【ICCV2025】仅需一段文字,MedSegFactory 同步生成医学图像与精确分割掩码

在医学图像分析中,训练一个优秀的深度学习模型往往需要大量带有精确标注的数据 。然而,获取医生级别的手工标注不仅成本高昂,还面临严格的隐私法规限制 。
为了应对“数据短缺”,合成数据成为了一种解决方案。但现有的合成方法往往要么难以精准控制,要么需要先提供昂贵的掩码图作为生成条件 。
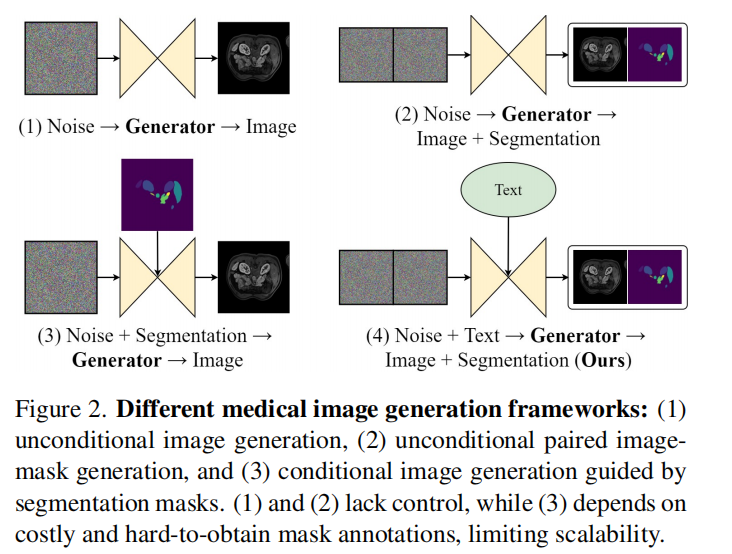
近期,加州大学圣克鲁兹分校联合英伟达等机构在 ICCV 2025 上发表了一项名为 MedSegFactory 的研究 。该框架打破了这一限制:只需输入一段简短的文本提示(包含目标器官、模态等),模型就能同步生成高质量的医学图像及其完美对齐的分割掩码(Mask) 。
目前,该项目的完整代码已在 GitHub 开源。本文将深入解析其背后的设计巧思。
1. 统一认知:共享的 VAE 编码器
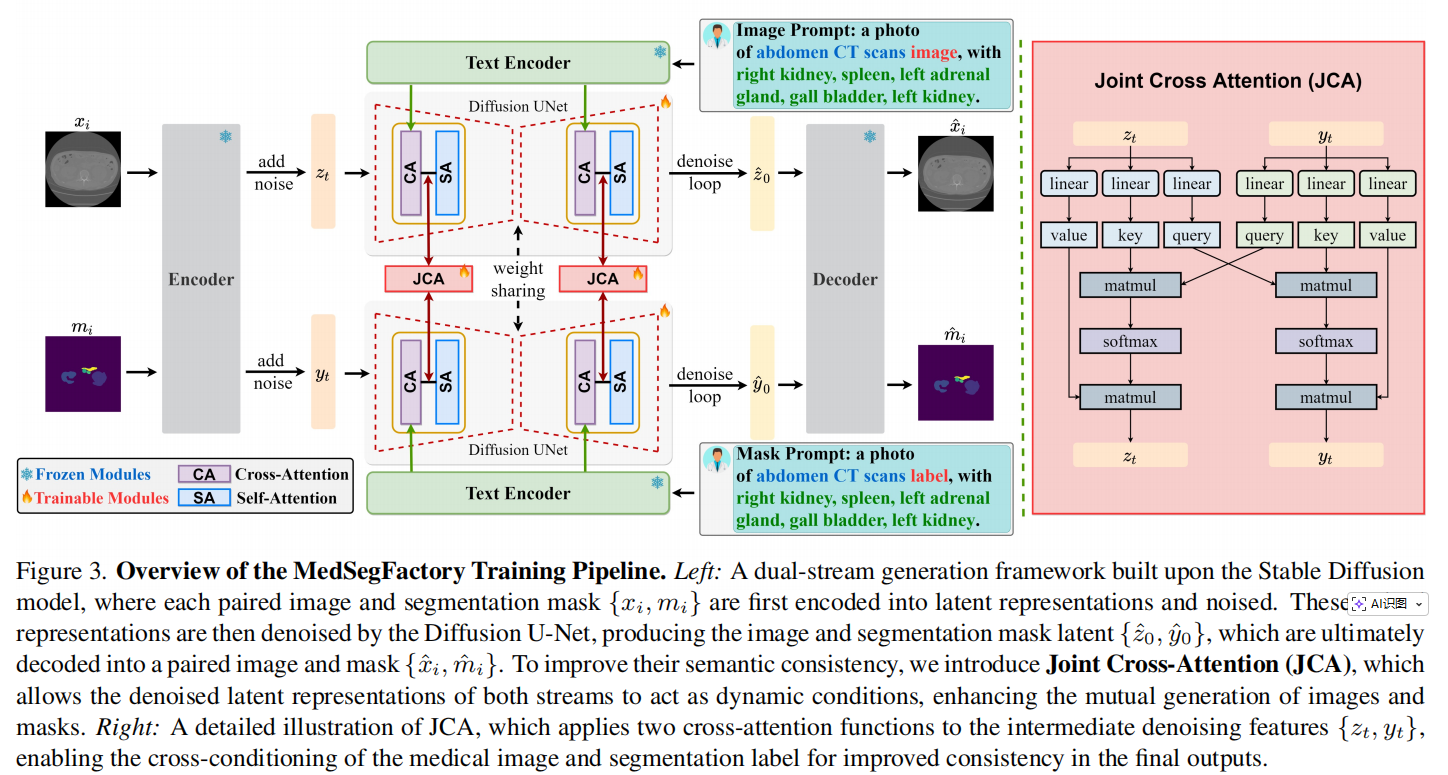
医学图像(通常包含复杂的纹理、灰度和解剖结构)与分割掩码(通常是简单的色块或二值图)在视觉上差异巨大。为了让这两类数据能在同一个生成框架下被处理,MedSegFactory 在特征压缩阶段做了一个关键设计:它们共享同一个变分自编码器(VAE) 。
