AI-Agent入门实战-AI私厨
AI Agent入门实战:从零搭建一个"AI私厨"应用
引言
在人工智能飞速发展的今天,AI Agent(智能体)已经成为大模型应用的主流形态。与简单的问答不同,Agent 能够感知环境、决策行动、调用工具、保持记忆,从而完成复杂的多步骤任务。
本篇文章,我们将从零开始,手把手教你搭建一个多模态 AI 私厨应用:
用户上传冰箱/厨房的照片,AI 自动识别食材,搜索相关食谱,并按营养价值和难度排序推荐给用户。
整个项目基于 LangChain + LangGraph 架构,使用 FastAPI 提供后端 RESTful 接口,前端采用 Next.js 构建单页应用。核心技术点包括:
- 多模态大模型:支持图片 + 文本的联合输入
- Web 搜索工具:实时搜索食谱( Tavily 搜索)
- Agent 记忆系统:基于 SQLite 的会话历史持久化
- 流式输出:SSE 实时推送 AI 响应
一、环境准备
1.1 依赖安装
在项目根目录下创建 pyproject.toml,声明所有依赖:
[project]
name = "food-recipe-recommender"
version = "0.1.0"
description = "AI-powered recipe recommender based on uploaded food images"
requires-python = ">=3.10"
dependencies = [
"langchain>=0.3.0",
"langchain-community>=0.3.0",
"langchain-openai>=0.2.0",
"langchain-core>=0.3.0",
"langchain-tavily>=0.1.0",
"streamlit>=1.40.0",
"pillow>=11.0.0",
"python-dotenv>=1.0.0",
"fastapi>=0.109.0",
"uvicorn>=0.27.0",
"python-multipart>=0.0.6",
"alibabacloud-oss-v2>=1.2.4",
"langgraph-checkpoint-sqlite>=3.0.3",
]
安装依赖:
uv sync
# 或使用 pip
pip install -r requirements.txt
1.2 API Key 配置
在项目根目录创建 .env 文件:
# 阿里百炼(通义千问)API - 支持多模态输入
DASHSCOPE_API_KEY=你的API_KEY
DASHSCOPE_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
# Tavily Web 搜索 API - 用于搜索食谱
TAVILY_API_KEY=你的API_KEY
# LangSmith 可选 - 用于调试和监控 Agent 运行时
LANGSMITH_API_KEY=你的API_KEY
LANGSMITH_TRACING=true
LANGSMITH_PROJECT=lc-course
# 阿里云 OSS(可选)- 用于图片上传
OSS_ACCESS_KEY_ID=你的AccessKey_ID
OSS_ACCESS_KEY_SECRET=你的AccessKey_Secret
OSS_BUCKET=你的Bucket名称
OSS_ENDPOINT=oss-cn-heyuan.aliyuncs.com
1.3 项目结构
项目根目录/
├── app/
│ ├── __init__.py
│ ├── main.py
│ ├── agents/
│ │ ├── __init__.py
│ │ └── personal_chief.py
│ ├── api/
│ │ └── v1/
│ │ ├── __init__.py
│ │ ├── chat.py
│ │ └── oss.py
│ ├── models/
│ │ ├── __init__.py
│ │ └── schemas.py
│ ├── common/
│ │ ├── __init__.py
│ │ └── logger.py
│ └── db/ # SQLite数据库目录(自动创建)
├── .env
└── pyproject.toml
二、完整源码
2.1 app/__init__.py
