机器学习-第七章 朴素贝叶斯+kmeans聚类
机器学习-第七章 朴素贝叶斯+kmeans聚类
目录
1.朴素贝叶斯算法介绍
2.朴素贝叶斯常见API
3.聚类算法的简介
4.聚类算法API的使用
5.Kmeans 实现流程
6.模型评估方法
7.案例顾客数据聚类分析法
一、朴素贝叶斯课程笔记总结
1. 朴素贝叶斯核心概念
朴素贝叶斯是一种分类算法,其核心思想是基于概率进行分类。它被称为“朴素”,是因为它有一个强假设:特征之间相互独立。
-
1.1 什么是朴素贝叶斯
- 贝叶斯:指基于贝叶斯定理,利用概率统计进行分类的方法。它是机器学习中唯一纯粹依赖概率值进行分类的算法。
- 朴素:指“特征条件独立假设”,即假设数据集中每个特征(列)之间是没有关联的,相互独立的。
- 朴素的作用:在这个假设下,计算联合概率或条件概率时,复杂的计算过程可以简化为直接进行概率相乘,从而大大简化了模型的计算复杂度。
-
1.2 概率基础
- 1.2.1 概率:指一件事情发生的可能性,数值在0到1之间。
- 1.2.2 条件概率:指在事件B已经发生的条件下,事件A发生的概率,记作
P(A|B)。- 计算公式理解:通过去掉部分样本的情况来计算。例如,在“女神喜欢”的条件下,“职业是程序员”的概率。先圈定“喜欢”的样本空间,再计算其中“程序员”的比例。
- 1.2.3 联合概率:指多个事件同时成立的概率,记作
P(A, B)或P(AB)。- 计算公式:
P(AB) = P(A) * P(B|A)或P(AB) = P(B) * P(A|B)。这两个等式是等价的。
- 计算公式:
- 1.2.4 相互独立:如果
P(AB) = P(A) * P(B),则称事件A与事件B相互独立。这也是“朴素”二字在数学上的体现。
2. 贝叶斯公式推导与理解
课程中通过基础概率公式推导出了贝叶斯公式。
-
2.1 公式推导
- 由
P(AB) = P(A) * P(B|A)和P(AB) = P(B) * P(A|B)这两个等式可以得出:P(A) * P(B|A) = P(B) * P(A|B) - 如果我们要计算
P(A|B),则公式可变为:P(A|B) = [P(A) * P(B|A)] / P(B)
- 由
-
2.2 转换为机器学习形式
- 将抽象的A、B替换为机器学习中的特征(W)和类别©,就得到了课程中使用的贝叶斯公式:
P(C|W) = [P(W|C) * P(C)] / P(W) P(C):先验概率,即类别C出现的概率(例如,所有评论中“好评”的概率)。P(W|C):条件概率,即在类别C的条件下,特征W出现的概率(例如,“好评”中包含“很好”这个词的概率)。P(W):特征概率,即特征W在所有样本中出现的概率,在分类比较时通常作为归一化因子,可以忽略。P(C|W):后验概率,即给定特征W,样本属于类别C的概率,这是我们最终要求的值。
- 将抽象的A、B替换为机器学习中的特征(W)和类别©,就得到了课程中使用的贝叶斯公式:
3. 拉普拉斯平滑系数
-
3.1 引入原因
在计算P(W|C)时,如果某个特征词在某个类别下从未出现过,其概率将为0。在“朴素”假设下,这会导致连乘结果为0,模型失效。同时,分母也可能在特定情况下为0,导致计算错误。 -
3.2 作用
在计算概率的分子和分母上分别加上一个数值(拉普拉斯平滑系数),避免出现概率为0的情况。- 公式体现:
P(W|C) = (包含特征W且属于类别C的样本数 + α) / (属于类别C的所有样本数 + α * m) - α:拉普拉斯平滑系数,通常取1。
- m:特征的总数(如不同单词的个数)。
- 公式体现:
4. 案例:商品评论情感分析
-
4.1 案例背景
该案例的目标是分析电商商品评论,通过评论的文字内容,自动判断该评论是“好评”还是“差评”。传统方法可能依赖星级评分,但本案例基于内容本身,利用朴素贝叶斯进行概率预测。 -
4.2 分析流程与代码实现
- 数据准备与标签处理:读取数据,并新增一列数值型标签(如,好评=1,差评=0)。
- 分词与数据清洗:使用结巴中文分词器(jieba)对每条评论进行分词,并加载停用词表(stopwords),剔除“的”、“是”、“从”等无实际语义的无效词。
- 特征向量化:使用
CountVectorizer将处理后的词语列表转换为词频矩阵(特征向量),作为模型的特征(X)。 - 模型训练与评估:划分训练集和测试集,创建
MultinomialNB对象,进行模型训练、预测和准确率评估。
# 1. 导入必要的库
import pandas as pd
import numpy as np
import jieba
from sklearn.feature_extraction.text import CountVectorizer # 用于文本向量化
from sklearn.naive_bayes import MultinomialNB # 导入朴素贝叶斯模型
from sklearn.metrics import accuracy_score
# 2. 数据读取与标签处理
# 读取csv文件,注意编码
df = pd.read_csv('./data/书籍评论.csv', encoding='utf-8')
# 创建新列 'labels',作为目标变量y:好评设为1,差评设为0
df['labels'] = np.where(df['评价'] == '好评', 1, 0)
