Unitree_RL_ Lab 项目:项目技术解析+复现+功能拓展优化
Unitree RL Lab 项目:项目技术解析+复现+功能拓展优化
一、项目技术解析
1. 项目概述
1.1 项目简介
Unitree RL Lab 是由宇树科技(Unitree Robotics)开源的强化学习机器人控制项目,基于 NVIDIA Isaac Lab 框架构建。该项目为宇树系列机器人提供了一套完整的强化学习训练与部署流程,实现了从仿真训练(Isaac Sim)到仿真验证(MuJoCo)再到真实机器人部署(Sim2Real)的全链路闭环。
1.2 核心特性
- 多机器人支持:支持 Go2、Go2W、B2(四足机器人)、G1-23dof、G1-29dof、H1、H1-2(人形机器人)共 7 款宇树机器人
- 双任务范式:支持 Locomotion(速度跟踪运动) 和 Mimic(动作模仿) 两种核心任务
- 完整部署链路:训练 → ONNX 导出 → C++ 部署 → 真实机器人控制
- 高保真仿真:基于 Isaac Sim 5.0.0 + Isaac Lab 2.2.0,支持 4096 并行环境
- 域随机化:物理材质、质量、关节默认位置、质心、外力扰动等多维度随机化
1.3 技术栈
| 类别 | 技术 |
|---|---|
| 仿真平台 | NVIDIA Isaac Sim 5.0.0 / Isaac Lab 2.2.0 |
| RL 算法库 | RSL-RL(PPO) |
| 深度学习 | PyTorch(CUDA 加速) |
| 模型导出 | ONNX Runtime |
| 部署语言 | C++17 |
| 机器人通信 | Unitree SDK2(DDS) |
| 构建系统 | CMake / setuptools |
| 配置管理 | YAML / dataclass |
2. 项目文件结构
unitree_rl_lab/
├── source/unitree_rl_lab/ # Python 训练源码
│ └── unitree_rl_lab/
│ ├── assets/robots/ # 机器人资产配置
│ │ ├── unitree.py # 机器人 Articulation 配置
│ │ └── unitree_actuators.py # 执行器模型(含 T-N 曲线)
│ ├── tasks/ # 任务定义
│ │ ├── locomotion/ # 速度跟踪运动任务
│ │ │ ├── agents/ # PPO 算法配置
│ │ │ ├── mdp/ # MDP 组件
│ │ │ │ ├── observations.py # 步态相位观测
│ │ │ │ ├── rewards.py # 奖励函数
│ │ │ │ ├── curriculums.py # 课程学习
│ │ │ │ └── commands/ # 速度命令
│ │ │ └── robots/ # 各机器人环境配置
│ │ │ ├── go2/
│ │ │ ├── g1/29dof/
│ │ │ └── h1/
│ │ └── mimic/ # 动作模仿任务
│ │ ├── agents/ # PPO 算法配置
│ │ ├── mdp/ # MDP 组件
│ │ │ ├── commands.py # 运动命令(MotionCommand)
│ │ │ ├── observations.py # 模仿观测
│ │ │ ├── rewards.py # 模仿奖励
│ │ │ ├── events.py # 域随机化事件
│ │ │ └── terminations.py # 终止条件
│ │ └── robots/g1_29dof/ # G1 舞蹈追踪
│ └── utils/ # 工具函数
│ ├── export_deploy_cfg.py # 部署配置导出
│ └── parser_cfg.py # 环境配置解析
├── deploy/ # C++ 部署代码
│ ├── include/ # 头文件
│ │ ├── FSM/ # 有限状态机
│ │ ├── isaaclab/ # C++ 版 IsaacLab 推理框架
│ │ │ ├── algorithms/ # ONNX 推理引擎
│ │ │ ├── assets/ # 关节接口
│ │ │ ├── envs/ # 环境管理
│ │ │ ├── manager/ # 观测/动作管理器
│ │ │ └── utils/ # 工具函数
│ │ ├── LinearInterpolator.h # 线性插值器
│ │ ├── param.h # 参数/配置加载
│ │ └── unitree_articulation.h # 机器人关节接口
│ ├── robots/ # 各机器人部署程序
│ │ ├── go2/ # Go2 四足
│ │ ├── g1_29dof/ # G1-29dof 人形
│ │ ├── h1/ # H1 人形
│ │ └── ... # 其他机器人
│ └── thirdparty/ # 第三方库(ONNX Runtime)
├── scripts/ # 训练/推理脚本
│ ├── rsl_rl/ # RSL-RL 训练脚本
│ │ ├── train.py # 训练入口
│ │ ├── play.py # 推理入口
│ │ └── cli_args.py # 命令行参数
│ └── mimic/ # 模仿学习脚本
│ ├── csv_to_npz.py # 运动数据转换
│ └── replay_npz.py # 运动回放
├── docker/ # Docker 配置
└── doc/ # 许可证文件
3. 技术架构
3.1 整体架构
项目采用 "训练-部署"分离 的架构设计:
┌──────────────────────────────────────────────────────┐
│ 训练侧 (Python) │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ Isaac Sim│ │ RSL-RL │ │ 环境配置(MDP) │ │
│ │ 仿真器 │←→│ PPO训练 │←→│ 观测/奖励/动作 │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ 4096并行 │ │ ONNX导出 │ │
│ │ 环境 │ │ deploy.yaml│ │
│ └──────────┘ └──────────┘ │
└──────────────────────┬───────────────────────────────┘
│
┌────────▼────────┐
│ Sim2Sim 验证 │
│ (MuJoCo) │
└────────┬────────┘
│
┌──────────────────────▼───────────────────────────────┐
│ 部署侧 (C++) │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │ ONNX │ │ FSM │ │ Unitree SDK2 │ │
│ │ Runtime │→│ 状态机 │→│ 机器人通信 │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
└──────────────────────────────────────────────────────┘
3.2 训练流程
训练流程的核心入口为 train.py,其执行流程如下:
- 解析命令行参数:任务名、环境数、GPU 设备、种子等
- 启动 Isaac Sim:通过
AppLauncher初始化仿真器 - 创建环境:
gym.make(task_name, cfg=env_cfg)创建 MDP 环境 - 包装环境:
RslRlVecEnvWrapper将 Isaac Lab 环境适配为 RSL-RL 接口 - 创建训练器:
OnPolicyRunner管理训练循环 - 导出部署配置:
export_deploy_cfg()生成deploy.yaml - 训练循环:
runner.learn()执行 PPO 训练
3.3 推理与导出流程
推理入口为 play.py:
- 加载训练好的 checkpoint
- 获取推理策略
runner.get_inference_policy() - 导出为 ONNX 格式:
export_policy_as_onnx()生成policy.onnx - 导出为 JIT 格式:
export_policy_as_jit()生成policy.pt - 在仿真环境中运行推理循环
3.4 部署架构
部署侧采用 有限状态机(FSM) 架构,核心组件:
| 组件 | 文件 | 功能 |
|---|---|---|
| CtrlFSM | CtrlFSM.h | 状态机控制器,1kHz 循环检测状态切换 |
| State_Passive | - | 被动状态,关节阻尼保持 |
| State_FixStand | - | 站立状态,PD 控制到目标姿态 |
| State_RLBase | State_RLBase.h | RL 推理状态,独立线程运行策略 |
| State_Mimic | State_Mimic.cpp | 动作模仿状态,同步运动数据 |
| ManagerBasedRLEnv | manager_based_rl_env.h | C++ 版环境管理器 |
| OrtRunner | algorithms.h | ONNX Runtime 推理引擎 |
状态转换流程(以 G1-29dof 为例):
Passive ──[L2+Up]──→ FixStand ──[R1+X]──→ Velocity(RL)
↑ │ │
│ │ [LT(2s)+Down] [LT(2s)+Left]
│ │ ↓ ↓
└────[LT+B]─────────┘ Mimic_Dance_102 Mimic_Gangnam
4. 核心功能模块
4.1 Locomotion(速度跟踪运动)
Locomotion 任务的目标是训练机器人跟踪给定的速度指令(线速度 v x v_x vx, v y v_y vy 和角速度 ω z \omega_z ωz),实现稳定的运动控制。
4.1.1 观测空间
策略观测(Policy)——部署时可用:
| 观测项 | 函数 | 维度 | 缩放 | 噪声 |
|---|---|---|---|---|
| 基座角速度 | base_ang_vel |
3 | ×0.2 | ±0.2 |
| 投影重力 | projected_gravity |
3 | - | ±0.05 |
| 速度指令 | generated_commands |
3 | - | - |
| 关节相对位置 | joint_pos_rel |
N | - | ±0.01 |
| 关节相对速度 | joint_vel_rel |
N | ×0.05 | ±1.5 |
| 上一步动作 | last_action |
N | - | - |
| 步态相位 | gait_phase(H1) |
