理解重参数化
变分自编码器(Variational Autoencoder, VAE)是生成模型领域的经典基石之一。在当前多模态大模型(VLM)、视觉-语言-动作模型(VLA)以及扩散模型等前沿技术的底层逻辑中,依然能看到 VAE 核心思想的影子。
一、 VAE 的核心介绍与设计思路
普通自编码器(AE)本质上是一个数据压缩与重建的网络,它将输入 xxx 映射到潜空间(Latent Space)的一个确定性的点 zzz。这种设计的致命弱点是潜空间不连续,如果在潜空间中随机取一个点进行解码,生成的往往是无意义的噪声。
VAE 的核心设计思路是:将确定性的映射转变为概率分布的映射,从而强制潜空间变得连续且结构化。
具体的设计与推导逻辑如下:
1. 目标:最大化数据似然
生成模型的终极目标是学到真实数据的分布 p(x)p(x)p(x)。在引入潜变量 zzz 后,数据的边缘似然可以表示为:
p(x)=∫p(x∣z)p(z)dz p(x) = \int p(x|z)p(z)dz p(x)=∫p(x∣z)p(z)dz
这里的问题在于,潜空间非常庞大,这个积分是不可解的(Intractable),因此无法直接用最大似然估计来优化。
2. 变分推断(Variational Inference)
既然无法直接求真实的后验分布 p(z∣x)p(z|x)p(z∣x),VAE 引入了一个神经网络(编码器)来拟合一个近似分布 qϕ(z∣x)q_\phi(z|x)qϕ(z∣x)。
为了让 qϕ(z∣x)q_\phi(z|x)qϕ(z∣x) 尽可能逼近真实的 p(z∣x)p(z|x)p(z∣x),我们利用 KL 散度来衡量这两个分布的差异,并推导出了证据下界(ELBO, Evidence Lower Bound)。
最大化对数似然 logp(x)\log p(x)logp(x) 转化为最大化 ELBO:
ELBO=Eqϕ(z∣x)[logpθ(x∣z)]−DKL(qϕ(z∣x)∣∣p(z)) \text{ELBO} = \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] - D_{KL}(q_\phi(z|x) || p(z)) ELBO=Eqϕ(z∣x)[logpθ(x∣z)]−DKL(qϕ(z∣x)∣∣p(z))
这个公式极其优美,它直接构成了 VAE 的损失函数(Loss = -ELBO),由两部分组成:
- 重构项(Reconstruction Term): Eqϕ(z∣x)[logpθ(x∣z)]\mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)]Eqϕ(z∣x)[logpθ(x∣z)]。即解码器(Decoder),要求从潜变量重建原始数据的误差尽可能小(通常对应 MSE Loss 或 BCE Loss)。
- 正则项(Regularization Term): DKL(qϕ(z∣x)∣∣p(z))D_{KL}(q_\phi(z|x) || p(z))DKL(qϕ(z∣x)∣∣p(z))。即编码器(Encoder),强制让编码器输出的后验分布 qϕ(z∣x)q_\phi(z|x)qϕ(z∣x) 逼近我们假设的先验分布 p(z)p(z)p(z)(通常是标准正态分布 N(0,I)\mathcal{N}(0, I)N(0,I))。
3. 重参数化技巧(Reparameterization Trick)
编码器输出的是分布的参数(均值 μ\muμ 和方差 σ2\sigma^2σ2),我们需要从这个分布 N(μ,σ2)\mathcal{N}(\mu, \sigma^2)N(μ,σ2) 中采样出 zzz 给解码器。但是“采样”这个操作是不可导的,会导致梯度无法反向传播给编码器。
VAE 巧妙地设计了重参数化:
z=μ+σ⊙ϵ其中ϵ∼N(0,I) z = \mu + \sigma \odot \epsilon \quad \text{其中} \quad \epsilon \sim \mathcal{N}(0, I) z=μ+σ⊙ϵ其中ϵ∼N(0,I)
这样一来,随机性被转移到了常数 ϵ\epsilonϵ 上,梯度就可以顺利地通过 μ\muμ 和 σ\sigmaσ 回传了。
VAE核心利器:深入理解重参数化技巧 (Reparameterization Trick)
变分自编码器(Variational Autoencoder, VAE)是深度学习生成模型中的一颗明星。但许多初学者在学习其原理时,都会被一个关键概念——“重参数化技巧”——弄得云里雾里。这篇文章将用一个生动的比喻和清晰的数学解释,带你彻底搞懂它。
VAE的目标与挑战
首先,我们得明白 VAE 想做什么。与传统的自编码器(AE)不同,VAE 不仅仅是想复制输入数据,它更希望学习到一个平滑、连续的潜在空间 (Latent Space)。这样,我们就可以在这个空间中任意采样,然后通过解码器生成从未见过但又合理的新数据。
为了实现这个目标,VAE 的编码器 (Encoder) 不会直接输出一个编码向量 z,而是输出一个概率分布的参数——通常是高斯分布的均值 μ 和标准差 σ。
