开发日志6-RAG知识库构建step3-向量化
一、向量化
1.计算机看不懂人类的自然语言,只能识别、计算数字、数组、坐标。我们写的 408 知识点、用户的提问都是文字,对计算机来说只是一堆字符,没法直接判断两段文字语义是否相似。如果不做向量化,只能用关键词匹配,存在大量问题:同义不同词搜不到,比如,原文:进程饥饿现象;提问:长时间得不到调度的进程。字面关键词完全不一样,但语义一模一样,可关键词检索匹配不到;字面匹配但语义无关两个句子有相同关键词,但讲的完全不是一个考点,造成乱召回;专业术语别名、口语化提问无法适配408 很多知识点有简称、通俗解释,关键词匹配完全失效;无法量化相似度。向量化就是把一段文字,转换成固定长度的高维浮点数向量。文字 → 向量坐标,计算机就能用数学方式处理语义。转换成向量后,能用余弦相似度 / 余弦距离量化语义相似度,可以精准排序,选出最相关的 Top 知识块,这是传统检索做不到的。
2.相关概念理解
(1)高维向量空间:所有文本生成的 Embedding 向量,都存在于同一个高维实数向量空间中。例如项目中使用的bge-small-zh-v1.5输出512维向量,代表空间中每个文本点由512个独立特征维度组成,每一维对应一种抽象语义特征(如专业属性、句式结构、考点关联、逻辑倾向等)。
(2)文本即空间点:每一个 408 知识块、每一个用户问题,都对应向量空间中的一个唯一坐标点;整个知识库就是高维空间中分布的成千上万个特征点集合。
(3)空间分布规律语义相近的文本,在向量空间中坐标距离更近;语义无关的文本,空间距离更远。
(4)余弦相似度:计算两个向量在高维空间中的夹角余弦值,值域 [-1, 1];值越接近 1,代表两段文本语义越相似;越接近 -1 语义完全相反。余弦距离:工程检索常用指标,公式:余弦距离 = 1 - 余弦相似度,值域 [0, 2];值越接近 0,语义匹配度越高。
3.工作流程
(1)文本分词:对输入的 408 知识点、用户问题进行分词、子词切分,拆解为模型可识别的基础语义单元;
(2)语义编码:预训练的 Embedding 模型依托海量中文语料、专业领域数据,对文本进行深层语义编码,捕捉上下文关系、专业术语含义、知识点逻辑;
(3)向量映射:将整段文本压缩映射为固定维度的稠密向量,同一份文本每次生成的向量空间位置保持一致。
二、Embedding 模型选择
我们的用户群体是408备考生,需要匹配的是中文语义,所以不能用英文模型,这会造成对408 专业术语比如死锁、流水线、平衡二叉树、页式虚拟内存 理解极差。其次,模型的上下文长度要需要 ≥ Chunk 大小,我的切块是450字符,如果模型输入长度必须小于450字符,会造成切块塞不进去,直接截断,语义丢失。模型的维度方面,维度太高:占内存、入库慢、检索变慢;太低:语义区分度不够。此外,建向量库用的 embedding = 用户提问检索用的 embedding,中途换模型会导致向量空间不一样,检索混乱。
基于上述要求初步锁定了两个模型,bge-small-zh-v1.5和text-embedding-v3。区别在于bge-small-zh-v1.5完全免费,可以下载模型到本地使用,支持512tokens上下文长度,维度是512;text-embedding-v3有免费额度但超量收费,最长支持8192token上下文,目前可以选择512,768和1024维度;二者都是中文适配的。
从维度和上下文长度两个参数来说,这两个模型都行。而前者优势在于完全免费,不用担心额度不够,且是本地模型,不会有接口超时、限流问题;后者优势在于通过预训练模型底座和SFT策略优化提升embedding模型整体效果,RAG 回答更准、不跑偏。现阶段的开发我选择了bge-small-zh-v1.5,主要是不用担心额度,可以尽情调试。到项目后期为了提升效果更换模型也来得及。
三、向量数据库是否要分表
在构建向量数据库的时候有个疑问:是否要按照学科分表。最后的决定是不分表,主要有以下几个原因:
1. 跨学科检索需要
比如用户提问“操作系统的文件分配方式中,哪里用到了链表结构?” 如果分表需要写复杂的并发逻辑,去“操作系统表”和“数据结构表”里分别查一次,然后再想办法把两边的分数(Score)统一归一化并重新排序。如果不分表只需要在单一的全局大表里搜一次,向量模型会自动根据语义,把操作系统里的“链接分配”和数据结构里的“链表”同时检索出来。
2.Metadata保障
我们之前在切片脚本里, {"学科分类": "一_数据结构"} 这个元信息塞进了每一个块里,如果之后想指定科目搜索时,直接加个过滤条件,Chroma 会把搜索范围缩小到该科目。
此外,如果遇到这种情况:使用的 Embedding 模型不一样(维度不同), 比如表 A 用了 512 维模型,表 B 用了 1024 维模型,因为维度不同,它们在数学空间里根本无法计算距离,则必须分表。
四、具体实现
1.之前切块后把chunk放在了json文件中,首先要做的是读取json文件并将每一行重新拼装成 LangChain 的 Document 对象;

