COLING 2025|LoRA-drop:基于输出评估的高效 LoRA 参数剪枝

论文地址:https://aclanthology.org/2025.coling-main.371.pdf
文章目录
一、论文信息
- 题目:LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation
- 作者: Hongyun Zhou, Xiangyu Lu, Wang Xu, Conghui Zhu, Tiejun Zhao, Muyun Yang
- 单位:Faculty of Computing, Harbin Institute of Technology
Department of Computer Science & Technology, Tsinghua University, Beijing, China - 会议:COLING 2025(第 31 届国际计算语言学大会)
- 论文链接:https://aclanthology.org/2025.coling-main.371.pdf
二、论文主要贡献
低秩适配(LoRA)是广泛应用的参数高效微调(PEFT)方法,但在大规模模型中,LoRA 仍面临较高的计算和存储成本。以往的研究通过剪枝技术来解决这一问题,通常基于参数特征(如数量、规模、梯度等)评估其重要性。然而,LoRA 的输出会直接影响微调后的模型性能,初步实验表明,部分 LoRA 模块的输出值显著偏高,对层输出产生了较大影响。为此,我们提出了 LoRA-drop 方法:通过评估 LoRA 输出的重要性,保留重要层的专属 LoRA,其余层共享同一 LoRA。
我们在不同规模的模型上,针对自然语言理解(NLU)与自然语言生成(NLG)任务开展了大量实验。结果显示,LoRA-drop 在平均仅保留 50% LoRA 参数的情况下,性能可与全参数微调和标准 LoRA 持平。
三、论文创新点
为进一步提升 LoRA 的参数效率,以往研究采用剪枝技术移除被判定为不重要的 LoRA 参数,这类方法的核心在于参数重要性的评估方式——均仅通过分析 LoRA 参数 Δ W ΔW ΔW 的特征来评估重要性,进而实现 LoRA 参数的精简。事实上,LoRA 的输出与参数和数据相关,且会直接影响最终结果。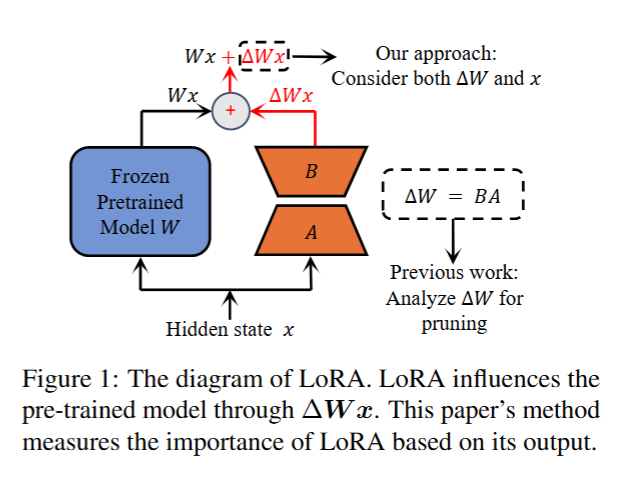
LoRA 会在预训练模型的每一层中添加一个偏置项 Δ W x ΔWx ΔWx(注: Δ W ΔW ΔW 为 LoRA 引入的辅助可训练参数, x x x 为模型对应层的输入或隐藏状态)。因此,冻结的预训练模型正是通过这个偏置项实现微调的。从直观上看,若 Δ W x ΔWx ΔWx 的数值较大,则该层的 LoRA 对冻结模型会产生重要影响。
