深入探索 Claude Code:当今与未来 AI 智体系统的设计空间(下)
26年4月来自阿联酋MBZUAI和英国UCL的论文“Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems”。
Claude Code 是一款具备智体能力的编程工具,能够代表用户执行 Shell 命令、编辑文件以及调用外部服务。本研究通过分析其公开可用的 TypeScript 源代码,详述该工具的综合架构;此外,本研究还将其与 OpenClaw 进行对比——OpenClaw 是一个独立的开源 AI 智体系统,它在截然不同的部署语境下,针对许多相同的架构设计难题给出了不同的解决方案。其分析归纳出五项驱动该架构设计的人本价值观、理念与需求(即:人的决策主导权、安全与防护、执行可靠性、能力增强以及语境适应性),并追溯这些理念如何通过十三项具体的设计原则,最终落实为特定的实现方案。该系统的核心是一个简单的“while”循环结构,负责依次调用语言模型、执行各类工具,并周而复始地循环运行。然而,该系统的绝大部分代码逻辑实际上分布于围绕这一核心循环构建的周边组件之中:其中包括一套具备七种运行模式及基于机器学习分类器的权限管理系统;一套用于上下文管理的五层级压缩流水线;四种实现系统扩展性的机制(即 MCP、插件、技能与钩子);一套用于实现子智体任务委托与协同编排的机制;以及一套采用追加写入模式的会话存储系统。通过与 OpenClaw(一款多通道个人助理网关系统)进行对比,可以发现:当部署上下文发生变化时,针对同一组反复出现的架构设计难题,往往会产生截然不同的架构解决方案——具体表现为:从针对单次操作的安全性评估转向边界层级的访问控制;从单一的命令行界面(CLI)循环模式转向嵌入于网关控制平面内部的运行时环境;以及从局限于特定“语境窗口”范围内的扩展机制,转向覆盖整个网关层面的全局能力注册机制。最后,基于近期在实证研究、架构设计及策略制定等领域的文献成果,为未来的智体系统指出六个值得深入探索的开放性设计方向。
。。。继续。。。
对于代码编写智体(coding agents)而言,一个反复出现的设计问题是如何构建其扩展接口:是采用单一的统一机制,少数几种专用机制,还是采用一种具有不同“上下文成本”的分层堆栈结构?表 1 中列出的两条设计原则:可组合的多机制扩展性,以及外部化的可编程策略。
回到贯穿全文的示例:当 Claude 尝试修复 auth.test.ts 文件,且此前发出的 npm test 请求已通过权限系统的仲裁之后,接下来的问题便是:针对此次修复任务,当前有哪些支持扩展的“操作接口”(action surface)可供调用?在 Claude Code 的交互回合(turn)开始时,模型所能“感知”到的不仅仅是像 BashTool 和 FileReadTool 这样的内置工具,还包括来自 MCP 服务器的数据库查询工具、来自 .claude/skills/ 目录的自定义 Lint 技能(skill),以及由已安装插件所贡献的各类工具。
这些工具通过四种不同的机制汇聚而来,分别在智体运行循环(loop)的不同阶段发挥扩展作用:MCP 服务器负责提供外部工具集成能力;插件(plugins)负责打包并分发一系列组件集合;技能(skills)负责注入特定领域的指令;而钩子(hooks)则负责拦截并介入工具执行的生命周期。Anthropic 官方文档(Anthropic, 2026d)对此提出了更为宏观的视角,除了这四种机制外,还涵盖 CLAUDE.md和子智体(subagents)等扩展方式。
1 四种扩展机制
上述四种扩展机制分别实现在不同的源代码目录中(如图 5 所示),并各自服务于特定的集成模式: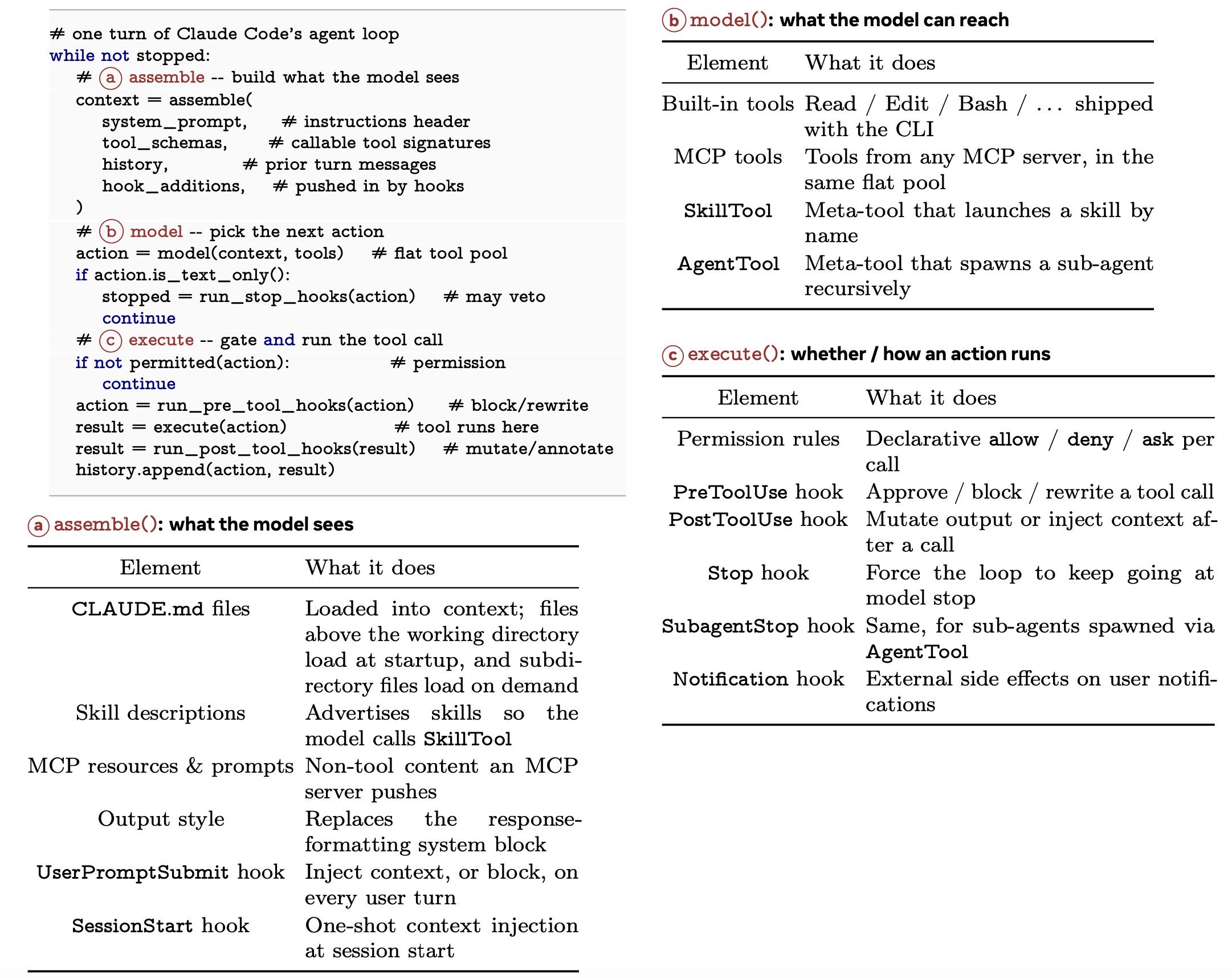
MCP 服务器。即“模型上下文协议”(Model Context Protocol)服务器,它是实现外部工具集成的首选路径。MCP 服务器的配置信息可来源于多个作用域(scopes):包括项目级、用户级、本地级以及企业级;此外,在运行时还会动态合并来自插件和 claude.ai 平台的额外服务器配置(具体实现见 services/mcp/config.ts)。MCP 客户端(具体实现见 services/mcp/client.ts)支持多种传输协议类型:包括标准 I/O(stdio)、服务器发送事件(SSE)、HTTP、WebSocket 以及 SDK 接口;此外还包含针对特定 IDE 环境的变体(如 sse-ide 和 ws-ide),以及一个用于内部通信的 claudeai-proxy 智体服务。每一个处于连接状态的 MCP 服务器都会将其所提供的工具定义作为 MCPTool 对象贡献给系统。专用的内置工具 ListMcpResourcesTool 和 ReadMcpResourceTool 提供访问 MCP 资源的途径。
插件(Plugins)。插件扮演着双重角色:它们既是一种打包格式,也是一种分发机制。PluginManifestSchema(位于 utils/plugins/schemas.ts)支持十种组件类型:命令、智体、技能、钩子、MCP 服务器、LSP 服务器、输出样式、通道、设置以及用户配置。插件加载器(位于 utils/plugins/pluginLoader.ts)负责验证清单文件,并将各类组件分派至其各自的注册表:命令和技能通过元工具 SkillTool 暴露出来;智体定义会被 AgentTool 引用并使用;钩子会被合并至钩子注册表中;MCP 和 LSP 服务器会被整合进其标准配置中;而输出样式则用于修改响应的格式。因此,单个插件包能够同时跨多种组件类型对 Claude Code 进行功能扩展,这使得插件成为了分发第三方扩展功能的主要载体。
技能(Skills)。每一项技能都通过一个包含 YAML 前置元数据(frontmatter)的 SKILL.md 文件进行定义。parseSkillFrontmatterFields() 函数(位于 loadSkillsDir.ts)负责解析超过 15 个字段,其中包括:显示名称、描述、允许使用的工具(赋予该技能访问额外工具的权限)、参数提示、模型覆盖配置、执行上下文(例如用于隔离执行的 'fork' 模式)、关联的代理定义、工作量级别以及 Shell 配置。技能可以定义属于自己的钩子,这些钩子会在技能被调用时动态注册。随主程序打包分发的内置技能会在程序启动时直接加载到内存中进行注册。当技能被调用时,元工具 SkillTool 会将该技能的具体指令注入到当前的执行上下文中。
