ai llm训练数据合成说明
一、推理服务
使用llamacpp做本地推理服务,使用gguf加gpu加速。
模型使用Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled-GGUF
llama-server.exe -m .\Qwen3.5-9B.Q4_K_M.gguf -ngl 99 -c 4096 --host 0.0.0.0 --port 8080 --parallel 4 -np 4 -cb
参数 全称 说明
--host 监听地址。默认 127.0.0.1(仅本机访问),设为 0.0.0.0 允许局域网/外网访问
--port 监听端口。默认 8080
-c --ctx-size 上下文长度。影响单次对话能处理的最大 token 数
-np --parallel 同时处理的请求数(并发槽位)。需要配合 -cb 使用
-cb --cont-batching 连续批处理。允许多个请求共享同一个批次,大幅提升并发性能,强烈建议开启
--parallel 同 -np,设置并发数量
-ngl --gpu-layers GPU 卸载层数,99 表示全部卸载
-sm --split-mode 多卡模式(layer / row)
-ts --tensor-split 多卡显存分配比例
请求测试llamacpp 服务
$body = @{
messages = @(
@{
role = "user"
content = "人工智能的发展历史?"
}
)
temperature = 0.7
max_tokens = 512
} | ConvertTo-Json -Depth 3
$bytes = [System.Text.Encoding]::UTF8.GetBytes($body)
$response = Invoke-RestMethod -Uri "http://localhost:8080/v1/chat/completions" `
-Method Post `
-ContentType "application/json; charset=utf-8" `
-Body $bytes
Write-Host "=== 模型思考过程 ===" -ForegroundColor Cyan
Write-Host $response.choices[0].message.reasoning_content
Write-Host "`n=== 模型最终回复 ===" -ForegroundColor Green
Write-Host $response.choices[0].message.content
使用powershell指令确实比linux shell麻烦很多,不熟悉用起来太坑人。
curl http://192.168.5.142:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"messages": [
{
"role": "system",
"content": "你是一个直接的AI助手,请直接给出答案,不要输出思考过程。"
},
{
"role": "user",
"content": "人工智能的发展历史?"
}
],
"temperature": 0.7,
"max_tokens": 1024
}'
二、数据合成处理:
distilabel做数据合成
代码示例:
import json
import re
from typing import List, Literal
from pydantic import BaseModel, Field
from distilabel.models import OpenAILLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
# 1. 定义带有元数据的结构化模型
class ExamQuestion(BaseModel):
question: str = Field(..., description="问题内容")
answer: str = Field(..., description="正确答案,必须完全基于文档")
distractors: List[str] = Field(..., description="干扰项列表")
difficulty: Literal["简单", "中等", "困难"] = Field(..., description="评估问题的难度")
topic: str = Field(..., description="问题所属的一级领域")
task_type: Literal["定义解释", "原理分析", "场景应用", "技术比较"] = Field(..., description="任务类型")