如图1所示,以往研究仅通过分析 Δ W ΔW ΔW(即低秩矩阵 A A A 、 B B B )的参数特征(如规模、梯度)来判断是否剪枝,未考虑输入 x x x 对 LoRA 实际输出的影响。而在本文提出的方法中,会同时结合 Δ W ΔW ΔW(参数)与 x x x(输入),通过 LoRA 的实际输出 Δ W x ΔWx ΔWx 来评估其重要性,进而决定是否保留该层的专属 LoRA,更精准地衡量 LoRA 对模型的实际影响。
具体步骤如下:
- 对特定任务的数据集进行采样
- 利用采样得到的数据对 LoRA 执行少量轮次的参数更新。各层 LoRA 的重要性依据 Δ W x ΔWx ΔWx 的数值大小判定。
- 保留重要性得分较高的层所对应的 LoRA,其余层则共享同一组 LoRA 参数。
- 在这一新的 LoRA 配置下微调模型,以更少的可训练参数实现性能衰减的最小化。
四、方法
LoRA-drop 是 一种基于 LoRA 输出进行剪枝的新型参数高效微调方法:依据 LoRA 的输出量化不同层 LoRA 的重要性;随后保留重要性较高的 LoRA,并使用一组共享的 LoRA 参数替代重要性较低的 LoRA。通过这种方式,在将 LoRA 训练所需的参数数量减少的同时,仍能维持与标准 LoRA 相当的性能。具体而言,LoRA-drop 由两部分构成:重要性评估(Importance Evaluation)与任务适配(Task Adaptation)。其整体流程如图 3 所示。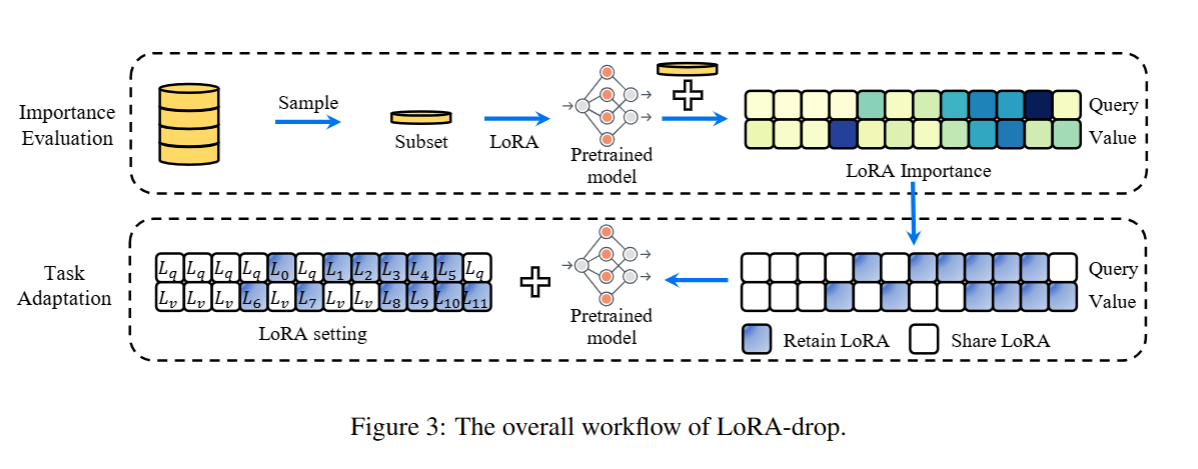
4.1 重要性评估(Importance Evaluation)
此步骤会评估不同层 LoRA 的重要性,为 “任务适配” 步骤中 LoRA 的保留策略提供参考依据。
已知 LoRA 的初始输出全为零。只有经过一定步数的参数更新后,LoRA 的输出才会具有实际意义。
- 对下游任务数据集进行分层抽样,得到训练数据 D D D 的子集 D s D_s Ds ,抽样比例设为 α α α(其中 0 < α < 1 0<α<1 0<α<1)。之后,利用该子集对 LoRA 参数进行若干步更新。
- 计算每一层( i i i ) LoRA 输出的平方范数之和,并将其记为 g g g 。 g i = ∑ x ∈ D s ∥ Δ W i x i ∥ 2 g_i = \sum_{x \in D_s} \|\Delta W_i x_i\|^2 gi=x∈Ds∑∥ΔWixi∥2
