LLM系列之-强化学习
在获得了一个 Reward Model 后,我们便可以利用这个 RM 来进化我们的模型。
目前比较主流的优化方式有 3 种:BON,DPO 和 PPO。
1. Best-of-N(BON)
BON 也叫 reject sampling,是指我们通过设置 temperature 值让同一个模型生成若干回复,
接着,使用 Reward Model 挑出这些回复中得分较高的回复并再次训练原本的模型。
在 [Llama2 Paper] 中使用了这种方法,由于这是一个循环迭代的过程(Sample -> SFT -> Sample -> ...),
论文中指出:在进行 SFT 时,应当使用之前所有策略下的 Good Samples(而非仅是最近一次策略模型 Sample 出的样本),以提高模型的泛化性。

“我们将之前每一个 stage 中优秀样本都汇聚到一起进行训练,这使得最后的效果显著提升”
BON 和 RL 的区别主要有以下 2 点:
- 探索广度:对同一个 prompt,BON 一次会进行 N 次采样,但 PPO 每次只会采样 1 个答案。
- 进化深度:BON 的方法只会进行一次模型的「采样-迭代」,而 PPO 会重复进行「采样-进化-采样-进化」。但我们同样可以持续做多个轮回的 BON,这种情况下这 2 种方法的差别就不那么大。
在这一篇 [OpenAI Paper] 中对比了 BON & RL 在训练效果上的区别,
相比于 RL,BON 的训练曲线要更稳定(不那么容易崩),但从最终效果来看 RL 的上限会更高一些:
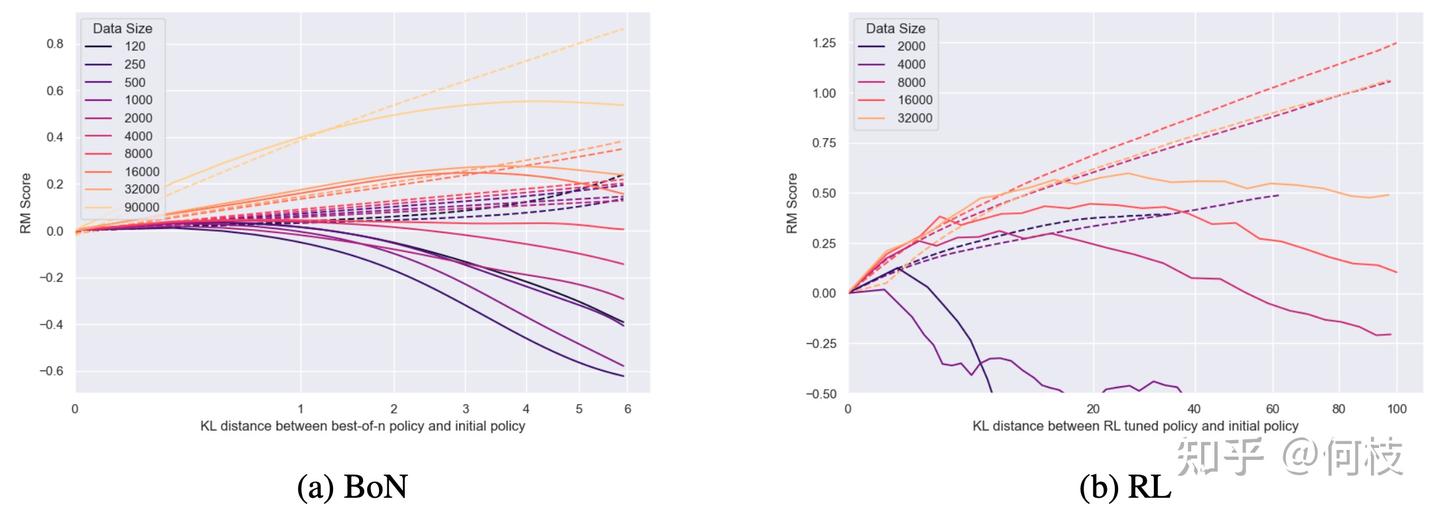
图左为 BON 训练 Reward 曲线,图右为 RL 训练 Reward 曲线
2. Direct Preference Optimisatio(DPO)
[DPO] 是一种不需要 Reward Model 的训练方法,它可以用训练 RM 的偏序对来直接训练模型本身。