钩子(Hooks)。源代码中定义 27 种钩子事件,涵盖以下类别:工具授权(PreToolUse、PostToolUse、PostToolUseFailure、PermissionRequest、PermissionDenied)、会话生命周期(SessionStart、SessionEnd、Setup、Stop、StopFailure)、用户交互(UserPromptSubmit、Elicitation、ElicitationResult)、子智体协作(SubagentStart、SubagentStop、TeammateIdle、TaskCreated、TaskCompleted)、上下文管理(PreCompact、PostCompact、InstructionsLoaded、ConfigChange)、工作区事件(CwdChanged、FileChanged、WorktreeCreate、WorktreeRemove)以及通知事件(详见 coreTypes.ts 和 coreSchemas.ts)。其中,有 15 个具有特定于事件的输出模式;这些模式包含丰富的字段,用于支持权限决策、上下文注入、输入修改、MCP 结果转换以及重试控制(位于 types/hooks.ts)。通过设置和插件配置的持久化 Hook 命令共包含四种类型:Shell 命令(类型:command)、LLM 提示 Hook(类型:prompt)、HTTP Hook(类型:http)以及智体式验证 Hook(类型:agent)(位于 schemas/hooks.ts)。
2 工具池组装
位于 tools.ts 文件中的 assembleToolPool() 函数,其文档描述为“整合内置工具与 MCP 工具的单一权威来源”。该组装过程遵循一个包含五个步骤的流水线:
- 基础工具枚举。
getAllBaseTools()(位于tools.ts)返回一个包含最多 54 种工具的数组:其中 19 种工具总是被包含在内(例如 BashTool、FileReadTool、AgentTool 和 SkillTool),而另外 35 种工具则根据功能标志(feature flags)、环境变量及用户类型进行条件式包含。Anthropic 内部用户可获得额外的内部专用工具。启用 Worktree 模式时,会激活 EnterWorktreeTool 和 ExitWorktreeTool。启用 Agent 群组(Agent swarms)功能时,会激活团队协作工具。当 Bun 二进制文件中已内置嵌入式搜索工具时,专用的 GlobTool 和 GrepTool 将被省略。 - 模式过滤。
getTools()(位于tools.ts)会应用针对特定模式的过滤规则。在CLAUDE_CODE_SIMPLE模式下,仅 Bash、Read 和 Edit 工具可用(若处于 REPL 分支,则为 REPLTool;此外,若适用,还会包含协调器工具)。系统会调用每种工具的isEnabled()方法,以进行运行时的可用性检查。 - 拒绝规则预过滤。
filterToolsByDenyRules()(位于tools.ts)会在任何调用发生之前,从模型的视角中剔除那些被“一揽子拒绝”的工具。 - MCP 工具集成。来自
appState.mcp.tools的 MCP 工具会先经过拒绝规则的过滤,随后与内置工具进行合并。 - 去重处理。工具将按名称进行去重,其中内置工具的优先级高于 MCP 工具。
无论是 REPL.tsx(通过 useMergedTools Hook 调用)还是 AgentTool.tsx(在构建工作智体的工具集时调用),均会调用此函数,从而确保所有执行路径上的工具组装过程保持一致。在请求处理阶段,某些“延迟加载工具”(deferred tools)可能会被暂时隐藏,不出现在模型的上下文(context)中,直至通过 ToolSearch(位于 tools.ts)被显式查询时才会显现。
Agent 在本质上与上述四种机制截然不同:它们创建的是全新的、相互隔离的上下文窗口,而非对当前已有的上下文窗口进行扩展。
3 为什么是四种机制?
鉴于每增加一种扩展机制,都会扩大开发者必须掌握的知识面,一个自然而然的问题便是:Claude Code 为何要采用四种截然不同的机制,而非将其整合为一两种?答案在于这样一种观察:不同类型的可扩展性会对“上下文窗口”(Context Window)施加不同的成本;单一机制无法涵盖从“零上下文”的生命周期钩子,到“重模式”(Schema-heavy)的工具服务器这一完整的扩展谱系,若强行统一,必将迫使扩展作者做出不必要的权衡与取舍。
如表 2 所示,每种机制都是通过权衡部署的复杂性,来换取特定类型的可扩展性。MCP 服务器提供运行时工具集成能力(即赋予模型新的可调用工具),但其代价是增加服务器管理开销,并消耗用于承载工具模式(Schema)的上下文预算。技能(Skills)机制旨在重塑智体(Agent)的思维方式(而不仅仅是其拥有的工具集),且其上下文成本极低——因为只有前置元数据描述(Frontmatter descriptions)会被保留在提示词(Prompt)中,而无需包含完整的技能内容。钩子(Hooks)机制提供横跨整个生命周期的控制能力(可用于阻断、重写或标注工具调用),且默认情况下不占用任何上下文资源;当然,钩子也可以选择性地注入额外的上下文信息。插件(Plugins)机制则可将上述三种机制的任意组合打包成可分发的组件;它主要充当扩展的打包与分发层,而非一种独立的运行时基础原语。这种按上下文成本递增的层级设计(钩子为零成本,技能成本低,插件成本中等,MCP 成本高)意味着:低成本的扩展可以大规模部署,而无需担心耗尽上下文窗口资源;高成本的扩展则专用于那些确实需要引入全新工具接口的特定场景。
某些智体框架仅提供单一的扩展机制——通常是一种“纯工具型”API,即所有的自定义功能都必须以新增的可调用工具形式来实现。另一些框架则采用双层架构,将工具机制与配置管理或指令注入机制区分开来。相比之下,Claude Code 的“四机制”方案能够支持更为广泛的扩展模式——从零上下文的事件处理器,到完整的外部服务集成,无所不包;但与此同时,这也增加开发者的学习曲线,因为他们在面对具体的集成任务时,需要花费更多精力去权衡并决定究竟应选用哪一种机制。
