【线程】:在并发的荒原上构筑秩序
前言:操作系统的最后一座大山:线程。本文一共5.6万字,这不仅是一份技术手册,更是我将操作系统理论“内化”为工程能力的一次极限长征。如果你也曾困惑于死锁的迷局,或是在高并发的竞态条件下如履薄冰,希望这篇全链路的复盘能为你拨开云雾。
目录
① 为什么 LogMessage 请求在 Logger 内部?
一、虚拟地址空间
1. struct page
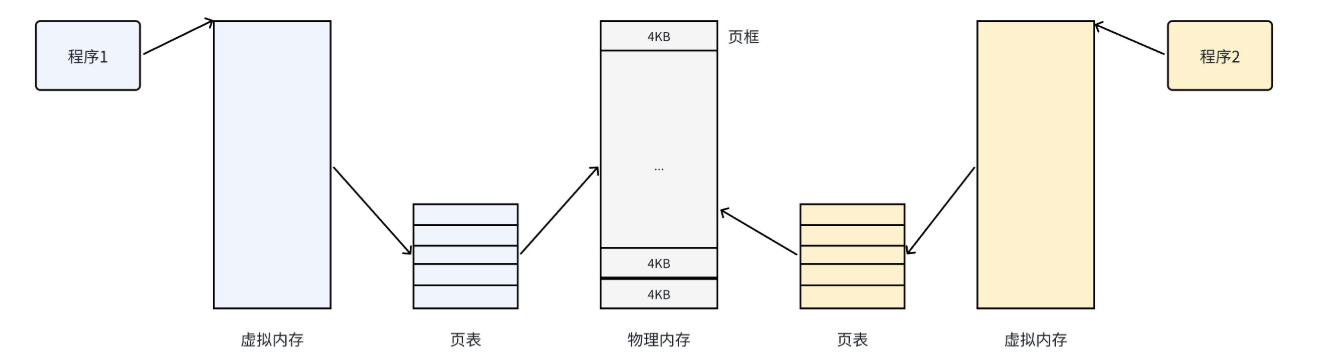
学习这个之前我们应该已经有了一些虚拟地址空间的基础了(之前讲过),我们先说我们常说的物理地址,物理内存是按照一个固定的长度的页框进行分割的,有时叫做物理页。而我们通常说的页是一个宏观概念,基础的意思是一个4KB的内存块,一个页的大小等于页框的大小。大多数32位体系结构支持 4KB 的页,而64位体系结构一般会支持 8KB 的页。
页 vs 页框
页 (Page):
所属层级:虚拟地址空间(逻辑层)。
定义:操作系统将虚拟内存划分为固定大小的连续块,通常为 4KB。
意义:它是 CPU 保护模式和 MMU(内存管理单元)管理内存的最小单位。
页框 (Page Frame / Physical Page):
所属层级:物理内存(硬件层)。
定义:物理内存被划分为与“页”大小完全相同的块。
关系:一个虚拟的“页”必须映射到一个物理的“页框”,程序才能真正存储数据。
页是“电影票上的座位号”(逻辑上的位置),页框是“影院里真实的椅子”(物理上的实体)。
在 Linux 内核中,每一个物理页框都有一个唯一的 struct page 结构体与之对应。 由于物理内存可能很大(如 64GB),而 struct page 数量极其庞大,为了节省空间,这个结构体被设计得极其精简且使用了大量的 union(联合体),它的大小一般有
// 文件: include/linux/mm_types.h
struct page {
// 1. 状态标志位: 原子操作,表示页面的各种状态 (如 PG_locked, PG_dirty, PG_lru)
unsigned long flags;
// 2. 引用计数: 表示内核中引用该页面的次数。为0时表示空闲,可被回收。
atomic_t _refcount;
// 3. 映射计数: 该页面被页表映射的次数 (PTE 数量)。
// -1 表示未映射;0 表示仅父进程映射。
atomic_t _mapcount;
// 4. 使用联合体来节省内存空间 (不同场景下字段含义不同)
union {
struct {
// 私有数据指针: 根据场景不同,可指向 buffer_head, swap_entry 等
unsigned long private;
// 地址空间映射:
// - 指向 address_space (文件页)
// - 若最低位为1,则指向 anon_vma (匿名页)
struct address_space *mapping;
};
// 其他场景: 如 SLUB 分配器使用时复用该内存区域
struct kmem_cache *slab_cache;
struct page *first_page; // 复合页的首页
};
// 5. 偏移量: 在映射中的偏移 (以页大小为单位的偏移量)
pgoff_t index;
// 6. LRU 链表节点: 用于页面回收算法 (active_list 或 inactive_list)
struct list_head lru;
// 7. 高端内存虚拟地址 (仅部分架构需要)
#if defined(WANT_PAGE_VIRTUAL)
void *virtual;
#endif
};(1)flags (状态标志位)
-
类型:
unsigned long -
作用:记录该页的状态。

-
地位:这是内核判断如何处理该物理内存的首要依据。
(2) _refcount (引用计数)
-
类型:
atomic_t -
作用:记录当前有多少个实体正在引用这个页框。当
_refcount为 0 时,说明没有人在用,内核可以回收它,对于多线程共享内存,多个执行流对应的页表项都会指向这里,计数会增加。
(3)mapping (映射关系)
-
类型:
struct address_space * -
作用:这是实现 文件缓存的核心。如果这个页是从磁盘文件读取的,
mapping就指向该文件对应的地址空间结构,这解释了为什么多个进程读取同一个动态库(.so)时,物理内存里只存一份:因为它们的虚拟页都指向了同一个mapping下的页框。
(4)index (页偏移)
-
作用:在
mapping指向的文件中,这一页处于文件的什么位置(第几个 4KB)。
(5)virtual (虚拟地址)
-
作用:记录该物理页框在内核空间中的虚拟地址(仅对部分内核页有效)。
men_map数组
men_map是 Linux 内核中一个全局的 struct page 数组,它是整个物理内存管理的核心数据结构。Linux 内核中,所有struct page存放在这个大数组里,即使每个结构体只有几十字节,在内存极大时也会消耗数百 MB。// 定义在 mm/page_alloc.c 中 struct page *mem_map; // 全局的 page 数组指针 // mem_map 是系统中所有物理页框的"户口本"物理页框号(PFN)与数组下标一一对应,第 n 个页框对应
mem_map[n]。这个数组在系统启动时就会根据物理内存总量一次性分配好,且永远驻留在物理内存中。什么是物理页框号,往下看!
2. 内存碎片问题
其实我们在前面已经讲过为什么要虚拟内存了,我们来具体讲一下内存碎片问题,内存碎片分为两种:外碎片(External Fragmentation)和内碎片(Internal Fragmentation)。
内碎片:拿到了,用不掉
-
现象:为了对齐或管理方便,系统分配给你的内存比你实际要求的多一点。
-
例子:你只需要 10 字节,但操作系统最小的分配单位是 4KB(一页)。剩下的 4086 字节就被白白浪费了,且别人也用不了。
-
危害:极大地降低了内存的有效利用率。
-
解决办法:SLAB / SLUB 分配器,内核会预先从系统申请一页,并将其切成固定大小的小块(如 32 字节、64 字节)。当你申请一个小对象时,直接从对应的 SLAB 链表里拿一个,即SLAB 负责“零售”(按字节给)。
外碎片:看得见,拿不到
-
现象:系统中有很多空闲的物理页框,但它们是散落在各处的。
-
例子:你需要 8 个连续的物理页来启动一个新线程,系统总共有 100 个空闲页,但由于中间被其他进程占用了,导致没有任何一处有连续的 8 个页。
-
危害:导致系统无法分配大块连续内存,即使剩余内存充足,程序也会报
Out of Memory。 -
解决办法:内核通过页表,把虚拟地址中连续的两个页(例如
0x08049000和0x0804A000),分别指向两个遥远的物理页框。
Buddy System 伙伴系统 (了解)
它是Linux内核中管理物理内存分配与回收的核心算法,将物理内存视为由2的幂次方大小(1页、2页、4页……直到最大阶)组成的块集合,每个大小的块都有一个空闲链表,同阶且地址连续的相邻两块互为“伙伴”。分配时,系统找到能满足需求的最小2的幂次块;如果没有空闲块,则从更大阶的块中分裂出一个块,一半用于分配,另一半作为新伙伴加入空闲链表。释放时,系统检查该块的伙伴是否也空闲,如果是则不断合并成更大的块,直到伙伴不空闲为止,从而有效减少外部碎片。
虚拟地址空间是解决内存碎片的终极武器。它通过页表的灵活映射,将物理上散乱分布的页框在逻辑上缝合为连续的线性空间,从而让程序员无需关心物理内存的破碎现状。然而,为了支持硬件 DMA 传输、提高大页分配效率以及优化页表遍历性能,内核依然依赖伙伴系统在物理层面尽可能维持内存的连续性。这两者的结合,既保证了程序运行的逻辑简洁性,又兼顾了底层硬件的执行效率。
应用层(C++)的碎片解决方法
(1)内存池 (Memory Pool):一次性
malloc一大块内存,自己内部管理。这避免了频繁调用系统接口产生的碎片,也是高性能 C++ 服务器的核心优化手段。(2)多线程内存分配器 (jemalloc / tcmalloc):为每个线程维护一个私有的本地缓存(Thread Cache)。线程申请小内存时不需要加锁,也不去全局堆里抢,直接在自己的缓存里拿。这既解决了多线程竞争,也通过精细的分级减少了碎片
3. 页表
我们以32位系统为例。
(1)页表项(PTE)
页表不仅仅记录地址,每个页表项通常有 32 位,即4字节,页表项是页表中的条目,其中包含大量权限和状态位:
-
物理页框号 (PFN):指向真实的物理地址。
-
有效位 (Present):标记该页是否已经在物理内存中。如果为 0,触发缺页中断(从磁盘调入内存)。
-
读写位 (R/W):标记该页是只读还是可读写
-
用户/超级用户位 (U/S):标记该页是用户态可见,还是仅内核态可见。
-
脏位 (Dirty):标记该页是否被写过。
(2)多级页表
如果把虚拟地址和物理地址一一映射,他需要多大的内存,我们来算一算:

这是一个进程需要的大小,那100个呢?这时我们就有了多级页表:
为了解决上述问题,Linux 将 32 位虚拟地址拆分成三段:10位 + 10位 + 12位。
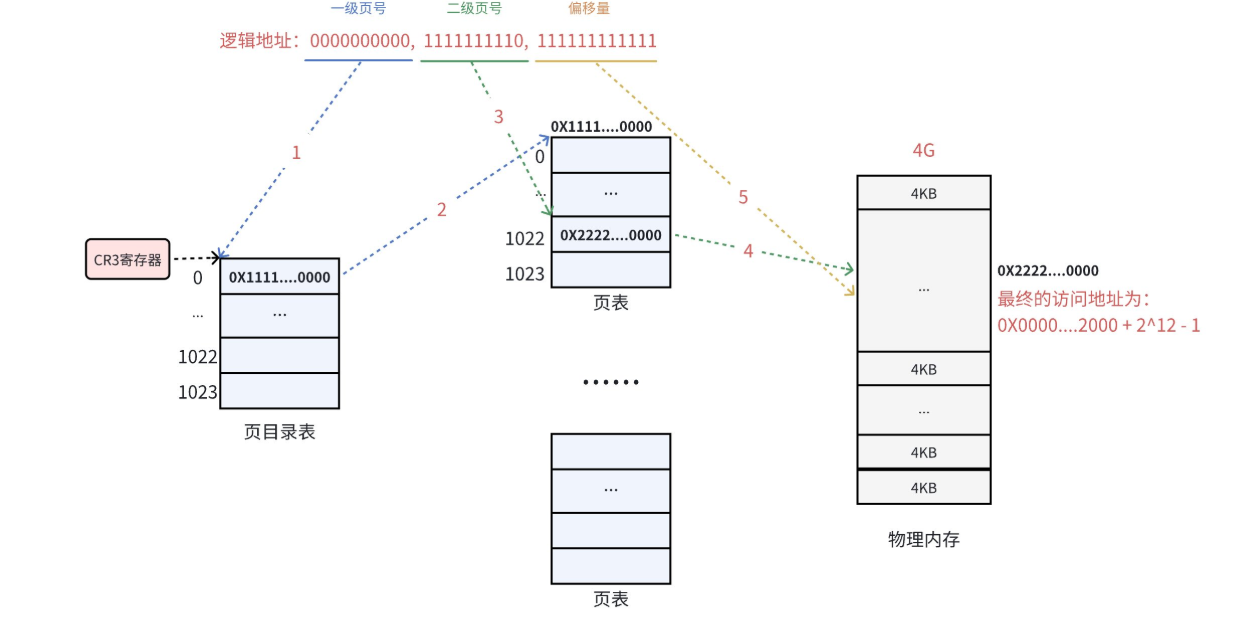
(1)第一级:页目录 (PD)
-
索引:虚拟地址的高 10 位(bit 22-31)。
-
内容:包含 1024 个页目录项 (PDE),它和页表项差不多。
-
作用:每个 PDE 指向一个“二级页表”的物理地址。页目录在进程的生命周期内是永远存在的,它是进程能够运行的最低限度的“不动产”。
-
大小:1024 * 4字节 = 4KB(正好占用一个物理页框)。
(2)第二级:页表 (PT)
-
索引:虚拟地址的中间 10 位(bit 12-21)。
-
内容:包含 1024 个页表项 (PTE)。
-
作用:每个 PTE 指向最终的物理页框地址。
-
大小:同样是 1024 * 4字节 = 4KB。这个页表是用哪个开哪个,一个页表能对应4MB的大小,但要是你的物理空间不在连续的4MB上,那就得开不只一个页表了。
(3)页内偏移 (Offset)
-
索引:虚拟地址的低 12 位(bit 0-11)。
-
作用:在 4KB 的物理页框内精准定位字节。
-
执行过程:① MMU 通过虚拟地址的高 20 位(页目录 + 页表),在 PTE(页表项)中提取出该页对应的物理页框起始地址(这可和虚拟地址的高20位没有关系,它是真正的物理地址的高20位),这个地址一定是 4KB 对齐的。② MMU 直接把虚拟地址的低 12 位拿出来,作为偏移量(Offset)。 ③ 将“物理页框起始地址”与“偏移量”进行相加。
PDE存的是二级目录的对应地址的前20位加权限位(12 bit),PTE存的是真实物理地址的前20位加权限位,因为它们是连续的,所以只要有偏移量,就一定能找到。64位下的系统也是此原理,只不过级数更多罢了。
CR3寄存器与MMU
CR3 (Control Register 3) 是 CPU 内部的一个核心控制寄存器,它在内存寻址中的地位至关重要。它保存着当前正在运行的进程的页目录的物理地址,每当 CPU 要翻译一个虚拟地址时,它的第一步动作就是:“看一眼 CR3 里的物理地址,跳到那个内存位置去读页目录的第一行”。每个进程都有自己独立的页目录,因此每个进程都有一个属于自己的 CR3 值。切换进程,本质上就是往 CR3 里写入一个新的物理地址。
MMU (Memory Management Unit) 是集成在 CPU 内部的一个硬件单元,它是虚拟内存到物理内存映射的执行者。它的作用就是转化地址与权限检查,就是我们上面的过程。
4. TLB缓冲机制
(1)原因
当我们深入到多级页表的底层时,你会发现一个残酷的现实:地址转换太慢了。在 32 位二级页表下,CPU 每读一个变量,都要先访问一次物理内存(页目录),再访问一次物理内存(页表),最后才能拿到数据。3 次内存访问换 1 个数据,性能直接打 3 折。为了解决这个“地址转换瓶颈”,硬件引入了 TLB (Translation Lookaside Buffer),中文常称为快表。
(2)概念
TLB 是集成在 CPU 内部(靠近 MMU)的一块高速缓存。它的结构非常简单,就像一个 Hash 表,存储的是最近使用过的虚拟页号 (VPN) 到 物理页框号 (PFN) 的映射关系,它基于程序的局部性原理(如果你访问了某个地址,你很有可能马上再次访问它或它附近的地址)。
(3)过程
第一步:查 TLB(命中检测) CPU 提取虚拟地址的高 20 位(以 32 位为例),直接在 TLB 硬件电路中搜索。如果TLB Hit (命中),直接拿到物理页框地址。总耗时几乎为 0。
第二步:查页表(TLB Miss) 如果 TLB 里没找到,MMU 只能老老实实去内存里走那套“页目录 -> 页表”的流程。
第三步:更新 TLB 当 MMU 终于从内存里找出了物理地址,它会顺手把这一对映射关系填入 TLB。如果 TLB 满了,就按照 LRU(最近最少使用)算法踢走一个旧条目。
(4)意义
TLB 是位于 CPU 内部的高速映射缓存,旨在跳过多级页表的多次内存访问,实现“一键转换”。它的存在极大地缓解了虚拟内存带来的性能损耗。对于 Linux 线程而言,由于共享页表导致的 TLB 持续有效性,是线程上下文切换开销远小于进程的关键硬件保障(后面说)。
5. 缺页异常
当我们谈论缺页异常(Page Fault)时,实际上是在谈论 Linux 内存管理中一个极其精妙的“骗局”:按需分配。内核为了节省物理内存,通常不会在程序启动时就把所有虚拟地址都映射到物理内存,而是等 CPU 真正访问那个地址“撞板”时,才急匆匆地去分配。
(1)缺页的触发
当 CPU 执行指令并尝试访问一个虚拟地址时,MMU 会自动启动地址翻译流程。但在以下两种底层场景下,硬件会强制按下“暂停键”,触发 14 号中断:
-
PTE 无效(Present 位 = 0):MMU 在遍历多级页表时,发现目标页表项(PTE)的高 20 位为空,或者有效位(Present)为 0。这意味着该虚拟地址在物理内存中暂无对应“房产”。
-
权限违规:MMU 发现 Present 位为 1,但当前指令的操作与页表项记录的权限冲突。
此时 CPU 会将导致异常的虚拟地址自动存入 CR2 寄存器,这是内核后续“修路”的核心依据。
(2)缺页的分类
① 匿名页缺页(Anonymous Page Fault)
-
场景:访问堆、栈、或是
malloc申请的内存。 -
处理:内核主动申请物理页框,更新页表映射。
② 文件页缺页(File-backed Page Fault)
-
场景:访问代码段、动态库或
mmap映射的文件。 -
处理:内核根据 VMA 中记录的文件信息和偏移量,启动磁盘 IO 将数据读入物理页框,再补全映射。
③ 写时拷贝缺页(COW Page Fault)
-
场景:
fork后的子进程尝试修改父进程共享的只读页面。 -
处理:内核申请新页框,拷贝原页内容,并将子进程页表指向新页,权限改为可写。
④ 交换缺页(Swap Page Fault)
-
场景:数据被置换到了磁盘 Swap 分区。
-
处理:内核从磁盘换回数据到内存。
(3)越界的检查
① VMA 范围检查
内核拿着 CR2 里的地址,在 mm_struct 的 VMA 红黑树中搜索。若地址不在任何 VMA 范围内:判定为真的越界。内核直接给进程发送 SIGSEGV 信号(段错误)。
② VMA 权限检查
即便地址在 VMA 内,内核还会对比访问行为(读/写/执行)与 VMA 预设的权限。比如,试图写代码段,虽然地址合法,但 VMA 标记为只读,依然触发段错误。
③ 页内越界(不会触发中断)
由于 MMU 以 4KB 为最小单位进行映射,如果你的数组越界但仍在同一个 4KB 页面内,MMU 会认为访问合法,不会触发缺页异常,这种越界不会报错,但会造成极其隐蔽的数据损坏。或者,如果你越界的地方,恰好落在了另一个合法的 VMA(比如另一个变量所在的区域)里,MMU 依然认为访问合法。
所以,这是内存管理的“惊天骗局”,虚拟内存是你老板PUA你的饼,你以为画了就会给你吗?但,只要将虚拟地址空间进行划分,进程资源就天然被划分好了,即使没有真正的物理空间。
6. 完整认知链路
第一阶段:软件建模(进程启动与布局)
当你在 Shell 中运行一个 C++ 程序时,内核并不是直接把程序塞进内存,而是先画了一张“大饼”:内核为进程创建一个 task_struct,其中的 mm 指针指向一个 mm_struct。这个结构体是该进程虚拟地址空间的“总管”,它记录了页表基址(pgd)和整个空间的概况。mm_struct 维护了一个链表,里面全是一个个的 vm_area_struct,每个 VMA 代表一段合法的虚拟地址范围(如:代码段、数据段、堆、栈、mmap 映射区),VMA 定义了“哪些虚拟地址是合法的”以及“这段地址能干什么”(只读、可写、可执行)。此时只分配了虚拟地址空间,页表项还是空的!
