Mysql架构揭秘:select语句的执行流程
一、概述:SELECT语句执行全景图
一条简单的SELECT * FROM users WHERE id = 1;语句在MySQL内部需要经历多个组件的协同处理。整个执行流程可以概括为以下关键阶段:
-
连接层 - 客户端与服务器建立通信
-
查询缓存 - 检查是否有可复用的查询结果
-
解析器 - 语法分析与语义验证
-
优化器 - 生成最优执行计划
-
执行器 - 调用存储引擎执行查询
-
返回结果 - 将数据返回给客户端
下面我们逐层深入解析每个环节的工作原理。
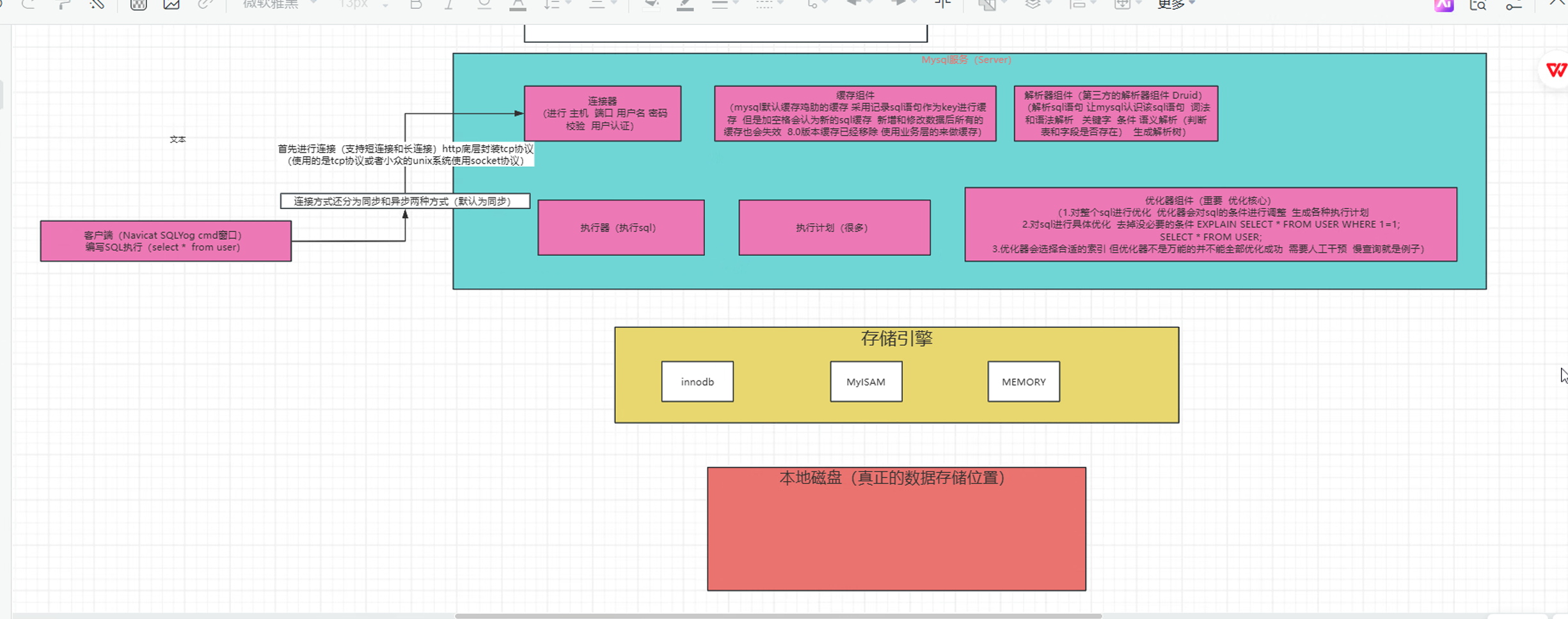
二、连接层:客户端与服务器的桥梁
2.1 连接建立机制
当MySQL服务器启动后,它作为一个守护进程监听客户端的连接请求。每次客户端发起连接时:
-
服务器为每个连接创建独立的线程(或从线程池分配)
-
每个线程拥有独立的内存处理空间
-
默认支持的最大并发连接数为151个(可通过配置调整)
-- 查看当前连接数
SHOW GLOBAL STATUS LIKE 'Thread%';
-- 查看最大连接数配置
SHOW VARIABLES LIKE 'max_connections';2.2 连接参数详解
|
参数 |
默认值 |
说明 |
|---|---|---|
|
|
28800秒 |
非交互式连接超时时间(如JDBC) |
|
|
28800秒 |
交互式连接超时时间(如客户端工具) |
|
|
151 |
最大并发连接数 |
-- 连接超时配置
SHOW GLOBAL VARIABLES LIKE 'wait_timeout';
SHOW GLOBAL VARIABLES LIKE 'interactive_timeout';重要提示:长连接可减少连接建立的开销,但需注意连接泄露问题。生产环境通常使用连接池管理连接。
三、查询缓存:已被淘汰的优化策略
3.1 历史背景
MySQL 5.7中查询缓存默认关闭,MySQL 8.0则完全移除了此功能。原因如下:
-
缓存失效频繁:任何表的数据变更都会使相关缓存失效
-
命中率低:SQL语句稍有变化(如空格差异)就不会命中缓存
-
维护开销大:缓存维护成本高,性能收益有限
3.2 历史配置回顾
-- 查看查询缓存配置(MySQL 5.7)
SHOW VARIABLES LIKE 'query_cache%';
-- 相关配置参数
query_cache_type = 0 -- 禁用缓存
query_cache_size = 0 -- 缓存大小为0现代建议:使用应用层缓存(如Redis)或分布式缓存替代MySQL查询缓存。
