在AI时代构建独属于自己的工作流
前言
时代的发展太快了,尤其AI还添了一把烈火。要学的东西太多了,学是学不完的,只能浅尝一下,寻其本质
唯一的感悟是
哈哈,只要你学的慢,就不用学了
AutoGen
一个用于原型设计和管理代理的应用,无需编写代码。 基于AgentChat构建。
使用以下命令构建,我们采用conda创建纯净环境,防止影响系统环境
conda create -n AutoGen python=3.10
conda activate autogen
pip install -U autogenstudio
# 安装完成后,启动,默认http://127.0.0.1:8081
autogenstudio ui
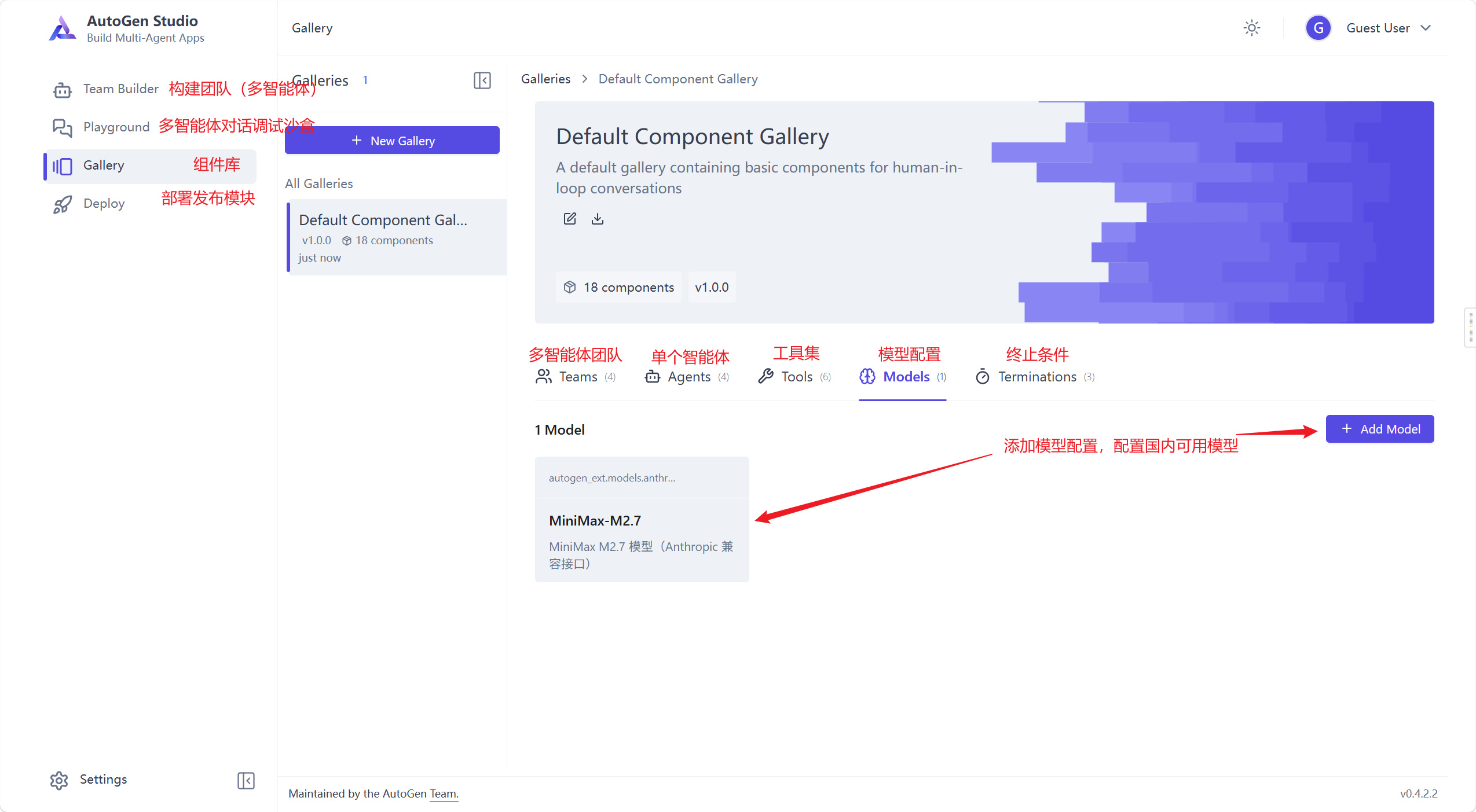
这里配置模型的时候,使用json配置,内容如下
{
"provider": "autogen_ext.models.anthropic.AnthropicChatCompletionClient",
"component_type": "model",
"version": 1,
"component_version": 1,
"description": "MiniMax M2.7 模型(Anthropic 兼容接口)",
"label": "MiniMax-M2.7",
"config": {
"model": "MiniMax-M2.7",
"api_key": "your api key",
"base_url": "https://api.minimaxi.com/anthropic",
"model_info": {
"family": "minimax",
"function_calling": true,
"vision": false,
"json_output": true,
"structured_output": true,
"max_tokens": 64000
}
}
}
同样的,我们可以配置Agents智能体、Tools工具、Terminations终止条件
然后可以在Team Builder中构建团队,比如我们选在已有的RoundRobin Team进行构建,这是轮询调度Agent,会交替开启不同的Agent。
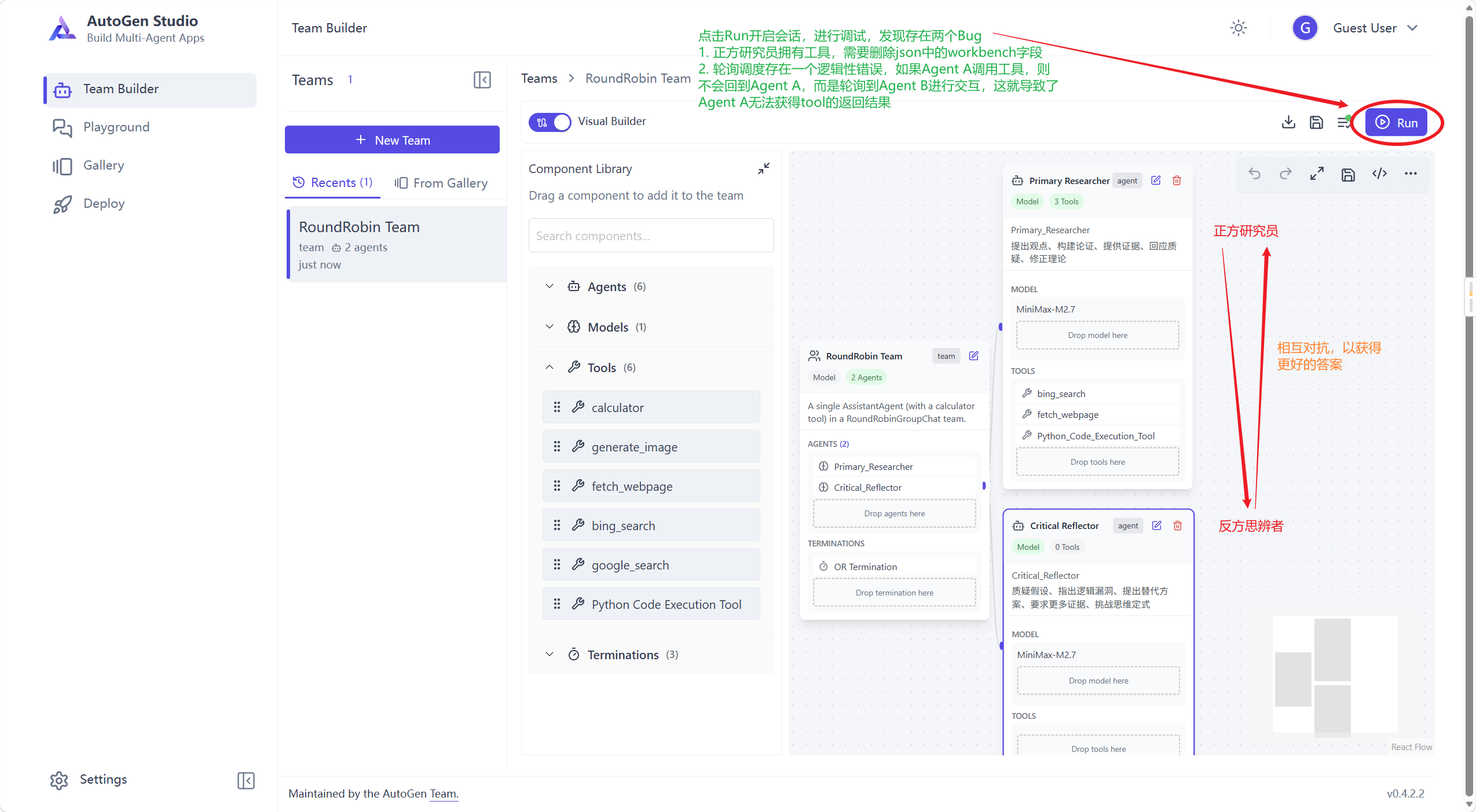
这个时候,我们可以在已搭建好的Team中打开会话进行交互,可以看到,每轮对话都展现出Agent相互之间的交互,可以快速调试Team,迭代产品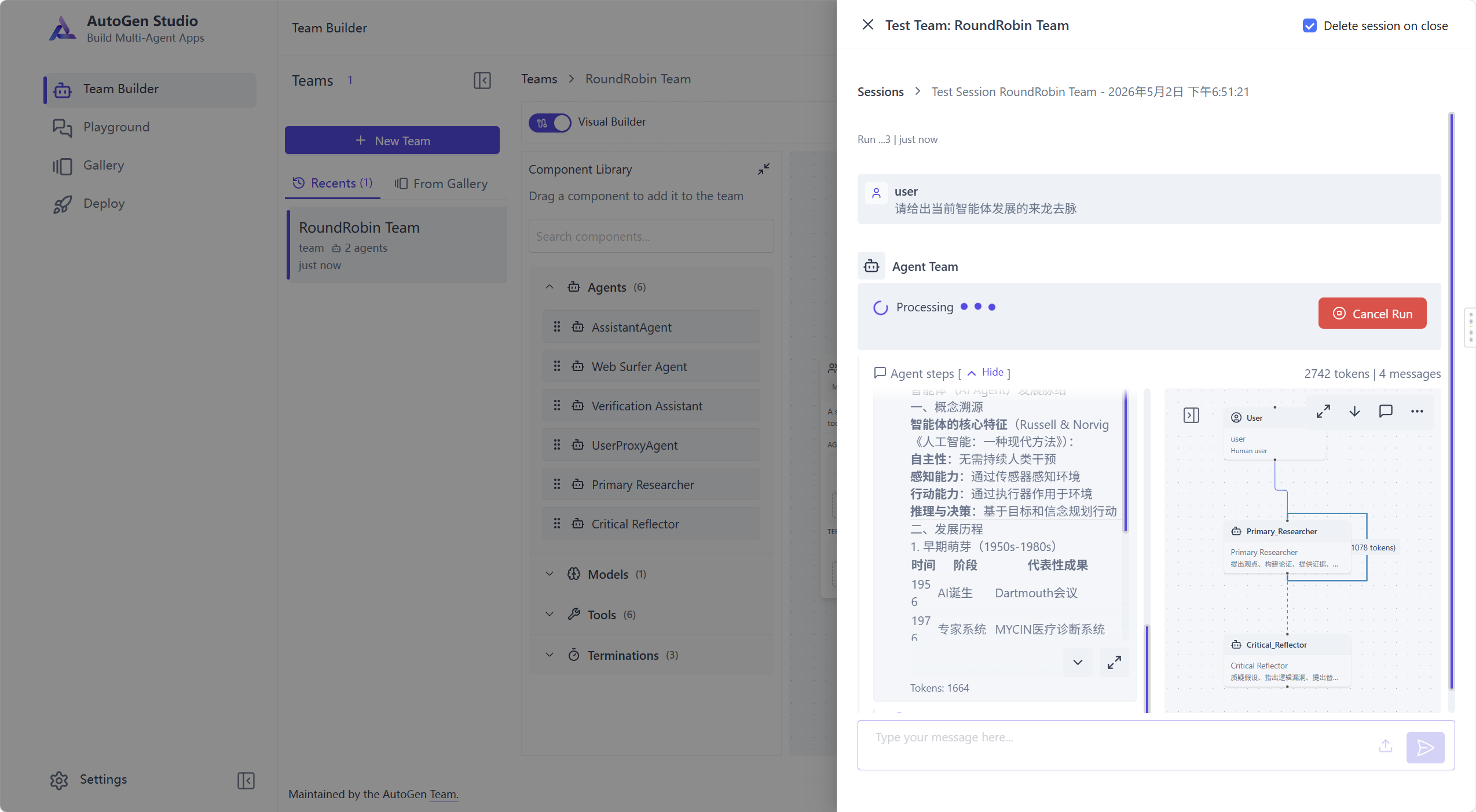
不过发现了一个严重bug,就是图形化界面所搭建的Team会把工具调用当成“独立轮次”,从而导致轮询错位,尝试了使用不同架构,这个问题依然存在
不建议使用图形化界面,感觉明显是半成品的展示,无法满足定制Team的需求。整体而言,感觉还是LangChain、LangGraph更好用
Coze
字节跳动推出的低代码AI智能体开发平台,通过可视化界面快速创建具备对话、联网搜索、文档问答、流程自动化等能力的AI助手。
如下,进入扣子编程,可以快速开发各个不同方向的应用,这里是新版,大幅降低了组件式方式,而是采用了自然语言对话交互。
比如这里我想要做个网页上的Linux系统,全程自动做完,看起来还不错,不过测试还是有很多问题的,而且一句话花费了大概1500积分。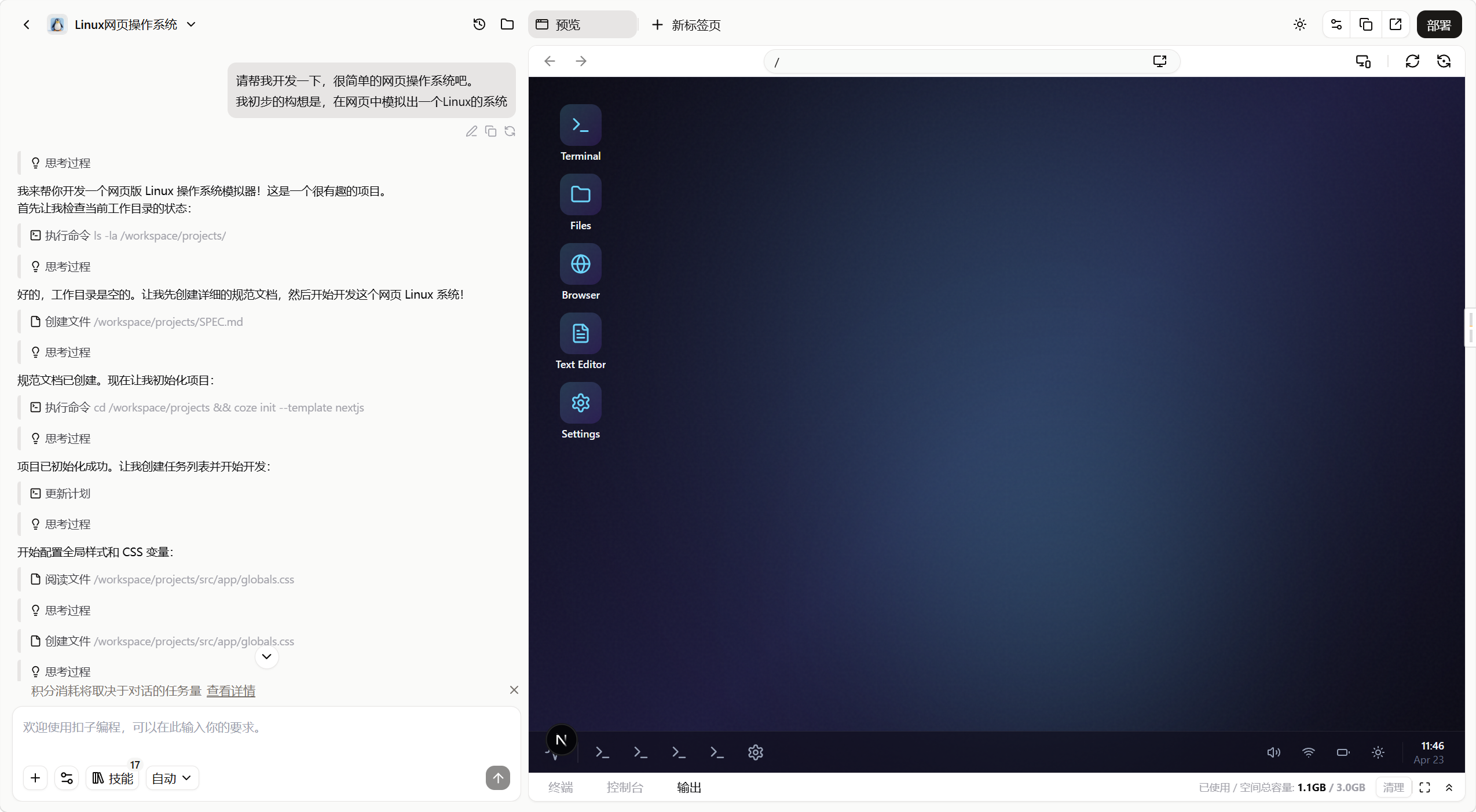
再比如,这里我制作了一个消息精选智能体,成功捕获到最新咨询,花费大概600积分。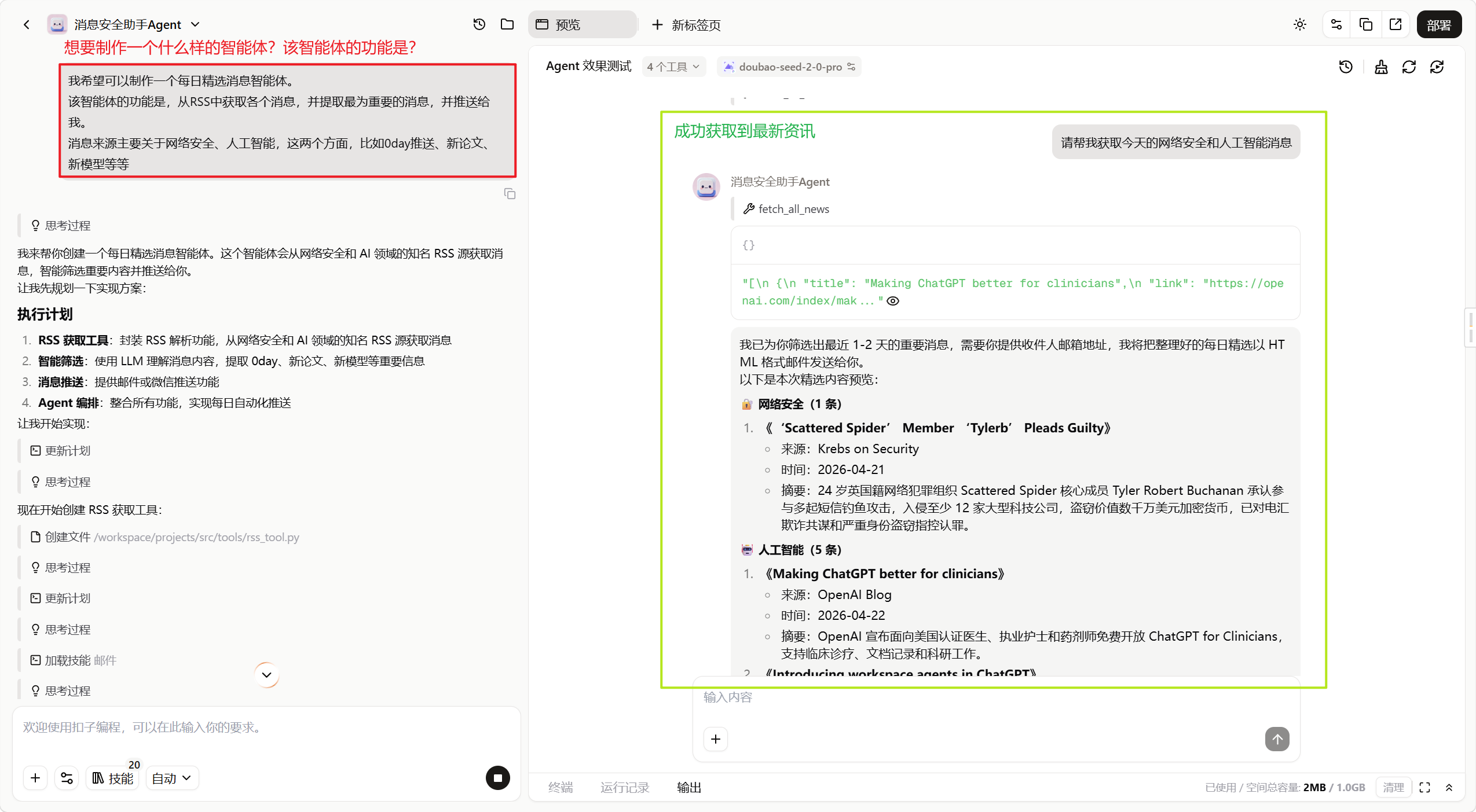
Dify
一款开源的LLM应用开发平台,可视化拖拽,可快速搭建含RAG知识库、Agent智能体、工作流的生产级AI应用。
使用docker启动,如下所示
我们可以安装插件,插件市场中有很丰富的工具,如下我们导入了外部模型供应商,此时我们的基座模型便可以使用外部模型

此后,我们便可以构建工作流,而且自带知识库的构建方式,这对于构建知识库来说极为方便,这是优点
构建知识库,可以从本地,云,Web站点不同方式导入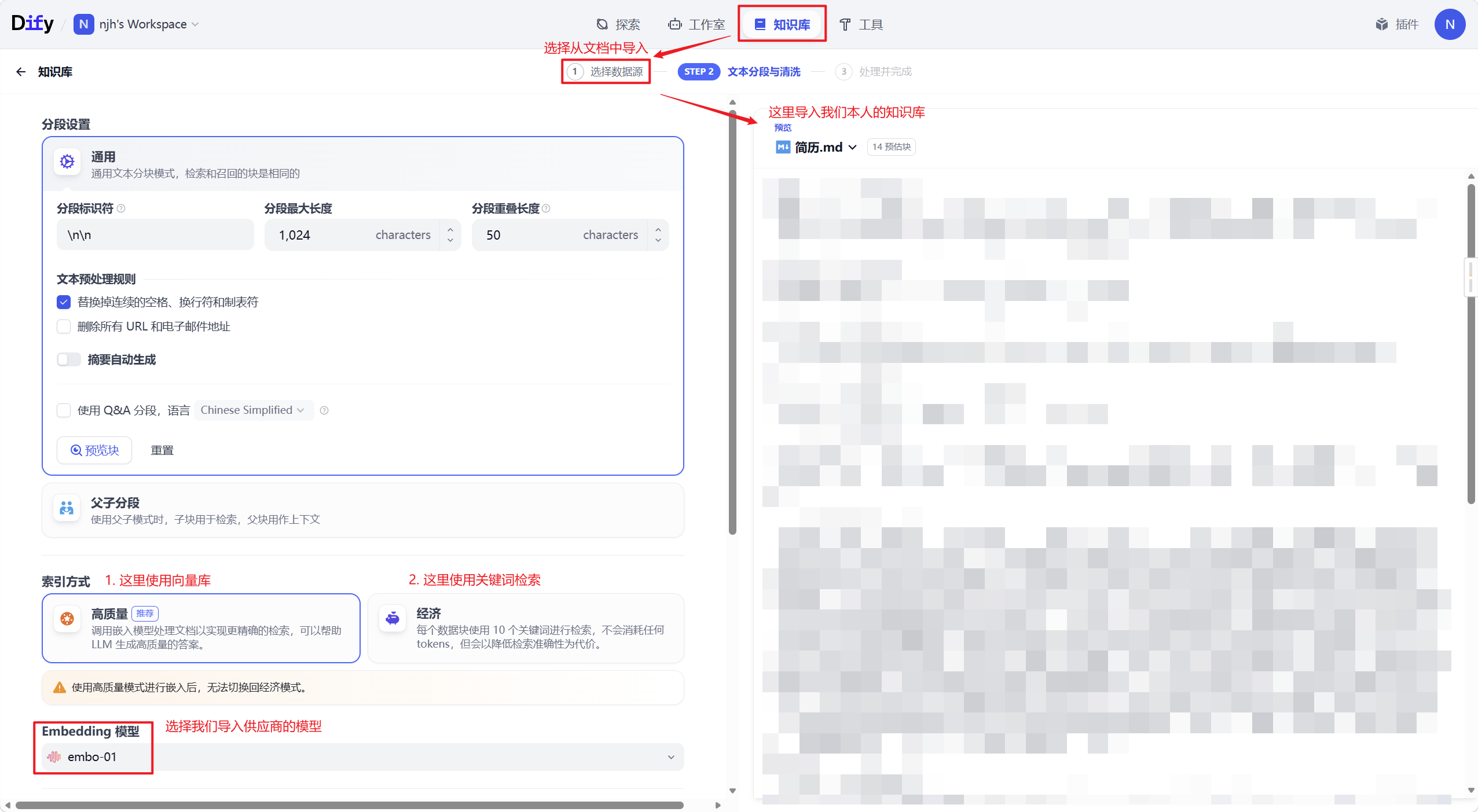
我们可以自行搭建流程,或使用他人已搭建好的workflow
n8n
