V-JEPA 2: Self-Supervised Video Models EnableUnderstanding, Prediction and Planning
现代人工智能面临的一项重大挑战,是如何主要通过观察来学习理解世界并学会行动(LeCun,2022)。本文探索了一种自监督方法,将互联网规模的视频数据与少量交互数据(机器人轨迹)相结合,以开发能够在物理世界中进行理解、预测和规划的模型。我们首先在一个包含超过100万小时互联网视频的视频与图像数据集上,预训练了一个不依赖动作信息的联合嵌入预测架构 V-JEPA 2。V-JEPA 2 在运动理解任务上表现优异,在 Something-Something v2 数据集上取得了 77.3% 的 top-1 准确率;同时,在人类动作预测任务 Epic-Kitchens-100 上取得了 39.7 的 recall-at-5,达到当前最先进水平,并超过了以往的任务专用模型。此外,在将 V-JEPA 2 与大语言模型对齐后,我们展示了其在 80 亿参数规模下,在多个视频问答任务中达到最先进性能,例如在 PerceptionTest 上取得 84.0,在 TempCompass 上取得 76.9。最后,我们展示了自监督学习如何应用于机器人规划任务:通过使用 Droid 数据集中少于 62 小时的无标注机器人视频,对一个潜在的动作条件世界模型 V-JEPA 2-AC 进行后训练。我们将 V-JEPA 2-AC 零样本部署到两个不同实验室的 Franka 机械臂上,使其能够基于图像目标完成物体抓取与放置任务。值得注意的是,这一过程没有从这些环境中的机器人采集任何数据,也没有进行任何任务特定训练或奖励设计。该工作表明,基于网络规模数据和少量机器人交互数据的自监督学习,可以得到一个能够在物理世界中进行规划的世界模型。
1 Introduction
人类在承担新任务或身处陌生环境时,具备适应与泛化的能力。多项认知学习理论指出,人类通过整合低级感官输入来构建对世界的内部模型,用以表征并预测未来状态(Craik ,1967; Rao and Ballard ,1999);这些理论进一步强调,这种世界模型会塑造我们当前的感知方式,在理解现实过程中发挥关键作用(Friston ,2010; Clark ,2013; Nortmann et al.,2015)。此外,预测自身行为对世界未来状态的影响能力,对于目标导向型规划至关重要(Sutton and Barto,1981,1998; Ha and Schmidhuber,2018; Wolpert and Ghahramani,2000)。通过让人工智能代理从视频等感官数据中学习世界模型,它们能够理解物理世界、预测未来状态,并像人类一样在新情境中制定有效计划,从而具备应对前所未见任务的能力。
以往研究已经探索了如何从由状态—动作序列构成的交互数据中构建预测型世界模型,这些方法通常还依赖环境提供的显式奖励反馈来推断目标(Sutton and Barto, 1981; Fragkiadaki et al., 2015; Ha and Schmidhuber, 2018; Hafner et al., 2019b; Hansen et al., 2022)。然而,真实世界交互数据的可获得性有限,这限制了此类方法的可扩展性。为了解决这一问题,近期一些研究开始同时利用互联网规模的视频数据和交互数据,训练用于机器人控制的动作条件视频生成模型,但这些方法在基于模型控制的机器人实际执行方面仅展示了较为有限的结果(Hu et al., 2023; Yang et al., 2024b; Bruce et al., 2024; Agarwal et al., 2025)。具体而言,这类研究通常更强调对预测真实性和视觉质量的评估,而不是对规划能力的评估,这可能是因为通过生成视频进行规划的计算成本较高。
在本文中,我们基于自监督学习假设,尝试学习一种世界模型,使其能够主要通过观察来获取关于世界的背景知识。具体而言,我们采用联合嵌入预测架构(Joint-Embedding Predictive Architecture, JEPA)(LeCun,2022),该架构通过在学习到的表征空间中进行预测来实现学习。与那些完全依赖交互数据进行学习的方法不同,自监督学习使我们能够利用互联网规模的视频数据。这类视频展示的是一系列状态变化,但并不直接提供对应的动作信息。通过这些数据,模型既可以学习如何表征视频观测,又可以在学习到的表征空间中学习世界动态的预测模型。此外,与基于视频生成的方法不同,JEPA 方法更关注学习场景中可预测部分的表征,例如运动物体的轨迹;同时忽略那些生成式目标通常会强调的不可预测细节,因为生成式方法需要进行像素级预测,例如精确预测田野中每一片草叶的位置,或树上每一片叶子的位置。通过扩大 JEPA 的预训练规模,我们证明该方法能够获得具有当前最先进理解与预测能力的视频表征,并且这些表征可以作为动作条件预测模型的基础,从而实现零样本规划。
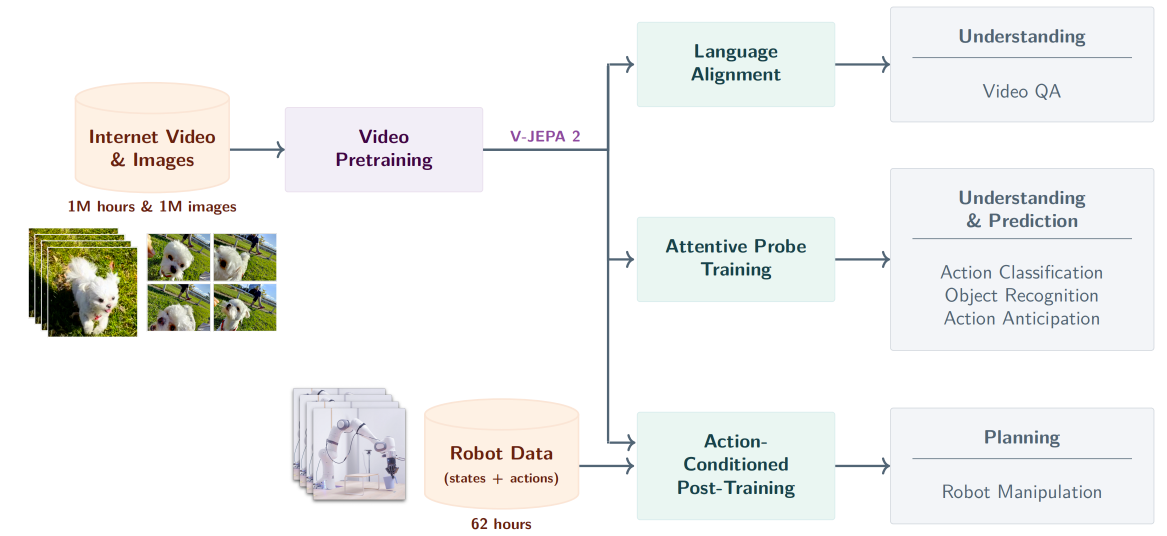
图1:图1 V- JEPA 2概述。我们利用100万小时的互联网规模视频数据和100万张图像,采用视觉掩码去噪目标函数(Bardes 等人,2024; Assran 等人,2023)对V- JEPA 2视频模型进行预训练,并通过将该模型与大语言模型(LLM)主干网络对齐,将其应用于动作分类、物体识别、动作预测及视频问答等下游任务。预训练完成后,可冻结视频编码器,在已学习的表征基础上利用少量机器人交互数据训练新的动作条件预测器;随后通过模型预测控制循环中的规划机制,利用该动作条件模型V- JEPA 2-AC完成下游机器人操控任务。
我们的方法 V-JEPA 2 采用阶段式训练流程:首先在互联网规模的视频数据上进行不含动作信息的预训练,随后使用少量交互数据进行后训练(见图 1)。在第一阶段,我们采用一种基于掩码去噪的特征预测目标(Assran et al., 2023; Bardes et al., 2024)。具体而言,模型需要在学习到的表征空间中预测视频中被遮蔽的片段。我们训练了参数规模最高达 10 亿、并使用超过 100 万小时视频数据的 V-JEPA 2 编码器。实验结果表明,扩大自监督视频预训练的规模能够增强编码器的视觉理解能力,包括更广泛的运动识别和外观识别能力。这一点通过基于探针的评估,以及将编码器与语言模型对齐后用于视频问答任务的实验得到了验证(Krojer et al., 2024; Pătrăucean et al., 2023; Liu et al., 2024c; Cai et al., 2024; Shangguan et al., 2024)。
在互联网规模视频上完成预训练之后,我们利用第一阶段学习到的表征,在一小部分交互数据上训练一个动作条件世界模型 V-JEPA 2-AC。我们的动作条件世界模型是一个拥有 3 亿参数的 Transformer 网络,采用块因果注意力机制,能够在给定动作和先前状态的条件下,以自回归方式预测下一帧视频的表征。仅使用 Droid 数据集(Khazatsky et al., 2024)中少至 62 小时的无标注交互数据,我们证明了训练潜在世界模型的可行性:在给定子目标的情况下,该模型可以用于 Franka 机械臂的动作规划,并且能够在新的环境中,仅依靠单目 RGB 相机,以零样本方式完成抓取类操作任务。
总而言之,我们表明,从视频中学习的联合嵌入预测架构可以用于构建世界模型,使模型具备理解物理世界、预测未来状态以及在新情境中有效规划的能力;这一目标是通过利用互联网规模视频和少量交互数据实现的。具体而言:
- 理解能力——基于探针的分类: 扩大自监督视频预训练规模,可以得到适用于多种任务的视频表征。V-JEPA 2 擅长编码细粒度运动信息,在需要运动理解的任务上表现突出。例如,在 Something-Something v2 数据集上,使用 attentive probe 可达到 77.3% 的 top-1 准确率。
- 理解能力——视频问答: V-JEPA 2 编码器可以用于训练多模态大语言模型,从而处理视频问答任务。我们观察到,在 80 亿参数级别的语言模型中,V-JEPA 2 在多个需要物理世界理解和时间推理能力的基准测试上达到当前最先进性能,例如 MVP 的 paired accuracy 为 44.5,PerceptionTest 测试集准确率为 84.0,TempCompass 多选准确率为 76.9,TemporalBench 多二分类短问答准确率为 36.7,TOMATO 准确率为 40.3。特别地,我们表明,一个没有经过语言监督预训练的视频编码器,也可以与语言模型对齐并取得当前最先进性能,这与传统观点相反(Yuan et al., 2025; Wang et al., 2024b)。
- 预测能力: 大规模自监督视频预训练能够增强模型的预测能力。V-JEPA 2 在 Epic-Kitchens-100 人类动作预判任务上,使用 attentive probe 取得了当前最先进性能,recall-at-5 达到 39.7,相比此前最佳模型相对提升了 44%。
- 规划能力: 我们证明,仅使用流行的 Droid 数据集中 62 小时无标注机器人操作数据对 V-JEPA 2 进行后训练得到的 V-JEPA 2-AC,可以部署到新的环境中,并通过给定子目标进行规划,从而完成抓取类操作任务。在没有使用我们实验室机器人采集的任何额外数据、没有进行任何任务特定训练、也没有设计奖励函数的情况下,该模型能够成功处理抓取和拾取—放置等操作任务,并且可以应对新物体和新环境。
本文其余部分结构安排如下:第2节阐述V- JEPA 2的预训练流程,重点介绍使其能够超越 Bardes 等人(2024)原始V- JEPA 方案的扩展关键要素;第3节介绍我们基于预训练V- JEPA 2模型训练任务无关的动作条件世界模型V- JEPA 2-AC的方法;第4节展示了如何通过基于模型的规划利用V- JEPA 2-AC实现机器人控制。由于V- JEPA 2-AC在学习到的表征空间中建模世界动态,其性能本质上取决于V- JEPA 2表征空间所捕获的信息,因此我们在第5节进一步探讨V- JEPA 2在视频理解任务中的表现,并在第6节分析其在预测任务中的表现;最后,第7节证明V- JEPA 2可与语言模型协同用于视频问答任务;第8节综述相关研究;第9节为全文总结。
2 V-JEPA 2: Scaling Self-Supervised Video Pretraining
我们在一个包含超过 100 万小时视频的视觉数据集上对 V-JEPA 2 进行预训练。该自监督训练任务基于表征空间中的掩码去噪,并建立在 V-JEPA 框架(Bardes et al., 2024)之上。在本文中,我们通过探索更大规模的模型、增加预训练数据规模,并引入一种空间和时间上的渐进式分辨率训练策略,对 V-JEPA 框架进行了扩展。该策略使我们能够高效地预训练模型,而不再局限于较短的 16 帧视频片段。
2.1 Methodology

Architecture.