- ( g g g 的数值大小可反映对其 LoRA 的重要性,实验证明见实验部分。为了更直观地体现各层 LoRA 的相对重要程度)对 g g g 进行归一化处理,最终得到各层 LoRA 的重要性指标 I I I。 I i = g i ∑ i g i I_{i} = \frac{g_{i}}{\sum_{i} g_{i}} Ii=∑igigi
我们发现,从训练数据中抽取一个小子集,即可得到与完整数据集相近的 LoRA 重要性分布。这一点已通过实验得到验证(见实验部分)。我们实验中抽样比例 α 的默认值设为10%。
4.2 任务适配(Task Adaptation)
此步骤会基于 LoRA 的重要性分布,制定适配下游任务的 LoRA-drop 微调策略。
- 基于各层 LoRA 的重要性得分,按照 I i I_i Ii 的大小对各层进行排序。
- 依照从高到低的重要性顺序选取网络层,直至选中各层的重要性之和达到阈值 T T T。本文中,阈值 T T T 为超参数,默认取值设为 0.9(有关该参数取值的详细讨论见实验部分)。训练过程中,被选中的这些层对应的 LoRA 参数将予以保留,而其余层的 LoRA 参数则由一组共享的 LoRA 参数替代。
- 基于这一新的 LoRA 配置,使用训练数据集对模型进行微调。
五、实验分析
5.1 预实验:分析大型语言模型(LLMs)中 LoRA 输出的分布特征
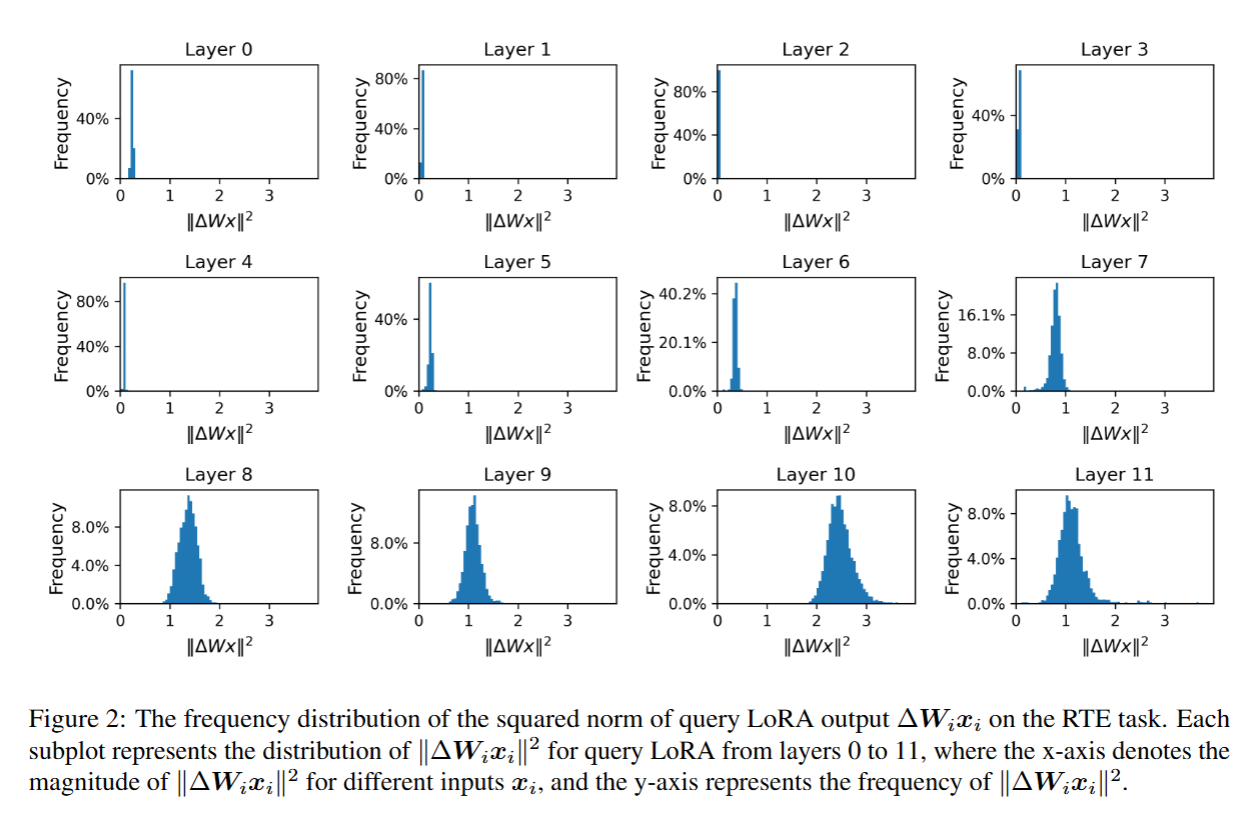
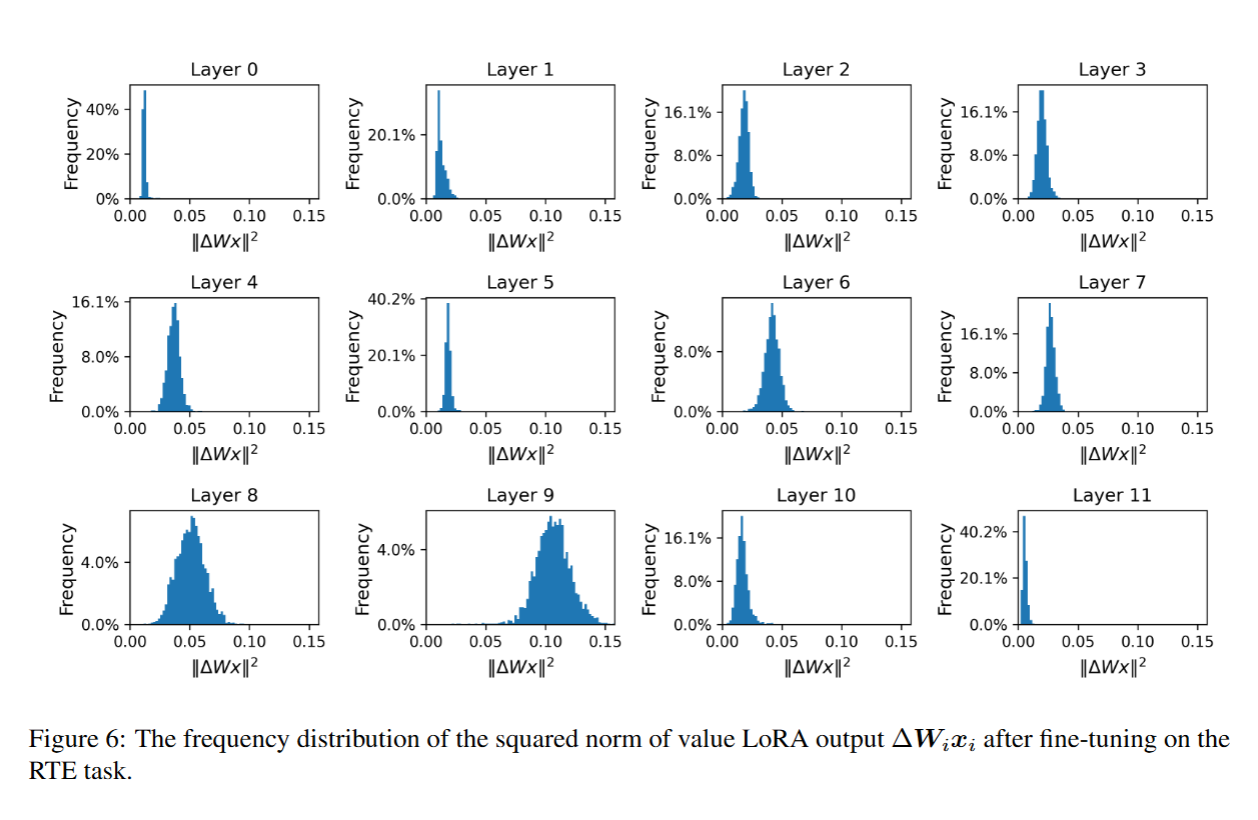
初步研究中,我们分析了每一层LoRA(低秩适配)输出的分布情况。具体而言:
- 实验设置:在RTE(文本蕴含识别,其核心任务是判断 “假设句(Hypothesis)” 能否从 “前提句(Premise)” 中逻辑推断得出)数据集和MRPC(微软研究释义语料库,其核心目标是判断给定的两个句子是否为 “同义改写(Paraphrase)”,即语义等价)数据集上,分别采用LoRA对RoBERTa-base模型进行微调;
- 分析指标:针对每个数据集,分析LoRA输出 Δ W i x i ΔW_ix_i ΔWixi 的平方范数分布,并通过计算该平方范数评估LoRA的影响——值越大,说明 LoRA 在该层的影响越强。;
- LoRA部署位置:将LoRA添加至每一层的查询矩阵(query matrix)和值矩阵(value matrix);
- 结果呈现:
- RTE数据集:查询矩阵LoRA分布见图2,值矩阵LoRA分布见图6;
- MRPC数据集:查询矩阵LoRA分布见图7,值矩阵LoRA分布见图8。
- RTE数据集:查询矩阵LoRA分布见图2,值矩阵LoRA分布见图6;
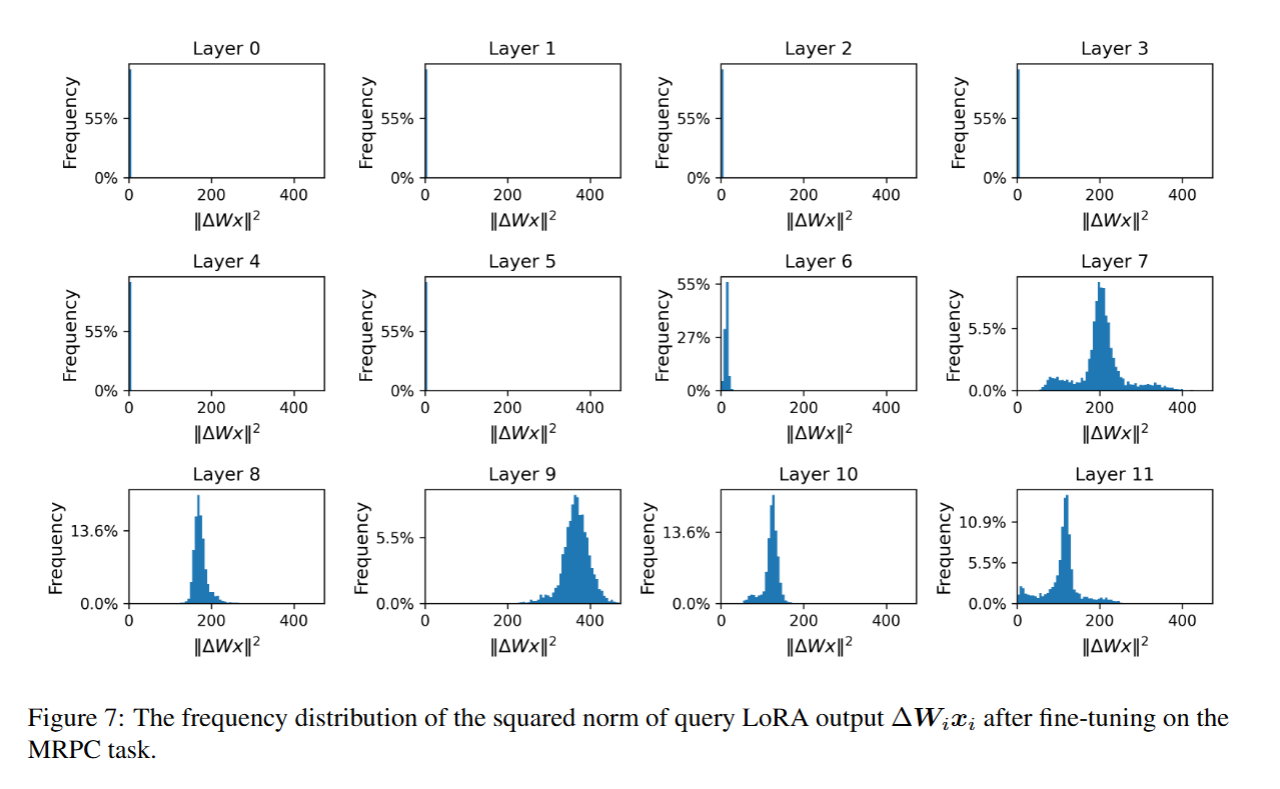