使用docker启动n8n项目,这里我们设置环境变量N8N_SECURE_COOKIE=false,从而可以使用http协议访问
root@iZ2ze12ce8ezgbw79em9ilZ:~# docker run -d --restart always --user root -p 8000:5678 -v ~/.n8n:/home/node/.n8n -e N8N_SECURE_COOKIE=false n8nio/n8n
Unable to find image 'n8nio/n8n:latest' locally
latest: Pulling from n8nio/n8n
e5fa8e894bad: Pull complete
02a129e7c0d5: Pull complete
f9a468cfb60d: Pull complete
aa8a6d834d6b: Pull complete
a8081f27e0c3: Pull complete
d133c4510efb: Pull complete
6a72349448c8: Pull complete
4f4fb700ef54: Pull complete
28e1e17b5fb8: Pull complete
7af75743a23f: Pull complete
036a8be28d69: Pull complete
3a90c83c8cd6: Download complete
Digest: sha256:81dc967a062bf267d6aa827e5dfb492ce80e366e77f3b8051c07970a653fb69a
Status: Downloaded newer image for n8nio/n8n:latest
154bec0f0707ffb947b1cbb70c4161e7086e4a308bb0d3392c7e04cc3b24e011
root@iZ2ze12ce8ezgbw79em9ilZ:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1252caf58c4d n8nio/n8n "tini -- /docker-ent…" 17 seconds ago Up 16 seconds 0.0.0.0:8000->5678/tcp, [::]:8000->5678/tcp great_hermann
启动成功后,访问网页,设置账户密码,登录之后界面如下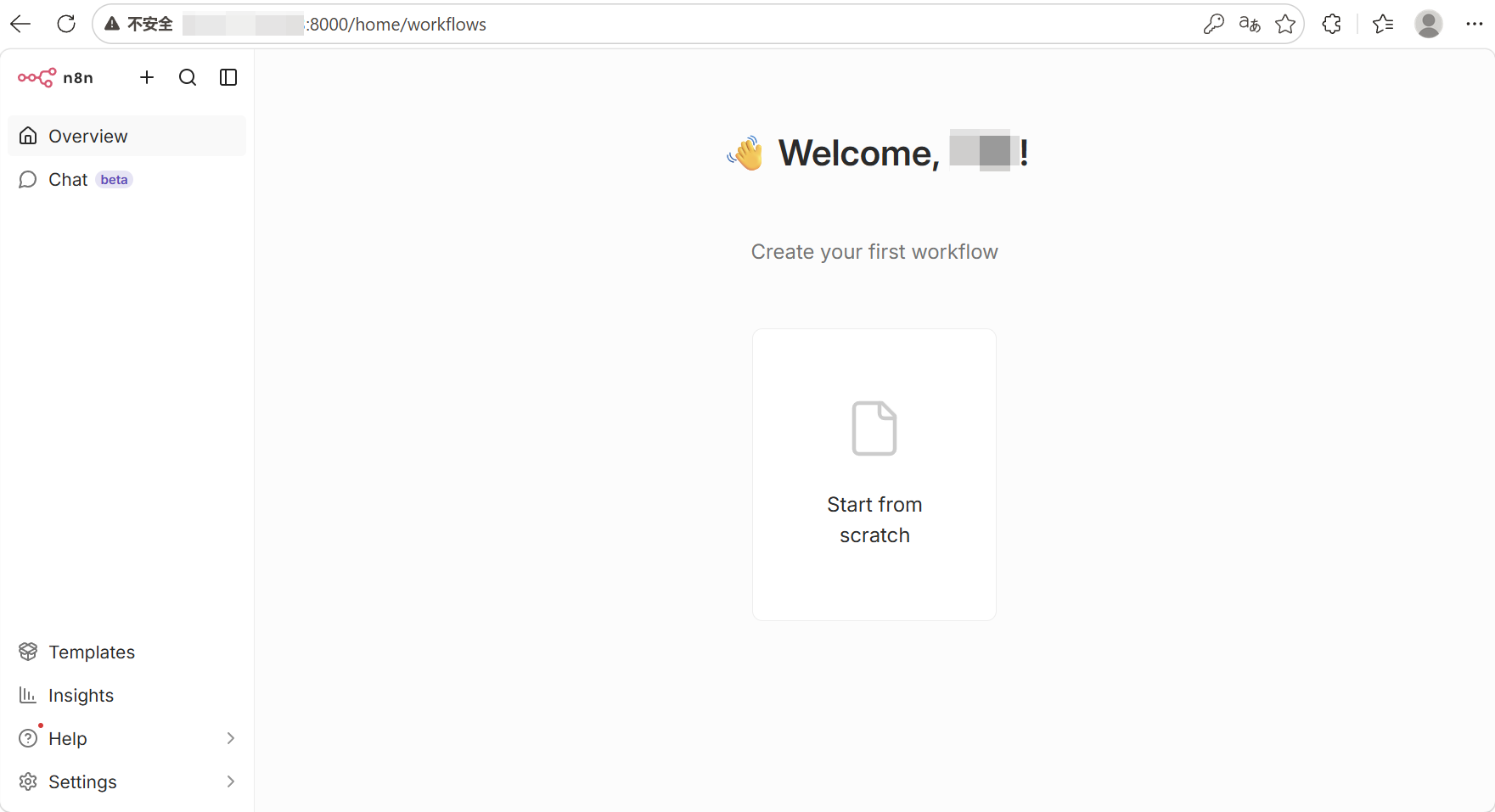
接下来,我想要切换中文,我们使用该项目中的语言包,使用以下命令重启n8n
root@iZ2ze12ce8ezgbw79em9ilZ:~# docker rm -f $(docker ps -q --filter "ancestor=n8nio/n8n")
root@iZ2ze12ce8ezgbw79em9ilZ:~# docker run -d \
--restart always \
--user root \
-p 8000:5678 \
-v /root/dist:/usr/local/lib/node_modules/n8n/node_modules/n8n-editor-ui/dist \
-v ~/.n8n:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_DEFAULT_LOCALE=zh-CN \
n8nio/n8n
a5b7c5f8b5b88a4c7b1d983fb7672710480ec31f95aee2aba73230863c7ef62d
root@iZ2ze12ce8ezgbw79em9ilZ:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a5b7c5f8b5b8 n8nio/n8n "tini -- /docker-ent…" 3 seconds ago Up 2 seconds 0.0.0.0:8000->5678/tcp, [::]:8000->5678/tcp epic_goldberg
root@iZ2ze12ce8ezgbw79em9ilZ:~#
进行了一番编排,制作了一个每日从RSS源中获取资讯,并交于AI判断,综合多个维度,精选一定数量的资讯,通过邮件发送给每个用户,方便用户实时获取最新资讯。
