深入探索 Claude Code:当今与未来 AI 智体系统的设计空间(上)
26年4月来自阿联酋MBZUAI和英国UCL的论文“Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems”。
Claude Code 是一款具备智体能力的编程工具,能够代表用户执行 Shell 命令、编辑文件以及调用外部服务。本研究通过分析其公开可用的 TypeScript 源代码,详述该工具的综合架构;此外,本研究还将其与 OpenClaw 进行对比——OpenClaw 是一个独立的开源 AI 智体系统,它在截然不同的部署语境下,针对许多相同的架构设计难题给出了不同的解决方案。其分析归纳出五项驱动该架构设计的人本价值观、理念与需求(即:人的决策主导权、安全与防护、执行可靠性、能力增强以及语境适应性),并追溯这些理念如何通过十三项具体的设计原则,最终落实为特定的实现方案。该系统的核心是一个简单的“while”循环结构,负责依次调用语言模型、执行各类工具,并周而复始地循环运行。然而,该系统的绝大部分代码逻辑实际上分布于围绕这一核心循环构建的周边组件之中:其中包括一套具备七种运行模式及基于机器学习分类器的权限管理系统;一套用于上下文管理的五层级压缩流水线;四种实现系统扩展性的机制(即 MCP、插件、技能与钩子);一套用于实现子智体任务委托与协同编排的机制;以及一套采用追加写入模式的会话存储系统。通过与 OpenClaw(一款多通道个人助理网关系统)进行对比,可以发现:当部署上下文发生变化时,针对同一组反复出现的架构设计难题,往往会产生截然不同的架构解决方案——具体表现为:从针对单次操作的安全性评估转向边界层级的访问控制;从单一的命令行界面(CLI)循环模式转向嵌入于网关控制平面内部的运行时环境;以及从局限于特定“语境窗口”范围内的扩展机制,转向覆盖整个网关层面的全局能力注册机制。最后,基于近期在实证研究、架构设计及策略制定等领域的文献成果,为未来的智体系统指出六个值得深入探索的开放性设计方向。
AI 辅助软件开发已历经演进:从 GitHub Copilot (Chen et al., 2021) 等自动补全式工具,过渡到 Cursor (Cursor, 2026) 等集成于 IDE 的辅助工具,最终发展为完全具备“智体”(agentic)特性的系统——此类系统能够自主规划多步修改、执行 Shell 命令、读写文件,并对自身的输出进行迭代优化。Claude Code (Anthropic, 2026a) 正是由 Anthropic (Anthropic, 2026c) 发布的一款智体式编程工具。其官方文档描述一种“智体循环”(agentic loop)机制:该机制负责规划并执行一系列操作以达成既定目标,并具备调用外部工具、评估执行结果的能力,直至任务圆满完成。这种从单纯提供“建议”向执行“自主行动”的范式转变,引入一系列全新的架构设计需求——这些需求在基于代码补全的传统工具中是前所未有的。这些需求共同构筑一个特定的“设计空间”:即一系列反复出现的关键议题,涵盖安全性、上下文管理、系统可扩展性以及任务委托机制等多个维度;任何一款智体式编程工具在设计与实现过程中,都必须妥善应对并解决这些议题。本研究通过对 Claude Code 进行源代码层面的深度分析,旨在揭示这一已投入实际生产应用的系统是如何具体应对并解决上述架构设计挑战的。
尽管 Claude Code 的用户群体正日益壮大,但 Anthropic 目前仅发布面向终端用户的操作文档,却未公开其详尽的系统架构设计说明。因此,本研究将借助对源代码的剖析,对该工具背后的架构设计决策进行详尽阐述。Anthropic 针对 132 名工程师与研究人员开展的一项内部调研 (Huang et al., 2025) 结果显示:约有 27% 的任务是在 Claude Code 的辅助下才得以启动并完成的——若无此工具,这些任务原本根本不会被尝试执行。这一数据有力地表明,该系统的架构设计并非仅仅局限于对现有工作流程进行单纯的“提速”优化,而是赋能并催生了具有本质性突破与创新性的全新工作流程。
用于生产环境的编程智体由人类构建,亦为人类服务;其内在的架构决策,折射出其创造者所看重的核心理念。Anthropic 关于安全智体的框架指出一个核心的内在张力:“智体必须具备自主工作的能力;正是这种独立运作的特性,赋予它们真正的价值。然而,人类应当始终掌握对其目标实现方式的控制权”(Anthropic, 2025a)。Claude 的《宪章》(Constitution)并未试图通过僵化的决策流程来化解这一张力,而是致力于培育一种“能够根据具体情境灵活运用的良好判断力与健全价值观”(Anthropic, 2026b)。上述承诺,结合关于开发者实际如何使用该工具的实证研究发现(Huang et al., 2025; McCain et al., 2026),共同指向塑造其架构的五项核心人本价值观。
1 五大价值观与理念
人类决策主导权(authority)。人类对系统的具体运作保留最终决策权;这一权力通过一种“主体层级结构”(Anthropic 公司 → 运营人员 → 用户)进行组织,从而正式界定“谁对何事拥有何种权限”(Anthropic, 2026b)。系统的设计旨在确保人类能够行使“知情控制”:即能够实时观察系统的行动、批准或拒绝拟议的操作、中断正在进行且兼容的操作,以及在事后进行审计。当 Anthropic 发现用户对 93% 的权限提示都选择“批准”时(Hughes, 2026),其应对策略并非简单地增加更多警告,而是对问题进行结构性重构:即划定明确的边界(通过“沙盒机制”和“自动模式分类器”实现),允许智体在这些边界范围内自由运作;以此取代那种需要对每一个具体动作进行审批的模式——因为用户一旦形成习惯,往往就会停止对这类审批进行审视(Dworken & Weller-Davies, 2025)。
安全、安保与隐私。系统致力于保护人类用户、其代码、数据及基础设施免受损害,即便用户处于疏忽大意或犯错的状态下,系统依然履行这一保护职责。这一点与前述的“人类决策主导权”有所区别:前者关乎人类行使选择的权力,而后者则关乎系统履行保护的义务——即便人类的决策权力因故失效,系统依然必须提供保护。Anthropic 的“安全智体框架”(Safe-Agents Framework)明确将“确保智体交互过程的安保性”以及“在跨越长时间、多轮次的交互过程中保护用户隐私”列为其核心承诺(Anthropic, 2025a)。其针对“自动模式”所构建的威胁模型(Hughes, 2026)明确聚焦于四大风险类别:过度热心的行为、无心之失、提示注入攻击,以及模型目标错位(即模型行为与人类意图不一致)。