2 | - | - |
其中 N 为机器人关节数。G1-29dof 支持观测历史(
history_length=5),H1 包含步态相位编码。
评论家观测(Critic)——训练时特权信息:
额外包含:基座线速度 base_lin_vel、关节力矩 joint_effort(缩放 ×0.01),以及可选的高度扫描 height_scanner。
4.1.2 动作空间
采用 关节位置目标 控制模式:
JointPositionAction = mdp.JointPositionActionCfg(
asset_name="robot",
joint_names=[".*"],
scale=0.25, # 动作缩放因子
use_default_offset=True, # 以默认关节位置为偏移
)
最终关节目标位置计算公式:
q t a r g e t = q d e f a u l t + 0.25 × a q_{target} = q_{default} + 0.25 \times a qtarget=qdefault+0.25×a
其中 a ∈ R N a \in \mathbb{R}^N a∈RN 为策略网络输出的动作向量, q d e f a u l t q_{default} qdefault 为默认关节角度。
4.1.3 奖励函数设计
奖励函数采用 加权和 形式,分为任务奖励和正则化奖励两大类:
任务奖励(正向):
| 奖励项 | 公式 | 权重 |
|---|---|---|
| 线速度跟踪 | r = exp ( − ∣ v x y c m d − v x y ∣ 2 σ 2 ) r = \exp\left(-\frac{|v_{xy}^{cmd} - v_{xy}|^2}{\sigma^2}\right) r=exp(−σ2∣vxycmd−vxy∣2) | 1.0~1.5 |
| 角速度跟踪 | r = exp ( − ( ω z c m d − ω z ) 2 σ 2 ) r = \exp\left(-\frac{(\omega_z^{cmd} - \omega_z)^2}{\sigma^2}\right) r=exp(−σ2(ωzcmd−ωz)2) | 0.5~0.75 |
| 存活奖励 | r = 1 r = 1 r=1 | 0.15 |
| 步态奖励 | r = ∑ i ¬ ( is_stance i ⊕ is_contact i ) r = \sum_i \neg(\text{is\_stance}_i \oplus \text{is\_contact}_i) r=∑i¬(is_stancei⊕is_contacti) | 0.5 |
| 足部离地 | r = exp ( − ∑ ( z f o o t − h t a r g e t ) 2 ⋅ tanh ( k ⋅ ∣ v x y ∣ ) σ 2 ) r = \exp\left(-\frac{\sum (z_{foot} - h_{target})^2 \cdot \tanh(k \cdot |v_{xy}|)}{\sigma^2}\right) r=exp(−σ2∑(zfoot−htarget)2⋅tanh(k⋅∣vxy∣)) | 1.0~20.0 |
其中 σ 2 = 0.25 \sigma^2 = 0.25 σ2=0.25, ⊕ \oplus ⊕ 表示异或操作。
正则化奖励(负向惩罚):
| 奖励项 | 公式 | 权重 |
|---|---|---|
| Z轴线速度 | r = − v z 2 r = -v_z^2 r=−vz2 | -2.0 |
| XY角速度 | r = − ∣ ω x y ∣ 2 r = -|\omega_{xy}|^2 r=−∣ωxy∣2 | -0.05~-0.5 |
| 关节速度 | r = − ∣ q ˙ ∣ 2 r = -|\dot{q}|^2 r=−∣q˙∣2 | -0.001 |
| 关节加速度 | r = − ∣ q ¨ ∣ 2 r = -|\ddot{q}|^2 r=−∣q¨∣2 | -2.5e-7 |
| 动作变化率 | r = − ∣ a t − a t − 1 ∣ 2 r = -|a_t - a_{t-1}|^2 r=−∣at−at−1∣2 | -0.05~-0.1 |
| 关节位置限制 | r = − penalty ( q → limit ) r = -\text{penalty}(q \to \text{limit}) r=−penalty(q→limit) | -5.0~-10.0 |
| 能量消耗 | $r = -\sum | \dot{q}_i |
| 姿态倾斜 | r = − ( 1 − g z ) 2 r = -(1 - g_z)^2 r=−(1−gz)2 | -1.0~-5.0 |
| 基座高度 | r = − ( h − h t a r g e t ) 2 r = -(h - h_{target})^2 r=−(h−htarget)2 | -10.0 |
| 关节偏差(手臂/腰部/髋部) | r = − ∣ q − q d e f a u l t ∣ 1 r = -|q - q_{default}|_1 r=−∣q−qdefault∣1 | -0.1~-1.0 |
| 足部滑动 | r = − sliding_penalty r = -\text{sliding\_penalty} r=−sliding_penalty | -0.1~-0.2 |
| 非期望接触 | r = − contact_penalty r = -\text{contact\_penalty} r=−contact_penalty | -1.0 |
4.1.4 终止条件
| 条件 | 说明 |
|---|---|
time_out |
达到最大 episode 时长(20s) |
bad_orientation |
基座倾斜角超过阈值( cos − 1 ( g z ) > 0.8 \cos^{-1}(g_z) > 0.8 cos−1(gz)>0.8 rad ≈ 45.8°) |
base_contact |
基座接触地面(四足机器人) |
base_height |
基座高度低于最小值(人形机器人:0.2~0.3m) |
4.1.5 课程学习
项目实现了两级课程学习:
- 地形课程:
terrain_levels_vel— 随训练进展逐步增加地形难度 - 速度课程:
lin_vel_cmd_levels/ang_vel_cmd_levels— 逐步扩大速度指令范围
速度课程的核心逻辑:当跟踪奖励超过权重 × 0.8 时,将速度范围扩大 ±0.1:
if reward > reward_term.weight * 0.8:
ranges.lin_vel_x = clamp(ranges + [-0.1, 0.1], limit_ranges)
4.1.6 域随机化
| 随机化项 | 模式 | 参数范围 |
|---|---|---|
| 摩擦系数 | startup | 静摩擦 [0.3, 1.0~1.2],动摩擦 [0.3, 1.0~1.2] |
| 恢复系数 | startup | [0.0, 0.0~0.15] |
| 基座质量 | startup | 加载 [-1.0, 3.0] kg |
| 基座位置 | reset | x,y ∈ [-0.5, 0.5],yaw ∈ [-π, π] |
| 关节位置 | reset | 缩放 [1.0, 1.0],速度 [-1.0, 1.0] |
| 推力扰动 | interval | 5~10s 间隔,速度 ±0.5 m/s |
4.2 Mimic(动作模仿)
Mimic 任务的目标是训练机器人模仿参考运动轨迹(如舞蹈动作),实现全身运动跟踪。
4.2.1 运动数据管线
BVH 动捕数据 (.csv)
│
▼ csv_to_npz.py(Isaac Sim 中重定向)
运动数据 (.npz)
│ 包含:joint_pos, joint_vel, body_pos_w, body_quat_w,
│ body_lin_vel_w, body_ang_vel_w
▼
MotionCommand(训练时实时采样)
│
▼ 线性插值
MotionLoader_(部署时 CSV 回放)
csv_to_npz.py 的核心流程:
- 加载 CSV 格式的动捕数据(基座位置/旋转 + 关节角度)
- 将输入帧率重采样到输出帧率(默认 50fps),使用 线性插值(LERP) 和 球面线性插值(SLERP)
- 通过数值微分计算速度:线速度 d p d t \frac{d\mathbf{p}}{dt} dtdp、关节速度 d q d t \frac{dq}{dt} dtdq、角速度 d R d t → ω \frac{d\mathbf{R}}{dt} \to \omega dtdR→ω
- 在 Isaac Sim 中重定向到机器人骨骼,记录所有刚体的位姿和速度
- 保存为
.npz格式
4.2.2 MotionCommand 自适应采样
MotionCommand 是 Mimic 任务的核心组件,实现了 自适应运动采样 策略:
基本原理:将运动序列按时间分箱(bin),统计每个 bin 的失败频率,优先采样失败率高的时间段。
采样概率计算:
P ( i ) = ( f i + u K ) ∗ h ∑ j ( f j + u K ) ∗ h P(i) = \frac{(f_i + \frac{u}{K}) * h}{\sum_j (f_j + \frac{u}{K}) * h} P(i)=∑j(fj+Ku)∗h(fi+Ku)∗h
其中:
- f i f_i fi 为 bin i i i 的指数移动平均失败率
- u u u 为均匀采样比例(默认 0.1)
- K K K 为总 bin 数
- h h h 为卷积核 h [ k ] = λ k / ∑ λ k h[k] = \lambda^k / \sum \lambda^k h[k]=λk/∑λk( λ = 0.8 \lambda = 0.8 λ=0.8)
失败率更新(指数移动平均):
f i n e w = α ⋅ c i + ( 1 − α ) ⋅ f i o l d f_i^{new} = \alpha \cdot c_i + (1 - \alpha) \cdot f_i^{old} finew=α⋅ci+(1−α)⋅fiold
其中 α = 0.001 \alpha = 0.001 α=0.001, c i c_i ci 为当前 episode 在 bin i i i 的失败计数。
采样指标:
- 采样熵 H n o r m = − ∑ P ( i ) log P ( i ) / log K H_{norm} = -\sum P(i) \log P(i) / \log K Hnorm=−∑P(i)logP(i)/logK(衡量采样均匀性)
- Top-1 概率和 Top-1 bin 位置
4.2.3 Mimic 观测空间
策略观测:
| 观测项 | 函数 | 说明 |
|---|---|---|
| 运动指令 | generated_commands |
参考关节位置 + 速度 |
| 参考锚点朝向 | motion_anchor_ori_b |
