【开源】Skill 写到上百行,Agent 却越来越迷茫?BitFun SkillTree实战:一键告别Skill臃肿,让Agent不再迷茫
一、先聊聊痛点
写 Skill 的时候,你有没有这种感觉:
刚开始很简单,一个 SKILL.md 几十行搞定。但随着功能增加,文件越来越长,几百行、上千行,Agent 反而越来越"笨"——明明写了很详细的指令,它却经常跑错分支,或者把不相关的功能混在一起执行。
更头疼的是,当你想拆成多个 Skill 时,新问题又来了:Agent 不知道该用哪个,用户 prompt 匹配不上任何入口,多个 Skill 之间也没法协作。
这就是我们在实际开发中遇到的两个核心痛点:单体太臃肿,多体又散乱。
二、Skill Tree 是什么
BitFun 的解法不是让你重写,而是帮你重构。
Skill Tree 模拟文件系统的层级结构,把臃肿的单体 Skill 拆成一棵清晰的能力树:
ROOT.md → 一级路由,看关键词决定进哪个模块
├── ROUTER.md → 二级路由,继续分发到具体能力
│ ├── SKILL.md [LEAF] → 叶子节点,真正的执行单元
│ └── SKILL.md [LEAF]
└── ROUTER.md
└── SKILL.md [LEAF]核心思路很简单:Agent 只需要看到它当前需要的那部分,其他的不用加载。
三、Skill Tree的三种模式
第一种:单体转树
你已经有一个大 Skill 了,直接一条命令拆成树:
bitfun skill-tree generate --source ./my-skill.md --output ./skill-tree/自动完成路由分层、能力拆分、共享合并。
第二种:多 Skill 聚合
手头有几个独立的 Skill,想统一管理?Skill Tree 能自动识别:
-
完全相同的能力 → 合并
-
相似但不同的能力 → 保留各自独立,自动生成消歧规则
-
跨 Skill 的工作流 → 自动串联
第三种:增量更新
树已经建好了,想加新功能?直接追加,自动完成结构适配。
四、数据说话:Skill Tree 到底强在哪
我们基于 SkillBench 框架,在 5 个不同领域的 Task 上做了对比测试,三种方案横向比较:
-
No-Skill:不加载任何 Skill,纯靠模型自身能力
-
150 个 Skill:全量加载所有 Skill,看看堆量有没有用
-
SkillTree:智能路由,按需加载

4.1 通过率对比:SkillTree 全面领先
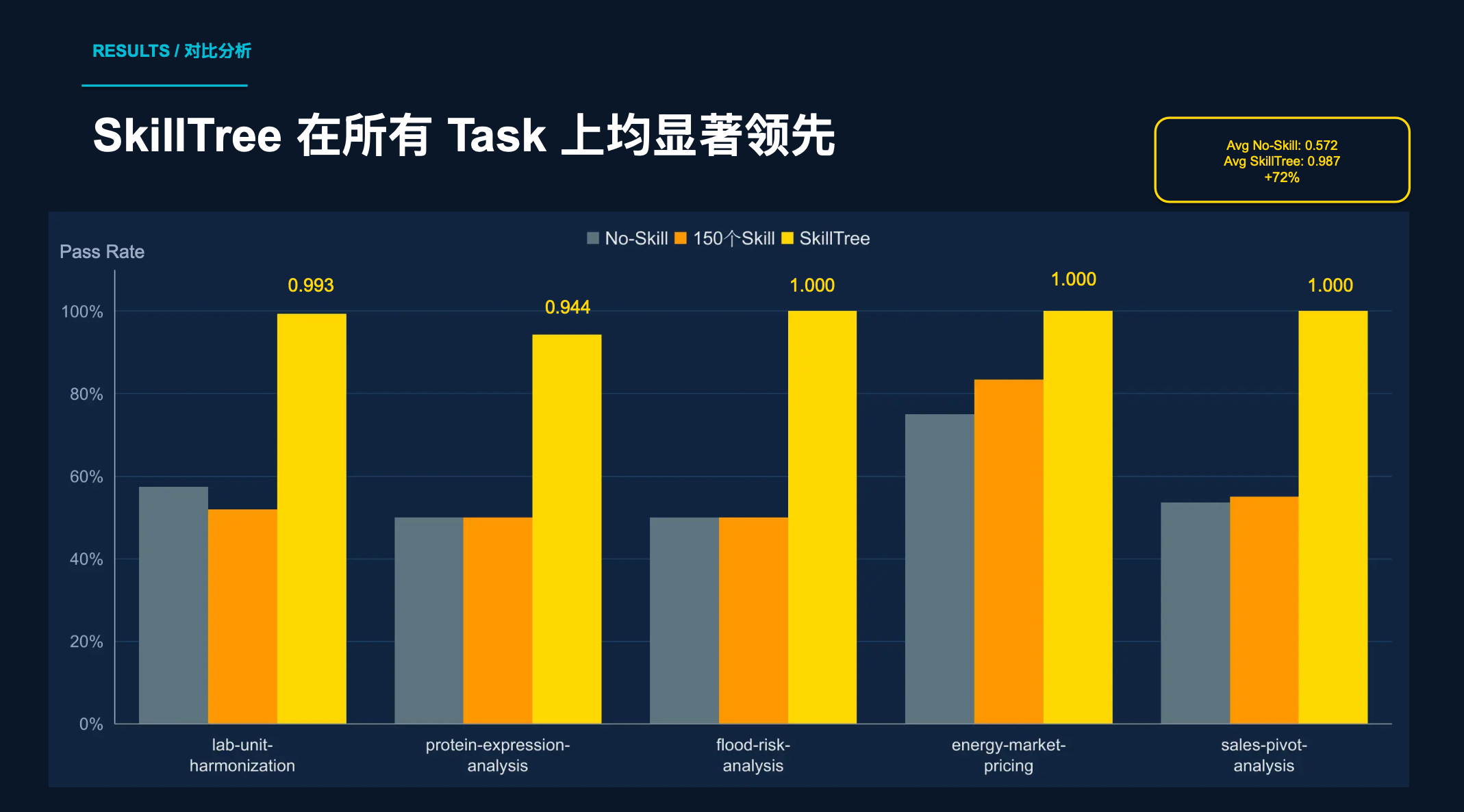
 测试结果很直观:
测试结果很直观:
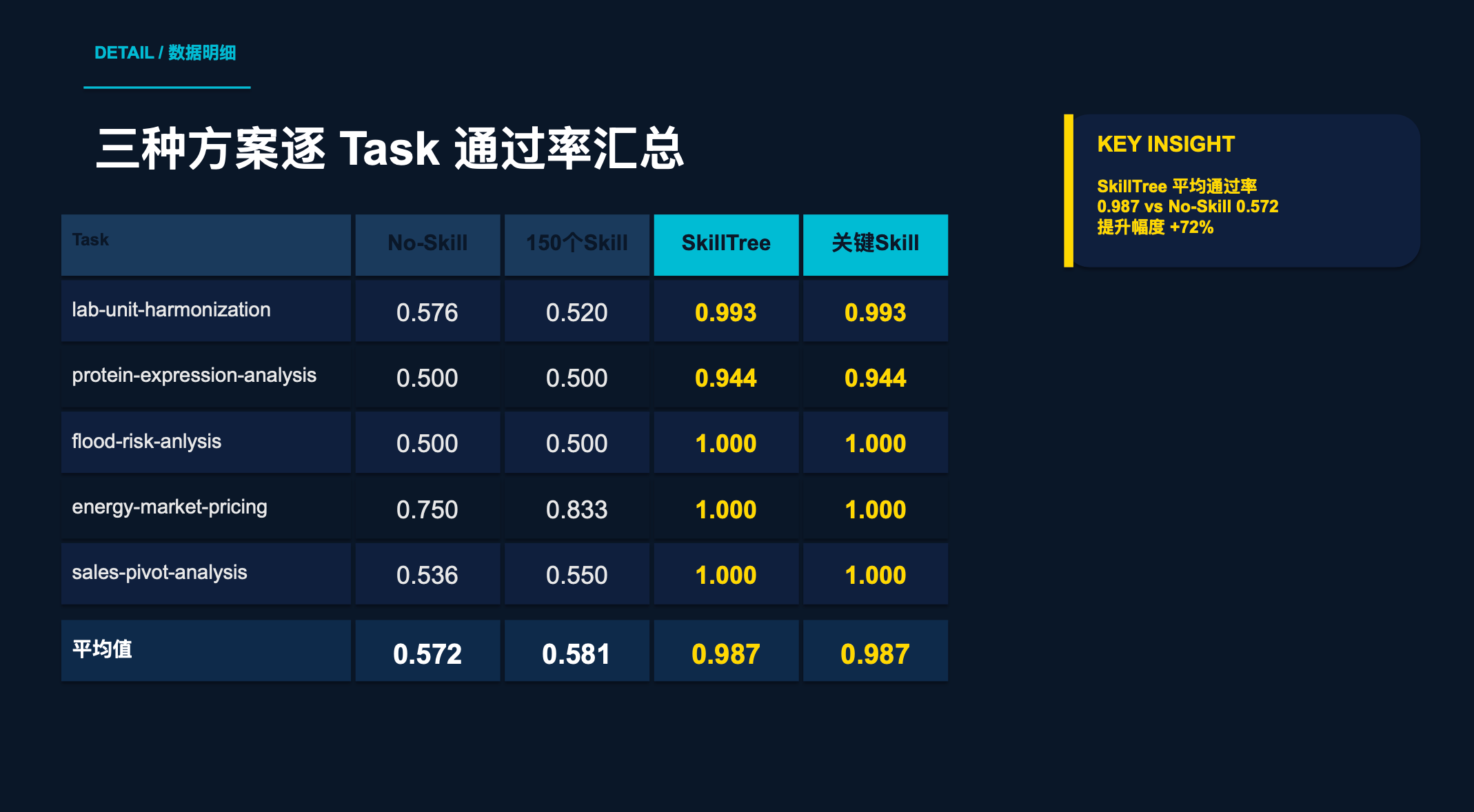
| Task | No-Skill | 150 个 Skill | SkillTree |
|---|---|---|---|
| lab-unit-harmonization | 0.576 | 0.520 | 0.993 |
| protein-expression-analysis | 0.500 | 0.500 | 0.944 |
