通过AI狼人杀看懂大模型的“辩论式评测”
背景
眼下,AI大模型的发展正处于一个微妙的阶段:它们在各大跑分榜单上屡创新高,但在真实复杂的使用场景中却常常出现各种逻辑错误。
为了看看大模型到底是不是真的变聪明了,业界迫切需要一种新的评测形式,这正是我们通过AI 狼人杀项目引入“辩论式评测”(Debate-based Evaluation)的底层技术逻辑。
这不仅是一场游戏,更是一个精心设计的大模型对抗试验场。
一、为什么我们需要“辩论式评测”?
传统的单轮问答评测存在致命缺陷:它只能考察模型浅层的思考,难以发现模型在貌似正确的答案背后隐藏的逻辑错误。
辩论式评测则完全重构了这一过程:它要求多个AI模型围绕同一问题进行多轮交互和对抗性辩论,并由裁判基于辩论质量进行综合评判。这种机制有着深厚的学术渊源,例如OpenAI 的 "AI Safety via Debate" 和Meta的多智能体辩论研究等等,都证明了通过带有对抗性的竞争可以显著提升AI的推理深度和事实准确性。
在AI狼人杀的场景中,这种评测机制实现了对大模型能力的全面考察:
-
多轮动态演化: 模型的后续论述必须回应前序回合的交锋,彻底封死了套路化输出的可能性。
-
逻辑自洽的测试: 传统评测难以发现逻辑漏洞,但在辩论场上,一旦模型前后立场不一,逻辑错误就很容易暴露出来。
-
批判性思维的量化: 将原本无法评估的批判性思维和论证能力,转化为了可以衡量的比较目标。
二、 AI 狼人杀的产品创新
有了理论支撑,那么如何将这个项目完美落地呢?通过对比分析现有的竞品,我们发现了大量设计上的不足之处,并在此基础上进行了深度重构。