关键扩展因素。 在本节中,我们介绍并研究四个额外的关键因素,这些因素使得我们能够将 V-JEPA 的预训练原则扩展到更大规模,从而得到 V-JEPA 2 模型。
-
数据扩展: 我们通过利用并筛选额外的数据来源,将数据集规模从 200 万个视频增加到 2200 万个视频。
-
模型扩展: 我们将编码器架构从 3 亿参数扩展到超过 10 亿参数,即从 ViT-L 扩展到 ViT-g(Zhai et al., 2022)。
-
更长时间的训练: 我们采用 warmup-constant-decay 学习率调度策略,这简化了超参数调节,并使训练迭代次数能够从 9 万次延长到 25.2 万次,从而更有效地利用新增的数据。
-
更高分辨率: 我们利用 warmup-constant-decay 学习率调度策略,高效地扩展到更高分辨率的视频和更长的视频片段。具体做法是在 warmup 和 constant 阶段使用较短、较低分辨率的视频片段进行训练,然后在最后的 decay 阶段提高分辨率和/或视频片段长度。
本节剩余部分将进一步详细描述这些因素,并使用下一部分介绍的评估协议,量化每个因素所带来的影响。
评估协议。 我们进行模型预训练的目标,是将通用视觉理解能力注入到编码器中。因此,我们通过评估模型在一组六个运动与外观分类任务上学习到的表征质量,来验证模型和数据设计选择的效果。这六个任务包括:Something-Something v2(Goyal et al., 2017)、Diving-48(Li et al., 2018)、Jester(Materzynska et al., 2019)、Kinetics(Kay et al., 2017)、COIN(Tang et al., 2019)和 ImageNet(Deng et al., 2009)。
我们采用冻结评估协议:冻结编码器的权重,并在其输出表征之上训练一个针对具体任务的 4 层 attentive probe,用于输出预测类别。在本节中,我们主要关注模型在这六个理解任务上的平均准确率。关于这些任务、评估协议和实验结果的更多细节,请参见第 5 节。
2.2 Scaling Self-Supervised Video Learning
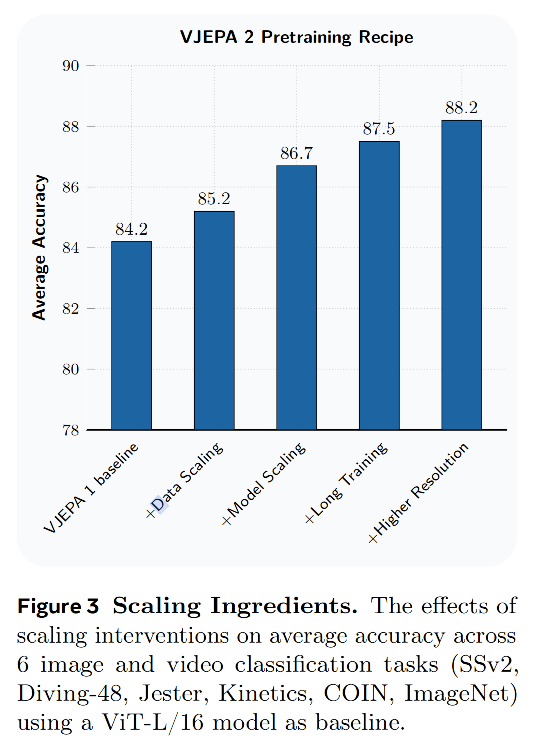
我们首先总结扩展分析中的关键发现,重点研究四个关键因素对下游任务平均性能的影响。图 3 展示了这些扩展策略对 6 个分类任务平均准确率的影响,其中以一个在 200 万个视频上、使用 V-JEPA 目标进行预训练的 ViT-L/16 模型作为基线。将数据集规模从 200 万个视频增加到 2200 万个视频(VM22M),带来了 1.0 个百分点的性能提升。将模型规模从 3 亿参数扩展到 10 亿参数(ViT-g/16),又额外带来了 1.5 个百分点的提升。将训练迭代次数从 9 万次延长到 25.2 万次,则进一步贡献了 0.8 个百分点的提升。最后,在预训练和评估阶段同时提高空间分辨率和时间长度,即将空间分辨率从 256 提高到 384,并将视频帧数从 16 帧增加到 64 帧,使模型性能提升到 88.2%。相较于 ViT-L/16 基线模型,这一系列改进累计带来了 4.0 个百分点的提升。每一项单独的改动都带来了正向影响,这证实了在视频自监督学习(SSL)中进行规模扩展的潜力。
2.3 Pretraining Dataset
接下来,我们将阐述构成我们预训练数据集的视频和图像来源,以及我们整理该数据集的方法。
扩展数据集规模。 我们通过整合公开可用的数据源,构建了一个大规模视频数据集。在本文中使用公开数据源,可以使其他研究者复现这些结果。整体数据集包括:来自 Something-Something v2 数据集(SSv2)(Goyal et al., 2017)的第一视角视频;来自 Kinetics 400、600 和 700 数据集(Kay et al., 2017; Carreira et al., 2018, 2019)的第三视角动作视频;来自 HowTo100M(Miech et al., 2019)的 YouTube 教程视频;以及来自 YT-Temporal-1B(Zellers et al., 2022)的一般 YouTube 视频,本文将其简称为 YT1B。我们还加入了 ImageNet 数据集(Deng et al., 2009)中的图像,以增加预训练数据的视觉覆盖范围。
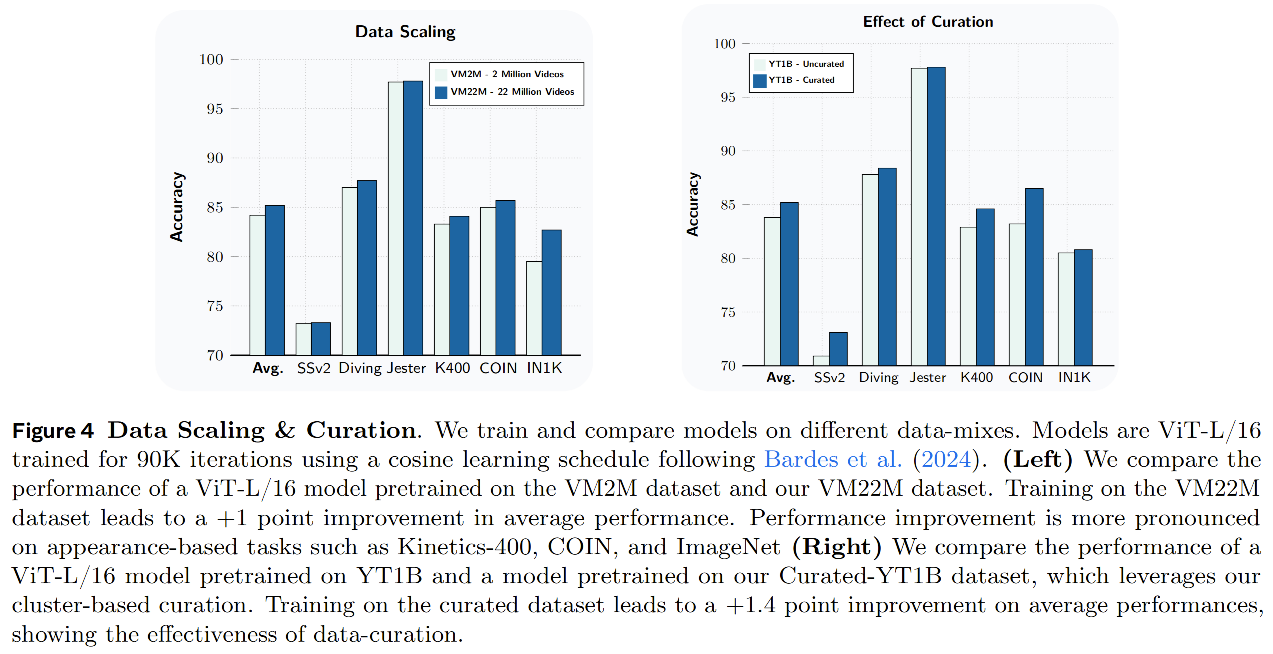
为了实现图像和视频的联合预训练,我们在时间维度上复制一张图像,并将其视为一个 16 帧视频,其中所有帧都是相同的。在训练过程中,我们根据经验通过手动调节,为每个数据源设置采样权重系数。最终得到的数据集被称为 VideoMix22M,简称 VM22M,包含 2200 万个样本。表 1 列出了这些数据源及其对应的权重。图 4 左侧比较了在 VM22M 上预训练的 ViT-L/16 与 Bardes et al.(2024)中在较小规模 VideoMix2M 数据集,即 200 万样本数据集上训练的类似模型的性能。与 VM2M 相比,在 VM22M 上训练使模型在视觉理解任务上的平均性能提升了 1 个百分点。性能提升在基于外观的任务上更加明显,例如 Kinetics-400、COIN 和 ImageNet,这说明扩大视觉覆盖范围对于这类任务非常重要。
数据筛选。 YT1B 是一个大规模视频数据集,包含 140 万小时的视频。与 Kinetics 和 Something-Something v2 等较小规模的视频数据集相比,YT1B 没有经过精细筛选,过滤程度也较低。由于未经筛选且分布不均衡的数据可能会影响模型性能(Assran et al., 2022; Oquab et al., 2023),因此我们通过改造一种已有的基于检索的数据筛选流程,使其能够处理视频数据,从而对 YT1B 进行过滤。具体而言,我们首先从 YT1B 视频中提取场景,为每个场景计算一个嵌入向量,然后使用基于聚类的检索过程(Oquab et al., 2023),按照一个目标分布来选择视频场景。这个目标分布由 Kinetics、Something-Something v2、COIN 和 EpicKitchen 的训练数据集组成。关于数据集构建流程的详细信息,我们在附录 A.2 中进行说明。与 Oquab et al.(2023)类似,我们确保目标验证集中的视频不会出现在最初未经筛选的数据池中。在图 4 右侧,我们比较了两个 ViT-L 模型在视觉理解评估中的平均性能:一个是在未经筛选的 YT-1B 数据上预训练的模型,另一个是在我们构建的 Curated-YT-1B 数据集上训练的可比模型。使用经过筛选的数据集进行训练,相比未经筛选的基线模型,平均性能提升了 1.4 个百分点。值得注意的是,在 ViT-L 规模下,基于 Curated-YT-1B 训练的模型相对于完整 VM22M 数据集也能取得具有竞争力的性能。然而,更大规模的模型从 VM22M 训练中获益更多(见附录 A.2),这表明将 Curated-YT-1B 与其他数据源结合,可以进一步增强模型的可扩展性。
2.4 Pretraining Recipe
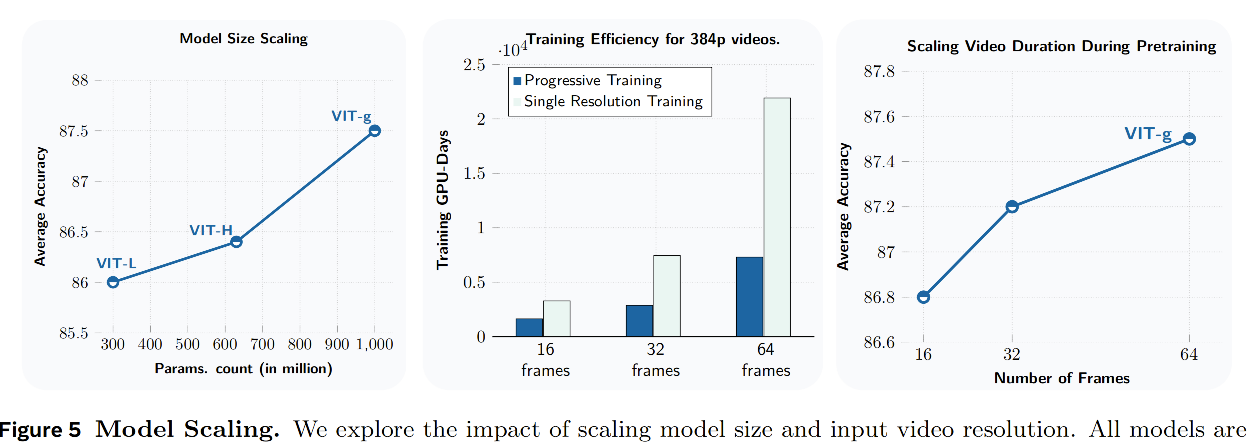
