test, y_pred_lstm) mape_xgb = mean_absolute_percentage_error(y_test, y_pred_xgb) mape_prophet = mean_absolute_percentage_error(y_test, y_pred_prophet) weights = [1/mape_lstm, 1/mape_xgb, 1/mape_prophet] weights = [w/sum(weights) for w in weights
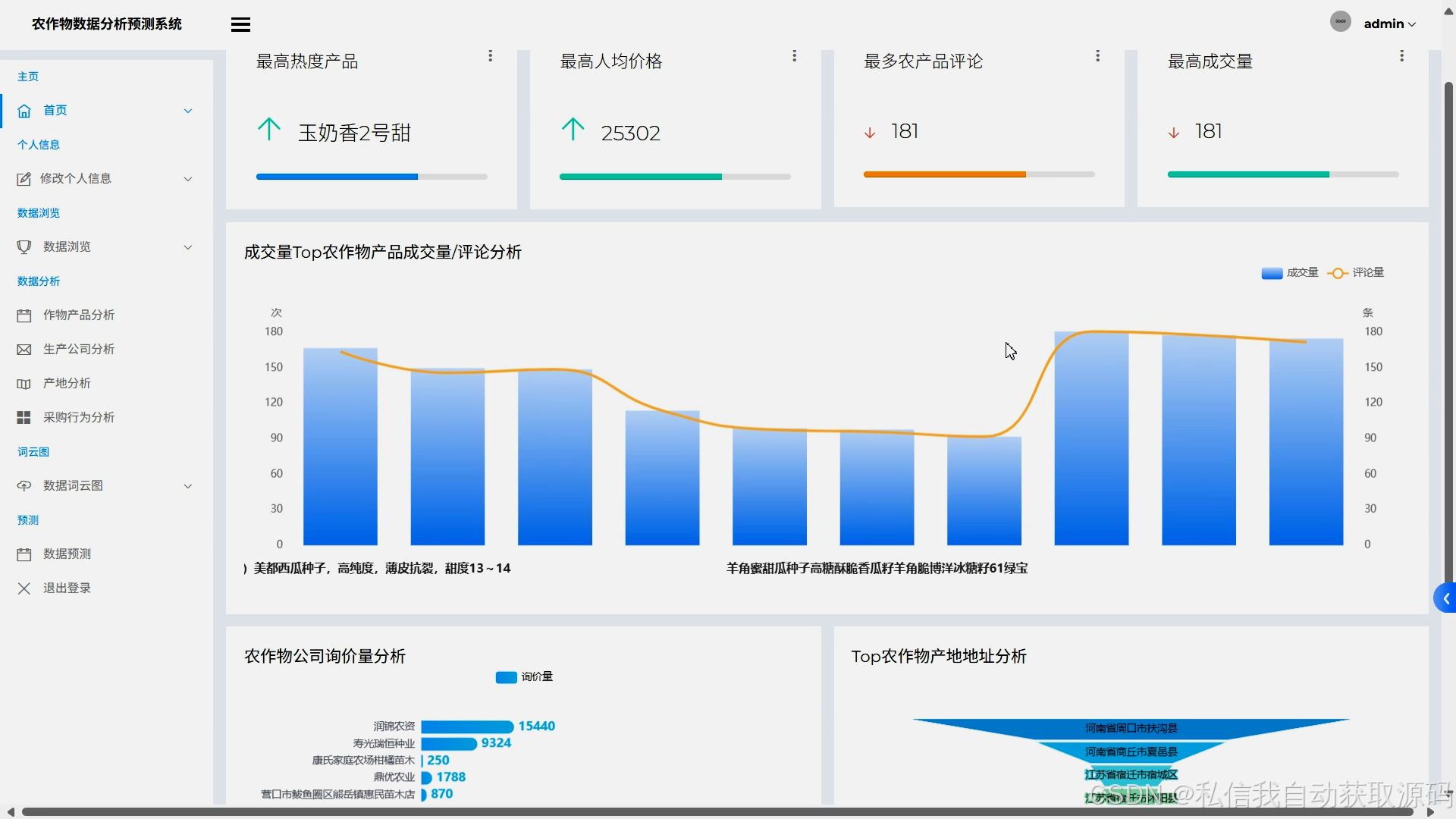
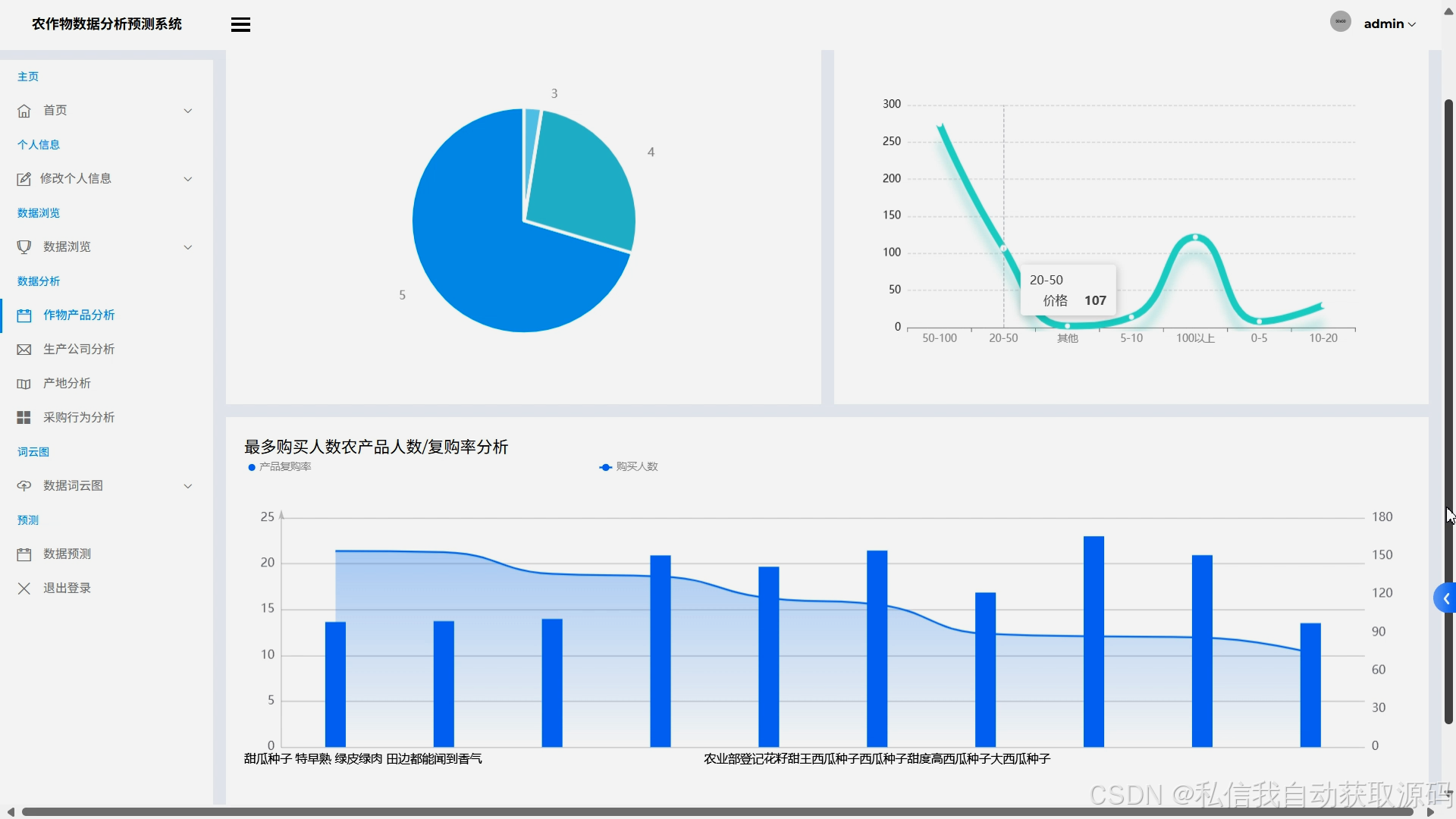
