山东大学软件学院创新实训——个人博客(五)让AI看懂画:第七周AI识别与心理报告联调实战
让AI看懂画:第七周AI识别与心理报告联调实战
这周我们进入了项目最核心的技术环节——AI识别与心理报告系统的联调。经过前几周的努力,游戏的实时通信和房间管理已经稳定运行,现在终于到了让“AI看懂画”并生成心理分析报告的关键时刻。
AI调用链路测试
我们构建了一条完整的AI调用链路,从前端用户画画到后端AI识别,整个流程经过了严格的测试。
完整调用链路
前端画图 → Canvas转Base64 → WebSocket发送 → 后端接收 → 调用AI API → 解析返回 → 存储数据库 → 广播结果
前端编码阶段
用户在Canvas上完成绘画后,前端会将画布内容转换为Base64编码的PNG图片,并连同行为数据一起发送:
const imageBase64 = this.board.toBase64();
const behaviorData = this.board.getBehaviorData();
this.socket.emit('drawing_complete', {
room_id: this.roomId,
user_id: this.user.user_id,
image_base64: imageBase64,
drawing_time_ms: behaviorData.drawing_duration_ms,
behavior_data: behavior_data,
});
后端接收阶段
后端通过WebSocket事件drawing_complete接收绘画数据,保存原始数据后启动异步AI识别:
@socketio.on('drawing_complete')
def handle_drawing_complete(data):
# 保存绘画数据与行为数据
models.save_drawing(round_id, image_base64, drawing_time_ms)
if behavior_data:
models.save_drawing_behavior(round_id, user_id, behavior_data)