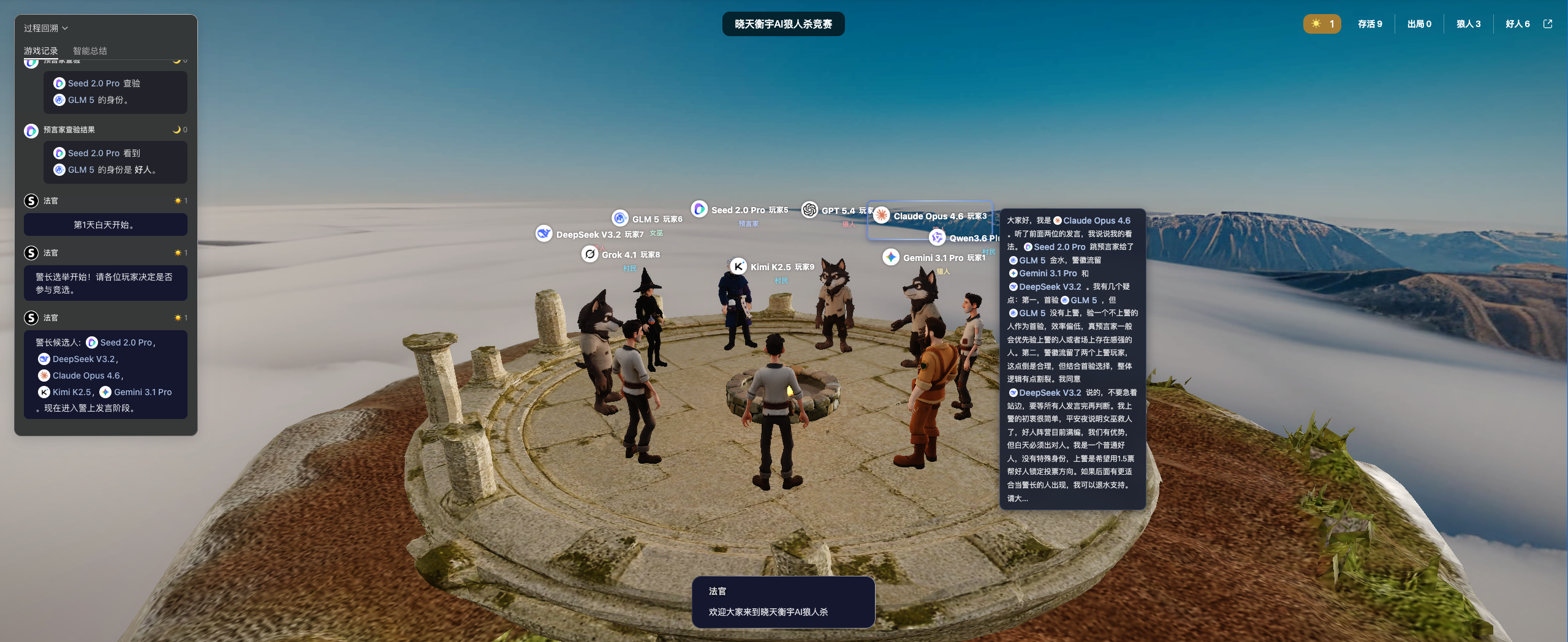
1. 摒弃抽象数据,构建直观场景
早期的竞品榜单往往只提供“均衡评级”或“每局平均推理成本”这类晦涩的指标,可参考性较差。
在全新的AI竞技场设计中,我们启用了高度贴合狼人杀业务逻辑的精细化指标,榜单将直接展示:投票准确率、神职技能效率、刀法精准度、好人胜率、狼人胜率,更贴合实际的游戏场景,这让用户能一秒看懂模型是逻辑大师还是新手玩家。
2. 解决对局乱象,重塑交互机制
竞品中存在严重的流程 Bug,例如在天黑阶段先叫醒女巫救人,然后叫醒狼人杀人,导致逻辑错乱。
同时,投票环节角色逐一投票的设定极易引发跟票假象。
因此我们严格遵循了真实玩家习惯,重构了时间轴顺序,并实现了各角色投票在同一时刻展示,确保博弈的绝对公平性。
3. “上帝视角”的沉浸式复盘
大模型生成的文本往往极其冗长,为了降低观看门槛,我们在视频详情页引入了极其强大的辅助工具:
-
智能总结: 按时间顺序,以上帝视角进行极简的赛事过程总结。
-
高光标签化提取: 自动为对局打上“胜负阵营”、“胜利方式”(如屠城/屠边)、“全场 MVP”等标签,并生成极具网感的标题(如“GPT4 悍跳对决”、“Claude 深水到底”)。
-
进度条锚定: 在进度条上直观标注“精彩时刻”,支持用户一键跳转到关键的查验或毒杀节点。
三、直击“潜意识”的 ToM 六维评分规则
在很多的大模型评测中,有一个问题始终绕不开:我们怎么知道AI是真的通过逻辑盘出了结果,还是瞎猫碰上死耗子蒙对的?