第二阶段:硬件挂钩(进程调度)
当 CPU 决定运行这个进程(或其下的某个线程)时,首先加载 CR3,内核从 mm_struct->pgd 中取出该进程页目录的物理地址,通过特权指令将其写入 CPU 的 CR3 寄存器。
第三阶段:硬件加速寻址(MMU 与 TLB)
CPU 执行指令 mov eax, [0x08049004]:
- MMU 介入:MMU 拿到虚拟地址
0x08049004。 - 快表查询 (TLB Hit):如果命中,直接拿到物理页框地址,叠加偏移量
0x004,瞬间完成访问。如果 TLB 没存,MMU 必须根据 CR3 指向的地址,去物理内存里老老实实地爬页表(查页目录 -> 查页表)。
第四阶段:撞墙与求助(缺页中断)
假设这是程序第一次访问这个地址,MMU 会发现页表项(PTE)是空的(Present = 0):
- 触发异常:MMU 停止工作,抛出 14 号异常(Page Fault)。
- 保存现场:CPU 把导致错误的虚拟地址
0x08049004存入 CR2 寄存器,并跳入内核的do_page_fault函数。 - VMA 合法性检查:内核作为“大法官”,拿着 CR2 里的地址去
vm_area_struct树里搜:如果地址不在任何 VMA 范围内则发送SIGSEGV(段错误)。地址在某个 VMA 范围内,但物理内存还没分,表明它是合法的 - 分配与映射:内核从物理内存池分配一个
struct page(页框),并在页表项中填入该物理地址,将Present位设为 1,并刷新 TLB
第五阶段:指令重执行
- 异常返回:内核处理完缺页,执行
iret返回用户态。 - 指令重试:CPU 再次执行
mov eax, [0x08049004]。 - 再次执行:这次 MMU 查页表发现 Present=1,物理地址就在那。数据通过总线被读入 EAX 寄存器。
- 之后就是我们上面所说的TLB和多级页表的过程了
二、认识Linux线程
1. 通用标准概念
| 概念 | 核心定义(操作系统) |
|---|---|
| 进程 | 承担系统资源分配的基本实体(地址空间、文件、信号等) |
| 线程 | CPU 调度的基本单位(指令流、栈、寄存器) |
| 概念 | 核心定义(Linux) |
|---|---|
| 进程 | PCB + 程序代码 |
| 线程 | 进程内部的一个执行分支 |
2. 从地址空间理解线程(重点)
(1)和进程的地址空间对比
当你启动一个进程时,系统会为它分配一套完整的、私有的虚拟地址空间。页表是私有的,进程 A 的地址 0x1234 与进程 B 的 0x1234 映射到完全不同的物理内存。进程间无法直接看到对方的代码段、堆、数据段等。
而线程并不拥有自己独立的虚拟地址空间。相反,同一进程内的所有线程共用同一个页表,看到的是同一份地址空间。
哪些是共享的?
-
代码段:所有线程执行同一个可执行文件中的指令,可以调用相同的函数。
-
已初始化/未初始化数据段:全局变量是线程间通信最快的方式,因为它们在地址空间中只有一份,任一线程修改,其他线程立刻可见。
-
堆:
malloc或new申请的空间对所有线程开放,前提是你持有指向该空间的指针。 -
共享库与文件描述符:打开的文件在地址空间中也是共享的。
哪些是独占的?
虽然页表是共享的,但为了保证线程能独立运行,地址空间会被“划区”:
-
栈:这是最核心的区别。在进程的地址空间中,每个线程都会被分配一块独立的栈区。主线程通常使用原生的进程栈。新线程的栈通常由
pthread库在进程的共享区(mmap 区域)中动态申请。独立栈保证了线程在进行函数调用时,局部变量、返回地址不会相互覆盖,但又因为是在共享区的一块区域,你要非要去访问,那也没招。 -
寄存器与程序计数器:这些属于 CPU 上下文,不属于地址空间的存储,但决定了线程在地址空间中“正站在哪行代码上”。
(2)Linux下的线程
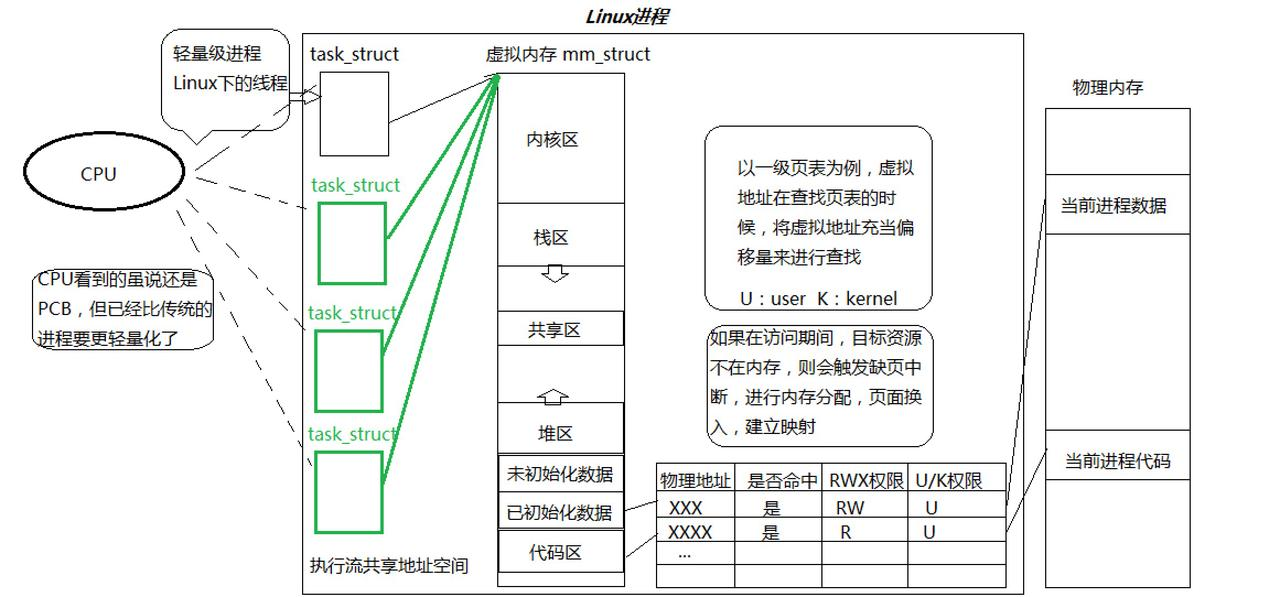
在 Linux 内核中,进程和线程都由 task_struct 表示。进程拥有独立的 mm_struct(内存描述符),指向一套独立的页表,而线程是多个 task_struct 里的 mm 指针指向同一个 mm_struct。这就解释了为什么 Linux 称线程为“轻量级进程(LWP)”:它们在调度上和进程一模一样,只是在访问内存时,大家“看的是同一张地图”。这种“偷懒”的设计让内核调度器非常简洁——它只需要调度 task_struct 即可,不管它是进程还是线程。
其他操作系统的线程实现方式
与 Linux 的“轻量级进程”哲学不同,Windows 等操作系统通常采用更严格的实体分离模型:在 Windows 内核中,进程仅作为资源容器(容器),而线程作为调度与执行的唯一单位(实体)被独立管理。这种设计导致线程创建时的上下文和属性极其复杂,系统调用开销相对较大;而早期某些系统如 Solaris 曾采用过将用户态线程多对多映射到内核线程的 M:N 模型,虽然理论上更灵活,但因调度复杂度过高,目前主流系统大多已回归到 1:1 模型,即每个用户级线程直接对应一个内核级执行实体,以简化调度并充分发挥多核性能。
(3)虚拟内存的本质
从代码区划分来看,线程为什么能精准执行对应的函数?本质上,函数就是虚拟地址空间中一段连续虚拟地址的集合! 当我们为一个线程分配任务时,实际上是在 vm_area_struct 划定的合法区域内,赋予了该执行流访问特定地址段的权利。
执行流看到的资源,本质上是在合法情况下拥有的虚拟地址范围,虚拟地址就是资源的代表! 虚拟内存通过 mm_struct 与 vm_area_struct 实现了对资源的统计与整体数据建模,而页表则充当了从虚拟到物理的映射地图。基于此,线程的资源划分本质上是划分地址空间,使执行流获得一定范围的合法虚拟地址,其核心操作就是在划分页表;而线程的资源共享本质上是对虚拟地址空间的共用,其核心操作就是对页表条目的共享。在 Linux 下,地址空间 = 资源总和。
3. 线程的优缺点
(1)线程切换
线程切换(Thread Switching)对比进程切换,它最核心的特点就是:“换人不换场”。你想想,一台戏只是换个演员继续演,和把场子拆了换戏演,哪个快,不是一个量级好吧。
① 线程切换不切什么
进程切换:切页表,必须将新的物理页目录地址写入 CR3 寄存器。一旦 CR3 改变,CPU 硬件缓存 TLB 就会自动失效,MMU 必须重新去物理内存里漫游页表,这会导致接下来的指令执行变得极慢。
线程切换:不切页表,由于同一进程下的线程共享同一个 mm_struct,它们的页表是同一套。CR3 不动,内核发现新旧线程的 mm 指针相同,干脆不刷新 CR3。因为地址空间没变,TLB 里的缓存依然有效。这种对硬件缓存的保护,是线程切换高效的根本原因。
② 线程切换切什么
-
CPU 寄存器:包括通用寄存器、栈指针和指令指针等,其实就是上下文。
CPU 内的寄存器硬件虽然只有一套,但其承载的数据(上下文)却是执行流私有的。线程切换的本质,就是一场关于物理寄存器所有权的‘快照存取’,将前者的现场封存在内存,将后者的记忆唤醒至硬件。即虽然大家在同一个办公室(地址空间)工作,但每个人手里的活儿(执行到哪一行代码)和私人笔记本(寄存器里的中间变量)是不一样的。这句话是之后理解互斥锁的关键。
-
内核栈:每个线程在内核态都有自己独立的栈空间,用于保存进入内核后的函数调用链。
(2)线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 线程之间的切换很快(主要)
- 线程占用的资源要比进程少
- 能充分利用多处理器的可并行数量
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作
计算密集型应用(如视频转码、科学计算)主要消耗 CPU 算力,其线程数应接近 CPU 核心数,设置过多反而会因频繁切换上下文(保存/恢复寄存器快照)导致性能下降;而 I/O 密集型应用(如网络请求、数据库查询)主要消耗时间在等待数据传输,CPU 大部分时间处于空闲,应设置较多线程,以便在一个线程阻塞等待数据时,其他线程能利用 CPU 继续计算,从而最大化整体并发效率。
(3)线程的缺点
- 性能损失:一个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
- 健壮性降低:编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
- 缺乏访问控制:进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
- 编程难度提高:编写与调试一个多线程程序比单线程程序困难得多
(4)线程的用途
合理的使用多线程,能提高CPU密集型程序的执行效率,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)。
4. 线程异常的处理
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
5. 线程与进程对比
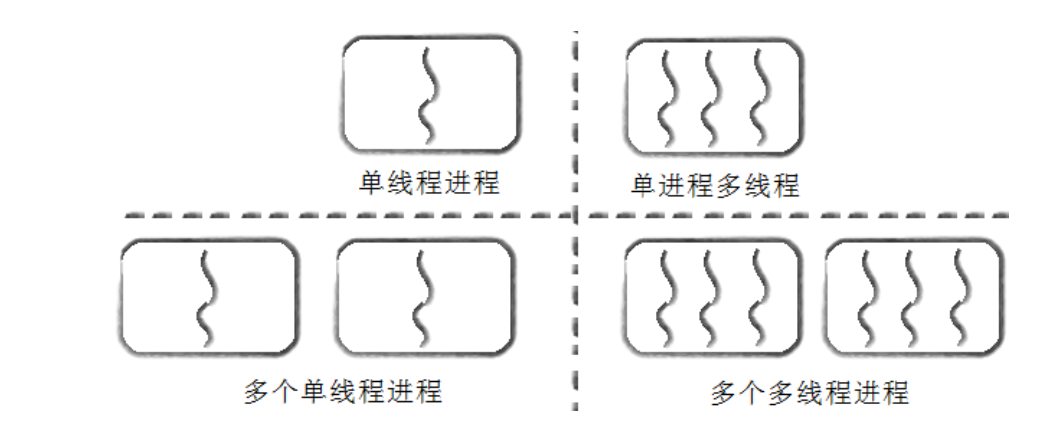
其实,我们以前说的进程,就是具有一个线程执行流的进程。
| 维度 | 进程 | 线程 |
|---|---|---|
| 本质定义 | 资源分配的基本单位 | 程序执行/调度的基本单位 |
| 地址空间 | 互不侵犯:拥有独立的 mm_struct 和页表 |
同舟共济:共享同一个 mm_struct 和页表 |
| 硬件标记 | 切换时必须刷新 CR3 寄存器 | 切换时 CR3 不动(TLB 缓存保持温热) |
| 创建开销 | 重:需要复制完整的资源描述符 | 轻:仅需创建 task_struct 并共享资源 |
| 通信方式 | IPC 机制(管道、信号量、共享内存等) | 直接读写:通过全局变量、堆内存直接交流 |
| 健壮性 | 高:一个崩了不影响别人 | 低:一个段错误(SIGSEGV)全家带走 |
三、Linux线程控制
1. POSIX线程库
在 Linux 内核眼中,只有轻量级进程(LWP),没有所谓的“线程”。我们写的多线程代码,依赖的是用户态的 POSIX 线程库(libpthread.so)。
这是一个用户态的动态库。它在底层调用了 clone() 系统调用生成 LWP,并在用户态维护了线程的管理架构。Linux 目前主流的实现叫 NPTL(Native POSIX Thread Library),实现了用户态线程与内核 LWP 的 1:1 映射。
它使与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的,要使用这些函数库,要通过引入头文件 <pthread.h>,链接这些线程函数库时要使用编译器命令的“-lpthread”选项。
2. 创建线程
(1)pthread_create
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);-
thread:输出型参数。用来接收新创建的线程 ID(tid)。注意,这个 ID 是用户态的地址,不是内核的 LWP ID。(后面讲) -
attr:线程属性(如栈大小、分离状态等),通常传nullptr用默认值。 -
start_routine:函数指针,线程启动后要执行的入口函数。注意返回类型和参数都是void*,这是 C 语言的泛型机制,意味着你可以传任何对象的指针进出。 -
arg:它会被原封不动地传递给start_routine。如果你想传多个参数,就在堆上new一个结构体,把结构体指针作为arg传进去。 -
返回值:如果是int,大多数都是成功返回0,失败返回错误码。
(2)使用PS命令查看线程信息
当你把程序跑起来后,可以用 ps -aL 或 top -H -p <PID> 来观察。
-
你会看到
PID(进程 ID)和LWP(轻量级进程 ID)两列。 -
主线程的
PID和LWP是相同的;而新创建的线程,PID与主线程相同,但拥有自己独立的LWP号。内核调度器就是看LWP来分配 CPU 时间片的。

3. 线程终止
(1)直接return
在线程入口函数中直接 return 是最常见的做法。return 的那个指针会被系统保存起来,等待主线程来拿。(绝对不能 return 线程栈上的局部变量指针,因为线程一结束,栈就被销毁了,指针会变成野指针!)
