OpenAI亮出网络安全“杀手锏“:GPT-5.5-Cyber专攻漏洞挖掘,红队测试迎来自动化拐点

大模型在网络安全领域的角色,正从"辅助修bug"转向"主动找漏洞"。本周四,OpenAI集团公共有限公司正式推出面向网络安全研究优化的专用模型——GPT-5.5-Cyber。这不是简单的功能解锁,而是一次针对攻防场景的底层能力重构。该模型目前仅通过"网络安全可信访问计划"(TAC)提供有限预览,准入门槛极高,首批用户锁定在负责关键基础设施安全的防御团队。
从写代码到挖漏洞:同一套引擎的两面性
GPT-5.5上个月刚亮相时,业界关注点还停留在编程效率上。鲜为人知的是,OpenAI内部曾用该模型开发过一款服务器集群加速软件,代码生成能力已经过生产环境验证。而代码理解与漏洞挖掘在技术路径上本就高度同源——能写出高效程序的逻辑,同样能逆向推导出程序边界条件的缺陷。GPT-5.5-Cyber正是基于这一技术连续性,将通用编程能力定向迁移到了安全研究领域。
不过,OpenAI对普通用户始终锁死了网络安全功能。常规ChatGPT账户若试图让模型分析网站漏洞,得到的回应要么是直接拒绝,要么被引导至修复建议。这种"只修不攻"的设定,本质上是在防止工具被滥用。
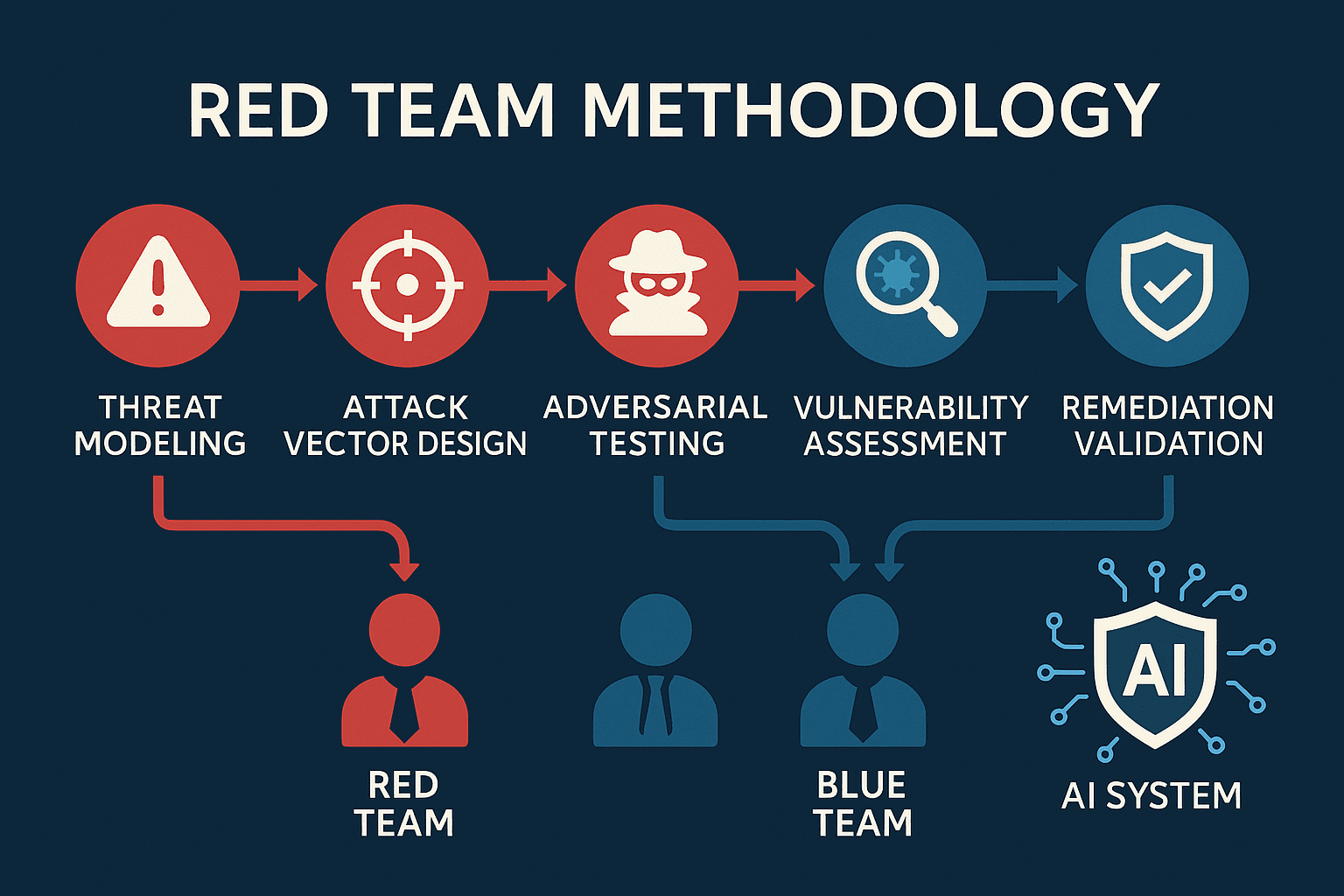
三层权限体系:普通版、TAC版与Cyber版的响应鸿沟
真正拉开差距的是访问层级。今年二月启动的TAC威胁研究计划,相当于为经过资质审核的网络安全专家开了一扇侧门。加入该计划的研究人员,可以获取更深层的技术响应:模型不仅生成攻击脆弱系统的技术描述,还能输出恶意软件样本供研究参考——当然,OpenAI明确不会验证这些样本的实际有效性,留了一道安全缓冲。
而新发布的GPT-5.5-Cyber则更进一步。它不再局限于"纸上谈兵"式的漏洞分析,而是能够自主生成漏洞利用方案,并通过模拟网络攻击验证方案是否可行。这意味着企业安全团队可以借助该模型开展自动化红队演练,让AI扮演攻击者角色,持续对自身基础设施进行压力测试。传统红队测试依赖人工渗透,周期长、成本高;而模型驱动的自动化攻防,理论上可以实现7×24小时不间断探测,大幅缩短从漏洞发现到防御加固的窗口期。