2.如果选用bge模型可以在本地运行,首先从huggingface加载模型将chunk翻译成向量并存入chroma数据库


3.向量知识库构建好之后要将其接入模型,这里用户query的向量化要和向量化知识库用同一个embedding模型,防止向量空间不一致。

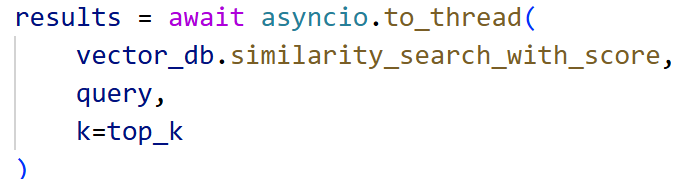
4.后端会话时执行数据库检索,这里使用 asyncio.to_thread 将同步的 Chroma 查询放入线程池运行;之后将检索到的块格式化后存在context_texts中,准备提供给prompt
5.构建prompt,将检索内容作为上下文传递给模型,使模型拥有知识块作为背景知识。

五、效果展示
1.首先写个test测试一下,问题是“TCP三次握手是怎么建立连接的?”,控制台输出找到的Top3匹配的知识块,并同时输出余弦距离,可以看到Top1余弦距离达到0.29,后面两个余弦距离也都在0.4左右。

2.未实现RAG时前端交互结果:

3.接入RAG后前端交互结果:
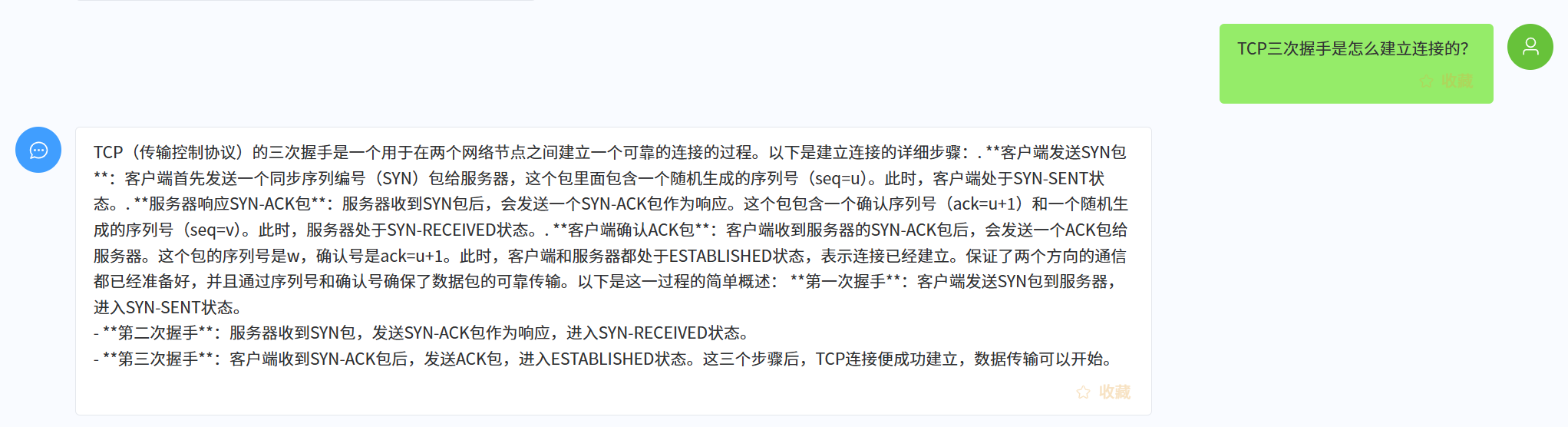
可以看到回答的内容明显受到了知识点作为上下文的影响,比较明显的是可以观察到seq=u,ack=u+1这种表述,这是来自于Top2知识点的。
接入RAG后的模型因为有常考点、知识点笔记作为上下文,回答更贴合408考点,避免了无效内容和冗余内容的输出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)