扩展模型规模。 为了探索模型的规模扩展行为,我们训练了一系列编码器模型,其参数量从 3 亿参数的 ViT-L 到 10 亿参数的 ViT-g 不等。所有编码器架构的详细信息见附录中的表 12。需要注意的是,每个编码器都使用相同的预测器架构,该预测器类似于 ViT-small。我们在图 5 左侧报告了这些编码器在视觉理解任务上的平均性能。将模型规模从 3 亿参数的 ViT-L 扩展到 10 亿参数的 ViT-g,可以带来 1.5 个百分点的平均性能提升。运动理解任务和外观理解任务都能从模型扩展中受益,其中 SSv2 提升了 1.6 个百分点,Kinetics 提升了 1.5 个百分点(见表 4)。这些结果表明,自监督视频预训练能够有效利用更大的模型容量,至少可以扩展到 10 亿参数规模的 ViT-g。
训练调度。 V-JEPA 2 的模型训练采用 warmup-constant 学习率调度策略,随后接一个 cooldown 阶段(Zhai et al., 2022; Hägele et al., 2024)。与 Hägele et al.(2024)类似,我们发现这种调度策略的表现与 half-cosine 调度(Loshchilov and Hutter, 2016)相当;同时,它也使长时间训练实验更具成本效率,因为可以从 constant 阶段的不同检查点出发,启动多个 cooldown 训练过程。我们还简化了 Bardes et al.(2024)中的训练方案:保持固定的教师模型 EMA 系数和权重衰减系数,而不是采用逐步增大的调度策略,因为这些变化对下游理解任务的影响很小。图 3 显示,将 ViT-g 模型的训练周期从 9 万次迭代延长到 25.2 万次迭代,可以带来 0.8 个百分点的平均性能提升,验证了延长训练时间的益处。该训练调度也有助于实现渐进式训练,即在 cooldown 阶段逐步提高视频分辨率。
高效的渐进式分辨率训练。 虽然以往大多数视频编码器主要关注 16 帧的短视频片段,即大约几秒钟的视频(Bardes et al., 2024; Wang et al., 2024b, 2023),但我们进一步探索了使用最长 64 帧、也就是 16 秒视频片段,并结合更高空间分辨率进行训练。然而,随着视频时长和空间分辨率的提高,训练时间会急剧增加。例如,如果直接使用 (64 \times 384 \times 384) 的输入训练 ViT-g 模型,大约需要 60 个 GPU 年的计算量(见图 5 中间)。为了降低这一成本,我们采用了一种渐进式分辨率策略(Touvron et al., 2019; Oquab et al., 2023),该策略能够在保持下游任务性能的同时提高训练效率。
我们的训练过程首先从 warmup 阶段开始,在 16 帧、(256 \times 256) 分辨率的视频上训练,并在 1.2 万次迭代内进行线性学习率预热;随后进入主训练阶段,在恒定学习率下训练 22.8 万次迭代。之后,在 cooldown 阶段,我们提高视频时长和分辨率,同时在 1.2 万次迭代内线性衰减学习率。因此,由更长视频时长和更高分辨率带来的额外计算开销,只会出现在最后的 cooldown 阶段。
这种方法实现了高效的高分辨率训练。如图 5 中间所示,对于一个能够处理 64 帧、(384 \times 384) 分辨率输入的模型,相比于从头开始在所有训练阶段都使用完整高分辨率进行训练,我们的方法可以将 GPU 时间减少 8.4 倍。此外,正如下文所讨论的,我们仍然观察到了模型处理更长时间跨度和更高分辨率输入所带来的收益。
扩展视频的时间和空间分辨率。 图 5 研究了输入视频分辨率如何影响下游任务性能。当在预训练阶段将视频片段长度从 16 帧增加到 64 帧,同时在评估阶段仍保持固定的 16 帧输入时,我们观察到平均性能提升了 0.7 个百分点(图 5 右侧)。此外,我们还发现,在评估阶段提高视频时长和分辨率,会在多个任务上带来显著提升(见表 4 和附录 A.4.2)。这些结果表明,视频自监督预训练在训练和评估阶段都能从更高的时间分辨率中受益。尽管我们也尝试将视频片段扩展到更长的 128 帧和 256 帧,但在这一组理解任务上,超过 64 帧后并没有观察到进一步提升。
3 V-JEPA 2-AC: Learning an Action-Conditioned World Model
在预训练之后,V-JEPA 2 模型可以对视频中缺失的部分进行预测。然而,这些预测并没有直接考虑智能体可能执行的动作所产生的因果影响。在本节所描述的下一阶段训练中,我们重点关注如何利用少量交互数据,使模型能够用于规划。为此,我们在冻结的 V-JEPA 2 视频编码器之上,学习一个帧因果的动作条件预测器(见图 2 右)。我们使用 Droid 数据集(Khazatsky et al., 2024)中的数据训练模型,该数据集包含通过遥操作方式采集的桌面 Franka Panda 机械臂实验数据。我们将最终得到的动作条件模型称为 V-JEPA 2-AC,并在第 4 节中展示,V-JEPA 2-AC 可以被用于模型预测控制的规划循环中,从而在新环境中规划动作。
3.1 Action-Conditioned World Model Training
我们的目标是利用预训练后的 V-JEPA 2 模型,得到一个可用于具身智能体系统控制的潜在世界模型,并通过闭环的模型预测控制方式实现控制。为此,我们训练了 V-JEPA 2-AC。它是一个自回归模型,能够在给定控制动作和本体感知观测的条件下,预测未来视频观测的表征。
在本节中,我们描述了该框架在一个具体场景中的实现:对象是一个桌面机械臂系统,配备固定的外部视角相机,其中控制动作对应机械臂末端执行器的控制指令。该模型使用原始 Droid 数据集中约 62 小时的无标注视频进行训练。该数据集由短视频组成,通常每段时长为 3–4 秒,记录的是一台 7 自由度 Franka Emika Panda 机械臂的操作过程,该机械臂配备双指夹爪。这里的“无标注视频”指的是:我们没有使用额外的元数据来指示奖励信息、每段演示中执行的任务类型,或者该演示是否成功完成了尝试执行的任务。相反,我们只使用数据集中的原始视频和末端执行器状态信号。数据集中的每段视频都附带元数据,用于表示每一帧中的末端执行器状态,包括三维位置信息、三维姿态信息,以及一维夹爪状态。
模型输入。 在训练的每一次迭代中,我们都会从 Droid 数据集中随机采样一个小批量的 4 秒视频片段。为了简化处理,我们会丢弃所有短于 4 秒的视频,因此最终使用的是一个较小的数据子集,总时长少于 62 小时。采样得到的视频片段分辨率为 256×256,帧率为每秒 4 帧(4 fps),因此每个视频片段包含 16 帧,记为:



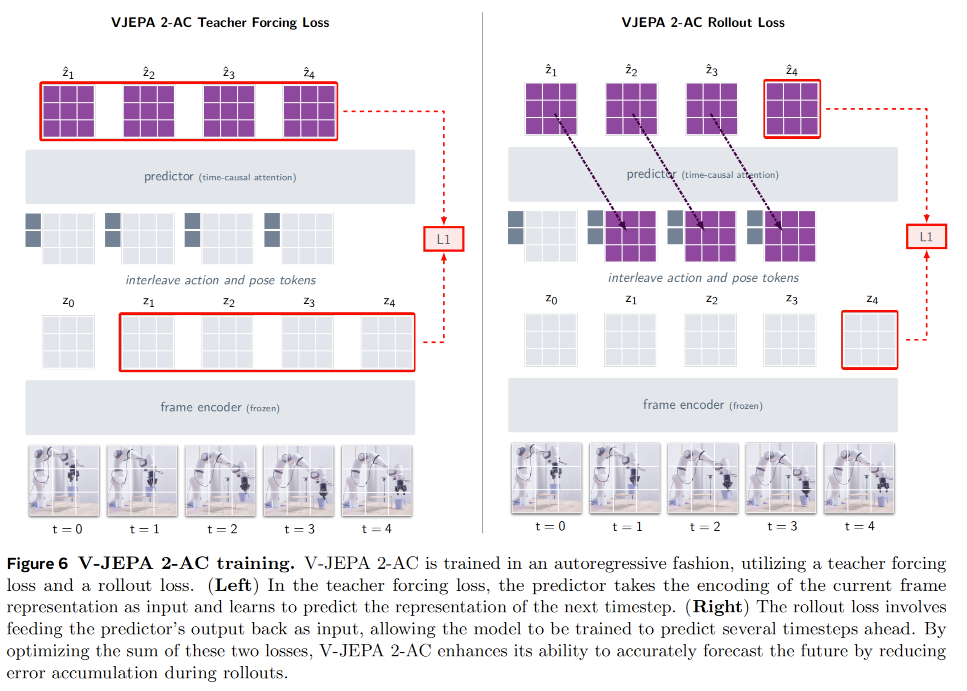
架构。 预测器网络是一个约 3 亿参数的 Transformer 网络,包含 24 层、16 个注意力头、1024 维隐藏层,并使用 GELU 激活函数。输入到预测器中的动作、末端执行器状态以及展平后的特征图,会分别经过独立的可学习仿射变换,从而映射到预测器的隐藏维度。同样地,预测器最后一个注意力模块的输出也会经过一个可学习的仿射变换,将其映射回编码器的嵌入维度。我们使用 3D-RoPE 来表示展平特征图中每个视频 patch 的时空位置;而对于动作 token 和位姿 token,则只应用时间维度的旋转位置编码。在预测器中,我们使用块因果注意力模式。这样,在某一时间步上的每个 patch 特征,都可以关注同一时间步的动作、末端执行器状态以及其他 patch 特征,同时也可以关注之前时间步中的这些信息。
3.2 Inferring Actions by Planning

4 Planning: Zero-shot Robot Control