智体(Agent)如何管理其上下文窗口并持久化用户指令,是一项核心的设计决策;不同的系统会在此处选择不同的方案,包括基于文件的透明管理、基于数据库的检索机制,以及基于学习模型的非透明表征。此处的设计选择体现表 1 中的两项原则:将上下文视为一种稀缺资源并实施渐进式管理;以及采用基于文件的透明配置与记忆机制。
在贯穿全文的示例流程进行到这一步时,任务已累积大量的状态信息:包括最初的请求、npm test 权限检查的结果、构建的工具池,以及迄今为止收集的所有文件读取内容或命令输出结果。在发起下一次模型调用之前,这些不断增长的状态信息被打包并适配进 Claude Code 那有限的上下文窗口之中。
在调用模型之前,智体的主循环(Agent loop)会整合来自工具池、CLAUDE.md 文件、自动记忆模块以及对话历史记录的内容,从而构建出完整的上下文窗口。
1 上下文窗口的构建
上下文窗口(如图 6 所示)由以下来源的内容组合而成;其中部分内容是在初始构建阶段即行加载,而另一些则是在当前交互回合(turn)进行过程中动态注入的:
- 系统提示词(System prompt):包含对输出格式风格的调整指令,以及通过
--append-system-prompt标志传入的任何附加内容。 - 环境信息(通过
getSystemContext()函数获取,位于context.ts文件中):包括git status状态信息(在远程模式下或禁用 Git 指令时会被跳过),以及针对内部构建版本可选注入的“缓存失效”指令(受BREAK_CACHE_COMMAND环境变量的控制)。此项内容在每个会话周期内仅计算并缓存(Memoize)一次。 CLAUDE.md文件层级结构(通过getUserContext()函数获取,位于context.ts文件中):即由四个层级构成的指令文件体系。此项内容同样经过缓存处理。- 路径作用域规则:即那些具有条件约束或基于目录路径进行匹配的规则;仅当代理读取位于特定匹配目录下的文件时,这些规则才会以“惰性加载”(Lazy loading)的方式被载入。
- 自动记忆(Auto memory):即那些与当前上下文高度相关、并已通过异步方式预先获取的记忆条目。
- 工具元数据:包括各类技能(Skill)的描述、MCP 工具的名称,以及那些需按需加载的“延迟定义”工具(通过
ToolSearch机制实现)。 - 对话历史记录:即此前交互回合中累积的对话内容;这些内容会被延续至当前回合,但需接受后续的压缩处理。
- 工具执行结果:包括文件读取的内容、命令执行的输出结果,以及由子智体(Sub-agent)生成的任务摘要。
- 压缩摘要:即用于替代并概括旧有历史记录片段的精简版摘要内容。
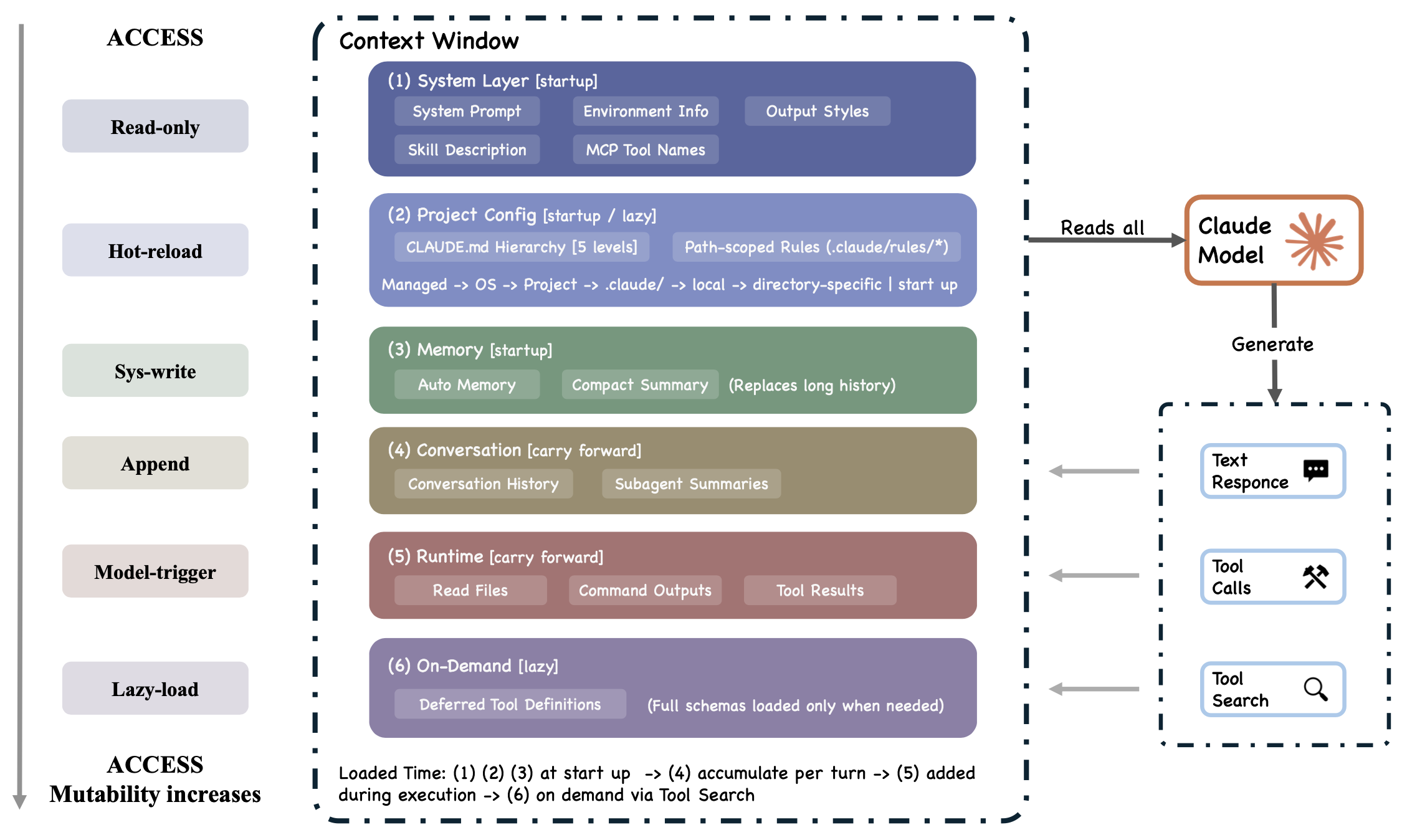
query.ts 中的系统提示组装模块通过 appendSystemContext(systemPrompt, systemContext)() 函数,将系统上下文与基础提示合并为“系统提示”(System-Prompt)。用户上下文(即 CLAUDE.md 文件内容及当前日期)则通过 prependUserContext() 函数被前置(prepend)到消息数组的开头。这种分离设计意味着,在 API 请求中,CLAUDE.md 文件的内容所占据的结构位置与系统提示不同,这可能会对模型的注意力分配模式产生影响。
有几类上下文来源是在主上下文窗口构建完毕后,才在较晚的阶段被注入进来的:包括相关记忆的预取(位于 query.ts 中)、MCP 指令的增量更新(仅包含新增或变更的服务器指令)、代理列表的增量更新,以及后台代理任务的通知。因此,上下文窗口并非在组装时就已固定不变,而是在整个交互回合(turn)进行过程中可能随之扩充。
2 CLAUDE.md 的层级结构与自动记忆机制
记忆系统遵循着一条核心设计原则:存储的上下文应当对用户是可查阅且可编辑的。CLAUDE.md 文件采用纯文本的 Markdown 格式,而非结构化的配置文件或不透明的数据库条目。这种对“透明度”的取舍,意味着牺牲一定的表达灵活性,换取极高的可审计性:用户可以轻松阅读、编辑、进行版本控制,甚至删除智体所接收的任何指令(MindStudio Team, 2026)。其他的记忆架构方案则进一步印证这种设计上的权衡取舍。例如,基于检索增强(Retrieval-Augmented)的方法利用基于嵌入向量(embedding)的查找机制来发掘相关的历史上下文;这种方法虽然提升灵活性,却牺牲可查阅性——用户很难直观地查看或编辑检索系统判定为“相关”的具体内容。而基于数据库的记忆系统虽然支持结构化的查询操作,但不仅需要额外搭建基础设施,且其内部数据对于版本控制系统而言通常是“不透明”的。相比之下,Claude Code 所采用的这种基于文件的记忆方案,使得智体所接收的每一条指令都能像普通代码文件一样,直接被用户阅读、编辑,并纳入版本控制系统进行统一管理。该系统在进行记忆检索时,既不依赖嵌入向量,也不使用向量相似度索引;取而代之的是,它利用大语言模型(LLM)对记忆文件的头部信息进行扫描,并根据当前需求动态选取最多五个相关文件,从而以“文件”为单位(而非以“单条条目”为单位)将相关上下文呈现出来。尽管基于嵌入向量的系统在检索单条具体条目时可能显得更为精准和灵活,但其代价是牺牲上下文的可查阅性,且需要额外投入基础设施资源来维护相应的索引系统。
CLAUDE.md 文件遵循一套多层级的加载层级结构。源头文件头(claudemd.ts)定义了四种记忆类型:
- 托管记忆(例如 Linux 上的
/etc/claude-code/CLAUDE.md):针对所有用户的操作系统级策略。 - 用户记忆(
~/.claude/CLAUDE.md):私有的全局指令。
3.项目记忆(位于项目根目录下的CLAUDE.md、.claude/CLAUDE.md以及.claude/rules/*.md):已纳入代码库进行版本控制的指令。
4.本地记忆(位于项目根目录下的CLAUDE.local.md):被.gitignore忽略,用于存放私有的、针对特定项目的指令。
