小模型训练题50(11-20)
11. 在 RLHF 的 PPO 微调阶段,小模型的策略更新方差通常更大。推导 PPO 的 clipped objective  中重要性采样比率
中重要性采样比率 的方差与模型容量的关系。
的方差与模型容量的关系。
重要性采样比率的定义为: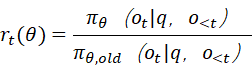
其方差的定义为: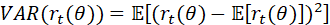
可见,模型容量越小,则的新策略和旧策略差异大时,
远大于1、或者接近0;而当新旧策略差异小时,
约等于1,由此,
的方差就会越大。而模型容量越大,新旧策略即便差异很大时,
也会变得离1更近,所以,
的方差就会变小。
12. 使用vLLM部署小模型时,PagedAttention 的 block 管理开销可能超过收益。分析当模型层数 L<12 且上下文长度T<2k 时,传统 contiguous KV Cache 与 PagedAttention 的内存访问效率差异。
当L<12且context<2k时,如果Attention的维度是d=4096,HBM内存占用=2*2LTd=384M,此时没有高并发。传统的contiguous KV Cache是一整块的内存分配,完全可以在一整块内完成一次完成取数或者update;384M的内存占用没必要“分表分库”,完全用contiguous KV cache就行,与PagedAttention在不同的地方分块分页、还要管理不同block的地址相比,反而会更快。
13. 在数据受限场景下(如仅 10K 样本),直接训练小模型易过拟合。设计一种结合自监督预训练(如 MLM)和下游任务微调的两阶段训练策略,并分析其在样本效率上的理论优势。
过拟合:样本少的情况下,模型学会了样本的特征也学会了噪音的特征,导致在真实场景下发生很大的“幻觉”。策略如下:(核心思路是在自监督预训练SSPT阶段,大量生成正负样本;在监督微调SWT阶段,让负样本的损失函数放大)
1、SSPT阶段,
1)对10K样本进行语义分析,通过结构化标记的方式,对每个样本的特征字段、逻辑关系、函数定义、参变量描述、时序关系等等,生成formalized language,再由此生成知识库;根据知识库的约束条件,随机更改、遮蔽、变换、冗余样本的语义结构,生成增广正负样本集合P和S;
2)采用 MLM(掩码语言模型)等自监督目标训练基础模型,优化参数π,形成;
2、SWT阶段,
1)使用LoRA框架,注入P和N,共同对低秩A、B矩阵进行微调;考虑early stopping机制,避免swt无效训练;
2)由于已知正负样本p和n,分别满足p∈P、n∈N,所以当使用p修正AB矩阵的时候,采用反向传播时要“使得趋近于pretraing的参数
”为微调目标;采用n微调并反向传播时,让“使得
远离
”成为微调目标。设
为正负样本混合训练AB矩阵的损失函数,
为正样本集P里任意一个正样本p的语义特征向量;
为负样本集N里任意一个负样本n的语义特征向量;
为10k个真实样本的语义向量,则建议先做一个简化版的如下:
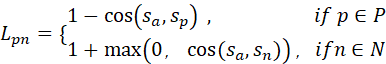
3、在样本效率上的理论优势,首先是产生了增广样本集,便于弱化小样本带来的噪音;其次是通过,在自监督的情况下,让参数的分布尽可能靠近正样本集、远离负样本集。
14. 对比 LoRA 与 Adapter 在小模型微调中的显存和吞吐性能。假设 Adapter bottleneck dimension 为d/4 ,LoRA rank 为8 ,推导二者在前向传播中的额外 FLOPs 和参数量。
1、参数量:设d=4096,则adapter的额外参数量为2*(d/4)*d=/2
, LoRA的参数量为2*d*r,二者的比值为128:1;
2、额外FLOPs,设层数为L,上下文长度为C,则Padapter=2*L*2(d/4)*d*C=LC;
PLoRA=2*2*L*C*d*r=4LCdr;二者的比值=d/4r=128:1,其中第一个2是每个token占2个byte,第二个2是两个矩阵;
15. 在多任务小模型训练中,不同任务的梯度可能冲突。推导 PCGrad (Projected Gradient Descent) 方法中梯度投影操作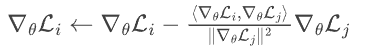 对优化轨迹的影响。
对优化轨迹的影响。
设是第i个小模型训练时的损失函数,对应的梯度是
;当第j个小模型训练的损失函数
,对应的梯度是
;
1、当两个小模型的优化轨迹重叠、即与
的内积趋近于1的时候,则
的梯度趋于舒缓,会对参数做微调;
2、当两个小模型i、j的梯度垂直,即与
的内积趋近于0的时候,两个小模型互相不受干扰,各自优化参数;
3、当两个小模型方向相反,从而二者的内积为负值时,则两个小模型互相拉扯,互相都在大改参数。这时,冲突是最大的。此时,PCGrad起作用了:
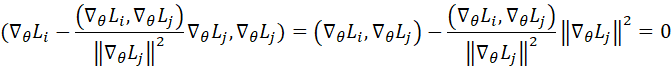
修正的新梯度向量与
正交,互不干扰。