本节展示了如何利用V- JEPA 2-AC通过模型预测控制实现机器人基本操作技能,如伸展、抓取和拾放。我们重点研究具有视觉目标设定的任务,并证明V- JEPA 2-AC能够实现零样本迁移至新环境。
4.1 Experimental Setup
我们将 V-JEPA 2-AC 的性能与两个基线方法进行比较:一个是通过行为克隆训练的视觉-语言-动作模型,另一个是基于视频生成的世界模型。
第一个基线基于 Octo 视觉-语言-动作模型,该模型支持以目标图像作为条件(Octo Model Team et al., 2024)。我们从 octo-base-1.5 版本模型的开源权重开始,该模型已经在 Open-X Embodiment 数据集上进行了预训练,该数据集包含超过 100 万条轨迹。随后,我们在完整的 Droid 数据集上,使用行为克隆对 Octo 模型进行微调,并结合 hindsight relabeling(Andrychowicz et al., 2017; Ghosh et al., 2019),使用图像目标和末端执行器状态作为条件。具体来说,在训练过程中,我们从 Droid 数据集中随机采样轨迹片段,并在轨迹中向前最多 20 个时间步的范围内,均匀采样目标图像。我们使用官方开源代码进行微调,包括所有标准的 Droid 优化超参数,并使用分辨率为 (256 \times 256) 的单侧视角图像作为输入,输入上下文包含前两帧,预测未来 4 个动作的时间范围。
第二个用于比较的基线基于 Cosmos 视频生成模型(Agarwal et al., 2025)。我们从动作无关的 Cosmos 模型开源权重开始,该模型是一个 latent diffusion-7B 模型,使用连续 tokenizer,并在 2000 万小时的视频上训练得到。随后,我们使用官方发布的动作条件微调代码,在 Droid 数据集上对该模型进行微调。为了提升其在 Droid 数据集上的训练效果,我们进行了三项调整:第一,将学习率降低到与视频条件 Cosmos 训练方案中使用的学习率一致;第二,去除视频条件中的 dropout,以改善训练动态;第三,将噪声水平提高 (e^2) 倍,因为我们观察到,在较低噪声因子下训练的模型难以有效利用条件帧中的信息。尽管 Cosmos 技术报告(Agarwal et al., 2025)提到将世界模型用于规划或模型预测控制是未来应用方向,但据我们所知,这是首次报告尝试将 Cosmos 模型用于机器人控制。
机器人部署。 所有模型都以零样本方式部署在 Franka Emika Panda 机械臂上,机械臂配备 RobotiQ 夹爪,并分别位于两个不同的实验室中。这两个实验室的环境都没有出现在 Droid 数据集中。视觉输入由一个未经标定的低分辨率单目 RGB 相机提供。这些机器人使用完全相同的模型权重和推理代码,并采用类似的底层控制器,该控制器基于操作空间控制。对于 V-JEPA 2-AC 世界模型和 Cosmos 世界模型,我们使用阻塞式控制,也就是说,系统会等待上一个发送的动作指令执行完成后,才向控制器发送新的动作指令。对于 Octo,我们同时尝试了阻塞式控制和非阻塞式控制,并报告两种方式中的最佳性能。在使用 V-JEPA 2-AC 和 Cosmos 进行规划时,我们将每个采样动作限制在以原点为中心、半径为 0.075 的 (L_1) 球内。这大约对应于每个单独动作的末端执行器最大位移约 13 cm。这样做的原因是,较大的动作对于这些模型来说相对属于分布外动作。
4.2 Results
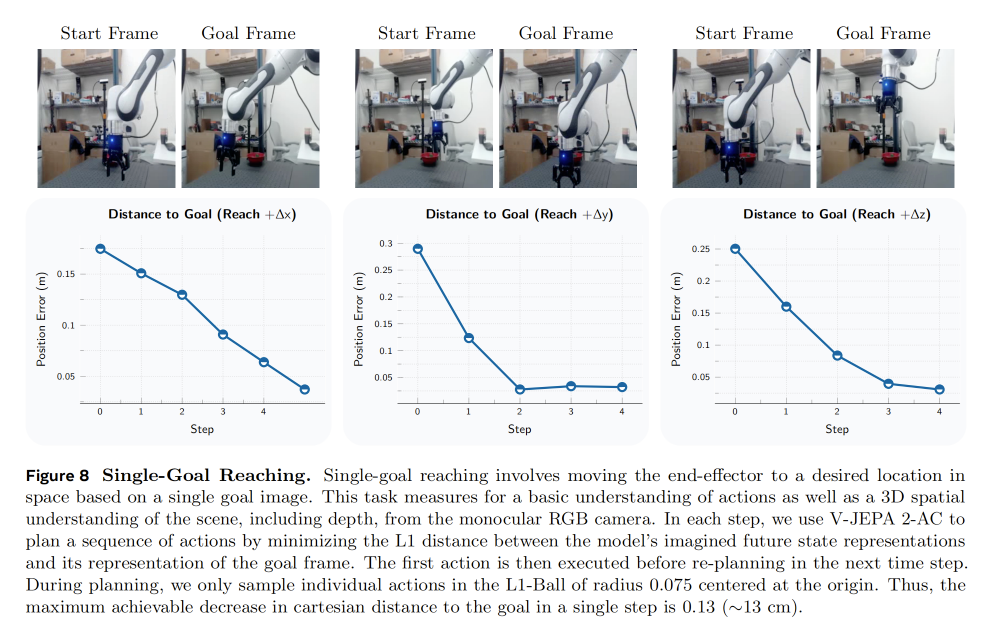
单目标到达。 首先,我们在单目标到达任务上进行评估。该任务要求机器人根据一张目标图像,将末端执行器移动到空间中的期望位置。该任务用于衡量模型对动作的基本理解能力,以及模型能否仅通过单目 RGB 相机获得场景的三维空间理解能力,包括深度信息。
图 8 展示了在三个不同的单目标到达任务中,机器人执行过程中末端执行器与目标位置之间的欧氏距离。在所有情况下,模型都能够将末端执行器移动到距离目标位置小于 4 cm 的范围内,并且能够选择使误差单调下降的动作。这个过程可以被看作一种视觉伺服(Hill, 1979),即利用相机的视觉反馈来控制机器人的运动。然而,与传统视觉伺服方法不同,V-JEPA 2-AC 是通过在无标注的真实世界视频数据上训练来实现这一能力的。
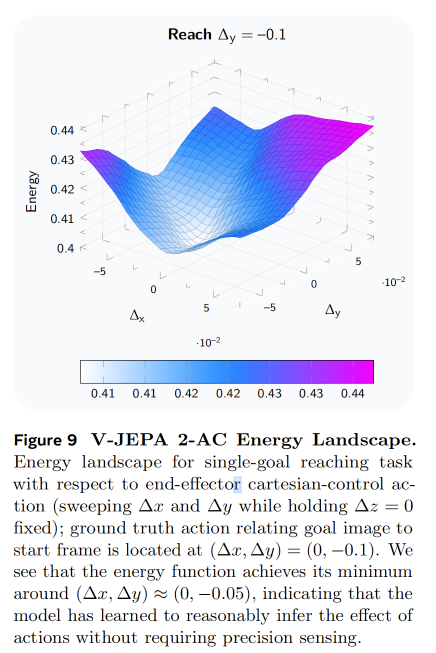
在图 9 中,我们对式(5)中的 V-JEPA 2-AC 能量景观进行了可视化,具体是在 (\Delta y) 到达任务中,将能量函数表示为单个笛卡尔控制动作的函数。实验中扫描 (\Delta x) 和 (\Delta y),同时固定 (\Delta z = 0)。结果显示,该能量函数在接近真实动作的位置取得最小值,这进一步表明模型已经学会了较合理地推断动作的影响,而不需要依赖精密传感。另一个有趣的现象是,由 V-JEPA 2-AC 产生的能量景观相对平滑,并且在局部呈凸形,这有助于后续规划。
抓取式操作。 接下来,我们在更具挑战性的抓取式物体操作任务上评估所有模型,包括抓取、携物到达以及拾取—放置任务。成功率见表 2 和表 3,并在 10 次实验中取平均;这些实验在不同任务变化下进行,例如物体位置、初始姿态等。
对于抓取任务和携物到达任务,模型只会看到一张目标图像。对于拾取—放置任务,除了最终目标外,我们还向模型提供两张子目标图像。第一张目标图像展示物体已被抓住的状态,第二张目标图像展示物体已经接近目标位置的状态。模型首先针对第一个子目标优化动作,持续 4 个时间步;随后自动切换到第二个子目标,持续接下来的 10 个时间步;最后切换到第三个目标,持续最后 4 个时间步。图 10 展示了拾取—放置任务中的机器人执行示例。实验室 1 中所有单独任务的起始帧和目标帧见附录 B.2。
抓取任务要求模型能够基于视觉反馈进行精确控制,从而正确夹取物体。携物到达任务要求模型在抓住物体的同时进行移动,这需要模型具备基本的直觉物理理解,以避免物体掉落。最后,拾取—放置任务则用于测试模型是否能够组合这些基础技能。
虽然所有模型在到达任务上都取得了较高成功率,但在涉及物体交互的任务中,不同模型之间的性能差异更加明显。我们观察到,所有模型的成功率都与被操作物体的类型有关。例如,对于杯子,最容易的抓取方式通常是将一个夹爪手指伸入杯内,并围绕杯沿进行夹持;然而,如果模型生成的控制动作不够准确,机器人就会错过杯沿,导致抓取失败。对于盒子来说,可行的抓取姿态更多,但模型需要更精确地控制夹爪,确保夹爪张开得足够宽,才能成功抓住物体。
总体来看,对于所有模型而言,不同物体类型造成的成功率差异,来自两个方面的共同影响:一是模型生成的动作并非最优,二是每种物体自身具有不同的操作难点。尽管如此,V-JEPA 2-AC 在所有任务中都取得了最高成功率,这突出了基于潜在空间规划进行机器人操作的可行性。
在表 3 中,我们比较了使用 V-JEPA 2-AC 和使用基于潜在扩散的 Cosmos 动作条件视频生成模型时的规划性能。在两种情况下,我们都使用交叉熵方法(Cross-Entropy Method, CEM)(Rubinstein, 1997)在单块 NVIDIA RTX 4090 GPU 上优化动作序列,并且与公式(5)类似,通过将目标帧编码到模型的潜在空间中来构造能量函数。
对于 Cosmos,当使用 80 个采样、10 次优化迭代以及规划时域为 1 时,每个规划步骤计算一个动作需要 4 分钟。虽然使用 Cosmos 在到达任务上可以取得 80% 的较高成功率,但在涉及物体交互的任务上表现较弱。需要注意的是,如果每个动作的规划时间为 4 分钟,那么完成一整条 pick-and-place 轨迹需要超过 1 小时的机器人执行时间。