y = df['labels']
# 3. 分词与清洗
# 加载停用词列表
with open('./data/stopwords.txt', 'r', encoding='utf-8') as f:
stop_words = [line.strip() for line in f.readlines()]
# 定义一个函数,对评论进行分词并去除停用词
def cut_words(comment):
# 使用jieba进行分词
words = jieba.lcut(comment)
# 去除停用词,并用空格连接成字符串,便于后续向量化
words_clean = ' '.join([w for w in words if w not in stop_words])
return words_clean
# 对所有评论内容应用该函数
# df['内容'] 包含了所有的评论文本
X_clean = df['内容'].apply(cut_words)
# 4. 特征向量化 (将文本转为数字矩阵)
# stop_words参数可以直接传入停用词列表,在向量化时一并处理
transfer = CountVectorizer(stop_words=stop_words)
X = transfer.fit_transform(X_clean) # 一步完成训练和转换,得到词频矩阵
# 5. 划分数据集 (由于数据量仅13条,直接手动切分)
x_train, x_test = X[:10], X[10:] # 前10条为训练集
y_train, y_test = y[:10], y[10:] # 后3条为测试集
# 6. 模型实例化与训练
# 创建朴素贝叶斯分类器对象,alpha为拉普拉斯平滑系数
estimator = MultinomialNB(alpha=1.0)
estimator.fit(x_train, y_train)
# 7. 模型评估与预测
# 对测试集进行预测
y_predict = estimator.predict(x_test)
print(f"预测结果: {y_predict}")
print(f"真实结果: {y_test.values}")
# 计算并打印模型准确率
accuracy = accuracy_score(y_test, y_predict)
print(f"模型准确率: {accuracy}")
- 4.3 代码补充说明
- 向量化结果:
X生成的是一个词频矩阵。矩阵的行代表每一条评论,列代表去重后的所有特征词。矩阵中的值0或1(或其他数字)代表该评论是否包含某个特征词及其频率。例如,处理后可能留下37个特征词,则每条评论会被转换为一个长度为37的特征向量。 CountVectorizer:这个工具集成了停用词处理、分词(对英文有效,中文需先自行分词)和向量化等多个步骤,非常高效。- 模型泛化:案例中数据量极少,准确率达到100%是过拟合的表现。在实际应用中,需要大规模数据,并且模型训练完成后应进行保存(如使用
joblib或pickle),避免每次预测时重新训练。
- 向量化结果:
5. 课后分析
-
5.1 在AI大模型学习路径中的位置
朴素贝叶斯是经典的统计机器学习算法,是学习AI的基础起点。它位于从经典机器学习到深度学习、大语言模型(LLM)的必经之路上。理解朴素贝叶斯有助于建立“从数据中学习统计规律”的思维,这种思维在理解更复杂的神经网络时至关重要。此外,分词、停用词、文本向量化等概念,也是自然语言处理(NLP)的基石,在大模型时代的数据预处理中依然通用。 -
5.2 面试价值
- 高频考点:面试中常问的问题是“为什么叫‘朴素’”,考察对“特征条件独立假设”的理解。
- 对比考察:常与其他分类算法(如逻辑回归、SVM)对比,考察各自优缺点和适用场景。
- 场景应用题:垃圾邮件过滤、新闻分类、情感分析等是朴素贝叶斯的经典应用场景,常被用作面试中的案例分析。
- 关键知识点:贝叶斯公式推导、拉普拉斯平滑的作用和原理也是面试官喜欢问的问题。
面试官,您好。关于朴素贝叶斯,我认为它的面试价值主要体现在四个层面。下面我逐一展开谈谈我的理解。
-
5.3 面试论述
第一,对“朴素”二字的理解,是考察算法基本功的试金石。
面试官常会直接问:“为什么叫‘朴素’?”这个问题看似简单,但答到什么深度,能直接体现对算法本质的理解。
我会这样回答:朴素指的是特征条件独立假设。意思是,贝叶斯公式本身是正确的,但在实际计算P(W|C)即“给定类别下特征出现的概率”时,如果特征之间有依赖关系,计算会极其复杂。朴素贝叶斯做了一个强假设——假设所有特征之间相互独立。
举个例子,在垃圾邮件分类中,“优惠”和“折扣”这两个词的出现其实是有关联的,但朴素贝叶斯会假设“出现‘优惠’”和“出现‘折扣’”这两个事件独立。这样一来,联合概率P(优惠, 折扣|垃圾邮件)就可以直接简化成P(优惠|垃圾邮件) * P(折扣|垃圾邮件),计算量从指数级降到了线性级。
这里还有一个容易掉进去的坑:有些人会说“朴素贝叶斯假设样本之间独立”,这是错的。样本之间本来就是独立采集的,不需要“假设”。朴素贝叶斯假设的是特征之间独立。把这个区分清楚,基本就能过关了。
第二,能和其他分类算法做对比,体现算法选型能力。
面试官问完原理后,通常会追问:“它和逻辑回归、SVM有什么区别?什么时候用朴素贝叶斯?”