可靠执行。智体执行的指令必须准确契合人类的真实意图,其行为表现需随时间推移保持一致与连贯,并且支持在正式宣告任务成功之前对工作成果进行验证。这一价值观涵盖两个层面:一是“单轮次正确性”(即智体是否忠实地解读用户的请求?);二是“长周期可靠性”(即智体能否在跨越上下文窗口边界、恢复中断的会话、以及涉及多智体协作委托等场景下,依然保持行为的连贯性?)。Anthropic 的产品文档(Anthropic, 2026d)描述一个由智体反复执行直至任务完成的“三阶段循环”流程:收集上下文信息 → 执行具体动作 → 验证结果。此外,智体设计指南(Schluntz & Zhang, 2024)进一步强调,在上述流程的每一个步骤中,都必须依据“源自环境的真值”(Ground Truth)来对任务进展进行评估。关于“驾驭(Harness)”设计(Rajasekaran, 2026)的指导原则同样指出,“智体往往倾向于通过自信地赞扬其工作来做出响应”——即便工作质量平庸(mediocre)——这将“生成”环节与“评估”环节分离开来。
能力放大(Capability Amplification)。该系统能够实质性地提升人类用户在单位投入和成本下所能完成的工作量。Anthropic 内部的一项调研(Huang et al., 2025)表明,该架构所促成的并非仅仅是现有工作流程的提速,而是催生在本质上全新的工作流程:在调研涵盖的任务中,约有 27% 属于若无该系统辅助便根本不会被尝试去完成的工作。该系统的创建者将其描述为“一种 Unix 实用工具,而非传统的软件产品”;它由一系列最小化的基础构建模块搭建而成,这些模块具备“实用、易懂且可扩展”的特性(Cherny and Wu, 2025)。该架构的资源投入侧重于确定性的基础设施(如上下文管理、工具路由、故障恢复等),而非决策辅助框架(如显式规划器或状态图);其核心预设在于:随着模型能力的不断增强,它们将从丰富且灵活的运行环境中获益更多,而非受制于那些会限制其选择空间的僵化框架。
上下文适应性(Contextual Adaptability)。该系统能够精准地契合用户的特定上下文环境(包括其所参与的项目、使用的工具、既定的工作惯例以及自身的技能水平),且这种契合度会随着时间的推移而不断提升。其扩展架构(涵盖 CLAUDE.md、技能模块、MCP 机制、钩子函数及插件等组件)提供多层级的可配置选项,以灵活应对不同层面的“上下文成本”需求。纵向追踪数据(McCain et al., 2026)显示,人与智体之间的协作关系呈现出动态演化的特征:在用户与系统交互不足 50 个会话(sessions)的初期阶段,系统输出内容的自动批准率约为 20%;而当交互会话数累积至 750 个时,该批准率已显著提升至 40% 以上。这种演变模式被描述为一种“由模型、用户及产品三方共同构建”的自主性机制;这意味着该系统的设计理念并非基于某种固定的信任状态,而是旨在支持一种动态演进的“信任轨迹”。MCP 项目向 Linux 基金会下属的“智体 AI 基金会”(Agentic AI Foundation)所作出的捐赠(The Linux Foundation, 2025),正是这一核心价值观在生态系统层面的具体体现。
2 设计原则
这些价值观通过十三项设计原则得以落地实施,每一项原则都旨在解答生产级代码编写智体(coding agents)必须解决的一个常见问题。表 1 概述这些原则。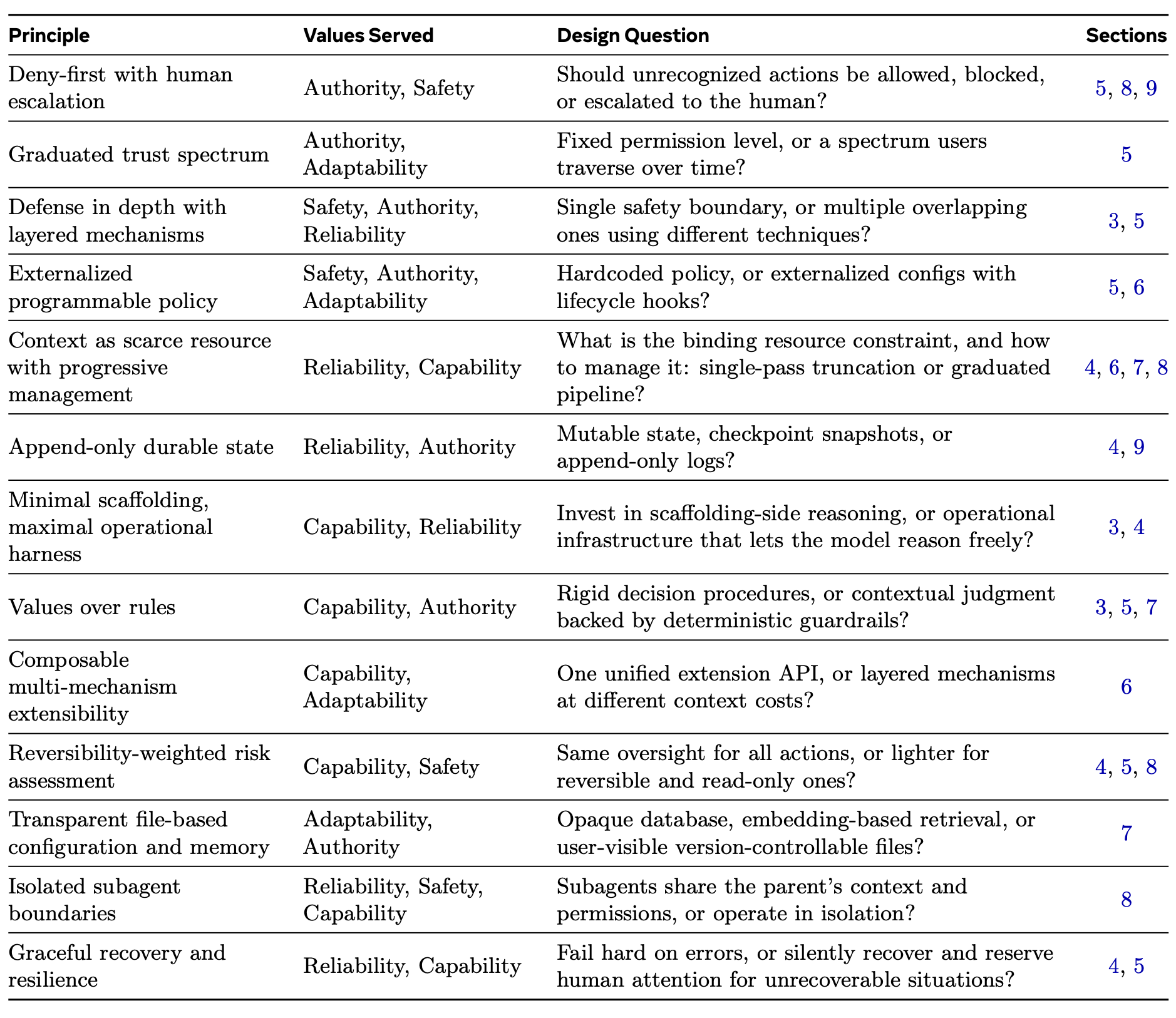
解读这些原则时,可将其与三种主要的替代设计范式进行对比。首先是“基于规则的编排”:以 LangGraph(LangChain, Inc., 2024)为代表的框架将决策逻辑编码为带有类型化边的显式状态图,倾向于采用结构化的脚手架(scaffolding),而非极简的驾驭(minimal harness)。其次是“容器隔离执行”:SWE-Agent 和 OpenHands(Yang et al., 2024; Wang et al., 2024b)依赖 Docker 容器提供的隔离机制,而非分层策略强制执行机制。第三是“以版本控制为安全保障”:像 Aider(Gauthier, 2024)这样的工具将 Git 回展(rollback)作为主要的安全性保障手段,而非采用“默认拒绝”(deny-first)的评估策略。Claude Code 的原则体系独具特色,它巧妙地结合了“极简决策脚手架与分层策略强制执行”、“基于价值观的判断与默认拒绝策略”,以及“渐进式上下文管理与可组合的扩展能力”。
3 从价值观到架构
每一项价值观都通过其对应的设计原则,最终落实为具体的架构决策:
• “人类决策主导权”(Human Decision Authority)这一价值观,促成“默认拒绝”评估策略、分级信任体系、仅追加(append-only)状态记录(即可审计的历史记录)、外部化可编程策略,以及“价值观优先于规则”的设计理念。
• “安全、保障与隐私”(Safety, Security, and Privacy)这一价值观,促成了纵深防御机制、“默认拒绝”策略、侧重可逆性的风险评估、外部化策略,以及隔离的子代理边界。
• “可靠执行”(Reliable Execution)这一价值观,确立“将上下文视为稀缺资源”的理念、仅追加的持久化状态、优雅恢复机制、隔离的子智体边界,以及纵深防御机制。
• “能力增强”(Capability Amplification)这一价值观,促成极简的脚手架设计、可组合的扩展能力、侧重可逆性的风险管理、上下文管理机制,以及优雅恢复机制。
• “上下文适应性”(Contextual Adaptability)这一价值观,促成基于文件的透明记忆机制、可组合的扩展能力、分级信任体系,以及外部化可编程策略。这些映射同时也揭示该架构未涉足的领域:它既未在模型的推理过程中强行植入显式的规划图(planning graphs),也未提供单一统一的扩展机制,更未在会话恢复时完整还原所有会话范围内的信任相关状态。这些特意的“缺失”恰与上文确立的设计原则相吻合。
4 评估视角:长期能力之维系
上文列举的五项价值观,界定该架构的设计初衷与服务宗旨。此外,本文还引入第六项考量——即该架构能否维系人类的长期能力——并将其作为一种独特的评估视角。这一考量绝非杞人忧天:Anthropic 针对 132 名工程师与研究人员开展的一项内部研究(Huang et al., 2025)揭示一种所谓的“监督悖论”——即对 AI 的过度依赖,恐将导致人类自身监督 AI 所需技能的退化;而另一项独立研究(Shen and Tamkin, 2026)亦发现,在 AI 辅助环境下工作的开发者,其在理解力测试中的得分较非辅助环境下的开发者低 17%。然而,在当前的架构设计中,抑或在 Anthropic 公布的设计价值观中,这一考量并未作为一项核心的设计驱动力而得到突出体现。鉴于此,并未将其视作一项与前五项价值观平起平坐的等同价值,而是将其定位为一项贯穿始终的“横向关切”(cross-cutting concern):即对前述五项价值观进行逐一审视时,始终伴随的一个核心追问——所获得的短期能力增益,是否正以牺牲人类的长期理解力、代码库的整体一致性以及开发者人才梯队的健康发展为代价?