相比之下,V-JEPA 2-AC 世界模型即使在每次优化迭代中使用多 10 倍的采样数量,也只需要 16 秒就能规划出一个动作,并且在所有考虑的机器人技能任务上都取得了更高的性能。
未来工作中,可以通过多种方式进一步减少两个模型的规划时间,例如:为规划过程使用更多计算资源、减少每个时间步中的采样数量和优化迭代次数、在世界模型的想象空间中训练一个前馈策略来初始化规划问题,或者对于 V-JEPA 2-AC,进一步利用基于梯度的规划方法。
4.3 Limitations
对相机位置的敏感性。 由于 V-JEPA 2-AC 模型是在没有任何显式相机标定的情况下,学习根据末端执行器的笛卡尔控制动作来预测下一帧视频表征的,因此它必须从单目 RGB 相机输入中隐式推断动作坐标轴。然而,在许多情况下,机器人基座并不会出现在相机画面中,因此模型很难明确推断动作坐标轴,这个问题本身就变得不够明确,从而可能导致世界模型产生预测误差。在实际实验中,我们手动尝试了不同的相机摆放位置,最终选择了一个在所有实验中都表现较好的相机位置。我们在附录 B.4 中对 V-JEPA 2-AC 世界模型对相机位置的敏感性进行了定量分析。
长时域规划。 使用世界模型进行长时域规划会受到多方面因素的限制。首先,自回归预测会受到误差累积的影响:随着自回归 rollout 步数的增加,表征空间中的预测准确性会下降,从而使得在较长时间范围内进行可靠规划变得更加困难。其次,长时域规划会增大搜索空间:当规划时域线性增加时,可能的动作轨迹数量会呈指数级增长,因此在长时域上进行规划会带来较大的计算挑战。另一方面,长时域规划对于解决非贪心式预测任务是必要的,例如在没有图像子目标的情况下完成 pick-and-place 任务。未来关于世界模型长时域规划的研究,将有助于解决更多复杂且有趣的任务。
图像目标。 与许多以目标为条件的机器人操作研究类似(Finn and Levine, 2017; Lynch et al., 2020; Chebotar et al., 2021; Jang et al., 2022; Liu et al., 2022; Gupta et al., 2022),我们当前的优化目标设定假设模型可以获得视觉目标,也就是目标图像。然而,在真实开放环境中部署机器人时,用其他形式表达目标可能更加自然,例如使用语言描述目标。未来,如果能够将潜在的动作条件世界模型与语言模型进行对齐,将有助于朝着通过自然语言进行更通用任务指定的方向迈进。
5 Understanding: Probe-based Classification
像上文讨论的 V-JEPA 2-AC 这类表征空间世界模型,其能力本质上受限于学习到的表征空间中所编码的状态信息。在本节及后续章节中,我们对 V-JEPA 2 学习到的表征进行探测,并将 V-JEPA 2 编码器与其他视觉编码器在视觉分类任务上的表现进行比较。
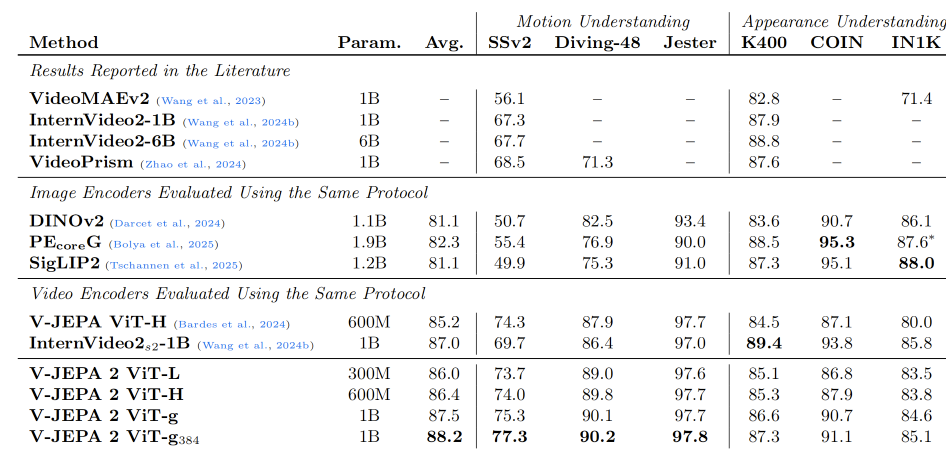
视觉分类任务可以侧重于外观理解,也可以侧重于运动理解。外观理解任务通常可以依靠输入视频片段中单帧可见的信息来解决,即使分类标签描述的是动作;而运动理解任务则需要结合多帧信息,才能正确判断视频类别(Goyal et al., 2017)。为了平衡评估模型的运动理解能力和外观理解能力,我们选择了三个运动理解任务,即 Something-Something v2(SSv2)、Diving-48 和 Jester,这些任务要求模型理解人的手势和动作变化。对于外观理解任务,我们选择了 Kinetics400(K400)、COIN 和 ImageNet(IN1K),这些任务涉及动作、场景和物体识别。实验结果表明,V-JEPA 2 在运动理解任务上优于当前最先进的视觉编码器,同时在外观理解任务上也具有竞争力。
Attentive Probe。 我们在冻结的编码器输出之上,使用各个任务的训练数据训练了一个 4 层 attentive probe。该 attentive probe 由四个 Transformer 块组成,其中最后一个块将标准的自注意力替换为交叉注意力层,并使用一个可学习的 query token。按照标准做法,在推理阶段,我们会从一个视频中采样多个包含固定帧数的视频片段。随后,将这些片段的分类 logits 进行平均,得到最终分类结果。我们保持评估分辨率与 V-JEPA 2 预训练时使用的分辨率相近。关于 attentive probe 层数的消融实验见附录 C.2,同时我们也提供了下游任务中使用的视频片段数量、片段大小以及其他超参数的完整细节。
评估协议。 我们将 V-JEPA 2 在运动理解和外观理解任务上的表现,与其他几种视觉编码器进行比较。DINOv2 with registers(Darcet et al., 2024)是当前图像自监督学习领域的先进模型;SigLIP2(Tschannen et al., 2025)和 Perception Encoder PEcoreG(Bolya et al., 2025)是两个先进的图像—文本对比预训练模型。此外,我们还考虑了两个视频编码器:自监督方法 V-JEPA(Bardes et al., 2024),以及主要依赖视觉—文本对比预训练的 InternVideo2s2-1B(Wang et al., 2024b)。
对于所有基线模型和 V-JEPA 2,我们都采用相同的评估协议:在冻结编码器之上训练一个 attentive probe,这与 Bardes et al.(2024)的做法类似。对于基于图像的模型,我们按照 Oquab et al.(2023)中的方法将其适配到视频任务中,即将输入视频中每一帧的特征进行拼接。对于 InternVideo2s2-1B,在 ImageNet 任务中,我们使用其图像位置嵌入;在视频任务中,我们将其位置嵌入从 4 帧插值到 8 帧,使其 token 数量与 V-JEPA 2 接近。
尽管我们使用了统一的评估协议,但这些基线编码器是在不同数据上训练的,例如 DINOv2 使用 LVD-142M,PEcoreG 使用 MetaCLIP,因此它们并不能被完全直接比较。因此,我们只能在系统层面比较不同方法,即在评估协议一致的情况下,对比不同训练协议和训练数据所得到的模型表现。
此外,我们还纳入了文献中使用类似冻结评估协议得到的已有结果,不过这些方法可能使用了不同的 attentive head 架构。具体来说,在相关分类任务结果可用的情况下,我们引用了 VideoMAEv2(Wang et al., 2023)、InternVideo-1B 和 InternVideo-6B(Wang et al., 2024b),以及 VideoPrism(Zhang et al., 2024c)的已报告结果。完整的评估细节和超参数设置见附录 C.1。
结果。 表 4 报告了 V-JEPA 2、我们评估的其他编码器,以及文献中其他重要方法在分类任务上的表现。V-JEPA 2 ViT-g 在 256 分辨率下,在运动理解任务上显著优于其他视觉编码器。例如,在 SSv2 上,V-JEPA 2 的 top-1 准确率达到 75.3,而 InternVideo 为 69.7,PEcoreG 为 55.4。V-JEPA 2 在外观理解任务上同样具有竞争力,例如在 ImageNet 上达到 84.6,相比 V-JEPA 提升了 4.6 个百分点。总体而言,与其他视频编码器和图像编码器相比,V-JEPA 2 在六个任务上的平均性能最好。更高分辨率、更长视频输入的 V-JEPA 2 ViT-g384 在所有任务上进一步提升,平均性能达到 88.2。