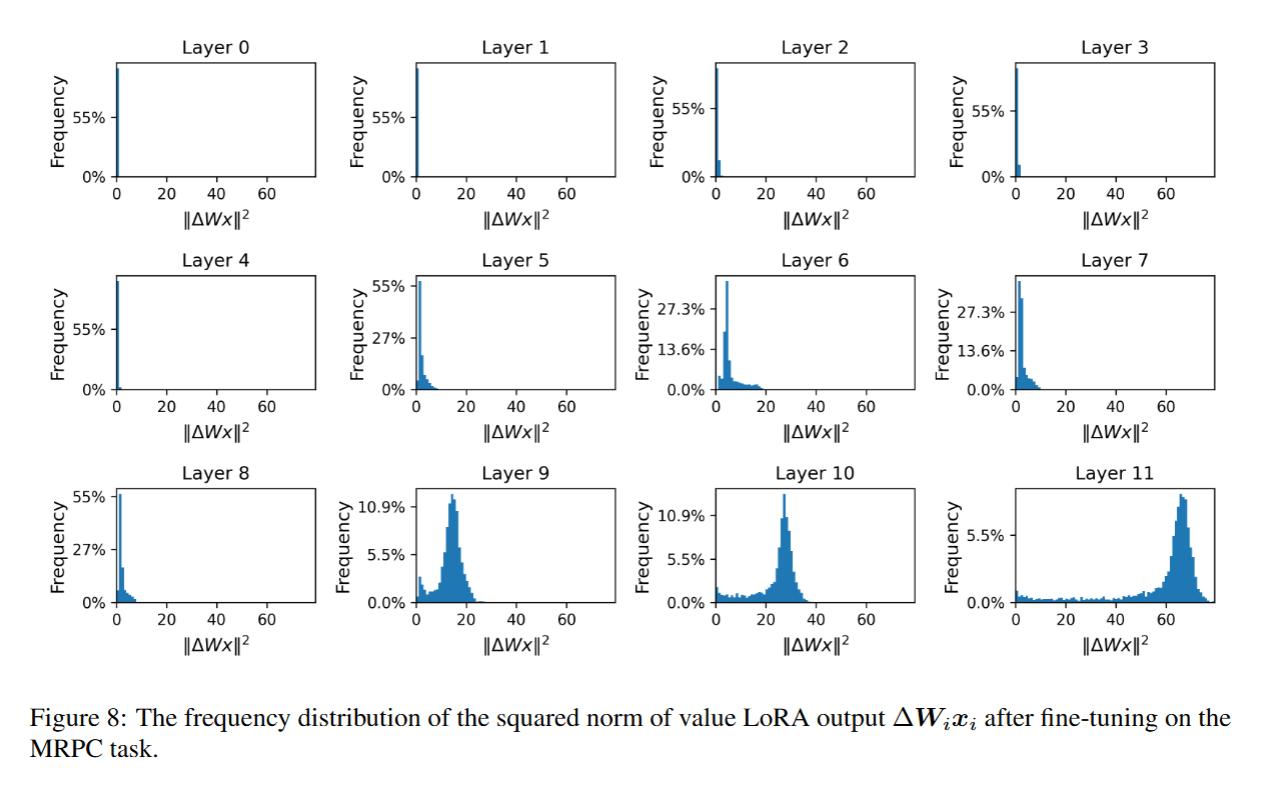
结果表明,部分层的 LoRA 对特定任务几乎无影响,而另一部分层的 LoRA 则表现出更为显著的作用。该结果为“基于 LoRA 输出评估进行剪枝” 的方法提供了实验依据(即可以裁剪输出影响弱的层,同时保留影响强的层)。
此外,RTE(文本蕴含识别任务)和 MRPC(微软研究释义语料库任务)呈现出不同的分布模式。这表明,在不同任务中,模型的不同层所发挥的作用存在差异。
5.2 实验指标
5.2.1 对于自然语言理解(NLU)任务
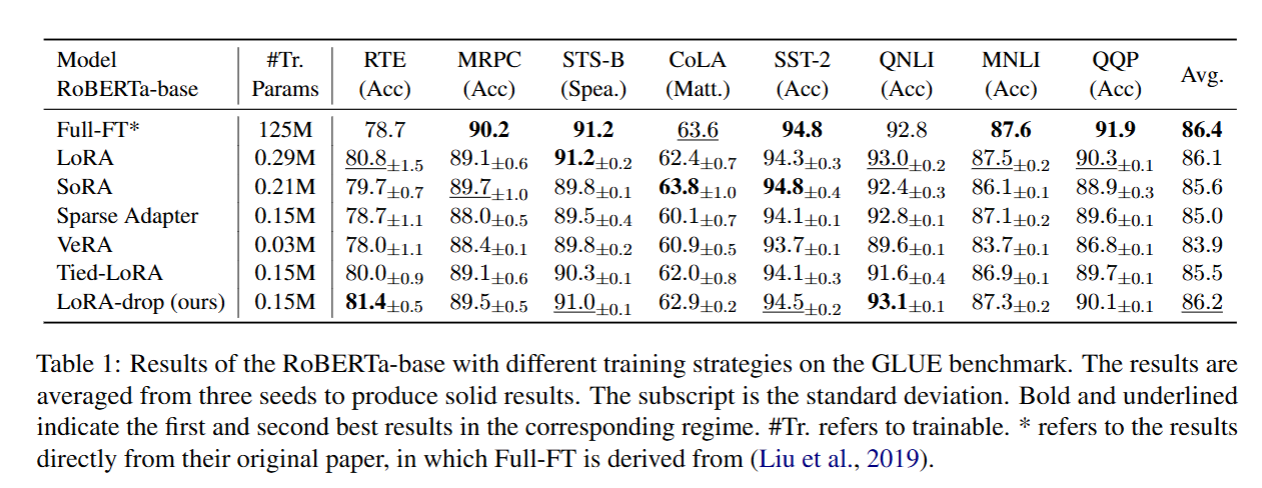
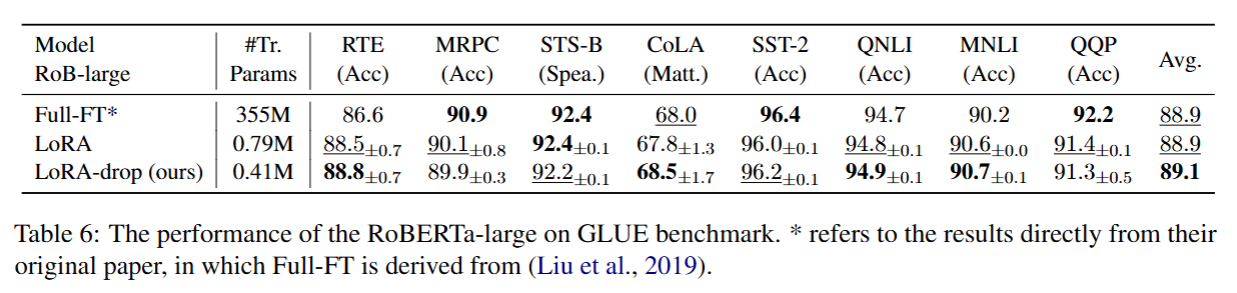
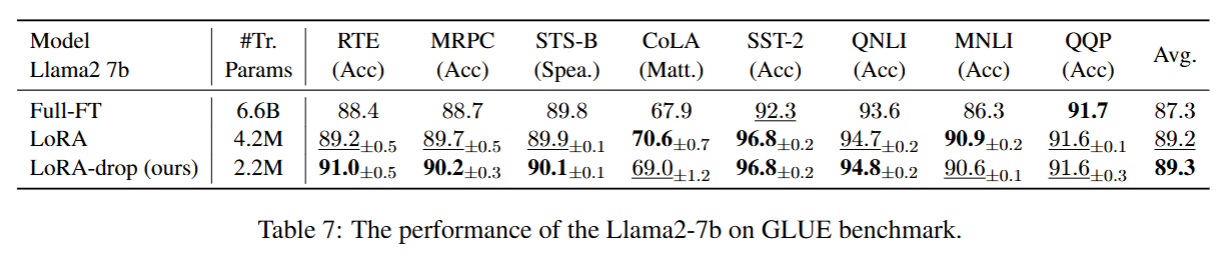
为验证所提方法在不同模型上的有效性,我们在 RoBERTa-base、RoBERTa-large以及 Llama2-7b三种模型上开展实验。我们基于这三款模型,在通用语言理解评估基准(GLUE)上完成了自然语言理解(NLU)任务的实验。该基准包含八个数据集,分别为:CoLA(单句语法判断(二分类),判断句子是否符合英语语法 / 语言习惯)、SST-2(单句情感分类(二分类),判断电影评论句子的情感是 “正面” 还是 “负面”)、MRPC(句子对释义判断(二分类),判断两个句子是否在语义上等价)、QQP(问题对语义等价判断(二分类),判断两个问题是否表达相同含义)、STS-B(句子对相似度评分(回归任务),给两个句子的语义相似性打 1-5 分(1 = 完全不相似,5 = 完全相似))、MNLI(句子对逻辑关系判断(三分类),判断 “前提句” 和 “假设句” 的关系:蕴含(假设成立)、矛盾(假设不成立)、中性(无关))、QNLI (问题与句子的蕴含判断(二分类),判断维基百科句子是否能回答对应的问题(即句子是否蕴含问题的答案))以及 RTE(句子对蕴含判断(二分类),判断 “前提句” 是否蕴含 “假设句”(仅区分 “蕴含” 和 “不蕴含”))。我们采用马修斯相关系数、斯皮尔曼相关系数和总体准确率,对 CoLA、STS-B以及 MNLI 数据集进行评估。对于其余数据集,我们采用准确率作为评估指标。针对每个数据集,我们使用不同的随机种子重复进行 3 次实验,并记录每次实验的最优结果,最终计算结果的平均值与标准差。
- 马修斯相关系数(MCC) 是一种用于评估二分类与多分类模型性能的平衡指标,衡量真实标签与预测标签间的相关程度,取值在 [-1, +1] (+1:完美预测,无任何错误。0:预测效果与随机猜测相当。1:预测与真实完全相反) 之间,综合考虑混淆矩阵的全部四个元素(TP、TN、FP、FN)。