这个问题我的回答框架是:从模型本质、适用场景、优缺点三个维度来对比。
从本质上讲,朴素贝叶斯是生成式模型,它学习的是数据的联合分布P(X, Y);而逻辑回归是判别式模型,直接学习决策边界P(Y|X)。这决定了它们在数据需求和性能上的差异。
在优缺点和场景上,朴素贝叶斯最大的优势是快。因为计算就是概率连乘,参数少,训练速度极快,而且在小数据集上也能工作得很好。比如做一个邮件系统的垃圾过滤,每天新增数据量不大,上线速度要求高,朴素贝叶斯就是首选。另外,它对缺失值也不太敏感。
相比之下,逻辑回归的可解释性强,SVM在高维稀疏数据上表现优异,但它们的计算复杂度通常更高,对数据量也有更高要求。如果数据量足够、特征也经过了精心的线性处理,逻辑回归通常效果更好。朴素贝叶斯的硬伤就是那个“特征独立”假设,现实中很少完全满足,所以当特征关联性强时,它的效果会打个折扣。
第三,能落地到具体场景题,展示解决问题的能力。
这是面试中的重头戏。考官给一个具体场景,让你从头到尾讲怎么做。比如经典题:“设计一个垃圾邮件过滤系统”。
我会这样构建回答:
第一步是定义问题。这是一个典型的二分类问题,可以用朴素贝叶斯来解决,因为它本来就是做这个的鼻祖算法,而且很合适。
第二步是数据处理和特征工程。我会先对邮件文本做分词。中文用结巴分词,英文更简单些。分词后要加载停用词表来做数据清洗,把“的、了、吗、呢”这些没用的虚词和标点符号去掉,留下有实际含义的词。
第三步是特征向量化。用CountVectorizer或TF-IDF将每条邮件转换成一个词频向量。这个向量就是特征矩阵X。同时把“垃圾邮件/正常邮件”的标签转换成 1 和 0,作为目标变量Y。
第四步是套用朴素贝叶斯公式。预测一封新邮件时,核心是比较P(垃圾|词向量)和P(正常|词向量)哪个更大。根据贝叶斯公式,主要是计算先验概率P(类别)和条件概率P(词|类别)的乘积。计算条件概率时,如果某个词在训练集垃圾邮件里没出现过,它的概率会是0,这会导致连乘结果全部为0。所以必须引入拉普拉斯平滑,在分子分母上加一个很小的常数,一般设为1。
第五步是评估。用准确率、精确率、召回率这些指标来看效果,特别是垃圾邮件,宁可不进垃圾箱也不要误杀重要邮件,所以召回率或F1值会更重要。实际部署时,模型训练好后要保存下来,新邮件来了直接加载模型预测,不用重复训练。
第四,能讲清楚公式推导和平滑原理,体现数理基础。
有些面试官喜欢深挖公式,考察你的数学功底。
对于贝叶斯公式推导,我不会上去就默写公式,而是讲逻辑:贝叶斯公式其实就来自联合概率的恒等变形。P(AB)既可以写成P(A) * P(B|A),也可以写成P(B) * P(A|B)。这两个写法是等价的。把它们连起来,两边同除以P(B),就得到了贝叶斯公式。换到机器学习的符号,A是类别C,B是特征W,就是P(C|W) = P(W|C) * P(C) / P(W)。这个推导过程是唯一需要记住的数学点。
对于拉普拉斯平滑,我会用一个数字例子说明:假设训练集里所有好评都恰好没提到“糟糕”这个词,那P(糟糕|好评)就等于零。如果不加平滑,即使其他词看起来很正面,因为这一个零,整个连乘后验概率就是零了,这显然不合理。拉普拉斯平滑就是在分子上加1,分母上加特征总数(或一个系数),避免极端概率。这本质上是给先验知识留了余地,是一种统计学上的收敛技巧。
以上就是我对朴素贝叶斯面试价值的理解。如果您对某个点想深入了解,我可以再展开。 -
5.4 后期学习铺垫
- 其他分类算法:为学习逻辑回归、决策树、支持向量机(SVM)等分类算法打下基础。
- NLP进阶:文本分词、向量化(如TF-IDF,Word2Vec)是进阶NLP学习的前置知识。
- 生成式模型:朴素贝叶斯是一种生成式模型,理解它有助于后续学习更复杂的生成式模型。
二、聚类算法与K-Means课程笔记总结
1. 聚类算法核心概念