通过共用同一个预训练 VAE,无论是复杂的 CT 切片还是简单的标签图,都被映射到了同一个高维度的“潜在空间(Latent Space)”中 。这为后续模型在统一的数学维度上理解两者的关联打下了基础。
2. 架构巧思:为什么要用“共享权重”的双流 U-Net?
在去噪生成阶段,MedSegFactory 采用了双流并行的 U-Net 架构:一条流水线生成图像,另一条流水线生成掩码 。 这里有一个极具探讨价值的架构设计问题:既然是双流,为什么不干脆训练两个完全独立的网络?或者,为什么不直接把图像和掩码拼在一起,用一个单流网络处理?
这其实是权衡了“特征解耦”与“语义统一”的结果:
-
为什么不用单流合并? 如果在输入端直接把图像和掩码拼接,特征从一开始就会混合在一起。由于特征被高度纠缠,模型很难接收针对图像和掩码各自独立的文本引导(Prompt),也无法在内部进行更细致的特征对齐。
-
为什么不用独立网络而要共享权重? 图像的纹理和掩码的轮廓,本质上描述的是“同一个医学解剖结构”。如果用两个独立的网络,参数量会翻倍,且容易在有限的医学数据上过拟合。让平行的双流共享同一套网络权重,相当于强制模型用同一套认知逻辑去理解“肝脏长什么样”和“肝脏的轮廓是什么”,促使它们在一个共享的语义空间内协同工作 。
3. 核心创新:联合交叉注意力(JCA)如何实现精准对齐?
