C++多线程编程:从入门到生产者-消费者模型
目录
一、为什么我们需要多线程?
想象一下,你经营着一家火爆的餐厅。如果后厨只有一位厨师(单线程),他既要切菜、又要炒菜、还要摆盘,顾客们得排长队等到天荒地老。为了解决这个问题,你雇佣了多位厨师(多线程),切菜的切菜,炒菜的炒菜,大家并行工作,上菜速度瞬间提升!
在现代计算机中,多核CPU就像拥有多个灶台的厨房。如果我们只用单线程编程,就好比让一位超级大厨独占所有灶台,虽然也能做菜,但其他灶台都在闲置,这简直是巨大的浪费!学习多线程,就是为了充分利用多核CPU的算力,让你的程序像高效运转的自动化工厂,不仅处理速度快,界面也不会因为后台计算而卡死。
思考题: 如果你的程序只需要做一个简单的数学加法(1+1=2),有必要开启多线程吗?为什么?
二、进程与线程
在深入代码之前,我们必须搞清楚两个“老大哥”:进程和线程。
进程就像是“工厂”本身。它是操作系统分配资源(内存、文件句柄、CPU时间)的基本单位。当你打开一个软件,操作系统就为它建立了一个独立的工厂,拥有自己的围墙(内存空间)和设备。
线程则是工厂里的“生产线”或“工人”。它是CPU调度的基本单位。一个工厂(进程)里可以有多条生产线(线程),它们共享工厂的资源(比如原材料仓库),但各自独立运作。
进程 vs 线程对比:
| 特性 | 进程 | 线程 |
|---|---|---|
| 根本区别 | 资源分配的基本单位 | CPU调度的基本单位 |
| 内存空间 | 独立,互不干扰 | 共享所属进程的内存 |
| 创建/切换开销 | 大(需要分配独立资源) | 小(仅分配少量私有数据) |
| 通信方式 | 复杂(管道、共享内存等) | 简单(直接读写共享变量) |
| 崩溃影响 | 进程崩溃不影响其他进程 | 一个线程崩溃通常导致整个进程挂掉 |
思考题: 既然线程共享内存通信很方便,那为什么我们还需要进程?直接把所有程序都做成一个进程里的不同线程不行吗?(提示:想想安全性)
三、线程模型简介
线程的实现方式主要有两种流派,这决定了你的代码在底层是如何跑起来的。
用户级线程: 由用户空间的库(如早期的Green Threads)管理,内核不知道线程的存在。
- 优点: 切换快,不需要陷入内核。
- 缺点: 如果一个线程阻塞(如IO操作),整个进程的所有线程都会被卡住,因为内核只看到一个CPU时间片。
内核级线程: 由操作系统内核直接管理。
- 优点: 真正的并行,一个线程阻塞不影响其他线程。
- 缺点: 创建和切换需要系统调用,开销稍大。
常见的三种模型:
- N:1模型(多对一): 多个用户线程映射到一个内核线程。并发但不并行。
- 1:1模型(一对一): 一个用户线程对应一个内核线程。C++
std::thread通常就是这种,利用多核能力强。- N:M模型(多对多): 混合模型,最灵活但也最复杂。
思考题: 现代C++标准库中的
std::thread通常采用的是哪种模型,以充分利用多核CPU?
四、线程生命周期
线程的一生并非一帆风顺,它会在不同的状态间反复横跳。我们可以用文字描述这个状态转换图:
- 新建: 线程对象被创建,但还没开始跑。就像运动员在起跑线上蹲好。
- 就绪: 线程准备好了,正在排队等待CPU临幸。就像运动员听到枪响,但在拥挤的人群中等待跑道空位。
- 运行: CPU正在执行该线程的代码。运动员正在跑道上飞奔。
- 阻塞: 线程因为等待某个事件(如IO完成、获取锁)而暂停。运动员鞋带开了,必须停下来系好才能继续。
- 终止: 线程任务完成,或者被强制结束。运动员冲过终点线。
思考题: 当一个线程在等待用户输入(比如等待你按回车键)时,它处于什么状态?此时CPU可以去执行其他线程吗?