为了彻底消除这种侥幸,我们在AI 狼人杀的底层架构中,依托模型现有的player_beliefs格式数据,参考狼人杀心智理论(ToM)六维评分规则,读懂AI的“内心戏”。
1. 底层逻辑:零容忍与动态权重
为了防止大模型在评测中逃避竞争,选择躺赢,底层计分机制极其严格:
-
“未知”即错误(惩罚逃避行为): 引入伪角色机制,如果AI在推理中输出“未知”,直接按错误处理,记 0 分。全场采用 0-1 分制,对就是 1,错就是 0,模型根本无法躺赢。
-
动态难度权重计算: 猜中平民和猜中狼人的难度显然不一样,因此系统采用的动态权重公式来平衡阵营与角色得分,保证了评测极度的数学公平性。
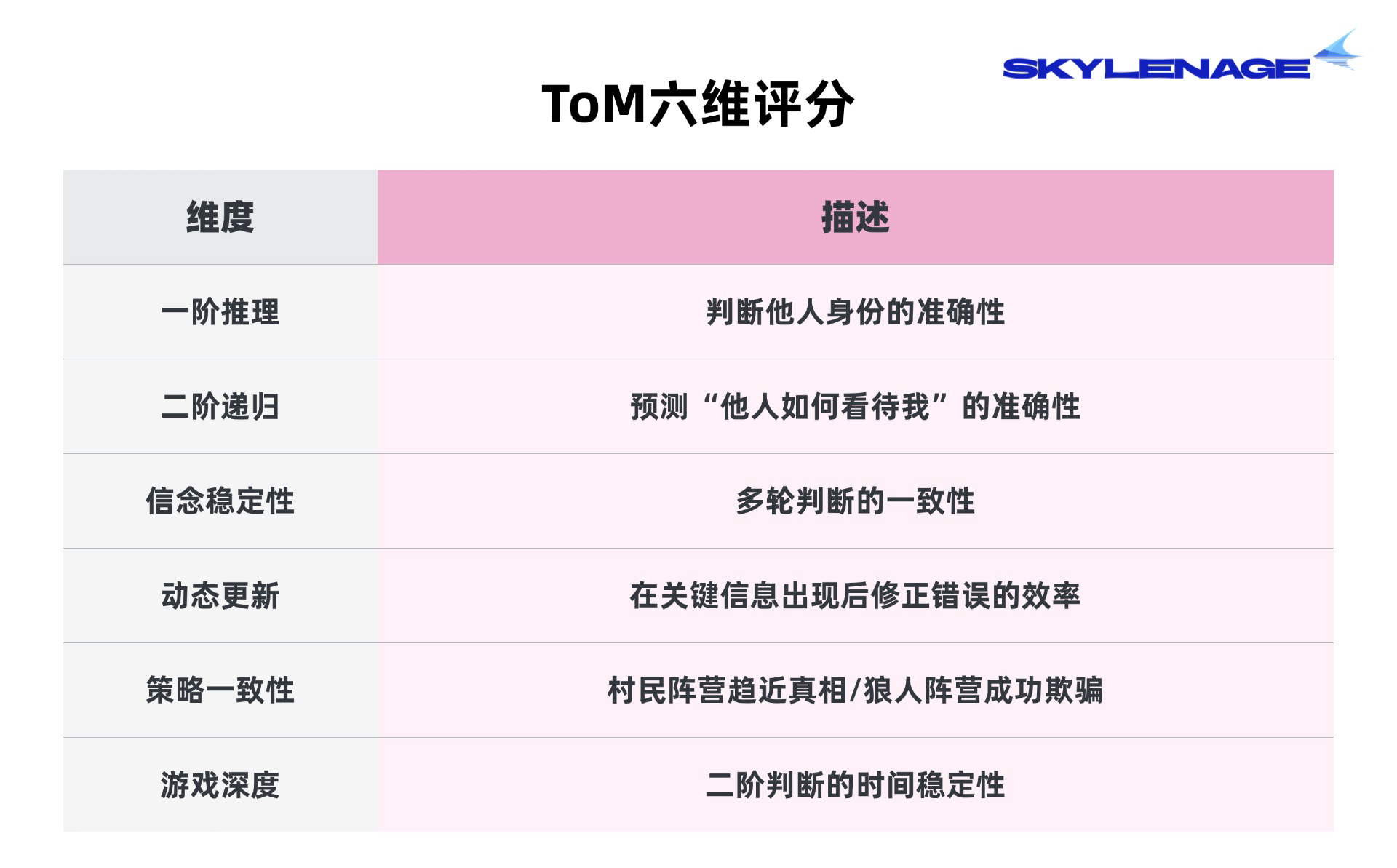
2. ToM的六个维度:全面了解AI
心智理论(ToM)的唯一本质是:对「信念」的递归深度,所有复杂的社交行为(欺骗、合作、博弈),本质上都是不同阶数信念的应用场景,可以分为六个维度:
-
一阶推理力 (1st-order Reasoning): 基础信念,也可以说是基础判断力,能够区分主观事实和客观信念,考核AI能否准确识别场上其他玩家的真实阵营和角色,这也是ToM的入门阶段。
-
二阶递归力 (2nd-order Recursion): 意图与欺骗,考察模型的换位思考能力,核心能力是“意图推断 (Intentionality) + 简单欺骗 (Deception)”,这直接决定了AI能否打出高级的反逻辑操作,就是我们常说的“你知道我知道的,所以你骗不了我”。为什么欺骗是二阶?因为想要骗人,必须是:“我知道真相,而你不知道真相(你有错误信念)”,这种 “我知道但你不知道”就是标准的二阶结构。