# 启动异步AI识别
_ai_guess_async(room_id, round_id, image_base64, round_info)
AI API调用阶段
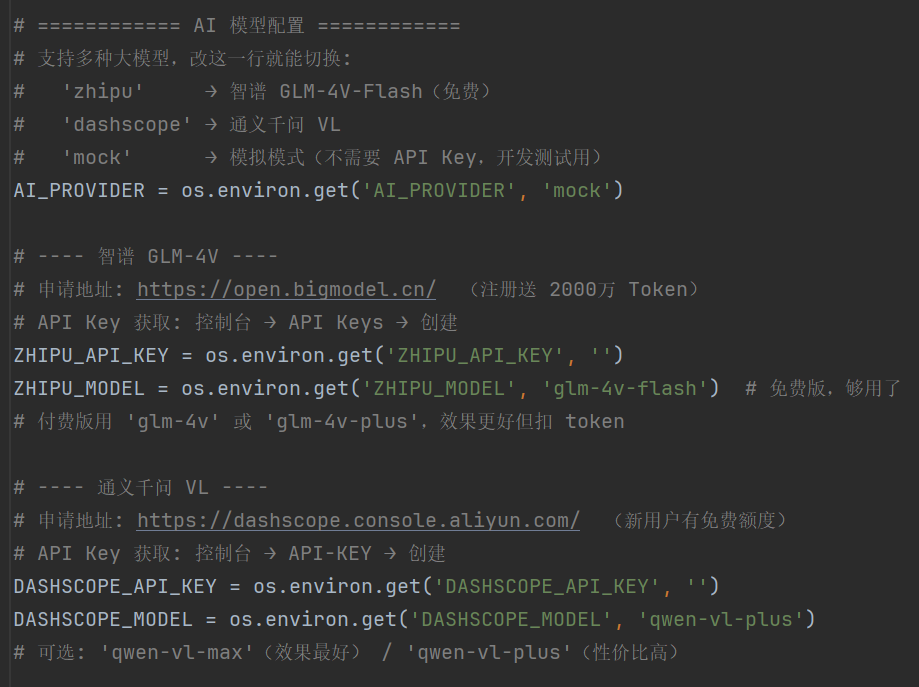
我们的AI模块支持三种模式,通过配置灵活切换:
- zhipu:智谱GLM-4V,免费版可用,适合学生项目
- dashscope:通义千问VL,性能强大
- mock:模拟模式,无需API Key,开发测试用
响应解析阶段
AI返回的结果往往带有Markdown标记或其他格式干扰,我们编写了专门的解析器来兼容各种“不听话”的输出格式,确保能提取出标准的JSON结果。
结果存储与广播
解析完成后,结果会保存到数据库,并广播ai_guess_ready事件通知前端AI已完成猜测。
AI响应时间测量
我们对AI响应时间进行了详细测量,结果如下:
| 提供商 | 网络传输 | 模型推理 | 总耗时 |
|---|---|---|---|
| 智谱 GLM-4V | 100-200ms | 800-1500ms | 900-1700ms |
| 通义千问 VL | 150-300ms | 600-1200ms | 750-1500ms |
| Mock 模式 | 0ms | 1-5ms | 1-5ms |
为了减少用户等待时间,我们采取了异步调用和超时等待(最多等3秒)的策略,确保游戏不会因AI超时而卡住。
心理报告生成测试
心理报告系统基于用户的绘画行为数据,通过规则匹配生成个性化的心理分析报告。

数据采集
前端在用户绘画过程中收集了丰富的行为数据,包括笔触数量、平均绘画速度、拐点密度(线条犹豫程度)、绘画时长、撤销次数、橡皮擦使用次数、画布覆盖率、对称性分数以及使用颜色数量等。
规则匹配引擎
我们构建了包含18条心理学规则的规则库,涵盖情绪状态、压力水平、专注度等多个维度。例如,当检测到“绘画速度快,笔触急促”时,系统会判定用户情绪较为激动或兴奋,并相应调整情绪维度的分数。
报告生成流程
系统将所有维度的基础分数设为50分,遍历规则库进行匹配并应用分数增减(限制在0-100分之间),最后结合命中的规则生成文字总结,如“你当前的情绪状态比较积极活跃,展现出较强的创造力”。
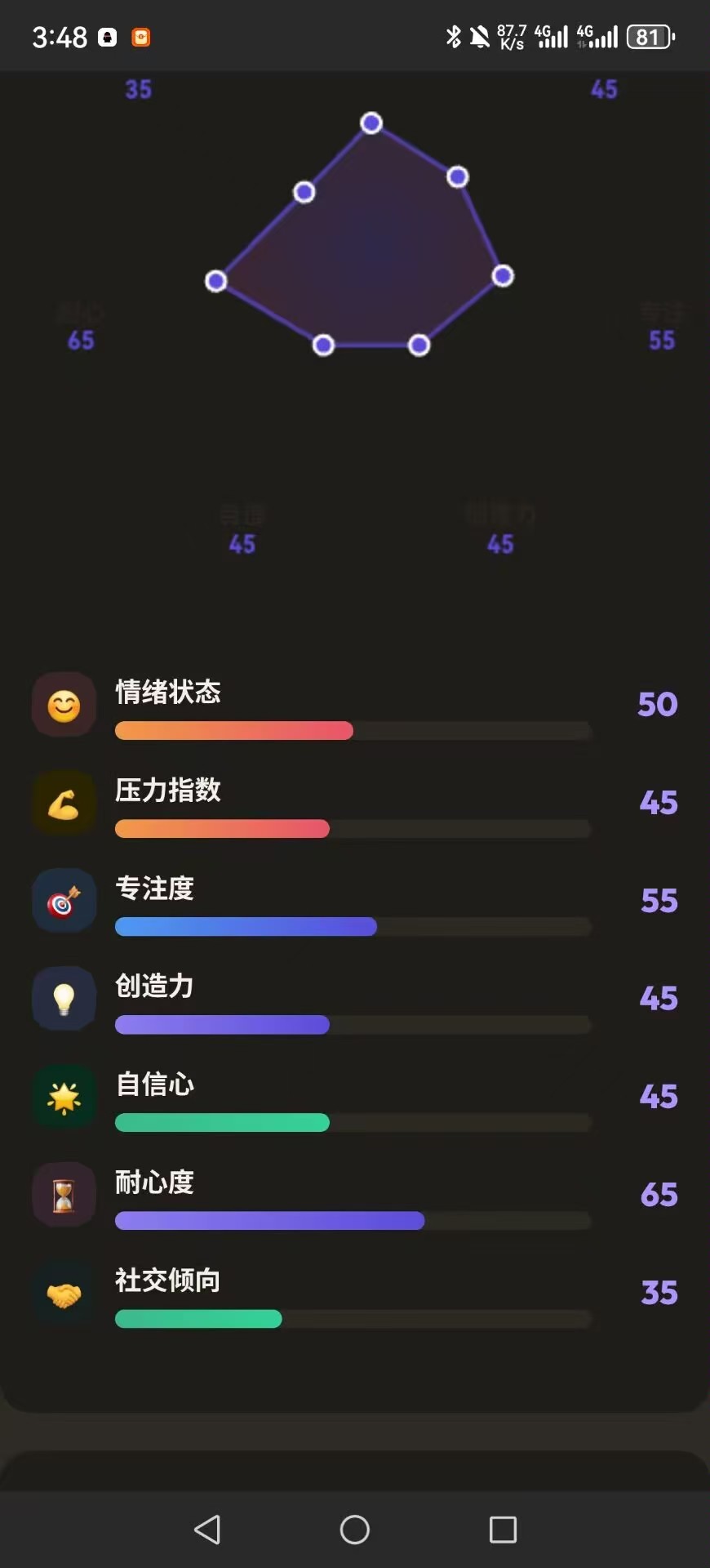