构建一个生产级的代码编写智体(coding agent)需要回答几个反复出现的设计问题:推理逻辑应置于何处?需要多少个执行引擎?应采取何种安全态势?以及应将何种资源视为核心的约束条件?Claude Code 的架构可以被视为对这些问题的一组具体解答。在实现层面,该系统由七个组件构成,并通过一条主数据流相互连接:用户通过多种接口之一提交提示(prompt),该提示随后被输入到一个共享的智体循环(agent loop)中。该智体循环负责汇编上下文信息、调用 Claude 模型、接收响应(响应中可能包含工具使用请求)、通过权限系统对这些请求进行路由,并将获批的操作分派给具体的工具,由这些工具与执行环境进行交互。在整个流程中,状态管理与持久化机制负责记录对话记录、管理会话身份,并支持会话的恢复、分支(fork)及回溯(rewind)操作。
1 设计问题与运行示例
本文的描述围绕四个设计问题展开,这些问题在各类生产级代码编写智体的设计中反复出现,且每一个问题都对应并体现表 1 中所列的一项或多项设计原则。
推理逻辑应置于何处?在 Claude Code 中,模型负责进行推理以决定“做什么”;而驾驭(harness)则负责执行具体的动作。模型在生成响应时会输出包含“工具使用”(tool_use)指令的代码块;随后,驾驭负责解析这些指令、进行权限校验、将其分派给相应的工具实现模块,并收集执行结果(具体逻辑见 query.ts 文件)。模型本身绝不直接访问文件系统、执行 Shell 命令或发起网络请求。这种职责分离的设计带来一项重要的安全优势:由于推理逻辑与执行强制机制分处于不同的代码路径,即使模型本身遭到入侵或被恶意操纵,也无法绕过驾驭中所实施的沙箱隔离、权限校验以及“默认拒绝”(deny-first)等安全规则。模型与外部世界进行交互的唯一接口是结构化的“工具使用协议”(tool_use protocol),且驾驭在执行前会对该协议指令进行严格的有效性验证。社区对已提取的源代码进行分析后估算,在 Claude Code 的整个代码库中,仅有约 1.6% 的代码构成 AI 的决策逻辑,而剩余的 98.4% 均为支撑系统运行的基础设施代码;这一比例生动地揭示核心智体推理层在整个系统中是何等精简与轻量。其他设计方案在“脚手架”层面的推理上投入更多资源:Devin 维护着显式的规划和任务追踪结构,而 LangGraph(LangChain, Inc., 2024)则通过开发者定义的状态图来路由控制流。
有多少个执行引擎?Claude Code 采用单一的 queryLoop() 函数进行执行,无论用户是通过交互式终端、无头(headless)CLI 调用、Agent SDK 还是 IDE 集成进行交互,该函数都能正常运行(参见 query.ts)。只有渲染层和用户交互层会因界面形式而异。其他系统则采用针对特定模式的引擎:例如,IDE 集成可能会遵循与 CLI 工具不同的代码路径,以此牺牲统一性来换取针对特定界面的优化效果。
默认的安全策略是什么?Claude Code 的默认安全策略是“优先拒绝并交由人工介入”(deny-first with human escalation):即“拒绝”规则优先于“询问”规则,而“询问”规则又优先于“允许”规则;对于无法识别的操作,系统会将其上报给用户处理,而非静默允许(参见 permissions.ts)。系统并行应用多个独立的安全层(包括权限规则、PreToolUse 钩子、启用时的自动模式分类器,以及可选的 Shell 沙箱机制),因此任何一层都能阻断潜在的危险操作。这一设计结合表 1 中所列的“优先拒绝并交由人工介入”原则,以及“深度防御与分层机制”原则。其他方案则将信任边界设定在不同的位置:SWE-Agent 和 OpenHands(Yang et al., 2024; Wang et al., 2024b)依赖基于容器的隔离技术来限制任意代码的执行范围;而 Aider(Gauthier, 2024)则将基于 Git 的版本回展(rollback)机制作为其主要的最后一道安全防线。
主要的资源约束瓶颈是什么?在 Claude Code 中,上下文窗口(旧版模型为 200K,Claude 4.6 系列模型为 1M)是主要的资源约束瓶颈。在每次调用模型之前,系统都会执行五种不同的上下文缩减策略(参见 query.ts);此外,还有多项子系统决策(如指令的惰性加载、工具模式的延迟加载、子智体仅返回摘要等)旨在限制上下文的消耗量。之所以采用这种五层处理流水线,是因为没有任何单一的压缩策略能够解决所有类型的上下文压力问题。“预算缩减”(Budget reduction)策略专门针对那些超出大小限制的单个工具输出内容;“代码片段”(Snip)策略负责处理时间维度上的深度问题;“微压缩”(Microcompact)策略用于应对缓存开销;而“上下文折叠”(Context collapse)策略则用于管理极长的历史交互记录。 Auto-compact 仅作为最后手段执行语义压缩。每一层级均对应不同的成本效益权衡,其中成本较低的层级会优先于成本较高的层级运行。另类架构将其他资源视为主要瓶颈,例如计算预算(限制模型调用或工具调用的次数)或工作记忆(维护显式的暂存区,而非仅仅依赖对话历史记录)。
运行示例。为了具体阐释这些原则,选一个单一任务:“修复 auth.test.ts 中失败的测试“。
2 高层级系统架构
这一由七个组件构成的模型(如图 1 所示)与源代码文件直接对应: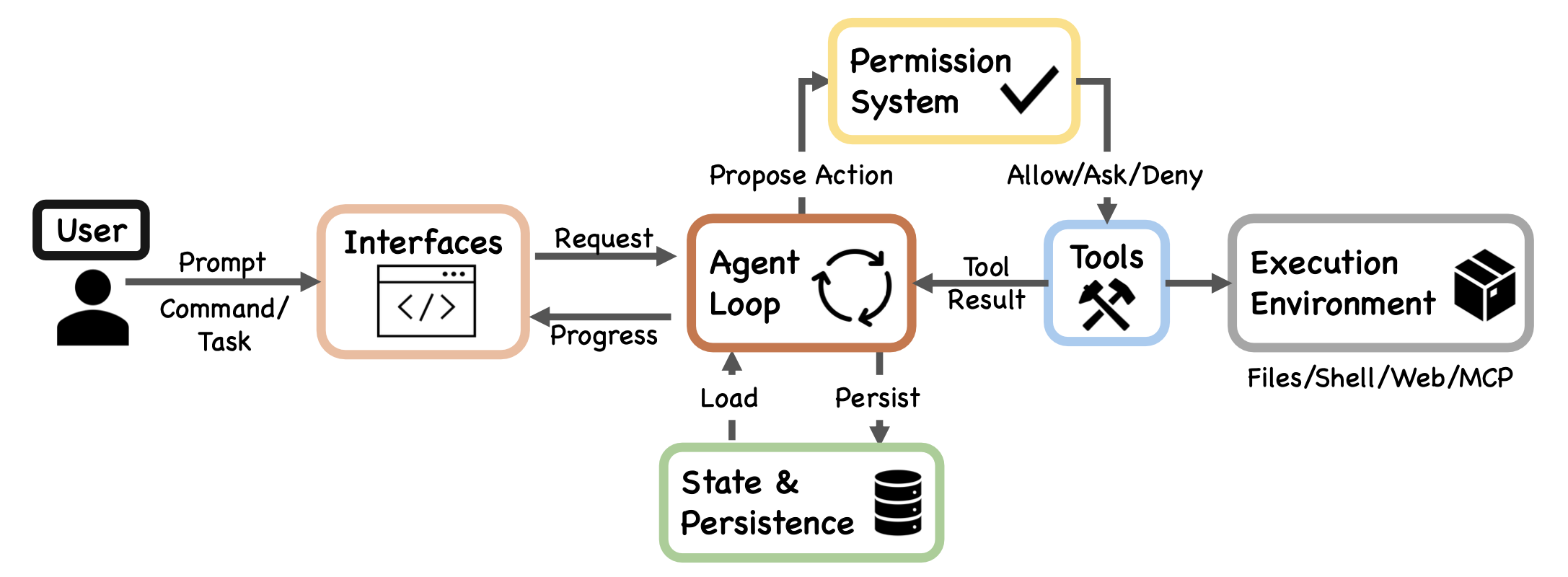
- 用户(User):提交提示词、批准权限、审查输出结果。
- 界面(Interfaces):交互式命令行界面(CLI)、无头模式命令行界面(
claude -p)、智体 SDK,以及 IDE/桌面应用/浏览器插件。所有这些交互界面最终都将请求汇入同一个处理循环中。 - 智体循环(Agent loop):即“模型调用—工具分派—结果收集”这一迭代周期,在
query.ts文件中以异步生成器函数queryLoop()的形式实现。 - 权限系统(Permission system):包含“默认拒绝”(Deny-first)规则评估机制(
permissions.ts)、用于自动模式的机器学习分类器,以及基于钩子(Hook)的拦截机制(types/hooks.ts)。 - 工具集(Tools):包含多达 54 种内置工具(其中 19 种为无条件可用,35 种取决于功能标志和用户类型),这些工具通过
assembleToolPool()函数(tools.ts)进行组装,并与 MCP 服务器提供的工具进行合并。插件则通过 MCP 服务器以及技能/命令注册表间接提供功能支持。 - 状态与持久化(State & persistence):主要包括采用 JSONL 格式且仅支持追加写入的会话记录(
sessionStorage.ts)、全局提示词历史记录(history.ts),以及子智体的侧链文件。 - 执行环境(Execution environment):涵盖支持可选沙箱隔离的 Shell 命令执行(
