ICCV 2025|ReasonVQA:一个融合结构化知识的多跳推理视觉问答基准数据集

论文地址:https://arxiv.org/abs/2507.16403
文章目录
一、论文信息
- 题目:ReasonVQA: A Multi-hop Reasoning Benchmark with Structural Knowledge for Visual Question Answering
- 作者:Duong T. Tran,Trung-Kien Tran,Manfred Hauswirth,Danh Le Phuoc
- 单位:Bosch Center for AI, Germany.Technical University of Berlin.Fraunhofer FOKUS
- 会议:ICCV 2025
- 数据集链接:https://duong-tr.github.io/ReasonVQA
二、论文主要贡献
本文提出了一个面向视觉问答(VQA)任务的新型数据集—— ReasonVQA。该数据集自动整合了结构化百科知识,通过低成本框架构建而成,能够生成复杂的多跳问题。我们在 ReasonVQA 上对当前最先进的 VQA 模型进行了评估,实证结果表明,该数据集对这些模型构成了显著挑战,凸显了其在视觉问答领域基准测试与技术推进中的潜力。此外,该数据集可根据输入图像轻松扩展规模;当前版本在需调用外部知识的视觉问答数据集中,规模已超过现有最大数据集一个数量级以上。
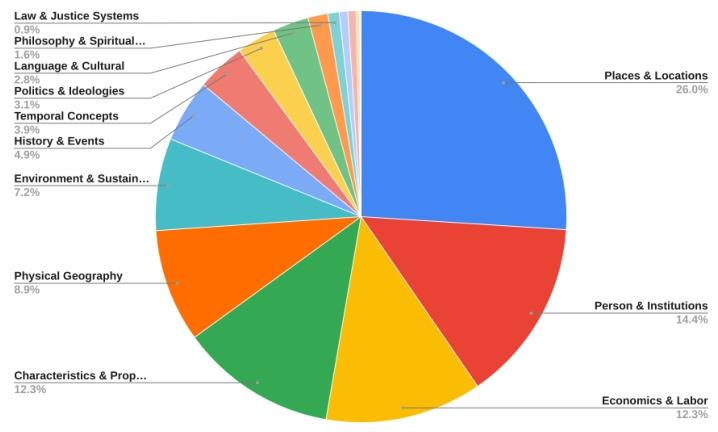
下图为ReasonVQA 的样本图像及问题示例。基于现有图像,通过在知识图谱上进行单跳或多跳推理来构建问题,生成的问题涵盖多个领域(领域见最后一张图)。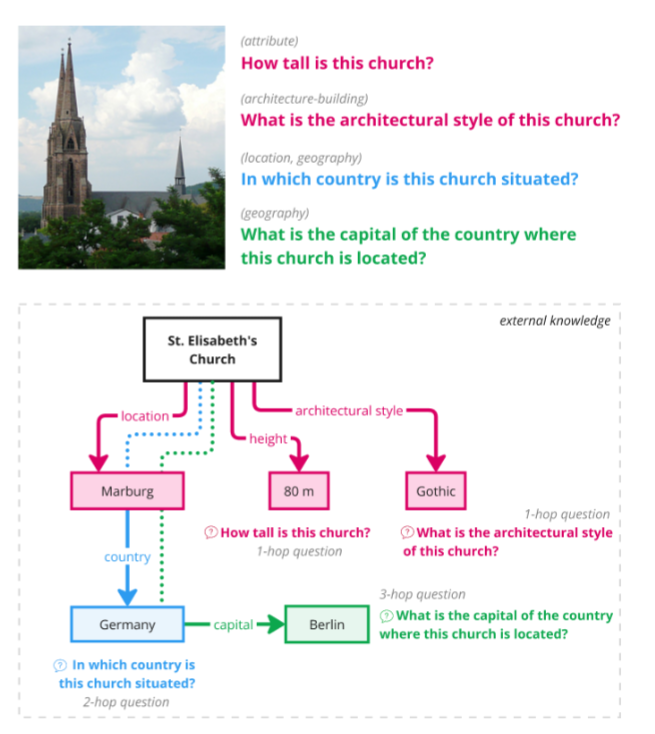
三、论文创新点
3.1 利用模板生成单跳或多跳推理问题