文件发现机制会从当前目录向上逐级遍历至根目录,检查每个目录中是否存在项目记忆文件和本地记忆文件。距离当前目录越近的文件具有越高的优先级(即加载顺序越靠后)。
文件的加载遵循“优先级逆序”原则:后加载的文件会获得模型更多的关注。对于从根目录到当前工作目录(CWD)的路径,来自 .claude/rules/*.md 的无条件规则会在启动时即刻加载(即“急切加载”)。对于 CWD 下方的嵌套目录,即使是无条件规则,也会在智体(Agent)读取匹配目录中的文件时才进行加载(即“惰性加载”)。这意味着随着代码库中新部分的探索,模型的指令集在对话过程中是可以动态演变的。
CLAUDE.md 的内容是以用户上下文(即一条用户消息)的形式传递的,而非作为系统提示(System Prompt)的内容(即 context.ts)传递。这一架构选择具有重大意义:由于 CLAUDE.md 的内容是以对话上下文而非系统级指令的形式传递的,模型对这些指令的遵从是概率性的,而非绝对保证的。按“拒绝优先”顺序进行评估的权限规则,提供确定性的强制执行层。这在“指导”(CLAUDE.md,概率性)与“强制执行”(权限规则,确定性)之间建立一种刻意的分离。程序会调用 setCachedClaudeMdContent() 函数,将已加载的内容缓存供自动模式分类器使用,以此避免 CLAUDE.md 加载器与权限系统之间产生循环导入(Import Cycle)的问题。
记忆文件支持使用 @include 指令来实现模块化的指令集(具体实现见 claudemd.ts 中的 processMemoryFile() 函数)。该指令支持多种语法变体,包括 @path、@./relative(相对路径)、@~/home(用户主目录路径)以及 @/absolute(绝对路径)。该指令仅作用于叶子文本节点(不适用于代码块内部)。在具体实现中,被包含文件将首先被压入,随后追加包含文件;通过追踪已处理的路径来防止循环引用;对于不存在的文件,则予以静默忽略。
3 压缩(Compaction)管道
五层压缩管道通过“分级压缩”机制(见 query.ts 文件)实现“将上下文视为瓶颈”的原则。Claude Code 并未采用单一策略,而是按顺序应用五个层级,每个层级的压缩力度依次递增(其中三个层级受“功能标志”控制;而“预算缩减”功能始终处于激活状态,“自动压缩”功能则由用户自行配置)。这种分级处理的方法与一些更简单的替代方案形成了鲜明对比:许多智体(Agent)框架通常只采用单次截断(即直接丢弃最旧的消息)或单次摘要生成步骤。这种分级设计体现一种“惰性降级”原则:即优先应用对用户体验干扰最小的压缩策略,仅当这些低成本策略不足以满足需求时,才会逐步升级至更强力的压缩手段。这种设计方法的代价在于其增加系统的复杂性。由于存在五个相互作用的压缩层级(其中部分受功能标志控制),其产生的系统行为有时会让用户难以完全预测。具体而言,“自动压缩”功能会在对话记录中生成并显示清晰可见的摘要;“微压缩”功能会插入一个边界标记(boundary marker);而“上下文折叠”功能则是在后台静默运行,不会产生任何用户可见的输出。相比之下,那些更简单的单次处理方案虽然可能会牺牲部分信息,但其运行逻辑更为直观,也更易于用户理解和推演。
- 预算缩减(始终激活):针对每个工具执行结果设定大小上限。
- 截断(
HISTORY_SNIP):对历史对话记录进行轻量级的尾部修剪。 - 微压缩(
CACHED_MICROCOMPACT):一种感知缓存机制的细粒度压缩策略。 - 上下文折叠(
CONTEXT_COLLAPSE):在读取对话记录时,对历史内容进行虚拟化的动态投影处理。 - 自动压缩(默认开启,可手动关闭):由语言模型自动生成完整的对话摘要。
buildPostCompactMessages() 函数(位于 compact.ts 文件中)负责构建并返回经过压缩处理后的输出结构,其具体格式如下:[边界标记, ...摘要消息, ...保留消息, ...附件, ...钩子(Hook)执行结果]。该“边界标记”通过 annotateBoundaryWithPreservedSegment() 函数进行元数据标注,其中记录 headUuid、anchorUuid 和 tailUuid 等关键信息,从而支持在读取对话记录时进行链式拼接与重构。这种“以追加为主”的设计理念确保压缩操作绝不会修改或删除此前已写入对话记录中的任何条目;它所做的仅仅是向记录末尾追加新的边界标记事件和摘要事件。
负责执行压缩任务的 compactConversation() 函数(位于 compact.ts 文件中)融合多项设计考量。其中,“前置压缩钩子”(Pre-compact hooks)会率先触发执行,从而允许用户通过钩子机制注入自定义的指令或逻辑。一个 GrowthBook 功能标志控制着压缩路径是否重用主对话的提示缓存(一段代码注释记录 2026 年 1 月的一项实验:“‘false’路径的缓存未命中率高达 98%,其开销约占整个服务集群缓存创建总量的 0.76%”)。完成压缩后,附件构建器会根据当前的实时应用状态,重新广播运行时状态(包括规划、技能和异步代理);这是因为压缩操作虽然丢弃先前的附件消息,但并未舍弃其底层所代表的实际状态。
当系统将工作委派给子智体时,上下文隔离变得尤为关键,因为每个子智体都运行在各自独立的、受限的上下文窗口内。
多智体编排是编码智能体设计中的一个关键维度,其设计选项涵盖了父子层级结构、基于对等体的对话框架(Wu 等人,2024)以及图结构工作流引擎(LangChain, Inc.,2024)等多种模式。Claude Code 的委托架构实现表 1 中所列的“子智体边界隔离”原则,并融合“默认拒绝与人工升级(权限覆盖)”以及“基于可逆性的风险评估(子智体工具限制)”等设计理念。
当 Claude 判定修复认证测试用例需要首先探索认证模块的内部结构时,它可以将这项探索任务委托给一个子智体来执行。实现这一委托机制的工具即为 Agent 工具(AgentTool.tsx),其中 Task 仍作为旧版别名予以保留。模型通过结构化的输入调用 Agent 工具;该输入包含委托指令(prompt)、可选的子智能体类型,以及针对隔离模式、权限覆盖设置和工作目录的配置参数。
1 Agent 工具与委托准则