时间耗费了差不多一天时间,主要是调试整个流程,实际上调试过程挺流畅的,主要在调用模型出了点小故障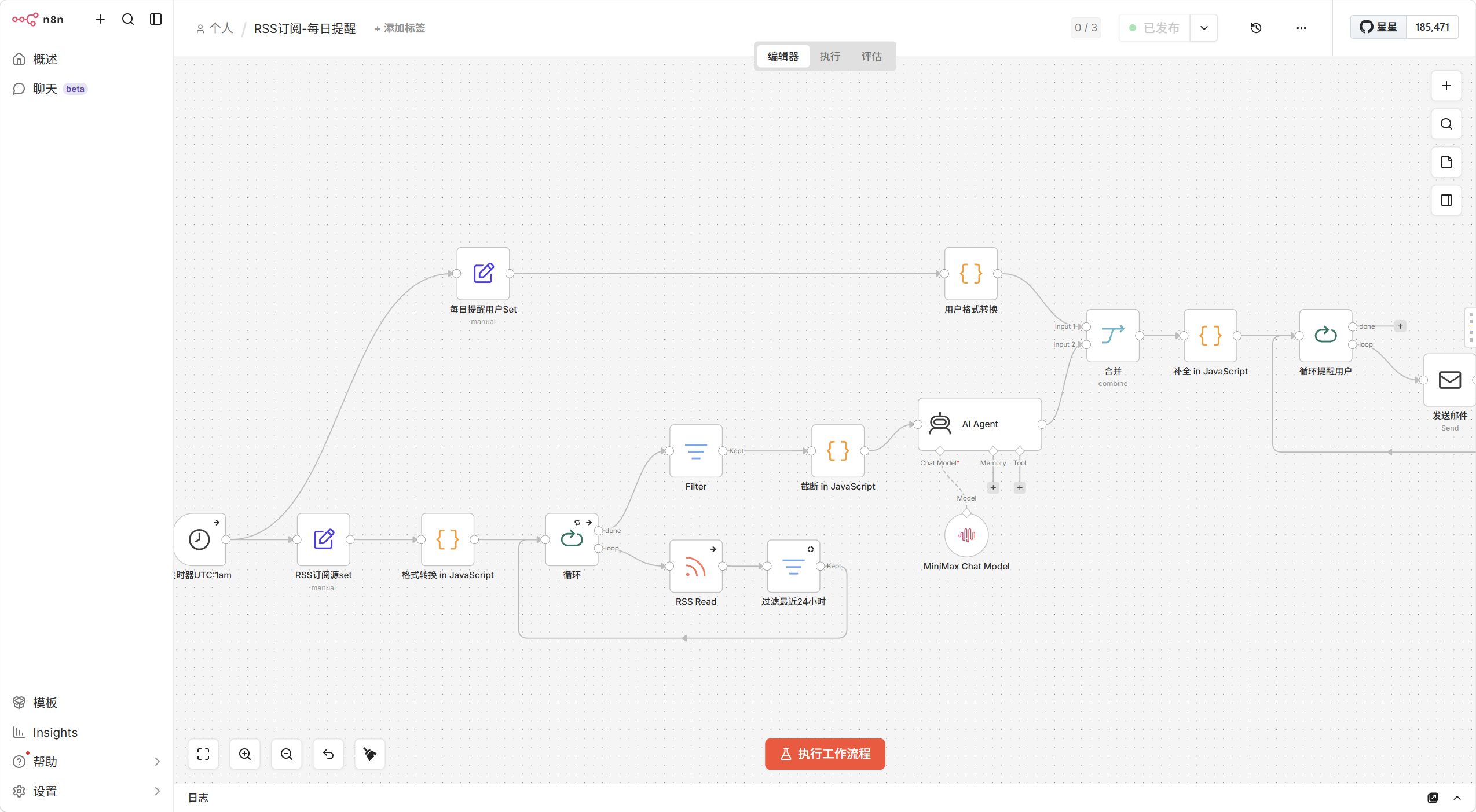
几个小坑:
- 首先测试发现,火山引擎无法通过n8n里面的OpenAI message a model节点进行调用,虽然火山引擎支撑openai格式调用,但在n8n里面却缺少background字段而出现报错。最后使用Agent形式,去调用minimax完成工作流
- 循环节点输出是多个项目,需要合并,否则会反复调用Agent,造成浪费,检查边可以显示当前传递了几个项目
- 记住,节点要设置错误继续,必须要有输出,否则会导致后续节点卡住,从而提前结束工作流
DeepSeek V4
最近DeepSeek V4发布且开源了,我们来研读一下,看看目前的技术演变
-
流形约束超连接 mHC
mHC 是 DeepSeek-V4 解决 60 层以上超大模型训练失稳的前提性架构创新,它为传统残差连接加上双随机矩阵数学护栏,在 HC 的基础上,强制每条残差路径的入度和出度权重和均为 1,天然保证信号谱范数≤1,从数学上杜绝了深层堆叠时的幅值爆炸与梯度消失。
-
CSA + HCA 混合注意力
CSA+HCA 混合注意力是实现 1M 原生上下文普惠的核心技术,它模拟人类 “先全局扫读定位、再局部精读细节” 的阅读逻辑,采用粗细两路注意力层级交替排布。CSA 以 64token 为粒度压缩后稀疏筛选关键块做精算,HCA 以 1024 左右的大粒度全局压缩做全量扫描兜底长程依赖。(主要是节省显存
-
Muon 优化器
Muon 是 DeepSeek-V4 全面替代 AdamW 的新一代训练优化器,它针对 AdamW “维度偏科” 的本质缺陷,先通过两段式 Hybrid Newton-Schulz 迭代将动量矩阵投影为正交矩阵,让所有参数方向的更新步长完全一致,避免奇异方向过更新与弱方向欠学习;通过 RMS Rescale 技术将更新幅度对齐 AdamW,直接复用原有超参无需重新调参,最终实现更快的收敛速度、更平滑的训练曲线,且无需额外的 QK-Clip 辅助 trick,大幅降低了千卡级大模型训练的时间成本与失败风险。
mHC(流形约束超连接)
传统的残差链接做了一个简单的变化,让每一层都可以获取前一层的信息,防止深度多层传递中的信息丢失,单层传播公式如下:
x l + 1 = x l + F ( x l , W l ) x_{l+1} = x_l + \mathcal{F}(x_l, W_l) xl+1=xl+F(xl,Wl)
公式进行多层递归展开:
x L = x l + ∑ i = l L − 1 F ( x i , W i ) x_L = x_l + \sum_{i=l}^{L-1} \mathcal{F}(x_i, W_i) xL=xl+∑i=lL−1F(xi,Wi)
自字节Seed-Foundation-Model Team的Hyper-Connections论文,首次提出了"拓宽残支流"的创新方向,打破了传统残差连接十年不变的单流范式
HC单层传播公式如下:
x l + 1 = H l r e s x l + H l p o s t ⊤ F ( H l p r e x l , W l ) x_{l+1} = \mathcal{H}_l^{res} x_l + \mathcal{H}_l^{post \top} \mathcal{F}(\mathcal{H}_l^{pre} x_l, W_l) xl+1=Hlresxl+Hlpost⊤F(Hlprexl,Wl),
相当于在进行FNN/Attention前拆封为多通道,但是进行 F \mathcal{F} F 计算的时候仍然通过 H l p r e \mathcal{H}_l^{pre} Hlpre 合并,没有改变原先计算流程,仅通过拆分残差为多通道以传递更多信息(语法信息、事实知识、逻辑推理、长程依赖等等不同维度的信息),动态映射计算如下:
{ x ~ l = RMSNorm ( x l ) H l p r e = α l p r e ⋅ tanh ( θ l p r e x ~ l ⊤ ) + b l p r e H l p o s t = α l p o s t ⋅ tanh ( θ l p o s t x ~ l ⊤ ) + b l p o s t H l r e s = α l r e s ⋅ tanh ( θ l r e s x ~ l ⊤ ) + b l r e s \begin{cases} \tilde{x}_l = \text{RMSNorm}(x_l) \\ \mathcal{H}_l^{pre} = \alpha_l^{pre} \cdot \tanh(\theta_l^{pre} \tilde{x}_l^\top) + b_l^{pre} \\ \mathcal{H}_l^{post} = \alpha_l^{post} \cdot \tanh(\theta_l^{post} \tilde{x}_l^\top) + b_l^{post} \\ \mathcal{H}_l^{res} = \alpha_l^{res} \cdot \tanh(\theta_l^{res} \tilde{x}_l^\top) + b_l^{res} \end{cases} ⎩ ⎨ ⎧x~l=RMSNorm(xl)Hlpre=αlpre⋅tanh(θlprex~l⊤)+blpreHlpost=αlpost⋅tanh(θlpostx~l⊤)+blpostHlres=αlres⋅tanh(θlresx~l⊤)+blres
HC 的所有性能提升都来自于H_res,但它的所有问题也都来自于这个矩阵,它是完全无约束的可学习矩阵
此后DeepSeek团队在此基础上改进,mHC: Manifold-Constrained Hyper-Connections论文给H_res加上一个数学约束,让它变成一个双随机矩阵,保证H_res所有元素非负且行和列为一
{ H l p r e = σ ( H ~ l p r e ) H l p o s t = 2 σ ( H ~ l p o s t ) H l r e s = Sinkhorn-Knopp ( H ~ l r e s ) \begin{cases} \mathcal{H}_l^{pre} = \sigma\left( \tilde{\mathcal{H}}_l^{pre} \right) \\ \mathcal{H}_l^{post} = 2\sigma\left( \tilde{\mathcal{H}}_l^{post} \right) \\ \mathcal{H}_l^{res} = \text{Sinkhorn-Knopp}\left( \tilde{\mathcal{H}}_l^{res} \right) \end{cases} ⎩ ⎨ ⎧Hlpre=σ(H~lpre)Hlpost=2σ(H~lpost)Hlres=Sinkhorn-Knopp(H~lres)
通过 Sinkhorn-Knopp \text{Sinkhorn-Knopp} Sinkhorn-Knopp迭代(也就是迭代出双随机矩阵),首先对原始矩阵的每个元素取指数,保证所有元素非负
M ( 0 ) = exp ( H ~ l r e s ) M^{(0)} = \exp(\tilde{\mathcal{H}}_l^{res}) M(0)=exp(H~lres)
然后开始交替归一化,重复进行行归一化和列归一化,直到足够收敛
M ( t ) = T r ( T c ( M ( t − 1 ) ) ) M^{(t)} = \mathcal{T}_r\left( \mathcal{T}_c(M^{(t-1)}) \right) M(t)=Tr(Tc(M(t−1)))
其核心改进如下
P M r e s ( H l r e s ) : = { H l r e s ∈ R n × n ∣ H l r e s 1 n = 1 n , 1 n ⊤ H l r e s = 1 n ⊤ , H l r e s ≥ 0 } \mathcal{P}_{\mathcal{M}^{res}}(\mathcal{H}_l^{res}) := \left\{ \mathcal{H}_l^{res} \in \mathbb{R}^{n \times n} \mid \mathcal{H}_l^{res} \mathbf{1}_n = \mathbf{1}_n, \mathbf{1}_n^\top \mathcal{H}_l^{res} = \mathbf{1}_n^\top, \mathcal{H}_l^{res} \geq 0 \right\} PMres(Hlres):={Hlres∈Rn×n∣Hlres1n=1n,1n⊤Hlres=1n⊤,Hlres≥0}