对于二分类问题,MCC 的计算公式如下: MCC = T P × T N − F P × F N ( T P + F P ) ( T P + F N ) ( T N + F P ) ( T N + F N ) \text{MCC} = \frac{TP \times TN - FP \times FN}{\sqrt{(TP + FP)(TP + FN)(TN + FP)(TN + FN)}} MCC=(TP+FP)(TP+FN)(TN+FP)(TN+FN)TP×TN−FP×FN
注意:若分母中任意一项为零(如 T P + F P = 0 TP+FP=0 TP+FP=0),通常将分母设为 1,此时 MCC 为 0,符合随机预测的边界情况。
多分类 MCC 通过将问题转化为多个二分类问题(如一对一、一对多)计算,最终取平均或加权结果。
- 斯皮尔曼相关系数 本质是对两个变量的秩次(即排序后的位次)计算皮尔逊相关系数(统计学中衡量两个连续变量之间线性相关程度的核心指标,常用符号 r r r 表示,取值范围严格介于 -1 到 1 之间),因此也被称为 “秩相关系数”,常用符号 ρ ρ ρ 表示,取值范围为 [-1, +1](+1:两个变量完全正单调相关。0:两个变量无单调相关关系。-1:两个变量完全负单调相关)
无相同秩次(无重复值)的情况: ρ = 1 − 6 ∑ i = 1 n d i 2 n ( n 2 − 1 ) \rho = 1 - \frac{6\sum_{i=1}^{n}d_i^2}{n(n^2-1)} ρ=1−n(n2−1)6∑i=1ndi2
有相同秩次(存在重复值)的情况(此公式等价于秩次的皮尔逊相关系数): ρ = ∑ ( R x i − R x ˉ ) ( R y i − R y ˉ ) ∑ ( R x i − R x ˉ ) 2 ⋅ ∑ ( R y i − R y ˉ ) 2 \rho = \frac{\sum(R_{xi}-\bar{R_x})(R_{yi}-\bar{R_y})}{\sqrt{\sum(R_{xi}-\bar{R_x})^2 \cdot \sum(R_{yi}-\bar{R_y})^2}} ρ=∑(Rxi−Rxˉ)2⋅∑(Ryi−Ryˉ)2∑(Rxi−Rxˉ)(Ryi−Ryˉ)
5.2.2 对于自然语言生成(NLG)任务
为验证所提方法在自然语言生成(NLG)任务上的有效性,我们采用 Llama2-7b 模型,在表格转文本数据集(E2E、DART)、摘要生成数据集 DialogSum 以及数学推理数据集 GSM8K 上开展实验。我们分别采用 BLEU 指标、ROUGE 指标与准确率,对 E2E 和 DART 数据集、DialogSum 数据集、GSM8K 数据集进行评估。