Agent 工具的输入模式(Schema,见图 7所示)采用“特性门控字段”机制:当某个可选参数所依赖的底层特性处于禁用状态时,该参数字段即会被自动省略。其中,isolation 字段针对内部用户提供 ['worktree', 'remote'] 两种选项,而针对外部用户仅提供 ['worktree'] 选项;这一可用性配置是在构建时确定的。cwd 字段的可用性则受控于特定的特性标志(feature flag)。此外,当系统禁用后台任务功能,或启用了“分叉子智体”(fork-subagent)模式时,run_in_background 字段也会被自动省略。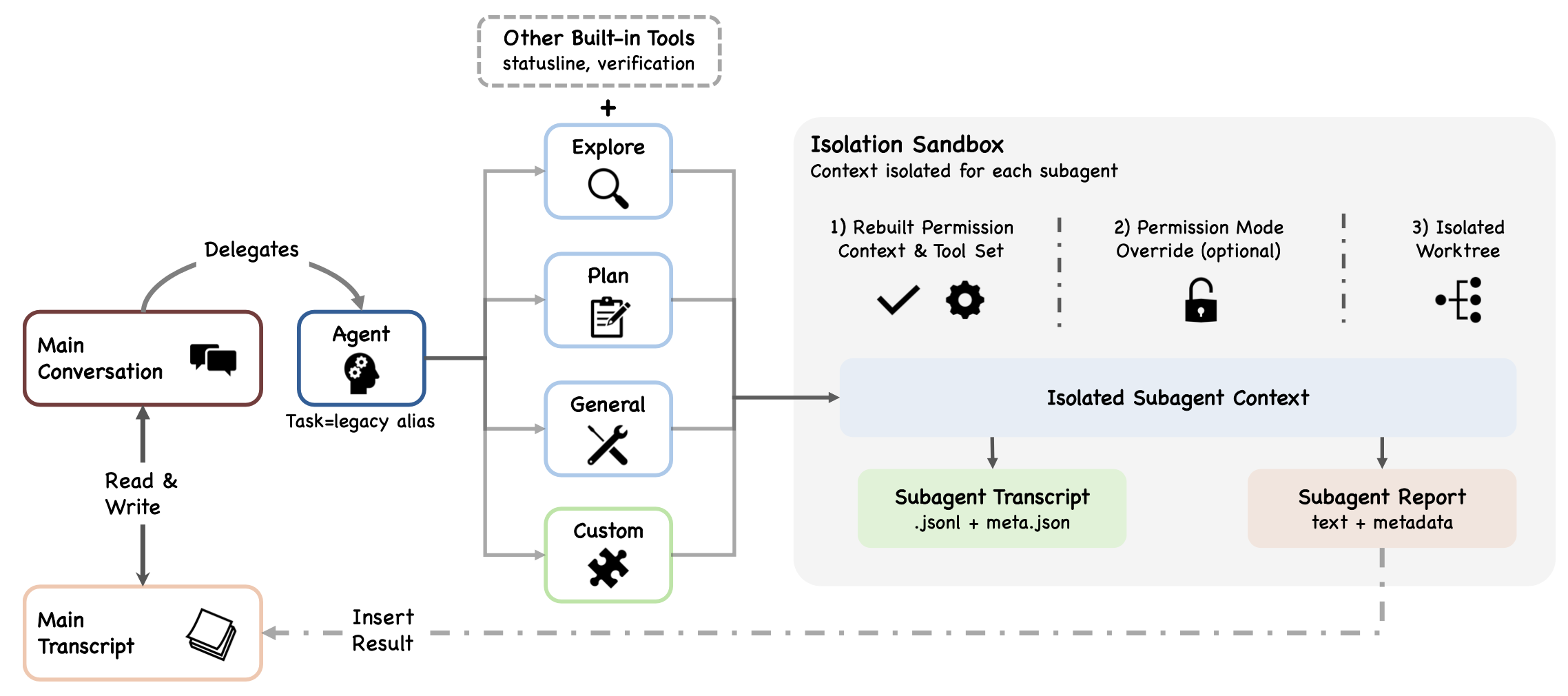
根据特征标志(feature flags)和入口点(entrypoint)的不同,Claude Code 提供多达六种内置的子智体类型:
• Explore(探索):主要面向读取/搜索的调查任务,其“拒绝列表”(deny-list)中排除写入和编辑工具。
• Plan(规划):用于创建结构化的规划;其执行过程遵循标准的权限模型。
• General-purpose(通用):功能广泛,仅在被明确请求时使用(注:若省略此类型,请求可能会被路由至“分叉子智体”路径)。
• Claude Code Guide(Claude Code 指南):提供入门引导和文档协助,并拥有独立的 permissionMode(权限模式)覆盖设置。
• Verification(验证):执行各类验证检查(如运行测试套件、代码 Lint 检查)。
• Statusline-setup(状态行设置):专用于终端状态行的配置任务。
除了内置类型外,用户还可以通过 .claude/agents/*.md 文件定义自定义子智体;此外,各类插件也可以通过 loadPluginAgents.ts 接口贡献智体定义。每个 Markdown 文件的正文内容将作为该智体的“系统提示”(system prompt);而文件头部的 YAML Frontmatter 部分则用于指定各类配置字段,包括:描述、工具列表(白名单)、禁用工具列表、所用模型、资源投入级别(effort)、权限模式、MCP 服务器配置、钩子函数(hooks)、最大对话轮次、技能集、内存作用域、后台运行标志以及隔离模式。若采用 JSON 格式定义智体,则支持上述所有字段,并额外包含一个显式的 prompt 字段(详见 loadAgentsDir.ts)。这意味着一个自定义智体可以作为一个完全独立配置的子系统运行,拥有专属的工具集、模型、权限、钩子、内存作用域及隔离模式。在基础工具池中,AgentTool 与 SkillTool 并列存在,作为一种“元工具”(meta-tool)负责将任务分派给上述智体定义;但这两种工具在本质上存在根本差异:SkillTool 仅将指令注入到当前的上下文窗口中,而 AgentTool 则会生成并启动一个新的、完全隔离的上下文环境。这种设计带来的权衡是:大多数子智体的调用都需要提供一份自包含的完整提示(prompt),因为默认的调用路径不会继承父级智体的对话历史记录(“分叉子智体”路径除外)。虽然那些共享完整对话记录的框架能够避免这一开销,但随着智体数量的增加,此类框架将面临“上下文爆炸”(context explosion)的潜风险。
2 隔离架构
子智体的隔离机制支持多种模式(详见 AgentTool.tsx):
• Worktree(工作树):创建一个临时的 Git 工作树(worktree),从而为子智体提供一份独立的仓库副本;子智体可直接修改该副本,而不会对父级智体当前的工作树造成任何影响。
• 远程模式(仅限内部使用):在远程 Claude Code Remote 环境中启动,始终在后台运行。
• 进程内模式(默认):与父进程共享文件系统,但在隔离的对话上下文中运行。
针对子智体的权限覆盖逻辑(位于 runAgent.ts 文件中)涉及几条具体规则。当子智体定义 permissionMode 时,该覆盖设置即被应用;但若父智体已处于 bypassPermissions、acceptEdits 或 auto 模式下,则该覆盖无效。这是因为上述父智体模式具有最高优先级,它们代表用户在安全性与自主性权衡方面所做出的明确决策。对于异步智体,系统通过一套级联逻辑来决定是否显示权限提示:首先检查显式的 canShowPermissionPrompts 设置;其次检查“冒泡模式”(bubble mode,该模式下总是显示提示,因为提示信息会逐级上报至父智体的终端界面);最后应用默认规则(即同步智体显示提示,异步智体不显示)。那些允许显示权限提示的后台智体,会将其 awaitAutomatedChecksBeforeDialog 参数设置为 true,从而确保分类器(classifier)和钩子函数(hooks)执行完毕后,才中断用户操作以显示提示。
这些隔离模式在设计空间中占据不同的位置。基于容器的隔离(如 SWE-Agent 和 OpenHands [Yang et al., 2024; Wang et al., 2024b] 所采用)提供更强的资源边界,但也要求具备相应的容器基础设施。仅基于上下文的隔离(如 AutoGen [Wu et al., 2024] 等对话式框架所采用)允许共享文件系统,但将对话历史记录彼此隔离。而 Claude Code 所采用的基于工作树(worktree)的隔离模式,在无需任何外部依赖的情况下实现文件系统层面的隔离;它充分利用 Git 的内置机制,而非引入复杂的容器编排技术。
当调用 runAgent() 函数(位于 runAgent.ts 文件中)时,若显式提供 allowedTools 参数,系统将应用一套双层权限作用域模型。其中,源自 --allowedTools 命令行参数的 SDK 级权限将被保留——这些权限被视为“由 SDK 调用方明确指定、且应适用于所有代理的全局权限”。然而,会话级(session-level)的规则将被子智体所声明的 allowedTools 列表所替换。若未提供 allowedTools 参数(即采用常见的 AgentTool 执行路径),系统将直接继承父智体的会话级规则,而不会进行任何替换。
3 侧链记录