聚类是一种无监督学习方法,旨在没有先验知识(标签)的情况下,根据数据样本间的相似性将数据集划分成不同的组或“簇”。
-
1.1 什么是聚类
- 定义:无监督学习,数据集只有特征(feature),没有标签(label)。算法根据样本之间的相似性,自动发现数据集的内在结构,并将其划分到不同类别中。
- 核心思想:簇内高内聚,簇间低耦合。即同一个簇内的样本点要尽可能相似(距离近),不同簇的样本点要尽可能不同(距离远)。
- 相似性度量:最常用的方法是计算距离。距离越近,相似性越高。常见的距离计算公式有:
- 欧式距离:对应坐标差值的平方和开根号(勾股定理),应用最普遍。
- 曼哈顿距离:对应坐标差值的绝对值求和(城市街区距离)。
- 切比雪夫距离:取所有坐标差值中的最大值。
- 应用场景:主要应用于项目初期,当没有明确标签时进行探索性分析。后期随着数据积累和标签明确,会过渡到分类模型。
- 用户画像:根据用户行为习惯,对用户进行分群,打上不同标签。
- 广告推荐:将相似兴趣的用户聚为一类,进行精准推送。
- 图像分割:将图像中的像素点根据颜色、纹理等特征进行聚类,以识别物体轮廓。
- 异常检测:如信用卡异常消费识别,异常点会远离正常聚类簇。
-
1.2 聚类分类与K-Means算法
- 常见聚类算法:K-Means(基于质心)、层次聚类、DBSCAN(基于密度)、谱聚类。
- K-Means算法原理:
- 核心:基于质心进行划分。质心是簇的中心点,不一定是真实存在的样本点,而是通过计算得出的虚拟点。
- 实现流程:
- 初始化:事先确定常数
K(即簇的数量),并随机选择K个样本点作为初始质心。 - 分簇:计算每个样本点到
K个质心的距离,将样本点划分到距离最近的质心所在的簇中。 - 更新质心:根据分好的簇,重新计算每个簇的质心(计算簇内所有样本点在每个维度上的均值)。
- 迭代收敛:重复步骤2和3,直到质心不再发生变化或变化极小,算法收敛,聚类完成。
- 初始化:事先确定常数
2. 聚类效果评估方法
由于没有真实标签,需要特定的指标来评估聚类效果的好坏和选择最佳的K值。
-
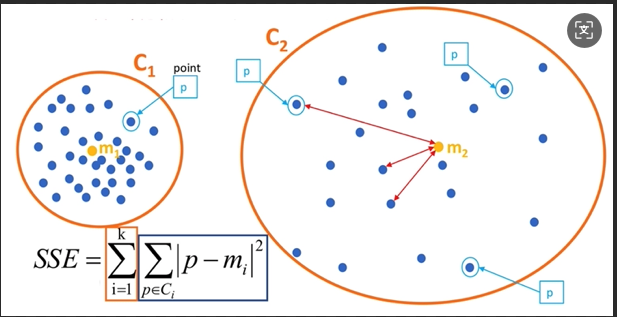
2.1 误差平方和 (SSE, Sum of Squared Error)
-
公式理解:计算所有簇内的每个样本点到其所属质心的距离的平方之和。
SSE = Σ(每个簇) Σ(簇内的每个样本 - 该簇质心)² -
评估标准:SSE值越小越好。越小,代表簇内样本点越聚集,内聚程度越高。
-
极限情况:当
K(簇的数量)等于样本总数N时,每个样本自成一组,质心就是它自己,距离为0,此时SSE达到最小值0。但这不是我们想要的聚类结果。 -
肘部法 (Elbow Method):用于寻找最佳的
K值。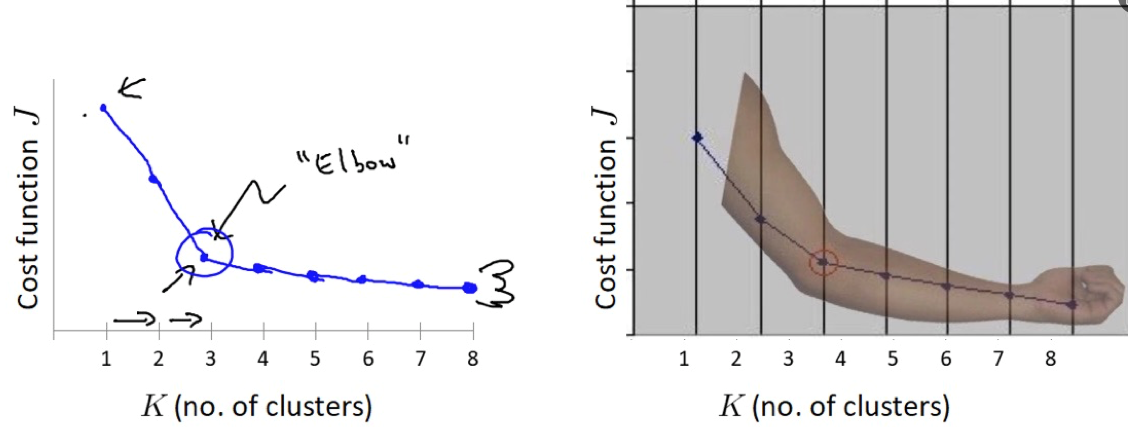
- 核心思想:计算
K从1到n取值时的SSE,并绘制SSE随K值变化的折线图。随着K值增大,SSE会持续下降。 - 最佳K值选择:当SSE的下降率突然变缓,出现类似肘部的拐点时,该拐点对应的
K值就是最佳的聚类数。因为之后再增加K值,带来的SSE下降收益会显著减小。
- 核心思想:计算
-
-
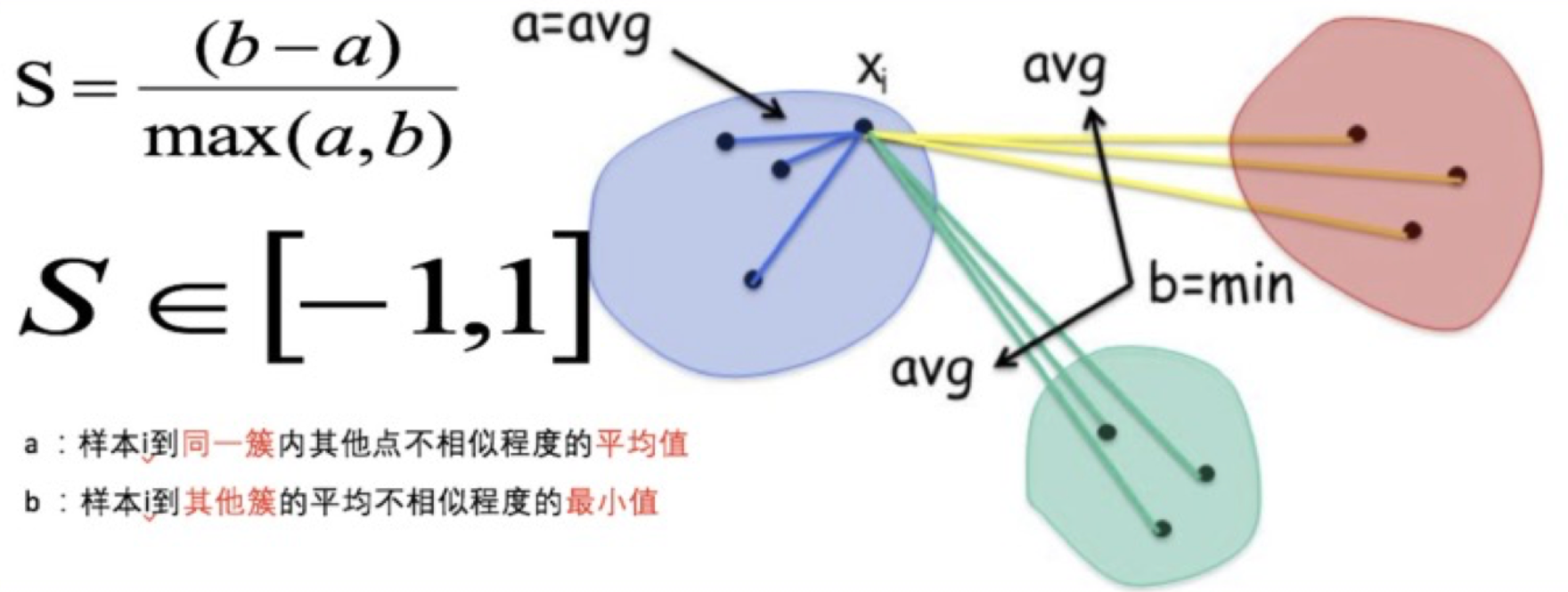
2.2 轮廓系数 (SC, Silhouette Coefficient)
- 核心思想:综合考虑了簇内聚集度与簇间分离度。
- 公式理解:
S = (b - a) / max(a, b)a:样本i到同一簇内其他所有样本的平均距离,衡量簇内不相似度。a越小越好。b:样本i到距离最近的其他簇内所有样本的平均距离,衡量簇间不相似度。b越大越好。
- 评估标准:SC值取值范围为[-1, 1],值越接近1越好。表示簇内距离远小于簇间最小距离,聚类效果优异。计算SC值至少需要2个簇。