五、实战代码:从入门到精通
5.1 最简线程创建
这是你的“Hello World”。我们将创建一个子线程,让它打印一句话。
#include <iostream> #include <thread> // 必须包含的头文件 // 线程要执行的函数 void myTask() { std::cout << "你好,我是子线程!" << std::endl; } int main() { // 1. 创建线程对象,传入函数名 std::thread t(myTask); // 2. 等待线程结束 // 如果不join,main函数可能先结束,导致子线程被强制终止 t.join(); std::cout << "主线程结束" << std::endl; return 0; }
5.2 演示竞态条件
现在我们让两个线程同时修改一个全局变量。猜猜结果是多少?
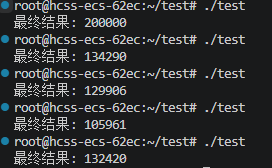
#include <iostream> #include <thread> #include <vector> int counter = 0; // 全局共享变量 void increment() { for (int i = 0; i < 100000; ++i) { counter++; // 看起来是一行代码,其实是三步操作 } } int main() { std::thread t1(increment); std::thread t2(increment); t1.join(); t2.join(); // 期望是200000,但实际往往小于这个数 std::cout << "最终结果: " << counter << std::endl; return 0; }
为什么结果不对?
counter++在汇编层面分为三步:
- 读: 把内存中的
counter读到寄存器。- 改: 寄存器里的值加1。
- 写: 把寄存器的值写回内存。
如果T1读了5,T2也读了5。T1加1变成6写回,T2也加1变成6写回。两个线程各干了一次活,结果只增加了1!这就是竞态条件。
5.3 使用互斥锁解决
我们需要给共享资源加一把锁,一次只允许一个人操作。
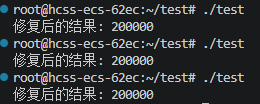
#include <iostream> #include <thread> #include <mutex> // 互斥锁头文件 int counter = 0; std::mutex mtx; // 定义一把锁 void safeIncrement() { for (int i = 0; i < 100000; ++i) { mtx.lock(); // 加锁 counter++; // 临界区:只有持有锁的线程能执行 mtx.unlock(); // 解锁 } } int main() { std::thread t1(safeIncrement); std::thread t2(safeIncrement); t1.join(); t2.join(); std::cout << "修复后的结果: " << counter << std::endl; // 稳了! return 0; }
提示: 实际开发中,我们更推荐使用
std::lock_guard,它能利用RAII机制自动解锁,防止忘记解锁导致的死锁。
5.4 生产者-消费者模型
这是多线程最经典的场景:一个线程生产数据,另一个线程处理数据。我们需要一个缓冲区,以及条件变量来协调“满了等”和“空了等”。
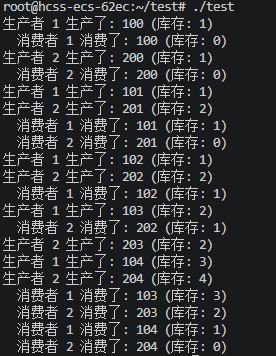
#include <iostream> #include <thread> #include <queue> #include <mutex> #include <condition_variable> #include <chrono> std::queue<int> buffer; // 缓冲区 std::mutex mtx; // 互斥锁 std::condition_variable cv; // 条件变量 bool finished = false; // 结束标志 // 生产者 void producer(int id) { for (int i = 0; i < 5; ++i) { std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 模拟生产耗时 std::unique_lock<std::mutex> lock(mtx); // 等待缓冲区不满(这里简化为不设上限,实际可加判断) cv.wait(lock, []{ return buffer.size() < 10; }); int data = id * 100 + i; buffer.push(data); std::cout << "生产者 " << id << " 生产了: " << data << " (库存: " << buffer.size() << ")" << std::endl; lock.unlock(); cv.notify_all(); // 通知消费者有货了 } } // 消费者 void consumer(int id) { while (true) { std::unique_lock<std::mutex> lock(mtx); // 等待缓冲区不空 或者 任务结束 cv.wait(lock, []{ return !buffer.empty() || finished; }); if (finished && buffer.empty()) { break; // 优雅退出 } int data = buffer.front(); buffer.pop(); std::cout << " 消费者 " << id << " 消费了: " << data << " (库存: " << buffer.size() << ")" << std::endl; lock.unlock(); cv.notify_all(); // 通知生产者有空位了 // 添加消费耗时,让缓冲区有机会堆积 std::this_thread::sleep_for(std::chrono::milliseconds(150)); } } int main() { std::thread p1(producer, 1); std::thread p2(producer, 2); std::thread c1(consumer, 1); std::thread c2(consumer, 2); p1.join(); p2.join(); // 通知消费者退出 { std::lock_guard<std::mutex> lock(mtx); finished = true; } cv.notify_all(); c1.join(); c2.join(); return 0; }
正如我们预料的,生产者(100ms)比消费者(150ms)快。
当消费者还在慢吞吞地处理数据时,两个生产者并没有闲着,他们利用这段“空窗期”疯狂生产,导致库存一路飙升到了 4。
这完美展示了异步的威力:生产者不需要等待消费者处理完,只要缓冲区没满,就可以继续干活。
六、常见误区提醒
在多线程的道路上,有些坑千万别踩:
- 不要一开始就深究内核调度算法: 除非你是写操作系统的,否则理解“抢占式调度”和“时间片”的概念就够了,不要去背调度算法的代码实现。
- 不要死记硬背所有锁类型:
mutex,recursive_mutex,shared_mutex,timed_mutex... 只需要先掌握std::mutex和std::lock_guard,其他的用到再查。- 不要在无竞争场景用多线程: 如果你的任务只是计算
1+1,或者处理一个极小的数组,开启线程的开销(创建、切换)远大于并行带来的收益。多线程是用来处理耗时任务的!思考题: 如果生产者的速度远快于消费者,且没有缓冲区大小限制,会发生什么后果?(提示:内存爆炸)
七、思考题参考答案
这里为你准备了每个章节思考题的参考答案与解析,帮助你查漏补缺,深入理解多线程的核心逻辑。
问题: 如果你的程序只需要做一个简单的数学加法(1+1=2),有必要开启多线程吗?为什么?
完全没必要。
解析: 多线程虽然强大,但它是有“成本”的。创建一个线程需要分配栈内存、初始化寄存器状态,线程切换也需要消耗CPU时间。对于1+1这种纳秒级就能完成的微小任务,开启线程的“准备工作”所花费的时间,可能比直接计算还要长几十倍甚至上百倍。这就像为了送一份文件到隔壁办公室,专门雇了一架飞机一样,得不偿失。多线程通常用于处理耗时较长(如网络请求、文件读写、复杂计算)的任务。
问题: 既然线程共享内存通信很方便,那为什么我们还需要进程?直接把所有程序都做成一个进程里的不同线程不行吗?
为了安全(隔离性)和稳定性。
解析: 线程之间是“坦诚相见”的,它们共享同一块内存空间。这意味着一个线程可以轻易地修改另一个线程的数据,甚至因为一个线程的非法指针操作(比如野指针)导致整个进程崩溃,进而让所有线程一起挂掉。
而进程之间是“老死不相往来”的,拥有独立的内存空间。如果浏览器(一个进程)崩溃了,它不会导致你的音乐播放器(另一个进程)也跟着崩溃。进程提供了必要的保护屏障。
问题: 现代C++标准库中的
std::thread通常采用的是哪种模型,以充分利用多核CPU?
1:1模型(一对一模型)。
解析: 在这种模型下,每一个用户态的std::thread对象都直接对应一个操作系统内核线程。虽然创建开销比用户级线程大,但它能直接利用操作系统的调度器,将不同的线程分配到不同的CPU核心上真正并行执行,从而最大化多核CPU的性能。
问题: 当一个线程在等待用户输入(比如等待你按回车键)时,它处于什么状态?此时CPU可以去执行其他线程吗?
阻塞状态;可以。
解析: 当线程发起I/O请求(如读取键盘输入、读取硬盘文件)时,由于硬件速度远慢于CPU,线程会主动放弃CPU,进入阻塞状态。此时,操作系统会检测到该线程无法继续执行,于是调度器会立即把CPU资源分配给其他处于就绪状态的线程。这正是多线程能提升程序响应速度的关键原因。
问题: 如果生产者的速度远快于消费者,且没有缓冲区大小限制,会发生什么后果?
内存溢出。
解析: 如果生产者像发疯一样往std::queue里塞数据,而消费者处理得很慢,队列就会无限膨胀。由于没有设置最大容量限制(即没有让生产者在队列满时等待),内存会被迅速耗尽,最终导致程序因为无法分配更多内存而崩溃。在实际开发中,必须为缓冲区设置合理的上限。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)