本文利用含可填充占位符的预定义模板。该方法支持构建低成本、可扩展的系统,原因是单个模板可生成多个问题。尽管这些模板是人工设计的,但它们具备足够的通用性,能够实现广泛覆盖。为提升语言多样性,我们还为每个模板设计了语言变体。我们所提方法的一个关键优势在于,它能够将多个模板组合成一个问题,从而进一步提升系统的可扩展性。此外,由于我们的潜在模板是基于从知识库(KB)中搜集的知识构建而成,因此模板的多样性与知识库中可用知识的广度是相匹配的。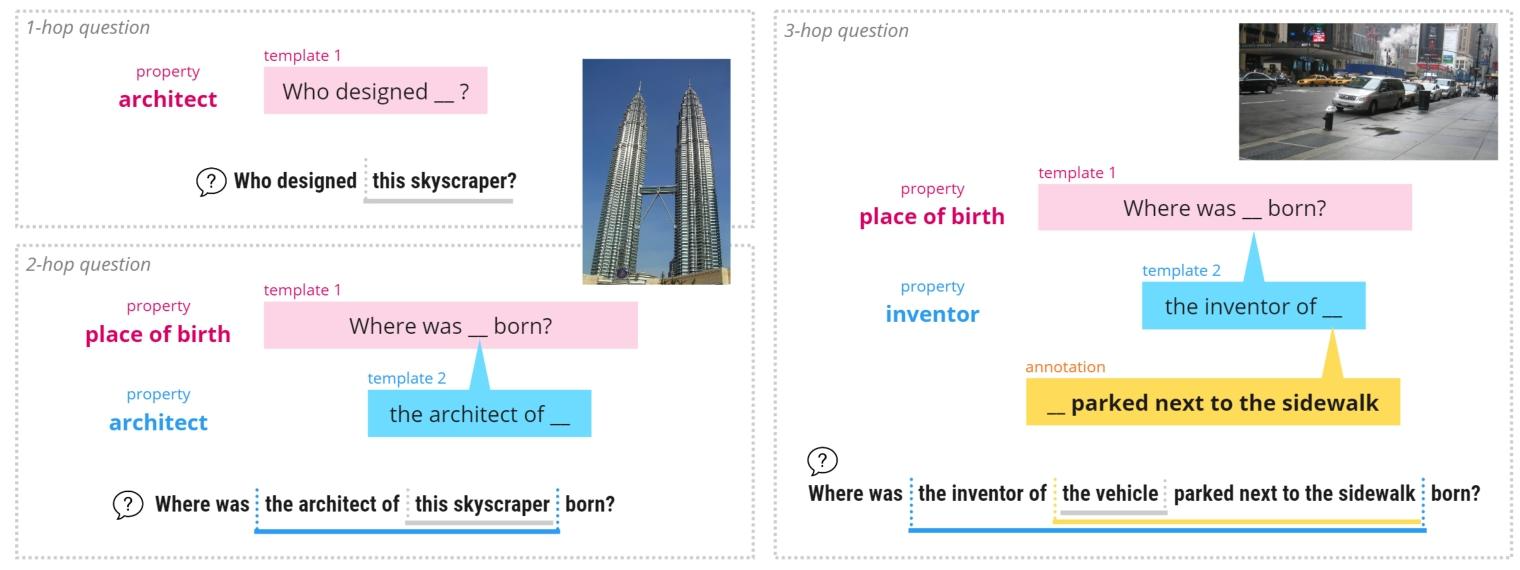
3.1.1 单跳问题生成
获取主物体在 Wikidata 中的外部事实后,我们为这些事实中出现的每个属性(或关系,二者可互换)使用一个预定义模板。每个模板包含一个占位符,后续会用主物体的类别名称填充该占位符,最终生成单跳问题。
3.1.2 多跳问题生成
围绕主物体的多跳问题,是通过在单跳问题模板(以下称为 “主模板”)的占位符中填入子从句来构建的。这个子从句由子从句模板生成 —— 每个关系也会对应人工设计的子从句模板。例如,“建筑师” 这一关系对应的子从句模板是 “…… 的建筑师”。子从句模板中的占位符,可以填入主物体的类别名称,也可以填入另一个子从句 —— 这正是我们多跳问题构建机制的核心。此外,我们还利用视觉图谱(VG)中的场景图标注来构建子从句(比如 “停靠在人行道旁的”),这能让我们更好地将视觉语义信息融入问题中。
此外,我们根据生成问题所依据的属性,将每个问题归类到一个或多个领域中。例如,一个关于名人出生日期的问题(基于 “出生日期” 这一属性生成),可同时归类到 “人物” 和 “历史事件” 领域。这一设计使系统能够接收单个或多个指定领域作为输入,并据此生成对应问题。该机制对于将数据集限定在特定领域尤为实用,有助于得到更具针对性和精准度的结果。
3.2 干扰项生成
为生成具有挑战性的选择题,除正确答案外,我们还需设计非简单化的干扰项。
