【GR系列 NVIDIA】
文章目录
- GR 系列调研:NVIDIA GR00T 与傅利叶 GRx
GR 系列调研:NVIDIA GR00T 与傅利叶 GRx
本文档系统梳理 GR 系列相关研究,涵盖 NVIDIA GR00T(通用人形机器人基础模型)和傅利叶 GRx(通用人形机器人硬件平台)两条主线。按时间线组织,每篇论文包含论文链接、痛点、创新点和方法详解。
1. 背景与概述
GR 系列代表了两条互补的研究路径:
- NVIDIA GR00T: 软件/算法层面的通用机器人基础模型 (Foundation Model,指在大规模多源数据上预训练、可适配多种下游任务的大模型),目标是构建"一种模型适配多种机器人"的 VLA (Vision-Language-Action,视觉-语言-动作模型——将图像感知、语言理解和动作执行统一到一个端到端框架中) 架构
- 傅利叶 GRx: 硬件/平台层面的通用人形机器人系列,为算法验证和部署提供物理载体
两者的交汇点在于:GR00T N1 的核心评估和部署就是在傅利叶 GR-1 人形机器人上完成的。换言之,算法与硬件从设计之初便形成闭环——GR-1 提供"身体"和真实世界反馈,GR00T N1 提供"大脑"和决策能力。

核心问题
| 问题 | 描述 |
|---|---|
| 数据稀缺 | 机器人操作数据采集依赖遥操作(即人类远程操控机器人执行任务并记录轨迹),成本高、规模小,远不及自然语言/视觉领域 |
| 跨平台泛化 | 不同机器人形态 (morphology,指机器人的身体结构——关节数量、自由度分布、肢体长度等) 差异大,单一策略难以迁移 |
| Sim-to-Real Gap | 仿真中训练的策略在真实世界性能下降,原因包括仿真物理模型简化、视觉渲染差异、传感器噪声等 |
| 实时性要求 | 人形机器人需要 10-50Hz 的实时控制频率,大模型推理延迟是瓶颈 |
| 长程任务 | 复杂操作需要多步骤规划与错误恢复能力,当前模型在 50+ 步任务中错误累积严重 |
2. 2024: Project GR00T 启动
GR(Generalist Robot,通用机器人)00T:《银河护卫队》中的角色
2.1 Project GR00T 发布 (GTC 2024)
时间: 2024年3月18日 (GTC 2024)
NVIDIA CEO 黄仁勋在 GTC 2024 上发布 Project GR00T,定位为"通用人形机器人基础模型"。同时宣布与多家机器人公司(包括傅利叶智能、Unitree、Agility Robotics 等)的合作,标志着 NVIDIA 正式从芯片供应商进入具身智能算法栈。
2.2 Bringing Robots Home: The Rise of AI Robots in Consumer Electronics
- 论文: arXiv:2403.14449
- 作者: Dong, Liu, Chu, Saddik
- 类型: 综述/评论
痛点: 家用机器人长期停留在实验室和工业场景,难以进入消费级市场。核心瓶颈在于:家用环境的非结构化程度远超工厂,机器人需要处理开放集物体、不确定布局和动态人类活动。
核心观点: NVIDIA Project GR00T 和 Tesla Optimus Gen 2 代表了人形机器人从工业走向家庭的新趋势,但环境复杂性和系统集成难度仍是核心挑战。文章指出,硬件成本下降和大模型能力提升正在同时推动这一拐点的到来。
3. 2025 Q1: GR00T N1 — 开源基础模型
3.1 GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
- 论文: arXiv:2503.14734
- 模型: HuggingFace: nvidia/GR00T-N1-2B
- 作者: NVIDIA GEAR Lab
- 数据集: nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim

图解: GR00T N1 采用双系统架构,左侧 System 2 (绿色) 为基于 Eagle-2 的 VLM 模块,负责接收图像和语言指令,进行环境理解和任务分解,输出语义特征;右侧 System 1 (紫色) 为 Diffusion Transformer,接收 VLM 特征和机器人状态,通过 Flow Matching 迭代去噪生成连续动作序列。两系统通过特征传递连接,实现了"慢思考(推理) + 快行动(执行)"的分工。
痛点:
- 现有 VLA 模型(如 OpenVLA、RT-2)参数量有限,泛化能力不足——在训练分布外的任务和环境中表现急剧下降
- 机器人数据规模远小于自然语言/视觉数据,模型难以学到通用操作知识(Open X-Embodiment 数据集约 100 万 episodes,而语言模型预训练数据达万亿 token 级别)
- 单系统架构难以同时兼顾高层语义理解和低层实时控制——语义推理需要深度但缓慢,动作生成需要快速但轻量
创新点:
- 双系统架构 (Dual-System Architecture): 借鉴认知科学中 Kahneman "快思考/慢思考"范式,将感知推理与动作执行解耦
- System 2 (慢思考): Vision-Language Module — 基于 Eagle-2 VLM backbone,负责环境理解、任务分解和语义推理,运行频率约 1-2Hz
- System 1 (快行动): Diffusion Transformer (DiT) — 基于 Flow Matching 的动作生成模块,负责实时连续动作输出,运行频率可达 10-50Hz
- 开源: 首个开源的人形机器人 VLA 基础模型 (2B 参数,BF16 精度——即 Bfloat16,一种 16 位浮点格式,在深度学习训练中兼顾数值范围和精度)
- 跨平台验证: 在多种机器人平台上验证(GR-1、Franka 等),证明同一模型架构可适配不同形态的机器人
方法详解:
双系统架构
System 2 的 VLM 接收图像观测 I t I_t It 和语言指令 ℓ \ell ℓ,输出语义特征 f VLM \mathbf{f}_{\text{VLM}} fVLM:
f VLM = VLM ( I t , ℓ ) \mathbf{f}_{\text{VLM}} = \text{VLM}(I_t, \ell) fVLM=VLM(It,ℓ)
System 1 的 DiT 接收 VLM 特征、机器人状态 s t \mathbf{s}_t st 和噪声动作 a t ( k ) \mathbf{a}_t^{(k)} at(k),通过 Flow Matching 迭代去噪生成动作序列:
a t ( k + 1 ) = a t ( k ) + α ⋅ v θ ( a t ( k ) , s t , f VLM , k ) \mathbf{a}_t^{(k+1)} = \mathbf{a}_t^{(k)} + \alpha \cdot v_\theta(\mathbf{a}_t^{(k)}, \mathbf{s}_t, \mathbf{f}_{\text{VLM}}, k) at(k+1)=at(k)+α⋅vθ(at(k),st,fVLM,k)
其中 v θ v_\theta vθ 是 DiT 预测的速度场 (velocity field,描述从噪声分布到目标动作分布的向量场方向), k k k 是去噪步数, α \alpha α 是步长参数。
Flow Matching