具体来讲,DPO 借鉴了对比学习的思路,
其目标是:对于同一个 prompt,尽可能大的拉开 selected 答案和 rejected 答案之间的生成概率。
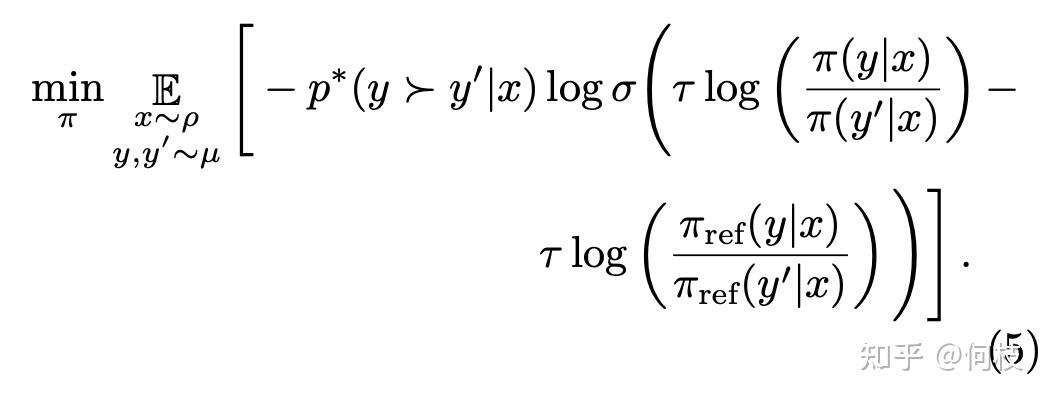
DPO Loss 的实现公式
上述公式源自 [ 这篇 paper],代码中实现也普遍采样该公式。
以下是 [trl] 中对 DPO 中的 loss 实现方式:
def dpo_loss(
self,
policy_chosen_logps: torch.FloatTensor,
policy_rejected_logps: torch.FloatTensor,
reference_chosen_logps: torch.FloatTensor,
reference_rejected_logps: torch.FloatTensor,
reference_free: bool = False,
) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
pi_logratios = policy_chosen_logps - policy_rejected_logps # 当前模型的 good/bad sample 的概率差
ref_logratios = reference_chosen_logps - reference_rejected_logps # Ref模型的 good/bad sample 的概率差
if reference_free:
ref_logratios = 0
logits = pi_logratios - ref_logratios # 如果 ref model 对这两个样本差异也很大,则不要拉的太猛(防止训飞了)
if self.loss_type == "sigmoid":