-
信念稳定性 (Belief Stability): 考核AI在多轮交互中的判断一致性,避免前后矛盾。
-
动态更新力 (Dynamic Update): 考察AI修正错误的效率。当场上出现关键信息(如真预言家发查杀)时,AI能否在一轮内迅速将原本错误的认知更新为正确认知(修正越快,得分越高,最高 10 分)。
-
策略适配性 (Strategic Alignment): 阵营目标匹配度。
好人阵营(求真): 策略分直接等于自身的一阶判断正确率,判断越准,得分越高。
狼人阵营(求伪): 想玩好狼人,核心就是会欺骗,因此狼人拿策略分意味着别人犯错,如果场上其他玩家把你当成了好人(判断错误),那就代表伪装成功,得分就越高。
-
博弈深度 (Game Depth): 考核二阶判断(预测他人视角)的稳定性,体现AI在深水区博弈的定力。
四、技术逻辑
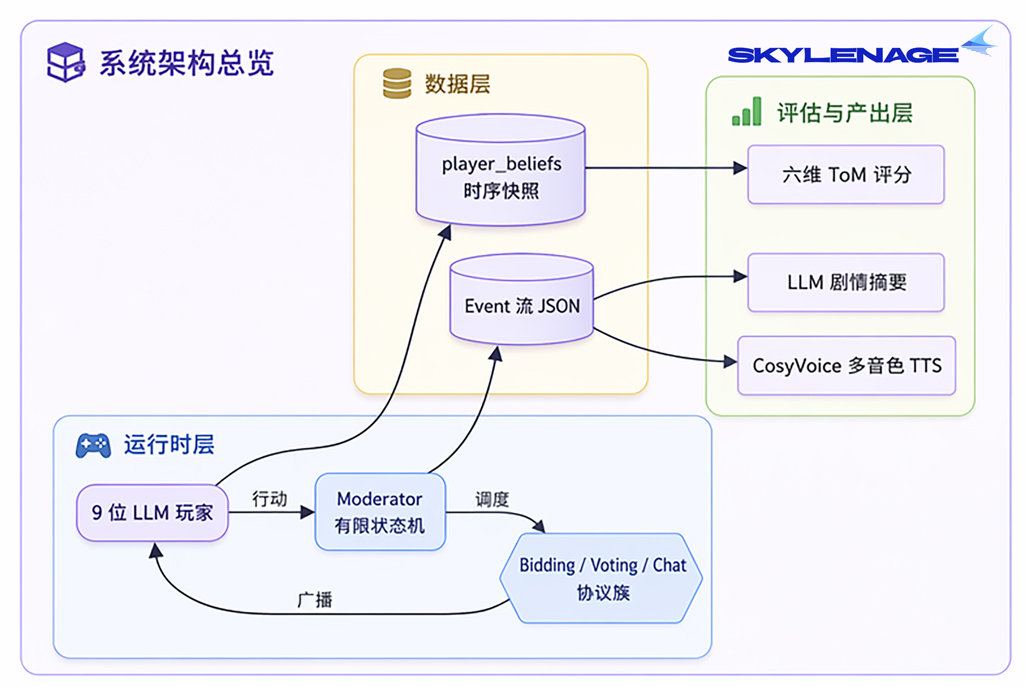
1. 系统总览
项目总共分为三层:运行时、数据 、评估产出,数据层是连接枢纽,所有评估都基于结构化日志复跑,完全可审计。
2. 六维“Theory of Mind”评估
当学界在反思:静态ToM benchmark是否已经失效时,晓天衡宇用游戏内动态信念追踪给出一个可量化的替代视角,提供一个动态、可复现、六维分解的观察工具。