参考躯干朝向(body frame) |
| 基座角速度 | base_ang_vel |
机器人角速度 |
| 关节相对位置 | joint_pos_rel |
当前关节位置 |
| 关节相对速度 | joint_vel_rel |
当前关节速度 |
| 上一步动作 | last_action |
前一步动作 |
特权观测(Critic):
额外包含:参考锚点位置 motion_anchor_pos_b、参考锚点朝向 motion_anchor_ori_b、机器人身体位置 robot_body_pos_b、机器人身体朝向 robot_body_ori_b、基座线速度 base_lin_vel。
4.2.4 Mimic 奖励函数
所有跟踪奖励均采用 指数核 形式:
r = exp ( − e 2 σ 2 ) r = \exp\left(-\frac{e^2}{\sigma^2}\right) r=exp(−σ2e2)
| 奖励项 | 误差 e e e | σ \sigma σ | 权重 |
|---|---|---|---|
| 锚点位置 | ∣ p a n c h o r r e f − p a n c h o r r o b o t ∣ 2 |\mathbf{p}_{anchor}^{ref} - \mathbf{p}_{anchor}^{robot}|^2 ∣panchorref−panchorrobot∣2 | 0.3 | 0.5 |
| 锚点朝向 | ∣ q a n c h o r r e f ⊖ q a n c h o r r o b o t ∣ 2 |q_{anchor}^{ref} \ominus q_{anchor}^{robot}|^2 ∣qanchorref⊖qanchorrobot∣2 | 0.4 | 0.5 |
| 身体位置 | ∣ p b o d y r e f − p b o d y r o b o t ∣ 2 |\mathbf{p}_{body}^{ref} - \mathbf{p}_{body}^{robot}|^2 ∣pbodyref−pbodyrobot∣2 | 0.3 | 1.0 |
| 身体朝向 | ∣ q b o d y r e f ⊖ q b o d y r o b o t ∣ 2 |q_{body}^{ref} \ominus q_{body}^{robot}|^2 ∣qbodyref⊖qbodyrobot∣2 | 0.4 | 1.0 |
| 身体线速度 | ∣ v b o d y r e f − v b o d y r o b o t ∣ 2 |\mathbf{v}_{body}^{ref} - \mathbf{v}_{body}^{robot}|^2 ∣vbodyref−vbodyrobot∣2 | 1.0 | 1.0 |
| 身体角速度 | ∣ ω b o d y r e f − ω b o d y r o b o t ∣ 2 |\omega_{body}^{ref} - \omega_{body}^{robot}|^2 ∣ωbodyref−ωbodyrobot∣2 | 3.14 | 1.0 |
正则化项:关节加速度(-2.5e-7)、关节力矩(-1e-5)、动作变化率(-0.1)、关节限制(-10.0)、非期望接触(-0.1)。
4.2.5 Mimic 域随机化
额外包含:
- 关节默认位置随机化:
randomize_joint_default_pos,偏移 ±0.01 rad - 质心随机化:
randomize_rigid_body_com,偏移 x∈[-0.025, 0.025],y∈[-0.05, 0.05],z∈[-0.05, 0.05] - 更频繁的推力扰动:1~3 秒间隔
5. 算法原理与数学公式
5.1 PPO 算法
项目使用 Proximal Policy Optimization (PPO) 算法,由 RSL-RL 库实现。
5.1.1 网络结构
Actor (策略网络): obs → [512] → ELU → [256] → ELU → [128] → ELU → action
Critic (价值网络): obs → [512] → ELU → [256] → ELU → [128] → ELU → value
初始标准差 σ 0 = 1.0 \sigma_0 = 1.0 σ0=1.0,采用可学习的对数标准差参数化。
5.1.2 PPO 核心公式
优势函数估计(GAE):
A ^ t = ∑ l = 0 T − t − 1 ( γ λ ) l δ t + l \hat{A}_t = \sum_{l=0}^{T-t-1} (\gamma \lambda)^l \delta_{t+l} A^t=l=0∑T−t−1(γλ)lδt+l
其中 TD 误差:
δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)
参数: γ = 0.99 \gamma = 0.99 γ=0.99, λ = 0.95 \lambda = 0.95 λ=0.95。
策略目标函数:
L C L I P ( θ ) = E ^ t [ min ( ρ t ( θ ) A ^ t , clip ( ρ t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \hat{\mathbb{E}}_t \left[ \min\left( \rho_t(\theta) \hat{A}_t, \, \text{clip}(\rho_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right] LCLIP(θ)=E^t[min(ρt(θ)A^t,clip(ρt(θ),1−ϵ,1+ϵ)A^t)]
其中重要性采样比:
ρ t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) \rho_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)} ρt(θ)=πθold(at∣st)πθ(at∣st)
裁剪参数 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2。
价值函数损失:
L V F ( θ ) = E ^ t [ ( V θ ( s t ) − V t t a r g ) 2 ] L^{VF}(\theta) = \hat{\mathbb{E}}_t \left[ \left( V_\theta(s_t) - V_t^{targ} \right)^2 \right] LVF(θ)=E^t[(Vθ(st)−Vttarg)2]
使用裁剪的价值损失(use_clipped_value_loss=True)。
熵正则化:
L E n t r o p y = − H ( π θ ) = E ^ t [ ∑ a π θ ( a ∣ s t ) log π θ ( a ∣ s t ) ] L^{Entropy} = -\mathcal{H}(\pi_\theta) = \hat{\mathbb{E}}_t \left[ \sum_a \pi_\theta(a|s_t) \log \pi_\theta(a|s_t) \right] LEntropy=−H(πθ)=E^t[a∑πθ(a∣st)logπθ(a∣st)]
熵系数 β = 0.01 \beta = 0.01 β=0.01(Locomotion)/ 0.005 0.005 0.005(Mimic)。
总目标函数:
L ( θ ) = L C L I P ( θ ) − c 1 L V F ( θ ) + c 2 L E n t r o p y ( θ ) L(\theta) = L^{CLIP}(\theta) - c_1 L^{VF}(\theta) + c_2 L^{Entropy}(\theta) L(θ)=LCLIP(θ)−c1LVF(θ)+c2LEntropy(θ)
其中 c 1 = 1.0 c_1 = 1.0 c1=1.0(价值损失系数), c 2 = β c_2 = \beta c2=β。
5.1.3 自适应学习率
采用 KL 散度自适应 学习率调度:
- 目标 KL 散度: δ K L = 0.01 \delta_{KL} = 0.01 δKL=0.01
- 当实际 KL 散度 > 1.5 δ K L 1.5 \delta_{KL} 1.5δKL 时,学习率 × 0.5
- 当实际 KL 散度 < δ K L / 1.5 \delta_{KL} / 1.5 δKL/1.5 时,学习率 × 2.0
- 初始学习率: α 0 = 1 × 10 − 3 \alpha_0 = 1 \times 10^{-3} α0=1×10−3
5.1.4 训练超参数
| 参数 | Locomotion | Mimic |
|---|---|---|
| 每环境步数 | 24 | 24 |
| 最大迭代 | 50000 | 30000 |
| 保存间隔 | 100 | 500 |
| Mini-batch 数 | 4 | 4 |
| 训练 Epoch | 5 | 5 |
| 经验归一化 | False | False |
| 梯度裁剪 | 1.0 | 1.0 |
5.2 步态相位编码
observations.py 中实现了步态相位编码:
ϕ ( t ) = ( t ⋅ Δ t ) m o d T T \phi(t) = \frac{(t \cdot \Delta t) \mod T}{T} ϕ(t)=T(t⋅Δt)modT
gait_phase = [ sin ( 2 π ϕ ) , cos ( 2 π ϕ ) ] \text{gait\_phase} = [\sin(2\pi\phi), \, \cos(2\pi\phi)] gait_phase=[sin(2πϕ),cos(2πϕ)]
其中 T T T 为步态周期(H1: 0.6s,G1: 0.8s)。该编码为策略网络提供了周期性的步态时序信息。
5.3 步态奖励
rewards.py 中的 feet_gait 函数实现了基于相位的步态奖励:
r g a i t = ∑ i ¬ ( is_stance i ⊕ is_contact i ) r_{gait} = \sum_{i} \neg(\text{is\_stance}_i \oplus \text{is\_contact}_i) rgait=i∑¬(is_stancei⊕is_contacti)
其中:
- is_stance i = ( ϕ i < θ t h r e s h o l d ) \text{is\_stance}_i = (\phi_i < \theta_{threshold}) is_stancei=(ϕi<θthreshold), θ t h r e s h o l d = 0.55 \theta_{threshold} = 0.55 θthreshold=0.55