(2)pthread_exit
void pthread_exit(void *retval); 随处可用的“自刎”函数。即使你在深层的函数调用栈里,只要调用它,当前线程立刻终止,并交出 retval 作为遗言。注意:如果在主线程中调用 pthread_exit,主线程会终止,但只要还有其他子线程在跑,进程就不会退出。
(3)pthread_cancel
int pthread_cancel(pthread_t thread); “他杀”函数。主线程可以通过 tid 强行取消某个目标线程。被取消的线程,其退出码会被宏定义设定为 PTHREAD_CANCELED(通常是 -1)。
4. 线程等待
(1)等待原因
和进程需要 waitpid 避免产生僵尸进程一样,默认创建的线程是 Joinable(可汇合的)。这意味着线程结束后,虽然它的代码跑完了,但它在虚拟内存中占用的线程栈和局部存储等资源并没有被释放。如果不等待,会导致严重的内存泄漏。同时,等待也是一种天然的同步机制,保证主线程在子线程干完活之后再继续。
(2)pthread_join
int pthread_join(pthread_t thread, void **retval);-
thread:你要等哪个线程,交出它的tid。 -
retval:这是一个二级指针。因为子线程return的是一个void*(一级指针),为了把这个指针的值写回到主线程的变量里,主线程必须提供一个void*变量的地址。这就是经典的“解引用修改本体”逻辑。
5. 分离线程
(1)如何理解分离操作
有些时候,主线程根本不关心子线程的死活和返回值(比如一个后台常驻的日志清理线程)。此时再让主线程去 join 就会造成不必要的阻塞。分离(Detach) 就是告诉系统:“这个线程我不管了,它死后请操作系统立刻自动回收它的所有 VMA 和内存资源。”
(2)pthread_detach
int pthread_detach(pthread_t thread); 子线程可以自己分离自己:pthread_detach(pthread_self());。一旦分离,主线程再调用 pthread_join 就会直接报错返回。
6. 获取线程名
#include <pthread.h>
int pthread_setname_np(pthread_t thread, const char *name);
int pthread_getname_np(pthread_t thread, char *name, size_t len);| 函数 | 作用 | 返回值 |
|---|---|---|
pthread_setname_np |
设置线程名称 | 成功返回 0,失败返回错误码 |
pthread_getname_np |
获取线程名称 | 成功返回 0,失败返回错误码 |
它们两都需要tid,所以只能在线程启动后命名,所以一般是线程内部自己改。
7. demo测试
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
#include <cstring>
using namespace std;
// 线程参数结构体
struct ThreadData
{
int id;
std::string name;
};
void *thread_routine(void *arg)
{
ThreadData *td = static_cast<ThreadData *>(arg);
// 这是想把自己想要参数传进来的常用方法
// 内部改名,线程名最长16个字节
pthread_setname_np(pthread_self(), td->name.c_str());
// 分离Thread_1
if (td->id == 1)
{
pthread_detach(pthread_self());
std::cout << "[Notice] " << td->name << " has detached itself." << std::endl;
}
for (int i = 0; i < 5; ++i)
{
char actual_name[16];
// 获取当前线程的名称 (内核维护在 task_struct 中)
pthread_getname_np(pthread_self(), actual_name, sizeof(actual_name));
std::cout << actual_name
<< " | Logic ID: " << td->id
<< " | Loop: " << i << std::endl;
sleep(1); // sleep 是一个经典的取消点 (Cancellation Point)
}
std::cout << td->name << "退出" << std::endl;
delete td;
return nullptr;
}
int main()
{
const int NUM_THREADS = 5;
std::vector<pthread_t> tids(5); // 多线程用vector来维护
for (int i = 0; i < NUM_THREADS; ++i)
{
// 在堆上为每个线程申请独立空间,避免主线程栈上的 i 发生竞态
ThreadData *td = new ThreadData;
td->id = i;
td->name = "Worker_" + std::to_string(i);
pthread_create(&tids[i], nullptr, thread_routine, td);
}
sleep(1);
std::cout << "取消 tids[0]" << std::endl;
pthread_cancel(tids[0]);
// 演示 pthread_join
for (int i = 0; i < NUM_THREADS; ++i)
{
// 已经 detach 的线程不能 join,否则会报错
if (i == 1)
{
std::cout << "Thread_1 is detached." << std::endl;
continue;
}
void *retval;
int res = pthread_join(tids[i], &retval);
if (res == 0)
{
if (retval == PTHREAD_CANCELED)
std::cout << "Thread_" << i << " was terminated by cancel." << std::endl;
else
std::cout << "Thread_" << i << " reaped successfully." << std::endl;
}
}
return 0;
}
当
pthread_cancel执行时,目标线程会收到一个信号。它会在最近的取消点(如sleep、read等)退出。如果delete td;在sleep之后,线程一旦在sleep期间被取消,它就永远没有机会执行delete了,那块堆内存(ThreadData对象)就变成了“孤儿”,直到进程退出前都无法被释放,这就是内存泄漏。可以用RALL解决,我们的代码没有解决这个问题。
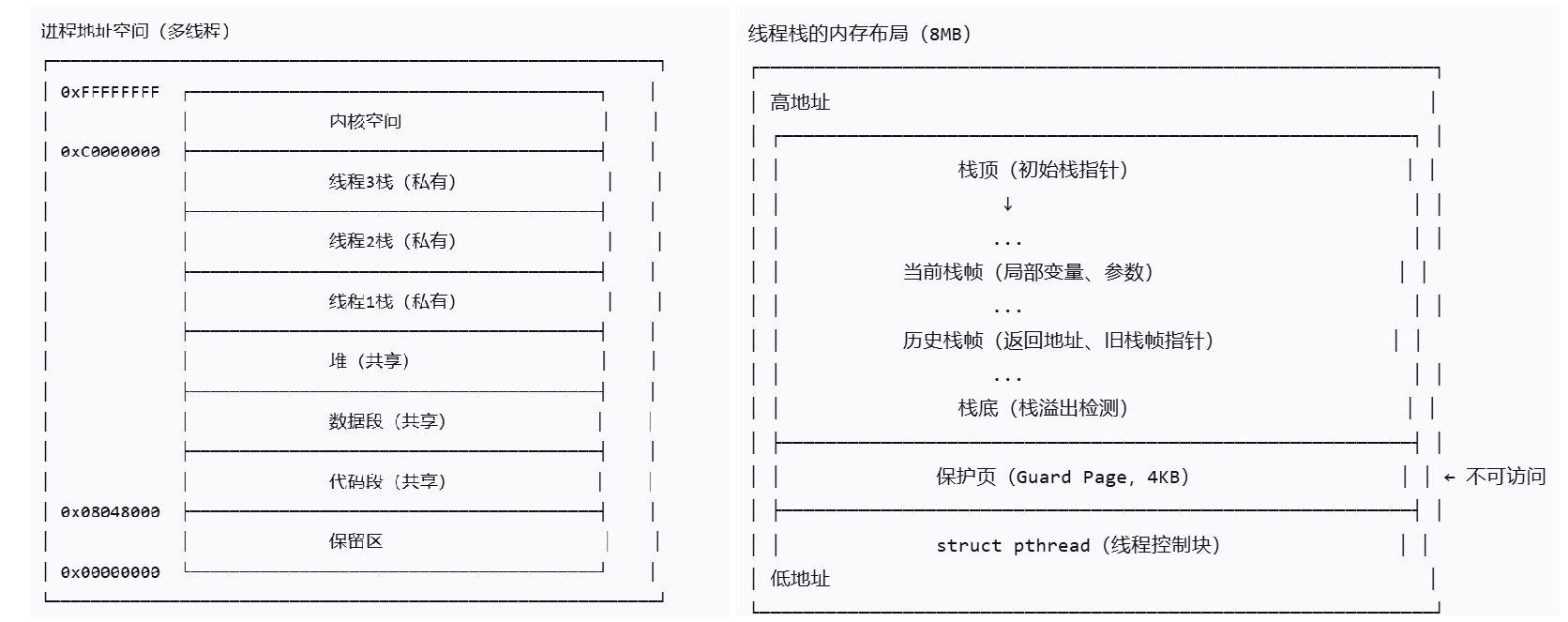
四、线程ID及进程地址空间布局
1. struct pthread
(1)空间布局
当我们调用 pthread_create 时,libpthread.so 库会在进程地址空间的 共享区中,通过 mmap 划出一块巨大的内存。这块内存不仅包含子线程的栈(Stack),还包含了这个线程的“身份卡”struct pthread 控制块。它就像PCB一样,但它是用户层的,
-
布局顺序:通常在这一块
mmap内存的最顶端(高地址处)存储着struct pthread结构体,紧接着下方就是该线程私有的栈空间。 -
pthread_t tid:你在代码里拿到的pthread_t tid,本质上就是指向这块内存起始位置的指针(即struct pthread*),它也是用户层的,内核真正用的使LWP。
(2)pthread_self()
pthread_self() 返回当前线程的线程 ID(pthread_t 类型),用于在线程内部标识自己。
#include <pthread.h>
#include <stdio.h>
void* thread_func(void* arg) {
// 获取当前线程的 ID
pthread_t tid = pthread_self();
// 打印(注意:pthread_t 可能不是整数,需要转换)
printf("Thread ID: %lu\n", (unsigned long)tid);
return NULL;
}
int main() {
pthread_t thread;
pthread_create(&thread, NULL, thread_func, NULL);
pthread_join(thread, NULL);
return 0;
}(3)与各个函数的关系
| 函数 | 操作 struct pthread 的逻辑 |
|---|---|
pthread_create |
在共享区 mmap 一块内存,初始化 struct pthread,把指针地址填入 tid 参数。 |
pthread_self |
这是一个非常精妙的操作。通过段寄存器(如 fs)直接定位到当前线程在共享区的 struct pthread 起始地址并返回。 |
pthread_join |
阻塞等待目标结构体中的状态变为“已退出”,去 tid 指向的内存块里,把 result 成员的值拷贝给 ptr。 |
pthread_detach |
将结构体中的状态标记为 DETACHED。这样线程退出时,库会自动调用 munmap 回收整块内存(包括结构体本身)。 |
pthread_cancel |
设置结构体内的 cancel_pending 标志位,并向该 LWP 发送信号。 |
2. 线程局部存储
线程局部存储(TLS) 是每个线程私有的全局变量——同一个变量名,在不同线程中指向不同的内存地址,互不干扰。
// 普通全局变量:所有线程共享
int global_counter = 0; // 所有线程看到的是同一个
// 线程局部存储:每个线程私有
__thread int tls_counter = 0; // 每个线程有自己的副本 加了该关键字的变量,编译后会被存放在 struct pthread 结构体内部的 TLS 区域中。这意味着,虽然变量名一样,但因为每个线程的 tid 地址不同,它们访问的 TLS 物理内存也完全隔离。
局部变量是线程的‘私人笔记本’,转瞬即逝;TLS 则是线程的‘私人保险柜’,持久且高效。当我们需要跨越函数的边界,在整个线程运行周期内保持状态,同时又想避开锁的竞争时,TLS 就是高性能并发编程中唯一不需要付出额外代价的‘上帝视角’。
3. 线程栈
线程栈 是每个线程私有的内存区域,用于存储:函数调用时的局部变量,函数参数,返回地址,函数调用上下文(栈帧)等。
| 维度 | 进程主栈 | 线程栈 |
|---|---|---|
| 创建者 | 内核创建进程时分配 | pthread 库分配(用户态) |
| 大小 | 通常 8MB(可配置) | 默认 8MB(可配置) |
| 位置 | 地址空间底部(高地址) | 地址空间中间(可分散) |
| 增长方向 | 向下增长 | 向下增长 |
| 共享性 | 主线程独占 | 每个线程独占 |
五、线程封装
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>
#include <functional>
namespace ThreadModule
{
class pthread
{
public:
using func_t = std::function<void()>;
pthread(func_t fun, std::string name = "")
: _tid(0), _isrunning(false), _isdetach(false), _fun(fun)
{
_name = "pthread_" + name;
}
bool Start()
{
if (_isrunning)
return false;
int n = pthread_create(&_tid, nullptr, Routine, this);
if (n == 0)
{
_isrunning = true; // 由主线程在启动成功后立即修改
return true;
}
return false;
}
bool Cancel()
{
if (!_isrunning)
return false;
int n = pthread_cancel(_tid);
if (n != 0)
return false;
else
{
_isrunning = false;
return true;
}
}
void Join()
{
if (_isrunning && !_isdetach)
{
pthread_join(_tid, nullptr);
_isrunning = false;
}
}
void Detach()
{
if (_isrunning && !_isdetach)
{
pthread_detach(_tid);
_isdetach = true;
}
}
std::string GetName() const { return _name; }
~pthread()
{
}
private:
pthread_t _tid;
bool _isrunning;
bool _isdetach;
func_t _fun;
std::string _name;
static void *Routine(void *args)
{
pthread *self = static_cast<pthread *>(args);
pthread_setname_np(self->_tid, self->GetName().c_str());
self->_fun();
self->_isrunning = false;
return nullptr;
}
};
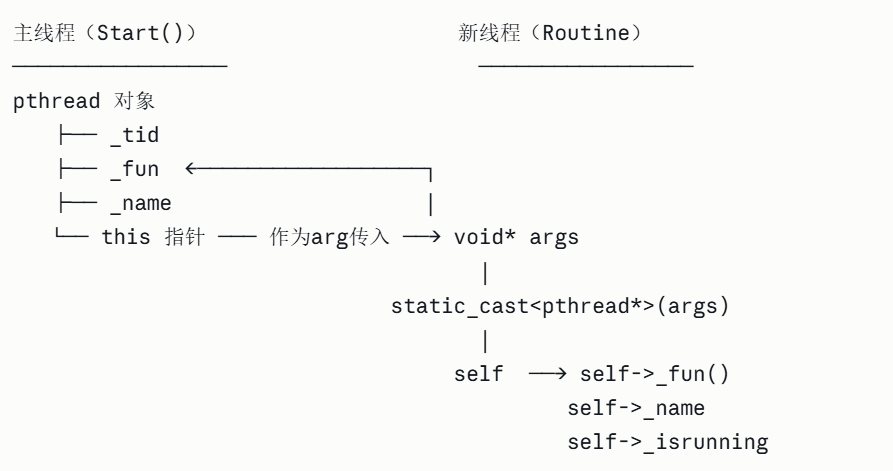
}pthread_create(&_tid, nullptr, Routine, this); 中的this指针怎么理解?
pthread_create是C函数,它不认识C++的成员函数和this,但线程函数必须是签名为void*(void*)静态函数或普通函数。但我们又想在线程里调用_fun()(一个成员变量),怎么办?把this作为参数偷渡入口!