每个子智体都会将自身的交互记录(transcript)写入一个独立的 .jsonl 文件中,并附带一个 .meta.json 元数据文件(参见 sessionStorage.ts 和 runAgent.ts)。这种“侧链”式设计意味着子智体的历史记录得以保留,便于后续的调试与审计,同时又不会导致父智体的会话文件过度膨胀。只有子智体最终的响应文本及相关元数据会被回传至父智体的对话上下文中;子智体的完整历史记录绝不会进入父智体的上下文窗口,从而充分遵循“上下文即瓶颈”这一设计原则。
runAgent() 函数接受多达 21 个参数,涵盖智体定义、提示词、权限、工具、模型设置、隔离机制以及回调函数等多个方面。
这种仅返回摘要信息的模式,是出于节约上下文资源而做出的一项深思熟虑的选择:在那些允许智体之间共享完整交互历史的对话式框架中,随着智体数量的增加,极易引发“上下文爆炸”的风险。即便采用上下文隔离的并行处理模式,其运行成本依然相当高昂。据统计,在“规划模式”(Plan Mode)下,Claude Code 的智体团队所消耗的 Token 数量约为标准会话模式下的 7 倍(Anthropic, 2025b);鉴于此,当子智体同样运行于隔离的上下文中时,这种仅返回摘要信息的机制便显得尤为关键。
针对智体团队内部的多实例协同工作,该运行驾驭(harness)采用文件锁机制,而非传统的中间件消息队列或分布式协调服务(Anthropic, 2025b)。智体通过基于文件锁的互斥机制,从一个共享的任务列表中认领任务;这些锁文件均存储在可预知的特定文件系统路径下。这种设计策略虽然在一定程度上牺牲系统吞吐量,却换取两项至关重要的特性:一是“零依赖”部署(无需任何外部基础设施支持),二是“完全可调试性”(通过读取纯文本格式的 JSON 文件,即可随时检查任意智体的当前状态)。
在编码智体(coding agents)中实现会话持久化时,需要在“仅追加日志(append-only logs)”、“结构化数据库”、“基于检查点的快照”以及“无状态架构”之间做出设计抉择;每种方案在可审计性、查询能力和部署复杂性方面都存在不同的权衡。Claude Code 的持久化设计遵循表 1 中所列的“仅追加持久状态”原则。会话范围内的权限仅存在于内存中,不会被序列化并写入到会话记录(transcript)中;因此,在恢复会话时,系统需要依据命令行参数(CLI args)和磁盘配置来重建权限上下文。对于那些重建后的上下文无法识别的请求,系统将回退至“默认拒绝(deny-first)”的提示处理模式。
当“auth-test”任务执行至本节所述阶段时,当前的会话状态已包含:原始提示、工具调用及其结果、压缩边界(compact boundaries),以及通过探索认证模块所生成的子智体摘要。问题是:上述各类会话产物中,哪些会被持久化保存下来?又有哪些内容可以在后续恢复会话时被重新加载——且在加载过程中,不会将旧会话中已授予的权限一并继承过来?
Claude Code 的持久化机制会在各类事件发生时,即时将对话内容(包括消息、工具执行结果及压缩边界信息)写入磁盘。
1 会话记录模型(Transcript Model)
会话记录(transcripts)主要以“仅追加”模式的 JSONL 文件形式存储在特定项目路径下(唯一的例外是出于清理目的而进行的显式重写操作;详见图 8所示)。getTranscriptPath() 函数(位于 sessionStorage.ts 文件中)负责计算该路径,其计算逻辑为 join(projectDir, ${getSessionId()}.jsonl)。其中,projectDir 的取值优先级如下:首先尝试调用 getSessionProjectDir() 函数(该函数的值由会话恢复/分支操作期间的 switchSession() 函数设置);若获取失败,则回退至调用 getProjectDir(getOriginalCwd())() 函数来确定项目目录。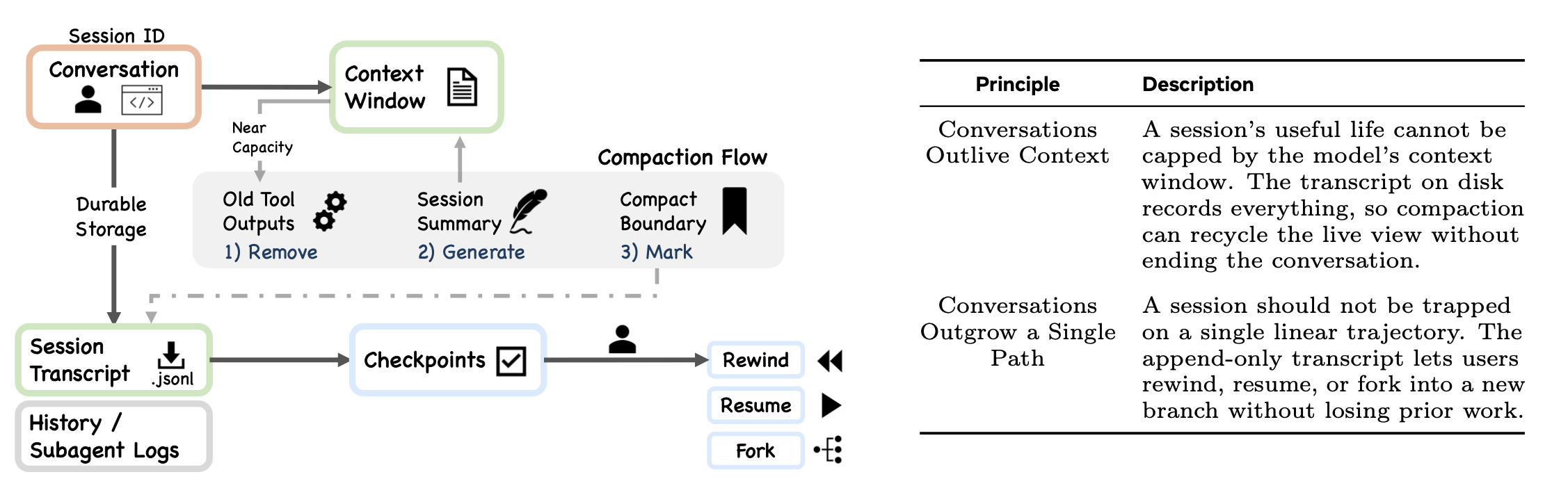
系统内部共有三个独立的持久化通道在并行运作:
- 会话记录(Session transcripts):包含用户、助手、附件及系统消息在内的对话记录;此外还包含压缩操作及其他元数据相关的事件记录。此类记录以项目为作用域,每个会话对应一个独立的记录文件。
- 全局提示历史(Global prompt history):仅存储用户输入的提示语(prompts),文件名为
history.jsonl,存储位置位于 Claude 配置文件的根目录下(相关逻辑位于history.ts文件中)。makeHistoryReader()生成器函数通过调用readLinesReverse()方法,以逆序(倒序)的方式逐条返回历史记录条目,从而支持用户通过“上箭头”键和Ctrl+r快捷键进行历史命令的导航与检索。 - 子智体侧链(Subagent sidechains):为每个子智体单独创建并存储一组文件,具体包括一个
.jsonl文件和一个.meta.json文件。
会话转录记录不仅存储简单的消息,还包含多种类型的事件,例如压缩标记(markers)、文件历史快照、归属快照以及内容替换记录。采用“仅追加”的 JSONL 格式是一项有意为之的决策,旨在优先确保可审计性和简洁性,而非追求强大的查询能力。每一项事件均具备人类可读性、支持版本控制,且无需借助专用工具即可进行重构。虽然基于数据库的替代方案能够实现针对会话历史的更丰富查询功能,但同时也引入了部署依赖性,并降低了系统的透明度。
会话身份识别系统将 sessionId 与 sessionProjectDir 进行配对,这两项标识会在会话恢复或分支操作期间一并设定。转录记录的存储路径必须与消息写入时所处的活动项目目录保持一致,以防止钩子程序在错误的目录中进行查找。
2 恢复(Resume)、分叉(Fork)与权限不予恢复