图解: GR00T N1 选用 Flow Matching 而非传统 DDPM 作为动作生成方式。左侧 DDPM (Denoising Diffusion Probabilistic Models,去噪扩散概率模型) 需要逐步预测噪声并进行 50-1000 步去噪,推理速度慢且离散时间步导致动作连续性差;右侧 Flow Matching (Continuous Normalizing Flows,连续归一化流框架) 直接学习从噪声到动作的连续向量场,仅需 4-10 步积分即可生成动作,推理速度快且动作轨迹更平滑——这对于需要 10-50Hz 实时控制的人形机器人至关重要。
与 DDPM 不同,Flow Matching 使用连续归一化流框架,直接学习从噪声分布到动作分布的向量场:
- 给定噪声样本 a ( K ) ∼ N ( 0 , I ) \mathbf{a}^{(K)} \sim \mathcal{N}(0, \mathbf{I}) a(K)∼N(0,I)
- 通过 K K K 步积分得到干净动作: a ( 0 ) = a ( K ) + ∫ 0 1 v θ ( a ( t ) , t ) d t \mathbf{a}^{(0)} = \mathbf{a}^{(K)} + \int_0^1 v_\theta(\mathbf{a}^{(t)}, t) \, dt a(0)=a(K)+∫01vθ(a(t),t)dt
- 离散化近似: a ( k − 1 ) = a ( k ) + 1 K v θ ( a ( k ) , k K ) \mathbf{a}^{(k-1)} = \mathbf{a}^{(k)} + \frac{1}{K} v_\theta(\mathbf{a}^{(k)}, \frac{k}{K}) a(k−1)=a(k)+K1vθ(a(k),Kk)
训练目标是最小化速度场预测误差:
L = E k , a ( 0 ) , a ( k ) [ ∥ v θ ( a ( k ) , k ) − ( a ( 0 ) − a ( k ) ) ∥ 2 ] \mathcal{L} = \mathbb{E}_{k, \mathbf{a}^{(0)}, \mathbf{a}^{(k)}} \left[ \| v_\theta(\mathbf{a}^{(k)}, k) - (\mathbf{a}^{(0)} - \mathbf{a}^{(k)}) \|^2 \right] L=Ek,a(0),a(k)[∥vθ(a(k),k)−(a(0)−a(k))∥2]
Action Chunking
模型预测一段动作序列 a t : t + H \mathbf{a}_{t:t+H} at:t+H (horizon H H H,即动作预测的时间跨度),而非单步动作。这种方式称为 Action Chunking(动作分块),其核心优势在于:① 减少规划频率——不必每个控制步都调用策略网络;② 提高动作连贯性——chunk 内的动作是一起生成的,避免了逐帧决策的抖动;③ 更符合人类操作习惯——人类执行复杂操作时也是一次性规划多步。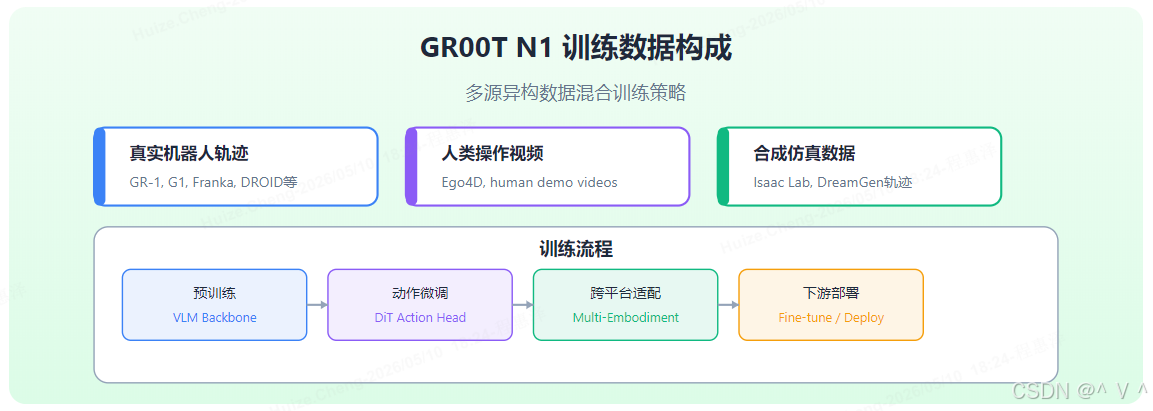
图解: GR00T N1 的训练采用多源异构数据混合策略,包括真实机器人轨迹(GR-1, G1, Franka, DROID 等)、人类操作视频(Ego4D 等)和合成仿真数据(Isaac Lab, DreamGen 轨迹)。训练流程分四阶段:预训练 VLM Backbone → 动作微调 DiT Action Head → 跨平台适配 → 下游部署 Fine-tune。这种多源混合训练是 GR00T 实现跨平台泛化的关键。
性能:
- 在仿真基准 (LIBERO、SimplerEnv) 上超越 ACT、Diffusion Policy 等模仿学习基线
- 在 GR-1 人形机器人上实现双臂操作的高数据效率——仅需少量遥操作演示即可学会复杂操作任务
- 开源 2B 参数模型,支持 LoRA (Low-Rank Adaptation,低秩适配——通过仅训练少量参数的高效微调方法,冻结预训练权重,仅更新低秩分解矩阵) 微调
4. 2025 Q2: GR00T N1.5 — 扩展与增强
4.1 GR00T N1.5
- 模型: HuggingFace: nvidia/GR00T-N1.5-3B
- 参数: 3B (BF16)
- VLM Backbone: Eagle-2
- 关联论文: Eagle 2: Building Post-Training Data Strategies from Scratch (arXiv:2501.14818)
与 N1 的核心区别:
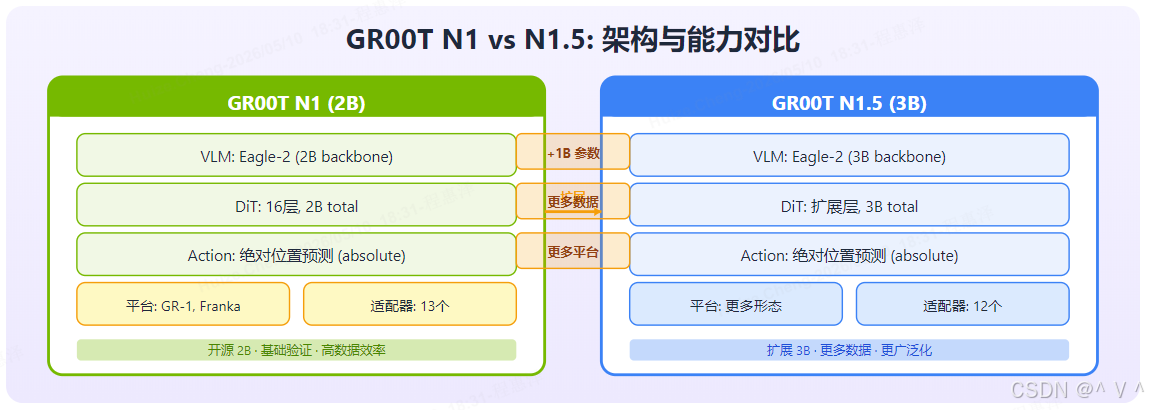
图解: GR00T N1.5 相比 N1 的核心变化体现在三个方面:① 参数从 2B 扩展到 3B(黄色标注 “+1B 参数”),增强了模型容量和表征能力;② 训练数据规模大幅扩展,涵盖更多跨平台遥操作数据(黄色标注 “更多数据”);③ 支持更多机器人形态适配(黄色标注 “更多平台”)。VLM backbone 均使用 Eagle-2,动作表示均为绝对位置预测。N1.5 定位为"扩展版",在基础架构不变的前提下通过规模提升实现更强泛化。
- 参数扩展: 从 2B 扩展到 3B,增强模型容量——更多参数意味着更强的函数逼近能力和更丰富的内部表征
- 训练数据扩展: 更多跨平台遥操作数据(人形机器人、移动操作臂、双臂平台),数据多样性是泛化的关键
- 增强跨平台泛化: 支持更多机器人形态适配,包括单臂、双臂和人形平台
- HuggingFace 生态: 提供 12 个 Adapter(适配器,针对特定平台/任务的轻量级微调模块)和 38 个 Finetune(社区贡献的全量微调版本)变体
关键指标:
- 模型规模: 3B 参数
- 精度: BF16
- 适配器 (Adapters): 12 个预训练适配器——每个适配器针对特定机器人平台优化,以 LoRA 方式叠加在基础模型上
- 微调 (Finetunes): 38 个社区微调版本——覆盖不同任务和场景的定制化模型
- 训练数据集: PhysicalAI-Robotics-GR00T-X-Embodiment-Sim——NVIDIA 发布的大规模跨平台机器人仿真数据集
5. 2025: DreamGen — 合成数据突破
5.1 DreamGen: Unlocking Generalization in Robot Learning through Video World Models
- 论文: arXiv:2505.12705
- 代码: GitHub: NVIDIA/GR00T-Dreams
- 作者: NVIDIA GEAR Lab
- 项目页: research.nvidia.com/labs/gear/dreamgen
痛点:
- 机器人操作数据采集依赖遥操作,成本高、规模小——采集一小时高质量遥操作数据可能需要数小时的准备和校准
- 现有合成数据方法难以保证动作一致性——视频生成模型可以生成视觉上合理的视频,但其中的"伪动作"可能不符合物理约束
- 新环境、新行为的泛化需要额外数据,但获取困难——每当需要新技能或新场景时,都需要重新采集数据
创新点:
- “神经轨迹” (Neural Trajectories): 通过视频世界模型生成合成轨迹,解决数据规模瓶颈——无需额外遥操作,仅凭单张图像和语言指令即可生成完整的操作演示
- 四阶段管道: 完整的从世界模型到策略训练的闭环,每一步都有明确的数学目标和质量保证
- DreamGen Bench: 评估视频生成质量与下游策略成功率的关联,发现相关性 r > 0.8 r > 0.8 r>0.8,验证了合成数据质量对策略性能的直接影响