为什么
Routine必须是static?普通成员函数的真实签名是
void*(MyClass*, void*),不符合pthread_create要求的void*(void*),所以必须用static,再手动把this传进去。
六、线程互斥
1. 问题引入
(1)现象查看
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100; // 共享资源:100张票
void *route(void *arg)
{
char *id = (char*)arg;
while (1) {
if (ticket > 0) {
usleep(1000); // 模拟售票耗时,放大问题
printf("%s sells ticket:%d\n", id, ticket);
ticket--;
} else {
break;
}
}
return NULL;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
return 0;
}
(2)概念复习
在IPC那部分我们阐述过的定义:
-
临界资源:像
ticket这种被多个执行流共享访问的资源。 -
临界区:代码中访问临界资源的那一部分逻辑(即
if (ticket > 0)到ticket--这段代码)。 -
原子性:一个操作要么完全不执行,要么执行完毕,绝对不会被任何调度机制在中间打断。
-
互斥:在任何时刻,只允许一个执行流进入临界区访问临界资源。
(3)原因深剖
为什么代码会失控?本质是因为我们高估了高级语言的原子性。
① --操作没有原子性的原因
在 C++ 层面看,ticket-- 只是一行代码。但在 CPU 看来,这是一组复杂的操作。我们可以理解为一条汇编一定是原子性的,把它转化为三条汇编指令:
- Load(读):将内存中
ticket的值读入 CPU 寄存器(如mov eax, [ticket])。 - Update(改):在 ALU(算术逻辑单元)中将寄存器的值减 1(如
sub eax, 1)。 - Store(写):将寄存器里的新值写回内存(如
mov [ticket], eax)。
致命缺陷:由于线程的调度是受操作系统控制的,一个线程极有可能在执行完第一步(刚把 100 读进寄存器)时,时间片耗尽被强行切走。此时它的上下文(带着寄存器里的 100)被保存。接着第二个线程飞速执行了三步,把内存里的 ticket 改成了 99。当第一个线程恢复执行时,它会拿着旧数据继续减 1,然后把 99 再次写回内存。100 减了两次,结果还是 99,这就发生了数据覆盖。
② if和usleep造成的问题
usleep(1000) 在这里模拟了真实的业务耗时(比如查库、网络延迟),它是一个极其危险的让权操作。 假设现在只剩最后 1 张票(ticket = 1):
-
thread 1判断ticket > 0成立,进入if,随即执行usleep进入睡眠,交出 CPU。 -
此时
thread 2获得时间片,它看到的ticket依然是 1,判断成立,也进入if并睡眠。 -
等它们相继醒来时,都会无条件执行
ticket--。第一条线程把票减到 0,第二条线程就会把票减到 -1。这就是缺乏互斥机制导致的并发灾难。
2. 互斥量mutex
既然临界区像一个毫无防备的房间,我们就需要给它装上一把锁。POSIX 线程库提供了互斥量(Mutex)机制。
① 初始化锁:
-
静态分配:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;(通常用于全局锁)。 -
动态分配:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);(用于堆上或局部的锁)。
② 加锁(Lock):int pthread_mutex_lock(pthread_mutex_t *mutex);如果锁是自由的,线程将其锁定并继续执行。如果锁已经被其他线程占用,当前线程会被阻塞(挂起等待),直到锁被释放。
③ 解锁(Unlock):int pthread_mutex_unlock(pthread_mutex_t *mutex);归还锁的所有权,并唤醒在等待队列中的某个线程。锁释放后,内核会从该锁对应的等待队列中唤醒一个线程(通常是等待最久的或优先级最高的),但该线程仍需与其它活跃线程竞争,不保证一定能抢到。
④ 销毁锁:int pthread_mutex_destroy(pthread_mutex_t *mutex);(静态初始化的锁不需要销毁)。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
int ticket = 100;
// 1. 定义并初始化全局互斥锁
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
void *route(void *arg)
{
// pthread_mutex_t mutex;
// 局部定义必须显式初始化
//pthread_mutex_init(&mutex, NULL);
char *id = (char*)arg;
while (1)
{
// 2. 加锁:进入临界区之前,必须先申请锁
// 如果锁被别人占用,线程会在这里阻塞挂起(等待)
pthread_mutex_lock(&mtx);
if (ticket > 0) {
usleep(1000); // 模拟业务耗时
printf("%s sells ticket: %d\n", id, ticket);
ticket--;
// 3. 解锁:操作完临界资源后,必须立即释放锁
pthread_mutex_unlock(&mtx);
}
else {
// 4. 陷阱提示:如果判断失败准备退出,也必须记得解锁!
// 否则该线程带着锁退出,其他线程会陷入永久死锁。
pthread_mutex_unlock(&mtx);
break;
}
// 适当让出CPU,防止一个线程靠着刚释放锁的优势立刻再次抢到锁
usleep(10);
}
//局部释放:pthread_mutex_destroy(&mutex);
return NULL;
}
int main(void)
{
pthread_t t1, t2, t3, t4;
pthread_create(&t1, NULL, route, (void*)"thread 1");
pthread_create(&t2, NULL, route, (void*)"thread 2");
pthread_create(&t3, NULL, route, (void*)"thread 3");
pthread_create(&t4, NULL, route, (void*)"thread 4");
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_join(t3, NULL);
pthread_join(t4, NULL);
// 5. 销毁锁(如果是 PTHREAD_MUTEX_INITIALIZER 初始化的全局锁,其实可以不手动销毁)
pthread_mutex_destroy(&mtx);
return 0;
}3. 互斥量实现原理探究
lock:
movb $0, %al # 1. 线程先在自己的私有寄存器 %al 里放一个 0
xchg %al, mutex # 2. 【核心】原子交换寄存器和内存 mutex 的值
if(al寄存器的内容 > 0){ # 3. 如果换回来的是 1,说明抢锁成功!
return 0; # 成功返回,进入临界区
} else { # 4. 如果换回来的还是 0,说明锁早被别人抢走了
挂起等待... # 乖乖去排队
goto lock; # 被唤醒后重新尝试
} 锁本身也是一个被多线程共享访问的全局变量,那谁来保护锁的安全? 如果“加锁”这个动作本身不是原子的,那锁就毫无意义。为了实现绝对的原子性,操作系统求助于硬件体系结构,以 x86 架构为例,CPU 提供了一条特殊的指令:xchg(或 swap)。这条硬件指令可以在一个总线周期内,原子性地交换内存和寄存器中的值。
我们可以用上面那个伪汇编来深刻理解加锁的底层逻辑:
- 规定内存中的
mutex变量为1代表锁空闲,为0代表锁被占用。 - 当线程尝试加锁时,它首先把自己的 CPU 寄存器(如
%al)清零(值为 0)。 - 接着,执行指令:
xchg %al, mutex(交换寄存器和内存的值)。 - 验证结果:如果交换后,寄存器
%al变成了 1,说明这根线程成功把内存里的 1 拿到了自己手里,而把 0 留在了内存里。加锁成功,进入临界区。如果交换后,寄存器%al依然是 0,说明内存里的值早就是 0 了,锁被别人拿走了。此时线程将自己挂起,等待被唤醒。
寄存器是线程私有的上下文,而内存是线程共享的。
xchg指令的伟大之处,就在于它原子地把一个共享的标记(锁),变成了一个线程私有的标记。就是你只要拿到了,同时证明了你也一定执行完了第一条语句,这是这个1就是你的,谁都拿不走自己也不会变,除了你自己释放。由于这条指令由硬件锁定了系统总线,任何调度器和中断都不可能在交换的过程中插入,从而在物理层面上保证了互斥的根基。
4. 互斥量的封装
#pragma once
#include <pthread.h>
namespace ThreadModule
{
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_mutex, NULL);
}
~Mutex()
{
pthread_mutex_destroy(&_mutex);
}
void Lock()
{
pthread_mutex_lock(&_mutex);
}
void Unlock()
{
pthread_mutex_unlock(&_mutex);
}
pthread_mutex_t *Get()
{
return &_mutex;
}
private:
pthread_mutex_t _mutex;
};
class LockGuard
{
public:
LockGuard(Mutex &mutex)
: l(mutex)
{
l.Lock();
}
~LockGuard()
{
l.Unlock();
}
private:
Mutex &l;
};
}注意点:
这就是RAII 风格的锁,但在是实现时一定要注意LockGuard传入的锁要引用!一定要保证一直是一把锁,在 C++ 多线程编程中,Mutex 是具有‘唯一性’的系统资源,本质上是不允许拷贝的。如果 LockGuard 错误地使用了值传递,就会导致每个线程都在锁‘虚空中的副本’,从而让本该互斥的代码块变成了‘裸奔’状态。这不仅会导致条件变量失效导致死锁,更会引发严重的线程安全问题。
七、线程同步
1. 条件变量
(1)问题引入
在售票系统中,如果票卖完了,但还有可能放票(ticket == 0),线程会发生什么? 它们会陷入一种“忙等待”:抢锁 -> 发现票为0 -> 解锁 -> 再次抢锁。这种高频的无效操作会白白浪费 CPU 资源。更糟糕的是,由于刚释放锁的线程离锁最近,它可能再次抢到锁,导致其他线程长时间“饥饿”。
(2)同步概念与竞态条件
-
同步 (Synchronization):在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源。这解决了多线程执行的无序性问题。
-
竞态条件 (Race Condition):虽然互斥锁保护了数据,但如果多个线程竞争资源的顺序是不确定的,且这种不确定性导致了逻辑错误或效率低下,就称为竞态条件。
(3)条件变量函数及设计流程
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);-
作用:在内存中开辟空间并初始化条件变量结构体。该结构体本质上维护了一个等待队列。
-
参数:
attr通常传NULL,表示使用默认属性。 -
静态初始化:如果你定义的是全局或静态条件变量,可以直接用宏:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;,这样省去了销毁的麻烦。
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);它在调用时会原子性地执行以下三个动作(这是为了防止信号丢失的关键):
- 释放锁:立即解开传入的
mutex。 - 挂起等待:将当前线程放入
cond的等待队列中,线程进入不可调度状态(不占用 CPU)。 - 重新拿锁:当线程被唤醒(从
wait返回前),它会自动重新竞争该mutex。只有重新拿到了锁,函数才会真正返回。 -
这说明
wait返回后,线程依然持有锁,可以安全地操作临界资源。
int pthread_cond_signal(pthread_cond_t *cond);-
作用:唤醒在
cond等待队列中的至少一个线程(通常是队首的那一个)。 -
应用场景:当你生产了一个资源(比如补了 1 张票),就调用它通知消费者。
-
安全性:即使当前没有线程在等待,调用
signal也是安全的,信号会被直接丢弃。
int pthread_cond_broadcast(pthread_cond_t *cond);-
作用:唤醒在
cond等待队列中的所有线程。 -
惊群效应:如果此时有 10 个线程在等 1 张票,调用
broadcast会导致 10 个线程全部醒来抢那 1 张票。虽然由于锁的保护只有一个能抢到,但这种频繁的上下文切换会带来性能损耗。 -
应用场景:当资源状态发生重大变化(比如一次性补了 100 张票,或者程序准备退出通知所有线程回收资源)时使用。
int pthread_cond_destroy(pthread_cond_t *cond);-
作用:清理条件变量占用的内核资源。
-
禁忌:绝不能销毁一个仍有线程在等待的条件变量。否则会导致未定义行为(通常是程序直接崩溃)。
#include <iostream>
#include <pthread.h>
#include <vector>
#include <string>
#include <unistd.h>
int tickets = 0; // 初始没票
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
void *consumer(void *arg)
{
std::string name = static_cast<const char *>(arg);
while (true)
{
pthread_mutex_lock(&mtx);
while (tickets == 0)
{
pthread_cond_wait(&cond, &mtx);
}
std::cout << name << " 抢到了票,剩余: " << --tickets << std::endl;
pthread_mutex_unlock(&mtx);
usleep(1000);
}
return nullptr;
}
void *producer(void *arg)
{
while (true)
{
sleep(2); // 每2秒补一次票
pthread_mutex_lock(&mtx);
tickets += 10;
std::cout << "[系统提示] 已补票 10 张\n" << std::endl;
// 唤醒在该条件变量下等待的一个线程
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mtx);
}
return nullptr;
}
int main()
{
pthread_t t1, t2, p;
pthread_create(&t1, nullptr, consumer, (void *)"Thread_A");
pthread_create(&t2, nullptr, consumer, (void *)"Thread_B");
pthread_create(&p, nullptr, producer, nullptr);
pthread_join(t1, nullptr);
pthread_join(t2, nullptr);
pthread_join(p, nullptr);
return 0;
}(4)条件变量原理
条件变量本质上是内核维护的一个等待队列。
-
当线程调用
wait时,它被放入队列并挂起。 -
当其他线程调用
signal(唤醒一个)或broadcast(唤醒全部)时,内核将线程从队列移出,重新投入运行队列。
(5)条件变量的规范使用
① 为什么 pthread_cond_wait 需要互斥量
假设 pthread_cond_wait 不需要锁:
消费者线程 A 先检查条件 if (tickets == 0),发现没票了,正准备去睡觉。就在此时,系统发生了线程切换——线程 A 还没来得及调用 wait,生产者线程 B 抢到 CPU 执行,迅速补了 10 张票,然后发了一个信号 pthread_cond_signal(&cond)。关键问题:此时线程 A 还没进入等待队列,这个信号就像对着空气喊了一声,无人接收,直接消失了。接着线程 A 恢复运行,执行 pthread_cond_wait(&cond),进入漫长的睡眠。虽然票已经变成了 10 张,但它永远错过了那个“起床闹钟”。如果生产者不再补票,线程 A 就会永久死锁。
本质:检查条件(判断要不要睡)和真正入睡(进入等待队列)之间,存在一个危险的“时间缝隙”,信号可能从这个缝隙中溜走。
pthread_cond_wait加锁:
为了堵死上面那个“时间缝隙”,pthread_cond_wait 必须和互斥量配合,完成一个原子性的接力。
消费者线程先加锁,在锁的保护下检查条件 if (tickets == 0)。因为手里握着锁,生产者线程此时无法修改票数,也无法发送信号,条件不会被破坏。当需要等待时,调用 pthread_cond_wait(cond, mutex)——这个函数在底层做了一气呵成的操作:把你放入条件变量的等待队列,同时原子地释放你手中的锁。这两个动作是捆绑的,中间不可能被任何线程插入。
一旦锁被释放,生产者线程就能获得锁、补票、发送信号。而这时,消费者线程一定已经在等待队列里了,信号不会丢失。消费者被唤醒后,pthread_cond_wait 返回之前会重新获取锁,带着锁继续执行,再次检查条件,确保万无一失。
本质:
pthread_cond_wait将“释放锁”和“进入等待”绑定成一个原子操作,彻底消灭了条件判断与等待之间的时间缝隙,让信号永远能找到它的接收者。
下一次pthread_cond_signal(&cond)时他不就醒来了吗?
如果生产者只负责加载 100 个配置文件,加载完发送一次
signal就结束线程了。如果消费者因为没有锁保护,在“检查条件”和“进入等待”的缝隙中错过了这唯一的一次信号。假设生产者每 10 秒才补一次票。消费者在第 1 秒其实已经看到有票了,但因为信号丢失,它被迫多等了 9 秒,直到第 11 秒的下一次信号传过来。对于高频交易、实时渲染等场景,这种“随机出现的几秒延迟”是不可接受的系统 Bug。
② 条件用while循环的原因
当 Thread_A 被唤醒时,它需要重新抢锁。如果它抢锁慢了,Thread_B 刚好把刚补的票抢走了。此时 Thread_A 醒来后票又是 0。如果是 if,它会继续往下跑导致逻辑错误(操作空资源);如果是 while,它会再次检查并重新进入睡眠。
为什么会有没让它醒来的线程醒来?