--resume 标志通过重放对话记录(transcript)来重建对话(见 conversationRecovery.ts)。Fork 命令则基于现有会话创建一个新会话(见 commands/branch/branch.ts)。然而,无论是“恢复”还是“分叉”操作,都不会恢复会话范围内的权限;用户必须在新会话中重新授予这些权限。这是一项经过深思熟虑、旨在保守确保安全的设计选择:将每个会话视为一个独立的信任域。如果在恢复会话时自动恢复此前已授予的权限,虽然能带来便利,但也存在将过时的信任决策带入已发生变化的上下文环境中的风险。因此,该架构选择“重新授予”而非“隐式持久化”的方案,并接受由此可能给用户带来的操作阻力,将其视为维护安全不变性(即信任关系必须始终在当前会话中建立)所必须付出的代价。compact_boundary 标记经过精心设计,旨在与持久化机制协同工作。annotateBoundaryWithPreservedSegment() 函数(见 compact.ts)会在边界事件中记录 headUuid、anchorUuid 和 tailUuid。利用这些 UUID,会话加载器(session loader)能够在读取数据时对消息链进行修补:那些被保留下来的消息在磁盘上依然保持其原有的 parentUuid,而加载器则利用边界元数据来确保它们能够被正确地链接起来。这种以“追加写入”为主的设计模式意味着:数据压缩(compaction)操作绝不会修改或删除此前已写入的对话记录行。
Claude Code 中的“检查点”(checkpoints)特指用于 --rewind-files 命令的文件历史检查点,其存储路径位于 ~/.claude/file-history/<sessionId>/。这些检查点属于文件层面的快照,专门用于回滚文件系统的变更,而非通用的检查点存储机制。
前文记录 Claude Code 针对一系列常见设计问题所给出的解答,这些问题涵盖循环架构、安全性、可扩展性、上下文管理、委托机制以及持久化等方面。为了对这些发现进行校准,将 Claude Code 与 OpenClaw 进行对比;OpenClaw 是一个独立的开源 AI 智体系统,它针对许多相同的设计问题,从一个截然不同的出发点给出相应的解答。OpenClaw 是一个“本地优先”(local-first)的 WebSocket 网关,它将大约二十余种消息交互界面(包括 WhatsApp、Telegram、Slack、Discord、Signal 等)连接至一个嵌入式智体运行时环境,并配有适用于 macOS、iOS 和 Android 平台的配套应用程序(Steinberger 和 OpenClaw 贡献者,2026)。如果说 Claude Code 是一个绑定至单一代码仓库会话的命令行(CLI)编码辅助工具,那么 OpenClaw 则是一个专为多渠道个人辅助服务而设计的持久化控制平面。这两个系统在“智体设计空间”中占据着截然不同的区域。进行此项对比的价值在于,它能够揭示:当部署环境发生变化时,面对同一系列常见的设计问题,系统架构会给出何种截然不同的解答。
1 六个对比维度
表 3 总结双方在六个维度上的对比情况。每一个维度都对应着一个设计问题,且这两个系统都必须针对这些问题给出解决方案。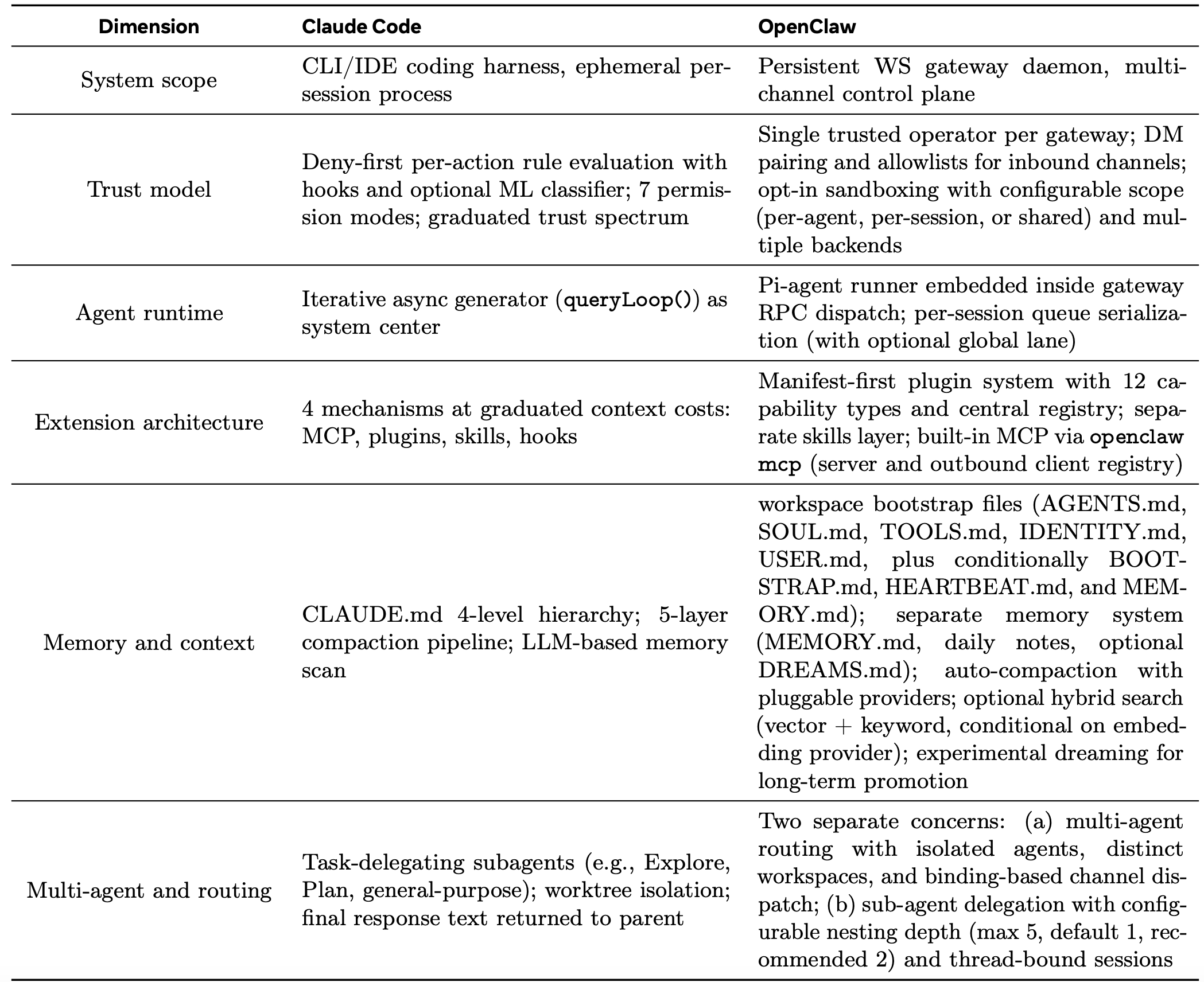
系统范畴与部署模型。Claude Code 作为一种“瞬时性”的命令行(CLI)进程运行,且仅绑定至单一的代码仓库。其每一个会话的生命周期均与终端窗口的开启与关闭同步。相比之下,OpenClaw 则作为一个“持久化”的守护进程(默认端口 18789,仅限本地回环访问)运行;它负责管理所有消息交互界面的连接,并通过一套类型化的 WebSocket 协议,对客户端、工具以及设备节点进行统一协调。这种在系统范畴上的差异,构成两者之间最为根本的架构分歧:它决定了其余所有设计问题将以何种视角和框架被加以审视与解决。此外,两者之间还存在一种“组合式”的关系:OpenClaw 能够通过其 ACP(代理客户端协议)集成机制,将 Claude Code、OpenAI Codex 以及 Gemini CLI 等工具作为“外部编码辅助工具”加以托管;这意味着这两个系统并非单纯的互斥替代品,而是可以相互叠加、协同工作的。
信任模型与安全架构。这两个系统所针对的“威胁模型”各不相同。Claude Code 假定自身运行于一个“不受信任”的环境模型之中——尽管其宿主环境(即开发者的本地机器)本身是可信的;为此,它采用一套“默认拒绝”(deny-first)的权限管理系统来逐一审查每一次工具调用请求;同时,其内置的机器学习分类器可提供自动化的安全风险评估;此外,系统还提供七种不同的权限模式,从而构建出一个涵盖不同自主程度的“分级自治”光谱。OpenClaw 所假定的模型则是:每一个网关实例均由且仅由一位“受信任的操作者”进行管理。因此,其安全架构的基石并非针对单一操作行为进行安全分类,而是聚焦于“身份认证与访问控制”机制(具体包括:私信配对码、发送者白名单、网关身份验证等)。工具策略采用针对每个智体(Agent)的可配置“允许/拒绝”列表,而非集中式的分类器。沙箱功能作为一项可选特性提供,支持多种后端(Docker、SSH 或 OpenShell)及可配置的作用域(按智体、按会话或共享);启用“非主模式”时,系统可对所有非主会话进行沙箱隔离,尽管默认情况下沙箱功能处于非激活状态。OpenClaw 的安全文档明确指出,在共享网关上实现针对恶意多租户的隔离,并非其所支持的安全边界。这一差异体现设计者在确立信任边界位置时的不同取舍:Claude Code 将信任边界置于模型与执行环境之间;而 OpenClaw 则将其置于网关的外围边界处。
智体运行时与工具编排。两套系统均实现“智体循环”(Agentic loops),但这些循环在其各自的架构中占据着截然不同的位置。在 Claude Code 中,queryLoop() 异步生成器构成整个系统的核心:所有接口的输入均汇聚于此,并由其直接负责管理上下文组装、模型调用、工具分派以及故障恢复等任务。而在 OpenClaw 中,智体运行时(即内嵌的 Pi-agent 核心)则位于一个更为宏大的网关分派层内部。网关层的智体 RPC 负责参数校验与会话解析,并随即返回结果;随后,内嵌的运行器接手执行智体循环,同时通过网关协议向外广播生命周期事件及流式事件。所有的运行任务均通过“按会话划分的队列”以及一个可选的“全局通道”进行序列化处理,从而有效杜绝在多通道交互界面上可能出现的工具与会话之间的竞态冲突。两套系统均遵循 ReAct 模式(Yao,2022),但 OpenClaw 中的智体循环仅作为控制平面内部的一个组件而存在,而非其本身即构成整个控制平面。