-
2.3 CH系数 (Calinski-Harabasz Index)
- 核心思想:在SC的基础上,进一步引入了质心数量
K作为惩罚项,全面评价聚类效果。 - 公式理解:
CH = [ SSB / (K-1) ] / [ SSW / (N-K) ], 其中N为样本总数。SSW(Within-cluster sum of squares):簇内误差平方和,等同于SSE,越小越好。SSB(Between-cluster sum of squares):簇间方差,是所有簇的质心到整个数据集中心点距离的平方加权和,越大越好。K:质心个数,作为分母项(N-K),使得在追求更大SSB时不至于无限增大K。
- 评估标准:CH值越大越好。值越大,表示簇内越聚集,簇间越分离,且簇数量越合适。
- 核心思想:在SC的基础上,进一步引入了质心数量
3. 案例:用户数据分群
-
3.1 案例背景
我们拥有一个包含客户ID、性别、年龄、年收入、消费指数的数据集。目标是利用K-Me算法,根据客户的年收入和消费指数这两个特征,将客户划分成不同的价值群体,从而发现如“高收入低消费”、“低收入高消费”等典型用户,以便制定针对性的营销策略。 -
3.2 代码实现
代码分为两步:第一步,利用SSE和SC系数寻找最佳K值;第二步,使用最佳K值进行聚类和可视化。
# 环境设置:解决新版sklearn多线程警告
import os
os.environ["OMP_NUM_THREADS"] = "4"
# 1. 导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 2. 数据加载与特征提取
# 读取客户数据文件
df = pd.read_csv('./data/customers.csv')
# 选取特征,这里采用年收入(第3列)和消费指数(第4列)作为聚类依据
# 注意:iloc[:, 3:5]表示获取所有行,第3列和第4列的数据(左闭右开,实际是索引3和4的列)
X = df.iloc[:, 3:5].values
# ========================= 阶段一:寻找最佳K值 =========================
def find_optimal_k():
sse_list = [] # 用于存储不同K值对应的SSE
sc_list = [] # 用于存储不同K值对应的轮廓系数
# 因为轮廓系数需要考虑簇间距离,至少需要2个簇
for k in range(2, 20):
# 创建KMeans模型对象
# n_clusters: 簇的数量
# max_iter: 最大迭代次数
# random_state: 随机种子,确保结果可复现
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
# 模型训练与预测
y_predict = estimator.fit_predict(X)
# 1. 获取SSE值:使用模型的inertia_属性
sse_list.append(estimator.inertia_)
# 2. 获取SC值:使用silhouette_score函数
sc_list.append(silhouette_score(X, y_predict))
# 可视化SSE与K值的关系图 (肘部法)
plt.figure(figsize=(10, 6))
plt.plot(range(2, 20), sse_list, marker='o', linestyle='--')
plt.title('Elbow Method for Optimal K (SSE vs K)')
plt.xlabel('Number of clusters (K)')