is_grounded: bool = Field(..., description="答案是否完全包含在文档中")
class ExamQuestions(BaseModel):
exam: List[ExamQuestion]
SYSTEM_PROMPT = """\
你是一名专业命题老师。根据文档生成高质量考试题。
输出必须是合法的 JSON 对象,不要包含 Markdown 标记。
结构如下:
{
"exam":[
{
"question": "问题",
"answer": "正确答案",
"distractors": ["错误1", "错误2", "错误3"],
"difficulty": "中等",
"topic": "领域名",
"task_type": "定义解释",
"is_grounded": true
}
]
}
""".strip()
# 3. 更新 Pipeline
with Pipeline(name="ExamGenerator") as pipeline:
load_dataset = LoadDataFromDicts(
name="load_instructions",
data=[
{"page": "迁移学习(TL)是机器学习(ML)中的一种技术,它涉及将知识从一个模型迁移到另一个模型。关键技术包括:1)特征提取——使用预训练模型中学到的表示;2)微调——调整预训练模型的全部或部分层;3)预训练模型——在大型数据集(如ImageNet)上训练的模型,如ResNet、VGG。迁移学习的优点包括减少训练时间、提高性能和降低数据需求。"},
{"page": "深度学习是机器学习的一个子集,它使用具有多层的神经网络。关键架构包括:1)卷积神经网络(CNN)——用于图像识别;2)循环神经网络(RNN)——用于序列数据;3)Transformer——用于自然语言处理。应用领域包括计算机视觉、语音识别和自动驾驶。"},
],
output_mappings={"page": "instruction"},
)
# 核心优化:使用 structured_output 自动处理格式,无需正则
text_generation = TextGeneration(
name="exam_generation",
system_prompt=SYSTEM_PROMPT,
template="文档内容:\n{{ instruction }}\n\n请按要求生成JSON:",
llm=OpenAILLM(
model="glm-5-fp8",
base_url="http://192.168.5.149:8080/v1",
api_key="EMPTY",
# 很多兼容 OpenAI 的本地服务支持 response_format
generation_kwargs={"response_format": {"type": "json_object"}}
),
input_batch_size=1,
num_generations=1,
)
load_dataset >> text_generation
if __name__ == "__main__":
distiset = pipeline.run(
parameters={
text_generation.name: {
"llm": {"generation_kwargs": {"max_new_tokens": 4096, "temperature": 0.2}}
}
},
use_cache=False,
)
# 导出数据:由于使用了 structured_output,item["generation"] 直接就是字典对象
dataset = distiset["default"]["train"]
output_data =[]
for idx, item in enumerate(dataset):
try:
raw_gen = item.get("generation", "")
# 如果是空的或过短,直接跳过
if not raw_gen or len(raw_gen.strip()) < 20:
print(f"数据解析跳过: 第 {idx} 条为空或内容异常")
continue
# 清理 Markdown 和多余字符
clean_gen = re.sub(r'^```json\s*|\s*```$', '', raw_gen.strip())
# 解析 JSON
data_dict = json.loads(clean_gen)
# 校验格式
exam_data = ExamQuestions(**data_dict)
output_data.append({
"instruction": item["instruction"],
"qa_list":[q.model_dump() for q in exam_data.exam],
"model": item.get("model_name", "glm-5-fp8")