| flood-risk-analysis | 0.500 | 0.500 | 1.000 |
| energy-market-pricing | 0.750 | 0.833 | 1.000 |
| sales-pivot-analysis | 0.536 | 0.550 | 1.000 |
| 平均 | 0.572 | 0.581 | 0.987 |
 几个关键发现:
几个关键发现:
第一,Skill 不是越多越好。 150 个 Skill 全量加载,平均通过率只有 0.581,比 No-Skill 的 0.572 几乎没提升。为什么?因为无关 Skill 严重干扰了 Agent 的判断,上下文被噪音淹没。
第二,SkillTree 提升幅度高达 +72%。 从 0.572 跃升到 0.987,这不是微调,是质变。
第三,SkillTree 在 3 个 Task 上达到满分 1.000。 说明精准命中关键 Skill 时,Agent 的表现可以非常稳定。
顺便提一个反直觉的发现:测试中还观察到,随着 Skill 数量增多,触发率会急剧下降——1 个 Skill 时 100%,30 个时 90%,150 个时直接归零。这也侧面印证了盲目堆 Skill 数量没用,关键在于精准命中。
4.2 为什么 SkillTree 能赢:精准命中 = 高通过率
 我们进一步做了验证:如果只用每个 Task 对应的关键 Skill(而不是 150 个全部加载),通过率是多少?