方法详解:
四阶段管道
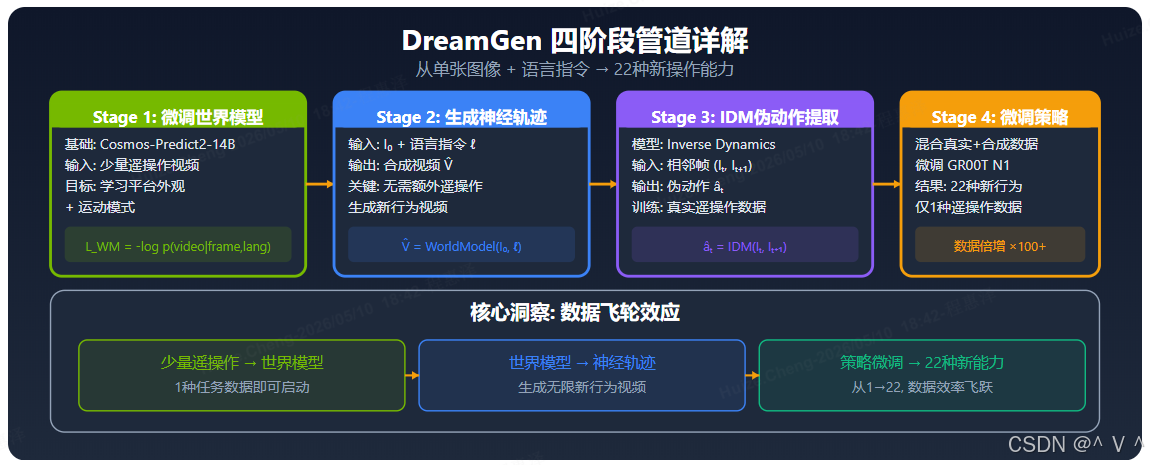
图解: DreamGen 的核心是四阶段数据飞轮。Stage 1(绿色):在少量真实遥操作数据上微调 Cosmos-Predict2-14B 世界模型,使其学会目标机器人平台的视觉外观和运动模式。Stage 2(蓝色):给定单张图像和语言指令,微调后的世界模型生成新的操作视频——即"神经轨迹",无需额外遥操作。Stage 3(紫色):使用 Inverse Dynamics Model (IDM) 从合成视频的相邻帧中恢复伪动作序列。Stage 4(橙色):将真实数据与合成数据混合微调 GR00T N1。底部展示了数据飞轮效应:1种遥操作数据 → 世界模型 → 神经轨迹 → 22种新操作能力。
阶段1: 微调视频世界模型 → 阶段2: 生成合成视频 → 阶段3: IDM提取伪动作 → 阶段4: 微调GR00T N1
阶段 1 — 微调世界模型:
使用 Cosmos-Predict2 作为视频世界模型基础(Cosmos-Predict2 是 NVIDIA 开发的基于 Diffusion Transformer 的视频预测模型,14B 参数),在目标机器人平台的少量遥操作数据上微调,使其学会该平台的视觉外观和运动模式:
L WM = E τ ∼ D real [ − log p θ ( video ∣ first_frame , language ) ] \mathcal{L}_{\text{WM}} = \mathbb{E}_{\tau \sim \mathcal{D}_{\text{real}}} \left[ -\log p_\theta(\text{video} \mid \text{first\_frame}, \text{language}) \right] LWM=Eτ∼Dreal[−logpθ(video∣first_frame,language)]
阶段 2 — 生成合成视频:
给定单张图像和语言指令,微调后的世界模型生成新的操作视频(“神经轨迹”):
V ^ = WorldModel ( I 0 , ℓ ) \hat{V} = \text{WorldModel}(I_0, \ell) V^=WorldModel(I0,ℓ)
其中 I 0 I_0 I0 是初始帧, ℓ \ell ℓ 是语言指令, V ^ \hat{V} V^ 是生成的视频序列。
阶段 3 — 伪动作提取:
使用 IDM (Inverse Dynamics Model,逆动力学模型——从相邻观测帧推断产生该状态转移所需的动作) 或 Latent Action Model(潜动作模型——在潜空间中学习帧间动作表示)从合成视频中恢复伪动作序列:
a ^ t = IDM ( I t , I t + 1 ) \hat{\mathbf{a}}_t = \text{IDM}(I_t, I_{t+1}) a^t=IDM(It,It+1)
IDM 的训练利用已有的遥操作数据 ( I t , a t , I t + 1 ) (I_t, \mathbf{a}_t, I_{t+1}) (It,at,It+1),学习从相邻帧推断动作的映射。其核心假设是:如果两帧之间的视觉变化与某已知动作产生的视觉变化一致,则可推断该帧间发生了类似动作。
阶段 4 — 微调 GR00T N1:
将合成数据 ( I t , a ^ t , ℓ ) (I_t, \hat{\mathbf{a}}_t, \ell) (It,a^t,ℓ) 与真实数据混合,微调 GR00T N1 策略。混合比例是关键设计选择——过多合成数据会降低策略质量,过少则无法充分利用数据扩展的优势。
关键发现
- 人形机器人仅需一个 pick-and-place 任务的遥操作数据,就能通过 DreamGen 执行 22 种新行为——这是"数据倍增效应"的极致体现
- DreamGen Bench 显示视频生成质量与下游策略成功率高度相关 ( r > 0.8 r > 0.8 r>0.8),验证了合成数据质量对策略性能的直接影响
- Cosmos-Predict2-14B 作为世界模型效果最佳,更大的模型容量带来了更准确的视频预测和更一致的动作生成
6. 2025: 生态与工具链
6.1 GR00T 生态工具链
NVIDIA 围绕 GR00T 构建了完整的工具链生态系统,覆盖从数据采集到部署的全流程: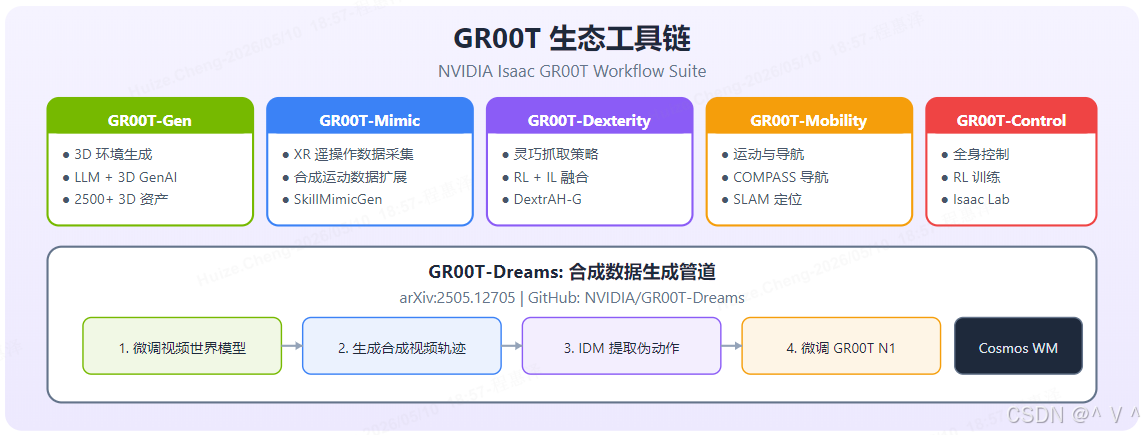
| 工具 | 功能 | 核心技术 |
|---|---|---|
| GR00T-Gen | 多样化环境生成 | LLM + 3D GenAI,2500+ 3D 资产,150+ 物体类别——通过语言描述自动生成多样化 3D 仿真场景 |
| GR00T-Mimic | 遥操作数据采集与扩展 | XR (Apple Vision Pro) 遥操作,SkillMimicGen 合成扩展——从少量演示自动生成大量变体轨迹 |
| GR00T-Dexterity | 灵巧操作策略 | DextrAH-G,RL + IL 融合,pixels-to-action 抓取——直接从像素到抓取动作的端到端学习 |
| GR00T-Mobility | 运动与导航 | COMPASS 导航(基于合成数据的导航策略),CUDA-accelerated SLAM(GPU 加速的同步定位与建图) |
| GR00T-Control | 全身控制 (WBC) | Isaac Lab RL 训练,多机器人适配——Whole-Body Control 即同时协调所有关节实现自然运动 |
| GR00T-Perception | 多模态感知 | 深度传感器融合,视觉定位——将 RGB、深度、IMU 等多源信息统一处理 |
6.2 ARMOR: Egocentric Perception for Humanoid Robot Collision Avoidance and Motion Planning
- 论文: arXiv:2412.00396
- 作者: Kim, Srouji, Chen, Zhang
- 部署平台: 傅利叶 GR-1
痛点: 人形机器人在密集环境中的感知和运动规划能力不足,容易发生碰撞。传统方案依赖外部固定深度相机阵列,存在感知盲区大(机器人自身手臂遮挡)、碰撞率高等问题。
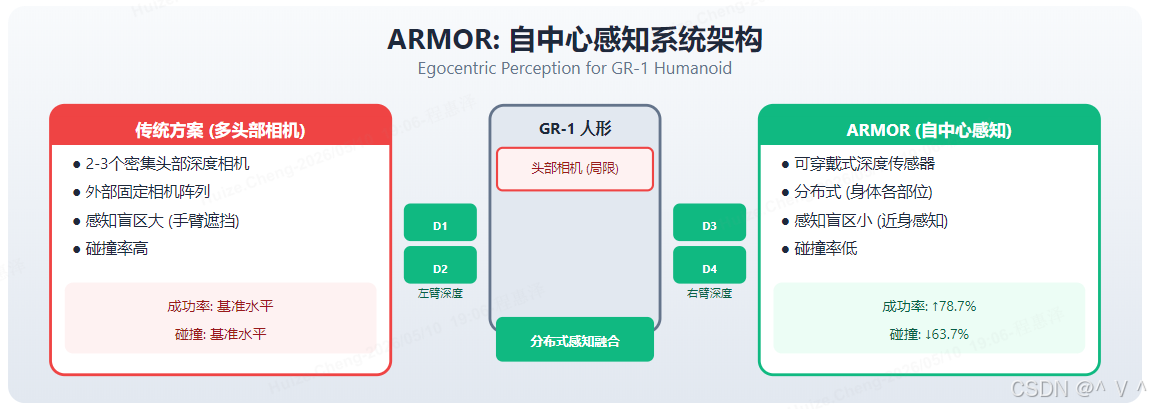
图解: ARMOR 的核心创新在于将感知方式从"多头部相机"(左侧红色区域)转向"可穿戴式深度传感器"(右侧绿色区域)。传统方案使用 2-3 个密集头部深度相机加外部固定阵列,存在感知盲区大(手臂遮挡)、碰撞率高等问题。ARMOR 在 GR-1 人形机器人的左臂(D1、D2)和右臂(D3、D4)部署可穿戴式深度传感器,通过分布式感知融合实现近身感知,大幅减少盲区。右侧数据显示 ARMOR 相比传统方案碰撞减少 63.7%、成功率提升 78.7%。
创新点:
- 自中心感知系统 (Egocentric Perception): 集成可穿戴式深度传感器——"自中心"指传感器安装在机器人自身身体上(而非外部固定架),感知坐标系与机器人身体一致
- 分布式感知: 在双臂部署传感器,增强空间感知能力,实现更灵活的运动规划——消除了传统集中式感知的盲区问题
- Transformer IL 策略: 利用 AMASS 数据集 86 小时的人体运动数据训练——通过模仿人类运动模式学习自然且安全的避碰策略
方法:
- 基于 AMASS 数据集的人体运动进行模仿学习 (IL,Imitation Learning——从演示数据中学习策略,而非通过奖励信号强化学习)
- 在仿真中训练动态避碰策略
- 使用 cuRobo 作为采样式运动规划基准——cuRobo 是 NVIDIA 开发的 CUDA 加速机器人运动规划库
性能:
- 碰撞减少 63.7%,成功率提升 78.7%(对比密集头部+外部深度相机)——分布式感知消除了手臂遮挡带来的感知盲区
- 对比 cuRobo: 碰撞减少 31.6%,成功率提高 16.9%,延迟降低 26x——学习策略比采样式规划更高效
7. 2026 Q1: GR00T N1.6 — Sim-to-Real 闭环
7.1 GR00T N1.6: Building Generalist Humanoid Capabilities
- 模型: HuggingFace: nvidia/GR00T-N1.6-3B
- 博客: NVIDIA Technical Blog (2026.01.08)
- 参数: 3B (BF16)
- VLM Backbone: Cosmos-Reason-2B (替代 Eagle-2)
- 关联论文: Eagle 2.5 (arXiv:2504.15271)
痛点:
- 之前版本视觉感知存在畸变——Eagle-2 需要将图像裁剪到固定尺寸输入,导致空间信息丢失,影响精细操作精度
- 动作生成存在抖动 (jitter),运动不够流畅——DiT 层数不足导致动作序列缺乏时间连续性
- 跨平台泛化仍有提升空间,特别是全身运动-操作协同 (Loco-Manipulation)
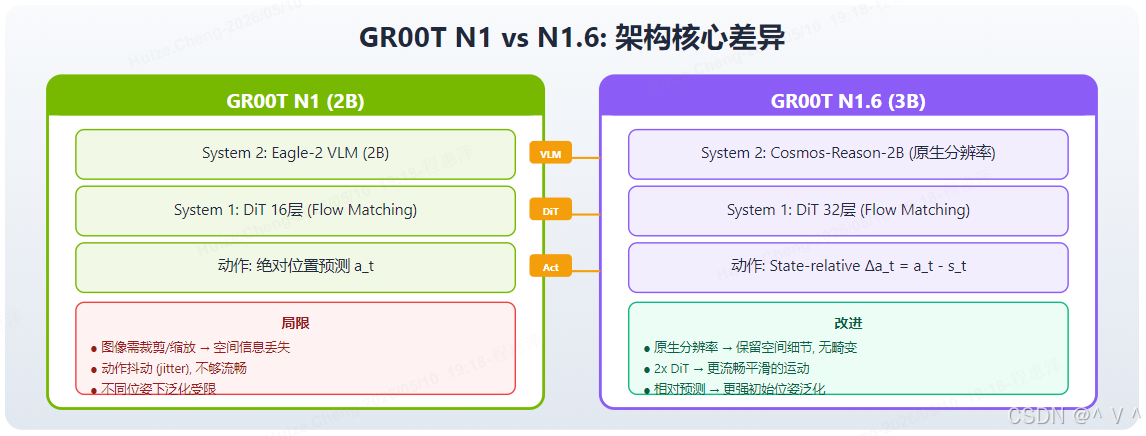
图解: GR00T N1.6 相比 N1 有三处核心架构变更。① VLM 层(黄色 “VLM” 标注):从 Eagle-2 替换为 Cosmos-Reason-2B,支持原生分辨率视觉输入——无需裁剪/缩放图像,保留空间细节无畸变。② DiT 层(黄色 “DiT” 标注):从 16 层扩展到 32 层(2x),更深的网络生成更流畅平滑的运动。③ 动作表示层(黄色 “Act” 标注):从绝对位置预测 a t a_t at 改为 State-relative 增量预测 Δ a t = a t − s t \Delta a_t = a_t - s_t Δat=at−st,不同初始位姿下的泛化能力更强。右侧绿色区域总结了三项改进的具体效果。
创新点:
- Cosmos-Reason-2B VLM: 替代 Eagle-2,支持原生分辨率视觉输入
- "原生分辨率"意味着无需将图像裁剪/缩放到固定尺寸,保留空间细节无畸变——这对需要精确定位的抓取和插入任务至关重要
- Cosmos-Reason 还内置了物理推理能力,能更好地理解物体间的空间关系和物理交互
- 2x 更大的 DiT: 32 层 Diffusion Transformer(相比 N1 的 16 层),更流畅的运动生成——更深的网络能更好地建模动作序列的时间连续性
- State-relative 动作预测: 动作预测相对于当前机器人状态,而非绝对位置
- 数学上: a ^ t = a t − s t \hat{\mathbf{a}}_t = \mathbf{a}_t - \mathbf{s}_t a^t=at−st,预测增量而非绝对值
- 优势: 不同初始位姿下的泛化能力更强——同样的"向前移动 5cm"指令,无论手臂当前在何处,增量表示都一致;而绝对位置表示则因初始位置不同而需要不同的目标值
- 完整的 Sim-to-Real 工作流: 整合 Isaac Lab RL 训练、COMPASS 导航和 CUDA SLAM
方法详解:
Sim-to-Real 工作流
Isaac Lab RL训练 (全身控制) → COMPASS导航 (合成数据) → CUDA SLAM (视觉定位) → 真实部署
- 全身控制 (Whole-Body Control): 在 Isaac Lab 中使用 RL (Reinforcement Learning,强化学习) 训练全身运动策略——同时协调所有关节实现自然运动,而非分别控制行走和操作
- COMPASS 导航: 使用合成数据训练导航策略,适应不同环境——COMPASS 是 NVIDIA 开发的基于合成场景的导航策略训练框架
- 视觉定位: CUDA 加速的 Visual SLAM (Simultaneous Localization and Mapping,同步定位与建图) 提供环境感知——GPU 加速使 SLAM 达到实时性能
- Loco-Manipulation: 以上模块协同实现运动-操作一体化——机器人在移动的同时执行操作任务,而非"走到位→停下→操作"的分离模式
训练数据
GR00T N1.6 的训练数据涵盖:
| 数据类型 | 来源 |
|---|---|
| 仿真环境 | BEHAVIOR, RoboCasa, GR-1 自定义仿真 |
| 真实遥操作 | GR-1 (Fourier), G1 (Unitree), YAM 双臂, Agibot, DROID |
| 合成轨迹 | DreamGen 神经轨迹 |
HuggingFace 生态
- 15 个微调变体——每个针对不同机器人平台和任务场景优化
- 2 个量化版本——降低模型精度以减少内存占用和推理延迟,适合边缘设备部署
- 与 N1.5 共享训练数据集: PhysicalAI-Robotics-GR00T-X-Embodiment-Sim
8. 2026: 基于 GR00T 的前沿研究
2026 年涌现了大量基于 GR00T N1/N1.5/N1.6 的前沿研究,以下按方向分类。
8.1 模型架构改进
VLA-0: Building State-of-the-Art VLAs with Zero Modification
- 论文: arXiv:2510.13054
- 作者: Goyal, Hadfield, Yang, Blukis, Ramos
痛点: 现有 VLA 需要修改词表 (vocabulary,即模型可输出的 token 集合) 或添加特殊 action head(专用的动作输出模块),设计复杂且破坏了 VLM 原有的生成能力。
创新: 将机器人动作直接表示为文本 token(即语言模型可理解的最小语义单元),无需修改 VLM 架构。核心思想是:动作本质上是一组数值,可以将其离散化后映射到已有词表中的 token,这样 VLM 的预训练语言生成能力便可以无损失地用于动作生成。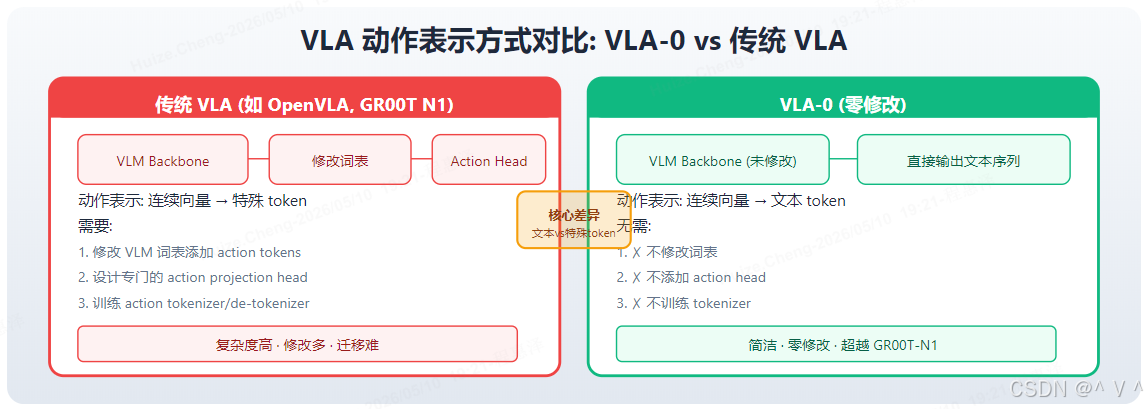
图解: 左侧为传统 VLA 架构,需要在预训练 VLM 基础上添加专用的 action head(如扩散头、连续输出头),并修改词表以支持动作 token,设计复杂且破坏了 VLM 原生结构。右侧为 VLA-0 的核心创新——将连续动作离散化为文本 token 序列,VLM 直接输出动作 token,无需任何架构修改。这种方式保留了 VLM 的原生生成能力,使得 VLM 的预训练知识可以无损失地迁移到动作生成任务中,在 LIBERO 上甚至超越了 pi_0 和 GR00T-N1 等专用 VLA 模型。
方法:
- 动作离散化为文本 token: a t → token_sequence \mathbf{a}_t \rightarrow \text{token\_sequence} at→token_sequence——将连续的动作值(如关节角度)量化为离散区间,每个区间对应一个已有 token
- VLM 直接输出动作 token 序列——复用 VLM 的自回归解码器,无需额外模块