- BLEU 指标是一种自动评估机器翻译质量的指标,通过对比机器翻译结果与人工参考译文的 n-gram 重叠程度来量化翻译的准确性和流畅性,取值范围为 [0, 1](也常换算为 0~100 的百分比),数值越高代表翻译质量越接近人工水平。核心思想是衡量候选译文与参考译文的 n-gram 匹配度,同时引入短句惩罚因子避免模型生成过短的译文,最终得分由 4 个 n-gram(通常 n=1~4)的精度( p n p_n pn )加权平均并结合惩罚因子(BP)得到。
BLEU = B P ⋅ exp ( 1 N ∑ n = 1 N ln p n ) \text{BLEU} = BP \cdot \exp\left( \frac{1}{N}\sum_{n=1}^N \ln p_n \right) BLEU=BP⋅exp(N1n=1∑Nlnpn)
B P = { 1 候选长度 ≥ 参考有效长度 exp ( 1 − 参考有效长度 候选长度 ) 否则 BP = \begin{cases} 1 & \text{候选长度} \geq \text{参考有效长度} \\ \exp\left(1 - \frac{\text{参考有效长度}}{\text{候选长度}}\right) & \text{否则} \end{cases} BP={1exp(1−候选长度参考有效长度)候选长度≥参考有效长度否则- ROUGE 指标 是一种自动文本生成评估指标,主要用于评估摘要、机器翻译等生成式任务的质量,核心是衡量生成文本与参考文本的 n-gram 重叠程度,且更侧重生成文本对参考文本关键信息的覆盖度。整体上,ROUGE 指标数值越高,通常意味着文本对参考文本关键信息的覆盖度越高。
5.3 实验结果
5.3.1 不同训练策略下 RoBERTa-base 模型、RoBERTa-large 与 Llama2-7b 模型在自然语言理解(NLU)上的实验结果
5.3.2 不同训练策略下 Llama2-7b 模型在自然语言生成(NLG)任务上的实验结果
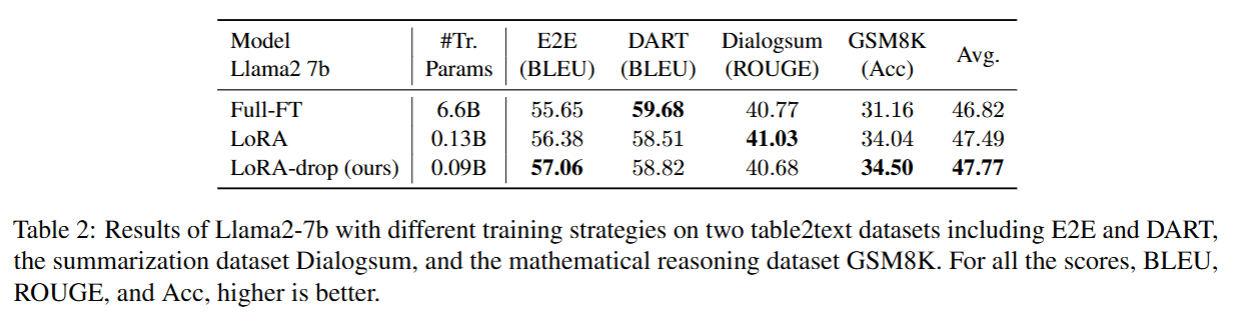
结合以上两项实验结果证实,LoRA-drop 在自然语言理解(NLU)与自然语言生成(NLG)两类任务上均具备有效性。
5.4 实验合理性分析
5.4.1 LoRA 的输出值代表其重要程度
重要性评估步骤会基于 LoRA 的输出对其重要性进行量化。我们验证这种基于输出的评估方法的有效性结果如下: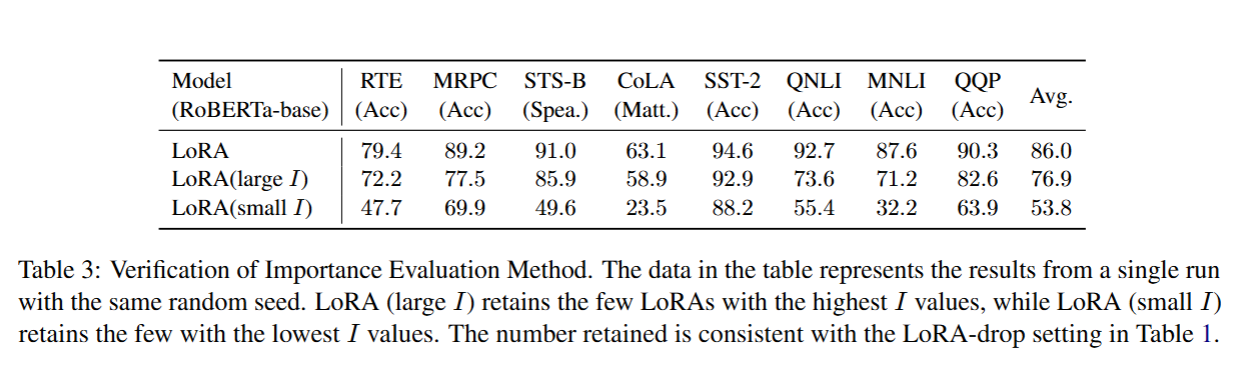