首先,根据正确答案的类型,将问题划分为四类:固定类、日期类、数字类和文本类。
固定类问题的可选答案集合是封闭的(如涉及性别、大洲、国家、语言的问题);
日期类、数字类和文本类问题分别对应与日期时间、数值和文本值相关的提问。
针对不同类别问题的干扰项生成规则如下:
- 固定类问题:从对应答案集合中随机选取干扰项;
- 日期类问题:在正确答案日期的 [ − 10 年, + 10 年 ] [-10 年,+10 年] [−10年,+10年] 区间内随机选取 N N N 个日期作为干扰项;
- 数字类问题:在特定区间 [ m , n ] [m, n] [m,n] 内随机选取 N N N 个数字作为干扰项,其中 m = i / 2 m = i/2 m=i/2, n = m a x ( 1.5 i , m + 2 N ) n = max (1.5i, m + 2N) n=max(1.5i,m+2N)。其中 i i i 为正确答案的数值。
- 文本类问题:我们通过检索与正确答案同属一个属性的 N N N 个取值来生成干扰项。在实际实验中,我们将 N N N 设为 3,即每个正确答案最多对应 3 个干扰项。
3.3 答案分布均衡化
现有视觉问答数据集的一个普遍问题是,其答案存在明显的特定倾向性,这会导致机器学习模型无需完全理解输入内容就能推测出输出结果。因此,我们研究了如何平滑答案分布以缓解这一问题。
我们计算了每个分组下所有正确答案的分布情况,其中每个分组由对应的属性定义。我们按答案的出现次数对其进行排序,且仅选取每个分组中出现次数前十的答案进入下一步处理。
随后,我们通过以下流程构建更平滑的答案分布:首先按出现频率从高到低遍历某一分组中的所有答案,反复剔除部分高频答案及其对应的问题,使头部答案的数量与尾部答案的数量趋于相当。其中,头部答案指对应问题数量最多的答案集合,尾部答案则指对应问题数量最少的答案集合。从本质上来说,出现频率越高的答案,被剔除的概率也越大。因此,该流程能让此基准数据集的倾向性降低、分布更均衡,同时也能提升对视觉问答模型的挑战难度。
