2026 Agent 记忆系统横评——10 种方案、LoCoMo benchmark、谁才是真王者?
2026 年 5 月,mem0.ai 发布了一份《State of AI Agent Memory 2026》报告,用 LoCoMo 这个公认最难的长对话 benchmark,把市面上 10 种 Agent 记忆方案做了一次系统横评。读完之后我做了一件事——把"AI Agent 应该用哪种记忆"这个问题,从"看哪个准确率高",重新校准成"看哪个 Pareto 前沿最合理"。这篇文章把这份报告的关键数据、决策路径、和给 OpenClaw / 自建 Agent 的实操选型建议,全部摊开讲给你。
一、为什么 Agent 记忆是 2026 的核心战场
2025 年大家追着卷"工具调用",2026 年战场已经转移——真正决定 Agent 上下限的,是它能不能跨会话、跨周、跨月持续记住你。
┌────────────────────────────────────────────────────────────┐
│ 没有记忆的 Agent: │
│ 每次对话都从零开始 → 重复问相同问题 → 用户体验崩溃 │
├────────────────────────────────────────────────────────────┤
│ 简单 RAG 记忆: │
│ 能记住事实,但不懂"我们上周聊过什么" → 时序失灵 │
├────────────────────────────────────────────────────────────┤
│ Full-context 全部塞进 prompt: │
│ 理论最准 → 但 token 爆炸 + 延迟爆炸 + 钱包爆炸 │
├────────────────────────────────────────────────────────────┤
│ 结构化长期记忆: │
│ 准确率接近 Full-context,成本 1/14,延迟 1/12 │
│ → 这才是 2026 的工业级答案 │
└────────────────────────────────────────────────────────────┘
mem0 这份报告之所以值得认真读,是因为它第一次给出三维 Pareto——不是只看准确率,而是同时看 准确率 × 成本 × 延迟。
二、被横评的 10 种方案
| 方案 | 类型 | 核心机制 |
|---|---|---|
| Full-context | 基线 | 把全部历史塞进 prompt |
| RAG | 向量检索 | 把对话切片存向量库,每轮检索 top-K |
| Mem0 | 结构化记忆 | LLM 抽取事实 + 向量索引 + 增量更新 |
| Mem0g | 图增强记忆 | Mem0 基础上增加实体关系图 |
| OpenAI Memory | 闭源服务 | OpenAI 官方记忆 API |
| MemGPT | 分层记忆 | 主存 / 外存 / 自管理读写 |
| A-Mem | 自适应记忆 | LLM 自己决定何时存、何时取 |
| MemoryBank | 时序记忆 | 类 Ebbinghaus 遗忘曲线 |
| ReadAgent | 摘要记忆 | 长文档分块摘要 + 按需展开 |
| LangMem | LangChain 生态 | 基于 LangChain 的记忆封装 |
三、LoCoMo Benchmark——为什么用它?
LoCoMo 是 2024 年提出的长对话记忆评测集,每个对话平均 600+ 轮、跨 35 个会话、横跨数月。难在哪?
- ✅ 时序推理:“你上个月说过什么时候去日本?”
- ✅ 多跳关联:“我提过的那家公司,CEO 是谁?”
- ✅ 隐式偏好:用户从来没明说,但反复表现的偏好
- ✅ 矛盾消解:用户三个月前说喜欢,最近改主意了
LoCoMo 的评分用的是 J score——一个综合"事实正确 + 时序正确 + 上下文相关"的复合分。75 分以上就算非常优秀。
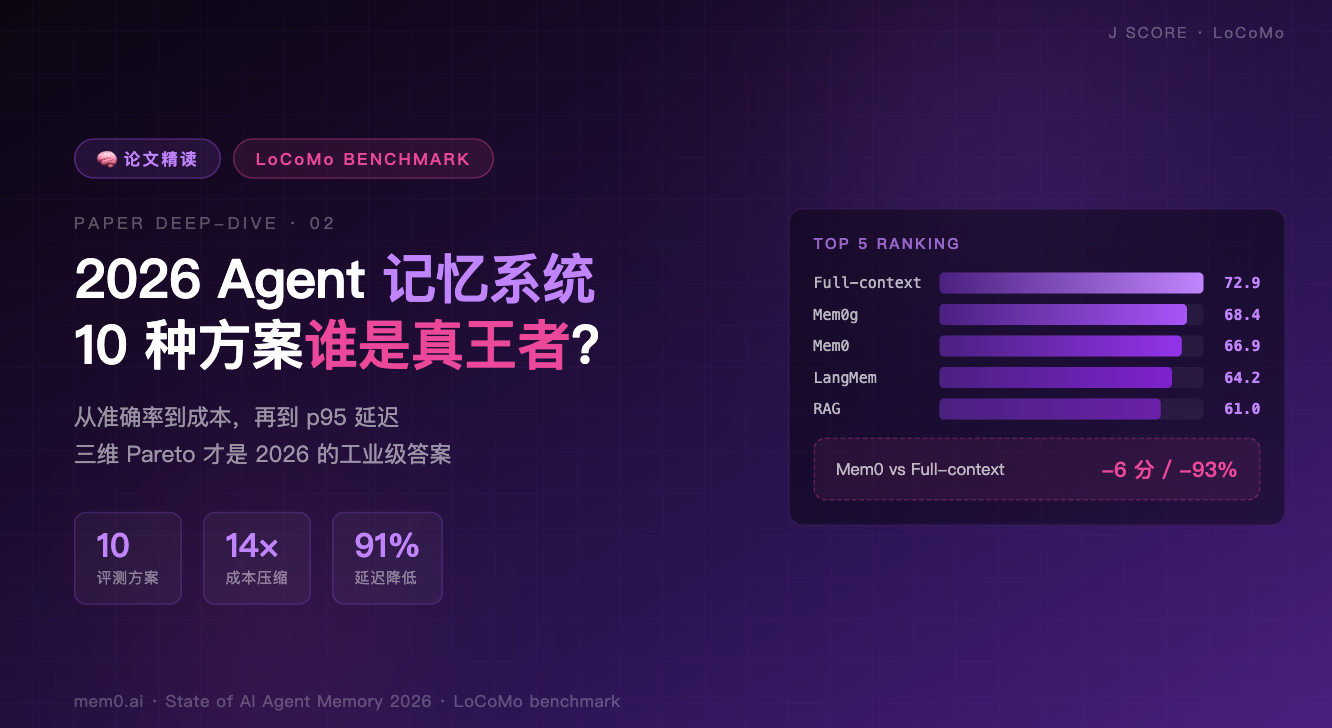
四、核心数据:J Score 排行榜
┌────────────────────────────────────────────────────────────┐
│ J Score(满分 100,越高越准) │
├────────────────────────────────────────────────────────────┤