显然,当仅保留约半数的 LoRA 模块时,模型性能会出现显著下降。而当我们保留重要性分数 I I I 较高的 LoRA 模块时,模型性能要明显优于保留重要性分数 I I I 较低的模块。这一结果表明,LoRA-drop 方法所采用的基于层的 LoRA 重要性评估策略是切实有效的。输出平方范数更大的 LoRA,对模型微调的贡献确实更为显著。
5.4.2 LoRA 重要性的分布会因任务的不同而产生差异
LoRA-drop 的核心思路,是推导适配不同下游任务数据分布的 LoRA 重要性,进而实现 LoRA 参数的简化。为了进一步验证这一思路的合理性,我们绘制了热力图,用以展示 RoBERTa-base 与 Llama2 模型在 GLUE 基准的 8 个不同数据集上的 LoRA 重要性 I I I 的分布情况。我们观察到,不同数据集上的重要性分布存在差异,这表明 LoRA 所赋予的重要性具有数据依赖性。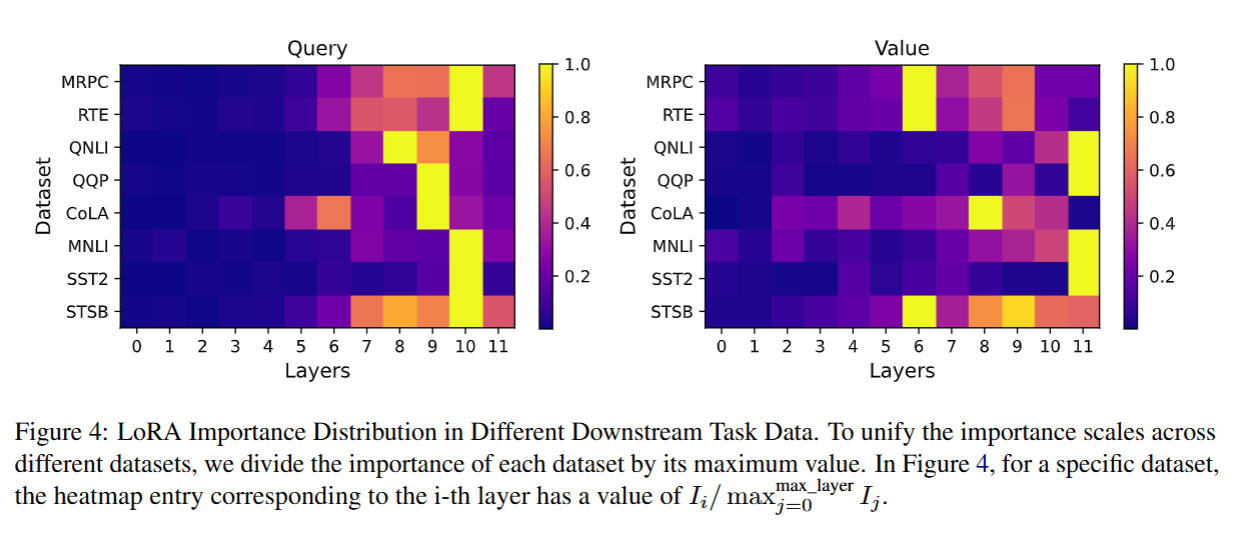
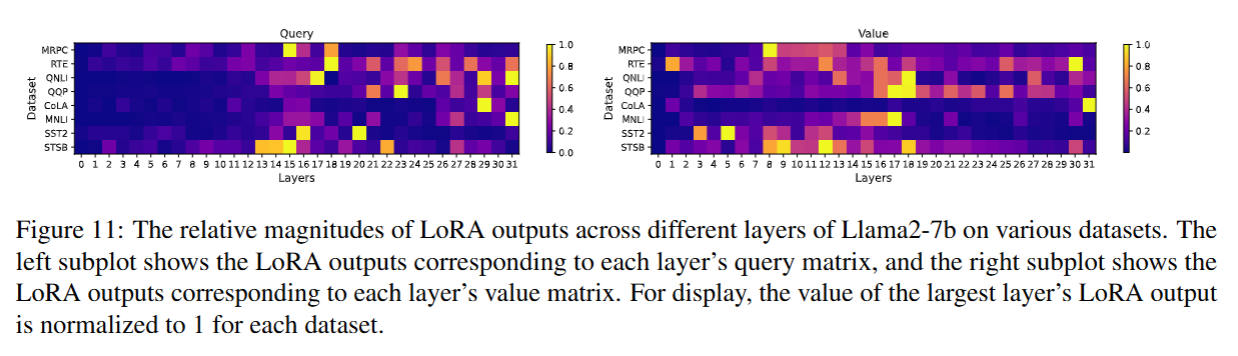
5.4.3 重要性较低的网络层共享相同的 LoRA 参数不会影响其他网络层的重要性分布
在我们的方法中,重要性较低的网络层会共享相同的 LoRA 参数。针对 LoRA 参数共享操作带来的影响展开探究,具体步骤为:先使用 20% 的 RTE (文本蕴含识别任务)训练集数据,对 RoBERTa-base 模型训练 4 个轮次,再执行 LoRA 参数共享操作;之后,我们绘制出了该模型各层的重要性分布图。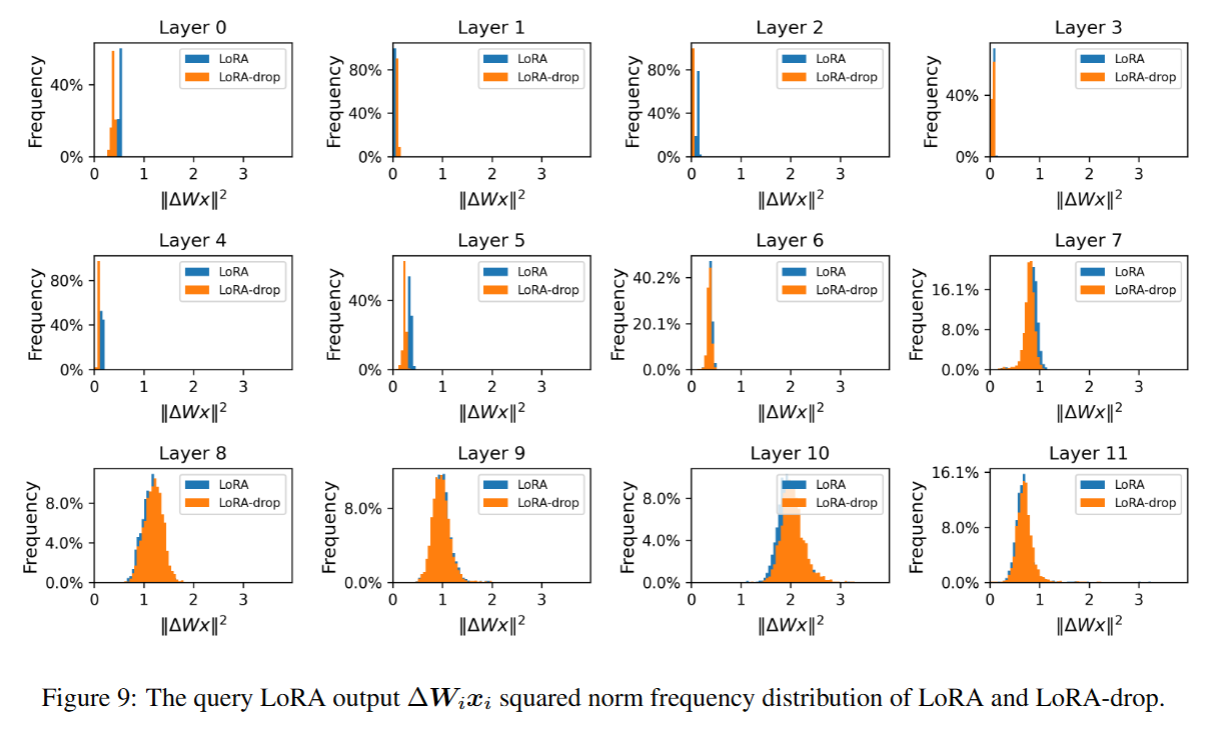
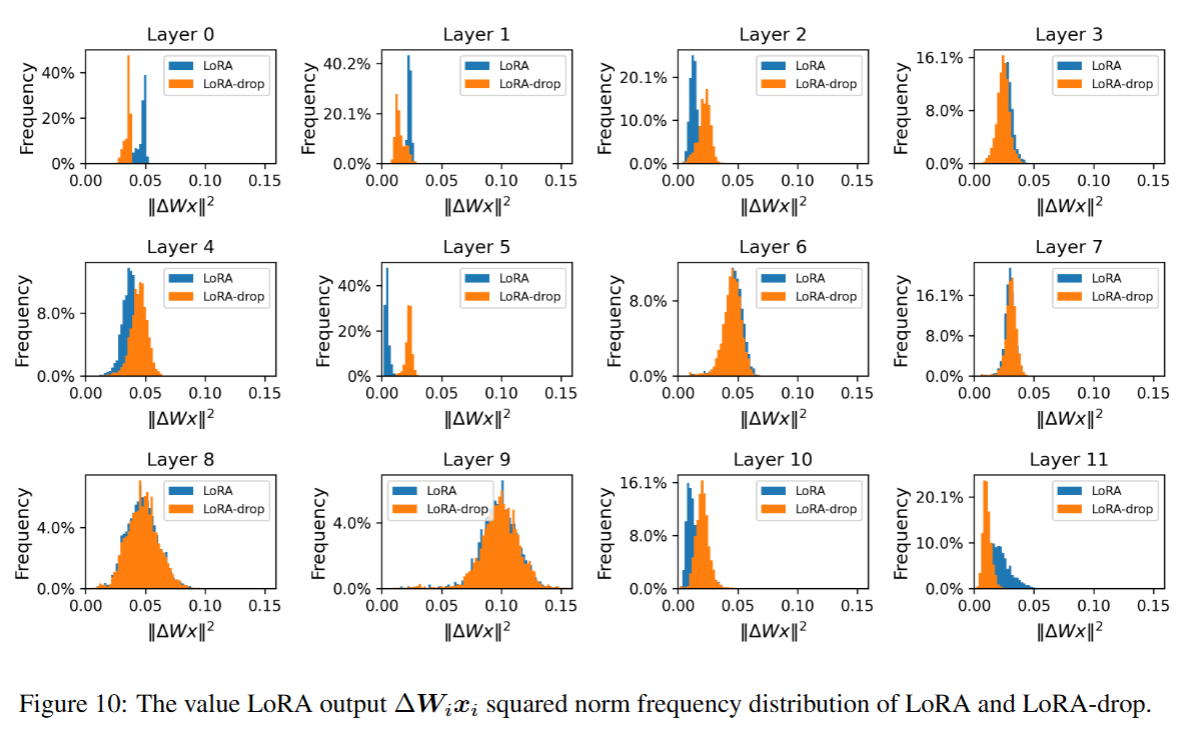
图中显示,各层 LoRA 的重要性分布在执行 LoRA 参数共享操作后,其分布与原始 LoRA 几乎保持一致。这表明,为低重要性网络层共享 LoRA 参数的做法,不会影响其他网络层的重要性分布,进而使模型维持良好的性能表现。
5.4.4 不同样本占比时各层的重要性排序保持相对稳定
我们探究了在计算 LoRA 重要性时,样本占比所产生的影响。随后我们从 RTE 数据集中采样得到10 个不同规模的数据集,采样比例覆盖 10% 至 100%,使用 LoRA 方法训练 RoBERTa-base 模型,且保证所有数据集的训练步数一致,随后得到不同样本占比对应的 LoRA 重要性分数。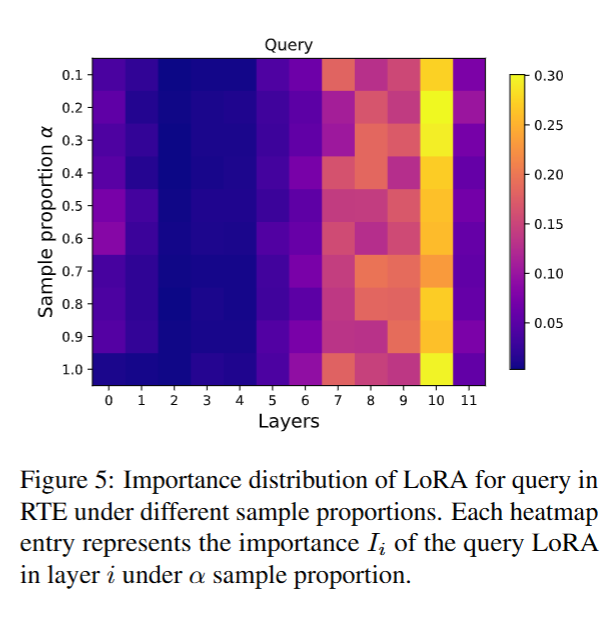
随着训练数据量的增加,各层的重要性排序保持相对稳定。对于作用于查询矩阵的 LoRA 而言,第 10 层始终是最重要的一层,而第 7、8、9 层的重要性则持续处于较高水平。这表明该操作对采样数据规模不敏感,具备良好的鲁棒性。
5.4.5 阈值 T T T 的选择