plt.ylabel('SSE')
plt.grid(True)
plt.show()
# 可视化轮廓系数与K值的关系图
plt.figure(figsize=(10, 6))
plt.plot(range(2, 20), sc_list, marker='o', linestyle='--', color='orange')
plt.title('Silhouette Score for Optimal K (SC vs K)')
plt.xlabel('Number of clusters (K)')
plt.ylabel('Silhouette Score')
plt.grid(True)
plt.show()
# 调用函数寻找最佳K值
find_optimal_k()
代码补充说明:
- SSE & 肘部法图解读:从输出图表中可以看到,SSE随着K增大而减小。在
K=5时,曲线有一个明显的拐点,之后下降趋势变缓。 - SC系数图解读:轮廓系数在
K=5时达到一个较高的峰值,表明此时的聚类结果在簇内紧密度和簇间分离度上取得了最佳平衡。 - 结论:综合两个指标,我们确定
K=5是最佳的聚类数目。
# ========================= 阶段二:使用最佳K值进行聚类与可视化 =========================
# 设定找到的最佳K值
optimal_k = 5
# 创建并训练最终的K-Means模型
estimator_final = KMeans(n_clusters=optimal_k, max_iter=100, random_state=23)
y_final_predict = estimator_final.fit_predict(X)
# 绘制聚类结果图
plt.figure(figsize=(12, 8))
# 为每个簇绘制散点图,并设置图例
# estimator_final.labels_ 包含每个样本的聚类标签 (0,1,2,3,4)
# 解释复杂代码:X[y_final_predict == 0, 0] 表示在X中筛选出预测标签为0的行,并取这些行的第0列(年收入)
labels = ['Standard', 'Careful', 'Sensible', 'Careless', 'Target'] # 自定义标签,需根据实际聚类中心含义调整
colors = ['purple', 'green', 'blue', 'orange', 'red']
for i in range(optimal_k):
plt.scatter(
X[y_final_predict == i, 0], # X轴:年收入
X[y_final_predict == i, 1], # Y轴:消费指数
s=100, # 点的大小
c=colors[i], # 点的颜色
label=f'Cluster {i} - {labels[i]}' # 图例标签
)
# 绘制每个簇的质心
centroids = estimator_final.cluster_centers_
plt.scatter(
centroids[:, 0], # X轴:质心年收入
centroids[:, 1], # Y轴:质心消费指数
marker='*', # 质心标记样式
s=300, # 质心大小
c='black', # 质心颜色
edgecolor='white',
label='Centroids' # 图例标签
)
# 设置图表信息
plt.title('Clusters of Customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend(loc='lower right') # 显示图例,并设置位置
plt.grid(True)