shouldUseSandbox.ts)、文件系统操作、网络抓取、与 MCP 服务器的连接通信,以及远程代码执行等功能。
数据流沿着一条“从左至右”的主轴线推进:用户通过某个界面提交请求,该请求随即进入智体循环。智体循环向权限系统提议待执行的操作;经批准的操作指令随后被分派给相应的工具;工具负责与执行环境进行交互,并将执行结果(tool_result 消息)反馈回智体循环。状态管理与持久化模块则伴随在智体循环的侧翼,负责记录会话过程,并在需要时加载过往的会话数据。位于 main.tsx 中的应用程序入口点 main() 负责初始化安全设置(包括用于防范 Windows PATH 劫持的 NoDefaultCurrentDirectoryInExePath),注册用于实现优雅关机的信号处理程序,并将控制流分派至相应的执行模式。
如图 2 所示运行时轮流程图展示单个智体轮的端到端执行过程:用户提示经由上下文组装模块进入系统,随后调用模型;工具请求通过权限关卡;工具执行结果反馈回循环流程中;最终由上下文压缩机制负责管理上下文压力。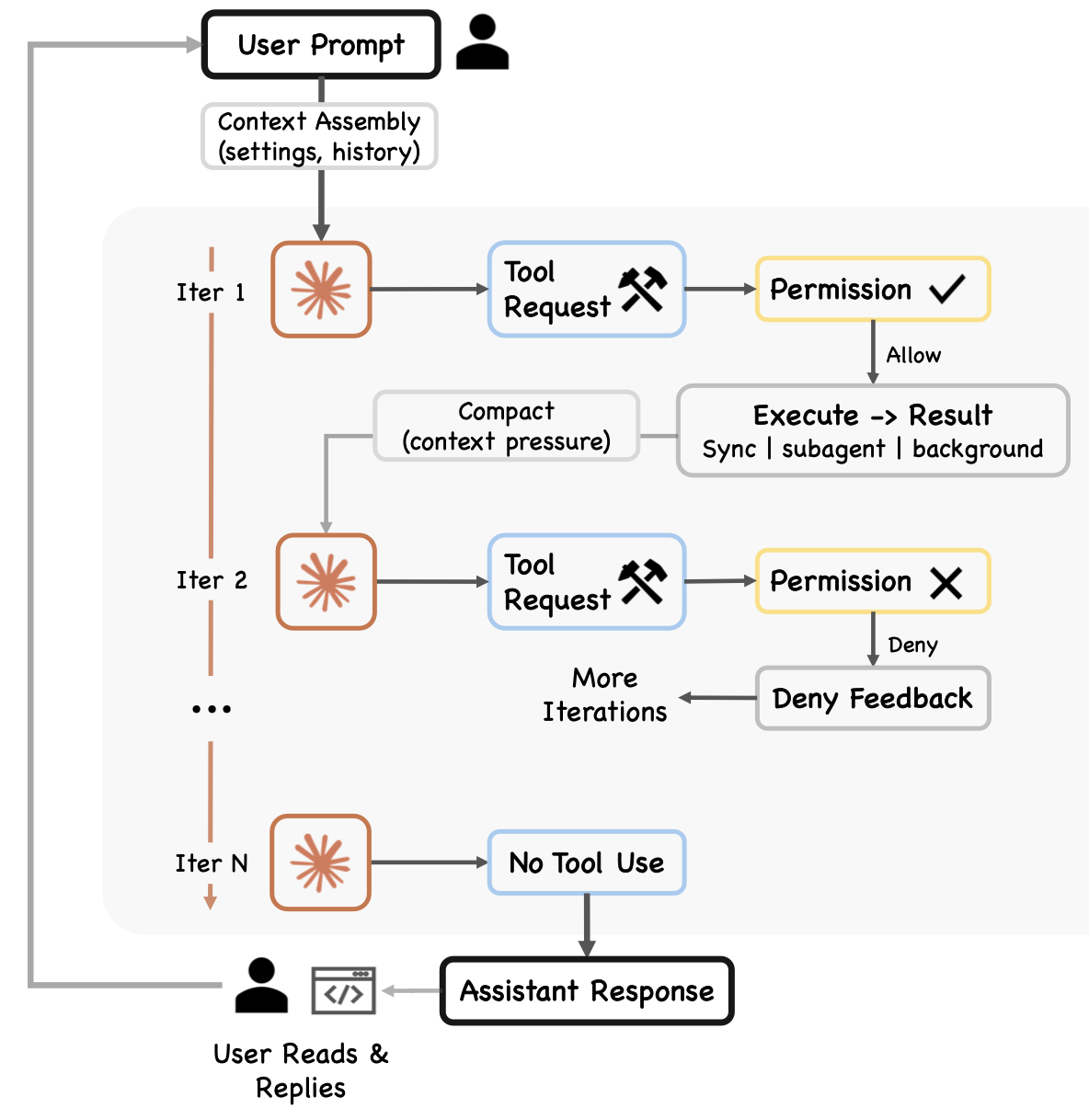
3 分层子系统分解
五层分解(图3所示)将七组件模型扩展为更细粒度的视图,并将每一层映射到特定的源目录。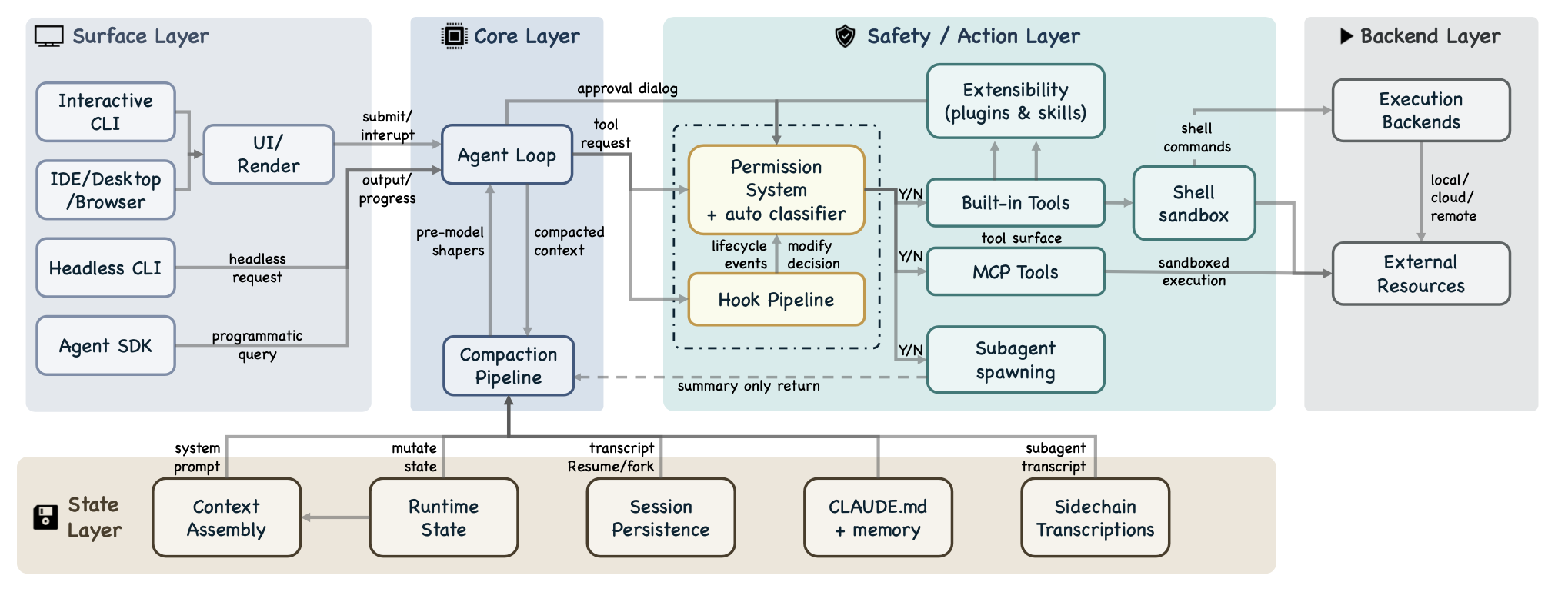
表层(入口点与渲染)。src/entrypoints/ 目录包含启动路径,其中包括带有 coreTypes.ts、controlSchemas.ts 和 coreSchemas.ts 文件的 SDK 入口。src/screens/ 目录负责构建全屏布局,而 src/components/ 目录则通过 Ink 框架提供终端 UI 的构建模块。交互式 CLI 会启动一个终端 UI,其中包含实时流式输出、权限对话框和进度指示器。无头模式 CLI(claude -p)会创建一个 QueryEngine 实例,用于执行单次处理任务。Agent SDK 通过异步生成器(async generators)发出类型化的事件。
核心层(Agent 循环、压缩管道)。queryLoop() 异步生成器(位于 query.ts 中)实现了迭代式的 Agent 循环,它从状态层消费已组装好的上下文,并将工具请求分派至安全/动作层。在每一次模型调用之前,一个由五个顺序执行的整形器(shapers)组成的压缩管道(query.ts:365–453)会负责管理上下文压力:包括预算削减、截断(snip)、微压缩、上下文折叠和自动压缩。
安全/动作层(权限系统、钩子、扩展性、工具、沙箱、子 Agent)。权限系统(permissions.ts)实现了“默认拒绝”(deny-first)的规则评估机制,支持多达七种权限模式(若计入仅限内部使用的“冒泡”模式和受功能开关控制的“自动”模式)(参见 types/permissions.ts),并集成一个自动模式的机器学习分类器(yoloClassifier.ts),该分类器通过“两阶段快速过滤”与“思维链”相结合的方式,对工具的安全性进行评估。一个涵盖27种事件类型的钩子管道(参见 coreTypes.ts;输出模式定义位于 types/hooks.ts)能够对工具请求进行拦截、重写或添加注解;其中,有5种钩子与安全性相关,其余22种则服务于生命周期管理和流程编排。扩展性子系统允许插件和技能(skills)将自定义的工具和钩子注册到运行时环境中。通过 assembleToolPool() 函数(位于 tools.ts 中)进行的工具池组装过程,会将内置工具与由 MCP 提供的工具进行合并。经批准的 Shell 命令会通过一个 Shell 沙箱(shouldUseSandbox.ts),该沙箱独立于权限系统之外,对文件系统和网络访问进行限制。通过 AgentTool(AgentTool.tsx, runAgent.ts)派生子智体的操作,会经由与所有其他工具相同的 buildTool() 工厂进行分派;随后,子智体会携带着一个隔离的上下文窗口重新进入 queryLoop() 循环,并仅向父级智体返回一份摘要。
状态层(上下文组装、运行时状态、持久化、记忆、侧链)。上下文组装模块是一个具备记忆化(memoization)功能的的状态加载器,而非路由中心:getSystemContext()(context.ts)负责计算会话级别的系统上下文(包括 Git 状态),而 getUserContext()(context.ts)则负责加载 CLAUDE.md 指令层级结构及当前日期。这两类上下文均会被缓存以供复用:系统上下文会被附加到系统提示词(System Prompt)中,而用户上下文则作为一条“用户上下文消息”被添加进去。src/state/ 目录负责管理应用程序的运行时状态。会话记录(Transcripts)主要以“仅追加”(append-only)的 JSONL 文件格式存储在针对特定项目设定的路径下(sessionStorage.ts)。CLAUDE.md 与记忆子系统共同构建一个四级指令层级结构(claudemd.ts),其范围涵盖从托管设置到特定目录文件的各个层面;此外,该系统还包含由 Claude 在对话过程中自动写入的“自动记忆”条目。侧链(sidechain)记录(sessionStorage.ts:247)将每个子智体的对话内容单独存储在一个文件中,从而避免子智体的内容过度膨胀并污染父级智体的上下文。全局提示词历史记录统一维护在 history.jsonl 文件中(history.ts)。“恢复会话”(Resume)与“分叉会话”(Fork)操作均通过读取历史记录文件来重建会话状态(conversationRecovery.ts)。
后端层(执行后端、外部资源)。此层涵盖支持可选沙箱机制的 Shell 命令执行功能(BashTool.tsx, PowerShellTool.tsx)、远程执行支持(src/remote/)、跨多种传输协议(包括 stdio、SSE、HTTP、WebSocket、SDK 以及针对特定 IDE 的适配器)建立 MCP 服务器连接的能力(services/mcp/client.ts),以及位于 src/tools/ 目录下、负责实现具体工具逻辑的 42 个工具子目录。
4 QueryEngine:一项澄清
QueryEngine.ts 中的类文档指出:“QueryEngine 负责管理对话的查询生命周期和会话状态。它将 ask() 方法中的核心逻辑提取到一个独立的类中,该类既可用于无头模式/SDK 路径,也可用于(在未来阶段)REPL 环境。”该类实际上是针对非交互式界面的对话包装器,而非查询引擎本身。其构造函数接收一个 QueryEngineConfig 对象,其中包含初始消息、中止控制器(AbortController)、文件状态缓存以及其他特定于当前对话的状态信息。其 submitMessage() 方法是一个异步生成器(async generator),负责编排对话中的单轮交互流程。共享的查询执行路径位于 query() 函数(query.ts 文件)中,该函数对内部的 queryLoop() 进行封装;QueryEngine 类的具体执行任务最终委托给了 query() 函数。