})
print(f"成功处理第 {idx} 条")
except Exception as e:
print(f"解析失败: {e} | 数据: {raw_gen[:100]}")
with open("data/optimized_exam_with_meta.json", "w", encoding="utf-8") as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
print("数据合成与元数据标注完成,已保存至 data/optimized_exam_with_meta.json")
合成数据示例:
[
{
"instruction": "迁移学习(TL)是机器学习(ML)中的一种技术,它涉及将知识从一个模型迁移到另一个模型。关键技术包括:1)特征提取——使用预训练模型中学到的表示;2)微调——调整预训练模型的全部或部分层;3)预训练模型——在大型数据集(如ImageNet)上训练的模型,如ResNet、VGG。迁移学习的优点包括减少训练时间、提高性能和降低数据需求。",
"qa_list": [
{
"question": "根据文档内容,迁移学习中的预训练模型主要是在什么类型的数据集上训练的?",
"answer": "大型数据集(如ImageNet)",
"distractors": [
"小型数据集",
"无标签数据集",
"随机生成的数据集"
],
"difficulty": "中等",
"topic": "机器学习/迁移学习",
"task_type": "定义解释",
"is_grounded": true
}
],
"model": "glm-5"
},
{
"instruction": "深度学习是机器学习的一个子集,它使用具有多层的神经网络。关键架构包括:1)卷积神经网络(CNN)——用于图像识别;2)循环神经网络(RNN)——用于序列数据;3)Transformer——用于自然语言处理。应用领域包括计算机视觉、语音识别和自动驾驶。",
"qa_list": [
{
"question": "根据文档内容,深度学习与机器学习之间的关系是什么?",
"answer": "深度学习是机器学习的一个子集",
"distractors": [
"机器学习是深度学习的子集",
"深度学习与机器学习是完全无关的领域",
"深度学习与机器学习是同一个概念"
],
"difficulty": "中等",
"topic": "深度学习基础概念",
"task_type": "定义解释",
"is_grounded": true
}
],
"model": "glm-5"
}
]
三、数据做清洗、处理:
注意:需要此处代码比不能直接处理上面带元数据的合成文件,是之前给简单合成问答对数据使用的。
import json
import re
from typing import List
# 1. 简单的特殊符号与隐私脱敏清理逻辑
def clean_text(text: str) -> str:
# 替换常见的全角转半角(如果需要)或清除不可见字符
text = text.replace("\u200b", "").replace("\xa0", " ")
# 简单脱敏:例如将形如 13800000000 的替换为 [PHONE]
text = re.sub(r'1[3-9]\d{9}', '[PHONE]', text)
# 去除多余的重复词(简单示例:连续出现的相同词组)
text = re.sub(r'(你好){2,}', '你好', text)
return text.strip()
# 2. 长度统计阈值
MIN_TOKENS = 5
MAX_TOKENS = 1024 # 根据你的模型上下文设定
def get_token_len(text: str) -> int:
# 这里使用简单的字符长度估算,如果需要精确可以使用 tiktoken
return len(text)
def process_data(input_file: str, output_file: str):
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
sft_data =[]
stats = {"total": 0, "filtered": 0}
for entry in data:
instruction = clean_text(entry["instruction"])
for qa in entry["qa_list"]:
stats["total"] += 1
question = clean_text(qa["question"])
answer = clean_text(qa["answer"])