- ϕ i = ( ϕ g l o b a l + offset i ) m o d 1.0 \phi_i = (\phi_{global} + \text{offset}_i) \mod 1.0 ϕi=(ϕglobal+offseti)mod1.0
- 偏移量:左脚
offset=0.0,右脚offset=0.5(交替步态)
该奖励鼓励机器人在步态的支撑相保持足部接触,在摆动相抬起足部。
5.4 执行器模型
unitree_actuators.py 实现了宇树执行器的 T-N 曲线模型:
扭矩限制 (N·m)
^
Y2─────|
|──────────────Y1
| │\
| │ \
| │ \
| | \
──────+──────────────|──────> 速度 (rad/s)
X1 X2
力矩裁剪逻辑:
τ m a x = { Y 1 if sgn ( q ˙ ) = sgn ( τ ) and ∣ q ˙ ∣ < X 1 Y 2 if sgn ( q ˙ ) ≠ sgn ( τ ) and ∣ q ˙ ∣ < X 1 k ( ∣ q ˙ ∣ − X 1 ) + τ m a x if ∣ q ˙ ∣ ≥ X 1 \tau_{max} = \begin{cases} Y_1 & \text{if } \text{sgn}(\dot{q}) = \text{sgn}(\tau) \text{ and } |\dot{q}| < X_1 \\ Y_2 & \text{if } \text{sgn}(\dot{q}) \neq \text{sgn}(\tau) \text{ and } |\dot{q}| < X_1 \\ k(|\dot{q}| - X_1) + \tau_{max} & \text{if } |\dot{q}| \geq X_1 \end{cases} τmax=⎩ ⎨ ⎧Y1Y2k(∣q˙∣−X1)+τmaxif sgn(q˙)=sgn(τ) and ∣q˙∣<X1if sgn(q˙)=sgn(τ) and ∣q˙∣<X1if ∣q˙∣≥X1
其中 k = − τ m a x / ( X 2 − X 1 ) k = -\tau_{max} / (X_2 - X_1) k=−τmax/(X2−X1)。
摩擦模型:
τ a p p l i e d = τ P D − F s ⋅ tanh ( q ˙ V a ) − F d ⋅ q ˙ \tau_{applied} = \tau_{PD} - F_s \cdot \tanh\left(\frac{\dot{q}}{V_a}\right) - F_d \cdot \dot{q} τapplied=τPD−Fs⋅tanh(Vaq˙)−Fd⋅q˙
其中 F s F_s Fs 为静摩擦系数, F d F_d Fd 为动摩擦系数, V a V_a Va 为摩擦激活速度。
各执行器参数:
| 型号 | X1 (rad/s) | X2 (rad/s) | Y1 (N·m) | Y2 (N·m) | Fs | Fd | Armature |
|---|---|---|---|---|---|---|---|
| Go2HV | 13.5 | 30 | 20.2 | 23.4 | - | - | - |
| N7520-14.3 | 22.63 | 35.52 | 71 | 83.3 | 1.6 | 0.16 | 0.01018 |
| N7520-22.5 | 14.5 | 22.7 | 111 | 131 | 2.4 | 0.24 | 0.02510 |
| N5020-16 | 30.86 | 40.13 | 24.8 | 31.9 | 0.6 | 0.06 | 0.00361 |
| W4010-25 | 15.3 | 24.76 | 4.8 | 8.6 | 0.6 | 0.06 | 0.00425 |
5.5 关节刚度/阻尼计算(Mimic 模式)
Mimic 模式下,G1-29dof 的关节刚度和阻尼基于 二阶系统自然频率 计算:
K = J ⋅ ω n 2 K = J \cdot \omega_n^2 K=J⋅ωn2
D = 2 ζ ⋅ J ⋅ ω n D = 2 \zeta \cdot J \cdot \omega_n D=2ζ⋅J⋅ωn
其中:
- ω n = 10 × 2 π ≈ 62.83 \omega_n = 10 \times 2\pi \approx 62.83 ωn=10×2π≈62.83 rad/s(自然频率 10Hz)
- ζ = 2.0 \zeta = 2.0 ζ=2.0(过阻尼)
- J J J 为转子惯量(armature)
5.6 动作缩放计算(Mimic 模式)
Mimic 模式的动作缩放因子根据执行器参数自动计算:
scale j = 0.25 × τ m a x , j K j \text{scale}_j = 0.25 \times \frac{\tau_{max,j}}{K_j} scalej=0.25×Kjτmax,j
这确保了动作输出在关节力矩限制范围内。
6. 部署系统
6.1 C++ 推理框架
部署侧在 C++ 中重新实现了 Python 训练侧的核心逻辑,确保 Sim2Real 的一致性:
| Python 组件 | C++ 对应 | 功能 |
|---|---|---|
| ObservationManager | observation_manager.h | 观测计算与缩放 |
| ActionManager | action_manager.h | 动作处理与缩放 |
| ManagerBasedRLEnv | manager_based_rl_env.h | 环境管理 |
| ONNX 导出 | OrtRunner | ONNX Runtime 推理 |
6.2 部署配置导出
export_deploy_cfg.py 在训练时自动导出 deploy.yaml,包含:
- 关节映射:
joint_ids_map— Isaac Lab 关节顺序到 SDK 关节顺序的映射 - 控制参数:
step_dt、stiffness、damping、default_joint_pos - 命令范围:速度指令的极限范围
- 动作配置:缩放因子、裁剪范围、偏移量
- 观测配置:缩放因子、裁剪范围、历史长度
6.3 推理循环
// State_RLBase::enter() 中启动独立策略线程
policy_thread = std::thread([this]{
auto sleepTill = clock::now() + dt;
env->reset();
while (policy_thread_running) {
env->step(); // robot->update() → obs → ONNX → action → joint_cmd
std::this_thread::sleep_until(sleepTill);
sleepTill += dt;
}
});
每个 env->step() 的执行流程:
robot->update()— 从 SDK 读取关节状态observation_manager->compute()— 计算观测向量(含缩放和裁剪)alg->act(obs)— ONNX Runtime 前向推理action_manager->process_action(action)— 处理动作(含缩放和偏移)- 在
run()中将动作写入 SDK 命令
6.4 Mimic 部署特殊逻辑
Mimic 部署需要同步运动数据,额外包含:
- MotionLoader_:从 CSV 文件加载运动轨迹,线性插值获取当前帧数据
- 参考朝向对齐:进入时计算初始偏航角对齐
init_quat = R_robot_yaw × R_ref_yaw^T - 躯干朝向计算:通过根四元数和腰部关节角度计算
torso_quat_w - 时间范围控制:支持
time_start和time_end截取运动片段
7. 仿真环境配置
7.1 仿真参数
| 参数 | 值 | 说明 |
|---|---|---|
sim.dt |
0.005s | 物理仿真步长(200Hz) |
decimation |
4 | 控制频率降采样比 |
| 控制频率 | 50Hz | 1/(0.005×4) = 50Hz |
episode_length_s |
20s / 30s | Locomotion / Mimic |
num_envs |
4096 | 并行环境数 |
env_spacing |
2.5m | 环境间距 |
7.2 地形配置
Locomotion 使用程序化生成的地形:
COBBLESTONE_ROAD_CFG = terrain_gen.TerrainGeneratorCfg(
size=(8.0, 8.0), # 每块地形尺寸
border_width=20.0, # 边界宽度
num_rows=9~10, # 行数(课程维度)
num_cols=20~21, # 列数
difficulty_range=(0.0, 1.0), # 难度范围
sub_terrains={
"flat": MeshPlaneTerrainCfg(proportion=0.1~0.5),
},
)
物理材质:静摩擦 1.0,动摩擦 1.0。
7.3 机器人配置
各机器人的初始状态和执行器参数在 unitree.py 中定义:
| 机器人 | 自由度 | 初始高度 | 关节数 | 执行器类型 |
|---|---|---|---|---|
| Go2 | 12 | 0.4m | 12 | Go2HV |
| Go2W | 16 | 0.45m | 16 | Go2HV |
| B2 | 12 | 0.58m | 12 | M107-24-2 |
| G1-23dof | 23 | 0.8m | 23 | N7520/N5020 |
| G1-29dof | 29 | 0.8m | 29 | N7520/N5020/W4010 |
| H1 | 19 | 1.1m | 19 | M107-24/GO2HV |
8. 设计模式与工程实践
8.1 MDP 管理器模式
项目采用 Isaac Lab 的 Manager-Based RL Env 架构,将 MDP 各组件解耦为独立管理器:
ObservationManager:管理观测项的计算、缩放、噪声注入ActionManager:管理动作的处理、缩放、偏移RewardManager:管理奖励项的加权和计算CommandManager:管理指令的采样与更新EventManager:管理域随机化事件的触发TerminationManager:管理终止条件的判断CurriculumManager:管理课程学习策略
8.2 配置即代码
所有环境配置均使用 Python @configclass 装饰器定义,兼具类型安全和可读性:
@configclass
class RobotEnvCfg(ManagerBasedRLEnvCfg):
scene: RobotSceneCfg = RobotSceneCfg(num_envs=4096)
observations: ObservationsCfg = ObservationsCfg()
actions: ActionsCfg = ActionsCfg()
...