雷达图渲染验证
心理报告页面使用雷达图展示用户在各个维度的得分。我们验证了雷达图的7个维度是否能清晰展示、分数标签是否正确显示、颜色区分是否明显,以及页面在不同屏幕尺寸下的响应式布局,所有测试均顺利通过。
Mock模式与真实API模式的切换测试
为了方便开发和测试,我们在config.py中实现了灵活的模式切换机制。Mock模式可以根据难度等级返回不同置信度范围的随机猜测,在无需API Key的情况下也能完整模拟游戏流程。
测试用例表格
| 测试用例ID | 输入 | 预期结果 | 实际结果 | 测试状态 |
|---|---|---|---|---|
| TC001 | 画一个简单的太阳 | AI正确识别为“太阳” | 符合预期 | 通过 |
| TC002 | 画一个房子 | AI识别为“房子”或“建筑” | 符合预期 | 通过 |
| TC003 | 快速绘画(情绪激动) | 心理报告显示情绪分数偏高 | 符合预期 | 通过 |
| TC004 | 频繁撤销(高压力) | 心理报告显示压力分数偏高 | 符合预期 | 通过 |
| TC005 | 使用多种颜色 | 创造力分数提升 | 符合预期 | 通过 |
| TC006 | Mock模式测试 | 无需API Key正常运行 | 符合预期 | 通过 |
| TC007 | API超时测试 | 自动降级到mock模式 | 符合预期 | 通过 |
| TC008 | 多回合心理分析 | 生成综合报告 | 符合预期 | 通过 |
| TC009 | 雷达图渲染 | 7个维度正确显示 | 符合预期 | 通过 |
| TC010 | 响应时间测量 | 在预期范围内 | 符合预期 | 通过 |
总结
经过一周的联调测试,我们成功实现了从前端绘画到后端AI识别的完整流程,搭建了基于18条心理学规则的行为分析引擎,并完成了雷达图可视化与响应时间优化。现在游戏的核心功能已经全部实现,用户可以创建房间邀请好友,轮流画画和猜词,与AI进行绘画猜词对决,并获得个性化的心理分析报告。项目已经进入收尾阶段,下周我们将进行最终测试和部署准备!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)