- 在 LIBERO 上超越 pi_0.5-KI、OpenVLA-OFT、SmolVLA
- 甚至在无大规模机器人数据训练下超越 pi_0、GR00T-N1——证明 VLM 的预训练知识对动作生成有直接帮助
Dream-VLA: Diffusion Language Model Backbone for VLAs
- 论文: arXiv:2512.22615
- 作者: Ye, Gong, Gao, Fan, Wu, Bi, Bai, Shang, Kong
痛点: 自回归 (AR,Autoregressive) VLA 在动作生成本质上是并行的——一个 Action Chunk 中的多个动作 token 可以同时预测,但被迫使用串行解码(每个 token 必须等待前一个 token 生成完毕才能开始),导致推理效率低下。
创新: 使用扩散语言模型 (dLLM,diffusion Language Model) 作为 VLA backbone,原生支持并行动作生成。dLLM 与传统 AR 模型的核心区别在于注意力机制:AR 使用因果掩码(只能看到之前的 token),dLLM 使用双向注意力(可以看到所有 token),这使得同一 chunk 中的动作 token 可以相互参考、并行生成。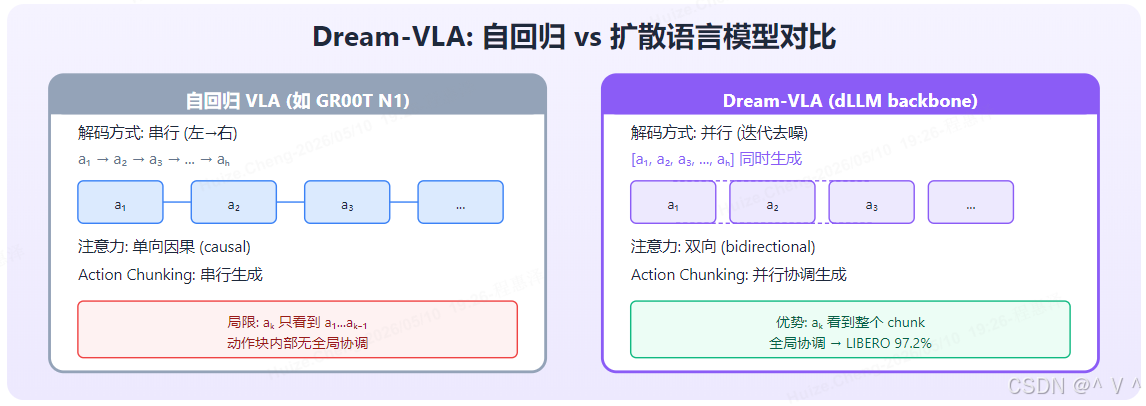
图解: 左侧展示传统自回归 (AR) VLA 的串行解码过程——动作 chunk a 1 , a 2 , a 3 \mathbf{a}_1, \mathbf{a}_2, \mathbf{a}_3 a1,a2,a3 必须逐个生成,每个 token 依赖前一个 token 的输出,导致推理延迟随 chunk 长度线性增长。右侧展示 Dream-VLA 的创新——使用扩散语言模型 (dLLM) 的双向注意力机制,所有动作 token 可并行生成,推理延迟大幅降低。dLLM 的掩码模式天然适配 action chunking,因为动作序列本质上是并行可预测的(而非逐帧依赖),这使得 Dream-VLA 在 LIBERO 上达到 97.2% 的成功率。
方法:
- dLLM 的双向注意力天然适配 Action Chunking——chunk 内所有动作 token 可通过一次前向传播并行生成
- Dream-VLA 在 LIBERO 达 97.2%,SimplerEnv-Bridge 达 71.4%
- 超越 pi_0 和 GR00T-N1
XR-1: Unified Vision-Motion Representations
- 论文: arXiv:2511.02776
痛点: VLA 中视觉感知与运动执行之间存在表示鸿沟 (representation gap)。视觉编码器提取的是"看到什么"的语义特征(如物体类别、位置),而动作解码器需要的是"如何操作"的运动特征(如关节速度、力矩方向),两者处于不同的语义空间,信息传递效率低。
创新: 统一的视觉-运动表示 (Unified Vision-Motion Representation),桥接感知与执行的语义鸿沟。核心思想是:在 VLM 的特征空间中引入运动感知维度,使视觉特征不仅编码"看到了什么",还隐式编码"该如何动"——这种统一的表示使得从感知到动作的映射更加直接和高效。
8.2 效率与推理优化
Latent Bridge: Feature Delta Prediction
- 论文: arXiv:2605.02739
痛点: 双系统 VLA 中 VLM 在每个控制步都执行完整前向传播,产生大量冗余计算。实际上,在连续控制中相邻帧的视觉变化通常很小(机器人手臂微动),VLM 输出的语义特征高度相似,每次重新计算整个 VLM 是巨大的计算浪费。
创新: 轻量级 Latent Bridge 模型预测 VLM 输出的特征增量 (feature delta),减少冗余前向传播。核心思想类似于视频压缩中的 P帧——只编码帧间差异,而非完整帧。
图解: 上方展示标准双系统 VLA 的推理流程——每个控制步 t t t 都需要完整执行 VLM 前向传播,从图像和语言输入中提取语义特征 f t \mathbf{f}_t ft,这在机器人连续控制中产生大量冗余计算。下方展示 Latent Bridge 的核心优化——仅在初始步执行完整 VLM 推理,后续步通过轻量级 Bridge 模型预测特征增量 Δ f t \Delta\mathbf{f}_t Δft,即 f t ≈ f t − 1 + Δ f t \mathbf{f}_t \approx \mathbf{f}_{t-1} + \Delta\mathbf{f}_t ft≈ft−1+Δft。当场景变化微小时(如仅手臂微动),Bridge 模型可准确预测增量,大幅降低推理延迟,同时保持策略性能不受损。
方法:
- 当场景变化小时: f t ≈ f t − 1 + Δ f t \mathbf{f}_t \approx \mathbf{f}_{t-1} + \Delta\mathbf{f}_t ft≈ft−1+Δft——用轻量级 Bridge 网络预测特征增量,替代完整 VLM 前向传播
- Latent Bridge 预测 Δ f t \Delta\mathbf{f}_t Δft 而非完整特征——Bridge 网络参数量远小于 VLM,推理速度快数倍
- 当检测到场景发生显著变化时(如相机视角切换),自动切换回完整 VLM 推理,保证鲁棒性
- 大幅降低推理延迟,同时保持策略性能
DepthCache: Depth-Guided Visual Token Merging
- 论文: arXiv:2603.10469
痛点: VLA 中 LLM backbone 处理大量视觉 token 成为推理瓶颈。标准方案中,一张图像被编码为 576 个视觉 token(24×24 网格),全部输入 LLM 进行注意力计算,但其中大量 token 对应的是无关背景区域,对操作决策没有贡献。
创新: 利用深度信息引导非均匀视觉 token 合并 (non-uniform token merging),保留空间推理能力。核心洞察是:深度图天然地提供了"重要性权重"——近处物体需要精细感知(保留更多 token),远处背景只需粗略理解(合并更多 token)。
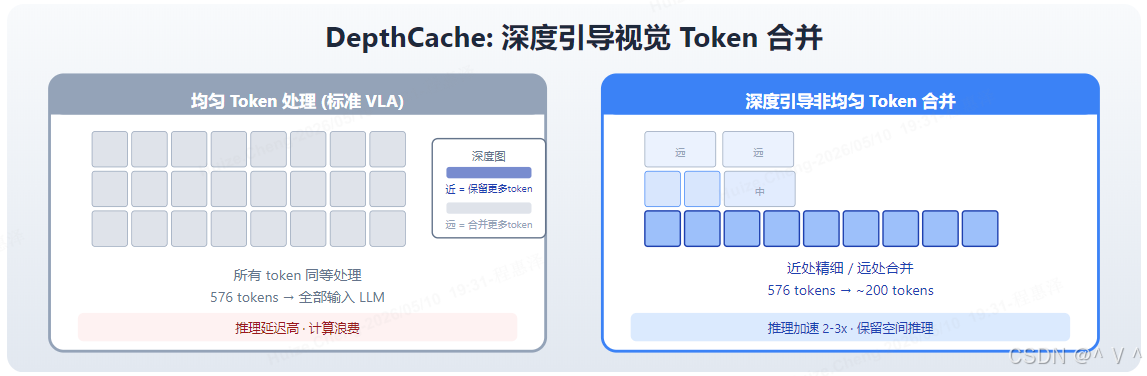
图解: 左侧展示标准 VLA 的视觉 token 处理方式——所有 576 个 token 被同等对待,全部输入 LLM backbone 进行推理,导致计算浪费和推理延迟高。右侧展示 DepthCache 的核心创新——利用深度图信息进行非均匀 token 合并:近处/重要的物体区域保留更多精细 token(蓝色深色块),远处/无关的背景区域合并更多 token(浅色大块),将 576 tokens 降至约 200 tokens。深度图作为"重要性权重"的天然来源——机器人需要精确感知近处操作目标,远处背景只需粗略理解。这种方法无需训练 (training-free),即插即用,推理加速 2-3x,同时保留空间推理能力。
方法:
- 深度图中近处/重要区域保留更多 token——保留操作目标区域的细节,确保精确抓取
- 远处/无关区域合并更多 token——将背景区域的多个 token 融合为一个,降低计算量
- 无需训练 (training-free),即插即用——仅需深度图作为额外输入,不修改模型权重
- 推理加速 2-3x,同时保留空间推理能力——与均匀裁剪不同,非均匀合并不破坏空间位置关系
HAMLET: History-Aware VLA