8.3 训练-部署一致性保障
- 训练时通过
export_deploy_cfg()导出完整的部署配置 - C++ 部署侧使用相同的
deploy.yaml配置 - 观测和动作的缩放、裁剪、偏移在两侧完全一致
- ONNX 模型导出包含观测归一化器
8.4 FSM 注册机制
部署侧使用宏注册 FSM 状态类,实现可扩展的状态机:
REGISTER_FSM(State_RLBase) // 自动注册到全局工厂映射
CtrlFSM 通过 YAML 配置动态创建状态实例,支持灵活的状态转换定义。
9. 与 unitree_rl_gym 项目对比
宇树科技同时维护了两个强化学习项目:unitree_rl_lab(本项目)和 unitree_rl_gym。两者在定位、技术栈和功能特性上存在显著差异。
9.1 仿真平台对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 仿真引擎 | Isaac Gym | Isaac Sim + Isaac Lab |
| 版本要求 | Isaac Gym Preview | Isaac Sim 5.1.0 + Isaac Lab 2.3.0 |
| 渲染方式 | GPU 加速的物理仿真 | 完整物理仿真 + 高保真渲染 |
| 并行环境 | 支持 | 支持(4096 环境) |
| 地形生成 | 基础地形 | 程序化地形生成器(课程学习) |
关键差异:Isaac Gym 是 NVIDIA 较早期的仿真平台,而 Isaac Lab 是基于 Isaac Sim 的新一代框架,提供更真实的物理仿真和更丰富的传感器支持。
9.2 部署方式对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 主要部署语言 | Python(deploy_real.py) | C++ |
| 模型格式 | PyTorch .pt / LibTorch |
ONNX .onnx |
| 推理引擎 | LibTorch | ONNX Runtime |
| C++ 示例 | 仅 G1 有 C++ 示例 | 所有机器人都有完整 C++ 部署 |
| FSM 状态机 | 无 | 完整 FSM 架构(Passive/FixStand/Velocity/Mimic) |
关键差异:
unitree_rl_gym主要使用 Python 部署,依赖 LibTorch;unitree_rl_lab采用纯 C++ 部署,使用 ONNX Runtime,更适合实时控制场景。
9.3 任务类型对比
| 任务类型 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| Locomotion(速度跟踪) | ✅ | ✅ |
| Mimic(动作模仿) | ❌ | ✅ |
| 舞蹈追踪 | ❌ | ✅(G1-29dof) |
关键差异:
unitree_rl_lab新增了 Mimic 任务,支持从动捕数据学习复杂动作(如舞蹈),包含自适应运动采样算法。
9.4 机器人支持对比
| 机器人 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| Go2 | ✅ | ✅ |
| Go2W | ❌ | ✅ |
| B2 | ❌ | ✅ |
| G1 | ✅ | ✅ |
| G1-23dof | ❌ | ✅ |
| G1-29dof | ❌ | ✅ |
| H1 | ✅ | ✅ |
| H1_2 | ✅ | ✅ |
关键差异:
unitree_rl_lab支持更多机器人型号,特别是 G1-29dof 和 B2。
9.5 架构设计对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 基础框架 | legged_gym | Isaac Lab |
| 环境架构 | 传统 RL 环境 | Manager-Based RL Env |
| 配置方式 | Python 配置类 | @configclass + YAML |
| MDP 组件管理 | 集成在环境类中 | 独立 Manager(观测/动作/奖励/命令/事件) |
| 域随机化 | 基础随机化 | 多维度随机化(物理材质/质量/质心/关节偏移/推力) |
| 课程学习 | 有限支持 | 地形课程 + 速度课程 |
9.6 RSL-RL 版本对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| RSL-RL 版本 | v1.0.2 | v2.3.1 |
| 分布式训练 | 不支持 | 支持 |
| 模型导出 | .pt 文件 |
ONNX + JIT |
9.7 执行器建模对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 执行器模型 | 理想 PD 控制器 | T-N 曲线 + 摩擦模型 |
| 力矩限制 | 固定限制 | 速度相关力矩限制 |
| 摩擦建模 | 无 | 静摩擦 + 动摩擦 |
关键差异:
unitree_rl_lab实现了更真实的执行器模型,包含 T-N 曲线和摩擦特性,有助于 Sim2Real 迁移。
9.8 观测空间对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 观测历史 | 无 | 支持(history_length=5) |