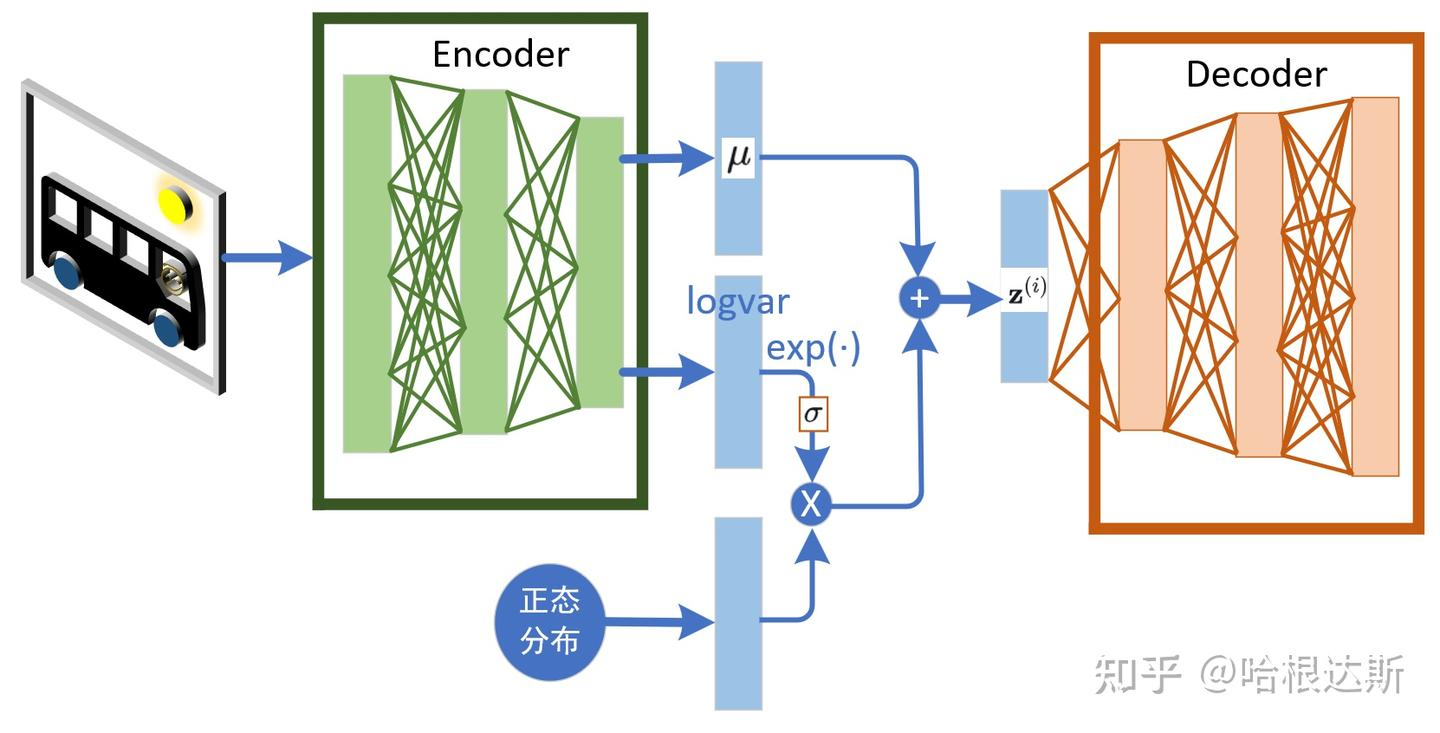
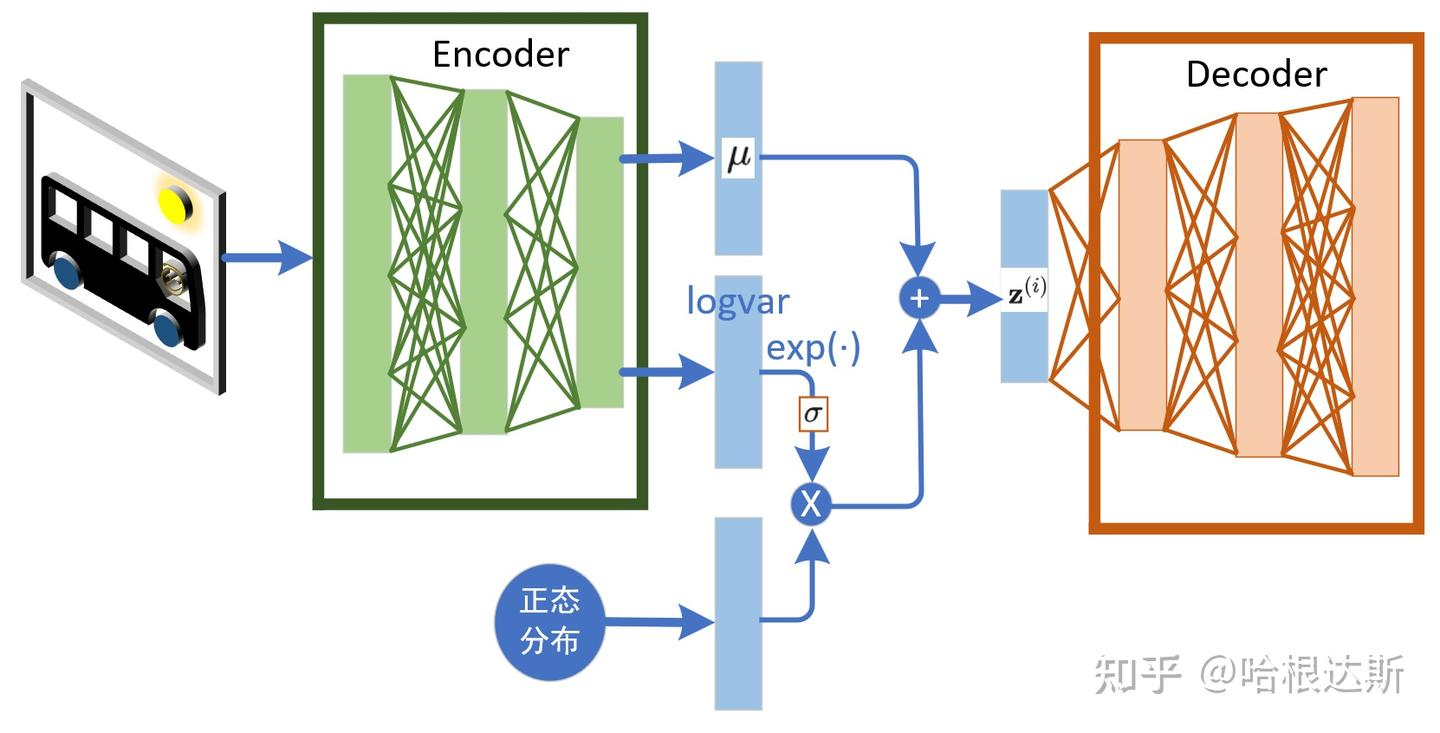
挑战来了:解码器 (Decoder) 需要从这个分布中采样一个 z 来重构图像。问题是,“采样”这个动作是随机的,它就像在神经网络中间设置了一个断点,导致梯度无法反向传播。没有梯度,就无法训练编码器。
“此路不通”:直接采样
从数学上讲,我们想要从编码器给出的分布中采样 z:
z∼N(μ,σ2I) z \sim \mathcal{N}(\mu, \sigma^2 I) z∼N(μ,σ2I)
这个过程是随机的,我们无法对一个随机事件求导。
让我们用一个比喻来理解为什么这会失败:
想象你正在训练一个助手(编码器)来指导一个蒙眼射手(解码器)射靶。
- 坏方法:你让助手告诉射手靶心所在的“大致范围”(即分布
N(μ, σ^2))。 - 射手在这个范围内随机蒙一个点射击。
- 箭射偏了。
现在你怎么改进?你无法怪罪助手,因为最终射偏可能是射手运气不好,随机选的点太偏了。助手的“指令”和最终的“结果”被这个随机选择隔断了,你无法给出明确的反馈(梯度)来让助手优化他给出的“范围”。
“柳暗花明”:重参数化技巧
为了打通这条被阻断的梯度之路,研究者们提出了一个极为巧妙的方案——重参数化技巧。
它的核心思想是:将随机性与模型参数分离开。
我们不再直接从 N(μ, σ^2) 中采样,而是换一种等价的方式来生成 z:
-
首先,从一个固定的、简单的标准正态分布中采样一个随机噪声
ε。这个过程完全独立于网络,不涉及任何需要学习的参数。
ϵ∼N(0,I) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I) -
然后,通过下面这个确定性的函数,利用编码器输出的
μ和σ来生成z:
z=μ+σ⊙ϵ z = \mu + \sigma \odot \epsilon z=μ+σ⊙ϵ
这里的⊙代表逐元素相乘。
回到我们的比喻中:
- 好方法:你改变规则,让助手提供两个明确的数字:一个“基准点”(
μ)和一个“不确定度”(σ)。 - 同时,你引入一个独立的“随机数生成器”(提供
ε)。 - 射手的最终目标点由一个固定公式算出:
目标点 = 基准点 + 不确定度 * 随机数。
现在,如果射偏了,责任链就清晰了!因为最终的目标点是通过一个明确的公式从 μ 和 σ 计算得来的。你可以明确地告诉助手:“你的基-准点偏右了”或者“你的不确定度太大了”,梯度可以顺畅地回传给助手,让他进行调整。
为什么它有效?