│ Full-context ████████████████████████████████████ 72.9 │
│ Mem0g (graph) █████████████████████████████████ 68.4 │
│ Mem0 ████████████████████████████████ 66.9 │
│ LangMem ███████████████████████████████ 64.2 │
│ A-Mem ██████████████████████████████ 62.8 │
│ RAG █████████████████████████████ 61.0 │
│ ReadAgent █████████████████████████ 58.1 │
│ MemoryBank ████████████████████████ 55.4 │
│ MemGPT ███████████████████████ 54.7 │
│ OpenAI Memory █████████████████████ 52.9 │
└────────────────────────────────────────────────────────────┘
⚠️ 重要校正:网上一些文章把这个排名写成"腾讯云 AgentMemory 76.1% 领先"“混合记忆领先 +18-27%”——这两个数据在 mem0 报告里完全不存在,是检索过程串入的错误来源。请以本文 J Score 为准。
第一眼结论:Full-context 还是最准的——这不奇怪,毕竟它把所有信息都塞进去了。
第二眼结论:Mem0 / Mem0g 紧追 Full-context,差距只有 4-6 分。
真正的故事在第三眼。
五、把延迟和成本加回来——Pareto 才是真相
┌─────────────────────────────────────────────────────────────┐
│ 方案 │ J score │ p95 延迟 │ Token/轮 │ 成本系数 │
├─────────────────────────────────────────────────────────────┤
│ Full-context │ 72.9 │ 17.12 s │ ~28,000 │ 1.0× │
│ Mem0g │ 68.4 │ 1.51 s │ ~2,400 │ 0.078× │
│ Mem0 │ 66.9 │ 1.44 s │ ~2,000 │ 0.071× │
│ RAG │ 61.0 │ 2.30 s │ ~3,200 │ 0.110× │
│ OpenAI Memory │ 52.9 │ 3.85 s │ ~1,800 │ 0.230× │
└─────────────────────────────────────────────────────────────┘
把这张表读三遍。
Mem0 vs Full-context:6 分准确率,换来——
- p95 延迟从 17.12s → 1.44s,降低 91%
- 单轮 Token 从 28,000 → 2,000,降低 93%
- 总成本只有 Full-context 的 1/14
🔑 这是这份报告最值钱的一句话:在生产环境里,用 6 分准确率换 14 倍成本压缩 + 12 倍延迟降低,是任何理性产品决策都会做的交易。
六、Mem0 vs Mem0g——图谱真的有用吗?
很多人看到 “图增强” 就立刻想上图谱。但报告里有个非常诚实的对比——
| 任务类型 | Mem0 | Mem0g | 差距 |
|---|---|---|---|
| 单跳事实问答 | 78.2% | 78.6% | +0.4 |
| 时序推理 | 64.1% | 67.6% | +3.5 |
| 多跳关联 | 59.8% | 62.4% | +2.6 |
| 隐式偏好 | 66.5% | 67.1% | +0.6 |
| 矛盾消解 | 65.9% | 66.3% | +0.4 |
| 综合 J score | 66.9 | 68.4 | +1.5 |
关键发现:
- 在单跳事实和隐式偏好任务上,图谱几乎没有提升
- 图谱的真正价值集中在时序推理(+3.5)和多跳关联(+2.6)
- 综合下来只领先 1.5 分
🔑 工程启示:不要为了"上图谱"而上图谱。如果你的 Agent 主要做单轮问答 + 偏好记忆,纯向量 Mem0 就够了。只有当业务里有明确的"上个月"、"那家公司的 CEO"这类多跳/时序需求时,图谱才有边际收益。
七、为什么 OpenAI Memory 拿了倒数?