- 论文: arXiv:2510.00695
痛点: 大多数 VLA 仅依赖当前帧观测(单张图像),忽略历史上下文。这导致模型无法理解任务的进展状态——例如,当物体已被拿起但尚未放下时,仅看当前帧的模型无法判断操作处于哪个阶段,可能重复执行已完成的步骤。
创新: 让 VLA 成为历史感知策略 (History-Aware Policy),利用时序信息提升鲁棒性。核心方法是将多帧历史观测作为输入,让模型不仅看到"现在是什么样",还能理解"之前发生了什么",从而更准确地判断任务进展并决定下一步动作。
8.3 空间推理与3D感知
SaPaVe: Active Perception and Manipulation
- 论文: arXiv:2603.12193
- 作者: Liu, Zhou, Chi, Han, Rong, Chen, Wang, Wang, Zhang
痛点: VLA 被动接受固定视角观测,无法主动调整感知以改善操作。当目标物体被遮挡或处于不利视角时(如从正上方看一个扁平物体),VLA 只能基于不完整/低质量的观测进行决策,导致操作失败率升高。
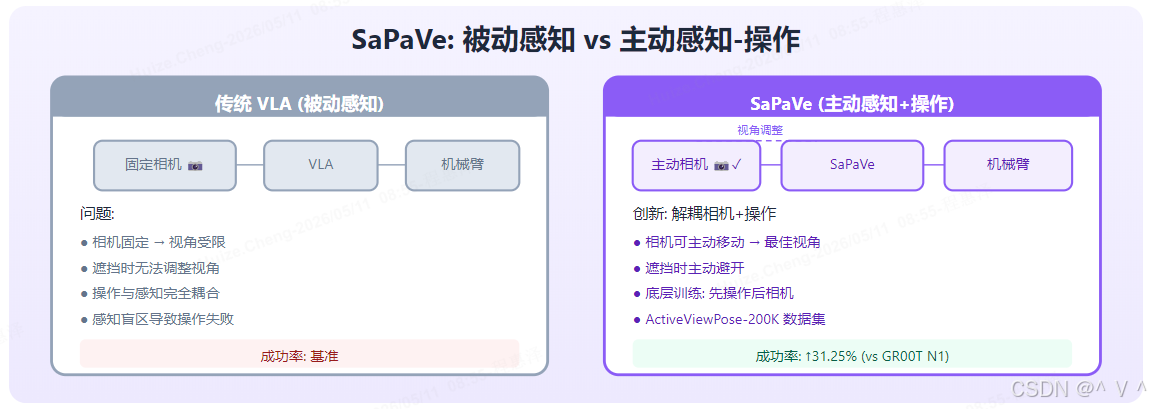
图解: 左侧展示传统 VLA 的被动感知模式——相机固定安装,视角不可调节,当目标物体被遮挡或处于不利视角时,VLA 只能基于不完整/低质量的观测进行决策,导致操作失败率升高。右侧展示 SaPaVe 的主动感知-操作联合框架——VLA 同时输出操作动作和相机控制动作,机器人可主动调整相机视角以获得更好的观测。关键创新在于解耦 (Decoupled) 设计:相机控制和操作动作分开预测,底层训练策略为先学操作再学相机控制,最终在真实任务中超越 GR00T N1 和 pi_0 高达 31.25%。
创新: 端到端的主动感知-操作联合框架 (Active Perception-Manipulation),解耦 (Decoupled) 相机控制和操作动作。关键设计是"解耦":相机控制动作和操作动作由两个独立的输出头分别预测,避免相互干扰;训练时先学操作(固定相机),再学相机控制(操作已学会),形成稳定的课程学习 (curriculum learning)。
方法:
- 底层训练策略: 先学操作,再学相机控制——这种课程式训练避免了两个目标同时优化的不稳定
- ActiveViewPose-200K 数据集——包含 20 万条主动视角调整的轨迹数据,为训练提供监督信号
- ActiveManip-Bench 评测基准——系统评测主动感知对操作性能的影响
- 在真实任务中超越 GR00T N1 和 pi_0 高达 31.25%——主动感知带来的观测质量提升直接转化为操作成功率
3D-Mix for VLA: VGGT-based 3D Information
- 论文: arXiv:2603.24393
痛点: VLA 基于 2D 图像数据训练,3D 空间推理能力不足。例如,从单张 2D 图像中无法准确判断物体的深度和厚度,这对于需要精确定位 3D 空间中抓取点的操作任务是一个严重限制。
创新: 即插即用模块 (plug-and-play module),注入 VGGT (Video-Guided Gaussian Transformer,一种从视频帧重建 3D 点云的模型) 的 3D 信息到 VLA。核心方法是将 VGGT 提取的 3D 点云特征作为额外输入注入 VLA 的视觉编码器,增强其空间推理能力,且不改变 VLA 原有架构。
CorridorVLA: Explicit Spatial Constraints
- 论文: arXiv:2604.21241
痛点: VLA 通过隐式特征注入空间引导(即让模型自行从视觉特征中学习空间约束),约束不够显式和可控。隐式方法的问题在于:模型可能学到错误的空间偏好,且无法在推理时调整空间约束的强度。
创新: 预测稀疏空间锚点 (sparse spatial anchors) 作为物理增量变化 (physical incremental change),提供显式空间约束。核心思想是:在动作生成之前,先预测几个关键的空间锚点(如抓取点的大致位置),将这些锚点作为硬约束引导后续动作生成,使空间推理从"隐式学习"变为"显式规划"。
VP-VLA: Visual Prompting Interface
- 论文: arXiv:2603.22003
痛点: VLA 将指令理解、空间定位和低层控制混在一个前向传播中,形成"黑盒"映射。这种耦合导致:① 错误难以归因(是理解错了还是执行错了?);② 无法独立改进某个子能力;③ 缺乏对空间定位的显式控制。
创新: 通过 Visual Prompting(视觉提示——在图像上叠加可视化标记引导模型注意力)解耦"黑盒"映射,分离指令理解、空间定位和低层控制三个子任务。核心方法是:先让 VLM 理解指令并输出视觉提示(如在目标位置画框),再基于带提示的图像生成动作,实现"理解→定位→执行"的显式流程。
8.4 数据与训练策略
MoIRA: Modular Instruction Routing Architecture
- 论文: arXiv:2507.01843
- 作者: Kuzmenko, Shvai
痛点: 单一通用 VLA 在多任务间存在干扰 (interference,又称"灾难性遗忘"或"负迁移")。当模型同时学习多个任务时,不同任务的梯度更新方向可能冲突,导致学新任务时旧任务性能下降,或多个任务间互相拖累。
图解: MoIRA 的核心架构如上图所示。中心为外部文本路由器 (Router),接收自然语言指令后,通过零样本嵌入相似度 + 提示驱动 LM 推理,将任务路由到最合适的专家模型。图中展示了两个专家:左侧 Expert 1 和右侧 Expert 2,每个专家基于底层 VLA(GR00T-N1 或 pi_0)+ LoRA 适配器,针对特定任务领域优化。路由器的关键设计是"架构无关"——不修改底层 VLA 架构,仅通过外部路由协调多个已适配的专家模型,避免了多任务间的参数干扰 (interference),在 GR1 Humanoid 和 LIBERO 上持续超越通用模型。
创新: 架构无关的模块化 MoE (Mixture of Experts,混合专家——一种通过路由机制将输入分配给不同专家模型处理的架构) 框架,使用外部文本路由器协调专家模型。"架构无关"意味着路由器不修改底层 VLA 的内部结构,而是在其外部协调——这种方式可以灵活组合不同的 VLA 作为专家,如同时使用 GR00T-N1 和 pi_0。
方法:
- 零样本嵌入相似度 (zero-shot embedding similarity) + 提示驱动 LM 推理路由——路由器先计算指令与各专家描述的嵌入相似度,再用 LM 推理判断最适合的专家,双保险确保路由准确
- GR00T-N1 和 pi_0 作为底层 VLA 专家 + LoRA 适配器——每个专家通过 LoRA 针对特定任务领域优化,保持基础模型权重不变
- 在 GR1 Humanoid 和 LIBERO 上持续超越通用模型——证明了模块化路由比单一通用模型更有效地处理多任务
World2Act: Latent Action Post-Training
- 论文: arXiv:2603.10422
痛点: 像素空间监督 (pixel-space supervision) 对 VLA 策略训练敏感且不稳定。直接在像素空间训练世界模型(预测下一帧图像)面临两个问题:① 像素级重建计算量大且低效(大量计算用于重建无关背景);② 像素预测对微小变化过敏感,训练不稳定。