伪唤醒。在 Linux/Unix 系统中,当线程在内核态挂起(比如在
wait队列里睡觉)时,如果收到了一个信号(比如Ctrl+C),内核必须唤醒该线程去处理信号。线程被强制唤醒,处理完信号后,系统调用(pthread_cond_wait)会返回。此时线程醒了,但并不是因为生产者发了cond_signal,所以资源(票)可能根本没变。或者,即使调用了pthread_cond_signal,由于多核并行,内核可能为了保证“至少唤醒一个”,而在底层实现上稍微“激进”了一点,导致 A 和 B 同时被唤醒
③ 添加释放锁的时机
| 顺序 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 先 Signal 后 Unlock | 绝对安全。保证条件修改和信号发送的原子性,逻辑最严密。 | 可能引发“唤醒后立即阻塞(换了个地方接着睡)”,增加上下文切换开销。 | 逻辑复杂、对安全性要求极高的代码。 |
| 先 Unlock 后 Signal | 高性能。减少消费者线程在锁上的等待时间,提高系统吞吐量。 | 在极其复杂的逻辑下,可能导致信号发送给了一个“已经不需要”的线程。 | 高性能服务器、频繁唤醒的生产者消费者模型。 |
2. 条件变量的封装
#pragma once
#include <pthread.h>
#include "Mutex.hpp"
namespace ThreadModule
{
class Cond
{
public:
Cond()
{
pthread_cond_init(&_cond, NULL);
}
void Wait(Mutex &mutex)
{
pthread_cond_wait(&_cond, mutex.Get());
}
void Signal()
{
pthread_cond_signal(&_cond);
}
void Broadcast()
{
pthread_cond_broadcast(&_cond);
}
~Cond()
{
pthread_cond_destroy(&_cond);
}
private:
pthread_cond_t _cond;
};
}3. 生产者消费者模型
(1)模型概述
① 是什么
简单来说,这就好比“厨师做菜”与“顾客吃饭”。厨师(生产者)不直接把菜喂给顾客(消费者),而是把菜放到出餐台(交易场所)。 在计算机中,它被总结为著名的 “321 原则”:
-
3 种关系:生产者与生产者(互斥,抢着放数据)、消费者与消费者(互斥,抢着拿数据)、生产者与消费者(互斥与同步,不能同时操作同一个位置,且有数据才能拿,有空位才能放)。
-
2 种角色:生产者线程(生成数据的执行流)与消费者线程(处理数据的执行流)。
-
1 个交易场所:一段特定结构的内存空间(通常是某种数据结构,如队列、环形缓冲区)。
② 为什么
在单线程中,函数调用是强耦合的同步过程:调用方必须等待被调用方执行完毕才能返回。如果被调用方的操作非常耗时(如写磁盘、网络请求),整个程序就会被卡死。 引入该模型,本质上是为了解决数据生产速度与处理速度严重不匹配的问题。
③ 怎么做
借助我们上一章学过的兵器库:使用互斥锁来维护交易场所的绝对安全(处理 3 种互斥关系),使用条件变量来建立生产者与消费者之间的通信机制(处理同步关系)。
(2)模型优点
-
彻底解耦:生产者只需关心如何高效生成数据并塞入容器,根本不需要知道消费者的数量、状态或处理逻辑。代码高度模块化。
-
支持高并发:由于数据生产和处理被容器隔开,当消费者在执行耗时的复杂运算时,只要容器没满,生产者依然可以全速运转,彼此互不干扰。
-
削峰填谷:这是后端抗高并发的核心。当双十一流量洪峰瞬间涌入时,服务器不会直接崩溃,因为海量请求(生产者)会被堆积在容器中,后端的处理集群(消费者)只需要按照自己的最大处理能力,平稳地从容器中取任务执行即可。容器就像一个巨大的“水库”,缓冲了洪水的冲击。
4. 基于BlockingQueue的生产者消费者模型
(1)什么是 BlockingQueue
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)
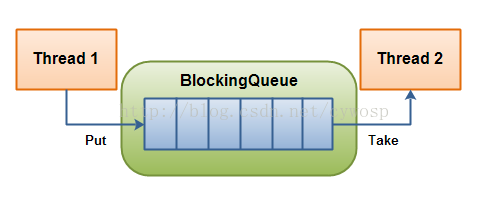
BlockingQueue(阻塞队列)是生产者消费者模型中最经典的“交易场所”。它不仅是一个队列,更是一个自带并发保护机制的智能容器。
(2)模拟实现
//BlockQueue.hpp
#pragma once
#include "../Packaging_tool/tool.h"
#include <iostream>
#include <queue>
template <class T>
class BlockQueue
{
private:
bool isFull() { return _cap == (int)_q.size(); }
bool isEmpty() { return 0 == (int)_q.size(); }
public:
BlockQueue(int cap)
: _cap(cap), _csleep(0), _psleep(0)
{
}
// 生产者产出任务入队
void Execute(const T &task)
{
LockGuard lock(mutex);
while (isFull())
{
_psleep++;
_full_cond.Wait(mutex);
_psleep--;
}
_q.push(task);
// if (_csleep > 0)
_empty_cond.Signal();
}
// 任务出队交付消费者
T Pop()
{
LockGuard lock(mutex);
while (isEmpty())
{
_csleep++;
_empty_cond.Wait(mutex);
_csleep--;
}
T task = _q.front();
_q.pop();
// if (_psleep > 0)
_full_cond.Signal();
return task;
}
~BlockQueue() {}
private:
std::queue<T> _q; // 阻塞队列容器
int _cap; // 队列容量
Cond _full_cond; // 生产者条件变量
Cond _empty_cond; // 消费者条件变量
Mutex mutex; // 大锁
// 单生产消费模型用来优化机制,多生产消费模型用来记录异常及日志
int _csleep;
int _psleep;
};//task.hpp
#pragma once
#include <iostream>
#include <functional>
#include <string>
class Task
{
public:
Task() : _x(0), _y(0), _op('+') {}
Task(int x, int y, char op) : _x(x), _y(y), _op(op) {}
// 仿函数:t()
void operator()()
{
int result = 0;
switch (_op)
{
case '+':
result = _x + _y;
break;
case '-':
result = _x - _y;
break;
case '*':
result = _x * _y;
break;
case '/':
if (_y != 0)
result = _x / _y;
else
std::cerr << "Error: Division by zero!" << std::endl;
break;
default:
break;
}
std::cout << "任务处理完成: " << _x << _op << _y << " = " << result << std::endl;
}
std::string DebugString()
{
return std::to_string(_x) + _op + std::to_string(_y) + "=?";
}
private:
int _x;
int _y;
char _op;
};
//main.cpp
#include "BlockQueue.hpp"
#include <unistd.h>
#include <vector>
#include <ctime>
void Produce(BlockQueue<Task> &bq)
{
char s[4] = {'+', '-', '*', '/'};
while (true)
{
int x = rand() % 10;
int y = rand() % 10;
char op = s[rand() % 4];
Task t(x, y, op);
std::cout << "[生产者" << pthread_self() << "] 放入任务: " << t.DebugString() << std::endl;
bq.Execute(t);
usleep(500000);
}
}
void Consume(BlockQueue<Task> &bq)
{
while (true)
{
sleep(1);
Task t = bq.Pop();
std::cout << "[消费者" << pthread_self() << "] 提取任务并处理... " << std::endl;
t();
}
}
int main()
{
srand(time(NULL));
BlockQueue<Task> bq(10); // 容量为10
std::vector<pthread *> producers;
std::vector<pthread *> consumers;
// 1. 创建 3 个生产者
for (int i = 0; i < 3; i++)
{
std::string name = "producer-" + std::to_string(i);
// 这里使用 lambda 表达式捕获 bq 的引用
std::cout << name << std::endl;
producers.push_back(new pthread([&bq]()
{ Produce(bq); }, name));
}
// 2. 创建 2 个消费者
for (int i = 0; i < 2; i++)
{
std::string name = "consumer-" + std::to_string(i);
std::cout << name << std::endl;
consumers.push_back(new pthread([&bq]()
{ Consume(bq); }, name));
}
// 3. 统一启动
for (auto p : producers)
p->Start();
for (auto c : consumers)
c->Start();
// 4. 等待回收
for (auto p : producers)
p->Join();
for (auto c : consumers)
c->Join();
return 0;
}对_csleep 与 _psleep 的理解
在多生产/消费模型中,
_csleep与_psleep所有修改均在互斥锁的保护下完成——Wait()释放锁之前计数器已完成自增,被唤醒重新持锁然后自减,因此,变量本身始终是线程安全的,并不存在“不受保护的窗口”。真正的问题在于用它做流控的逻辑复杂度。在单生产/消费模型中,计数值是二元稳定的(0或1),
if (_csleep > 0) Signal()这个优化语音信号、判断可靠。但在多线程场景下,多个生产者轮流持锁、各自独立地读取计数并决策,随着线程数增加,“谁来负责唤醒谁”的协调关系逐渐发难以推理,逻辑的脆弱性也开始上升。而同时,Signal()在等待队列空时的前期几乎可以忽略不计。或许“省掉一次”信号”的收益微乎其微,但却要结构逻辑复杂化的代价,在多生产/消费场景下完全不值得去算——直接无条件信号才是更明智的选择。因此,
_csleep与_psleep在多生产/消费模型中更适合作为系统压力的监控指标:若_csleep长期偏高,说明消费者频频挨饿,队列容量可能偏小或生产速率过低;若_psleep长期高,则说明生产者持续偏性阻塞,消费端瓶颈存在。将其定期打印输出,是观察系统运行状态、指导参数调优的一种轻量而有价值的运维手。
对Lambda表达式new pthread([&bq]() { Consume(bq); }的理解


八、POSIX信号量
1. 信号量复习
在 Linux 中,我们接触过两种信号量:
-
System V 信号量:常用于进程间通信(IPC),它由于历史悠久,接口设计极其复杂(如
semget、semop等),且生命周期随内核。 -
POSIX 信号量:专为多线程和现代多进程设计。它的接口极其简洁(
sem_init、sem_post、sem_wait),性能更高,且分为有名信号量(用于进程)和无名信号量(用于线程)。 -
核心本质:信号量就是一个计数器,代表临界资源的剩余数量。它的 P(Wait) 操作是申请资源,V(Post) 操作是释放资源。这两者都是原子性的。
2. 接口演示
POSIX 信号量的头文件是 <semaphore.h>
-
sem_init(sem_t *sem, int pshared, unsigned int value):pshared为0 表示线程间共享,非 0 表示进程间共享,value是信号量的初始值(资源的个数)。 -
sem_wait(sem_t *sem):P 操作。将信号量减 1。如果信号量为 0,线程进入阻塞队列挂起,直到信号量大于 0。 -
sem_post(sem_t *sem):V 操作。将信号量加 1。同时唤醒在等待队列中的线程。 -
sem_destroy(sem_t *sem):销毁信号量。
// 伪代码
sem_t sem;
sem_init(&sem, 0, 10); // 初始有10个资源
sem_wait(&sem); // 申请资源 (P)
// --- 访问临界资源 ---
sem_post(&sem); // 归还资源 (V)
sem_destroy(&sem);3. 封装信号量
#pragma once
#include <semaphore.h>
namespace ThreadModule
{
class Sem
{
private:
sem_t _sem;
public:
explicit Sem(unsigned int sem_value = 1)
{
sem_init(&_sem, 0, sem_value);
}
~Sem()
{
sem_destroy(&_sem);
}
void P()
{
sem_wait(&_sem);
}
void V()
{
sem_post(&_sem);
}
};
}4. 基于环形队列(RingQueue)的生产者消费者模型
(1)简述环形队列
它依然是一个连续的数组(std::vector 或 T arr[]),内存并不会弯曲。它是通过取模运算 ,我们人为地将数组的“尾巴”和“头部”缝合在了一起。当指针走到 capacity-1 之后,下一个位置会自动跳回 0,其实就是循环队列。
核心机制
环形队列的精髓在于维护两个偏移量:p_step_(生产者下标)和 c_step_(消费者下标)。
-
起始状态:
p_step == c_step == 0。 -
生产过程:生产者每放一个数据,
p_step = (p_step + 1) % capacity。 -
消费过程:消费者每取一个数据,
c_step = (c_step + 1) % capacity。
所以,在绝大多数时刻,
p_step和c_step指向不同的位置。这意味着生产者和消费者在操作数组的不同下标,物理上不冲突! 只有在以下两种极端情况下,两人才会“碰头”:
- 队列为空:消费者追上了生产者。此时必须消费者等待。
- 队列为满:生产者领先了一圈,反向追上了消费者。此时必须生产者等待。
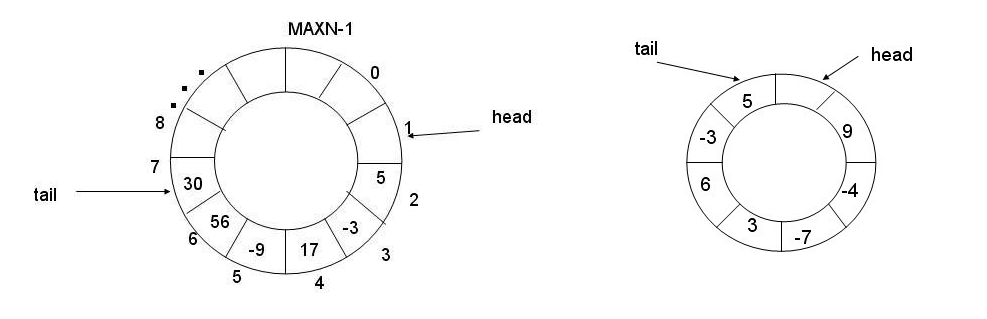
核心逻辑
这是环形队列比阻塞队列最高明的地方。我们引入两个信号量:
-
_blank_sem(格子信号量):代表“剩余空位”。初始值为Capacity。 -
_exist_sem(数据信号量):代表“已有资源”。初始值为0。 -
生产者:先申请
_blank_sem(P操作)。只要有格子,我就能秒进队列,不需要关心消费者在哪。放完后,给_exist_sem加1(V操作)。 -
消费者:先申请
_exist_sem(P操作)。只要有数据,我就能秒取。取完后,给_blank_sem加1(V操作)。
| 维度 | 阻塞队列 (BlockingQueue) | 环形队列 (RingQueue) |
| 锁的粒度 | 大锁。生产者和消费者共用一把锁,一人在动,另一人必阻塞。 | 细粒度/无锁化倾向。只有在多生产者或多消费者竞争同类资源时才加锁,生产和消费之间几乎不互斥。 |
| 并发度 | 串行化。同一时刻只允许一个执行流进入容器。 | 高并发。生产者在写 index 1,消费者在读 index 5,真正的物理并行。 |
| 判满/判空 | 依赖 size() 结合条件变量判断。 |
依赖信号量计数器。信号量本身就是原子的资源计数,不需要进入临界区就能知道能不能执行。 |
| 应用场景 | 任务量较小,结构简单的场景。 | 高性能、高吞吐。 |
阻塞队列之所以使用‘大锁’,表面上是因为
std::queue非线程安全,深层原因则是为了保证‘判断容量’与‘执行入队’这两个动作的原子性。这种‘一刀切’的保护虽然简单,却强制将生产与消费串行化。
(2)C++模拟实现
#pragma once
#include "../Packaging_tool/tool.h"
#include <iostream>
#include <vector>
template <class T>
class RingQueue
{
public:
RingQueue(int cap)
: _rq(cap), _cap(cap), _p_site(0), _c_site(0), _blank_sem(cap), _exist_sem(0)
{
}
void Execute(const T &task)
{
_blank_sem.P();
{
LockGuard lock(_p_mtx);
_rq[_p_site] = task;
_p_site++;
_p_site %= _cap;
}
_exist_sem.V();
}
// 任务出队交付消费者
T Pop()
{
T task;
_exist_sem.P();
{
LockGuard lock(_c_mtx);
task = _rq[_c_site];
_c_site++;
_c_site %= _cap;
}
_blank_sem.V();
return task;
}
~RingQueue() {}
private:
std::vector<T> _rq;
int _cap;
int _p_site;
int _c_site;
Sem _blank_sem;
Sem _exist_sem;
Mutex _p_mtx;
Mutex _c_mtx;
};
//main.cpp和上面的一样,改个容器就行当_p_step== _c_step时,它是怎么处理的
环形队列在运行时,
_p_site与_c_site的关系无两种情况:重合或不重合。当两者不同时时,队列一个正常的生产/消费状态——两个下标分别指向不同的槽位,生产者写
_p_site,消费者读_c_site,自然操作不同的内存位置,互不干涉。此时信号量增大余量,线程请求,直接推进即可。多消费/生产场景下,虽然不同生产者之间、不同消费者之间会竞争同一个下标,但_p_mtx与_c_mtx两把独立的互锁保护各自的下标读写,使得写端与读端可以真正互相调用,互不接入。当两者同时时,下标不一致出现歧义——它既可能代表队列全空,也可能代表队列绕一圈后全满,仅凭下标本身无法区分。
RingQueue解法是让系统通过双信号量的计数机制强行解开这一逻辑死结,信号量不仅作为资源的计数器,更充当了线程进入临界区的“入场券”。初始化时_blank_sem被设定容量上限cap,_exist_sem被设为0,两者之和始终相等cap,构成一个一致式。生产者读取前必须先对_blank_sem执行P——操作若队列已满则_blank_sem == 0生产者此时直接无缝,根本支持下标;消费者读取前必须先对_exist_sem执行P操作——若队列为空则_exist_sem == 0,消费者此时同样阻塞。两者下标即将重合的那一刻,对应线程最多被信号量拦截,_p_site == _c_site这一歧义状态在运行时永远不需要被代码主动判断。这种设计高效修改体现了信号量与互斥锁的职责划分:信号量负责流量控制,队列能否推进、队列是否相邻边界;互斥锁负责临界区保护,防止多个生产者或消费者同一下标。两者各司其职、互不相干,使得环形队列在多生产/消费模型下依然能够正确、接地运行。
九、线程池
1. 日志系统
#pragma once
#include "../Packaging_tool/Mutex.hpp"
#include <iostream>
#include <cstdio>
#include <string>
#include <filesystem>
#include <sstream>
#include <fstream>
#include <memory>
#include <ctime>
#include <unistd.h>
using namespace std;
namespace fs = std::filesystem;
#define LOG(level) _logger(level, __FILE__, __LINE__)
#define ENABLE_CONSOLE() _logger.EnableConsoleLogStrategy()
#define ENABLE_FILE() _logger.EnableFileLogStrategy()
const string gsep = "\r\n";
class Strategy
{
public:
virtual ~Strategy() = default;
virtual void SyncLog(const string &txt) = 0;
};
class ConsoleLogStrategy : public Strategy
{
public:
virtual void SyncLog(const string &txt) override
{
ThreadModule::LockGuard lock(_mtx);
cout << txt << gsep;
}
private:
ThreadModule::Mutex _mtx;
};
const string defaultpath = "./log";
const string defaultname = "my.log";
class FileLogStrategy : public Strategy
{
public:
FileLogStrategy()
: _filepath(defaultpath), _filename(defaultname)
{
ThreadModule::LockGuard lock(_mtx);
if (_filepath.back() != '/')
_filepath += "/";
if (!fs::exists(_filepath))
{
try
{
fs::create_directories(_filepath);
}
catch (const fs::filesystem_error &e)
{
std::cerr << "创建目录失败: " << e.what() << '\n';
}
}
_name = _filepath + _filename;
}
virtual void SyncLog(const string &txt) override
{
ThreadModule::LockGuard lock(_mtx);
ofstream out(_name.c_str(), ios::app);
if (out.is_open())
{
out << txt << gsep;
out.close();
}
}
private:
string _filepath;
string _filename;
string _name;
ThreadModule::Mutex _mtx;
};
enum class LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
std::string Level2Str(LogLevel level)
{
switch (level)
{
case LogLevel::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "INFO";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
std::string GetTimeStamp()
{
time_t curr = time(nullptr);
struct tm curr_tm;
localtime_r(&curr, &curr_tm);
char timebuffer[128];
snprintf(timebuffer, sizeof(timebuffer), "%4d-%02d-%02d %02d:%02d:%02d",
curr_tm.tm_year + 1900, curr_tm.tm_mon + 1, curr_tm.tm_mday,
curr_tm.tm_hour, curr_tm.tm_min, curr_tm.tm_sec);
return timebuffer;
}
class Logger
{
public:
class LoggerMessage
{
public:
LoggerMessage(LogLevel level, const string &name, int line, Logger &log)
: _log(log)
{
stringstream ss;
ss << "[" << GetTimeStamp() << "]"
<< "[" << Level2Str(level) << "]"
<< "[" << getpid() << "]"
<< "[" << name << "]"
<< "[" << line << "]";
_loginfo += ss.str();
}
template <class T>
LoggerMessage &operator<<(const T &data)
{
stringstream ss;
ss << data;
_loginfo += ss.str();
return *this;
}
~LoggerMessage()
{
if (_log._s)
{
// 调用父类 Logger 选择的策略进行落盘
_log._s->SyncLog(_loginfo);
}
}
private:
Logger &_log;
string _loginfo;
};
Logger() { EnableConsoleLogStrategy(); }
LoggerMessage operator()(LogLevel level, const string &name, int line)
{
return LoggerMessage(level, name, line, *this);
}
void EnableConsoleLogStrategy() { _s = make_unique<ConsoleLogStrategy>(); }
void EnableFileLogStrategy() { _s = make_unique<FileLogStrategy>(); }
private:
unique_ptr<Strategy> _s;
};
Logger _logger;
(1)策略模式
现实中的问题:同一件事有多种做法,而且做法可能随时切换。
- 日志系统:输出到屏幕 / 输出到文件 / 输出到网络
- 支付系统:微信支付 / 支付宝 / 银行卡
- 排序算法:快速排序 / 归并排序 / 冒泡排序
你可能会这样写:
void Log(string msg, int type)
{
if (type == 0) {
cout << msg; // 屏幕
} else if (type == 1) {
ofstream out("a.log");
out << msg; // 文件
} else if (type == 2) {
// 网络发送...