6 Prediction: Probe-based Action Anticipation
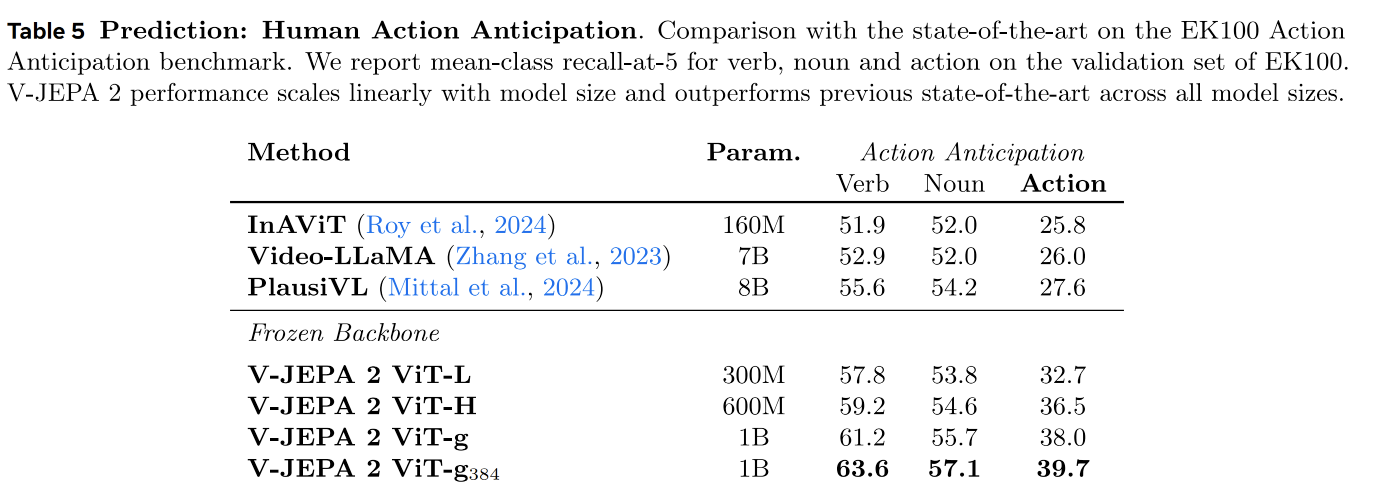
基线方法。 我们将模型与三个专门针对动作预判任务训练的基线方法进行比较:InAViT(Roy et al., 2024)是一种监督学习方法,显式建模手—物交互;Video-LLaMA(Zhang et al., 2023)和 PlausiVL(Mittal et al., 2024)则都是利用大语言模型的方法,参数规模最高可达 70 亿。
结果。 表 5 总结了在 EK100 动作预判基准上的结果。我们比较了 V-JEPA 2 的 ViT-L、ViT-H 和 ViT-g 编码器,参数量从 3 亿增加到 10 亿。这三个模型都使用 32 帧、每秒 8 帧、分辨率为 (256 \times 256) 的视频上下文。我们还报告了 ViT-g384 的结果,该模型使用 (384 \times 384) 分辨率。在动作预测的 recall-at-5 指标上,V-JEPA 2 表现出随模型规模增大而近似线性提升的趋势。拥有 3 亿参数的 V-JEPA 2 ViT-L 达到 32.7 的 recall-at-5;当模型规模增加到 10 亿参数时,性能提升了 5.3 个百分点,动作 recall-at-5 达到 38.0。此外,V-JEPA 2 还能从更高分辨率的视频上下文中受益。使用 (384 \times 384) 分辨率的 V-JEPA 2 ViT-g384,相比其他使用 (256 \times 256) 分辨率的模型,recall-at-5 进一步提升了 1.7 个百分点。
V-JEPA 2 明显优于此前的最先进模型 PlausiVL。即使 V-JEPA 2 只有 3 亿参数,也超过了使用 80 亿参数的 PlausiVL。尤其是 V-JEPA 2 ViT-g384 在动作 recall-at-5 上比 PlausiVL 高出 12.1 个百分点,对应 44% 的相对提升。
图 11 可视化了 V-JEPA 2 在 EK100 验证集上三个样本的预测结果,其中两个预测成功,一个预测失败。在两个成功样本中,V-JEPA 2 不仅以 top-1 置信度正确找到了真实动作,还根据给定上下文提出了合理的 top-2 到 top-5 候选动作。例如,在第一行中,正确动作是 “wash sink”(清洗水槽),但由于画面中存在水龙头和墙壁,“turn on water”(打开水)或 “clean wall”(清洁墙壁)也都是合理的候选动作。模型还预测了 “rinse sponge”(冲洗海绵),这是当前正在执行的动作,可能是因为模型认为该动作在 1 秒之后仍可能继续发生。对于失败样本,V-JEPA 2 仍然提出了一些合理动作,例如 “close door”(关门)和 “put down spices package”(放下香料包),但它没有准确识别物体的具体类别,即 “tea package”(茶包)。
局限性。 V-JEPA 2 和 EK100 基准仍存在若干局限。第一,V-JEPA 2 并没有完全解决 EK100 任务,仍然存在失败案例,例如模型可能预测错动词、名词,或者二者都预测错误。作者在附录 D.2 中分析了这些失败案例的分布。第二,本文主要关注 1 秒预判时间下的动作预测;当预测更长时间范围内的未来动作时,V-JEPA 2 的准确率会下降,相关结果见附录 D.2。第三,EK100 基准局限于厨房环境,并且使用一个封闭且定义明确的词汇表,因此尚不清楚 V-JEPA 2 能在多大程度上泛化到其他环境。这限制了在 EK100 上训练模型的实用性和适用范围。最后,EK100 中的动作来自固定类别集合,因此模型无法泛化到训练集中不存在的动作类别。

7 Understanding : Video Question Answering
在本节中,我们探究 V-JEPA 2 执行开放语言视频问答(Video Question Answering, VidQA)的能力。为了赋予模型语言能力,我们使用 V-JEPA 2 作为视觉编码器,训练了一个多模态大语言模型(Multimodal Large Language Model, MLLM)。该模型采用非 token 化的早期融合设置(Wadekar et al., 2024),这一设置由 LLaVA 系列模型(Li et al., 2024b)推广开来。在这类 MLLM 中,视觉编码器会与大语言模型进行对齐:具体做法是将视觉编码器输出的 patch embeddings 投影到大语言模型的输入嵌入空间中。随后,MLLM 可以采用端到端方式训练,也可以在冻结视觉编码器的情况下训练。目前,大多数用于 VidQA 的 MLLM 所采用的编码器通常是图像编码器。在处理视频输入时,这些图像编码器会逐帧独立地应用于每一帧图像(Qwen Team et al., 2025; Zhang et al., 2024b)。这类编码器的代表包括 CLIP(Radford et al., 2021)、SigLIP(Tschannen et al., 2025)和 Perception Encoder(Bolya et al., 2025)。它们之所以常被使用,主要是因为这些模型通过图像—文本配对数据进行预训练,因此天然具有较好的视觉语义与语言对齐能力。据我们所知,本文是首次使用一个没有经过任何语言监督预训练的视频编码器,来训练用于 VidQA 的多模态大语言模型。
MLLM 在下游任务上的性能也高度依赖于对齐数据。在这些实验中,我们使用了一个包含 8850 万个图像/视频—文本配对样本的数据集,该数据集与训练 PerceptionLM(Cho et al., 2025)时使用的数据类似。为了证明 V-JEPA 2 编码器的有效性,我们首先在第 7.2 节中,在一个受控数据设置下,使用 1800 万个样本的子集,将 V-JEPA 2 与其他当前最先进的视觉编码器进行比较。随后,在同样的受控设置下,我们在第 7.3 节中展示:扩大视觉编码器规模和提高输入分辨率,都会持续提升 VidQA 性能。最后,在第 7.4 节中,我们进一步扩大对齐数据规模,使用完整的 8850 万个样本,测试 V-JEPA 2 与语言进行对齐的能力上限。实验结果表明,在受控数据设置下,V-JEPA 2 在开放式 VidQA 任务上相比其他视觉编码器具有竞争力;而当扩大对齐数据规模后,V-JEPA 2 在多个 VidQA 基准测试上达到了当前最先进性能。
7.1 Experiment Setup
视频问答任务。 我们在 PerceptionTest(Pătrăucean et al., 2023)上进行评估,该基准用于考察模型在不同能力上的表现,例如记忆、抽象、物理理解和语义理解。此外,我们还在 MVP 数据集(Krojer et al., 2024)上评估模型的物理世界理解能力。MVP 采用最小视频对的评估框架,以减轻文本偏差和外观偏差的影响。
我们还在 TempCompass、TemporalBench 和 TOMATO(Liu et al., 2024c; Cai et al., 2024; Shangguan et al., 2024)上进行评估,以考察模型的时间理解能力和记忆能力。最后,我们使用 MVBench(Li et al., 2024c)报告模型的一般理解能力结果。需要注意的是,MVBench 偏向于单帧外观特征(Krojer et al., 2024; Cores et al., 2024)。同时,我们还使用 TVBench(Cores et al., 2024)进行评估,该基准在文献中被提出作为一般理解和时间理解任务的替代评估方式,旨在缓解上述偏差。