即便共享了权重,两条平行流水线如果在去噪时各干各的,最终生成的图像边界和掩码形状依然容易发生错位。
为了解决多模态同步生成中的“对齐”难题,研究团队提出了核心创新——联合交叉注意力机制(Joint Cross-Attention, JCA) 。 在传统的条件生成中,掩码通常被作为静态条件死板地输入给图像。而在 MedSegFactory 中,JCA 让图像流和掩码流在去噪的每一步中进行“双向交流” : 图像流的特征会作为查询(Query),去和掩码流的特征(Key/Value)进行注意力计算;反之亦然 。这种动态的互参机制,使得图像的边界能根据掩码的形状自适应调整,而掩码的细节也能参考图像的生成状况进行修正,从而实现了最终结果的极高语义一致性 。
4. 实际效与应用价值
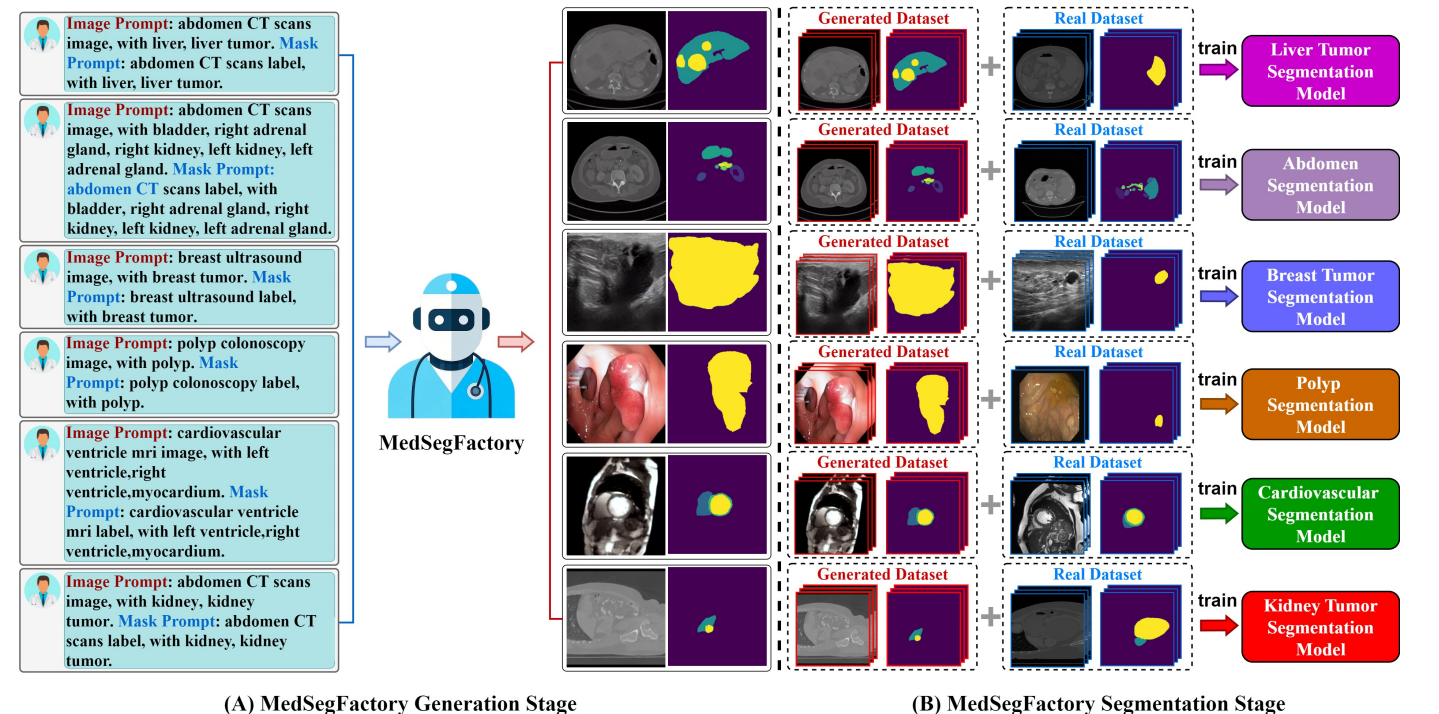
实验表明,将 MedSegFactory 生成的“图像-掩码对”作为数据增强加入真实训练集后,能够显著提升 nnUNet 等主流分割网络在多种模态(如腹部 CT、心血管 MRI、乳腺超声等)上的分割性能 。
5.代码解读
开源仓库地址:https://github.com/jwmao1/MedSegFactory。开源代码中的三份代码(tutorial_train.py, Our_Attention.py, Our_UNet.py)非常清晰地揭示了 MedSegFactory 论文中的理论是如何用朴素、优雅的 PyTorch 逻辑实现的。我们之前讨论的“双流架构”、“共享权重”以及最核心的“联合交叉注意力(JCA)”,在这三份代码中都有直接的体现。以下是我为你梳理的代码解读:
5.1 tutorial_train.py:“共享权重的双流架构”究竟是怎么写的?
我们在之前的讨论中提到,模型使用了两个平行的 U-Net,并且它们共享权重。那么在代码里,作者是不是真的定义了两个 unet 对象呢?