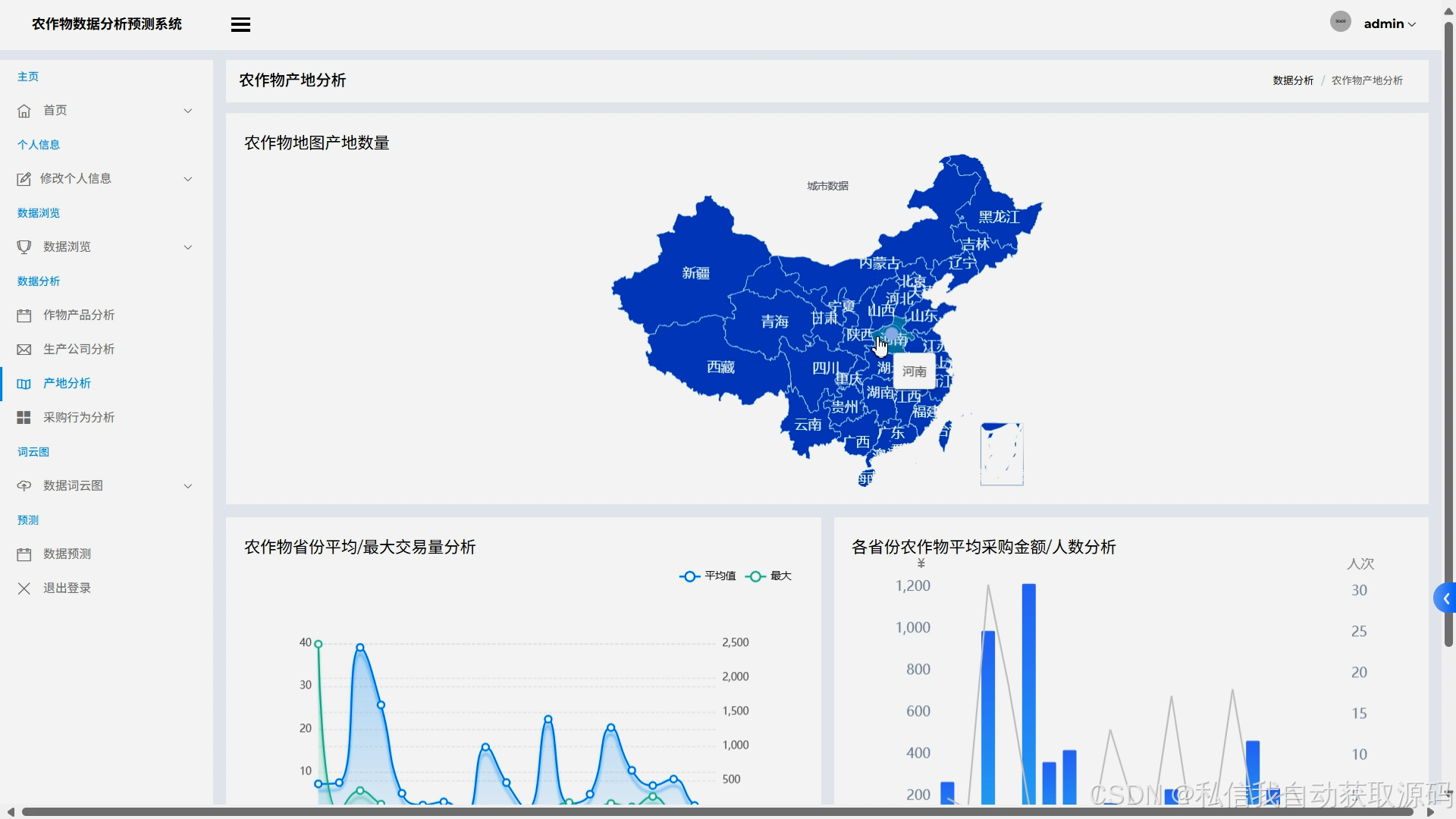
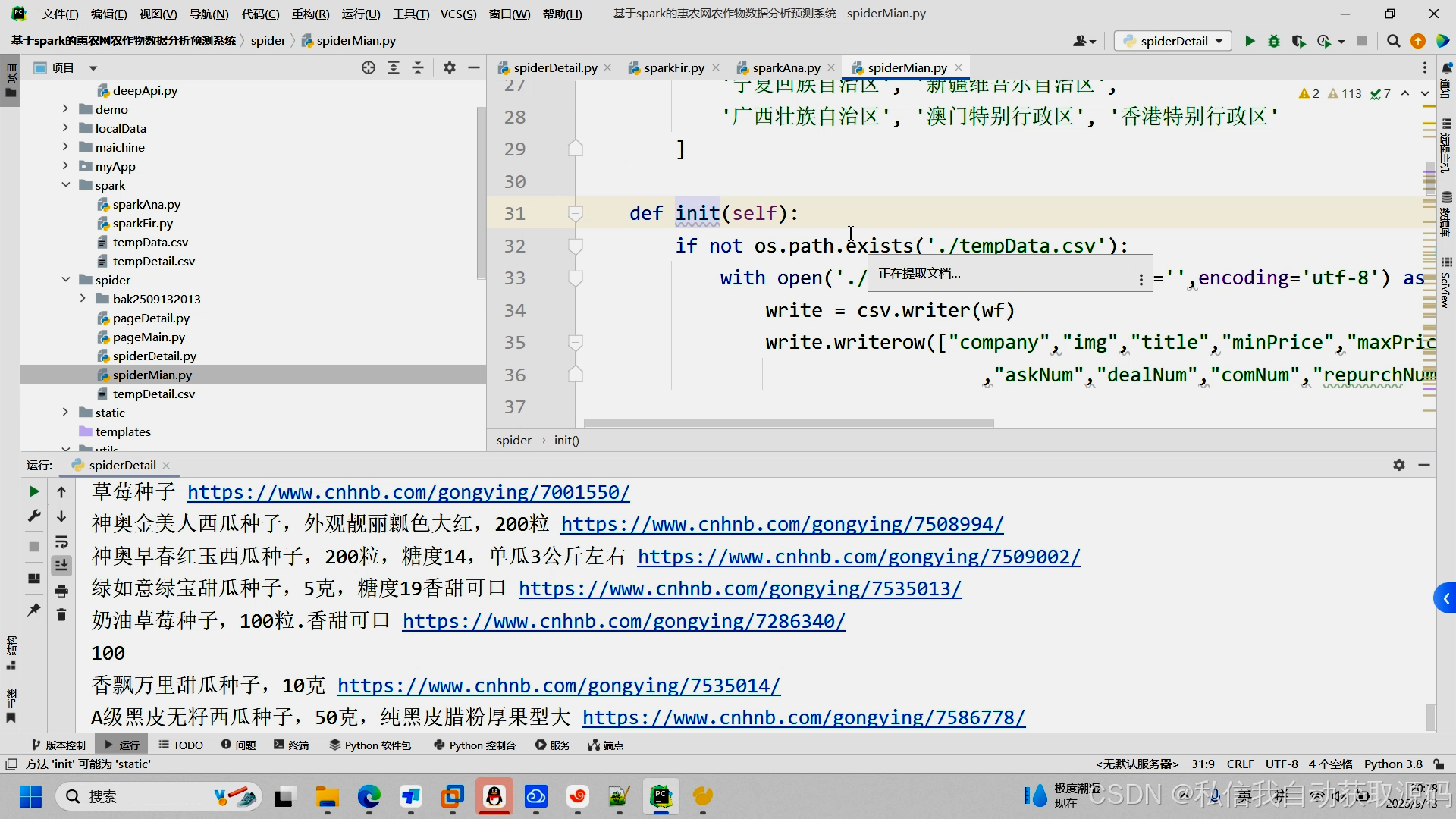