| 步态相位编码 | 无 | 支持(sin/cos 编码) |
| 高度扫描 | 基础 | RayCaster 支持 |
| 特权观测 | 基础 | 完整 Critic 观测 |
9.9 奖励函数对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 奖励项数量 | 基础奖励 | 更丰富(能量/步态/足部离地等) |
| 步态奖励 | 无 | 基于相位的步态奖励 |
| 足部离地奖励 | 基础 | 带速度调制的离地奖励 |
| Mimic 奖励 | 无 | 全身跟踪奖励(位置/朝向/速度) |
9.10 部署配置对比
| 特性 | unitree_rl_gym | unitree_rl_lab |
|---|---|---|
| 配置导出 | 手动配置 | 自动导出 deploy.yaml |
| 关节映射 | 手动处理 | 自动生成 joint_ids_map |
| 观测/动作缩放 | 手动配置 | 自动导出缩放参数 |
二、复现
本节详细介绍如何从零开始复现 Unitree RL Lab 项目,包括环境安装、模型训练、推理演示以及 Sim2Real 部署的完整流程。
2.1 准备工作:安装与配置
1. 安装 Isaac Lab
这是整个项目的基础,需要严格按照 Isaac Lab 官方指南完成安装。
2. 克隆并安装本项目
⚠️ 注意:必须将本项目克隆到 Isaac Lab 目录之外。
git clone https://github.com/unitreerobotics/unitree_rl_lab.git
cd unitree_rl_lab
# 激活已安装 Isaac Lab 的 conda 环境
conda activate env_isaaclab
# 运行安装脚本,之后重启终端
./unitree_rl_lab.sh -i
3. 下载并配置 Go2 模型文件
官方提供两种方式,推荐使用方法二(URDF),但需注意其对 Isaac Sim 的版本要求。
方法一:使用 USD 文件
git clone https://huggingface.co/datasets/unitreerobotics/unitree_model
然后编辑 source/unitree_rl_lab/unitree_rl_lab/assets/robots/unitree.py,将 UNITREE_MODEL_DIR 变量改为你克隆的 unitree_model 目录的实际路径。
方法二:使用 URDF 文件
⚠️ 此方法要求 Isaac Sim 版本 >= 5.0。
git clone https://github.com/unitreerobotics/unitree_ros.git
同上,修改 unitree.py 文件中的 UNITREE_ROS_DIR 变量为 unitree_ros 文件夹的实际路径。
2.2 验证环境并开始训练 Go2
1. 验证安装是否成功
# 列出所有可用任务,在输出中寻找以 "Unitree-Go2" 开头的任务名
./unitree_rl_lab.sh -l
2. 执行训练
根据上一步找到的 Go2 任务名,运行训练命令。例如,如果任务名为 Unitree-Go2-Velocity(实际名称请以上一条命令的输出为准):
# 无头模式训练(不显示图形界面)
./unitree_rl_lab.sh -t --task Unitree-Go2-Velocity
等效于直接运行 Python 脚本:
python scripts/rsl_rl/train.py --headless --task Unitree-Go2-Velocity
3. 恢复中断的训练
训练中断后,可通过以下方式从最新检查点恢复:
cd ~/unitree_rl_lab
# 方法1:让脚本自动查找最新的实验和检查点(推荐)
python scripts/rsl_rl/train.py --task Unitree-Go2-Velocity --resume --headless
# 方法2:手动指定实验目录和检查点
python scripts/rsl_rl/train.py \
--task Unitree-Go2-Velocity \
--resume \
--load_run 2026-05-12_10-38-01 \
--checkpoint model_108.pt \
--headless
📁 检查点文件位置:
logs/rsl_rl/<experiment_name>/<run_name>/示例:
logs/rsl_rl/unitree_go2_velocity/2026-05-12_10-38-01/model_108.pt
4. 使用已训练模型进行推理演示
./unitree_rl_lab.sh -p --task Unitree-Go2-Velocity
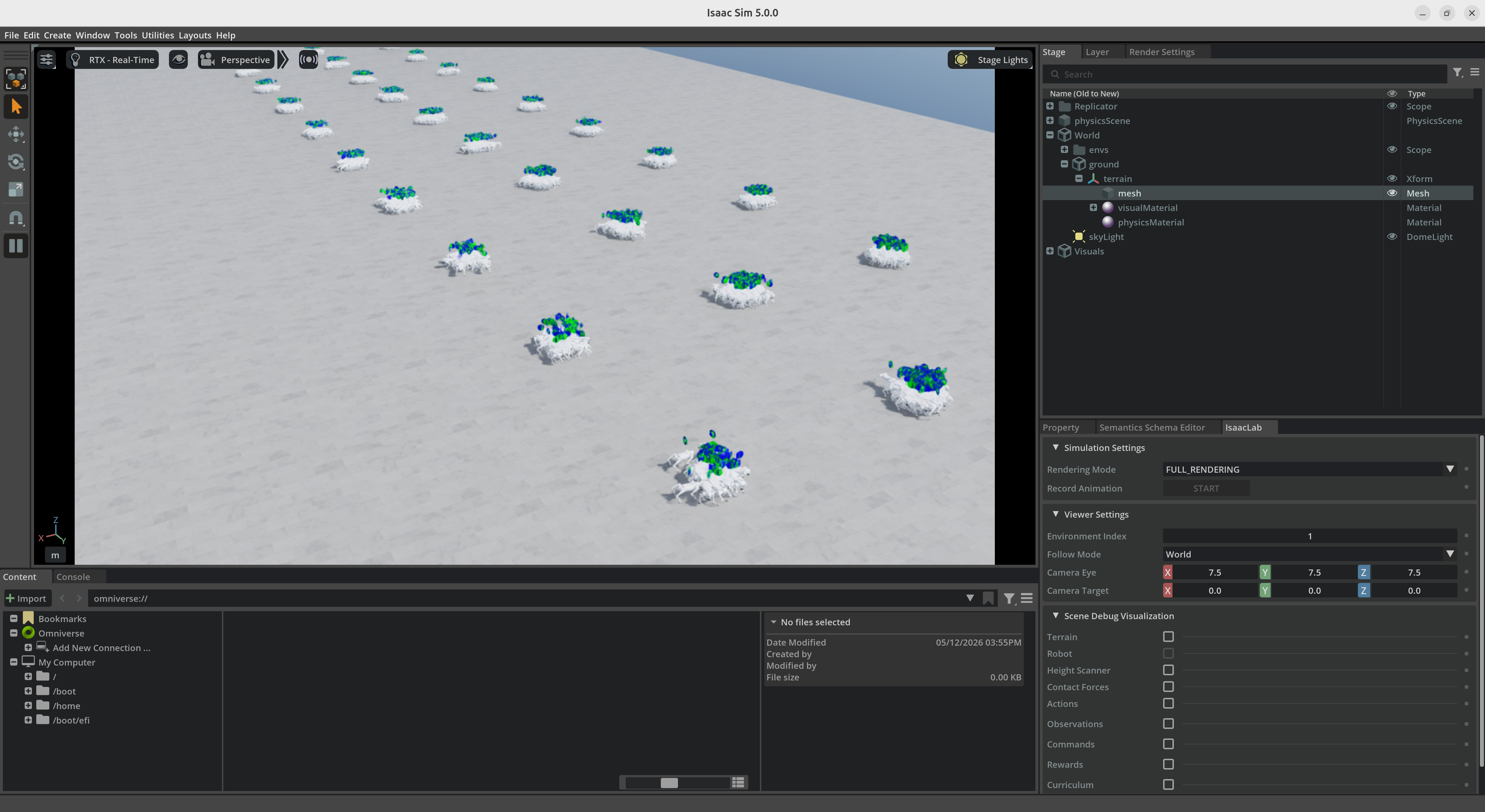
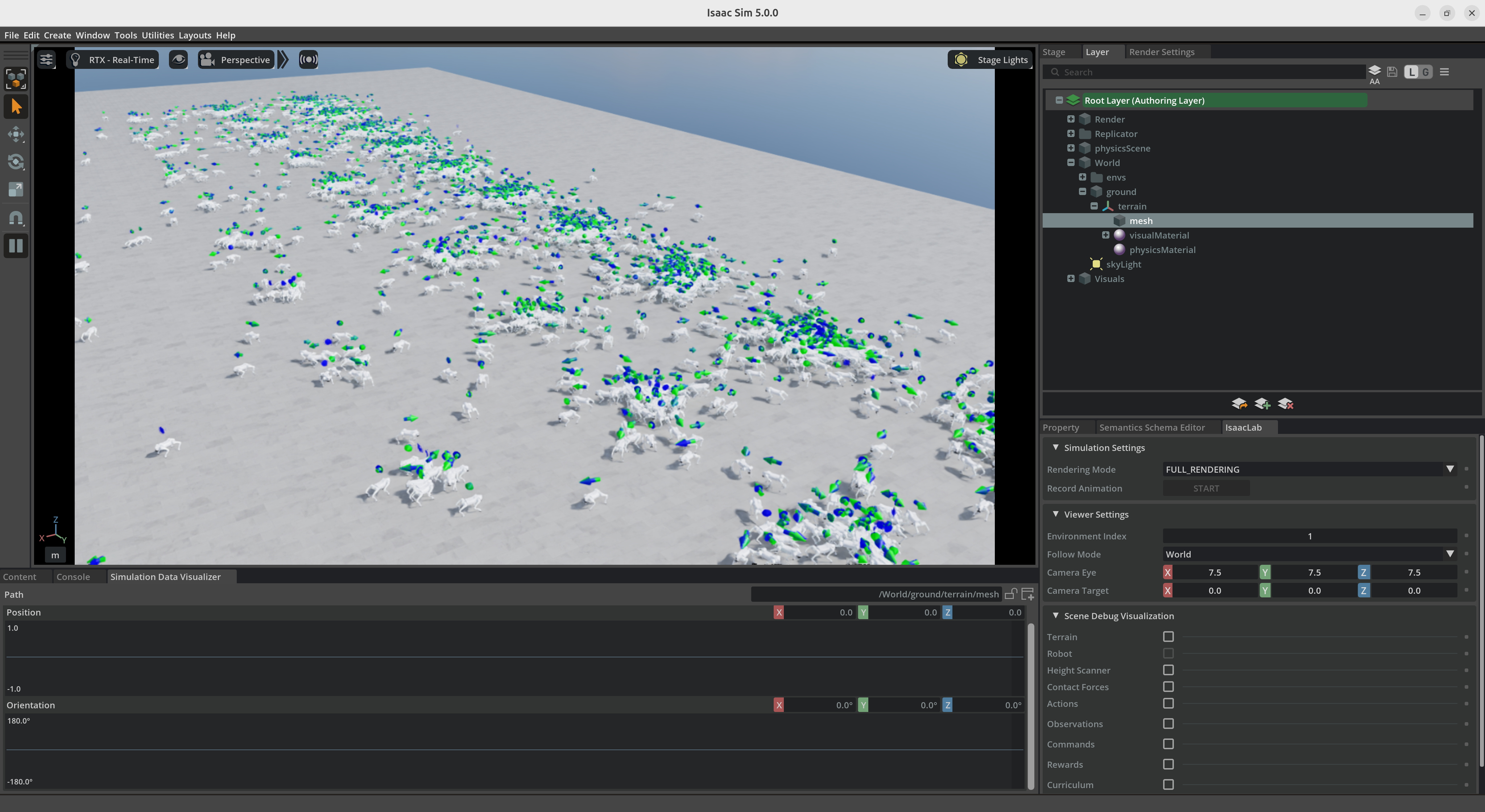
四足机器人Isaac Sim/Lab测试
5. 训练参数详解
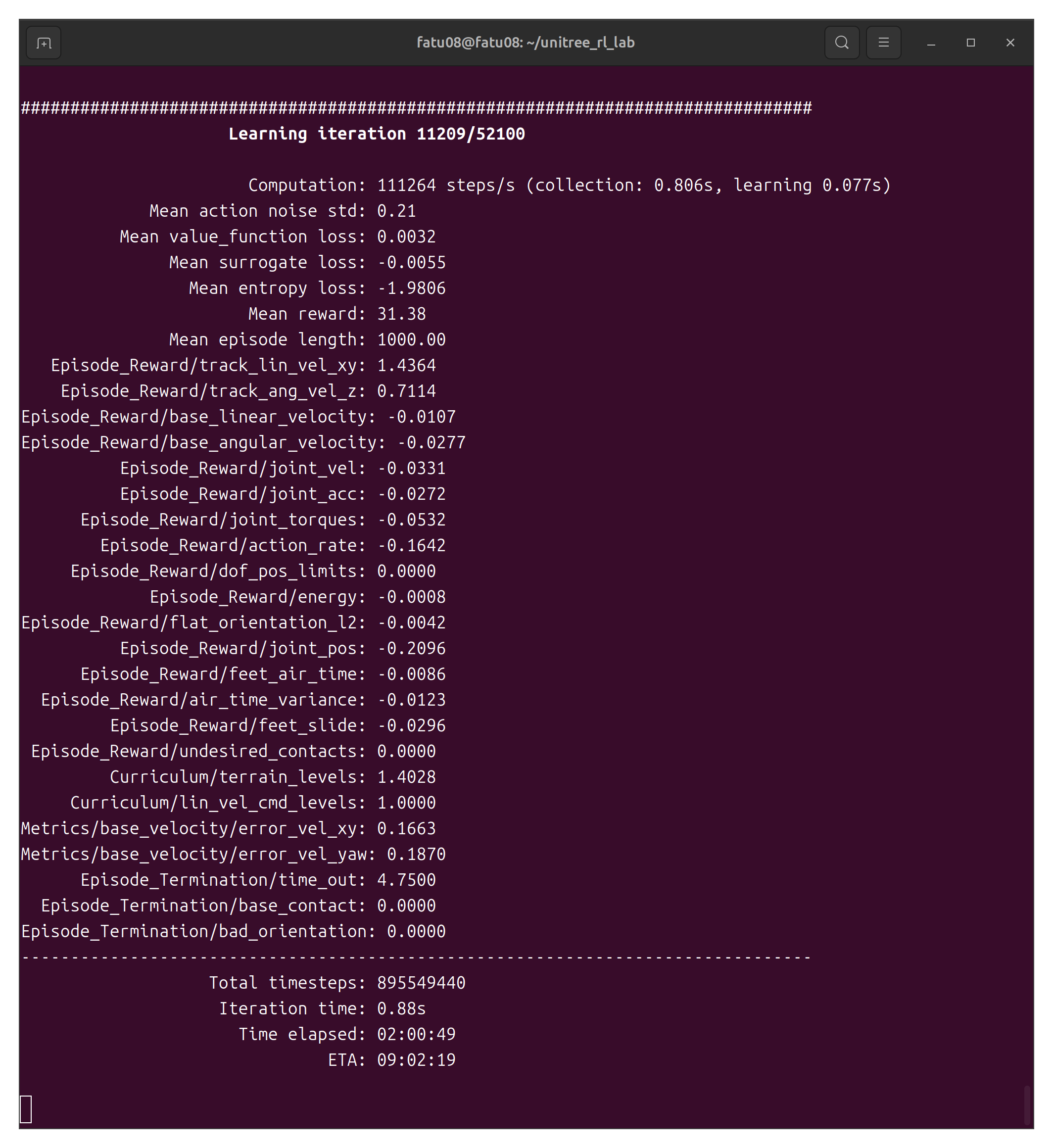
1、性能指标
| 参数 | 含义 | 当前值 | 说明 |
|---|---|---|---|