扩展架构。Claude Code 的四种扩展机制(即 MCP、插件、技能与钩子)依据“上下文开销”进行归类:其中,钩子机制不消耗任何上下文资源;技能机制消耗少量上下文资源;而 MCP 服务器则会消耗大量的上下文资源。这四种机制均旨在对单个智体的上下文窗口及工具交互界面进行功能扩展。OpenClaw 则采用一套“清单优先”(Manifest-first)的插件系统,该系统由发现、启用、运行时加载以及界面消费这四个架构层级构成,并涵盖十二种不同的能力类型,具体包括文本推理、语音交互、媒体理解、图像/音乐/视频生成、网络搜索以及消息通道交互等。插件将其功能注册到一个中心注册表中;网关读取该注册表,从而对外暴露工具、通道、提供商配置、钩子(Hooks)、HTTP 路由、CLI 命令以及各类服务。OpenClaw 还设有一个独立的“技能层”(Skills Layer),其技能来源多样(包括工作区、项目级、个人级、托管级、捆绑级及额外目录,其中工作区技能具有最高优先级);此外,它还对接一个公共注册表(ClawHub),并通过内置的 openclaw mcp 命令(涵盖服务器端与出站客户端注册)支持 MCP 协议。两者的关键架构差异在于:Claude Code 的扩展程序仅修改单个智体的行动界面(Action Surface),而 OpenClaw 的插件则扩展网关的功能界面,从而惠及所有智体。
记忆、上下文与知识管理。这两个系统均采用透明的、基于文件的记忆机制,而非不透明的数据库存储。Claude Code 加载一个四层级的 CLAUDE.md 文件层级结构,并通过一个五层级的压缩管道来管理上下文压力。其记忆检索机制基于大语言模型(LLM),通过扫描文件头部信息来实现。OpenClaw 则在会话启动时,将工作区的引导文件(Bootstrap files)注入到系统提示词(System Prompt)中:这包括五个核心文件(AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md),以及根据条件注入的 BOOTSTRAP.md、HEARTBEAT.md 和 MEMORY.md(其中大型文件会被截断处理)。此外,其记忆系统独立管理着三种类型的文件:用于存储长期持久性事实的 MEMORY.md;带有日期戳的每日笔记文件(位于 memory/YYYY-MM-DD.md 路径下);以及用于存储“梦境”(Dreaming)清扫摘要的可选文件 DREAMS.md。若配置嵌入(Embedding)提供商,记忆搜索功能将采用混合检索模式,结合向量相似度匹配与关键词匹配进行查找。一套实验性的“梦境系统”会在后台执行记忆整合任务:它会对候选条目进行评分,仅将符合条件的条目从短期回忆区晋升至长期记忆库中。在执行上下文压缩操作之前,OpenClaw 会自动提醒记忆将重要笔记保存至记忆文件中,从而有效防止上下文信息的丢失。这两个系统在设计理念上均秉持同一承诺:即记忆数据必须对用户可见且可编辑。OpenClaw 在结构化长期记忆的晋升机制(包括梦境系统、每日笔记及记忆搜索)方面投入更多资源;而 Claude Code 则在分级式上下文压缩机制(即具备缓存-觉察能力的五层级压缩管道)方面投入更多精力。OpenClaw 虽然也支持可插拔的压缩提供商及会话剪枝功能,但其上下文压缩管道的分级精细度不及 Claude Code 的五层级系统。
多智体架构与路由。这一维度揭示两者在架构上最为显著的差异。Claude Code 的多智体模型采用的是“任务委托”模式:父智体生成子智体(包括探索、规划、通用及自定义类型),这些子智体在相互隔离的上下文窗口中运行,仅拥有受限的工具集,且仅返回摘要式结果。工作树(Worktree)隔离机制提供文件系统层级的隔离保障。OpenClaw 则将两类截然不同的关注点进行分离。首先是多智体路由:单个网关可托管多个完全相互隔离的智体实例,每个实例均拥有独立的工作空间、身份验证配置文件、会话存储及模型配置,并可通过确定性的绑定规则被路由至特定的通道或发送方。其次是子智体委托:在单个智体内部,可生成后台运行任务,其嵌套深度可配置(上限 5 层,默认为 1 层,建议设为 2 层);在受支持的通道上,这些任务可绑定至特定线程会话;此外,不同深度的任务层级还可应用不同的工具策略。OpenClaw 的项目愿景明确拒绝将“智体层级结构”作为默认的架构范式。这种区分至关重要,因为 Claude Code 的子智体仅是隶属于同一用户编程会话之下的辅助工作单元;而 OpenClaw 的多智体路由机制则创建真正相互独立的智体实例,通过不同的通道服务于不同的用户或不同的应用目的。
2 对比所揭示的洞见
通过对比分析,对 AI 智体系统的设计空间得出三点观察。
首先,第那些反复出现的设计问题(即推理功能应置于何处、应采取何种安全姿态、如何管理上下文、以及如何构建可扩展性)并不仅仅局限于代码编写类智体。OpenClaw 对上述每一个问题都给出解答,但其设计出发点是一个“多渠道个人助理”,而非一个局限于代码仓库的“代码编写工具”。这些设计问题本身具有普适性和稳定性,但针对这些问题的具体解答则会随着部署环境的不同而发生变化。
其次,这两套系统在多个设计维度上采取截然不同的策略。Claude Code 侧重于投入资源构建“逐动作”的精细化安全评估机制;而 OpenClaw 则侧重于构建“边界层级”的身份与访问控制机制。Claude Code 将“智体循环”(Agent Loop)视为其架构的核心;而 OpenClaw 则将“网关控制平面”视为核心,并将智体循环作为其中的一个嵌入式组件。Claude Code 的扩展功能主要通过修改单一的“上下文窗口”来实现;而 OpenClaw 的插件功能则是通过扩展共享的“网关交互界面”来实现。这些设计上的反向选择并非随意为之,而是源于两套系统所采用的不同信任模型及部署拓扑结构。
第三,这两套系统之间所存在的“组合关系”在架构层面具有重要的意义。OpenClaw 能够通过 ACP 协议将 Claude Code 作为一种“外部代码执行框架”进行托管;这意味着这两套系统之间并非互斥的替代品,而是可以相互组合、协同工作的。这一事实表明,AI 智体系统的设计空间并非一种扁平化的分类体系,而是一种分层化的结构——在这一结构中,处于网关层级的系统与处于任务层级的执行框架是可以相互组合、协同运作的。
讨论
略
未来方向
略
相关工作
略

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献111条内容
已为社区贡献111条内容

所有评论(0)