**答案是:没有。作者用了一个非常聪明的“Batch 拼接(Concat)”技巧,在一个 U-Net 实例中同时实现了双流和权重共享。**请看 tutorial_train.py 中训练循环的核心代码:
Python
images = batch["images"].to(accelerator.device, dtype=weight_dtype)
masks = batch["masks"].to(accelerator.device, dtype=weight_dtype)
# 【核心技巧】:在 Batch 维度(dim=0)将图像和掩码拼接在一起
inputs = torch.cat([images, masks], dim=0).to(...)
# 送入 VAE 编码
latents = vae.encode(inputs).latent_dist.sample()
# ... (加噪过程省略) ...
# 文本提示也同样在 Batch 维度拼接
encoder_hidden_states = torch.cat([img_encoder_output, mask_encoder_output], dim=0)
# 送入同一个 UNet
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
逻辑解析:
- 假设你的
batch_size是 20。 - 作者把 20 张图像和 20 张掩码在第 0 维拼起来,变成了一个
batch_size = 40的大张量。前半部分(0-19)是图像流,后半部分(20-39)是掩码流。 - 为什么这等同于“共享权重”? 因为这 40 个样本被送进了同一个
unet的前向传播(Forward)中,它们不可避免地经过了完全相同的卷积层和线性层参数计算。 - 这种写法既避免了在内存中实例化两个庞大的网络模型,又利用并行计算加速了训练,完美契合了“统一语义空间”的设计初衷。
5.2 Our_Attention.py:核心创新“联合交叉注意力 (JCA)”的真面目
既然图像和掩码被拼在了一个 Batch 里,它们在普通的卷积层里是互不干扰的(因为卷积是在空间维度上操作)。**那么,它们是在哪里进行“双向交流”的呢?**答案就在 Our_Attention.py 文件中的 DualAttnProcessor 类。这是整个框架的灵魂。请看 DualAttnProcessor.__call__ 方法中的这段代码:
# 1. 拆分:把之前拼接在一起的 Batch 重新拆成图像和掩码两半
img_hidden_states, mask_hidden_states = hidden_states.chunk(2, dim=0)
# ================= 图像流的 JCA =================
# 图像的 Query 来自哪里?来自掩码的特征 (mask_hidden_states)!
img_query = attn.to_q(mask_hidden_states)
# 图像的 Key 和 Value 来自自身 (img_hidden_states)
img_key = attn.to_k(img_hidden_states)
img_value = attn.to_v(img_hidden_states)
# 计算注意力得分并更新图像特征
img_attention_probs = attn.get_attention_scores(img_query, img_key, None)
img_hidden_states = torch.bmm(img_attention_probs, img_value)
# ================================================
# ================= 掩码流的 JCA =================
# 掩码的 Query 来自哪里?来自图像的特征 (img_hidden_states)!
mask_query = attn.to_q_mask(img_hidden_states)
# 掩码的 Key 和 Value 来自自身
mask_key = attn.to_k_mask(mask_hidden_states)
mask_value = attn.to_v_mask(mask_hidden_states)
# 计算注意力得分并更新掩码特征
mask_attention_probs = attn.get_attention_scores(mask_query, mask_key, None)
mask_hidden_states = torch.bmm(mask_attention_probs, mask_value)
# ================================================
# 2. 合并:交流完毕后,再次在 Batch 维度拼接回去,继续后面的计算
hidden_states = torch.cat([img_hidden_states, mask_hidden_states], dim=0)
逻辑解析:
- 论文中的公式
Zt = CA(Yt, Zt, Zt)(用掩码 Yt 去引导图像 Zt 的生成)在这里得到了完美的数学复现。 - 代码中明确体现了:拿着对侧的特征去生成 Query(用来“提问”),拿着自己的特征去生成 Key 和 Value(用来“回答”)。