这种架构上的区分至关重要:交互式 CLI 界面同样调用 query() 函数,从而完全绕过 QueryEngine 类。因此,真正的共享代码路径是那个循环函数(loop function),而非 QueryEngine 类本身。
5 权限与安全层级
“默认安全”(safety-by-default)原则是通过七个相互独立的层级来实现的。任何请求都必须依次通过所有适用的层级,且其中任何一个层级均有权阻断该请求:
- 工具预过滤(
tools.ts):在执行任何调用之前,系统会先将那些被“一概拒绝”(blanket-denied)的工具从模型的可视范围内移除,从而防止模型试图去调用这些工具。 - “拒绝优先”规则评估(
permissions.ts):拒绝规则(Deny rules)的优先级始终高于允许规则(Allow rules),即便允许规则的匹配条件更为具体、精确,也是如此。 - 权限模式约束(
types/permissions.ts):当前处于激活状态的权限模式,决定那些未匹配到任何显式规则的请求应采用何种基准处理策略。 - 自动模式分类器:这是一个基于机器学习(ML)的分类器,专门用于评估工具调用的安全性;它有权拒绝那些按照既定规则系统本应被允许执行的请求。
- Shell 沙箱隔离(
shouldUseSandbox.ts):即使是那些已被批准执行的 Shell 命令,也可能被强制置于沙箱(Sandbox)环境中运行,从而对其文件系统及网络访问权限施加严格限制。 - 恢复会话时不重载权限(
conversationRecovery.ts):在恢复(Resume)中断的会话或对会话进行分叉(Fork)操作时,那些仅在当前会话范围内有效的权限设置将不会被自动恢复。 - 基于钩子(Hook)的拦截机制(
types/hooks.ts):PreToolUse钩子允许在工具调用前修改既定的权限决策;而PermissionRequest钩子则允许系统在与用户进行对话交互的同时(若处于协调者模式,甚至可在对话开始之前),以异步方式对权限请求做出最终裁决。
6 上下文作为瓶颈:超越压缩机制
除了压缩流水线之外,还有多项子系统设计决策体现“上下文作为瓶颈”这一约束:
• CLAUDE.md 文件的惰性加载:基础的 CLAUDE.md 层级结构会在会话启动时加载,但额外的嵌套目录指令文件及条件规则,仅在智体实际读取对应目录下的文件时才会加载,从而避免了未使用的指令占用上下文资源。
• 工具模式的延迟加载:当启用 ToolSearch 功能时,部分工具在初始上下文中仅包含其名称;完整的工具模式(Schema)仅在按需使用时才会被加载。
• 子智体的仅摘要返回:子智体仅向其父智体返回摘要文本,而非完整的对话历史记录。
• 单个工具结果的预算限制:单个工具的执行结果设有可配置的大小上限,旨在防止某项输出内容过于冗长,从而不成比例地消耗上下文资源。
当用户提交指令“修复 auth.test.ts 中失败的测试”时,该输入便进入一个“响应式循环”(reactive loop)——这是用于构建编程智体的几种潜在编排模式之一。 Claude Code 选用一种简单的 while 循环架构,端到端地追踪该循环的单次迭代过程,可以阐释表 1 中列出的三项设计原则:即“以最小的脚手架(scaffolding)实现最大的操作驾驭(harness)”、“将上下文视为稀缺资源并进行渐进式管理”,以及“优雅恢复与系统韧性(resilience)”。
1 查询管道
每一次迭代都遵循固定的序列(参见图 2 中的 query.ts 文件):
- 设置解析。
queryLoop()函数会解构并提取一系列不可变参数,其中包括系统提示词、用户上下文、权限回调函数以及模型配置。 - 可变状态初始化。一个单一的
State目标负责存储跨迭代周期的所有可变状态,涵盖了消息列表、工具上下文、上下文压缩追踪信息以及恢复计数器等。该循环中的七个“继续点(continue points)”(即“continue sites”)在更新状态时,均采用“整个目标赋值”的方式来覆盖此State目标,而非逐域(fields)进行局部修改。 - 上下文组装。
getMessagesAfterCompactBoundary()函数负责从上一个“压缩边界”处开始检索消息;此举旨在确保已被压缩的内容以其摘要形式呈现,而非直接包含原始消息文本。 - 模型前置上下文整形。五个不同的“整形器”(shapers)将按序执行。
- 模型调用。通过对
deps.callModel()执行 `for await loop‘,系统将以流式方式接收模型的响应。在调用过程中,系统会向模型传递已组装好的消息列表(其中用户上下文被前置)、完整的系统提示词、思考过程配置、可用的工具集、中止信号、当前的模型规格,以及包括“快速模式”设置、工作量(effort)数值和备用模型等在内的额外选项。 - 工具使用分派。如果模型的响应中包含
tool_use代码块,这些指令将被导流至“工具编排层”进行处理。 - 权限关卡。每一项工具请求在执行前,都必须通过权限系统的审查。
- 工具执行与结果收集。工具的执行结果将被作为
tool_result类型的消息添加到对话序列中,随后循环继续执行。 - 终止条件。如果模型的响应中未包含任何
tool_use代码块(即仅包含纯文本内容),则表明当前迭代已完成。
这个queryLoop() 函数被定义为一个异步生成器(AsyncGenerator),在执行过程中会依次产出 StreamEvent、RequestStartEvent、Message、TombstoneMessage 和 ToolUseSummaryMessage 等事件。这种基于生成器的设计使得系统能够向 UI 层进行流式输出,同时在循环内部保持单一的同步控制流。
Claude Code 的响应式循环遵循 ReAct 模式(Yao,2022):模型负责生成推理过程和工具调用指令;驾驭(harness)负责执行相应的动作;而执行结果则作为输入反馈给下一次迭代。其他的编排模式还包括显式的基于图的路由模式(LangChain, Inc., 2024),在该模式下,控制流被定义为一个带有类型化边(typed edge)的状态机;以及树搜索方法(Zhou,2023),该方法会在最终确定执行路径之前探索多条可能的动作轨迹。Anthropic 官方文档(Schluntz & Zhang, 2024)指出五种可组合的工作流模式(包括提示链、路由、并行化、编排器-工作器模式以及评估器-优化器模式);其中,Claude Code 主要采用“编排器-工作器”模式来实现子智体的委托管理,同时保持其核心循环的响应式特性。这种响应式设计以搜索的完备性为代价,换取了系统的简洁性和低延迟:在每一个回合(turn)中,系统都会直接确定并执行某一系列动作,而不会进行回溯(backtracking)。
2 工具分派与流式执行