losses = -F.logsigmoid(self.beta * logits) # 最大化 good/bad sample 的概率差
elif self.loss_type == "hinge":
losses = torch.relu(1 - self.beta * logits)
else:
raise ValueError(f"Unknown loss type: {self.loss_type}. Should be one of ['sigmoid', 'hinge']")
chosen_rewards = self.beta * (policy_chosen_logps - reference_chosen_logps).detach()
rejected_rewards = self.beta * (policy_rejected_logps - reference_rejected_logps).detach()
return losses, chosen_rewards, rejected_rewards3. Proximal Policy Optimization(PPO)
[PPO] 是强化学习中一种基于AC架构(Actor-Critic)的优化方法,其前身是TRPO,
PPO通过引入重要性采样(Importance Sampling)来缓解 on policy 模型一次采样数据只能更新一次模型的问题,提升了数据利用率和模型训练速度。
在 LLM 的训练中,使用 PPO 需要同时载入 4 个模型:
- Actor Model:用于进化训练的生成模型
- Critic Model:用于进化训练的评判模型
- Ref Model:参照模型,通过 KL 来限制 Actor 模型的训练方向
- Reward Model:奖励模型,用于指导 Actor 进化
为了节省显存,通常会将 actor / critic 共享一个 backbone,这样只用同时载入 3 个模型。
