论文阅读LoRA: Low-Rank Adaptation of Large Language Models
一、论文信息
论文题目:LoRA: Low-Rank Adaptation of Large Language Models
论文作者:Edward Hu∗ ,Yelong Shen∗, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang ,Weizhu Chen
代码链接:https://github.com/microsoft/LoRA
论文期刊:arXiv
二、论文主要贡献
LoRA(Low-Rank Adaptation)是一种用于高效微调大规模预训练语言模型的新方法。随着模型规模不断增长,如 GPT-3 级别的超大模型在多个下游任务上的应用需求越来越高,但传统的全参数微调方式不仅计算成本巨大,还需要为每个任务保存一套完整模型,导致存储与部署开销极高。LoRA 针对这一痛点提出了一个关键观点:大型模型在适配下游任务时,其权重更新往往存在“低秩特性”,也就是说,模型的有效更新方向远低于其原始参数维度。基于这一观察,LoRA 将预训练模型的原始权重完全冻结,不再对其进行梯度更新,而是在模型需要适配的位置(尤其是 Transformer 的注意力投影矩阵如 Wq、Wv 中)注入一个低秩矩阵分解形式的可训练模型。
这一设计带来了多重优势:
(1)极大减少可训练参数量 —— 在 GPT-3 175B 参数模型上,传统微调需要更新全部参数;而 LoRA 只需更新百万级甚至更低规模参数即可实现相当甚至更好的效果。
(2)训练效率显著提高 —— 因为原始权重被冻结,优化器状态、梯度存储等开销减少,使得在同样 GPU 设备上能够训练更大的模型或更大的 batch。
(3)在多项自然语言处理任务中的表现优于或匹配全参数微调 —— 包括语义匹配、文本生成、问答等任务。在许多任务上,LoRA 在节省巨大开销的同时依然能保持甚至超越 full fine-tuning 的验证得分。
三、论文创新点
1.发现并提出“大模型微调具有低秩结构”的关键假设(理论创新)
论文指出:大型预训练模型在下游任务微调时,其权重更新 ΔW 的秩远低于原始权重矩阵。 这是 LoRA 的基础理论:任务相关的变化只存在于一个小的低维子空间。
2. 设计了低秩分解形式的可训练参数化:ΔW = BA(方法创新)
论文提出把原本庞大的权重更新矩阵替换为低秩结构:ΔW = BA,r≪d。冻结原模型权重,只训练小规模的 A 与 B。
max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 log ( p Φ ( y t ∣ x , y < t ) ) \max_{\Phi}\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}\log\left(p_{\Phi}(y_{t}|x,y_{<t})\right) Φmax(x,y)∈Z∑t=1∑log(pΦ(yt∣x,y<t))完全微调的主要缺点之一是,对于每个下游任务,我们会学习一组不同的参数∆Φ,其维度为|∆Φ|等于 |Φ|。因此,如果预训练模型规模较大(如 GPT-3 的 |Φ| ≈ 1750 亿),存储和部署多个独立的微调模型实例可能会很有挑战性,尽管这几乎不可能
3.提出“模块化、可组合”的微调框架(系统创新)
LoRA 不改变原模型拓扑结构:
(1)不占用输入长度(区别于 Prefix)
(2)不插入新层(区别于 Adapter)
(3)可与其他微调技术组合(FT, Prompt, Prefix, Adapter 等)
LoRA 被设计为可插拔模块(plug-in module),具有普适性和通用性。
四、方法

对于线性层收重 W 0 , LoRA 不直接更新权重,而是学习低秩更新 : W = W 0 + a B A \text{对于线性层收重}W_0,\text{ LoRA 不直接更新权重,而是学习低秩更新}:W=W_0+aBA 对于线性层收重W0, LoRA 不直接更新权重,而是学习低秩更新:W=W0+aBA
我们对 A 使用随机高斯初始化,B 为零,因此训练开始时∆W = BA 为零
五、实验分析
不同调整方法在GPT-2和GPT-3上表现的效果
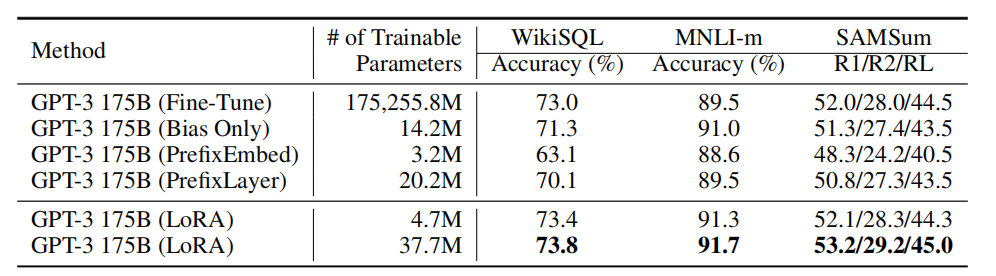

LoRA在微调GPT-2和GPT-3中均表现出优良的性能
在这两个任务中,LoRA 是更稳定、高效的参数微调方法—— 无论可训练参数规模如何变化,它的准确率都能保持在较高水平。
WikiSQL 任务中,Wq,Wv(r=4)的性能远高于单独Wq(r=8),说明组合权重做低秩分解的效果更好
1.WikiSQL 的Wq,Wv:r=8时性能最,r=64反而下降,说明秩并非越大性能越好,存在最优秩范围;
2.MultiNLI 的Wq,Wv:r=8时性能达到峰值,验证了 “中等秩(而非最大秩)更优” 的规律;
3.Wq单独低秩时,r=4的性能略高于r=8,说明部分权重用更小的秩即可保留性能。
∆W代表 “低秩分解后权重与原权重的变化量”,该图展示不同维度上权重变化的大小分布。
1.左图(大维度区间):低维度(如 x=1)的∆W更大(颜色浅),高维度(如 x=58)∆W更小(颜色深),说明低秩分解对权重的低维度影响更显著
2.右图(1-8 小维度):∆W的分布更均匀,说明小维度范围内权重变化的差异更小。
1.左上角颜色浅(关联强)、右下角颜色深(关联弱),说明权重变化存在结构化的维度关联;
随机高斯矩阵的热力图:几乎全黑(关联接近 0),验证了 “权重变化的关联是模型学到的结构化模式,而非随机噪声”。
六、个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)