当模型响应中包含 tool_use 代码块时,系统会在两条执行路径中进行选择。主要路径采用 StreamingToolExecutor,该执行器会在工具调用指令从模型响应中流式传输进来时即刻启动执行,从而有效降低处理包含多个工具调用的响应时的延迟。备用路径则调用 toolOrchestration.ts 文件中的 runTools() 函数,该函数会对由 partitionToolCalls() 函数所生成的工具调用分区进行迭代处理。无论采用哪条路径,系统都会将工具操作划分为“并发安全”或“独占”两类。只读操作可以并行执行,而像 Shell 命令那样会修改系统状态的操作则会被串行化处理。
StreamingToolExecutor(位于 StreamingToolExecutor.ts 文件中)通过以下两种协调机制来管理并发执行:
• 同级中止控制器(Sibling abort controller):当任何一个 Bash 工具执行出错时,该控制器即被触发,从而立即终止所有正在运行中的其他子进程,避免其继续运行直至结束。
• 进度可用信号(Progress-available signal):当有新的输出结果就绪时,该信号会唤醒 getRemainingResults() 消费者函数,使其继续处理后续结果。
结果会被缓存,并按照工具接收的顺序依次输出;因此,即使工具以并行方式运行,其输出顺序依然保持不变。这一点至关重要,因为模型期望接收到的工具结果顺序,应与其发出的工具调用请求顺序完全一致。这种“并发读取、串行写入”的执行模式,介于完全串行的调度方式与诸如 PASTE(Sui et al., 2026)这类更为激进的推测性方法之间;后者利用推测机制,在模型仍在生成内容的同时抢先预执行预测的后续工具调用,从而通过推测性执行来掩盖工具调用的延迟。
工具结果收集阶段会迭代处理来自流式执行器(streaming executor)或同步 runTools() 生成器的更新。每次更新可能包含一个工具结果、一个附件或一个进度事件。一个特殊的检查机制用于检测 hook_stopped_continuation 附件:如果某个 PostToolUse 钩子(hook)发出信号表明当前轮次(turn)不应继续,则会设置一个 shouldPreventContinuation 标志。随后,通过 normalizeMessagesForAPI() 函数对结果进行标准化处理以适配 Anthropic API,该函数会进行过滤,仅保留用户类型的消息。
3 模型前上下文整形器(Pre-Model Context Shapers)
在 query.ts 文件中,每次调用模型之前,会有五个上下文整形器按顺序执行,每个整形器都作用于 messagesForQuery 数组。这五个整形器依次运行,较早的步骤执行较轻度的缩减操作,而较晚的步骤则执行更广泛的压缩操作。
预算缩减(Budget reduction)。(由 applyToolResultBudget() 实现)。该步骤对工具结果强制执行单条消息的大小限制,将超限的输出内容替换为内容引用(content references)。被豁免的工具(即那些 maxResultSizeChars 参数值非有限的工具)将保留其完整的输出内容。对于智体(agent)和会话(session)查询源,这些内容替换信息会被持久化保存,以便在恢复会话时能够进行重建。预算缩减操作在“微压缩”(Microcompact)之前运行,因为微压缩完全依据 tool_use_id 进行操作,而不会检查具体的内容;因此,这两者可以完美地结合在一起。
截断(Snip)。(由 snipCompactIfNeeded() 实现,受 HISTORY_SNIP 特性标志控制)。这是一项轻量级的修剪操作,用于移除较旧的历史对话片段,并返回 {messages, tokensFreed, boundaryMessage} 结构。其中 snipTokensFreed(截断所释放的 Token 数量)这一数值会被传递给后续的自动压缩流程。这是因为主要的 Token 计数器是从最近一条助手(assistant)消息的 usage 字段中获取上下文大小的;而该助手消息在经过截断操作后依然保留,且其附带的截断前 input_tokens 数值也未改变。因此,如果不显式地将截断所节省的 Token 数量传递过去,计数器将无法感知到这部分节省的空间。
微压缩(Microcompact)。这是一项细粒度的压缩操作,总是会执行基于时间的压缩路径,并可选择性地执行基于缓存-觉察的压缩路径(受 CACHED_MICROCOMPACT 特性标志控制)。当启用基于缓存的路径时,边界消息(boundary messages)的处理会被推迟至 API 响应返回之后,以便能够使用实际的 cache_deleted_input_tokens 值,而非估算值。该操作返回 {messages, compactionInfo} 结构,其中 compactionInfo 字段可能包含 pendingCacheEdits(待处理的缓存编辑信息)。
上下文折叠(Context collapse)。受 CONTEXT_COLLAPSE 特性标志控制。这是一项针对对话历史记录进行的“读取-时投影”(read-time projection)操作。源代码注释解释道:“没有任何数据被实际移除;所谓的‘折叠视图’(collapsed view)实际上是对 REPL 完整历史记录在读取时进行的一种投影。摘要信息存储在‘折叠存储区’(collapse store)中,而非直接存储在 REPL 的主数组里。正是这一机制确保折叠状态能够在不同的交互轮次之间得以持久保存。”与其他“整形器”(shapers)不同,上下文折叠操作并不会直接修改 REPL 中已存储的历史记录;相反,它通过调用 applyCollapsesIfNeeded() 函数,将 messagesForQuery 数组替换为一个经过投影处理的视图。这样一来,语言模型在处理时看到的是经过折叠的精简版本,而完整的历史记录依然保留在后台,随时可用于重建或回溯。
自动压缩(Auto-compact)。这是第五个塑形器,它通过调用 compact.ts 文件中的 compactConversation() 函数,触发一次由语言模型主导的全面摘要生成过程。该函数首先执行一系列“预压缩钩子”(PreCompact hooks),接着利用 getCompactPrompt() 函数构建一个摘要请求,随后调用语言模型来生成一份压缩后的摘要内容。生成的结果随后会被输入至 buildPostCompactMessages() 函数(位于 compact.ts 文件中)进行后续处理。自动压缩机制仅在满足特定条件时才会触发:即在所有前四个整形器均已执行完毕之后,如果当前的上下文(context)长度依然超出预设的“压力阈值”(pressure threshold)。
4 恢复机制
查询循环(query loop)针对各类边缘情况实现一系列恢复机制:
• 最大输出 Token 限制提升(escalation):当语言模型的响应内容触及预设的“输出 Token 上限”时,系统可以尝试通过提升该上限值的方式进行重试。此项功能受 GrowthBook 特性标志(flag)的控制,且仅在当前未设置任何显式覆盖规则或环境变量上限的情况下才会生效。在每一个交互轮次中,系统最多允许执行三次此类恢复尝试(由常量 MAX_OUTPUT_TOKENS_RECOVERY_LIMIT = 3 定义)。
• 响应式压缩(受 REACTIVE_COMPACT 标志控制):当上下文长度逼近其容量上限时,“响应式压缩”机制会被激活,它会生成恰好足以腾出所需空间的摘要内容。通过设置 hasAttemptedReactiveCompact 标志,系统确保了在每一个交互轮次中,该响应式压缩操作最多只会被执行一次。
• “提示过长”错误处理:如果 API 返回 prompt_too_long(提示过长)错误,查询循环会首先尝试执行“上下文折叠溢出恢复”操作,紧接着尝试执行“响应式压缩”操作。只有当上述两种恢复尝试均告失败后,循环才会终止,并明确指明终止原因(reason)为:prompt_too_long。
• 流式回退(Streaming fallback):onStreamingFallback 回调函数专门用于处理流式 API 调用过程中遇到的各类异常或问题,从而允许查询循环切换至另一种策略进行重试。
• 备用模型(Fallback model):通过设置 fallbackModel 参数,系统能够在主语言模型发生故障或无法正常响应时,自动切换至预设的备用模型继续执行任务。
5 终止条件
查询循环的执行可能会因满足以下多种条件之一而终止:
- 未使用工具(No tool use):语言模型生成的内容仅包含纯文本(这是最主要的循环终止条件)。
- 最大轮次:已达到可配置的
maxTurns上限。 - 上下文溢出:API 返回
prompt_too_long错误。 - Hook 介入:
PostToolUseHook 触发了hook_stopped_continuation信号。 - 显式中止:
AbortController的中止信号被触发。
“轮次管道”(Turn Pipeline)负责编排工具请求的执行流程及恢复机制。
用于生产环境的代码编写智体通常采用不同的安全架构:分层策略执行、操作系统级沙箱隔离,或基于版本控制的回展(rollback)机制。Claude Code 结合前两种架构,并落实表 1 中列出的四项设计原则:优先拒绝并辅以人工升级审查、分级信任谱系、基于分层机制的纵深防御,以及侧重于可逆性的风险评估。
当 Claude 决定执行某项工具(例如,通过 BashTool 运行 npm test 以复现身份验证测试失败的问题)时,该请求将进入图 4 所示的权限处理流水线。每一次工具调用都必须通过权限系统的审查;系统的默认行为是“优先拒绝”或“请求确认”,而非“静默允许”。这一默认设置的依据是一项有据可查的行为模式:Anthropic 针对“自动模式”进行的分析(Hughes, 2026)发现,用户对权限提示的批准率高达约 93%;这表明,由于存在“批准疲劳”现象,若仅将交互式确认作为唯一的安全机制,其在行为层面是不可靠的。鉴于用户往往习惯性地在未经仔细审查的情况下直接予以批准,系统必须具备独立于人类警惕性之外的安全保障能力。正是基于这一考量,该架构确立以下核心设计理念:采用“优先拒绝”的评估策略、“全面拒绝”的预过滤机制,以及沙箱隔离技术;这三者作为相互独立的防御层级,无论用户是否保持高度警惕,都能持续发挥其安全防护作用。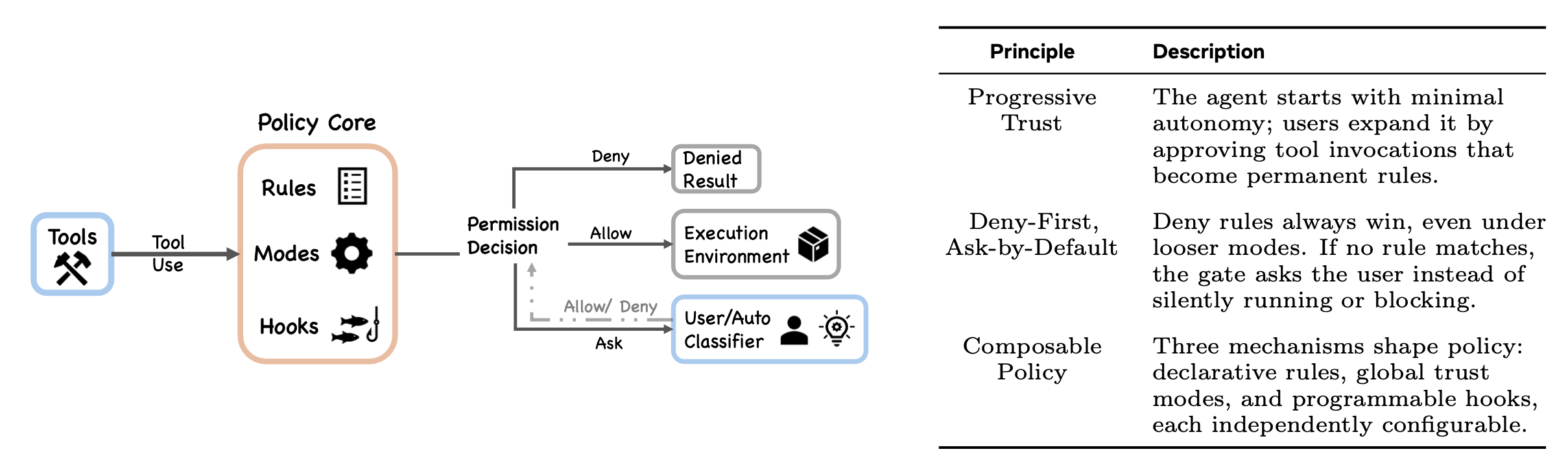
1 权限模式与规则评估
在类型定义中共有七种权限模式(其中 5 种为外部模式,定义于 types/permissions.ts;auto 模式根据条件自动添加;bubble 模式包含在类型联合中):
plan:模型必须先制定执行规划;只有在获得用户批准后,执行过程才会继续。default:标准的交互式使用模式。大多数操作都需要获得用户的批准。acceptEdits:对工作目录内的编辑操作,以及特定的文件系统 Shell 命令(如mkdir、rmdir、touch、rm、mv、cp、sed)将自动获得批准;而其他的 Shell 命令仍需批准。auto:基于机器学习的分类器将对那些未能通过“快速路径”检查的请求进行评估(此功能受TRANSCRIPT_CLASSIFIER特性标志控制)。dontAsk:不进行任何提示,但拒绝规则(deny rules)依然会被强制执行。bypassPermissions:跳过大多数权限提示,但涉及安全关键的检查以及那些不可绕过的规则(bypass-immune rules)依然适用。bubble:仅供内部使用的模式,用于将子智体(subagent)的权限请求上报至父级终端进行处理。
上述五种外部可见的模式(即 acceptEdits、bypassPermissions、default、dontAsk 和 plan)均定义在 EXTERNAL_PERMISSION_MODES 数组中。auto 模式仅在 TRANSCRIPT_CLASSIFIER 特性标志处于启用状态时,才会被有条件地包含进来。bubble 模式虽然存在于类型联合中,但并未包含在上述任何一个模式数组内;它仅在内部用于处理子智体的权限上报需求。
权限规则的评估遵循“拒绝优先”(deny-first)的原则(详见 permissions.ts)。toolMatchesRule() 函数会首先对拒绝规则进行检查:拒绝规则的优先级总是高于允许规则,即便该允许规则在匹配范围上更为具体也是如此。例如,一条宽泛的拒绝规则(如“拒绝所有 Shell 命令”)无法被一条狭窄的允许规则(如“允许 npm test”)所覆盖。该规则系统支持两种匹配层级:工具级匹配(依据工具名称进行匹配)以及内容级匹配(依据特定的工具输入模式进行匹配,例如 Bash(prefix:npm))。
这七种模式共同构成一个渐进式的自主性谱系:从 plan 模式(用户在执行前需批准所有规划),经由 default 和 acceptEdits 模式,最终过渡至 bypassPermissions 模式(即极少进行提示)。这种渐进式的设计体现一种反复出现的权衡困境:随着系统自主性的提升,其运作机制必须从依赖“交互式批准”逐步转向依赖“自动化安全检查”。不同的智体系统在解决这一权衡困境时,往往会采取各异的设计策略。 SWE-Agent 和 OpenHands(Yang,2024;Wang,2024b)采用 Docker 容器隔离技术,对智体(Agent)的整个执行环境进行沙箱化处理,而非仅评估单个工具的调用。Aider(Gauthier,2024)则依赖 Git 作为安全网,通过版本控制确保所有变更均可回滚。Claude Code 的方案在可选的容器沙箱机制之上,叠加多层策略强制执行机制;这种设计虽牺牲一定的简洁性,却换取对单个操作进行细粒度控制的能力。
2 授权管道
完整的授权管道流程包含以下几个阶段:
预过滤(Pre-filtering)。在任何工具请求进入运行时评估阶段之前,filterToolsByDenyRules() 函数(位于 tools.ts 文件中)会在工具池组装阶段,彻底将那些被“一刀切”式拒绝的工具从模型的视野中移除。相关文档对此阐述道:“该函数使用的匹配器与运行时权限检查所用的匹配器相同;因此,诸如 mcp__server 这样的 MCP 服务器前缀规则,能在模型看到该服务器下的任何工具之前,就将其全部过滤掉。”这一机制旨在防止模型试图调用被禁用的工具,从而避免模型在这些无效调用上浪费资源。
PreToolUse 钩子(Hook)。已注册的钩子(Hooks)会作为权限管道流程的一部分被触发。一个 PreToolUse 钩子可以返回一个 permissionDecision 对象,用于决定是拒绝(deny)该操作还是向用户征询意见(ask);亦可返回一个 updatedInput 对象,用于修改该工具的输入参数(详见 types/hooks.ts)。值得注意的是,即使钩子返回了“允许”(allow)指令,也无法绕过后续基于规则的拒绝策略或安全检查。在交互式流程中,用户对话框会首先被放入队列中,随后钩子才开始异步运行;而在协调器(Coordinator)及类似的后台代理流程中,系统会先等待自动检查(包括分类器、钩子及规则评估)全部完成后,才会向用户展示对话框。
规则评估(Rule evaluation)。采用“拒绝优先”(deny-first)策略的规则引擎会对请求进行评估。MCP 工具通过其完整的限定名称(格式为 mcp__server__tool)进行匹配;而服务器层级的规则则适用于该服务器下的所有工具。
权限处理器(Permission handler)。位于 useCanUseTool.tsx 文件中的权限处理器,会根据当前的运行时上下文,将流程分派至以下四条路径之一:
- 协调器(Coordinator):专用于多智体(Multi-agent)协作模式。在最终回退至用户交互环节之前,系统会首先尝试通过自动化手段(包括分类器、钩子及规则评估)来解决请求。
- 群体工作体(Swarm worker):负责处理多智体群(Swarm)中的工作智体,这些工作智体拥有各自独立的请求解决逻辑。
- 预测分类器:当启用 BASH_CLASSIFIER 且工具为 BashTool 时,预测分类器会针对预先启动的分类结果执行一场“竞速”——即在设定的超时时限内进行判定。如果分类器返回了高置信度的结果,该工具将立即获得批准,无需任何用户交互。
- 交互模式:作为一种回退机制。通过终端用户界面(UI)显示标准的用户批准对话框。
在协调器(coordinator)及某些后台执行路径中,系统会在用户介入之前尝试进行自动化决策。而在标准的交互式执行路径中,用户对话框可能会率先弹出,与此同时,相关的钩子(hooks)或分类器检查工作仍在并行进行。当分类器或拒绝规则阻止某项操作时,系统会将此拒绝指令视为一种“路由信号”,而非简单的“硬性终止”:模型会接收到拒绝的具体原因,据此调整其策略,并在下一个循环迭代中尝试执行更为稳妥的替代方案。PermissionDenied 钩子事件允许外部代码以编程方式监测并响应此类拒绝事件。这种以“恢复”为导向的设计理念意味着:权限强制执行机制旨在对智体(Agent)的行为进行引导与塑造,而非仅仅将其粗暴地叫停。
3 自动模式分类器与钩子的生命周期
当处于启用状态时,自动模式分类器(yoloClassifier.ts)将参与到权限决策的制定过程中。若 TRANSCRIPT_CLASSIFIER 配置项处于启用状态,该分类器便会加载以下三项提示资源(prompt resources):
• 基系统提示(Base system prompt)。
• 外部权限模板。
• (仅针对 Anthropic 内部用户)一套独立的内部专用模板。
分类器会结合当前的对话记录(transcript)与权限模板,对拟议的工具调用指令进行评估,并据此输出三种结果之一:允许执行、拒绝执行,或请求进行人工审批。其中的 isUsingExternalPermissions() 函数负责检查 USER_TYPE 变量以及 forceExternalPermissions 配置标志,从而判定并选用恰当的权限模板。
在源代码(coreTypes.ts)所定义的全部 27 个钩子事件中,有 5 个事件直接参与到权限流的运作之中;每一个事件均对应一套经由 Zod 库严格校验的特定输出模式(详见 types/hooks.ts):
• PreToolUse:可返回 permissionDecision(决策结果,仅限“拒绝”或“请求审批”——注:“允许”结果并不能绕过后续的检查环节)、permissionDecisionReason(决策理由),以及 updatedInput(用于修改输入参数)。
• PostToolUse:可注入 additionalContext(额外上下文信息);若涉及 MCP 工具,还可返回 updatedMCPToolOutput,以便在工具执行结果被纳入整体上下文之前对其内容进行修改。
• PostToolUseFailure:可注入 additionalContext,用于针对特定的错误场景提供相应的指引或说明。
• PermissionDenied:在自动模式下的权限拒绝事件发生后,可提供相应的重试指引或建议。
• PermissionRequest:可返回“允许”或“拒绝”的决策结果。在协调器及类似的执行路径中,该钩子可在用户对话框弹出之前便完成决策;而在标准的交互式执行路径中,该钩子也可与用户对话框的显示过程并行运行。对于非 MCP 类型的工具而言,其执行结果(即 tool_result)会在 PostToolUse 钩子被触发之前便先行发出。对于 MCP 工具,其结果会被延迟,直至后置钩子(post hooks)运行完毕,从而确保 updatedMCPToolOutput 能够生效。
4 Shell 沙箱机制
Shell 沙箱机制为 Bash 和 PowerShell 命令提供一层额外的保护(参见 shouldUseSandbox.ts)。shouldUseSandbox() 函数会检查沙箱机制是否已全局启用、当前调用是否已明确选择跳过沙箱,以及该命令是否与任何排除模式相匹配。
启用后,沙箱机制将提供文件系统和网络隔离,且这种隔离独立于应用层面的权限模型。一个命令可能已通过权限审批但仍需在沙箱中运行;也可能因权限不足而被拒绝执行,从而根本无法触及沙箱检查环节。这两个系统在不同的维度上运作:即“授权”与“隔离”这两个维度。
这种分层的安全架构建立在一种“独立性假设”之上:即如果某一层防护失效,其他层仍能捕获并拦截违规行为。然而,多个防护层往往面临着共同的性能瓶颈。安全研究人员(Adversa.ai, 2026)指出,对于包含超过 50 个子命令的指令,系统会回退至显示一个通用的审批提示,而不再逐一执行针对各子命令的拒绝规则检查;这是因为逐一解析子命令的操作会导致用户界面(UI)发生卡顿甚至死机。这一案例表明,当安全架构中的各层防护机制存在共同的失效模式时,其“纵深防御”(defense-in-depth)的有效性便会大打折扣。
权限管道机制决定工具请求是否能够最终执行。
。。。待续。。。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)