}
}这时,每次新增一种输出方式,就要改这个函数,if-else 越来越长,改一个地方可能影响其他逻辑
所以就有了策略模式,把“变化的部分”抽出来,封装成独立的类别。
// 第一步:定义接口(稳定的部分)
class Strategy {
public:
virtual void SyncLog(const string &msg) = 0;
//const string &msg,数据从外部传入,保证策略只负责"动作"
virtual ~Strategy() = default;
};
// 第二步:每种做法是一个子类(变化的部分)
class ConsoleStrategy : public Strategy {
public:
void SyncLog(const string &msg) override {
cout << msg;
}
};
class FileStrategy : public Strategy {
public:
void SyncLog(const string &msg) override {
ofstream out("a.log", ios::app);
out << msg;
}
};
class NetworkStrategy : public Strategy {
public:
void SyncLog(const string &msg) override {
// 发送到远程服务器
}
};
//如果还有直接添加即可
// 第三步:Logger 持有策略指针,不关心具体是哪种
class Logger {
unique_ptr<Strategy> _s; // ← 只认识基类接口
public:
void Log(const string &msg) {
_s->SyncLog(msg); // ← 不管背后是谁,直接调用
}
void SetStrategy(unique_ptr<Strategy> s) {
_s = move(s);
}
};怎么改变策略,指针的指向何时改变?
// 1. Logger 构造时:默认指向屏幕 Logger() { EnableConsoleLogStrategy(); } // ↓ 等价于 _fflush_strategy = std::make_unique<ConsoleLogStrategy>(); // 2. 你主动调用切换函数时: ENABLE_FILE(); // ↓ 宏展开为 logger.EnableFileLogStrategy(); // ↓ 等价于 _fflush_strategy = std::make_unique<FileLogStrategy>(); // make_unique 会析构旧对象,再构造新对象,指针指向改变 // 3. LogMessage 析构时只做一件事: ~LogMessage() { _logger._fflush_strategy->SyncLog(_loginfo); // 只管调用,不管是谁 }
(2)嵌套结构解析
① 为什么 LogMessage 请求在 Logger 内部?
首先,嵌套类适合的场景:某个类只为另一个类服务,对外没有独立存在的意义。LogMessage 的存在完全依附于 Logger,由 Logger 创建,解析架构时回调Logger的策略,离开 Logger 没有任何意义,而且内部类天然可以访问外部类的内部成员,不需要friend声明,这也是好处之一。它俩各司其职:
Logger → 管理"怎么输出"(策略的选择和切换)
LogMessage → 管理"一条日志的构建过程"(拼接、最终提交) 其次,要实现 << 的链式调用,就必须有一个中间对象来承接每一次 << 的结果——这个中间对象就是 LogMessage。
同时,还有一点好处就是天然保证了线程安全:如果只写一个类它必须要至少处理打印消息与选择策略两件事,而logger是全局对象,那打印消息时就必然会有消息混乱,但有了内部类:
// 每次调用 LOG,都创建一个全新的 LogMessage 临时对象
LOG(LogLevel::INFO) << "服务器启动";
// 展开后:
LogMessage msg_A(...); // 线程A 自己的对象,在线程A 的栈上
LogMessage msg_B(...); // 线程B 自己的对象,在线程B 的栈上② 为什么解析结构函数触发刷新是精髓?
如果不用解析结构函数,你要怎么实现“写完就提交”?
// 方案A:手动调用 commit
LOG(LogLevel::INFO) << "服务器启动";
LOG.commit(); // ← 用户必须手动调用,很容易忘
// 方案B:专门一个 end 标志
LOG(LogLevel::INFO) << "服务器启动" << END; // ← 必须记得加 END
// 方案C:现在的设计
LOG(LogLevel::INFO) << "服务器启动";
// ← 分号结束,自动提交,什么都不用做他所以利用的就是临时对象的生命周期!
LOG(LogLevel::INFO) << "服务器启动";
//宏展开后:
LogMessage(level, file, line, logger) << "服务器启动";
//创建临时对象
//→ 分号,语句结束
//→ 临时对象立刻析构
//→ ~LogMessage() 被调用
//→ SyncLog 触发
(3)陌生函数调用讲解
① filesystem
std::filesystem 是一个命名空间 (Namespace)。在这个命名空间里,包含了一系列相互协作的类、常量以及非成员函数。我们可以把它看作是一个专门管理文件系统的“工具箱”。
#include <filesystem>
namespace fs = std::filesystem; // 别名,方便写
// 判断路径是否存在
fs::exists("./log"); // true / false
// 创建目录(单层)
fs::create_directory("./log");
// 递归创建多层目录 ← 代码里用的这个
fs::create_directories("./a/b/c"); // a、b、c 都会被创建
// 其他常用功能
fs::remove("a.txt"); // 删除文件
fs::rename("a.txt", "b.txt"); // 重命名
fs::file_size("a.txt"); // 获取文件大小(字节)
fs::is_directory("./log"); // 判断是不是目录② ofsteam
常用打开模式 (std::ios_base::openmode)
-
ios::out:默认模式。打开文件时会清空原有内容。 -
ios::app(Append):追加模式。每次写入都定位到文件末尾,保留原有内容。 -
ios::binary:二进制模式。不进行特殊字符转义(如\n转成\r\n),通常用于图片或压缩包。
缓冲区机制 (Buffering)
ofstream 并不是每写一个字符就触发一次磁盘 IO,它内部有一个缓冲区。触发写入的时机有缓冲区满了;调用 flush();调用 close();遇到 std::endl(它会执行 \n + flush)。在高性能日志系统中,频繁 endl 会导致频繁 IO,降低性能。通常推荐只用 \n,依靠缓冲区自动落盘。
检查打开是否成功
std::ofstream out("a.txt", std::ios::app);
if (out.is_open()) // ← 代码里有这个判断
{
out << "写入内容";
out.close();
}
// 打不开的情况:路径不存在、没有写权限等为什么不直接用C的fopen?
维度 C 语言 (FILE*) C++ (ofstream + filesystem) 安全性 容易忘记 fclose导致泄漏析构函数自动关闭(RAII) 目录创建 必须自己写递归 mkdircreate_directories一键搞定扩展性 很难处理自定义类 只要重载 <<就能直接写入对象性能 略高(开销更小) 略低(封装较多),但符合工程化要求
③ 获取时间函数
整体流程
<span style="color:#14181f"><code>time(nullptr) → 获取当前时间(一个大整数)
↓
localtime_r(&curr, &curr_tm) → 把整数转成年月日时分秒结构体
↓
snprintf(...) → 格式化成可读字符串第一步:time_t和time()
time_t curr = time(nullptr);time_t本质上就是一个long,存在的是Unix计时器——从1970年1月1日00:00:00到现在经过的秒数,即时间戳,time(nullptr)就是获取当前时间,传nullptr表示“我不需要你把结果写到指针里,直接返回给我就行”。
第二步:struct tm和localtime_r
光有秒数无法用,需要转成人能看懂的结构体:
struct tm curr_tm;
localtime_r(&curr, &curr_tm); //这个函数是线程安全的struct tm 是C标准库提供的时间结构体,拆解好了年月日:
struct tm {
int tm_year; // 年,从 1900 开始算,所以要 +1900
int tm_mon; // 月,0~11,所以要 +1
int tm_mday; // 日,1~31
int tm_hour; // 时,0~23
int tm_min; // 分,0~59
int tm_sec; // 秒,0~59
// 还有星期、一年第几天等
};注意点:
curr_tm.tm_year + 1900 // 比如存的是 126,+1900才是 2026 curr_tm.tm_mon + 1 // 比如存的是 3, +1才是 4月
第三步:snprintf规范
snprintf是printf的“安全版”,区别使用第二个参数最多写多少字节,防止故障溢出:
printf( fmt, ...); // 写到屏幕
sprintf (buf, fmt, ...); // 写到 buf,不安全,可能溢出
snprintf(buf, n, fmt, ...); // 写到 buf,最多写 n 字节,安全(4)其他注意点
① const std::string gsep = "\r\n"
使用\n在纯Linux环境完全没问题,更简洁。用\r\n是一种防御性,牺牲一点Linux彻底选择,换取跨平台和网络场景下的兼容性。写服务端日志时,考虑到日志可能被各种工具查看,\r\n是更稳妥的做法。
② __FILE__
-
含义:当前源代码文件的文件名(字符串常量)
-
示例:如果代码在
main.cpp中,__FILE__会被替换为"main.cpp"
③ __LINE__
-
含义:当前源代码文件的行号(整数常量)
-
示例:如果这行代码在第 42 行,
__LINE__会被替换为42
2. 单例模式
(1)单例模式概述
单例模式是一种创建型设计模式,其核心约束只有一条:一个类在整个程序的生命周期内只允许存在一个实例。为了强制这一约束,通常需要将函数构造成私有的,对外只引用一个获取实例的静态接口。
单例模式适用于那些“全局唯一、资源共享”的场景,例如日志系统、线程池、配置管理器、数据库连接池等——这类对象反复创建既没有意义,又会带来资源浪费或状态不一致的风险。
(2)饿汉实现方式与懒汉实现方式
两种方式的根本区别在于实例在什么时机被创建。
① 饿汉模式:程序启动时就立即创建实例,不管后续是否用到。
class Singleton
{
public:
static Singleton &GetInstance()
{
return _instance;
}
void DoSomething() { }
private:
Singleton() {}
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton _instance; // 类外初始化,程序启动即创建
};
Singleton Singleton::_instance;优点是实现简单、天然线程安全(静态对象在 main 之前由编译器保证单次初始化);缺点是无论该实例是否被用到,内存都已占用,若初始化开销较大则会拖慢启动速度。
| 存储期 | 关键字/位置 | 创建时机 | 销毁时机 |
|---|---|---|---|
| 自动存储期 | 局部变量 | 执行到声明处 | 离开作用域 |
| 静态存储期 | static / 全局 |
程序启动前后 | 程序结束 |
| 线程存储期 | thread_local |
线程创建时 | 线程结束 |
| 动态存储期 | new |
显式调用时 | 显式 delete |
② 懒汉模式:第一次调用 GetInstance() 时才创建实例,真正做到按需加载。
class Singleton
{
public:
// static函数属于类,它不依赖于任何具体的对象
// 如果不加 static,这个函数就必须先有对象才能调用,这不矛盾了
static Singleton *GetInstance() //没有this指针
{
if (_instance == nullptr) // 首次调用才创建
_instance = new Singleton();
return _instance;
}
private:
Singleton() {}
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton *_instance;
};
Singleton *Singleton::_instance = nullptr; //开局只创建一个小指针 优点是延迟初始化,不使用则不占资源;缺点是在多线程环境下,多个线程可能同时通过 if (_instance == nullptr) 的检查,导致实例被创建多次,存在线程安全隐患。
(3)线程安全的懒汉实现方式
方案一:加锁 + 双重检查
class Singleton
{
public:
static Singleton *GetInstance()
{
if (_instance == nullptr) // 第一次检查:避免每次都加锁
{
LockGuard lock(_mutex);
if (_instance == nullptr) // 第二次检查:防止重复创建
_instance = new Singleton();
}
return _instance;
}
private:
Singleton() {}
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
static Singleton *_instance;
static Mutex _mutex; //静态函数只能访问 static 成员变量
};
Singleton *Singleton::_instance = nullptr;两次检查的必要性
若只有锁内的第二次检查,则每次调用
GetInstance()都要加锁,在实例已存在的情况下产生大量无意义的锁竞争;若只有锁外的第一次检查,则多线程同时通过检查后仍会重复创建。双重检查将两者结合:锁外过滤高频访问,锁内保证创建安全。
方案二:局部静态变量(C++11)
C++11 标准明确规定:局部静态变量在首次经过其声明时才初始化,且该初始化过程是线程安全的——编译器会在底层自动生成一次性初始化的保护逻辑。无需手动加锁,代码简洁,是现代 C++ 中最推荐的单例写法。
class Singleton
{
public:
static Singleton &GetInstance()
{
static Singleton _instance; // C++11 保证局部静态变量初始化的线程安全
return _instance;
}
private:
Singleton() {}
Singleton(const Singleton &) = delete;
Singleton &operator=(const Singleton &) = delete;