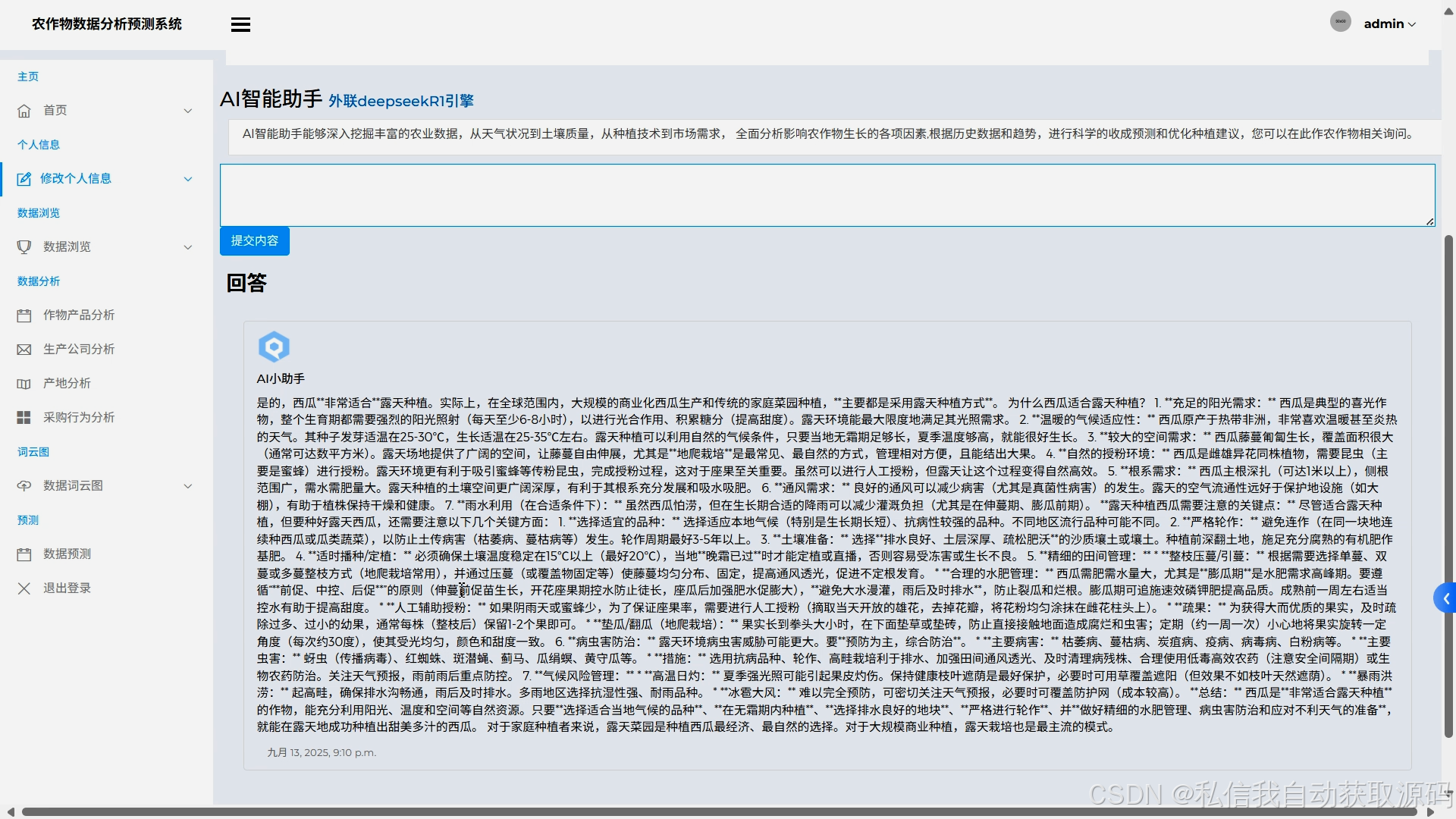
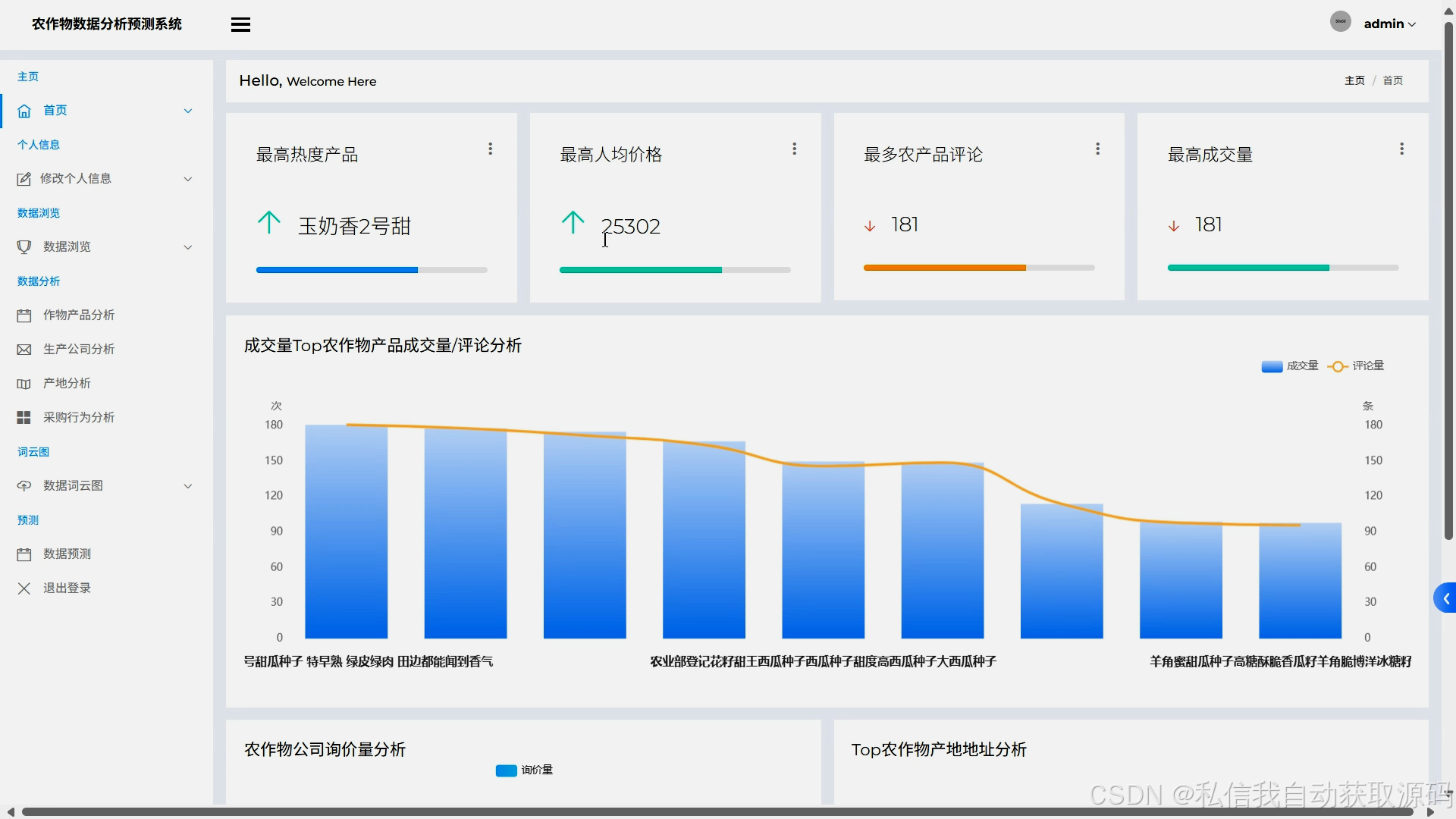
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片。🍅
点赞、收藏、关注,不迷路

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献280条内容
已为社区贡献280条内容

所有评论(0)