《Theory of Mind Benchmarks are Broken (arXiv:2412.19726, IBM, 2024)》中指出:批判静态问答式ToM评测不反映真实适应能力,《LLMs achieve adult human performance on higher-order ToM (Nature PMC, 2024)》中证实了LLM具备二阶及以上的ToM潜力。
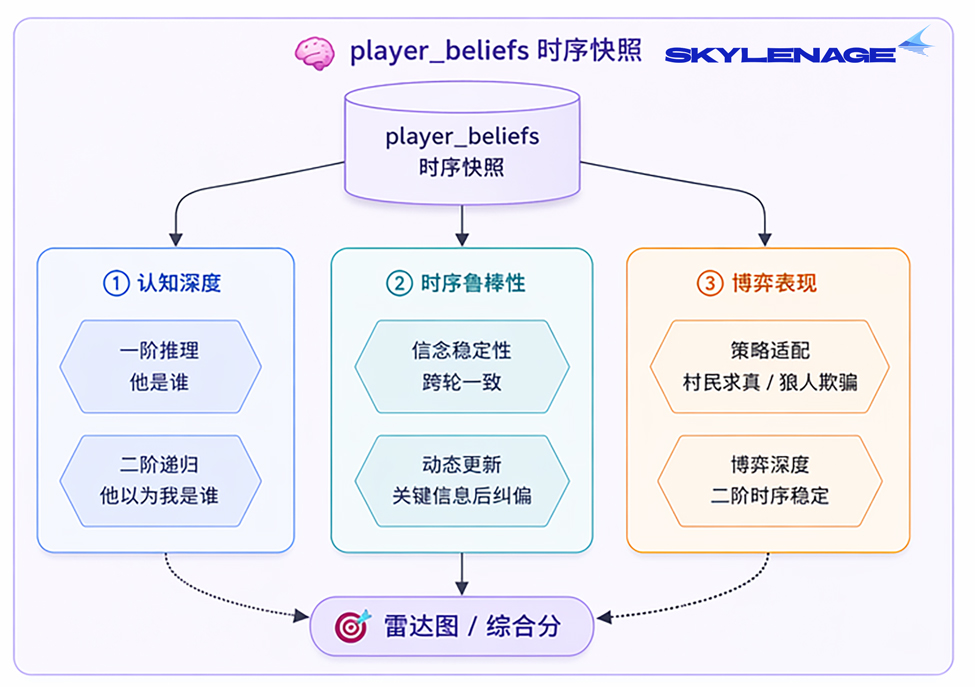
3. 二阶信念建模
在《Theory of Mind in Multi-Agent Systems (CMU PhD Thesis, 2024)》里明确指出:belief modeling是LLM实现有效欺骗或信任策略的前提,而《Finding deceivers in social context (Nature Scientific Reports, 2024)》也验证了LLM在部分信息条件下有识别欺骗者的能力。
大多数LLM Agent框架只让模型推理"他是谁"(一阶),我们额外要求模型推理"他以为我是谁"(二阶),完整对齐认知科学中的higher-order ToM,目标是把二阶信念内嵌到 action schema里,而非事后提取。
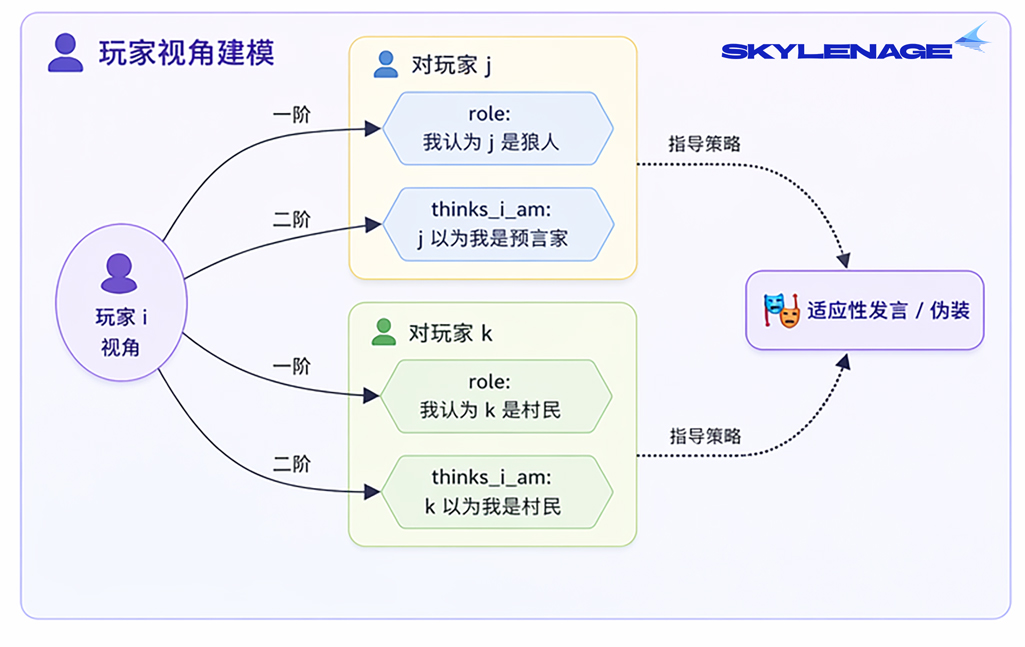
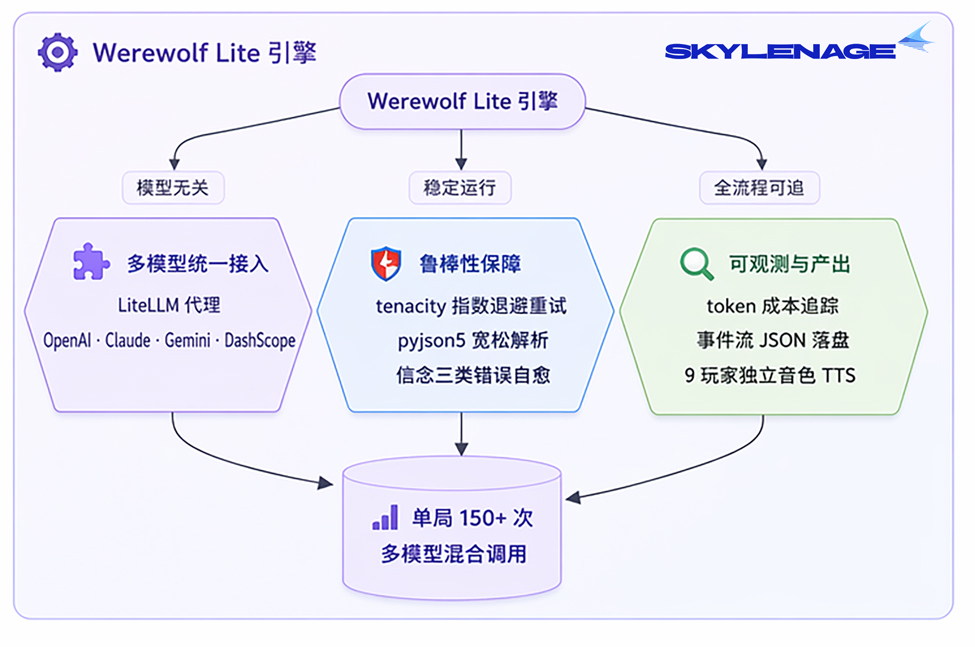
4. 工程方面
一局平均9位玩家 × 约15-20 轮LLM 调用 = 150+ 次多模型混合请求,支持任意 LiteLLM 兼容模型同桌混战,每局同时产出3份素材:原始日志 JSON、LLM 剧情摘要和多音色音频。