plt.show()
代码补充说明:
- 散点图绘制:通过
X[y_final_predict == i, 0]这种花式索引的方式,从特征矩阵X中筛选出属于特定簇的样本。X是一个二维数组,第一列是年收入,第二列是消费指数。这个操作结合了布尔索引和列索引。 - 质心绘制:
estimator_final.cluster_centers_返回一个形状为 (5, 2) 的数组,包含了5个质心的坐标。我们在散点图上用黑色的大五角星标记出来。 - 结果分析:
- 右上角 (Target - 红色):高收入,高消费。这是最有价值的“黄金客户”群。
- 左上角 (Careless - 橙色):低收入,高消费。虽然有消费意愿但能力有限,可适当推荐分期或性价比高的产品。
- 中间 (Standard - 紫色/蓝色):中等收入,中等消费。这是最大众化的标准客户群。
- 右下角 (Sensible - 蓝/绿色):高收入,低消费。有很强消费能力但较节俭,是需要挖掘潜力的客户群。
4. 课后分析
-
4.1 在AI大模型学习路径中的位置
聚类是机器学习中无监督学习的代表算法,它在AI学习路径上起到了衔接和补充的作用。在学习完大量的有监督学习(分类、回归)后,聚类为我们展示了另一片天地:当世界没有标准答案(标签)时,算法如何从数据本身发现规律。这种思维是理解更复杂模型的基石,例如深度学习中自编码器、生成对抗网络(GANs)等无监督或半监督模型,其思想源头都可以追溯到聚类。 -
4.2 面试价值
- 概念辨析题:“请简述K-Means的算法流程。” 这是送分题,必须倒背如流。
- 对比与选择:“K-Means算法有什么优缺点?在面对什么场景时会失效?”
- 主要缺点:需要预先指定K值,对初始质心敏感,不适合发现非球状(如月牙形)的簇,对噪声和异常值敏感。
- 评估方法题:“你是如何确定K-Means中K的取值的?” 这考察你是否知道肘部法、轮廓系数、CH指数,并能讲清它们的原理和区别(SSE只考虑簇内,SC联合考虑簇内和簇间)。
- 场景应用题:“设计一个对用户进行分群的方案。” 这考察从特征选择、数据预处理、模型选择、到评估与解释的完整项目落地能力。
-
4.3 面试题论述性回答
第一,对算法原理与流程的扎实掌握,是理论知识体系的试金石。
面试官可能会直接问:“请简述K-Means算法的完整流程。” 这个问题看似基础,但能清晰、完整、有逻辑地讲下来,直接体现你对无监督学习核心思想的理解深度。
我会这样组织回答:
首先,K-Means解决的是一个“如何在没有标签的情况下自动分组”的问题。它的核心思想很朴素:先猜中心,再迭代优化。
具体流程我总结为四步循环:
- 初始化:预先设定要分成几个组,也就是
K值。然后算法会随机挑选K个样本点作为初始的质心,也就是簇的中心。这里强调一点,初始质心是随机选的,这也为后面“对初始值敏感”这个缺点埋下了伏笔。 - 分簇:计算数据集中每一个样本点到这
K个质心的距离。通常是欧式距离。哪个质心离得近,就把这个样本点划到哪个簇里。这就像班里分小组,大家会本能地站到离自己最近的组长身边。 - 更新质心:所有人都站好队之后,组长的位置就不再合适了。算法会重新计算每个簇内所有点的均值中心,把这个均值点作为新的质心。这里要强调,新的质心不一定是个真实存在的样本点,它是一个计算出来的虚拟点。
- 迭代收敛:拿着新的质心,回到第二步重新分簇,分完再更新质心。如此循环,直到质心不再发生变化,或者变化极小,就说明算法收敛了,每个簇内的点都紧紧地围绕在自己的中心周围,聚类完成。
如果能把这四步逻辑清晰地讲出来,特别是点出“新质心不一定是真实样本点”这个细节,基础原理这关就算过了。
第二,能与其他算法进行对比分析,体现算法选型能力和优缺点的深刻认知。
面试官常会追问:“K-Means有什么优缺点?在什么场景下会失效?”