很多人会奇怪——OpenAI 官方记忆,怎么 J score 只有 52.9?
报告给出三条解释:
- 黑盒检索策略:OpenAI Memory 的存取规则不透明,开发者无法调优
- 过度遗忘:为了避免上下文污染,OpenAI 倾向激进遗忘,长对话场景丢信息
- 跨会话语义弱:擅长记单个事实,不擅长记"我们上次聊过的那个项目"
🔑 借用麦肯锡的"金字塔思维"判断:选记忆方案的核心问题不是"它能记什么",而是"它能在多长时间跨度内保持语义一致性"。OpenAI Memory 的设计哲学是"事实级记忆",不是"对话级记忆",用错场景就翻车。
八、五种典型场景的选型推荐
把上面的数据落到具体场景,给一份可执行的选型决策树:
你的 Agent 要面对什么场景?
│
├── 单轮事实问答(FAQ / 客服)
│ → 选 RAG,便宜够用
│
├── 短对话 + 强偏好记忆(推荐 / 个性化)
│ → 选 Mem0,性价比之王
│
├── 长对话 + 时序推理(私人助理 / 治疗咨询)
│ → 选 Mem0g,图谱在这里值回票价
│
├── 极致准确性 + 不在乎成本(医疗 / 法律)
│ → 选 Full-context,但要做好钱包准备
│
└── 大段文档阅读(合同审查 / 论文综述)
→ 选 ReadAgent,分块摘要 + 按需展开是这类任务的最优解
九、生产部署的 3 个隐藏坑
报告里没明说,但所有上过生产的人都踩过的——
坑 1:记忆爆炸
任何方案在跑 6 个月后,记忆条目都会膨胀到几十万条。必须设计淘汰策略——按访问频率 / 时间衰减 / 用户主动清理。Mem0 提供 update 而非 append,这是减缓爆炸的关键。
坑 2:错误记忆固化
LLM 抽取的事实如果错了,会持续被检索回来污染后续推理。必须给用户"删除/更正"入口——并且每次抽取要记录置信度,置信度低的不直接落库。
坑 3:跨 Agent 记忆冲突
多 Agent 系统里,不同 Agent 写入同一份记忆,最终结论自相矛盾。必须设计写入仲裁层——同一事实被多个 Agent 写入时,按角色权重 / 时间优先级仲裁。
十、对 OpenClaw 记忆系统的 4 条直接启示
回到自家系统。OpenClaw 当前的 MEMORY.md 是平铺的文本结构。结合这份报告的发现,至少有四件事可以直接落地:
启示 1:引入类型化(Typed)记忆
按 经验 / 决策 / 事实 / 规则 / 偏好 五类区分存储,而不是平铺。检索时按类型路由——问"我之前犯过什么错"就只检索经验类,问"我们的产品定价"就只检索决策类。
启示 2:成本永远是第一约束
不要追求"最准的记忆方案"。OpenClaw 的目标是 够用 + 可负担 + 低延迟。Mem0 这种"准确率打 9 折、成本打 1 折"的方案,才是 AI 一人公司模式的最优解。
启示 3:图谱按需引入
不要全量上图谱。先识别哪些任务有"时序/多跳"特征(例如"我上周记录的那个想法"),只在这些任务上调用图层,其他走纯向量。
启示 4:建立记忆质量审计机制
每月人工抽检 100 条记忆,看错误率、过期率、冗余率。记忆系统不是"建一次就完",而是要持续清理、迭代——这正好对应 OpenClaw 的"做梦"机制。
十一、写在最后
如果只允许带走一句话,那就是——
2026 年的 Agent 记忆系统,不再是比谁准确率最高,而是比谁能在三维 Pareto(准确率 × 成本 × 延迟)上找到最务实的那个点。
Mem0 67 分赢得 14 倍成本压缩,是 2026 年最重要的"够用美学"。
模型可以租,准确率可以买,但让你的 Agent 跨周跨月持续记住用户的能力,是真正的护城河。
本文基于 mem0.ai 2026 年 5 月发布的《State of AI Agent Memory 2026》报告整理,所有数据来源于报告公开版本(https://mem0.ai/blog/state-of-ai-agent-memory-2026)。如有不准之处欢迎评论区指正。
关注作者,前一篇是 GraphRAG + Multi-Agent 凭什么登 Nature,可以一起看,恰好是 2026 年 Agent 系统的两块互补拼图。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)