混合注意力
注意力是关键中的关键,也是推理中最主要的消耗,这方面的改进也是要极为谨慎,刚开始的注意力:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left( \frac{Q K^\top}{\sqrt{d_k}} \right) V Attention(Q,K,V)=softmax(dkQK⊤)V
粗粒度全局压缩注意力 Heavily Compressed Attention
把一整段长文本,压缩成很少的几个“大块”,如 1M token 可以压缩为 1000 块,每一块就相当于那一章节(抽象来看)的整体语义,从而降低内存使用率
它只负责看懂全局结构,相当于文章大纲
其计算,首先进行块划分与压缩:
X = [ X 1 , X 2 , … , X N h ] , N h = ⌈ n m h ⌉ X = [X_1, X_2, \dots, X_{N_h}], \quad N_h = \left\lceil \frac{n}{m_h} \right\rceil X=[X1,X2,…,XNh],Nh=⌈mhn⌉
X ˉ i = Flatten ( X i ) P h , X ˉ = [ X ˉ 1 , X ˉ 2 , … , X ˉ N h ] ∈ R N h × d \bar{X}_i = \text{Flatten}(X_i) P_h, \quad \bar{X} = [\bar{X}_1, \bar{X}_2, \dots, \bar{X}_{N_h}] \in \mathbb{R}^{N_h \times d} Xˉi=Flatten(Xi)Ph,Xˉ=[Xˉ1,Xˉ2,…,XˉNh]∈RNh×d
然后进行注意力计算:
Q ˉ = X ˉ W Q , K ˉ = X ˉ W K , V ˉ = X ˉ W V \bar{Q} = \bar{X} W_Q, \quad \bar{K} = \bar{X} W_K, \quad \bar{V} = \bar{X} W_V Qˉ=XˉWQ,Kˉ=XˉWK,Vˉ=XˉWV
A ˉ = softmax ( Q ˉ K ˉ ⊤ d k ) V ˉ \bar{A} = \text{softmax}\left( \frac{\bar{Q} \bar{K}^\top}{\sqrt{d_k}} \right) \bar{V} Aˉ=softmax(dkQˉKˉ⊤)Vˉ
上采样回原始序列长度:
A h = Upsample ( A ˉ , m h ) ∈ R n × d A_h = \text{Upsample}(\bar{A}, m_h) \in \mathbb{R}^{n \times d} Ah=Upsample(Aˉ,mh)∈Rn×d
压缩稀疏注意力 Compressed Sparse Attention
假设64个token为一块,则将 1M token 变为 16000 块,此时进行一次打分,选择最优的块进行注意力计算(相当于只抓重要的,舍弃无关噪音)
中等粒度分块压缩后,先快速筛选出与当前 token 最相关的 Top-K 个块,只对这 K 个块做精细注意力,彻底抛弃无关内容。
同样,首先进行块划分与轻量级压缩:
X = [ X 1 , X 2 , … , X N c ] , N c = ⌈ n m c ⌉ X = [X_1, X_2, \dots, X_{N_c}], \quad N_c = \left\lceil \frac{n}{m_c} \right\rceil X=[X1,X2,…,XNc],Nc=⌈mcn⌉
X ~ i = Flatten ( X i ) P c , X ~ = [ X ~ 1 , X ~ 2 , … , X ~ N c ] ∈ R N c × d c \tilde{X}_i = \text{Flatten}(X_i) P_c, \quad \tilde{X} = [\tilde{X}_1, \tilde{X}_2, \dots, \tilde{X}_{N_c}] \in \mathbb{R}^{N_c \times d_c} X~i=Flatten(Xi)Pc,X~=[X~1,X~2,…,X~Nc]∈RNc×dc