# app/__init__.py
# 包初始化文件,可以为空
2.2 app/common/__init__.py
# app/common/__init__.py
# 公共模块初始化文件
2.3 app/common/logger.py
# app/common/logger.py
import logging
import sys
# 配置日志格式:时间 - 级别 - 模块 - 消息
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(name)s - %(message)s"
def setup_logging():
"""
初始化日志配置。
- StreamHandler:将日志输出到控制台(stdout),方便在终端实时查看
- FileHandler(注释掉):如果需要持久化到文件,可取消注释
"""
logging.basicConfig(
level=logging.INFO, # INFO级别起步,生产环境可改为WARNING
format=LOG_FORMAT,
handlers=[
logging.StreamHandler(sys.stdout), # 输出到控制台
# logging.FileHandler("app.log") # 追加模式写入文件
]
)
# 创建一个全局的logger实例,供其他模块直接调用
# 使用__name__可以自动显示调用方的模块名,便于定位日志来源
logger = logging.getLogger("personal_chief")
2.4 app/models/__init__.py
# app/models/__init__.py
# 数据模型模块初始化文件
2.5 app/models/schemas.py
# app/models/schemas.py
from typing import Optional, List
from pydantic import BaseModel
class ChatRequest(BaseModel):
"""
聊天请求的数据模型。
使用Pydantic做运行时类型校验,FastAPI自动从请求体解析字段。
"""
message: str # 用户输入的文本内容
image_url: Optional[str] = None # 可选:图片的OSS URL
thread_id: str # 会话线程ID,用于关联同一轮对话的所有消息
2.6 app/agents/__init__.py
# app/agents/__init__.py
# Agent模块初始化文件
2.7 app/agents/personal_chief.py
这是整个应用最核心的文件,包含了 Agent 的完整逻辑:
# app/agents/personal_chief.py
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, AIMessageChunk, AIMessage
from langchain_core.tools import tool
from langchain_tavily import TavilySearch
from langchain.agents import create_agent
from app.common.logger import logger
import os
from langgraph.checkpoint.sqlite import SqliteSaver
import sqlite3
# 加载环境变量
from dotenv import load_dotenv
load_dotenv()
# web搜索工具,使用tavily作为web搜索工具
# max_results=5:每次搜索最多返回5条结果
# topic="general":通用主题搜索
tavily = TavilySearch(
max_results=5,
topic="general"
)
# 多模态模型
# 使用通义千问的qwen3-omni-flash(多模态模型)
# model_provider="openai":因为通义兼容OpenAI的接口协议,所以填openai
model = init_chat_model(
model="qwen3-omni-flash", # 模型名称,支持图片、文本、音频、视频多模态输入