创新: 潜空间世界模型后训练 (Latent World Model Post-Training),通过技能组合世界模型提升鲁棒性。核心方法是在潜空间 (latent space) 中而非像素空间预测未来状态——潜空间编码了与操作相关的高层特征(如物体位置、抓取状态),忽略无关的视觉细节,使训练更稳定高效。
RLDX-1: Robust VLA Training
- 论文: arXiv:2605.03269
痛点: VLA 继承了 VLM 的通用智能但鲁棒性 (robustness) 不足——模型对分布外输入(如未见过的物体外观、光照变化、相机标定偏差)非常敏感,微小的输入扰动可能导致完全失败的动作输出。
创新: 改进通用机器人策略的鲁棒性训练方法。核心思路是通过数据增强(如随机化纹理、光照、相机位姿)、对抗训练和一致性正则化等技术,迫使模型学到对扰动不变的表征——即同一操作任务在不同视觉条件下产生一致的动作输出。
8.5 验证与安全
Validating Generalist Robots with Situation Calculus and STL
- 论文: arXiv:2601.03038
- 作者: Li, Yan, Cheng, Zhang
痛点: 通用机器人策略的验证缺乏系统性方法。当前验证主要依赖人工测试和随机采样,无法保证覆盖所有可能的失败场景,更无法提供形式化的安全保证。
创新: 双层验证框架 — 抽象推理 (情境演算) + 具体系统证伪 (STL 监控)。上层使用形式化方法推导任务的逻辑规范,下层通过时序逻辑监控实际执行轨迹是否违反规范。
方法:
- 情境演算 (Situation Calculus): 一种形式化推理框架,推导最弱前置条件 (weakest precondition,即保证任务成功所需的最宽松初始条件),形式化任务规范
- STL (Signal Temporal Logic) 证伪: STL 是一种描述连续信号时序性质的逻辑(如"5秒内关节角度必须小于阈值"),用于监控执行轨迹是否满足时序规范
- 约束感知组合测试: 生成语义有效的多样化世界-任务配置——确保测试配置在物理上可行(如物体不会重叠),同时覆盖尽可能多的边界情况
在桌面操作实验中成功发现 NVIDIA GR00T 控制器的失败案例——验证了该框架发现隐藏缺陷的能力。
ROBOGATE: Adaptive Failure Discovery
- 论文: arXiv:2603.22126
- 作者: Kim
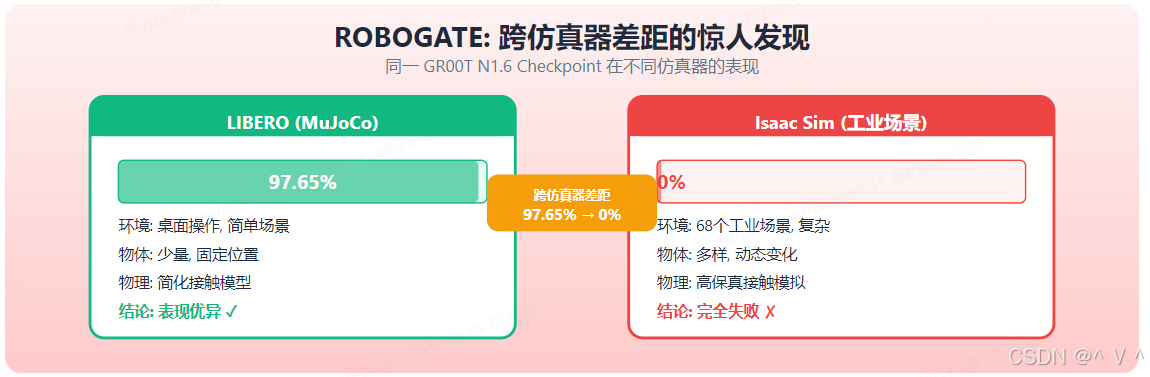
痛点: VLA 策略在仿真中取得高分,但真实部署风险未知——当前评测主要依赖单一仿真器(如 MuJoCo)的简单场景,无法暴露策略在复杂物理环境中的潜在失败。缺乏系统性的自适应测试方法来发现策略的"失败边界"(即策略在哪些条件下会崩溃)。
创新: 两阶段自适应采样发现失败边界。第一阶段使用自适应模糊测试 (adaptive fuzzing)——根据已发现的失败案例动态调整测试参数的分布,使采样逐步聚焦于边界区域。第二阶段使用分层参数搜索——对仿真环境中的物理参数(如物体质量、摩擦系数、光照条件)进行系统性变化,精准定位策略对哪些物理因素最敏感。
方法:
- 自适应采样: 基于贝叶斯优化 (Bayesian optimization) 的采样策略,优先探索已发现失败附近的参数空间,而非随机均匀采样
- 跨仿真器对比: 在 LIBERO (MuJoCo) 和 Isaac Sim 两种不同保真度的仿真器中部署同一策略,系统量化跨仿真器差距 (cross-simulator gap)
9. 傅利叶 GRx 硬件平台

傅利叶智能 (Fourier Intelligence) 的 GRx 系列是 GR00T 模型的主要物理验证平台。
9.1 GR-1
发布时间: 2023年
定位: 科研与开发平台
关键特性:
- 通用人形机器人平台,面向学术界与算法验证
- 双臂操作能力,支持灵巧操作——每条手臂具备多个自由度 (DOF),可执行精细的抓取和放置任务
- GR00T N1 的核心评测平台 (arXiv:2503.14734)
- ARMOR 感知系统的验证平台 (arXiv:2412.00396)
- RoboCurate 合成数据方法验证 (arXiv:2602.18742)
在 GR00T 论文中的角色:
GR00T N1 在 GR-1 上进行了双臂操作的实物验证,展示了高数据效率——仅需少量遥操作数据即可学会复杂操作任务。这验证了 VLA 架构在真实人形机器人上的可行性。
9.2 GR-2
发布时间: 2024年
定位: 商业服务机器人
关键改进:
- 增强运动性能和稳定性——改进了下肢的自由度 (DOF) 分布和关节扭矩输出,使行走步态更加自然稳健
- 更强的灵巧操作能力——升级了灵巧手和手腕的末端执行器 (end-effector) 设计,支持更精细的抓取和操作
- 多场景部署能力——针对商业服务场景(如酒店接待、展厅引导)优化了人机交互 (HRI) 能力
- 商业化产品迭代——从科研导向转向产品导向,降低单机成本,提升可靠性
9.3 GR-3 Series
发布时间: 2025+ (规划中)
定位: 大规模产品矩阵
规划:
- 系列化产品矩阵,多尺寸/多场景——根据应用场景推出不同身高、负载和成本的型号,类似汽车产品线的分级策略
- 灵巧手集成——将多指灵巧手 (dexterous hand) 作为标配,而非可选模块,实现更接近人类的精细操作
- 全身控制优化——整合 EAGLE 等跨平台全身控制技术,实现移动-操作一体化 (loco-manipulation),即行走与操作不再分立执行
- 面向多元市场应用——覆盖工业制造、医疗辅助、家庭服务等场景,推动人形机器人从专用设备走向通用平台
9.4 EAGLE: 跨平台全身控制
- 论文: arXiv:2602.02960
- 作者: Peng, Lin, Xue, Pang, Zhang
- 项目页: eagle-wbc.github.io
痛点: 不同人形机器人动力学、自由度、运动学拓扑差异大,单一策略难以跨平台控制。例如 Unitree H1 专注于双足行走和下蹲,Unitree G1 侧重灵巧操作,Fourier N1 擅长双臂协调——它们在形态学 (morphology) 上的差异(关节数量、肢体长度、DOF 分布)使得为单一平台训练的策略无法直接迁移到其他平台。
创新: 迭代式通用-专家蒸馏 (EAGLE, Embodiment-Aware Generalist-Specialist Distillation) 框架。核心思想是通用策略不应一次性学习所有平台,而是通过"分化→优化→聚合"的迭代过程逐步积累跨平台知识。
方法:
EAGLE 采用循环蒸馏策略:
初始化通用策略 G_0 → 对每个平台 i 分化专家 S_i^{(k)} → 专家优化 → 蒸馏回通用策略 G_{k+1} → 重复直至收敛
数学描述:
- 专家分化: S i ( k ) ← Fork ( G k ) S_i^{(k)} \leftarrow \text{Fork}(G_k) Si(k)←Fork(Gk) + 在平台 i i i 上 RL 优化
- 通用蒸馏: G k + 1 ← Train ( ⋃ i D S i ( k ) ) G_{k+1} \leftarrow \text{Train}(\bigcup_i \mathcal{D}_{S_i^{(k)}}) Gk+1←Train(⋃iDSi(k))
- 收敛判定: ∥ G k + 1 − G k ∥ < ϵ \|G_{k+1} - G_k\| < \epsilon ∥Gk+1−Gk∥<ϵ