Lightning Indexer(一个核心算子,不深入追究) 快速打分:
s i = q ~ K ~ i ⊤ d c , i = 1 , 2 , … , N c s_i = \frac{\tilde{q} \tilde{K}_i^\top}{\sqrt{d_c}}, \quad i=1,2,\dots,N_c si=dcq~K~i⊤,i=1,2,…,Nc
只对选中的 K 个块的原始 K、V 做精细注意力:
K s e l e c t e d = [ X i 1 W K , X i 2 W K , … , X i K W K ] ∈ R K m c × d K_{selected} = [X_{i_1} W_K, X_{i_2} W_K, \dots, X_{i_K} W_K] \in \mathbb{R}^{K m_c \times d} Kselected=[Xi1WK,Xi2WK,…,XiKWK]∈RKmc×d
V s e l e c t e d = [ X i 1 W V , X i 2 W V , … , X i K W V ] ∈ R K m c × d V_{selected} = [X_{i_1} W_V, X_{i_2} W_V, \dots, X_{i_K} W_V] \in \mathbb{R}^{K m_c \times d} Vselected=[Xi1WV,Xi2WV,…,XiKWV]∈RKmc×d
A c = softmax ( q K s e l e c t e d ⊤ d k ) V s e l e c t e d ∈ R 1 × d A_c = \text{softmax}\left( \frac{q K_{selected}^\top}{\sqrt{d_k}} \right) V_{selected} \in \mathbb{R}^{1 \times d} Ac=softmax(dkqKselected⊤)Vselected∈R1×d
可以采用层间交替堆叠的方式来使用这两种注意力机制,让全局信息和局部信息逐层传递融合,这种方式工程实现起来很简单
Muon 优化器
优化器的发展,本质上是 “人类不断解决梯度更新中各种缺陷”,从最原始的 “一步一步走”,到 “带着惯性走”,到 “给每个参数单独调步长”,再到 “解决大模型特有的维度偏科”。每一代优化器都是为了解决上一代的致命缺陷。(就像发论文一样,你需要有个待解决的问题
| 优化器 | 提出时间 | 核心论文 | 要解决的问题 | 核心创新 | 局限性 |
|---|---|---|---|---|---|
| SGD | 1951 | A Stochastic Approximation Method | 批量梯度下降(BGD)计算量过大,无法大规模训练 | 用单样本梯度近似真实梯度,大幅降低单次迭代的计算开销 | 梯度噪声大,更新轨迹震荡严重;学习率需手动调优;所有参数共享同一学习率,无法自适应 |
| Momentum SGD | 1964 | Some methods of speeding up the convergence of iteration methods | SGD 梯度噪声大、震荡严重,收敛速度慢 | 引入动量项,累积历史梯度方向,平滑更新轨迹,降低震荡 | 容易在极值点附近冲过头(更新幅度过大),仍使用全局共享学习率,无法为不同参数自适应调整步 |
| NAG | 1983 | A method of solving the convex programming problem with convergence O ( 1 / k 2 ) O(1/k²) O(1/k2) | 解决 Momentum SGD 在极值点附近易冲过头、震荡的问题 | 在 “预测位置” 计算梯度,提前修正更新方向,避免冲过头 | 仍依赖全局学习率,无法为不同参数自适应调整步长 |
| Adagrad | 2011 | Adaptive Subgradient Methods for Online Learning and Stochastic Optimization | 传统优化器全局共享学习率,无法为稀疏参数自适应调整步长 | 为每个参数维护梯度平方的累加和,实现逐参数自适应学习率,提升稀疏场景下的更新效率 | 梯度平方累加和单调递增,导致学习率后期趋近于 0,模型无法继续更新。仅适用于稀疏场景,不适合深度网络 |