model_provider="openai",
base_url=os.getenv("DASHSCOPE_BASE_URL"),
api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 初始化checkpointer
# 连接SQLite数据库文件,用于持久化Agent的对话历史
# check_same_thread=False:允许跨线程访问(uvicorn多worker时需要)
checkpointer = SqliteSaver(sqlite3.connect("db/personal_chief.db", check_same_thread=False))
# 自动建表
checkpointer.setup()
# Agent系统提示词
# 这是给AI的"角色设定 + 操作流程"说明书
# 提示词的质量直接决定Agent的行为是否符合预期
system_prompt = """
你是一名私人厨师。收到用户提供的食材照片或清单后,请按以下流程操作:
1.识别和评估食材:若用户提供照片,首先辨识所有可见食材。基于食材的外观状态,评估其新鲜度与可用量,整理出一份"当前可用食材清单"。
2.智能食谱检索:优先调用 web_search 工具,以"可用食材清单"为核心关键词,查找可行菜谱。
3.多维度评估与排序:从营养价值和制作难度两个维度对检索到的候选食谱进行量化打分,并根据得分排序,制作简单且营养丰富的排名靠前。
4.结构化方案输出:把排序后的食谱整理为一份结构清晰的建议报告,要包含食谱信息、得分、推荐理由、食谱的参考图片,帮助用户快速做出决策。
请严格按照流程,优先调用 web_search 工具搜索食谱,搜索不到的情况下才能自己发挥。
"""
# 创建代理
# create_agent是LangChain的高级封装,内部基于LangGraph实现
# 只需传入model、tools、prompt,框架自动构建推理循环
agent = create_agent(
model=model, # 多模态大模型(大脑)
tools=[tavily], # 工具列表(手脚)
checkpointer=checkpointer, # 记忆存储(笔记)
system_prompt=system_prompt # 行为规范(手册)
)
# 流式对话
async def search_recipes(prompt: str, image: str, thread_id: str):
"""
调用agent搜索食谱,支持流式输出(打字机效果)。
Args:
prompt: 用户输入的文本
image: 可选的图片URL(来自OSS上传)
thread_id: 会话线程ID
Yields:
str: AI响应的文本片段(用于SSE流式推送)
"""
logger.info(f"[用户]: {prompt}, image: {image}, thread_id: {thread_id}")
try:
# 判断是否有图片,封装不同格式的消息
# LangChain的HumanMessage支持多模态content(列表形式)
if not image or image.strip() == "":
# 纯文本场景:直接传字符串
message = HumanMessage(content=prompt)
else:
# 多模态场景:content是list,包含image URL + text
message = HumanMessage(content=[
{"type": "image", "url": image}, # 图片URL(不传base64,省内存)
{"type": "text", "text": prompt} # 配合图片的文本问题
])
# 流式调用Agent
for chunk, metadata in agent.stream(
{"messages": [message]},
{"configurable": {"thread_id": thread_id}}, # 注入thread_id,关联记忆
stream_mode="messages"
):
if isinstance(chunk, AIMessageChunk) and chunk.content:
yield chunk.content
except Exception as e:
logger.error(f"\n[错误]: {str(e)}")
yield "信息检索失败,试试看手动输入食物列表?"
# 清空会话
def clear_messages(thread_id: str):
"""清空会话"""
logger.info(f"清空历史消息,thread_id: {thread_id}")
checkpointer.delete_thread(thread_id)
# 查询会话历史
def get_messages(thread_id: str) -> list[dict[str, str]]:
"""
获取会话历史。
LangChain的checkpoint中存储了完整的消息列表,
我们从中提取HumanMessage(用户)和AIMessage(AI)进行返回。
"""
logger.info(f"获取历史消息,thread_id: {thread_id}")
# 根据thread_id查询checkpoint
checkpoint = checkpointer.get({"configurable": {"thread_id": thread_id}})
# 如果不存在,返回空列表
if not checkpoint:
return []
# 安全获取messages
channel_values = checkpoint.get("channel_values")
if not channel_values:
return []
messages = channel_values.get("messages", [])
if not messages:
return []
# 转换消息格式
result = []
for msg in messages:
if not msg.content:
continue
if isinstance(msg, HumanMessage):
result.append({"role": "user", "content": msg.content})
elif isinstance(msg, AIMessage):
result.append({"role": "assistant", "content": msg.content})
return result
2.8 app/api/__init__.py
# app/api/__init__.py
# API模块初始化文件
2.9 app/api/v1/__init__.py
# app/api/v1/__init__.py
# API v1版本初始化文件
2.10 app/api/v1/chat.py
# app/api/v1/chat.py
from fastapi import APIRouter
from app.models.schemas import ChatRequest
from fastapi.responses import StreamingResponse
from app.agents.personal_chief import search_recipes, get_messages, clear_messages
router = APIRouter()
@router.post("/chat/stream")
async def chat_endpoint(request: ChatRequest):
"""流式聊天接口"""
return StreamingResponse(
search_recipes(request.message, request.image_url, request.thread_id),
media_type="text/event-stream"
)
@router.get("/chat/messages")
async def get_chat_messages(thread_id: str):
"""获取历史消息"""
messages = get_messages(thread_id)
return {"messages": messages}
@router.delete("/chat/messages")
async def clear_chat_messages(thread_id: str):
"""清空历史消息"""
clear_messages(thread_id)
return {"success": True}
2.11 app/api/v1/oss.py