- 比如在更新图像特征时,模型实际上在计算:“基于当前掩码长什么样(Query),我应该从图像自身的特征(Value)中提取哪些部分来与之对齐?”。反之亦然。
5.3 Our_UNet.py:对 Diffusers 库的兼容性魔改
这份代码主要是魔改了 HuggingFace diffusers 库中标准的 UNet2DConditionModel。它的主要作用是提供一个基础的壳子,用来挂载上述的自定义注意力机制。
- 作者在里面保留了所有标准扩散模型所需的模块(时间步嵌入
time_embedding、编码器映射encoder_hid_proj等)。 - 这份代码的核心价值在于它的工程兼容性。由于它继承并模仿了标准库的接口,这使得 MedSegFactory 可以直接无缝加载现有 Stable Diffusion 的预训练权重(正如
tutorial_train.py中from_pretrained("runwayml/stable-diffusion-v1-5")所做的那样)。作者并不需要从头训练庞大的视觉大模型,而是站在巨人的肩膀上,只需训练 JCA 模块和微调相关层即可。
6.批判性分析
6.1 出彩之处
1. 极高生态兼容性下的“借力打力” 在医疗 AI 领域,从零开始训练一个生成模型成本极高。代码显示,作者没有试图从头手搓一个全新的双流网络,而是极其聪明地保留了 HuggingFace diffusers 库的标准 U-Net 接口,仅仅通过替换 AttentionProcessor 为 DualAttnProcessor 来实现核心创新。这使得模型可以直接加载 Stable Diffusion 1.5 强大的开源预训练权重。这种“四两拨千斤”的做法极大地降低了训练成本,并保证了图像生成的基础质量。
2. “大道至简”的权重共享 在传统的深度学习工程中,想要让两个平行的网络共享权重,通常需要写复杂的参数绑定(Parameter Tying)或者使用 Siamese Network 架构。而这份代码直接在数据输入前执行 torch.cat([images, masks], dim=0),用最朴素的张量拼接在数据层面“欺骗”了网络,让同一个网络不知不觉地处理了两条流。这种设计鲁棒、不易出错,且前向传播效率极高。
6.2 局限性
仔细推敲其代码逻辑,我们会发现以下几个核心痛点:
1. 显存刺客:严重的 VRAM 瓶颈 (Memory Bottleneck)
- 问题剖析:
torch.cat([images, masks], dim=0)意味着实际送入 U-Net 计算的张量 Batch Size 直接翻倍(例如设定的batch_size=8,实际前向传播是16)。 - 致命影响: 医疗图像(即使是 2D)通常也需要较高的分辨率才能保留病灶细节。Diffusion 模型的 U-Net 本身就是“显存大户”,现在特征维度在 Batch 上翻倍,再加上 JCA 引入的额外注意力矩阵计算,极易导致 GPU 显存溢出(OOM)。这限制了模型在高分辨率医疗数据上的应用,或者逼迫研究者只能使用极小的 Batch Size,从而影响训练梯度的稳定性。
2. 模态不对等带来的“特征互相拖累” (Modal Imbalance)
- 问题剖析: 图像(Images)包含极其复杂的解剖纹理、灰度渐变和噪声;而掩码(Masks)通常是极其简单、平滑的二值或多分类色块。
- 深度质疑: 让这两种信息熵差异巨大的数据 100% 共享 U-Net 的所有卷积核(从浅层到深层),真的是最优解吗?
- 掩码那半边的梯度回传,可能会迫使底层的卷积核学习“平滑、锐利边缘”的特征;
- 而图像那半边的梯度回传,又要求卷积核学习“复杂纹理”。
- 这种特征提取目标上的冲突,可能会导致网络容量(Capacity)的浪费,甚至在复杂病灶边缘生成上出现模糊(因为被掩码的平滑特性“中和”了)。更好的方案或许是:浅层特征提取独立,深层语义空间共享。
3. 硬编码导致扩展性差 (Poor Extensibility)
- 问题剖析: 在
DualAttnProcessor中,代码写死了img_hidden_states, mask_hidden_states = hidden_states.chunk(2, dim=0)。 - 局限性: 这种“一刀切两半”的做法非常 Hardcoded(硬编码)。如果未来的研究者想在图像和掩码之外,引入第三个引导流(例如:加入边缘检测图、或者另一模态如 PET),整个数据流和 Attention 机制的底层代码必须全部推翻重写。它是一个极度定制化的方案,缺乏框架级别的普适性。
4. 维度的降级:无法处理 3D 空间连续性
- 问题剖析: 代码库中使用的依然是
UNet2DConditionModel。 - 医疗痛点: 真正的 CT 或 MRI 扫描是 3D 的体素(Voxel)。2D 切片生成虽然容易套用现成的 SD 模型,但相邻切片之间缺乏物理和解剖学上的连续性(比如生成的肿瘤在上一层切片和下一层切片可能根本对不上)。只要模型仍然依赖这种基于 2D Batch 拼接的方法,它就无法真正解决临床级 3D 医疗数据合成的核心痛点。
总结
MedSegFactory 通过共享权重的双流架构与 JCA 机制,巧妙解决了医学图像合成中“缺标注”和“难对齐”的痛点 。这种将文本提示直接转化为成对可用数据的范式,为降低医学 AI 研发门槛提供了一个极具实用价值的基础工具。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)