| RMSprop | 2012 | ---- | 解决 Adagrad 学习率单调衰减,后期无法更新的问题 | 用梯度平方的指数移动平均(EMA)替代累加和,动态调整学习率,避免单调衰减 | 仅使用梯度平方的 EMA,未引入一阶动量项,更新轨迹易受梯度噪声影响,稳定性不足 |
| Adam | 2014 | Adam: A Method for Stochastic Optimization | 整合 Momentum 和 RMSprop 的优点,解决两者的单一缺陷 | 同时维护一阶矩(梯度 EMA,带动量)和二阶矩(梯度平方 EMA,自适应步长),实现带动量的自适应学习率更新 | 权重衰减与 L2 正则不等价,导致正则化失效,模型泛化能力不足,高维场景下易出现维度偏科 |
| AdamW | 2017 | Decoupled Weight Decay Regularization | 解决 Adam 中权重衰减与 L2 正则不等价,导致泛化能力差的问题 | 将权重衰减与梯度更新解耦,使权重衰减不受自适应学习率影响,恢复正则化效果 | 需同时维护一阶、二阶矩,显存占用大。大模型训练中易出现维度偏科,更新效率不足 |
| Lion | 2023 | Symbolic Discovery of Optimization Algorithms | 解决 AdamW 需维护二阶矩、显存与计算开销大的问题 | 仅使用一阶动量的符号(sign)更新,抛弃二阶矩计算,大幅降低显存与计算开销 | 对学习率等超参数高度敏感,调参难度大。仅使用梯度方向更新,步长固定,易出现震荡,稳定性弱于 AdamW |
| Muon | 2024 | Muon: An optimizer for the hidden layers of neural networks | 解决 AdamW 在高维矩阵参数上的维度偏科问题,提升更新效率与训练稳定性 | 通过 Newton-Schulz 迭代对动量矩阵正交化,消除高维参数的各向异性,实现各方向更新力度均等 | 矩阵正交化步骤增加了计算开销,仅适用于二维矩阵参数,标量/向量参数仍需搭配其他优化器,实现复杂度较高 |
其核心公式整理如下:
| 优化器 | 核心数学公式 |
|---|---|
| SGD | θ t = θ t − 1 − η g t \theta_t = \theta_{t-1} - \eta g_t θt=θt−1−ηgt |
| Mini-batch SGD | θ t = θ t − 1 − η ⋅ 1 B ∑ i = 1 B g t , i \theta_t = \theta_{t-1} - \eta \cdot \frac{1}{B} \sum_{i=1}^B g_{t,i} θt=θt−1−η⋅B1∑i=1Bgt,i |
| Momentum SGD | θ t = θ t − 1 − η ( β v t − 1 + ( 1 − β ) g t ) \theta_t = \theta_{t-1} - \eta \left( \beta v_{t-1} + (1-\beta) g_t \right) θt=θt−1−η(βvt−1+(1−β)gt) |
| NAG | θ t = θ t − 1 − η ( β v t − 1 + ( 1 − β ) g t ( θ t − 1 − η β v t − 1 ) ) \theta_t = \theta_{t-1} - \eta \left( \beta v_{t-1} + (1-\beta) g_t(\theta_{t-1} - \eta \beta v_{t-1}) \right) θt=θt−1−η(βvt−1+(1−β)gt(θt−1−ηβvt−1)) |
| Adagrad | θ t = θ t − 1 − η G t + ϵ ⊙ g t \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{G_t} + \epsilon} \odot g_t θt=θt−1−Gt+ϵη⊙gt |
| RMSprop | θ t = θ t − 1 − η v t + ϵ ⊙ g t \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{v_t} + \epsilon} \odot g_t θt=θt−1−vt+ϵη⊙gt |