16. 当小模型用于边缘设备时,需进行算子融合以减少 kernel launch 开销。描述如何将 LayerNorm、Linear 和 GELU 融合成单个 CUDA kernel,并分析其对端到端延迟的提升。
边缘设备好比广义的客户端,不可能总是访问云,而是要在更小的GPU和HBM下,完成小模型的encoding/decoding。此时,有必要将LayerNorm、Linear、GELU融合成一个算子。将这三步原先是“计算->存储->读取”的三个独立kernel过程,只开一个kernel做成一个串行过程。期间,LayerNorm、Linear的计算结果,都只在寄存器里临时存储而不写HBM。kernel结束之后,才会存储在一个本地HBM里,整个transformer的运算是端到端的,所有的参数都直接在GPU的寄存器存储、在GPU里计算,计算完了统一存HBM后就抛弃。这样就减少了每一个算子之间的I/O,也不存在与云的I/O。
17. 在使用 DeepSpeed 的 activation checkpointing 时,对于层数较少的小模型(如 6 层),重新计算所有激活的 FLOPs 开销可能超过显存收益。推导最优 checkpointing 策略的 break-even point。
y1=y0+σ(wx+b);不开启activation checkpointing时,所有的y1要存一份到显存,如果层数是L,被激活的y1的单层张量数是F,则总的显存开销是L×F;开始activation checkpointing时,所有的y1都被丢弃了,反向传播时要重新算一次,重算所有的y1的总FLOPS设为A,通常A>F。
假如,存储y1的显存开销LF的存储效率(HBM)、与重算y1的计算开销LA的计算效率(GPU),二者大约是效率相当的。则平衡点就是LF=LA。因此,当层数较小、预示着LF较小的时候,不建议开启activation checkpointing,把所有的y1都存储在显存里,反向传播时y1就不用重算了,显存开销代替了重算Flops的开销;反之,当层数太大、从而LF很大的时候,建议使用check pointing临时重算y1,不再从显存读取。
18. 分析小模型在 FP16 训练中更容易出现梯度下溢(underflow)的现象。从梯度幅值的统计分布出发,推导其与模型深度和初始化尺度的关系,并提出一种动态 loss scaling 策略。
FP16由于是半精度浮点存储,范围约在 6.10×10⁻⁵ ~ 6.55×10⁴,所以极小梯度易归零,形成参数光训练不更新的underflow现象。若模型有L层,每递进一层,梯度就会因为链式偏导缩小一个数量级。也就是说,层级越深,梯度值“很小”的分布样本就会越多,从而梯度幅度统计分布的“期望值”就会“更小”。整个方差就会收缩(都向0去偏移)。同理,如果初始化尺度就过小,则多层梯度后就更容易向0偏移。因此,动态loss scaling的策略是,让更小的值放大,不要向0偏移:
设损失时函数为L,则反向传播当<阈值C(比如1*e-5)的时候,对
进行一个S(S>1)的放大。
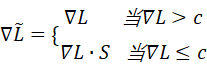
19. 在指令微调小模型时,若指令模板过于复杂,会挤占有效上下文。设计一种基于 instruction compression 的数据预处理方法,在保持语义不变的前提下最小化 token 消耗。
指令微调小模型,即直接通过把指令写成MD的形式,形成文本上下文。但是,MD格式可能存在冗余的内容,需要在保持语义不变的约束条件下,进行压缩。
1、结构化+无损压缩,剔除冗余、修饰词、换行等等token。将意图、输入、约束条件、输出效果的标准格式结构化;
2、将结构化指令模板与未进行结构化+无损压缩的指令模板进行相关性比较。先通过余弦相似度,分析意图、输入、约束条件、输出效果是否和原先的指令模板的置信度高于阈值,如果是,则向下推进;如果不是,则重新返回1;
3、如果是,再进一步做知识库增强检索,确保新生成的结构化指令模板不仅与原模板语义不变,并且是能够与垂直小模型微调目标是高度一致的。
4、将不同格式、但语义不变的模板,合并成一个;
20. 使用 Ring Attention 扩展小模型上下文窗口是否合理?从通信开销 与计算开销
与计算开销 的比值出发,分析其在小模型( d小)长上下文( L大)场景下的适用性。
的比值出发,分析其在小模型( d小)长上下文( L大)场景下的适用性。
ring attention是将KV分为N个小矩阵,分别循环计算分块的QKV,再统一合并的方法。特点是以通信的代价换取显存的占用,即与contiguous attention比,显存占用会小,而通信开销会放大至原先的N倍,显存占用缩小为原来的1/N。所以,扩展小模型上下文窗口时,如果参数很少,使用ring attention扩展小模型上下文窗口时没有必要的;只有大模型时,才更有意义。
通信开销与计算开销
的比值是N/L。因此,如果d小L大,则ring attention形成了很大的计算开销,反而没有发挥大幅度节省显存的优势,个人认为不太适合。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)