| Computation | 计算速度 | 129,755 steps/s | 每秒处理的仿真步数,越高越好 |
| collection | 数据采集时间 | 0.689s | 收集机器人经验数据的时间 |
| learning | 学习更新时间 | 0.068s | 神经网络参数更新的时间 |
| Iteration time | 单次迭代总时间 | 0.76s | 完成一次训练循环的总时间 |
| Total timesteps | 总时间步数 | 84,639,744 | 累计仿真的总步数 |
| Time elapsed | 已用时间 | 00:11:08 | 训练已运行的时间 |
| ETA | 预计剩余时间 | 10:35:52 | 预计还需要多长时间完成 |
2、核心奖励指标(越高越好)
| 参数 | 含义 | 当前值 | 说明 |
|---|---|---|---|
| Mean reward | 平均总奖励 | 30.29 | 综合得分,核心指标 |
| Mean episode length | 平均回合长度 | 995.58 | 机器人存活步数,最大1000 |
| track_lin_vel_xy | 线速度跟踪 | 1.4196 | 前后/左右速度跟随能力 |
| track_ang_vel_z | 角速度跟踪 | 0.7040 | 转向速度跟随能力 |
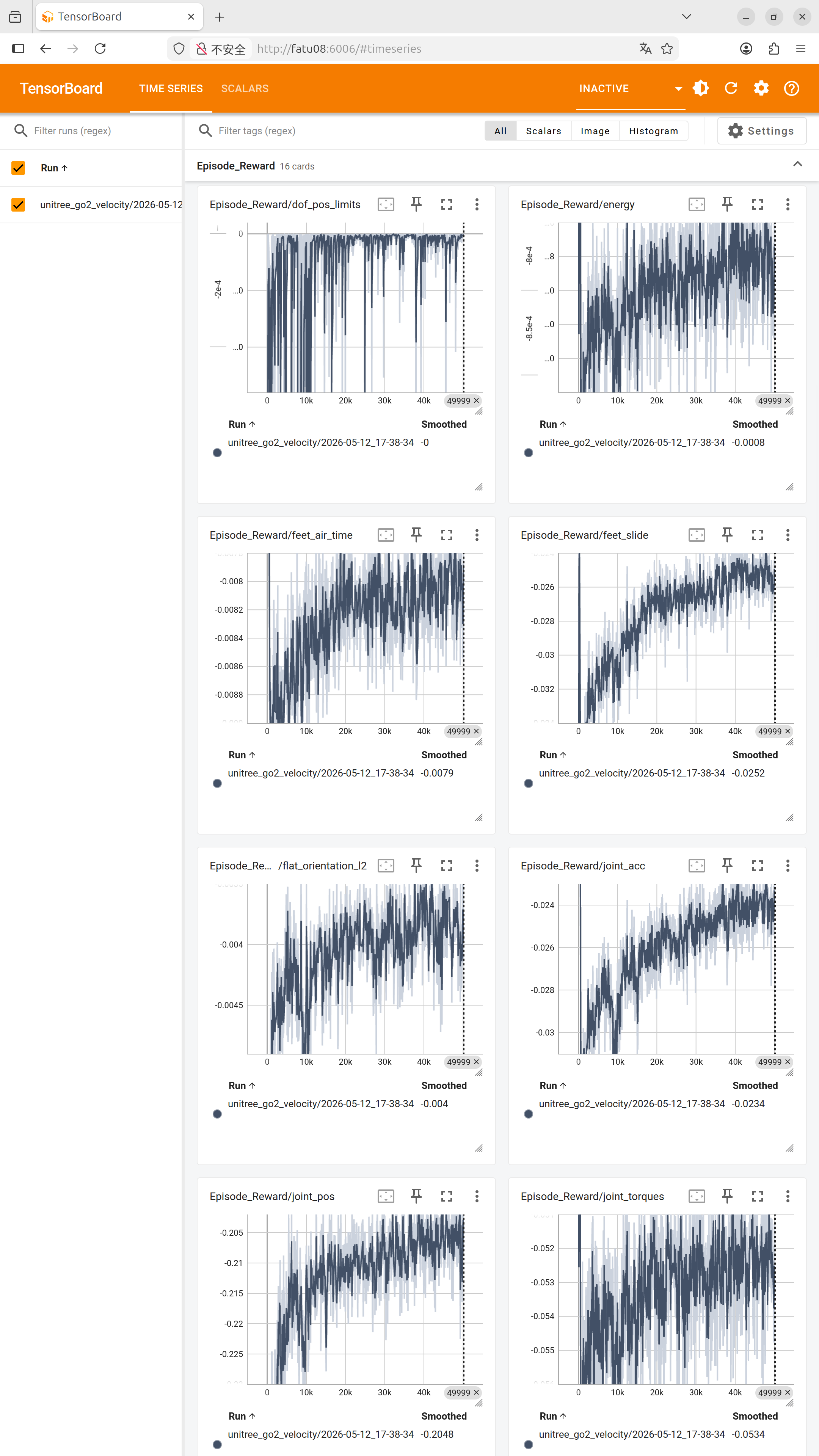
3、惩罚项(越低越好,越接近0越好)
身体控制类
| 参数 | 含义 | 当前值 | 理想范围 |
|---|---|---|---|
| base_linear_velocity | 基座线速度 | -0.0115 | 接近0 |
| base_angular_velocity | 基座角速度 | -0.0294 | 接近0 |
| flat_orientation_l2 | 身体姿态偏离 | -0.0052 | 接近0 |
关节运动类
| 参数 | 含义 | 当前值 | 理想范围 |
|---|---|---|---|
| joint_vel | 关节速度 | -0.0322 | 接近0 |
| joint_acc | 关节加速度 | -0.0279 | 接近0 |
| joint_torques | 关节力矩 | -0.0531 | 接近0(省力) |
| joint_pos | 关节位置偏离 | -0.2267 | 接近0(姿势标准) |
步态质量类
| 参数 | 含义 | 当前值 | 理想范围 |
|---|---|---|---|
| action_rate | 动作变化率 | -0.1671 | 接近0(动作平滑) |
| feet_air_time | 脚离地时间 | -0.0087 | 接近0 |
| air_time_variance | 离地时间方差 | -0.0155 | 接近0(左右对称) |
| feet_slide | 脚滑动 | -0.0319 | 接近0(不打滑) |
安全限制类
| 参数 | 含义 | 当前值 | 理想范围 |
|---|---|---|---|
| dof_pos_limits | 关节限位 | -0.0001 | 0(不触碰极限) |
| energy | 能量消耗 | -0.0008 | 接近0(节能) |
| undesired_contacts | 意外接触 | -0.0000 | 0(无碰撞) |
4、课程学习指标
| 参数 | 含义 | 当前值 | 说明 |
|---|---|---|---|
| Curriculum/terrain_levels | 地形等级 | 1.0828 | >1表示已进入复杂地形 |
| Curriculum/lin_vel_cmd_levels | 速度指令等级 | 1.0000 | 1.0表示已达最大速度要求 |
5、性能误差指标(越低越好)
| 参数 | 含义 | 当前值 | 说明 |
|---|---|---|---|
| error_vel_xy | 线速度误差 | 0.1830 m/s | 目标速度和实际速度的差距 |
| error_vel_yaw | 角速度误差 | 0.1969 rad/s | 目标转向和实际的差距 |
6、终止条件(越低越好)
| 参数 | 含义 | 当前值 | 说明 |
|---|---|---|---|
| time_out | 超时终止 | 3.4583 | 正常完成任务的比例 |
| base_contact | 基座接触 | 0.0000 | 腹部触地次数(0=没摔倒) |
| bad_orientation | 姿态不良 | 0.0417 | 4.17%因姿态不好终止 |
7、神经网络学习指标
| 参数 | 含义 | 当前值 | 说明 |
|---|---|---|---|
| Mean action noise std | 动作噪声标准差 | 0.21 | 探索程度,训练初期高后期低 |
| Mean value_function loss | 价值函数损失 | 0.0041 | 接近0表示学习稳定 |
| Mean surrogate loss | 策略损失 | -0.0038 | 负值表示策略在改进 |
| Mean entropy loss | 熵损失 | -1.5768 | 负值表示策略确定性增强 |
2.3 训练后:Sim to Sim/Real