LoRA-drop 引入了超参数 T T T 来控制选中的层数。我们从 GLUE 基准中选取了 4 个数据集,用以分析阈值 T T T 的影响。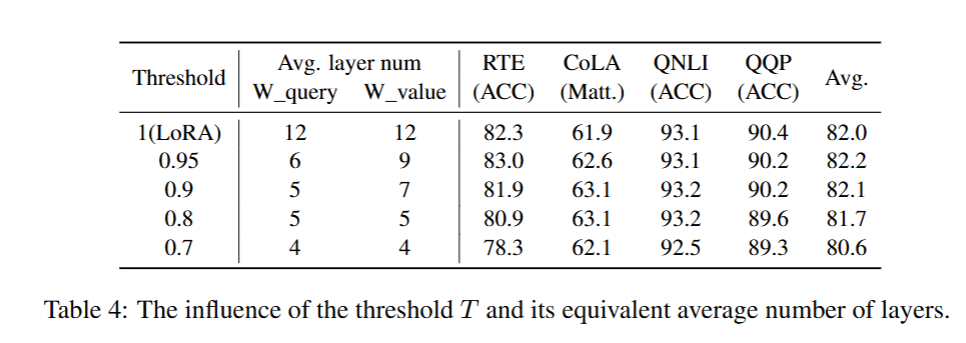
当阈值 T T T 设为 1 时,所有网络层均会被保留,这一设置等价于标准 LoRA 方法。当 T T T 小于 0.9 时,模型性能会随 T T T 的增大而提升,此时被筛选出的是重要性相对较高的 LoRA 模块。当 T T T 等于 0.9 时,平均约有半数网络层的 LoRA 模块会被选中。若 T T T 继续增大,新增选入的 LoRA 模块重要性会更低,模型性能也不再出现显著提升。因此,在本实验中,我们将阈值 T T T 默认设置为 0.9。
5.5 消融实验
消融实验( Ablation Study )指通过逐一移除模型的某个组件或模块,来验证该组件对模型性能的影响。我们通过开展消融实验来验证以下两个问题:
- 问题 1:在任务适配阶段,将重要性分数 I I I 较低的网络层对应的 LoRA 替换为共享参数,是否优于直接移除这些 LoRA?
- 问题 2:在任务适配阶段,保留重要性分数 I I I 较高的 LoRA 是否具备合理性?
为回答这两个问题,我们在 RoBERTa-base 模型上,将 LoRA-drop 方法与以下变体模型进行对比,其中 k k k 代表 LoRA-drop 方法所保留的 LoRA 模块数量。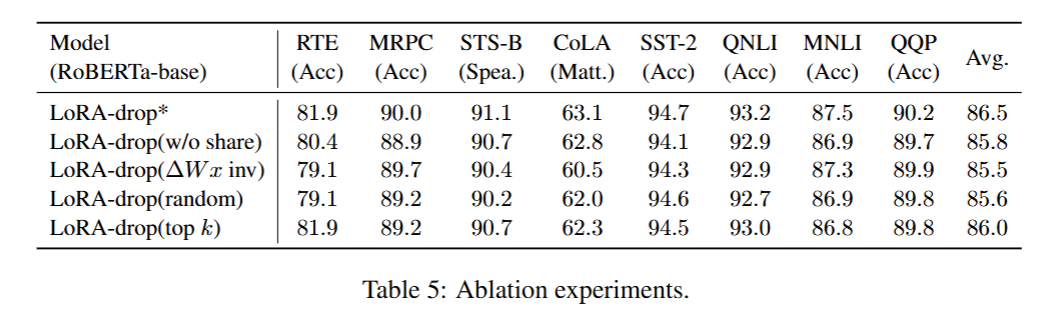
针对问题 1,直接移除重要性较低的 LoRA 参数在所有任务上的表现均劣于 LoRA-drop 方法,平均得分下降了 0.7 分。这表明,为重要性较低的网络层共享 LoRA 参数,相比直接移除这些网络层,该操作能实现更优的微调效果。
针对问题 2, Δ W x ΔWx ΔWx 共享设置取得了最差的平均性能,表现略逊于随机选取设置。这表明重要性分数 I I I 较低的 LoRA对模型性能提升的贡献更小。凭借经验保留前 k k k 层的前 k k k 层选取设置虽表现良好,但与 LoRA-drop 方法相比,仍存在 0.5 分的平均性能差距。
与其余三种变体模型相比,LoRA-drop 方法取得了更优的性能表现。这一结果验证了保留重要性较高的网络层对应的 LoRA这一策略的合理性,同时进一步证实了本文所提出的 LoRA 重要性评估方法的有效性。
六、个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解有限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)