在重复执行该剔除操作的过程中,我们通过维持每两个连续出现的答案之间的频率最小与最大比值,保证答案的频率排序始终不变。我们还优先从包含问题数量最多的图像中剔除对应答案,这一做法有助于均衡各图像对应的问题数量,同时尽可能避免直接剔除整幅图像。
上述均衡化流程以迭代方式执行,每完成一次迭代,答案的分布就会变得更加均匀。
四、方法
4.1 ReasonVQA 的整体框架
ReasonVQA 数据集的构建初衷,是评估视觉问答(VQA)模型回答多跳问题与运用外部知识的能力。该数据集包含大量问题,并按复杂度划分为三个等级:单跳、两跳和三跳。
本文构建 ReasonVQA 数据集的框架整体流程共分为三个步骤:
- 外部知识融合
- 问题生成
- 数据集构建
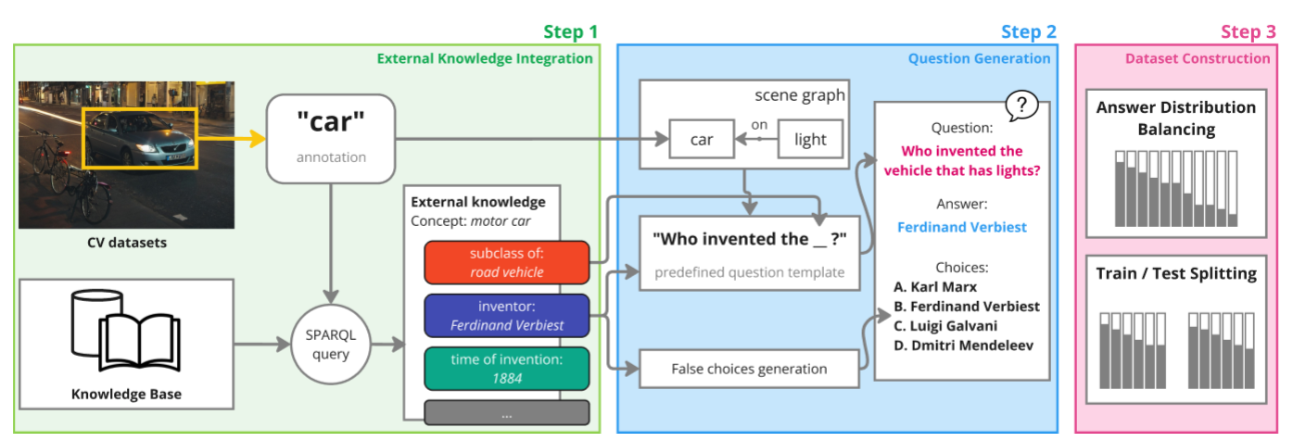
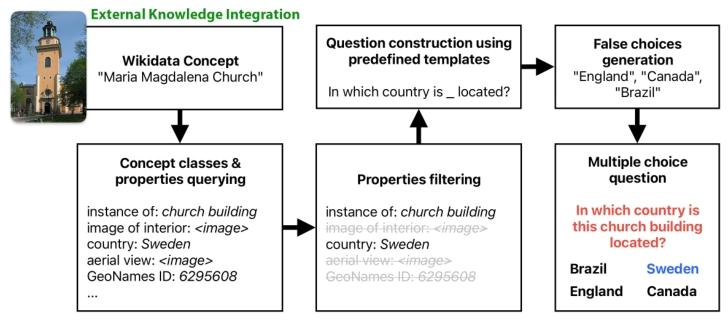
4.1.1 外部知识整合(External Knowledge Integration)
- 输入来源:计算机视觉(CV)数据集(比如图中的含汽车的图像),以及知识库(Knowledge Base,如 Wikidata)
- 操作:先从 CV 数据集中提取图像里的物体标注(比如图中的 “car”);再通过 SPARQL 查询语言,将 “car” 关联到知识库,获取对应的外部知识(比如 “car” 属于 “road vehicle” 子类、发明者是 Ferdinand Verbiest、发明时间 1884 等)。
4.1.2 问题生成(Question Generation)
- 结合场景信息:先利用图像的场景图(比如 “car” 和 “light” 的关系);
- 模板生成问题:用预设的问题模板(比如 “Who invented the _?”),填入知识中的 “road vehicle”,生成问题 “Who invented the vehicle that has lights?”;