# 3. 长度分布过滤
if not (MIN_TOKENS < get_token_len(instruction + question) < MAX_TOKENS):
stats["filtered"] += 1
continue
# 5. 适配 SFT 问答对格式 (ChatML/Messages 格式)
sft_entry = {
"messages":[
{"role": "system", "content": "你是一名专业助手,请根据提供的参考文档回答问题。"},
{"role": "user", "content": f"参考文档:{instruction}\n\n问题:{question}"},
{"role": "assistant", "content": answer}
]
}
sft_data.append(sft_entry)
# 导出数据
with open(output_file, 'w', encoding='utf-8') as f:
for entry in sft_data:
f.write(json.dumps(entry, ensure_ascii=False) + "\n")
print(f"处理完成!")
print(f"原始样本数: {stats['total']}, 过滤后样本数: {len(sft_data)}, 过滤数: {stats['filtered']}")
if __name__ == "__main__":
process_data("../distidata/data/optimized_exam.json", "../distidata/data/sft_train.jsonl")
四、数据人工处理:
argilla做数据人工处理:
服务使用本地docker启动。
操作说明https://docs.argilla.io/latest/getting_started/how-to-deploy-argilla-with-docker/
本地需要安装sdk 客户端用与加载数据,示例
import argilla as rg
import json
import os
# 1. 设置连接参数
os.environ["ARGILLA_API_URL"] = "http://localhost:6900"
os.environ["ARGILLA_API_KEY"] = "argilla.apikey"
# 2. 初始化客户端 (v2.0 推荐方式)
client = rg.Argilla(
api_url=os.environ["ARGILLA_API_URL"],
api_key=os.environ["ARGILLA_API_KEY"]
)
# 3. 定义数据集 (v2.0 使用 rg.Dataset)
# 如果数据集已存在,可以使用 client.datasets("exam_dataset_v1") 获取
dataset = rg.Dataset(
name="exam_dataset_v1",
settings=rg.Settings(
fields=[
rg.TextField(name="instruction"),
rg.TextField(name="question"),
rg.TextField(name="answer"),
rg.TextField(name="topic"),
],
questions=[
rg.LabelQuestion(
name="difficulty_check",
title="难度是否准确?",
labels=["简单", "中等", "困难"]
),
rg.RatingQuestion(
name="quality_score",
title="数据质量评分",
values=[1, 2, 3, 4, 5]
),
rg.LabelQuestion(
name="task_type",
title="任务类型分类",
labels=["定义解释", "原理分析", "场景应用", "技术比较"]
)
]
)
)
# 4. 创建或加载数据集
try:
dataset.create()
print("数据集已创建")
except rg._exceptions._api.ConflictError:
dataset = client.datasets("exam_dataset_v1")
print("数据集已存在,直接加载")
# 5. 读取数据并构建记录
with open("D:/tool/distilabel/distidata/data/optimized_exam_with_meta.json", "r", encoding="utf-8") as f:
data = json.load(f)
records =[]
for entry in data:
for qa in entry["qa_list"]:
# v2.0 直接使用 Dataset.records.log 来上传数据
records.append({
"instruction": entry["instruction"],
"question": qa["question"],
"answer": qa["answer"],
"topic": qa["topic"],
"difficulty_check": qa["difficulty"], # 直接在 record 中填入响应值
"task_type": qa["task_type"]
})
# 6. 上传记录
dataset.records.log(records)
print("数据已成功导入 Argilla v2+ 环境")
在windows上遇到问题是启动server服务es服务没有启动,报错
Unrecognized VM option 'UseSVE=0'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
原因:Unrecognized VM option 'UseSVE=0',是 Argilla 官方示例docker-compose.yaml里给 Elasticsearch 加了-XX:UseSVE=0这个 JVM 选项,但你的 JVM / 架构不支持这个参数,导致 ES 容器直接起不来,所以 Argilla 也连不上 ES、UI 也不会正常可用。
解决方法:把elasticsearch组件ES_JAVA_OPTS和CLI_JAVA_OPTS里的-XX:UseSVE=0删掉,再重启容器。
environment:
- ES_JAVA_OPTS=-Xms512m -Xmx512m -XX:UseSVE=0
- CLI_JAVA_OPTS=-XX:UseSVE=0
environment:
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- CLI_JAVA_OPTS=
登录页面的username、password在docker-compose文件里,apikey也在其中。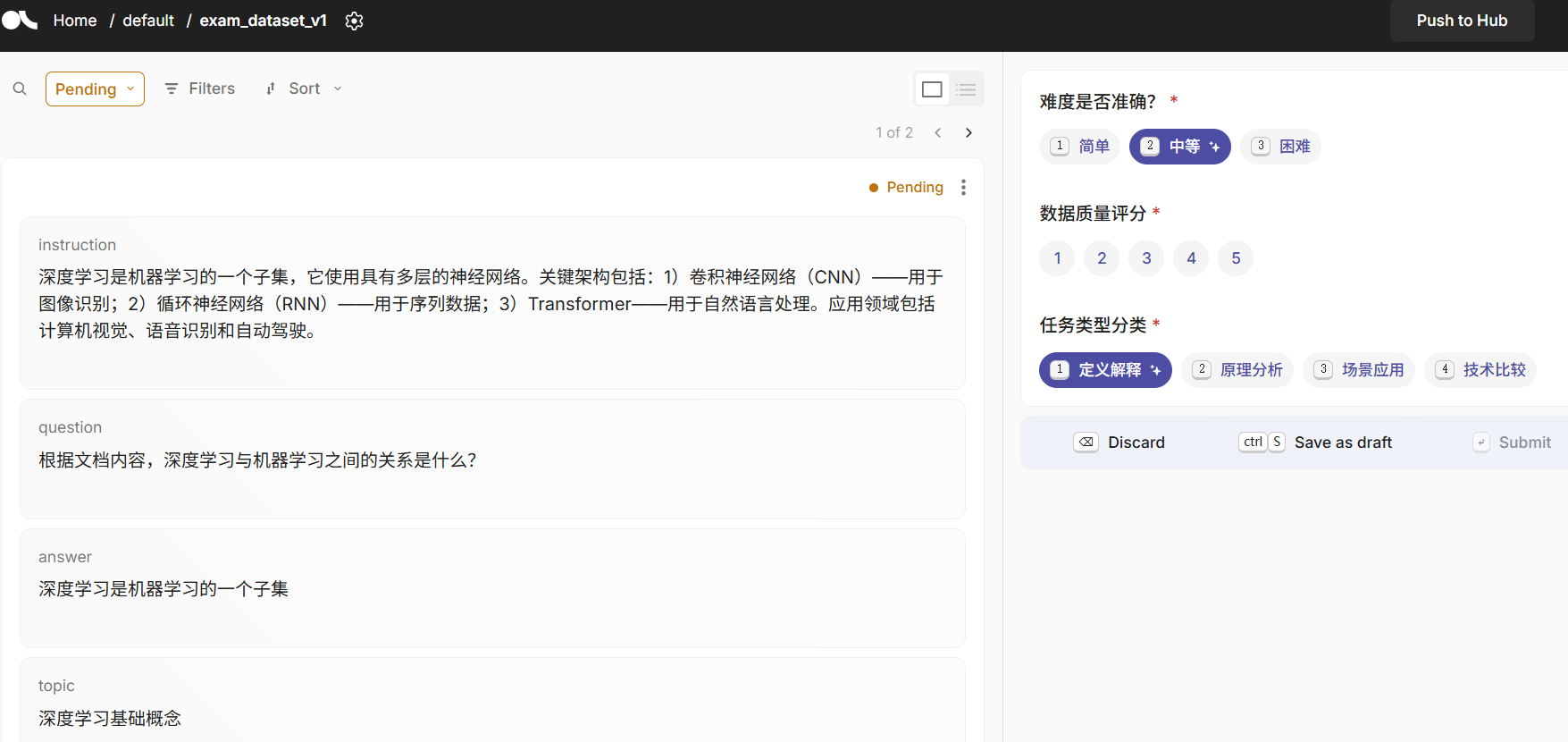
五、原始数据合成处理过程总结:
1、 合成数据阶段:从“生成”到“构建”
- 结构化输出是核心:不要寄希望于模型的 Prompt 约束“自觉性”。在合成阶段,必须通过 Schema
定义Pydantic或结构化协议强制模型输出格式。这能从根源上减少后续清洗的负担。
- 元数据注入即正义:合成数据不应仅仅包含问题和答案。在合成阶段就通过 Prompt 引导模型自动生成
元数据Metadata如:领域主题、难度等级、任务类型、事实性标记,是实现后续精细化分析的前提。
- 防御性Prompt设计:针对合成任务,System Prompt
应始终包含“事实一致性约束”禁止幻觉,要求模型回答必须完全基于给定的文档上下文,而非利用模型自身的知识库。
2、 数据清洗阶段:防御性处理与稳健性
- 后置校验Post-Validation是最后一道防线:无论模型生成多么规范,都必须在Pipeline末端加入强类型校验Schema
Validation。任何不符合预定义结构的数据应被视为“脏数据”并直接过滤,而不是试图对其进行复杂的正则修复。
- 工程化过滤策略:清洗不应仅针对特殊符号,更要涉及“业务过滤”。例如:长度分布过滤,剔除过短或过长的无效样本、事实覆盖过滤,剔除文档外信息、以及隐私脱敏。
- Markdown 与 噪声处理:LLM 倾向于添加 Markdown 格式包装,清洗逻辑应作为 Pipeline的标配组件,专门负责去除干扰字符,确保数据进入训练框架前是纯净的JSON/JSONL。
3、 数据分析与处理过程:从“数据”到“资产”
- 利用元数据实现“数据驱动”的决策:一旦具备了主题、难度等元数据,数据分析就不再是简单的“看一眼”,而是能够计算出各分类下的量值占比。这能精准识别数据“洼地”如:计算机视觉领域缺少困难题目,从而指引下一步的补充生成Data
Augmentation。
- 人工辅助校验 (Human-in-the-loop):Argilla
等工具的价值在于通过抽检和校准来闭环合成流程。当分析发现自动标注的“难度”与人类感知不一致时,应反向优化合成阶段的System Prompt,而非仅在后期修补。
- SFT 的标准化适配:在数据处理末端,必须将嵌套的结构化数据如文档+QA列表扁平化(Flatten)为标准化的 messages
格式。这是训练框架可移植性的保障,也是实现“多领域微调”或“课程学习”的基础。
- 在 Argilla 中标记为“低质量”的数据后,不要直接丢弃。将这些数据导出,分析其共同特征,比如是否都出现在某个特定的 Topic 下,然后回过头去优化 gensftqa.py 中的 SYSTEM_PROMPT。每次微调前,你可以只导出在 Argilla 中被人工标记为 quality_score >= 4 的数据,确保训练出的模型性能最大化。