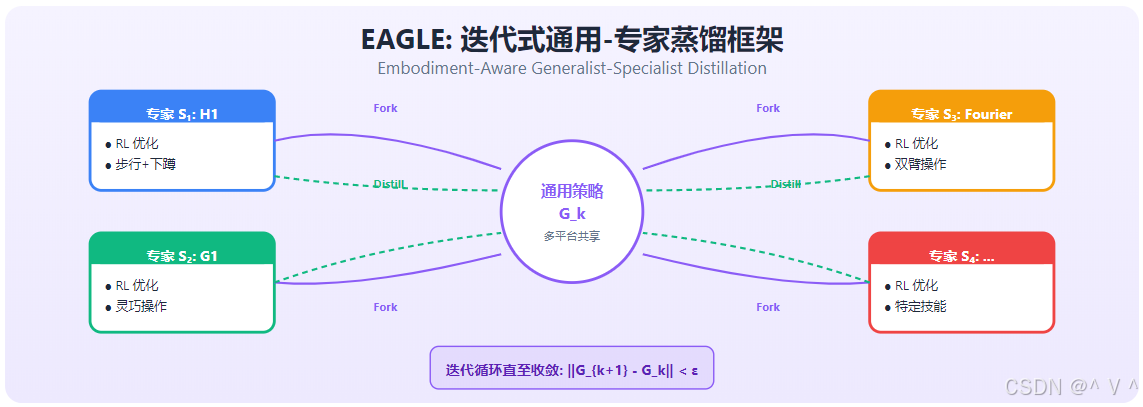
图解: EAGLE 的核心架构是一个迭代循环。中心为通用策略 G k G_k Gk(紫色圆形),它为多个平台提供共享的基础控制能力。循环包含两个阶段:Fork 阶段(紫色实线箭头)将通用策略分化为各平台专家 S 1 , S 2 , S 3 , S 4 S_1, S_2, S_3, S_4 S1,S2,S3,S4(分别对应 Unitree H1、G1、Fourier N1 等),每个专家通过 RL 在各自平台上独立优化,获得平台专有的运动技能。Distill 阶段(绿色虚线箭头)将所有专家的优化经验蒸馏回通用策略,形成 G k + 1 G_{k+1} Gk+1。循环迭代直至 ∥ G k + 1 − G k ∥ < ϵ \|G_{k+1} - G_k\| < \epsilon ∥Gk+1−Gk∥<ϵ 收敛。这一设计的核心洞察是:通用策略不应一次性学习所有平台,而是通过"分化→优化→聚合"的迭代过程逐步积累跨平台知识。
验证平台: Unitree H1、Unitree G1、Fourier N1 等五款机器人仿真 + 四款真机。
9.5 RoboCurate: 合成数据质量过滤
- 论文: arXiv:2602.18742
- 作者: Kim, Jang, Yoon, Kim, Won, Shin
痛点: 视频生成模型(如世界模型)产生的合成数据动作质量不一致——视频看起来视觉上合理,但对应的伪动作 (pseudo-action) 可能不符合物理约束(如物体穿透、动作序列不连贯),直接用于策略训练会引入噪声和错误示范。
创新: 通过仿真回放验证动作质量,过滤低质量数据。核心思路是将合成数据中的动作在仿真器中实际执行,对比仿真轨迹与生成视频的运动一致性——只有一致性高的数据才被保留用于训练。

图解: RoboCurate 提出了一条四阶段合成数据质量验证管道。阶段 1(紫色):视频世界模型生成——输入图像和语言指令,世界模型输出合成视频 V ^ \hat{V} V^ 和伪动作 a ^ \hat{a} a^,但动作质量不一致(红色标注问题)。阶段 2(蓝色):仿真回放验证——将伪动作 a ^ \hat{a} a^ 在仿真器中执行,得到仿真轨迹 τ sim \tau_{\text{sim}} τsim,与生成视频 V ^ \hat{V} V^ 进行运动一致性对比。阶段 3(橙色):质量过滤——一致性高于阈值的轨迹保留,低于阈值的丢弃,确保仅高质量数据进入训练。阶段 4(绿色):观测多样性增强——通过图像编辑和动作保持视频迁移增加视觉多样性,但不改变动作标签。底部展示性能提升:GR-1 Tabletop +70.1%、DexMimicGen +16.1%、ALLEX 人形灵巧操作 +179.9%。
方法:
- 将预测动作在仿真器中回放——将伪动作 a ^ \hat{a} a^ 在物理仿真器中逐帧执行,得到仿真轨迹 τ sim \tau_{\text{sim}} τsim
- 对比仿真器轨迹与生成视频的运动一致性——使用运动学指标(如关节角度差异、末端执行器位置偏差)量化一致性
- 通过图像编辑增加观测多样性——对保留的高质量数据进行外观增强(纹理、颜色、光照变化),同时保持动作标签不变,提升策略对视觉变化的鲁棒性
性能:
- GR-1 Tabletop: +70.1% 成功率提升 (300 demos) —— 数据效率大幅提升,少量真实数据 + 过滤后的合成数据即可达到高成功率
- ALLEX 人形灵巧操作: +179.9% 提升 —— 合成数据对灵巧操作 (dexterous manipulation) 的增益尤为显著,因为该领域真实数据采集极为困难
10. 未来展望
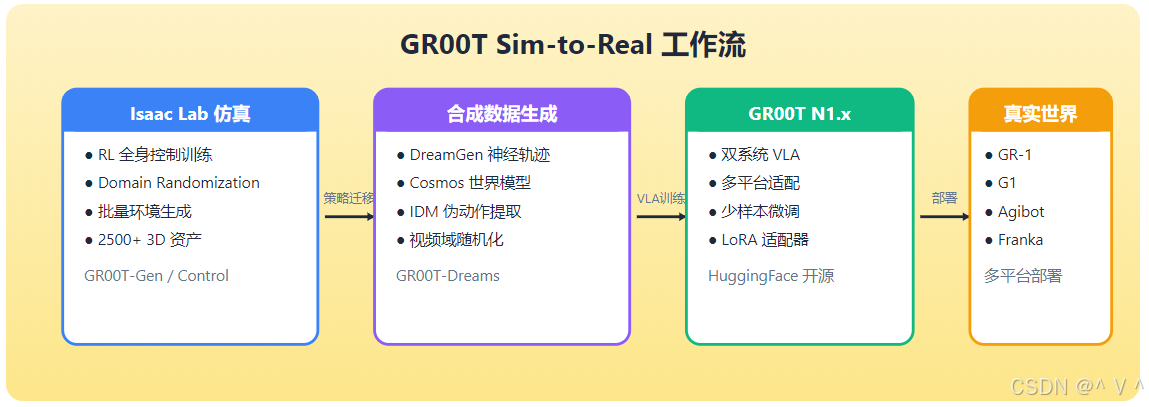
10.1 技术趋势
| 方向 | 当前状态 | 预期发展 |
|---|---|---|
| 模型规模 | 2B-3B 参数 | 向 10B+ 扩展,更强的世界理解和推理——更大的模型容量意味着更丰富的物理常识和更精细的动作控制 |
| VLM Backbone | Eagle-2 → Cosmos-Reason | 端到端视频理解 + 物理推理——Cosmos-Reason 的原生分辨率输入和物理推理能力将替代裁剪/缩放的旧方案 |
| 动作生成 | Flow Matching + DiT | 更快的推理速度,更流畅的动作——Flow Matching 的连续归一化流路径使 4-10 步即可生成高质量动作 |
| 跨平台泛化 | LoRA 适配器 | 零样本跨平台迁移——从需要微调适配到直接在新平台上部署,类似 EAGLE 的迭代蒸馏方向 |
| 数据来源 | 遥操作 + 合成 | 大规模互联网视频 + 世界模型生成——DreamGen 的合成数据管道将成为数据扩增的标准范式 |
| 全身控制 | 分离训练 | Loco-Manipulation 一体化——行走与操作不再由独立策略控制,而是统一在单一模型中协调执行 |
10.2 开放问题
-
跨仿真器一致性: ROBOGATE 揭示的 MuJoCo vs Isaac Sim 差距 (97.65% vs 0%) 表明,仿真评测结果不可简单迁移。需要更可靠的 Real-to-Sim 验证——即确保仿真环境中的评测结果能真实反映真机表现,而非仿真器特有的"虚假信心"。
-
动作表示标准化: 当前不同 VLA 使用不同的动作空间和表示方式(绝对位置、相对增量、关节角等),缺乏统一标准。这导致不同模型的输出无法直接比较,也阻碍了跨模型的数据共享和策略迁移。
-
长程任务与错误恢复: 当前 VLA 主要评测短程任务(5-15步),长程任务(50+步)的错误累积 (error compounding)——即每步微小的预测偏差在长序列中逐步放大——和恢复策略 (recovery) 仍是开放问题。
-
实时性瓶颈: 3B 模型在边缘设备 (edge device, 即部署在机器人本体上的低功耗计算单元) 上的推理延迟仍是挑战,需要更高效的蒸馏 (distillation) 和量化 (quantization) 方法,如 DepthCache 等训练无关 (training-free) 的加速方案。
-
安全验证: 随着机器人进入人机协作 (human-robot collaboration) 场景,形式化验证 (formal verification) 和安全保证变得至关重要——需要数学上可证明的安全约束,而非仅依赖经验测试。
-
数据闭环: DreamGen 开启了"世界模型→合成数据→策略训练"的循环,但如何自动评估合成数据质量(RoboCurate 提供了一种方案)和迭代这个闭环仍需探索。
10.3 GR00T + GRx 的协同演进
GR00T 和 GRx 代表了软硬件协同的典范:
- GR-1/2/3 提供物理载体: 为算法提供真实世界的反馈信号——只有在真机上验证,才能暴露仿真中无法发现的Sim-to-Real 问题
- GR00T 提供智能内核: 为机器人赋予通用操作能力——VLA 架构将视觉理解和动作生成统一在同一模型中
- DreamGen 打破数据瓶颈: 让算法从有限的遥操作数据泛化到新行为——通过世界模型生成海量合成轨迹
- Isaac Lab 闭环仿真: 在安全环境中大规模训练和验证——GPU 并行仿真使数千个环境同时运行成为可能
这种软硬件协同的范式,正是具身智能从"实验室验证"走向"工业级部署"的关键路径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)