};3. 线程安全的单例式线程池
// RingQueue.hpp
#pragma once
#include "../Packaging_tool/tool.h"
#include <iostream>
#include <vector>
#include <atomic>
template <class T>
class RingQueue
{
public:
RingQueue(int cap)
: _rq(cap), _cap(cap), _p_site(0), _c_site(0), _blank_sem(cap), _exist_sem(0), _size(0)
{
}
void Execute(const T &task)
{
_blank_sem.P();
if (IsFull())
return;
{
LockGuard lock(_p_mtx);
_rq[_p_site] = task;
_p_site++;
_p_site %= _cap;
_size++;
}
_exist_sem.V();
}
// 任务出队交付消费者
bool Pop(T *out)
{
_exist_sem.P();
if (IsEmpty())
return false;
{
LockGuard lock(_c_mtx);
*out = _rq[_c_site];
_c_site++;
_c_site %= _cap;
_size--;
}
_blank_sem.V();
return true;
}
void WakeALL()
{
for (int i = 0; i < _cap; i++)
{
_blank_sem.V();
_exist_sem.V();
}
}
bool IsEmpty() { return _size == 0; }
bool IsFull() { return _size == _cap; }
~RingQueue() {}
private:
std::vector<T> _rq;
int _cap;
int _p_site;
int _c_site;
Sem _blank_sem;
Sem _exist_sem;
Mutex _p_mtx;
Mutex _c_mtx;
std::atomic<int> _size; // 原子计数器,记录真实任务数
//std::atomic 是 C++11 引入的原子操作库,用于实现无锁编程。
//它保证对变量的操作是不可分割的,不会因为线程切换而导致数据竞争。这个我们之后会讲
};//Threadpool.hpp
#include "../Packaging_tool/tool.h"
#include "RingQueue.hpp"
using namespace std;
template <class T>
class Threadpool
{
public:
static Threadpool<T> *GetInstance(int nums = 5, int cap = 10)
{
if (!_instance)
{
LockGuard lock(_mtx);
if (!_instance)
{
_instance = new Threadpool<T>(nums, cap);
_instance->Start();
}
}
return _instance;
}
void Start()
{
if (_isrunning)
return;
_isrunning = true;
_pool.reserve(_nums);
for (int i = 0; i < _nums; i++)
{
_pool.emplace_back([this]()
{ this->HandlerTask(); }, "worker-" + std::to_string(i));
}
for (auto &thread : _pool)
thread.Start();
LOG(LogLevel::INFO) << "线程池启动成功";
}
void Stop()
{
if (!_isrunning)
return;
_isrunning = false;
LOG(LogLevel::INFO) << "正在关闭线程池...";
_rq.WakeALL();
for (auto &thread : _pool)
thread.Join();
LOG(LogLevel::INFO) << "所有线程已回收";
}
bool Enqueue(const T &task)
{
if (_isrunning)
{
_rq.Execute(task);
return true;
}
else
return false;
}
private:
Threadpool(int nums, int cap)
: _isrunning(false), _rq(cap), _nums(nums)
{
}
Threadpool(const Threadpool<T> &) = delete;
Threadpool<T> &operator=(const Threadpool<T> &) = delete;
void HandlerTask()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
while (true)
{
T task;
if (!_rq.Pop(&task))
{
if (!_isrunning)
break;
else
continue;
}
LOG(LogLevel::DEBUG) << "线程 " << name << " 处理任务中...";
task();
}
LOG(LogLevel::INFO) << "线程 " << name << " 安全退出";
}
atomic<bool> _isrunning;
vector<pthread> _pool;
RingQueue<T> _rq;
int _nums;
static Threadpool<T> *_instance;
static Mutex _mtx;
};
template <class T>
Threadpool<T> *Threadpool<T>::_instance = nullptr;
template <class T>
Mutex Threadpool<T>::_mtx;//main.cpp
#include <iostream>
#include <ctime>
#include <vector>
#include <unistd.h>
#include "Threadpool.hpp"
using namespace std;
// 生产者逻辑
void ProducerRoutine(Threadpool<Task> *tp, int count, string name)
{
char ops[] = "+-*/";
for (int i = 0; i < count; ++i)
{
int x = rand() % 100;
int y = rand() % 10 + 1; // 避免除0
char op = ops[rand() % 4];
Task t(x, y, op);
if (!(tp->Enqueue(t)))
{
LOG(LogLevel::INFO) << name.c_str() << "任务被退回,准备退出";
return;
}
// 使用 printf 保证多线程输出不被打断
printf("[%s] 派发任务: %s\n", name.c_str(), t.DebugString().c_str());
usleep(300000);
}
printf("[%s] 任务派发完毕,生产者退出。\n", name.c_str());
}
int main()
{
srand((unsigned int)time(nullptr));
// 1. 获取线程池单例 (5个消费者线程,队列容量10)
auto tp = Threadpool<Task>::GetInstance(5, 10);
// 2. 创建 3 个生产者线程
vector<pthread *> producers;
producers.push_back(new pthread([tp]()
{ ProducerRoutine(tp, 10, "Producer-1"); }, "P1"));
producers.push_back(new pthread([tp]()
{ ProducerRoutine(tp, 50, "Producer-2"); }, "P2"));
producers.push_back(new pthread([tp]()
{ ProducerRoutine(tp, 30, "Producer-3"); }, "P3"));
// 3. 主线程模拟管理逻辑:观察并计时
int monitor_time = 5;
LOG(LogLevel::INFO) << monitor_time << " 秒后关停线程池...";
// 4. 启动所有生产者
for (auto p : producers)
p->Start();
while (monitor_time--)
{
sleep(1);
}
// 5. 关停线程池
LOG(LogLevel::INFO) << "时间到";
tp->Stop();
// 6. 回收生产者线程资源
for (auto p : producers)
{
p->Join();
delete p;
}
LOG(LogLevel::INFO) << "所有生产者已回收,主程序正常退出。";
return 0;
}该说的上面我们已经讲过,唯一有一个线程池退出逻辑比较难,下面我们具体讲解:
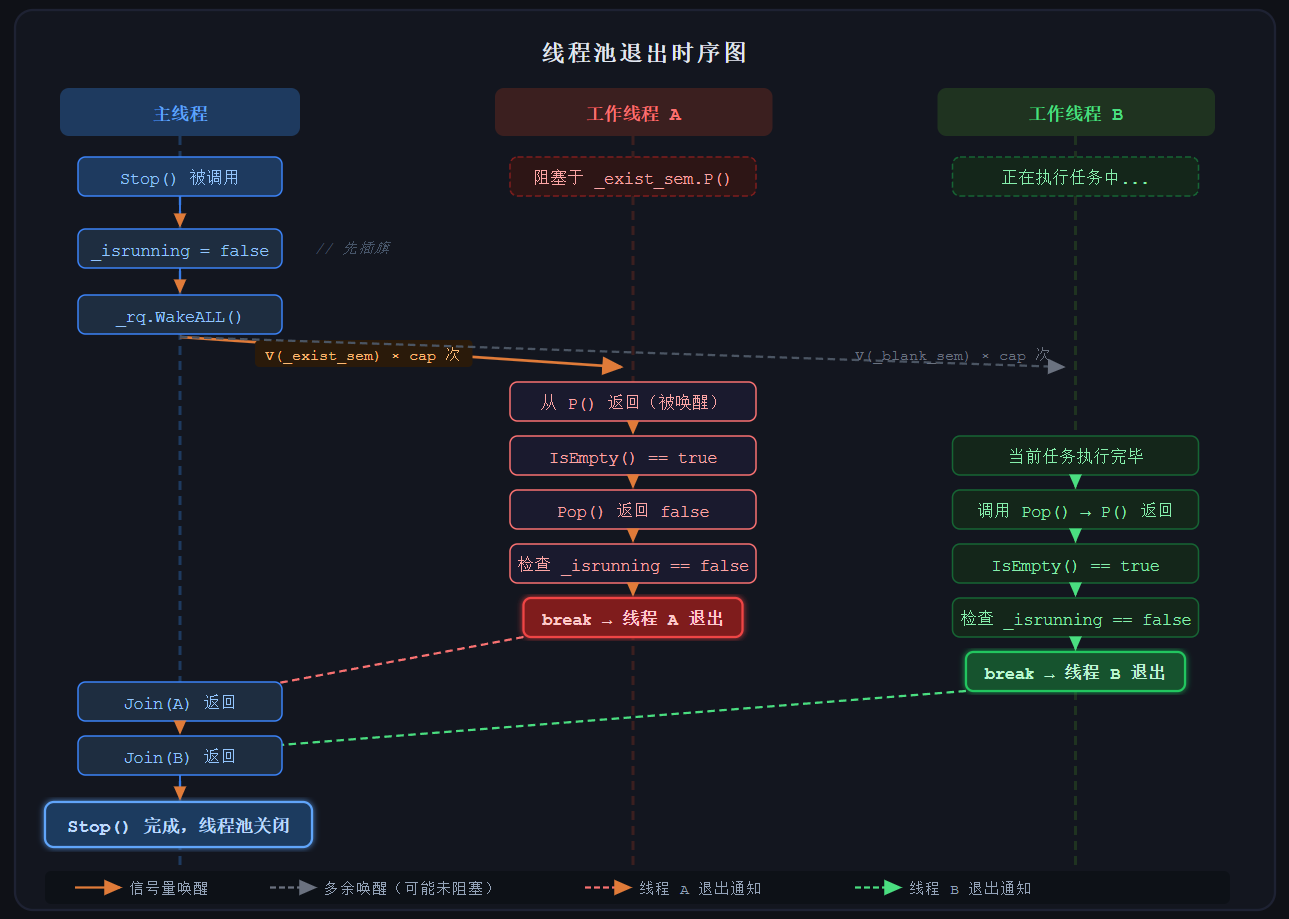
(1)整体结构回顾
线程池的退出是多线程编程中最容易出错的环节之一。一个健壮的退出流程需要解决三个核心问题:
- 如何通知所有工作线程"该停了"
- 如何唤醒那些正阻塞在信号量上、无事可做的线程
- 如何保证每一个线程都能干净地退出,不泄漏资源
线程池由三个核心组件构成:
Threadpool
├── vector<pthread> // 工作线程集合
├── RingQueue<T> // 环形任务队列
│ ├── _blank_sem // 信号量:剩余空位数(初始值 = 容量)
│ ├── _exist_sem // 信号量:现有任务数(初始值 = 0)
│ └── _size // 原子计数器:当前队列中的真实任务数
└── _isrunning // 原子标志:线程池是否处于运行状态
正常运行时,生产者(调用 Enqueue)和消费者(工作线程)通过一对信号量协调:
- 生产者入队前 P(
_blank_sem),入队后 V(_exist_sem) - 消费者出队前 P(
_exist_sem),出队后 V(_blank_sem)
这套机制在正常运行时完美工作,但退出时面临一个经典难题:工作线程可能正阻塞在 _exist_sem.P() 上等待任务,没有任何人去 V 它,线程永远无法退出。
(2)退出流程全景
Threadpool::Stop() 的调用触发了整个退出链:
Stop()
│
├─ 1. _isrunning = false // 插旗:告知所有人"要停了"
│
├─ 2. _rq.WakeALL() // 强制唤醒所有阻塞线程
│ └─ 对每个槽位:
│ V(_blank_sem) // 唤醒可能阻塞的生产者
│ V(_exist_sem) // 唤醒可能阻塞的消费者
│
└─ 3. 对每个线程调用 Join() // 等待所有线程安全退出
(3)WakeALL() 的设计细节
void WakeALL()
{
for (int i = 0; i < _cap; i++)
{
_blank_sem.V();
_exist_sem.V();
}
}
循环次数选择 _cap(队列容量)而非线程数,原因是:我们不知道有多少线程正阻塞在哪个信号量上。最坏的情况是所有线程全部阻塞在 _exist_sem.P() 上,而信号量的 V 操作是幂等累加的,多余的 V 不会造成崩溃,只会留下一些多余的计数,这是可以接受的代价。
这个设计有一个关键前提:正常运行期间,_blank_sem 和 _exist_sem 的计数严格受 _size 约束,不会出现虚假的空位或任务。 因此 WakeALL() 产生的"多余信号"只在退出路径上有意义。
(4)工作线程如何感知退出
工作线程运行在 HandlerTask() 的循环中:
void HandlerTask()
{
while (true)
{
T task;
if (!_rq.Pop(&task)) // Pop 返回 false → 退出信号
{
if (!_isrunning)
break; // 确认是退出信号,跳出循环
else
continue; // 意外的空返回,继续尝试
}
task(); // 正常执行任务
}
}
工作线程通过 Pop() 的返回值来判断是否退出,而不是直接读 _isrunning。这样设计的好处是:退出检测与任务获取在同一个路径上,不需要额外的轮询或条件变量。
(5)Pop()与 Execute() 中的退出检测
bool Pop(T *out)
{
_exist_sem.P(); // 正常情况:等待直到有任务
// 退出情况:被 WakeALL() 的 V 唤醒
if (IsEmpty()) // 被唤醒后检查队列是否真的有任务
return false; // 没有任务 → 这是退出信号,返回 false
{
LockGuard lock(_c_mtx);
*out = _rq[_c_site];
_c_site = (_c_site + 1) % _cap;
_size--;
}
_blank_sem.V();
return true;
}
IsEmpty() 只在退出路径上才会为 true。 这是整个设计的核心不变式:
- 正常运行时,
_exist_sem.P()成功意味着_size > 0,IsEmpty()必然为 false - 只有
WakeALL()额外 V 了信号量之后,才会出现"信号量计数 > 实际任务数"的情况,此时IsEmpty()为 true,Pop 返回 false,工作线程得到退出通知
void Execute(const T &task)
{
_blank_sem.P(); // 正常情况:等待直到有空位
// 退出情况:被 WakeALL() 的 V 唤醒
if (IsFull()) // 被唤醒后检查队列是否真的有空位
return; // 没有空位 → 这是退出信号,静默丢弃任务
{
LockGuard lock(_p_mtx);
_rq[_p_site] = task;
_p_site = (_p_site + 1) % _cap;
_size++;
}
_exist_sem.V();
}
与 Pop() 对称,IsFull() 同样只在退出路径上才会为 true。被唤醒的生产者发现队列已满(无真实空位),静默返回,不写入任何数据。
(6)全景图
十、常见锁概念
1. 死锁
(1)死锁的概念
死锁是指两个或多个线程在执行过程中,因互相持有对方所需的资源且都不愿释放,导致所有线程永久阻塞、无法推进的状态。
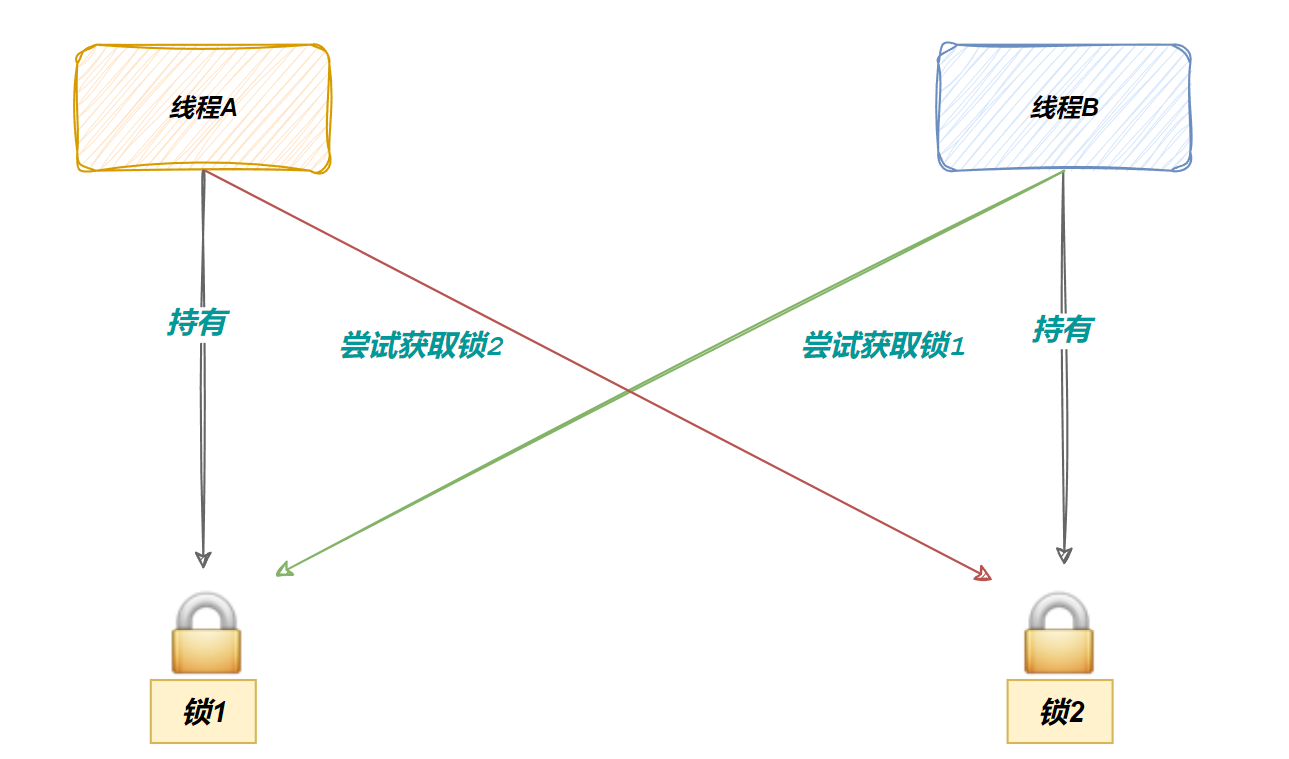
两个线程永远互相等待,谁也无法继续执行——程序既不报错、也不退出,只是静静地"卡死"在那里。
(2)四个必要条件
死锁的发生必须同时满足以下四个条件,缺少任意一个死锁就不会产生:
① 互斥条件(Mutual Exclusion)
资源在同一时刻只能被一个线程持有,其他线程必须等待。
// 互斥锁天然满足此条件
pthread_mutex_lock(&mutex); // 只有一个线程能进入② 请求与保持条件(Hold and Wait)
线程已经持有至少一个资源,同时又在请求新的资源,且在等待期间不释放已持有的资源。
pthread_mutex_lock(&lock1); // 持有 lock1
// ... 做一些事情 ...