# app/api/v1/oss.py
import alibabacloud_oss_v2 as oss
from fastapi import APIRouter
from datetime import timedelta
import os
# 加载环境变量
from dotenv import load_dotenv
load_dotenv()
router = APIRouter()
# 从环境变量中加载凭证信息,用于身份验证
# 使用EnvironmentVariableCredentialsProvider,密钥不落地代码
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
# 加载SDK的默认配置,并设置凭证提供者
cfg = oss.config.load_default()
cfg.credentials_provider = credentials_provider
# 方式一:只填写Region(推荐)
# 必须指定Region ID,SDK会根据Region自动构造HTTPS访问域名
cfg.region = 'cn-heyuan'
# 使用配置好的信息创建OSS客户端
client = oss.Client(cfg)
# OSS 域名配置
OSS_ENDPOINT = os.getenv("OSS_ENDPOINT", "oss-cn-heyuan.aliyuncs.com")
OSS_BUCKET = os.getenv("OSS_BUCKET")
@router.get("/oss/presign")
def chat_endpoint(filename: str):
"""
返回一个预签名的PUT请求URL。
前端拿这个URL,直接上传文件到OSS,不经过我们的服务器。
这样设计的好处:
1. 服务器不承担文件传输,省带宽
2. OSS原生支持HTTPS,安全
3. 签名URL有时效,过期无法上传,防滥用
"""
# 根据文件扩展名判断Content-Type,OSS上传需要准确类型
content_type_map = {
"jpg": "image/jpeg",
"jpeg": "image/jpeg",
"png": "image/png",
"gif": "image/gif",
"webp": "image/webp",
}
ext = filename.split(".")[-1].lower() if "." in filename else "jpg"
content_type = content_type_map.get(ext, "application/octet-stream")
# 预签名URL,有效期1小时
pre_result = client.presign(oss.PutObjectRequest(
bucket=OSS_BUCKET,
key=filename,
content_type=content_type,
), expires=timedelta(seconds=3600))
# 返回上传URL和可访问的图片路径
return {
"uploadUrl": pre_result.url.strip('"'), # 前端用这个URL上传
"contentType": content_type,
"accessUrl": f"https://{OSS_BUCKET}.{OSS_ENDPOINT}/{filename}" # 上传后的访问地址
}
2.12 app/main.py
# app/main.py
import os
from fastapi import FastAPI
from fastapi.responses import FileResponse
from fastapi.staticfiles import StaticFiles
from fastapi.middleware.cors import CORSMiddleware
from app.api.v1 import chat
from app.api.v1 import oss
from app.common.logger import setup_logging
# 初始化日志配置(最早执行,确保后续所有模块都能正确记录日志)
setup_logging()
# 创建FastAPI应用实例
app = FastAPI(