注:这也是 RL 非常耗卡的一个重要原因。
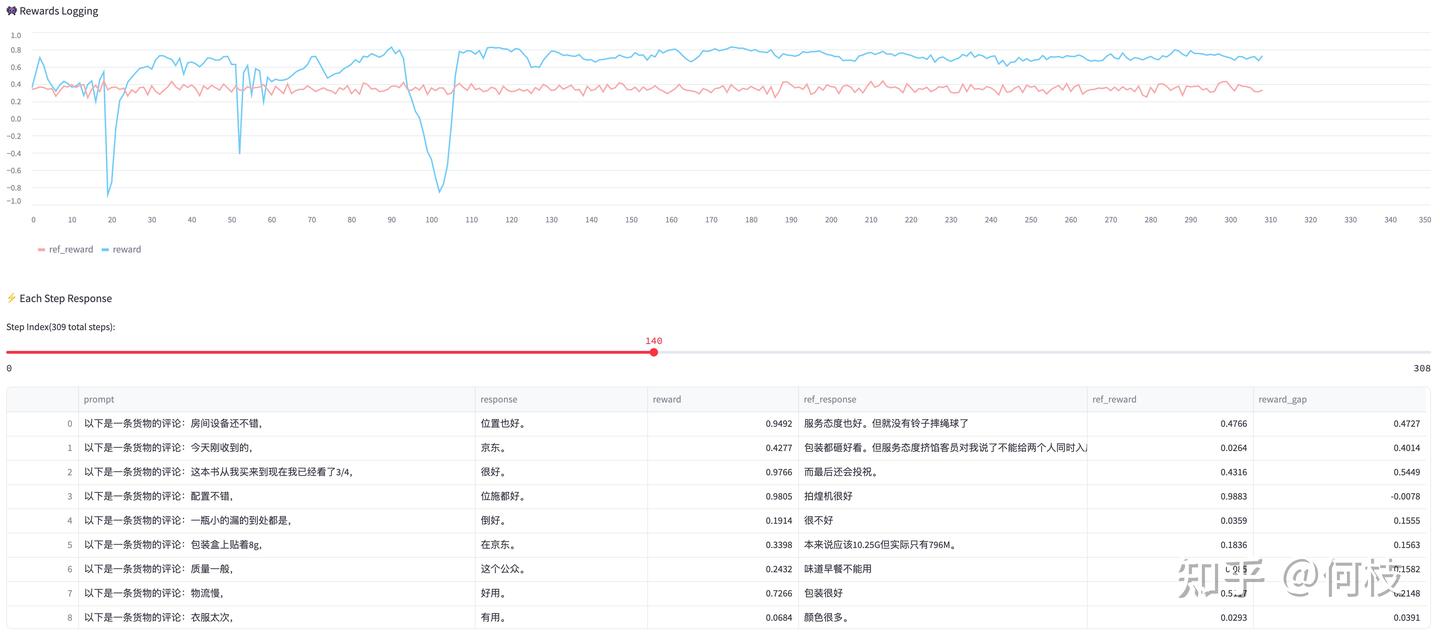
PPO 以其「训练过程不稳定」和「效果不稳定」著称,这里我们通过列出一些具体的 case 来说明。
训练过程不稳定
由于 PPO 对超参非常敏感,不合理的超参搭配很有可能使得模型训练过程中 Reward 剧烈抖动:
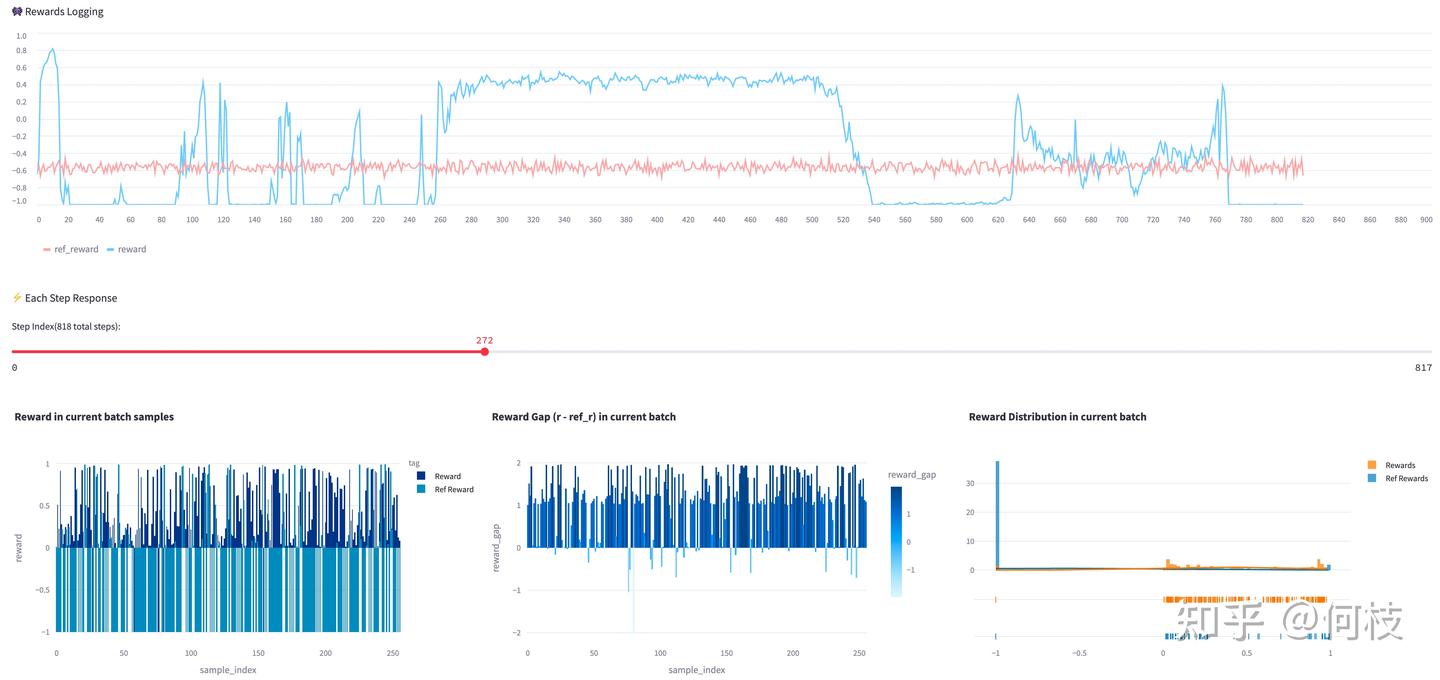
图中蓝色折线为 actor 的 reward 曲线,粉红色折线为 ref_model(不参与训练)的 reward 曲线
从上图中可以看出,模型在训练过程中奖励曲线抖动的非常剧烈,
经过实验,我们发现存在几个因素与此有关:
- KL Penalty:适当调大 KL可以帮助稳定训练(可使用动态调整 KL 系数策略)。
- Reward Model:使用一个更稳定的 RM 能够有效缓解这种问题。
- Reward Scaling:reward 的归一化对训练稳定有着很重要的作用。
- Batch Size:适当增大 batch_size 有助于训练稳定。
训练结果不稳定
当你看到一条比较平稳且漂亮的 Reward 折线时 —— 也不要高兴的太早,
因为 reward 的提升并不代表模型真的表现的更好。
如下图所示:
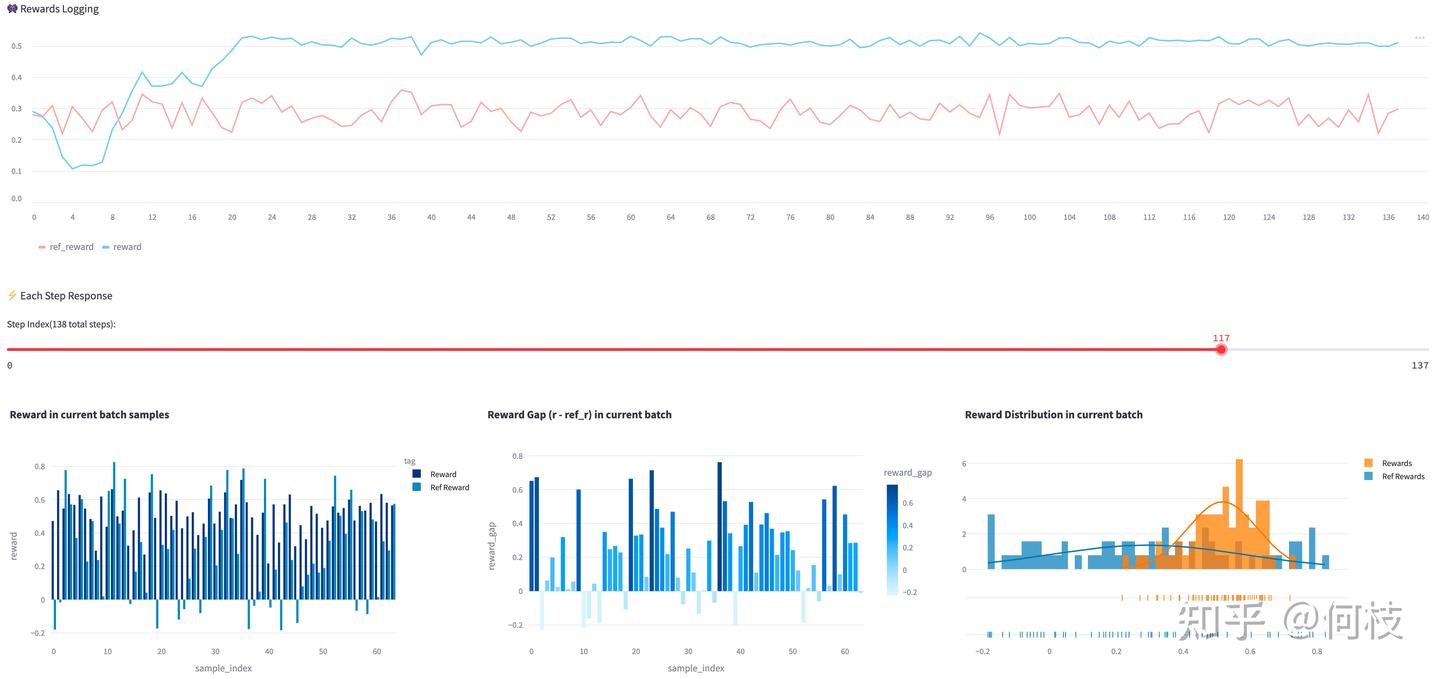
一条看起来很完美的训练曲线,图中右下角为 reward 分布,橙色为当前模型的 reward 分布(集中在高分区域)
这次看起来非常完美的训练,当模型最终生成的结果却如下所示:

以「情绪识别模型」作为 RM,目标为生成更优情绪的答案
我们发现,模型的输出都是一些乱码,
之所以生成这种结果,是因为 Reward Model 对于这类「乱码」打分很高(最后一列为 RM 打出的分数)。