通过重参数化,z 仍然是一个服从分布 N(μ, σ^2) 的随机变量,但它的生成过程从一个随机采样操作变成了一个确定性计算。
- 之前:
z是一个随机节点,梯度流到这里就断了。 - 现在:随机性源于外部输入
ε,而μ和σ是网络的输出。从μ和σ到z,再到最终的损失,整个计算路径只涉及加法和乘法,完全可导。
这样,我们就可以计算损失函数关于 μ 和 σ 的梯度,并进一步将梯度反向传播,以更新编码器网络的权重。
总结
重参数化技巧是 VAE 能够成功训练的魔法棒。它通过以下方式解决了随机采样不可导的难题:
- 目标:在网络中引入可控的随机性以学习概率分布。
- 问题:直接的随机采样操作会阻断梯度反向传播。
- 解决方案:将随机性剥离为固定的外部噪声输入 (
ε),并将原有的采样过程转变为一个由网络参数 (μ,σ) 和该噪声共同参与的、可微分的确定性函数 (z = μ + σ * ε)。
正是这个技巧,使得 VAE 可以像普通神经网络一样,使用梯度下降进行端到端的优化,也成就了它在深度生成模型领域的重要地位。
面试高频问题
1. 理论推导与机制类
-
请推导一下 VAE 的损失函数(ELBO)。
-
解答关键: 从 logp(x)\log p(x)logp(x) 出发,分子分母同乘 q(z∣x)q(z|x)q(z∣x),利用 Jensen 不等式推导出下界,或者通过 logp(x)=ELBO+DKL(q(z∣x)∣∣p(z∣x))\log p(x) = \text{ELBO} + D_{KL}(q(z|x)||p(z|x))logp(x)=ELBO+DKL(q(z∣x)∣∣p(z∣x)) 来推导。
-
为什么要使用重参数化技巧(Reparameterization Trick)?如果没有它会怎样?
-
解答关键: 解释采样操作打破了计算图的连续性,导致反向传播(Backpropagation)无法计算关于 μ\muμ 和 σ\sigmaσ 的梯度。
-
VAE 训练中常遇到的后验坍塌(Posterior Collapse / KL Vanishing)是什么?怎么解决?
-
解答关键: 当解码器非常强大(例如使用了自回归模型)时,它可能会完全忽略潜变量 zzz,导致 KL 项直接降为 0,q(z∣x)q(z|x)q(z∣x) 退化为先验 p(z)p(z)p(z)。解决手段包括:KL Annealing(KL 权重退火)、Free bits(限制 KL 的最小阈值)、弱化解码器等。
2. 模型横向对比类(极其重要)
-
VAE 生成的图像为什么通常比较模糊?而 GAN 或 Diffusion 生成的更清晰?
-
解答关键: VAE 的重构损失通常基于 L2 范数(假设似然为高斯分布),这会导致模型倾向于输出所有可能结果的“平均值”,从而产生平滑、模糊的边缘。而 GAN 有对抗损失,Diffusion 有逐步去噪的过程,能更好地拟合高频细节。
-
VAE 和 VQ-VAE(Vector Quantized VAE)有什么本质区别?
-
解答关键: VAE 的潜空间是连续的高斯分布,而 VQ-VAE 的潜空间是离散的(通过查表 Codebook 实现)。VQ-VAE 解决了 VAE 潜变量空间利用率低的问题,避免了后验坍塌,并且离散的 Token 非常适合对接 Transformer 进行自回归生成(这在当前多模态音频、动作序列生成中是主流范式)。
-
Diffusion Model 和 VAE 有什么内在联系?
-
解答关键: Diffusion Model 在数学上可以看作是一个无限层级的、权重共享的马尔可夫 VAE(Hierarchical VAE)。Diffusion 的前向加噪等价于 VAE 的 Encoder,反向去噪等价于 VAE 的 Decoder,其优化的也是 ELBO(变分下界)。
3. 架构与进阶类
-
VAE 的先验分布 p(z)p(z)p(z) 一定要是标准正态分布吗?如果用其他分布会怎样?
-
解答关键: 不一定。标准正态分布是为了计算 KL 散度方便(有闭式解)。但在很多复杂任务中,单峰高斯表达能力不足。现在常用 Normalizing Flows(标准化流)或离散化的先验(如 VQ-VAE 配合 PixelCNN/Transformer)来构建更强大的先验。
-
如果把 VAE 里的 KL 散度去掉,模型会退化成什么?
-
解答关键: 会退化成普通的自编码器(AE)。潜空间会变得不再规整,不同类别的特征在潜空间中会产生割裂,导致无法通过随机采样生成有意义的新样本。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)