- 补充答案与干扰项:确定答案为 Ferdinand Verbiest,再生成错误选项(如 Karl Marx 等),形成完整的问答对。
4.1.3 数据集构建(Dataset Construction)
- 答案分布均衡化:通过调整数据,避免某类答案占比过高(防止模型依赖偏见答题);(详见创新点部分)
- 划分训练 / 测试集:为保证训练集与测试集的答案分布保持一致,本数据集通过以下步骤完成划分:
- 将图像划分至不同类别,再按相同的训练 / 测试比例对每个类别进行随机拆分。
- 对于每张图像,首先计算其所有答案的出现频率,筛选出在答案池中出现占比至少 1% 的答案(答案池即数据集的所有答案构成的集合)。
- 将每张图像归至一个类别,该类别的名称由图像对应出现频率最高的两个答案拼接而成。且将所有仅包含单张图像的类别进行合并。
- 将每个类别中的图像及其对应的问答对按 70% 训练集、30% 测试集的比例随机拆分。
最终得到的数据集可保证图像无重叠,且针对某一特定图像的所有问题均归属于同一数据子集。训练集与测试集的答案分布相似度可视化结果。
五、实验分析
5.1 数据集统计及质量评估
ReasonVQA 数据集的最新版本包含超 59.8 万张图像和约 420 万个问题。该数据集的可扩展性取决于两个关键因素:(1)大量实体拥有共同属性;(2)多跳问题通过嵌套多个模板构建而成。例如,由于各类建筑的相关事实中均包含 “高度” 这一属性,我们在问题生成阶段仅需为该属性定义一个模板即可。
为评估当前主流的模型方法,我们从原数据集衍生出一个子集版本 ReasonVQA-U,核心目的是构建一个规模可控的数据集子集,以高效开展模型的评估与对比实验。我们还在该子集上执行了答案分布均衡化流程,得到了均衡化版本 ReasonVQA-B。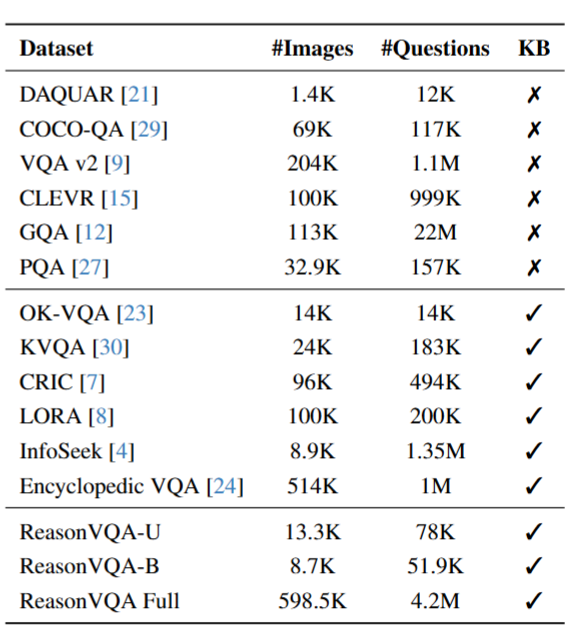