pthread_mutex_lock(&lock2); // 持有 lock1 的同时,请求 lock2③ 不可剥夺条件(No Preemption)
线程已持有的资源不能被外部强制剥夺,只能由线程自己主动释放。
OS无法从线程A手中强行拿走 lock1 交给线程B,只能等线程A自己调用 unlock
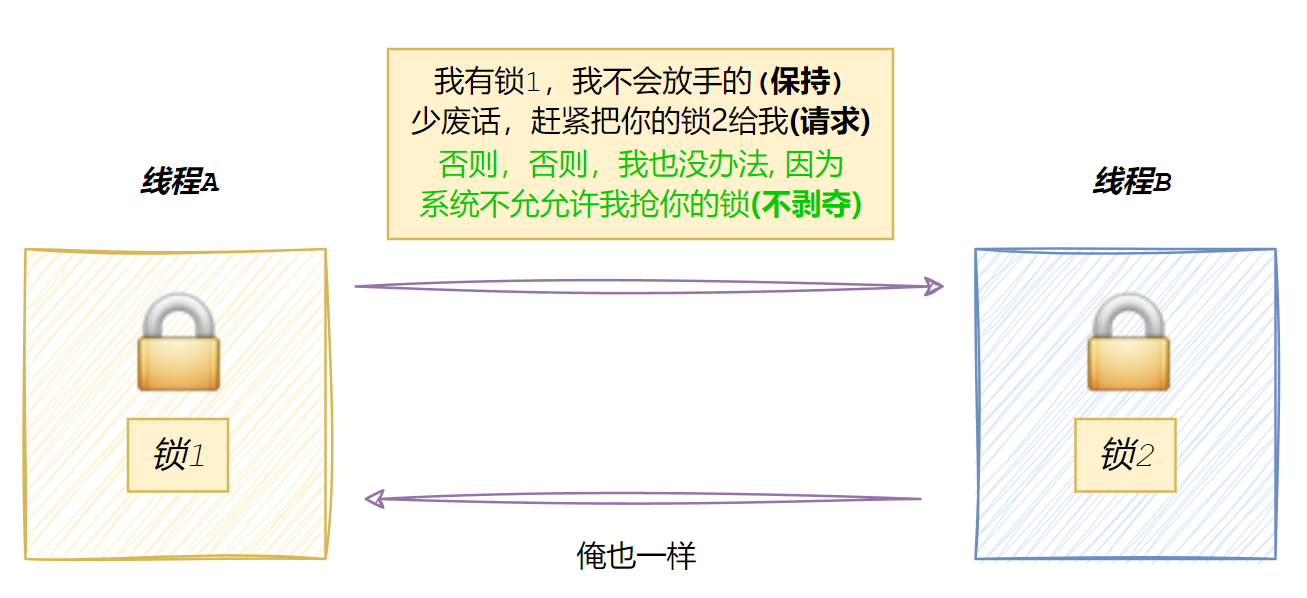
④ 循环等待条件(Circular Wait)
存在一条由线程和资源构成的循环等待链:线程A等线程B持有的资源,线程B等线程C持有的资源,……,最终线程N等线程A持有的资源。
线程A → 等待 → 线程B → 等待 → 线程C → 等待 → 线程A
(→ 表示"等待对方持有的资源")(3)避免死锁
对应四个必要条件,破坏其中任意一个即可避免死锁:
① 破坏互斥条件
将资源设计为可共享,例如只读数据允许多线程并发访问(读写锁中的读锁,后面讲)。但互斥往往是资源本身的属性,并非总能破坏。
pthread_rwlock_rdlock(&rwlock); // 多个读者可同时持有② 破坏请求与保持条件
一次性申请所有资源,若无法全部获得则一个都不持有:
// 要么全拿到,要么全不拿
if (trylock(lock1) && trylock(lock2))
{
// 安全执行
}
else
{
// 释放已持有的,稍后重试
unlock_all();
}③ 破坏不可剥夺条件
当线程请求新资源失败时,主动释放已持有的资源,之后重新申请:
pthread_mutex_lock(&lock1);
if (pthread_mutex_trylock(&lock2) != 0) // 尝试获取 lock2
{
pthread_mutex_unlock(&lock1); // 失败则释放 lock1
// 稍后重新申请
}
pthread_mutex_trylock与pthread_mutex_lock的对比pthread_mutex_lock(&mutex); // 抢不到锁 → 阻塞,死等 pthread_mutex_trylock(&mutex); // 抢不到锁 → 立即返回,不等// 返回值 int ret = pthread_mutex_trylock(&mutex); if (ret == 0) // 加锁成功,当前线程持有锁 if (ret == EBUSY) // 锁已被别人持有,本次尝试失败
④ 破坏循环等待条件(最实用)
对所有锁规定全局统一的加锁顺序,所有线程都按此顺序申请资源,循环链就无法形成:
// 规定:所有线程必须先加 lock1,再加 lock2,不允许反序
// 线程 A
pthread_mutex_lock(&lock1);
pthread_mutex_lock(&lock2);
// 线程 B(也必须遵守同样顺序)
pthread_mutex_lock(&lock1); // 而不是先加 lock2
pthread_mutex_lock(&lock2);(4)银行家算法
银行家算法是 Dijkstra 提出的死锁避免算法,其核心思想来源于银行放贷:银行不会把所有钱都贷出去,必须保留足够的准备金,确保客户能陆续还款,银行才能持续运转。对应到操作系统中,就是在每次分配资源前预判此次分配是否会导致系统进入不安全状态,若会则拒绝分配。不具体说了,有兴趣的伙伴可以自行了解。工程中较少直接使用,实际系统更多采用"破坏循环等待"等简单策略。
2. 自旋锁
(1)概念
自旋锁是一种忙等待锁:当线程尝试获取一个已被持有的锁时,它不会放弃 CPU、进入睡眠,而是在原地反复轮询锁的状态,直到锁被释放为止。
普通互斥锁(睡眠等待):线程B 抢锁失败 → 挂起,让出CPU → 等待OS唤醒 → 重新竞争
自旋锁(忙等待):线程B 抢锁失败 → 原地循环检查 → 检查 → 检查 → 锁释放 → 立即获取
(2)原理
自旋锁的底层依赖 CPU 提供的原子操作指令,最经典的是 CAS:CAS(addr, expected, new_val):若 *addr == expected ,将 *addr 改为 new_val,返回 true;否则,不做任何修改,返回 false。以上过程是原子的,不可被中断
// 自旋锁内部状态:0 = 未锁定,1 = 已锁定
atomic<int> flag = 0;
void lock()
{
// CAS:期望 flag==0,若是则改为1(加锁成功),否则继续循环
while (!CAS(flag, 0, 1))
{
// 自旋:反复尝试,直到成功
}
}
void unlock()
{
flag = 0; // 原子写,释放锁
}(3)优缺点及使用场景
自旋锁最大的优势在于没有上下文切换的开销。互斥锁竞争失败时,线程需要从用户态陷入内核态、挂起保存现场、等待调度器唤醒,整个过程耗时在微秒级;而自旋锁只是原地循环执行几条汇编指令,耗时在纳秒级。因此在临界区极短、多核高竞争的场景下,自旋锁的性能往往远优于互斥锁。此外,锁一旦释放,自旋线程能立即感知并获取,没有任何唤醒延迟。
但自旋锁的缺点同样明显。当锁被长时间持有时,等待的线程会持续占用 CPU 核心做无效循环,白白浪费算力。在单核 CPU 上情况更糟——持锁线程时间片耗尽被调度出去后,自旋线程会占满 CPU 导致持锁线程永远无法被调度,从而造成死锁。此外,若持锁期间发生 IO 或系统调用等阻塞操作,其他线程将在这段时间内持续空转,得不偿失。
因此,自旋锁适合的场景是:多核 CPU、临界区极短(纳秒级)、竞争激烈但持锁时间极短的情况,典型如内核中断处理程序(中断上下文本就不能睡眠)。反之,临界区较长、单核环境、或持锁期间存在阻塞操作的场景,应当选择互斥锁。
(4)demo测试
// POSIX 提供的自旋锁 API:
#include <pthread.h>
pthread_spinlock_t spinlock;
pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE);
pthread_spin_lock(&spinlock); // 加锁(自旋等待)
pthread_spin_trylock(&spinlock); // 尝试加锁(非阻塞)
pthread_spin_unlock(&spinlock); // 解锁
pthread_spin_destroy(&spinlock); // 销毁#include <iostream>
#include <pthread.h>
pthread_spinlock_t spinlock;
int g_count = 0;
void *Worker(void *arg)
{
for (int i = 0; i < 100000; i++)
{
pthread_spin_lock(&spinlock);
g_count++; // 临界区
pthread_spin_unlock(&spinlock);
}
return nullptr;
}
int main()
{
// 初始化自旋锁,PTHREAD_PROCESS_PRIVATE 表示仅用于同进程内的线程间
pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE);
pthread_t t1, t2;
pthread_create(&t1, nullptr, Worker, nullptr);
pthread_create(&t2, nullptr, Worker, nullptr);
pthread_join(t1, nullptr);
pthread_join(t2, nullptr);
std::cout << "g_count = " << g_count << std::endl;
pthread_spin_destroy(&spinlock);
return 0;
}3. 读写锁
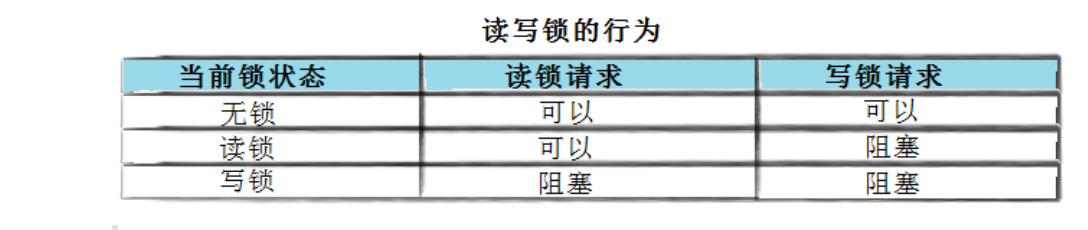
(1)读写者模型
在很多实际场景中,共享数据的访问模式并非完全对等——读操作远多于写操作,且多个线程同时读取同一个数据并不会引发任何冲突,真正需要互斥保护的只有写操作。若对读操作也一律加互斥锁,则读者所有强制串行执行,白白损失了许多性能。
读写器模型就是基于这个观察抽象的外部模型,将线程角色分为两类:读者(Reader)读写数据,写者(Writer)修改数据。核心规则只有三条:与读者之间可以共存;读者与写者之间必须互斥;读者与写者之间必须互斥。用一句话来说就是——读读共享,读者互斥,写写互斥。
另外,读写者模型还有一个经典的优先级问题:当读者和写者同时等待时,该先让谁进入?读者优先会导致写者长期饥饿(读者源不断时写者永远排不上);写者优先则可能让读者饥饿。实际工程中需根据业务特点选择策略,POSIX读写锁默认倾向于读者优先。
| 生产消费 | 读者写者 | |
|---|---|---|
| 数据流向 | 单向流动,任务被消耗 | 原地共享,数据长期存在 |
| 核心问题 | 供需同步 | 读写器权限互斥 |
| 典型工具 | 信号量 + 互斥锁 / 条件变量 | 锁读写器 |
| 读读关系 | 多消费者竞争,互斥取任务 | 多读者共享,阅读量 |
| 典型场景 | 线程池任务队列、消息队列 | 服务器、配置表、数据库查询 |
(2)读写锁
读写锁是读写器模型的直接实现,它在内部维护一个状态机,自动处理读写器与写者之间的算数关系,对外提供多种加锁接口:读锁(共享锁)和写锁(排他锁)。
(3)demo测试
// POSIX读写锁API:
#include <pthread.h>
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
pthread_rwlock_rdlock(&rwlock); // 加读锁(阻塞版)
pthread_rwlock_tryrdlock(&rwlock);// 加读锁(非阻塞版)
pthread_rwlock_wrlock(&rwlock); // 加写锁(阻塞版)
pthread_rwlock_trywrlock(&rwlock);// 加写锁(非阻塞版)
pthread_rwlock_unlock(&rwlock); // 解锁(读锁写锁统一调用)
pthread_rwlock_destroy(&rwlock); // 销毁#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include "./ThreadPool/log.hpp"
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
int g_data = 0;
void *Reader(void *arg)
{
int id = *(int *)arg;
while (1)
{
pthread_rwlock_rdlock(&rwlock);
// 读锁区间:多个读者可同时进入
LOG(LogLevel::Dedug) << "[读者 " << id << "] 读到数据: " << g_data;
sleep(1); // 模拟读耗时,此时其他读者仍可并发读
pthread_rwlock_unlock(&rwlock);
sleep(1);
}
return nullptr;
}
void *Writer(void *arg)
{
while (1)
{
sleep(1); // 模拟写的间隔
pthread_rwlock_wrlock(&rwlock);
// 写锁区间:独占,读者写者均被阻塞
g_data += 10;
LOG(LogLevel::Dedug) << "[写者] 写入数据: " << g_data;
pthread_rwlock_unlock(&rwlock);
}
return nullptr;
}
int main()
{
pthread_t readers[3], writer;
int ids[3] = {1, 2, 3};
for (int i = 0; i < 3; i++)
pthread_create(&readers[i], nullptr, Reader, &ids[i]);
pthread_create(&writer, nullptr, Writer, nullptr);
for (int i = 0; i < 3; i++)
pthread_join(readers[i], nullptr);
pthread_join(writer, nullptr);
pthread_rwlock_destroy(&rwlock);
return 0;
}4. 其它常见锁
| 锁名称 | 核心逻辑 |
| 递归锁 (Recursive Lock) | 允许同一个线程多次获取同一把锁,防止在递归调用中死锁。 |
| 乐观锁 (Optimistic Lock) | 假设不会冲突,只在更新时检查数据是否被改过(常用 CAS 实现)。 |
| 悲观锁 (Pessimistic Lock) | 假设一定会冲突,操作前必须先加锁(互斥锁、写锁都是此类)。 |
十一、线程安全
1. 对比重入函数

可重入与线程安全联系
- 函数是可重入的,那就是线程安全的
- 函数是不可重入的,那就不能由多个线程使用,有可能引发线程安全问题.
- 如果一个函数中有全局变量,那么这个函数既不是线程安全也不是可重入的。
可重入与线程安全区别
- 可重入函数是线程安全函数的一种
- 线程安全不一定是可重入的,而可重入函数则一定是线程安全的。
- 如果将对临界资源的访问加上锁,则这个函数是线程安全的,但如果这个重入函数若锁还未释放则会产生死锁,因此是不可重入的。
注意点:
- 如果不考虑信号导致一个执行流重复进入函数这种重入情况,线程安全和重入在安全角度不做区分
- 但是线程安全侧重说明线程访问公共资源的安全情况,表现的是并发线程的特点
- 可重入描述的是一个函数是否能被重复进入,表示的是函数的特点
2. 在STL中的问题
STL 容器本身不是线程安全的。
原因是,STL的设计初衷是将性能挖掘到极致,而一旦涉及到加锁保证线程安全,会对性能造成巨大的影响。而且对于不同的容器,加锁方式的不同,性能可能也不同(例如hash表的锁表和锁桶)。因此STL默认不是线程安全。如果需要在多线程环境下使用,往往需要调用者自行保证线程安全。
3. 在智能指针中的问题
-
引用计数:
std::shared_ptr的引用计数操作是原子的(线程安全)。 -
指向的对象:智能指针指向的内容不是线程安全的。如果你多个线程去改同一个
shared_ptr指向的对象,依然要加锁。 -
指针本身:多个线程并发读写同一个
shared_ptr对象本身(比如同时重定向指向不同的地址)不是线程安全的。 -
对于unique_ptr,由于只是在当前代码块范围内生效,因此不涉及线程安全问题。
后记:
系统部分在这里就正式结束了,大家要记得,底层的深度,决定了应用层的高度。 只有真正理解了底层,才能在面对复杂的系统 Bug 时,拥有那种“穿透迷雾”的底气。线程的学习虽然收官,但在高性能后端开发的征途中,这仅仅是一个基石。下一站,我将带着这份对底层原理的敬畏,去叩开网络编程与高并发服务器的大门。愿我们都能在并发的荒原上,构筑出最稳固的秩序!
Linux系统编程,杀青!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 49
49 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)