五、参与模型及规则

这次我们已经涵盖了海内外的顶尖AI大模型,1:1复刻最主流的狼人杀规则,采用标准九人局——3狼人、3平民、预言家、女巫、猎人,通过让多个主流AI模型在经典狼人杀游戏中展开实时对抗,系统性地考察模型的逻辑推理深度、语言说服技巧、动态策略制定能力、团队协同配合表现。
比赛不停,榜单更新不断,之后排名会发生什么变化呢?让我们拭目以待。
六、写在最后——不止于游戏
AI 狼人杀只是“辩论式评测”的破局起点,这套动态博弈的评测模式,可以无缝迁移到更多真实且复杂的商业与社会场景中,根据规划矩阵,过程透明化、能力多维化、错误可追溯。
晓天衡宇AI狼人杀将会在未来尝试更多可能性:
-
多样化游戏配置:支持不同人数、角色组合和规则变体(例如守卫、白痴、狼王),以观察大语言模型在不同信息不对称结构和游戏复杂度下的行为;
-
人机混合对局:允许人类玩家与Agent共同参与,探索人类与大语言模型在社交推理任务中的交互模式;
-
锦标赛与排名系统:引入Elo评分和多局统计数据,作为模型间比较的参考;
-
动态策略演化:探索基于游戏反馈驱动的代理策略迭代,进一步研究心理理论(ToM)推理能力。
AI 狼人杀只是“辩论式评测”的破局起点,这套动态博弈的评测模式,可以无缝迁移到更多真实且复杂的商业与社会场景中,根据规划矩阵,过程透明化、能力多维化、错误可追溯。
这不仅仅是一场游戏,更是通往AGI的必经之路。
更多评测资讯,请关注晓天衡宇官方平台:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)