在图像数量方面,本数据集的规模为所有对比数据集之最;在问题数量上,除 GQA 数据集外,本数据集的问题数量显著多于其他所有数据集。
为评估本数据集的质量,我们针对随机选取的 1000 组图文问答对开展了用户调研。本次调研共招募 20 名以英语作为主要工作和 / 或学习语言的受试者,每位受试者需对随机分配的 50 个问题,分别评估其答案的正确性与表述的自然度,并按照评分标准对其进行打分。
自然度采用四级量表评分:(1)非常不自然;(2)不自然;(3)自然;(4)非常自然。此外,受试者还需标记出存在语法错误的问题。本次用户调研结果显示,96% 的问答对答案均准确无误;错误的主要来源为数值相关信息(如城市面积),以及物体高度、长度描述中存在的歧义。错误的另一类主要来源为部分建筑相关的描述偏差。调研结果还显示,仅有 2.20% 的问题被评为 “非常不自然”,13.9% 为 “不自然”,58.1% 为 “自然”,25.8% 为 “非常自然”,存在语法错误的问题仅占 2.5%。本次用户调研表明,超 83% 的问题对人类而言表述自然,这说明该数据集已具备良好的表述自然度,但仍有优化提升的空间。
5.2 实验设置
- 评估模型:为严谨评估本数据集在基于知识的视觉问答任务中形成的挑战,采用数据集的非均衡版本与均衡版本,在多款当前主流的视觉 - 语言模型上开展了全面的性能评估,涉及模型包括:BLIP-2 、InstructBLIP 、mPLUG-Owl2、Idefics2 、Mantis-SigLIP 、Mantis-Idefics2 、mPLUG-Owl3、GPT-4o 、LLaVA-OV 、Qwen2.5-VL 、PaliGemma-2、PaliGemma2-Mix 、SmolVLM-Instruct 。
- 评估场景:零样本开放问答、零样本选择题,同时测试模型微调前后性能及数据集规模对模型表现的影响。