我的回答框架是:先讲优点,再讲缺点,每个缺点最好能带出一个能弥补它的算法,形成知识体系。
优点方面:
-
原理简单,实现快:就是算距离、找均值,没有复杂的数学推导,收敛速度快。
-
可解释性强:聚类结果就是哪个点离哪个中心近,非常直观,容易向业务方解释。
-
适合大数据集:只要
K值不太大,处理大规模数据的效率相对较高。
缺点方面,我会重点展开: -
第一,
K值需要预先指定,且对初始值敏感。
这是K-Means最核心的痛点。怎么解决?可以从两个层面来回答:- 用评估指标确定K值:我们可以跑一个循环,让
K从2到N都试一遍。然后用肘部法看SSE曲线在哪个K值处陡然变缓,或者用轮廓系数和CH指数找最大值。这三种方法联合起来选出的K值是比较可靠的。 - 用算法优化初始值:传统的K-Means是随机选初始点,容易陷入局部最优。它的一个改进算法叫K-Means++,核心思想是让初始质心尽可能离得远,这样收敛更快、结果更稳定。现在Scikit-learn里KMeans的
init参数默认就是k-means++。
- 用评估指标确定K值:我们可以跑一个循环,让
-
第二,只适合发现球状簇,对噪声和异常值敏感。
因为是基于距离均值的,所以它很容易被一些极端的异常点带偏,也很容易把一个月牙形的数据硬切成两块。这时我会引出另一个算法——DBSCAN,它是一种基于密度的聚类。它不要求簇是圆形的,还能自动识别噪声点,刚好能弥补K-Means在这方面的不足。这就体现了你的算法体系感,不是在背孤立的点。
第三,能完整设计并落地一个场景化应用,展示综合解决问题的能力。
当被问到场景题,比如“如何对电商用户进行分群”时,我会按照一个完整的机器学习项目流程来展开,展示我的工程落地能力。 -
第一步,业务定义与特征选择。 首先明确目标,是区分用户的价值。接着选特征,思路是可以选年收入(购买力)和消费指数(购买意愿)这两个核心指标。
-
第二步,数据处理。 一般会先用
pandas加载数据。因为收入和消费的尺度可能不一样,所以通常会先做标准化,消除量纲影响。 -
第三步,模型选择与K值确定。 场景中我们不知道分几类,所以要用
for循环来筛选K值。同时计算SSE和轮廓系数,画出它们的曲线图,综合找到一个既不至于太碎、簇内又足够聚集的最佳K值。 -
第四步,训练与结果分析。 拿到最佳
K后,训练最终的模型。核心是会把聚类结果画成散点图,并标上质心。然后对着图给业务方解释:“右上角这群人,赚钱多花钱也多,是黄金用户;右下角赚钱多但花钱少,需要我们发优惠券去激活。” -
第五步,效果验证与迭代。 聚类是无监督的,效果不直观。除了看评估指标,我还会用交叉表来验证:比如分完组后,看看各组在性别、年龄等未参与聚类的特征上是否有显著差异,以此来佐证分群的有效性。如果模型要反复上线使用,我还会考虑用
joblib把它持久化保存下来,避免每次预测都重新训练。
第四,能深挖评估指标的原理与差异,展现内功和数学直觉。
面试官如果继续深挖:“肘部法、轮廓系数、CH指数,为什么都能用来找K?它们有什么区别?” 这问到根上了。 -
1. 误差平方和 SSE(用于肘部法)
它衡量的是簇内的紧凑度。计算方法是每个点到其质心距离的平方和。所以它天生就是K的单调递减函数,K越大,SSE越小。我们找肘部点,就是找边际收益递减的那个临界点。它的局限是只考虑内聚,不考虑分离。 -
2. 轮廓系数 SC
它进步了,同时考虑了内聚和分离。公式是(b-a) / max(a, b)。a是样本到同簇其他点的平均距离,小了说明内聚好;b是样本到最近其他簇所有点的平均距离,大了说明分离好。所以这是一个“分得开、聚得拢”的综合指标,取值在-1到1之间,越大越好。它弥补了SSE只看对内的缺点。 -
3. CH指数 (Calinski-Harabasz Index)
这个考虑得更全面,它把簇的数量K也作为一个惩罚项加入了。简单来说,CH值是(簇间方差 / 簇内方差)再乘上一个关于K的系数。这意味着,你如果为了减小簇内距离而无限加大K值, CH指数会因为K变大而给你惩罚。从而找到一个最均衡的点。这三个指标从只对内、到内外兼顾、再到带参数惩罚,是一个逐步完善、层层递进的关系。
- 4.4 后期学习铺垫
- 其他聚类算法:K-Means之后,自然会引出能自适应形状的DBSCAN和能生成层次树状图的层次聚类。
- 降维算法:在进行高维聚类时,常需要先用PCA(主成分分析)或t-SNE进行降维或可视化。本节课的聚类为学习这些降维算法提供了直接的应用场景。
- 推荐系统基础:用户分群是推荐系统中“基于用户的协同过滤”的一个基础步骤,理解聚类为后续深入推荐系统领域打下了基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)