核心结论
高质量的 SFT数据集不是“清洗出来的”,而是“设计出来的”。通过在合成阶段强制结构化与元数据标注,在清洗阶段进行强校验过滤,在分析阶段进行可视化监控,可以形成一个从“原始文档”到“黄金训练集”的闭环系统,极大地降低微调过程中的“试错成本”并提升模型的泛化与逻辑能力。
额外补充,处理含思考think标签的合成数据处理脚本:
import json
import re
from typing import List, Literal
from pydantic import BaseModel, Field
from distilabel.models import OpenAILLM
from distilabel.pipeline import Pipeline
from distilabel.steps import LoadDataFromDicts
from distilabel.steps.tasks import TextGeneration
# 1. 定义带有元数据的结构化模型
class ExamQuestion(BaseModel):
question: str = Field(..., description="问题内容")
answer: str = Field(..., description="正确答案,必须完全基于文档,要求详细、完整地回答问题,包含具体细节和解释")
distractors: List[str] = Field(..., description="干扰项列表,每个干扰项应该具有一定的迷惑性")
difficulty: Literal["简单", "中等", "困难", "基础"] = Field(..., description="评估问题的难度")
topic: str = Field(..., description="问题所属的一级领域")
task_type: str = Field(..., description="任务类型")
is_grounded: bool = Field(..., description="答案是否完全包含在文档中")
class ExamQuestions(BaseModel):
exam: List[ExamQuestion]
SYSTEM_PROMPT = """\
你是一名专业命题老师。根据文档生成高质量考试题。
输出必须是合法的 JSON 对象,不要包含 Markdown 标记。
重要要求:
1. 答案必须详细、完整,不能只是简单的关键词或短语
2. 答案应该包含具体细节、解释和必要的背景信息
3. 答案长度至少20个字符,复杂问题应该有100-200字符的详细说明
4. 答案必须完全基于提供的文档内容,不能编造
5. 干扰项应该具有一定的迷惑性,与正确答案在形式上相似但内容错误
结构如下:
{
"exam":[
{
"question": "问题",
"answer": "详细、完整的正确答案,包含具体细节和解释",
"distractors": ["错误1", "错误2", "错误3"],
"difficulty": "中等",
"topic": "领域名",
"task_type": "定义解释",
"is_grounded": true
}
]
}
""".strip()
# 3. 更新 Pipeline
with Pipeline(name="ExamGenerator") as pipeline:
load_dataset = LoadDataFromDicts(
name="load_instructions",
data=[
{"page": "迁移学习(TL)是机器学习(ML)中的一种技术,它涉及将知识从一个模型迁移到另一个模型。关键技术包括:1)特征提取——使用预训练模型中学到的表示;2)微调——调整预训练模型的全部或部分层;3)预训练模型——在大型数据集(如ImageNet)上训练的模型,如ResNet、VGG。迁移学习的优点包括减少训练时间、提高性能和降低数据需求。"},
{"page": "深度学习是机器学习的一个子集,它使用具有多层的神经网络。关键架构包括:1)卷积神经网络(CNN)——用于图像识别;2)循环神经网络(RNN)——用于序列数据;3)Transformer——用于自然语言处理。应用领域包括计算机视觉、语音识别和自动驾驶。"},
],
output_mappings={"page": "instruction"},
)
# 核心优化:使用 structured_output 自动处理格式,无需正则
text_generation = TextGeneration(
name="exam_generation",
system_prompt=SYSTEM_PROMPT,
template="""文档内容:
{{ instruction }}
请根据上述文档内容生成考试题。要求:
1. 生成2-3个不同难度的问题
2. 每个问题的答案必须详细、完整,包含具体细节和解释
3. 答案不能只是简单的关键词,应该是完整的句子或段落
4. 确保答案完全基于文档内容
请按要求生成JSON:""",
llm=OpenAILLM(
model="glm-5-fp8",
base_url="http://127.0.0.1:8905/v1",
api_key="EMPTY",
generation_kwargs={"response_format": {"type": "json_object"}}
),
input_batch_size=1,
num_generations=1,
)
load_dataset >> text_generation
if __name__ == "__main__":
distiset = pipeline.run(
parameters={
text_generation.name: {
"llm": {"generation_kwargs": {"max_new_tokens": 4096, "temperature": 0.2}}
}
},
use_cache=False,
)
# 导出数据:由于使用了 structured_output,item["generation"] 直接就是字典对象
dataset = distiset["default"]["train"]
output_data =[]
for idx, item in enumerate(dataset):
try:
raw_gen = item.get("generation", "")
# 如果是空的或过短,直接跳过
if not raw_gen or len(raw_gen.strip()) < 20:
print(f"数据解析跳过: 第 {idx} 条为空或内容异常")
continue
# 清理 Markdown 和多余字符
clean_gen = raw_gen.strip()
# 处理 LLM 思考模式的输出,移除 <think>...</think> 标签
# 模式1: <think>...</think> 在开头
clean_gen = re.sub(r'^\<think\>[\s\S]*?\<\/think\>\s*', '', clean_gen)
# 模式2: <think>...</think> 在任何位置
clean_gen = re.sub(r'\<think\>[\s\S]*?\<\/think\>', '', clean_gen)
# 清理 Markdown 代码块
clean_gen = re.sub(r'^\`\`\`json\s*|\s*\`\`\`$', '', clean_gen)
# 确保以 { 开头
if clean_gen and not clean_gen.startswith('{'):
# 找到第一个 { 的位置
first_brace = clean_gen.find('{')
if first_brace != -1:
clean_gen = clean_gen[first_brace:]
# 解析 JSON
data_dict = json.loads(clean_gen)
# 处理两种格式:数组格式和对象格式
if isinstance(data_dict, list):
# 如果是数组格式,包装成 {"exam": [...]}
data_dict = {"exam": data_dict}
# 校验格式
exam_data = ExamQuestions(**data_dict)
output_data.append({
"instruction": item["instruction"],
"qa_list":[q.model_dump() for q in exam_data.exam],
"model": item.get("model_name", "glm-5-fp8")
})
print(f"成功处理第 {idx} 条")
except Exception as e:
print(f"解析失败: {e} | 数据: {raw_gen[:100]}")
with open("data/optimized_exam_with_meta.json", "w", encoding="utf-8") as f:
json.dump(output_data, f, ensure_ascii=False, indent=2)
print("数据合成与元数据标注完成,已保存至 data/optimized_exam_with_meta.json")
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)