title="Personal Chief API",
description="私厨",
version="0.1.0"
)
# 配置跨域资源共享 (CORS)
# 因为我们的前端可能是独立部署的(Next.js静态导出),
# 需要允许跨域请求,否则浏览器会阻止AJAX请求
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境建议指定具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 挂载路由
# /api/v1/chat/* -> chat.py中的接口
# /api/v1/oss/* -> oss.py中的接口
app.include_router(chat.router, prefix="/api/v1", tags=["对话"])
app.include_router(oss.router, prefix="/api/v1", tags=["申请上传签名url"])
# 挂载前端资源(如果有static目录的话)
static_dir = os.path.join(os.path.dirname(__file__), "static")
if os.path.exists(static_dir):
app.mount("/", StaticFiles(directory=static_dir, html=True), name="static")
# 前端fallback路由 - 只处理非API请求
# Next.js是单页应用(SPA),所有路由都由index.html处理
# FastAPI不知道前端有哪些路由,所以对未匹配的路径返回index.html
@app.get("/{path:path}", include_in_schema=False)
async def serve_frontend(path: str):
# 排除API路径
if path.startswith("api/"):
from fastapi.responses import JSONResponse
return JSONResponse({"error": "Not Found"}, status_code=404)
# 如果请求的是静态文件,直接返回
file_path = os.path.join(static_dir, path)
if os.path.isfile(file_path):
return FileResponse(file_path)
# 否则返回index.html(SPA fallback)
index_path = os.path.join(static_dir, "index.html")
if os.path.exists(index_path):
return FileResponse(index_path)
return {"message": "你的独家私厨上线了~", "status": "ok"}
if __name__ == "__main__":
import uvicorn
# 启动命令:python -m app.main
uvicorn.run("app.main:app", host="127.0.0.1", port=8001, reload=True)
三、快速运行
3.1 创建所有文件
按照上面的项目结构,创建好所有目录和文件,将对应的代码复制进去。
3.2 启动服务
# 1. 安装依赖
uv sync
# 2. 启动服务
python -m app.main
# 3. 打开浏览器访问
# http://localhost:8001
四、运行效果演示
4.1 基础聊天界面
启动后访问 http://localhost:8001,可以看到完整的聊天界面:

- 支持图片上传(点击上传按钮选择冰箱/厨房照片)
- 支持纯文本对话(直接输入食材列表)
- AI自动识别食材并搜索食谱
4.2 上传食材图片
上传一张冰箱图片后,AI 会自动识别食材:

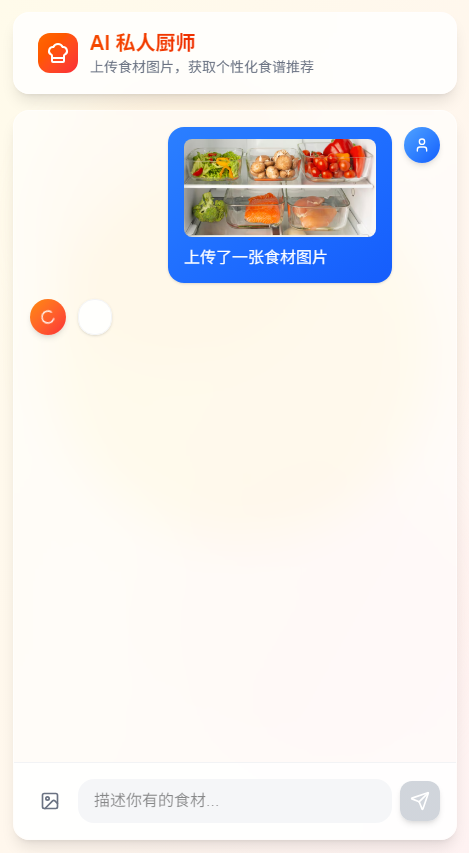

4.3 智能食谱推荐
AI 调用 Tavily 搜索相关食谱,并按营养价值 + 制作难度打分排序:

4.4 多轮对话(Agent 记忆)
用户:我喜欢第1道菜,可以说得更详细点吗?
AI:当然可以!下面是"三文鱼西兰花烤盘料理"的详细步骤...