| Adam | θ t = θ t − 1 − η m ^ t v ^ t + ϵ \theta_t = \theta_{t-1} - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} θt=θt−1−ηv^t+ϵm^t |
| AdamW | θ t = θ t − 1 − η ( m ^ t v ^ t + ϵ + λ θ t − 1 ) \theta_t = \theta_{t-1} - \eta \left( \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} + \lambda \theta_{t-1} \right) θt=θt−1−η(v^t+ϵm^t+λθt−1) |
| Lion | θ t = θ t − 1 − η ( sign ( m t ) + λ θ t − 1 ) \theta_t = \theta_{t-1} - \eta \left( \text{sign}(m_t) + \lambda \theta_{t-1} \right) θt=θt−1−η(sign(mt)+λθt−1) |
| Muon | θ t = θ t − 1 − η ( Orthogonalize ( M t ) ⋅ r m s t + λ θ t − 1 ) \theta_t = \theta_{t-1} - \eta \left( \text{Orthogonalize}(M_t) \cdot rms_t + \lambda \theta_{t-1} \right) θt=θt−1−η(Orthogonalize(Mt)⋅rmst+λθt−1) |
符号表示:
- θ t \theta_t θt: 第 t t t 步更新后的模型参数
- θ t − 1 \theta_{t-1} θt−1: 第 t − 1 t-1 t−1 步的模型参数
- η \eta η: 学习率(步长)
- g t g_t gt: 第 t t t 步的梯度(单样本)
- B B B: 小批量样本数(batch size)
- g t , i g_{t,i} gt,i: 第 t t t 步第 i i i 个样本的梯度
- β \beta β: 动量系数
- v t − 1 v_{t-1} vt−1: 第 t − 1 t-1 t−1 步的动量(梯度的指数移动平均)
- g t ( θ t − 1 − η β v t − 1 ) g_t(\theta_{t-1} - \eta \beta v_{t-1}) gt(θt−1−ηβvt−1): 在 “先看一步” 的位置计算的梯度
- G t G_t Gt: 梯度平方的累加和(逐元素)
- ϵ \epsilon ϵ: 防止分母为 0 的常数
- ⊙ \odot ⊙: 逐元素乘法(哈达玛积)
- v t v_t vt: 梯度平方的指数移动平均(逐元素)
- m ^ t \hat{m}_t m^t: 偏差修正后的一阶矩(动量)
- v ^ t \hat{v}_t v^t: 偏差修正后的二阶矩(梯度平方的 EMA)
- λ \lambda λ: 权重衰减系数
- sign ( ) \text{sign}() sign(): 符号函数(输出 -1/0/1)
- m t m_t mt: 一阶矩(动量)
- M t M_t Mt: 动量矩阵(按块更新)
- Orthogonalize \text{Orthogonalize} Orthogonalize: 正交投影操作(Newton-Schulz 迭代)
- r m s t rms_t rmst: 全局 RMS 缩放因子(对齐 AdamW 步长)
结语
现在这个时代,智力已不再是稀缺资源。工业革命稀释了体力价值,而AI的到来,正在不断抹平传统智力的溢价。
这不禁让我思考,未来一个人的核心价值是什么?学习还有用吗?第一想法当然有用,但现在却又说不出来用在哪里。这种矛盾,像是生产力的极大提升,但生产关系却毫无动静,不知道该走向何处。
我们处于时代的浪口,却不知身向何处,心往何向

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)