视觉指令微调。 为了在视觉问答任务上评估 V-JEPA 2 的表征能力,我们采用 LLaVA 框架(Liu et al., 2024a)中的视觉指令微调流程,将 V-JEPA 2 与大语言模型进行对齐。该过程需要使用一个可学习的投影模块,通常是 MLP,将视觉编码器的输出,也就是视觉 token,转换为大语言模型可以接收的输入。
我们按照 Liu et al.(2024b)的方法,通过一个渐进式三阶段流程训练多模态大语言模型:
第一阶段,只在图像描述数据上训练投影器;
第二阶段,在大规模图像问答数据上训练完整模型;
第三阶段,进一步在大规模视频描述和视频问答数据上训练模型。
通过这种分阶段训练方式,大语言模型能够逐步提升对视觉 token 的理解能力。视觉编码器既可以保持冻结,也可以与 MLLM 的其余部分一起进行微调。我们探索了这两种设置:冻结视觉编码器可以更清楚地反映视觉特征本身的质量,而微调视觉编码器则通常能够带来更好的整体性能。关于视觉指令训练的更多细节见附录 E。
7.2 Comparing with Image Encoders
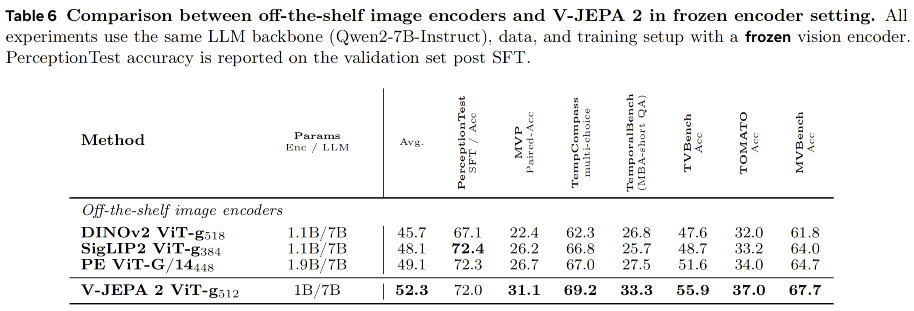
为了单独分析视觉编码器对 MLLM 性能的贡献,并将其与 V-JEPA 2 进行比较,我们引入了一个受控实验设置:使用相同的大语言模型骨干和相同的训练设置,分别搭配不同的当前最先进视觉编码器来训练独立的 MLLM。在该受控设置中,我们使用 Qwen2-7B-Instruct(Yang et al., 2024a)作为语言模型,并冻结视觉编码器。训练数据使用 1800 万个图像/视频—文本对齐样本。我们首先将以 (512 \times 512) 分辨率预训练的 V-JEPA 2,与 DINOv2(Oquab et al., 2023)、SigLIP-2(Tschannen et al., 2025)以及 Perception Encoder(Bolya et al., 2025)进行比较。
实验结果表明,在冻结视觉编码器的设置下,V-JEPA 2 表现出具有竞争力的性能。除 PerceptionTest 外,V-JEPA 2 在所有测试基准上都优于 DINOv2、SigLIP 和 Perception Encoder(PE);在 PerceptionTest 上,V-JEPA 2 的表现略低于 SigLIP 和 PE。其性能提升在 MVP、TemporalBench 和 TVBench 上尤为明显,而这些基准主要关注时间理解能力。
此外,由于实验中唯一改变的是视觉编码器,因此这些结果证明:一个没有经过语言监督训练的视频编码器,也可以超过经过语言监督训练的编码器。这与以往的传统观点相反(Tong et al., 2024; Li et al., 2024b; Liu et al., 2024d; Yuan et al., 2025)。这些结果还表明,在视频问答任务中使用视频编码器而不是图像编码器,可以提升模型的时空理解能力,也进一步说明了开发更强视频编码器的重要性。
7.3 Scaling Vision Encoder Size and Input Resolution
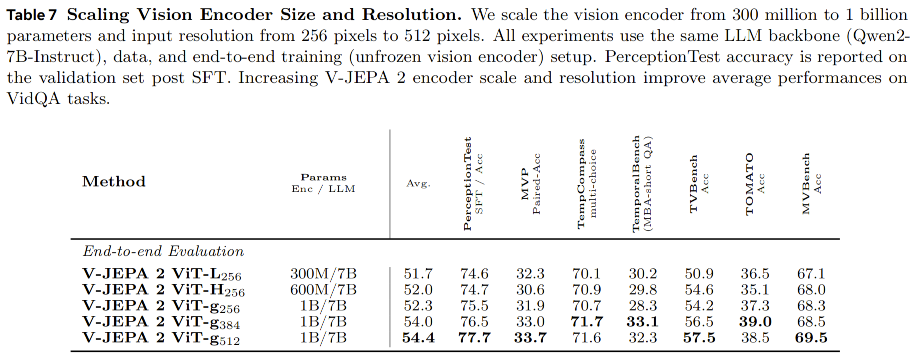
已有研究(Fan et al., 2025)表明,对于自监督图像编码器而言,扩大视觉编码器规模和提高输入分辨率可以显著提升 VQA 性能。因此,我们将 V-JEPA 2 的模型规模从 3 亿参数扩展到 10 亿参数,并将输入分辨率从 256 像素提升到 512 像素,结果如表 7 所示。
当在固定输入分辨率为 256 像素的情况下,将视觉编码器规模从 3 亿参数提升到 10 亿参数时,我们观察到多个任务上的性能提升:PerceptionTest 提升 0.9 个百分点,TVBench 提升 3.3 个百分点,MVBench 提升 1.2 个百分点。
此外,将输入分辨率进一步提高到 512 像素后,所有下游任务的性能都继续提升。例如,PerceptionTest 提升 2.2 个百分点,TemporalBench 提升 4.0 个百分点,TVBench 提升 3.3 个百分点。
这些结果表明,进一步扩大视觉编码器规模并提高输入分辨率,是提升视频问答(VidQA)性能的一个有前景的方向。
7.4 Improving the State-of-the-art by Scaling Data
在受控实验设置下,我们对使用 V-JEPA 2 训练 MLLM 的能力有了更深入理解之后,进一步研究了扩大对齐数据集规模对提升 VidQA 当前最先进性能的影响。已有研究(Cho et al., 2025)表明,增加训练数据规模通常能够带来下游任务性能的阶段性提升。为此,我们将 MLLM 训练数据规模从 1800 万增加到完整的 8850 万,约扩大了 4.7 倍。
虽然提高模型输入分辨率有助于提升下游性能,但这也带来了一个挑战:大语言模型输入中需要容纳大量视觉 token。因此,我们选择使用 V-JEPA 2 ViT-g384,每帧产生 288 个视觉 token。我们遵循 Cho et al.(2025)的相同训练方案,使用 Llama 3.1 作为语言模型骨干来训练 V-JEPA 2 ViT-g384。为了简化训练过程,我们使用不带 pooling 的 MLP 投影器。关于扩展训练设置的详细信息见附录 E。
实验结果表明,扩大数据规模能够全面提升下游基准性能,并在多个基准上取得当前最先进结果(表 8),包括 PerceptionTest、MVP、TempCompass、TemporalBench 和 TOMATO。与当前最先进的 PerceptionLM 8B(Cho et al., 2025)相比,V-JEPA 2 在 PerceptionTest 测试集准确率上提升了 1.3 个百分点,在 MVP paired accuracy 上提升了 4.8 个百分点,在 TempCompass 准确率上提升了 4.2 个百分点,在 TemporalBench 短问答部分的 multi-binary accuracy 上提升了 8.4 个百分点,在 TOMATO 准确率上提升了 7.1 个百分点。
不过,V-JEPA 2 在 TVBench 和 MVBench 上没有超过 PerceptionLM,但仍然显著优于其他相关基线模型,例如 InternVL 2.5、Qwen2VL 和 Qwen2.5VL。这些结果强调了扩大视觉—语言对齐训练数据规模的重要性,并进一步证明:像 V-JEPA 2 这样没有经过语言监督预训练的编码器,在拥有足够规模的对齐数据后,也能够取得当前最先进的性能。
8 Related Work
以下为上传文本的中文翻译:
世界模型与规划
早在 Sutton 和 Barto(1981)以及 Chatila 和 Laumond(1985)的工作中,人工智能研究者就已经开始尝试构建能够利用内部世界模型的智能体。这类模型既可以建模世界的动态变化,也可以对静态环境进行映射,从而实现高效的规划与控制。