(包含食材清单、详细步骤、小贴士、营养分析)
Agent 自动记住了之前的上下文,知道"第1道菜"指的是什么食谱。
4.5 LangSmith 调试界面
LangChain 提供了基于 LangSmith 的 GUI 控制台,可以方便地调试 Agent: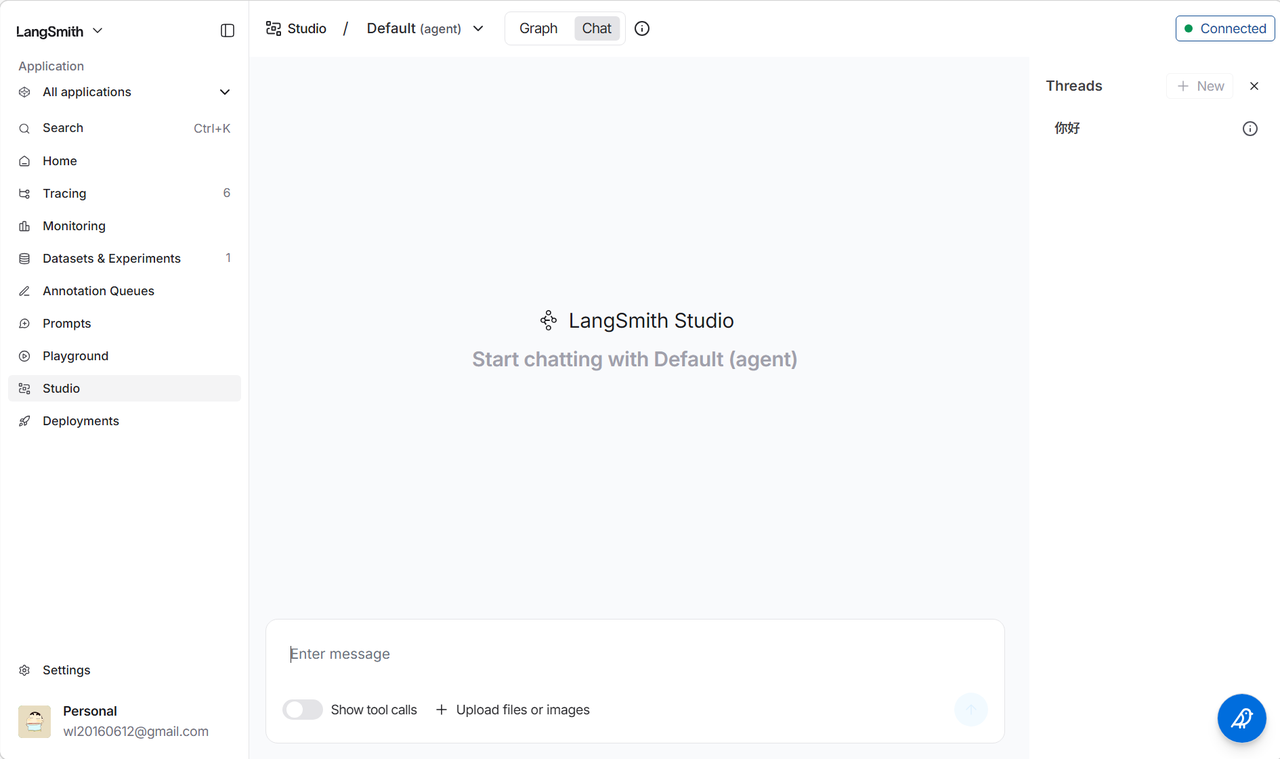
4.6 详细的调用过程追踪
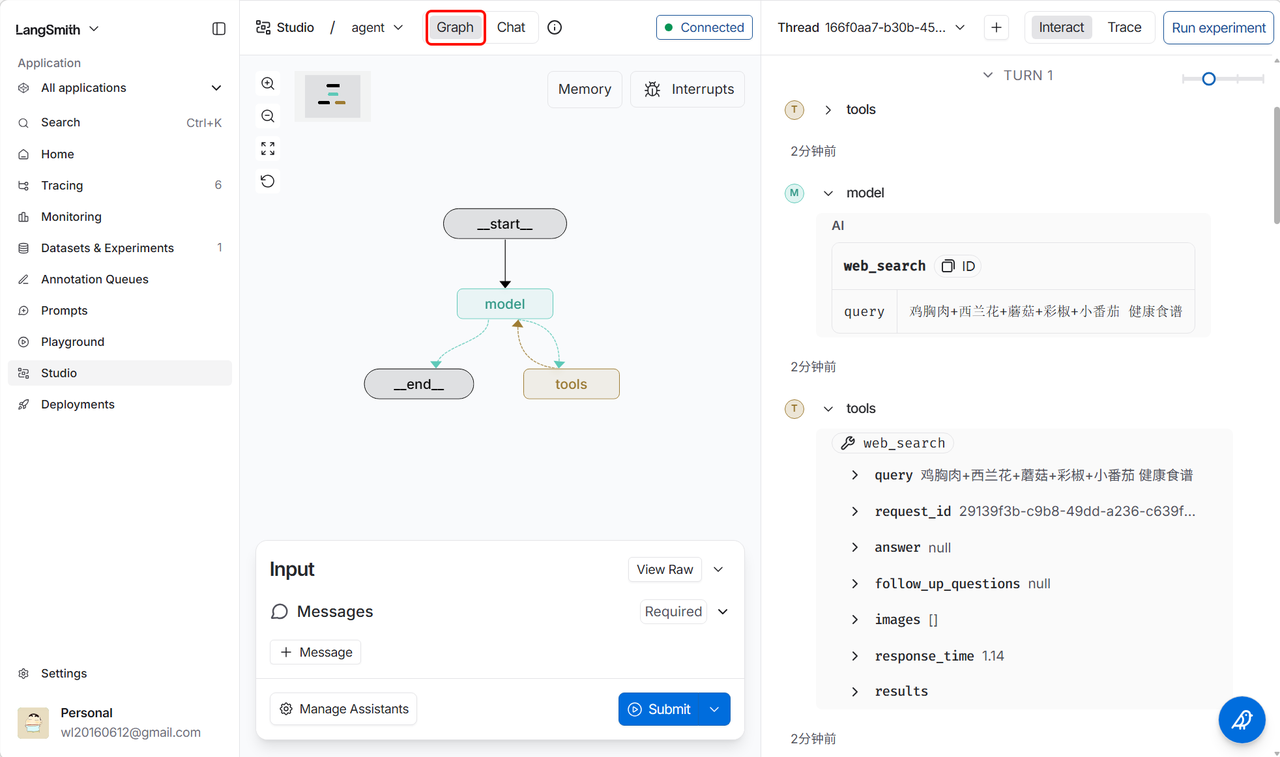
五、总结与扩展
5.1 Agent 核心原理回顾
┌─────────────────────────────────────────────┐
│ Agent 架构 │
├─────────────────────────────────────────────┤
│ ┌─────────┐ ┌──────────┐ ┌────────┐ │
│ │ Model │◄──►│ Tools │◄──►│ Memory │ │
│ │ (大脑) │ │ (手脚) │ │ (笔记) │ │
│ └────┬────┘ └──────────┘ └────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ 推理循环 │ │
│ │ (Agent Loop)│ │
│ └─────────────┘ │
│ │
│ 1. 接收用户输入(文本 + 图片) │
│ 2. 模型理解意图,决定是否调用工具 │
│ 3. 执行工具(Tavily 搜索) │
│ 4. 将工具结果注入模型,生成最终回复 │
│ 5. 将本轮对话存入 Memory,供后续使用 │
└─────────────────────────────────────────────┘
| 组件 | 技术选型 | 作用 |
|---|---|---|
| Model | qwen3-omni-flash(通义) |
多模态理解 + 文本生成 |
| Tools | TavilySearch |
实时 Web 搜索食谱 |
| Memory | SqliteSaver |
多轮对话历史持久化 |
| Framework | LangChain + create_agent |
Agent 编排框架 |
5.2 扩展练习
扩展 1:添加更多工具
目前 Agent 只有 Web 搜索一个工具。可以尝试添加:
- 天气 API:根据当地天气推荐适合的菜品(如雨天推荐热汤)
- 营养计算器:接入营养数据库,计算每道菜的热量/碳水/蛋白质
扩展 2:支持语音输入
利用浏览器的 Web Speech API 采集语音,通过 ASR 转文字后发送给 Agent,实现"拍照 + 语音提问"的交互方式。
扩展 3:换用不同的模型
将 qwen3-omni-flash 替换为 gpt-4o 或 claude-3-opus,只需修改 model 和 base_url/api_key,提示词和工具代码无需改动——这就是 LangChain 接口统一抽象的好处。
推荐阅读
| 类型 | 名称/描述 | 链接 |
|---|---|---|
| 视频教程 | 黑马程序员2026最新版LangChain+LangGraph开发实战 | B站视频 BV178w1z7EHQ |
| 官方文档 | LangChain 官方文档 | https://python.langchain.com/ |
| 官方文档 | LangGraph 快速入门 | https://langchain-ai.github.io/langgraph/ |
| 官方文档 | Tavily Search API | https://tavily.com/ |
| 官方文档 | 阿里云百炼 API | https://bailian.console.aliyun.com/ |
注意事项
- API Key 安全:生产环境中务必将 Key 放在环境变量或密钥管理服务中,切勿硬编码到代码
- OSS 权限:示例中将 Bucket 设置为"公共读"仅用于演示,生产环境应设为私有并通过 CDN 对外暴露
- 流式输出兼容性:部分 HTTP 客户端(如某些版本requests)不支持 SSE,请使用浏览器 Fetch API 或 Postman 测试

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)