我们进一步做了验证:如果只用每个 Task 对应的关键 Skill(而不是 150 个全部加载),通过率是多少?
结果惊人:关键 Skill 的通过率 ≈ SkillTree 的通过率。
| Task | 关键 Skill 通过率 | SkillTree 通过率 |
|---|---|---|
| lab-unit-harmonization | 0.993 | 0.993 |
| protein-expression-analysis | 0.944 | 0.944 |
| flood-risk-analysis | 1.000 | 1.000 |
| energy-market-pricing | 1.000 | 1.000 |
| sales-pivot-analysis | 1.000 | 1.000 |
这说明 SkillTree 的核心价值在于精准命中关键 Skill。它不是加载更多,而是加载更对。
4.3 实战对比:同一任务,两种输出
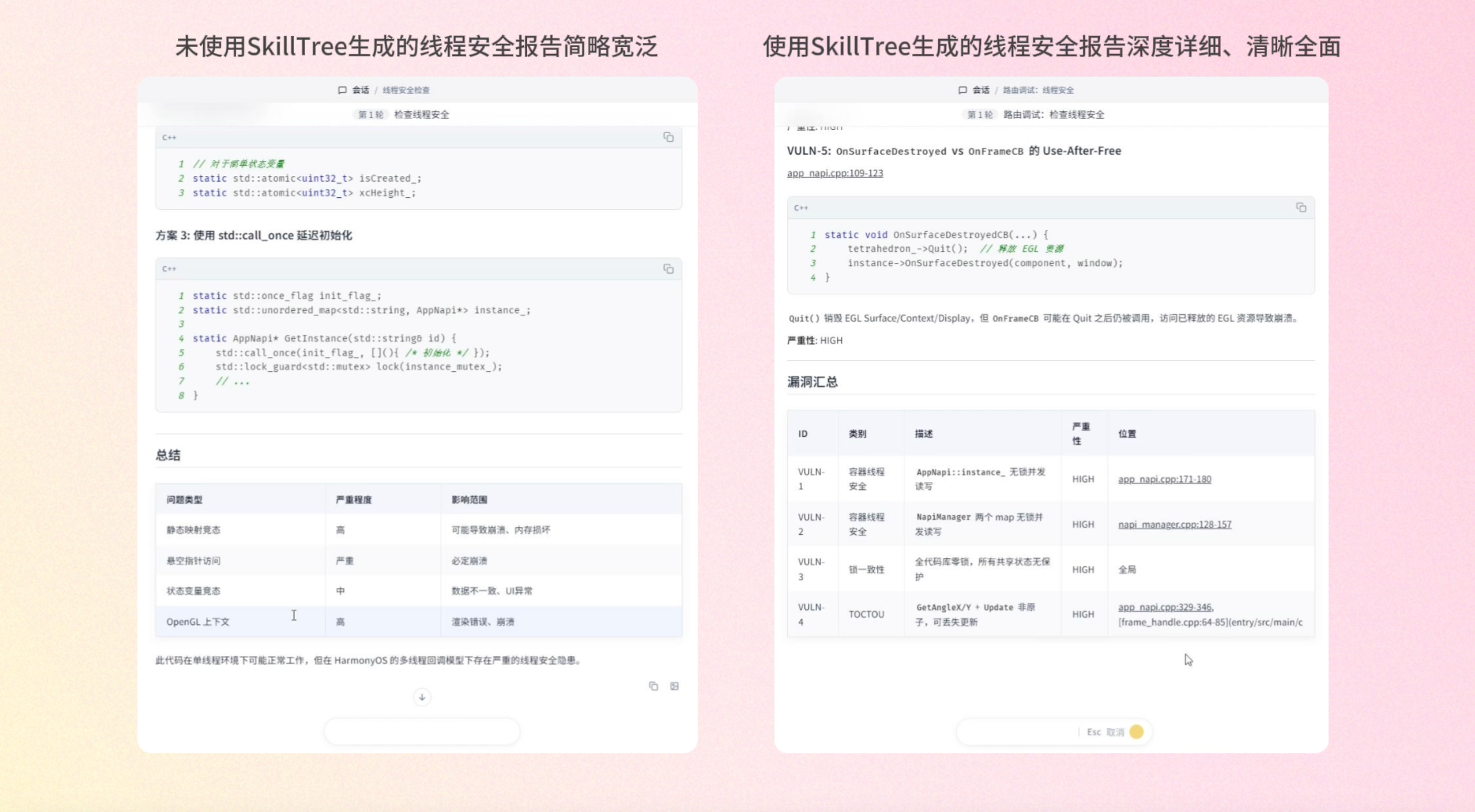
我们拿一个真实的 C++ 多线程项目做测试,Task 是线程安全审查。
不用 Skill Tree 时,Agent 只能给出宽泛结论:
-
静态变量无同步保护(位置:app_napi.h:68-83)
-
GetInstance() 存在竞态条件(位置:app_napi.cpp:171-180)
-
NapiManager 映射竞态(位置:napi_manager.cpp:128-157)
-
OpenGL 上下文线程安全(位置:tetrahedron.cpp:264-329)
问题列出来了,但缺少深入分析:风险有多大?怎么触发的?怎么修?都没有展开。
使用 Skill Tree 后,Agent 精准加载「并发安全审查」专业能力,输出深度报告:
-
每个问题给出具体代码片段,标出读写位置
-
分析竞态路径:线程1的回调链 vs 线程2的 JS 调用链如何冲突
-
评估严重程度:静态映射竞态(高)、悬空指针(严重)、状态变量竞态(中)、OpenGL 上下文(高)