- 评估指标:采用精确匹配、子串匹配、语义相似度匹配(基于 all-MiniLM-L6-v2 模型)三种方式,解决开放问答答案格式不统一的评估难题。
5.3 核心实验结果
- 模型整体表现:
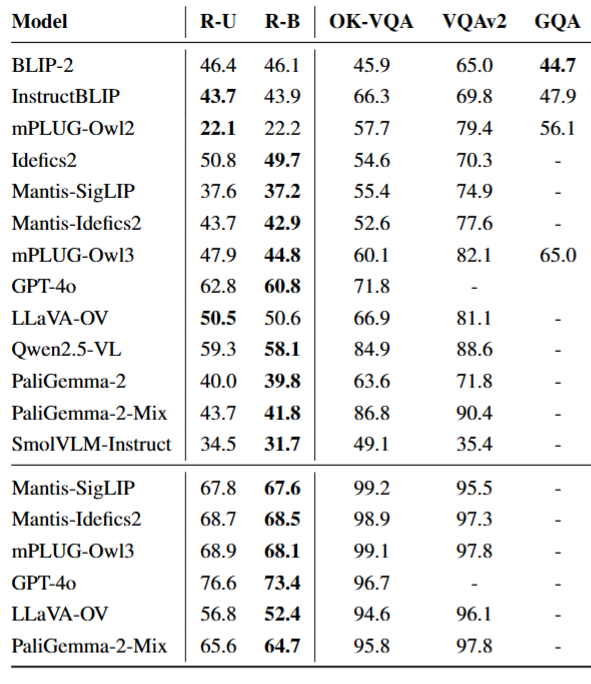
所有模型在 ReasonVQA 上的准确率均显著低于传统数据集(如 VQAv2、GQA),即使顶级模型(GPT-4o)在开放问答中准确率仅 62.8%(ReasonVQA-U),证明数据集的挑战性。
- 多跳推理难度:模型性能随推理跳数增加而下降,3 跳问题准确率显著低于 1-2 跳,且部分模型在 2 跳问题上表现优于 1 跳(因 2 跳问题提供更多上下文)。
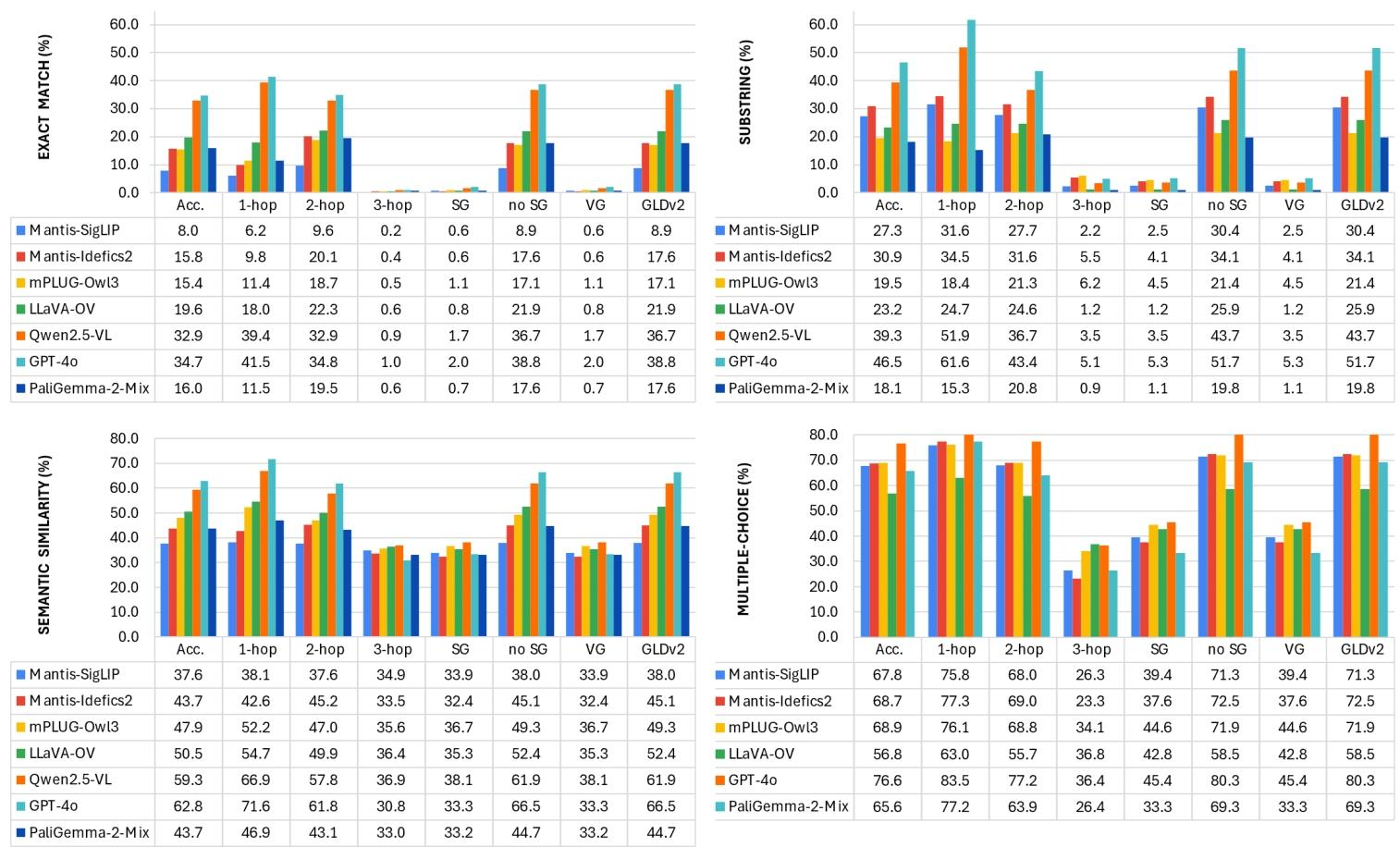
Exact Match(精确匹配)
Substring(子串匹配)
Semantic Similarity(语义相似度)
Multiple-Choice(选择题)
Acc.:整体平均准确率
1-hop / 2-hop / 3-hop:问题推理跳数(单跳、双跳、三跳)
SG / no SG:是否基于场景图生成(SG = 有场景图,no SG = 无)
VG / GLDv2:图像来源(VG=Visual Genome,GLDv2=Google Landmarks v2)
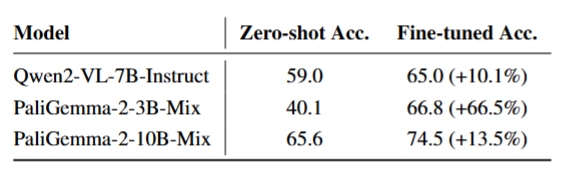
- 微调效果:Qwen2-VL、PaliGemma-2 等模型微调后准确率提升明显,值得关注的是,PaliGemma-2-3B-Mix 模型以更少的资源投入实现了显著的性能提升,这表明小型模型在适配特定数据集时,拥有更大的性能提升空间。
六、个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解有限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)