这种通过找到 shortcut 形成 reward 提升的现象又称为 reward hacking。
对于这种情况,除了提升 RM 本身的能力以外,我们还可以通过 Combine 多个 RM 以防止这种情况出现。
如 Llama 2 中同时使用了 2 个 RM(Safety + Helpful)来进行打分,不过论文中给出的理由是 Safety 和 Helpful 这两个任务目标之间可能存在冲突,但使用多个 RM 来综合打分同时也能较好的防止模型训到天上去。
最终的训练结果如下:
使用多个混合RM策略进行训练的结果
通过使用多种策略进行混合,最终模型能够获得较为稳定的分数增长,输出模型也不再崩溃。
体验大模型
通过https://teniuapi.online,的令牌管理,新建自己的TENIU API Key,替换下面代码中的TENIUAPI_API_KEY
# 通过claude code方式,使用deepseek-v4-flash来体验
# 通过https://teniuapi.online,的令牌管理,新建自己的TENIU API Key
# 替换`TENIUAPI_API_KEY` 为您新建的 TENIU API Key
{
"env": {
"ANTHROPIC_BASE_URL": "https://teniuapi.online",
"ANTHROPIC_AUTH_TOKEN": "TENIUAPI_API_KEY",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_MODEL": "deepseek-v4-flash",
"ANTHROPIC_SMALL_FAST_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-v4-flash"
}
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)