-
给出修复方案:添加互斥锁、使用
std::call_once延迟初始化等,附带代码示例 -
最后总结影响范围:崩溃、内存损坏、数据不一致、渲染错误
| 维度 | 无 Skill Tree | Skill Tree |
|---|---|---|
| 问题定位 | 文件和行号 | 文件和行号 + 代码片段 |
| 风险分析 | 无 | 竞态路径 + 严重程度 |
| 修复方案 | 无 | 多种方案 + 代码示例 |
| 影响评估 | 无 | 按类型汇总影响范围 |
差距不在于 prompt 长短,而在于 Skill Tree 让 Agent 只加载当前需要的专业能力,从识别到分析到修复,每一步都精准到位。
五、Skill Tree 为什么能这么优秀
Skill Tree 的优势可以总结成四点:
| 优势 | 实际意义 |
|---|---|
| 按需加载 | Agent 只读当前路径上的文件,无关 Skill 不加载,上下文更干净 |
| 精准路由 | 分层匹配关键词,Agent 知道该走哪条路 |
| 统一入口 | 多 Skill 聚合成一棵树,用户不用关心背后有几个 Skill |
| 可扩展 | 加新能力就像加文件夹,不影响现有结构 |
而且整个过程免训练、轻量级、开箱即用,和现有 BitFun 工作流无缝衔接。
六、写在最后
Skill Tree 不是为了炫技,而是为了解决我们在实际开发中真实遇到的问题:
-
从混沌到清晰:单体 → 分层路由
-
从模糊到精准:全量加载 → 按需加载
-
从孤立到协同:单 Skill → 统一能力树
如果你也在折腾 AI 助手,不妨试试看。
官网:https://openbitfun.com
GitHub:https://github.com/GCWing/BitFun
欢迎大家试用,喜欢的话顺手点个 Star 🌟🌟支持我们~
感谢每一位选择BitFun的小伙伴 ,让我们一起在AI时代玩得开心~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)