以往研究已经在仿真任务中探索了世界模型(Fragkiadaki et al., 2015; Ha and Schmidhuber, 2018; Hafner et al., 2019b,a; Hansen et al., 2022, 2023; Hafner et al., 2023; Schrittwieser et al., 2020; Samsami et al., 2024),也在真实世界的运动控制和机器人操作任务中进行了研究(Lee et al., 2020; Nagabandi et al., 2020; Finn et al., 2016; Ebert et al., 2017, 2018; Yen-Chen et al., 2020)。
世界模型方法可以直接在像素空间中学习预测模型(Finn et al., 2016; Ebert et al., 2017, 2018; Yen-Chen et al., 2020),也可以在学习到的表征空间中进行预测(Watter et al., 2015; Agrawal et al., 2016; Ha and Schmidhuber, 2018; Hafner et al., 2019b; Nair et al., 2022; Wu et al., 2023b; Tomar et al., 2024; Hu et al., 2024; Lancaster et al., 2024),或者使用更结构化的表征空间,例如关键点表征(Manuelli et al., 2020; Das et al., 2020)。
以往已经在真实机器人任务中展示性能的方法,通常训练的是任务特定的世界模型,并且依赖机器人部署环境中的交互数据。其评估重点通常是证明世界模型方法在已探索任务空间中的表现,而不是验证其对新环境或未知物体的泛化能力。相比之下,本文训练的是一个任务无关的世界模型,并展示了其对新环境和新物体的泛化能力。
近期一些工作同时利用互联网规模视频和交互数据,训练面向自主机器人的通用动作条件视频生成模型,即任务无关模型(Bruce et al., 2024; Agarwal et al., 2025; Russell et al., 2025)。然而,到目前为止,这些方法主要展示的是:给定机器人动作后,模型能够生成视觉上看起来合理的计划;但它们尚未证明这些模型能够被实际用于控制机器人。
还有一些研究探索了将生成式建模整合到策略学习中(Du et al., 2024; Wu et al., 2023a; Zhao et al., 2025; Zhu et al., 2025; Du et al., 2023; Zheng et al., 2025; Rajasegaran et al., 2025)。与这类工作不同,本文的目标是通过模型预测控制来利用世界模型,而不是通过策略学习来使用世界模型,从而避免需要专家轨迹的模仿学习阶段。这两类方法是正交的,未来也可以结合使用。与本文最接近的工作是 Zhou et al.(2024)和 Sobal et al.(2025),它们表明可以通过阶段式或端到端方式学习世界模型,并将其用于零样本规划任务。不同的是,这些先前工作主要关注小规模规划评估,而本文展示了类似原则可以被扩展,并用于解决真实世界机器人任务。
用于机器人控制的视觉—语言—动作模型
近年来,真实世界机器人控制中的模仿学习方法取得了显著进展,逐渐能够学习具有更好泛化能力的策略。这主要得益于利用在互联网规模视频和文本数据上预训练的视频—语言模型,然后通过专家演示数据上的行为克隆对其进行微调或适配,使模型也能够预测动作(Driess et al., 2023; Brohan et al., 2023; Black et al., 2024; Kim et al., 2024; Bjorck et al., 2025; Black et al., 2025)。
尽管这些方法展示了有前景的泛化结果,但由于它们缺少显式的世界预测模型,并且没有利用推理阶段的计算进行规划,因此尚不清楚它们是否能够学会预测训练数据中没有展示过的行为。这类方法需要高质量、大规模的遥操作数据,并且通常只能利用成功轨迹。相比之下,本文关注的是如何利用任意交互数据,不论这些数据来自成功的交互还是失败的交互。
视觉基础模型
计算机视觉中的视频基础模型表明,由图像和/或视频组成的大规模观察数据集,可以通过自监督学习方法用于学习通用视觉编码器。这些编码器能够在广泛的下游任务中表现良好。相关方法包括基于图像的自监督学习(Grill et al., 2020; Assran et al., 2023; Oquab et al., 2023; Fan et al., 2025)、基于视频的自监督学习(Bardes et al., 2024; Carreira et al., 2024; Wang et al., 2023; Rajasegaran et al., 2025)、使用弱语言监督的方法(Wang et al., 2024b; Bolya et al., 2025),以及这些方法的组合(Tschannen et al., 2025; Fini et al., 2024)。
然而,以往研究通常更关注理解能力评估,例如基于 probe 的评估,或者在与大语言模型对齐之后进行视觉问答任务评估。虽然这些任务推动了相关领域的发展,但视觉系统的一个重要目标仍然是使智能体能够与物理世界进行交互(Gibson, 1979)。因此,除了视觉理解任务上的结果之外,本文进一步研究了大规模视频自监督学习如何使模型能够在新环境中以零样本方式解决规划任务。
9 Conclusion
本研究表明,联合嵌入预测架构能够通过自监督方式从网络规模数据和少量机器人交互数据中学习,从而得到一个具备理解、预测和规划物理世界能力的世界模型。V-JEPA 2 在需要运动理解的动作分类任务和人类动作预判任务上取得了当前最先进的性能。当与大语言模型对齐后,V-JEPA 2 在视频问答任务上也优于以往的视觉编码器。此外,利用 V-JEPA 2 的表征对动作条件世界模型 V-JEPA 2-AC 进行后训练,可以使真实世界机器人成功完成零样本抓取式操作任务,例如拾取—放置任务。这些发现表明,V-JEPA 2 是迈向更先进人工智能系统的一步,使 AI 系统能够更有效地感知环境并在环境中执行动作。
未来工作:未来仍有若干重要方向需要进一步研究,以解决 V-JEPA 2 当前的局限性。
首先,本文主要关注需要预测未来约 16 秒以内状态的任务。这使模型能够基于单张目标图像,对较简单的操作任务进行规划,例如抓取和携物到达。然而,如果要将其扩展到更长时域的任务,例如在不依赖子目标的情况下完成拾取—放置任务,甚至更复杂的任务,则需要在建模方法上进一步创新。一个有前景的方向是发展层次化模型,使其能够在多个空间和时间尺度上,并在不同抽象层级上进行预测。
其次,正如第 4 节所述,V-JEPA 2-AC 当前依赖以图像目标形式指定任务。虽然这种方式对某些任务而言是自然的,但在其他场景中,使用语言来指定目标可能更加合适。因此,将 V-JEPA 2-AC 扩展为能够接受语言目标,是未来工作的另一个重要方向。例如,可以设计一个模型,将语言形式的目标嵌入到 V-JEPA 2-AC 的表征空间中。第 7 节中关于将 V-JEPA 2 与语言模型对齐的结果,可能为这一方向提供起点。
最后,本文中 V-JEPA 2 模型的规模最大扩展到了约 10 亿参数,这仍然是一个相对适中的规模。第 2 节的结果表明,在扩展到这一规模的过程中,模型性能持续提升。已有研究已经探索了将视觉编码器扩展到高达 200 亿参数的规模(Zhai et al., 2022; Carreira et al., 2024)。未来仍需要在这一方向上开展更多工作,发展可扩展的预训练方案,使模型性能能够随着规模扩大而持续提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)