先后进行 Sim2Sim(仿真迁移验证) 和 Sim2Real(实物部署) 两步。
1. 部署步骤
-
安装依赖
按照页面的
Deploy > Setup部分,依次安装系统依赖、unitree_sdk2。 -
编译控制器
进入
deploy/robots目录下 Go2 对应的文件夹(而非 G1 的),执行:mkdir build && cd build && cmake .. && make -
执行 Sim2Sim
安装
unitree_mujoco后,修改simulate/config.yaml中的机器人类型为go2,再按指南启动仿真和控制程序。 -
执行 Sim2Real
确保机器人上的控制程序已关闭,然后运行编译好的 Go2 控制器程序,并指定网络接口。
重要提示:部署部分的命令和配置文件路径可能需要根据 Go2 的实际目录结构进行相应调整,请以
deploy/robots/go2目录下的实际文件为准。
2. 效果展示
1)Sim2Sim
步骤:
1、cd ~/unitree_mujoco/simulate/build
./unitree_mujoco
2、cd ~/unitree_rl_lab/deploy/robots/go2/build
./go2_ctrl --network wlp132s0(lo不支持组播,可采用网卡eth0或者wlp132s0)
注意:1、在进行Isaac Sim到MuJoCo的sim2sim时,mujoco环境和go2的控制器一直连接不上,后来发现原因并解决:
问题原因:
MuJoCo仿真端与Go2控制器端通过CycloneDDS通信,连接失败有两个根本原因:
一是网络接口不一致,MuJoCo配置文件simulate/config.yaml中指定了lo本地回环接口(不支持多播),而Go2控制器可绑定wlp132s0无线网卡,两者不在同一网络通道上导致发现机制失效;
二是DDS Domain ID不一致,MuJoCo的config.yaml中domain_id: 1,而Go2控制器的config.yaml中没有此配置项默认为0,不同Domain ID的DDS参与者互相不可见。
解决方法:
修改MuJoCo配置文件~/unitree_mujoco/simulate/config.yaml中的两项配置:
将interface: "lo"改为interface: "wlp132s0",将domain_id: 1改为domain_id: 0,使网络接口和Domain ID与控制器端保持一致。
修改后MuJoCo端直接运行./unitree_mujoco,控制器端运行./go2_ctrl --network wlp132s0,即可成功建立连接。排查过程中应注意:MuJoCo程序直接读取config.yaml而非环境变量,应优先检查双方配置文件的一致性。
2、虚拟手柄可参考:
1) 虚拟手柄:https://github.com/WJason106/Go2-Virtual-controller
2)键盘代替手柄:详见我另一篇blog(Unitree MuJoCo 键盘替代手柄控制说明)
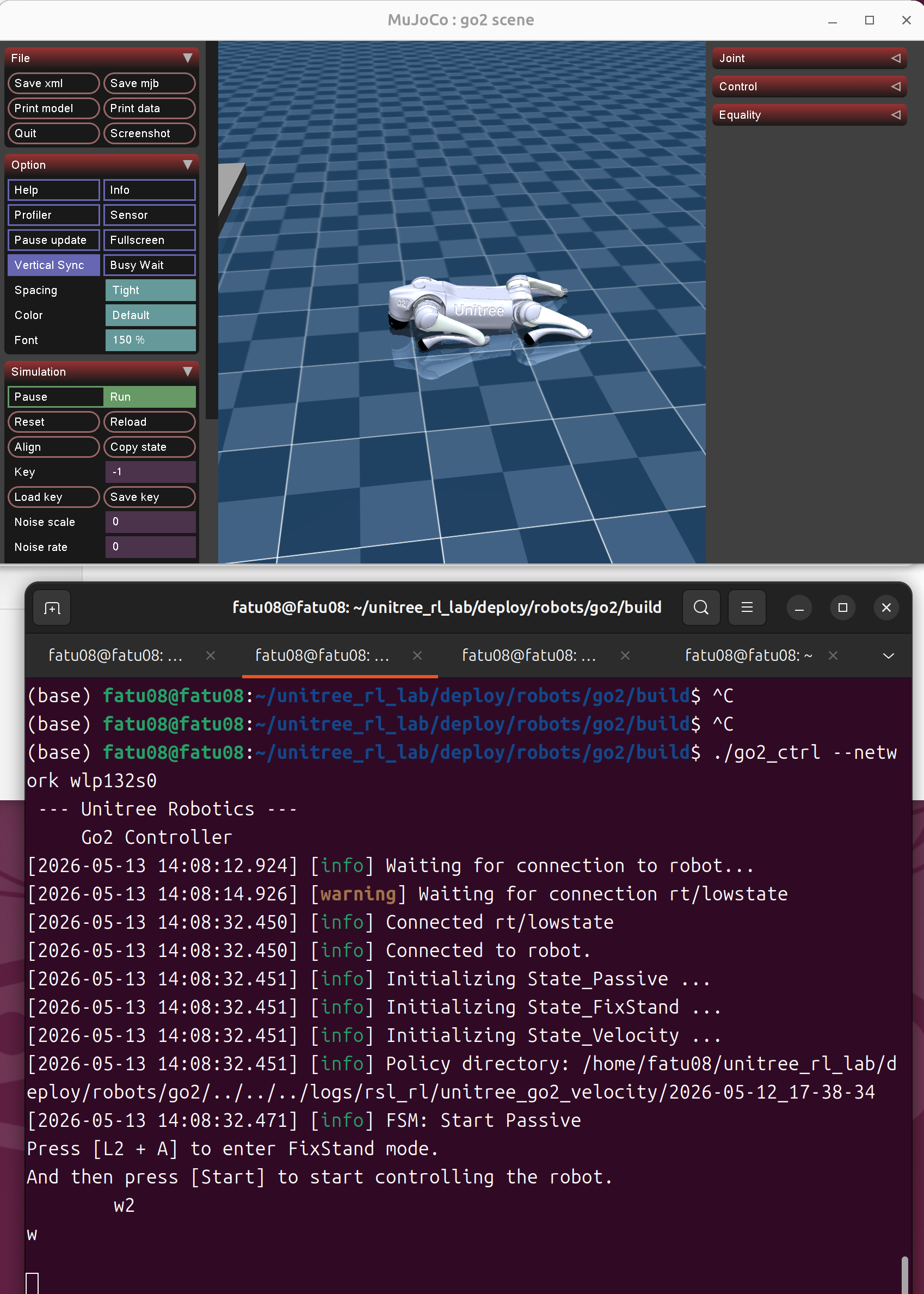
sim2sim四足机器人mujoco
2)sim2real
相关教程参考:https://support.unitree.com/home/zh/developer/Quick_start
https://github.com/unitreerobotics/unitree_rl_lab
sim2real旋转
sim2real前进后退侧移
三、功能拓展优化
3.1 楼梯场景训练(Go2-Stair)
针对上下楼梯场景,项目提供了专用的训练环境 Unitree-Go2-Stair,相比平地 Velocity 环境,做了以下关键优化:
| 优化项 | 平地 Velocity | 楼梯 Stair | 说明 |
|---|---|---|---|
| 地形 | 仅 flat | 上楼25%+下楼25%+斜坡30%+box15%+flat5% | 渐进式课程学习 |
| 高度扫描 | 关闭 | 启用(187点) | 机器人需"看见"楼梯 |
| 足部腾空奖励 | weight=0.1 | weight=2.0 | 爬楼必须抬脚 |
| 抬脚高度奖励 | 无 | target=0.10m | 鼓励抬脚过台阶 |
| 足部绊倒惩罚 | 无 | weight=-0.5 | 避免脚尖撞台阶 |
| 俯仰终止限制 | 0.8 rad | 1.2 rad | 放宽,允许爬楼前倾 |
| 摩擦随机化 | 0.3~1.2 | 0.3~1.5 | 楼梯表面更多样 |
训练与测试命令:
# 训练楼梯策略
./unitree_rl_lab.sh -t --task Unitree-Go2-Stair
# 测试/演示楼梯策略
./unitree_rl_lab.sh -p --task Unitree-Go2-Stair
# 恢复中断的楼梯训练
python scripts/rsl_rl/train.py --task Unitree-Go2-Stair --resume --headless
楼梯训练模型保存位置:
logs/rsl_rl/unitree_go2_stair/
(其他拓展优化待补充~~~)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)