CyberGym拿下81.9%:基准测试背后的含金量
OpenAI披露了一组硬指标:GPT-5.5-Cyber在CyberGym基准测试中得分81.9%。这个测试集覆盖了数百个开源项目中的1500余处历史漏洞,考察的是大模型在真实代码库中识别、分析安全缺陷的综合能力。八成以上的准确率,意味着该模型已经具备了辅助安全研究员进行初步漏洞筛查的工程价值,而非停留在概念演示阶段。
但能力越强,防护越重。OpenAI为Cyber版本配备了双重安全锁:一是"更强验证"机制,防止黑客通过身份伪装获取模型访问权;二是增强型滥用监控,实时追踪研究人员的使用行为,确保其操作符合网络安全最佳实践。这种"高开高防"的策略,反映出OpenAI在开放能力与安全底线之间的谨慎权衡。
有限开放背后的战略考量
目前GPT-5.5-Cyber并未大规模铺开。OpenAI的表态很直接:对绝大多数网络安全项目而言,标准版GPT-5.5配合TAC计划已经足够。Cyber版本更像是为国家级关键基础设施、大型金融与能源网络量身定制的"重型装备",普通企业安全团队暂时无需触碰。
这一布局也暗含竞争意味。Anthropic旗下最先进的Claude Mythos Preview同样主打软件漏洞发现,今年初已向部分机构定向开放,意图抢占企业安全心智。GPT-5.5-Cyber的登场,显然是要在AI驱动的漏洞挖掘与红队测试赛道中,与Anthropic正面交锋。
结语
GPT-5.5-Cyber的发布,标志着大模型在网络安全领域完成了从"防御顾问"到"攻防模拟器"的跃迁。当AI不仅能指出哪里可能出问题,还能亲自模拟攻击验证时,企业安全建设的逻辑将被彻底改写。不过,这种能力目前仍被严格圈定在可信研究者手中——技术突破与风险管控之间的拉锯,或许才是这场发布背后更值得关注的长期命题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)