四、解析器:SQL语句的"翻译官"
解析器负责对SQL语句进行词法分析和语法分析:
-
词法分析:将SQL语句拆分为一个个"单词"(token)
-
语法分析:根据MySQL语法规则验证语句结构
-
生成解析树:构建树形数据结构表示查询结构
例如,对于SELECT * FROM users WHERE id = 1;:
-
识别
SELECT、FROM、WHERE为关键字 -
识别
*、users、id、1为标识符和常量 -
验证表
users是否存在,列id是否有效 -
构建包含查询所有元素的解析树
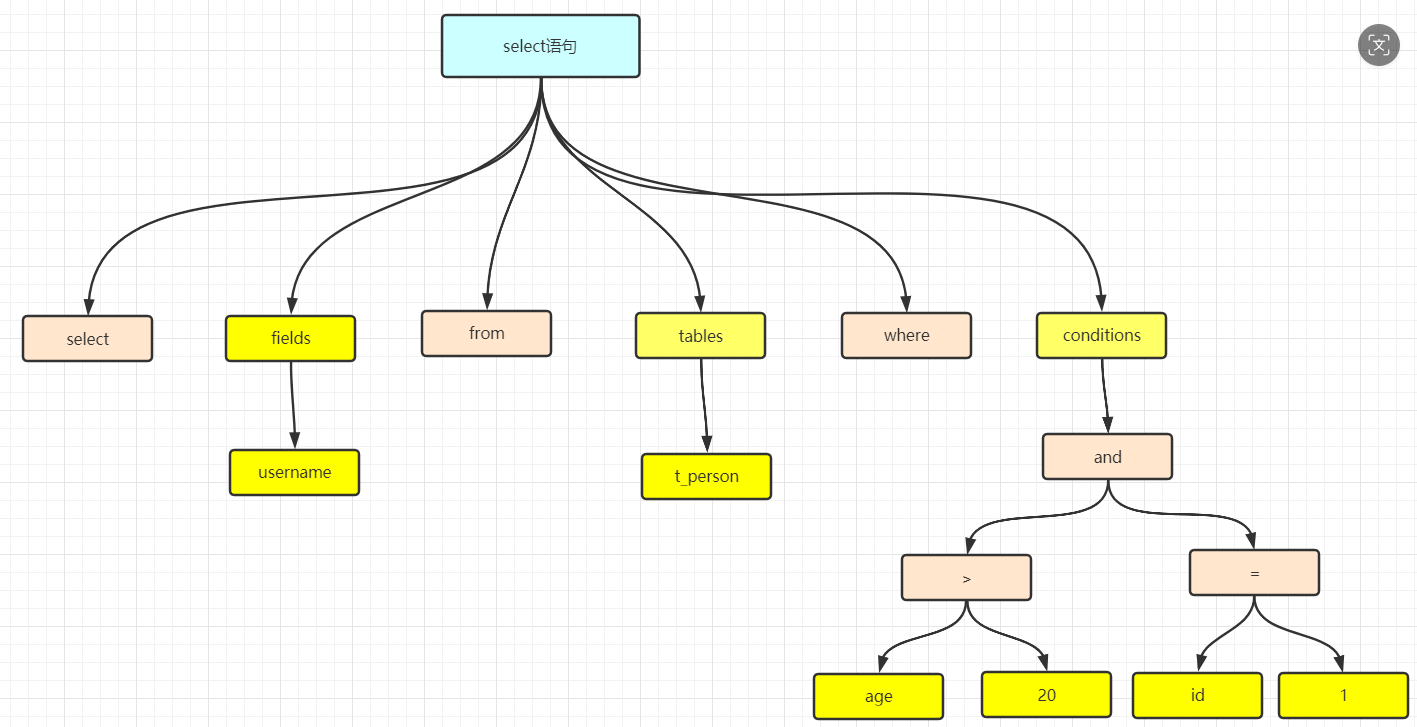
常见错误处理:
-
表不存在:
ERROR 1146 (42S02): Table 'test.users' doesn't exist -
语法错误:
ERROR 1064 (42000): You have an error in your SQL syntax
五、优化器:查询性能的关键大脑
优化器是MySQL的"智能引擎",负责从多种可能的执行路径中选择最优方案。
5.1 优化器核心职责
|
优化类型 |
具体说明 |
示例 |
|---|---|---|
|
执行计划选择 |
基于成本模型选择最优路径 |
多表JOIN的顺序优化 |
|
索引选择 |
从多个可用索引中选择最优索引 |
选择区分度高的索引 |
|
条件简化 |
简化冗余表达式 |
将 |
|
子查询优化 |
将子查询转换为JOIN操作 |
IN子查询转为SEMI-JOIN |
5.2 查看执行计划
-- 基本执行计划
EXPLAIN SELECT * FROM users WHERE age > 20;
-- 详细JSON格式执行计划
EXPLAIN FORMAT=JSON SELECT * FROM users WHERE age > 20;执行计划关键字段:
-
id:查询序列号 -
select_type:查询类型 -
table:访问的表 -
type:访问类型(性能关键) -
possible_keys:可能使用的索引 -
key:实际使用的索引 -
rows:预估扫描行数 -
Extra:额外信息
5.3 优化器成本模型
优化器基于"成本"(Cost)选择执行计划,成本因素包括:
-
I/O成本:磁盘读取数据页的开销
-
CPU成本:数据处理的计算开销
-
内存成本:内存使用开销
六、执行器与存储引擎:数据的最终获取
6.1 执行器职责
执行器根据优化器生成的执行计划:
-
调用存储引擎接口获取数据
-
处理WHERE条件过滤
-
执行必要的排序、分组等操作
-
将结果返回给客户端
6.2 存储引擎选择
MySQL支持多种存储引擎,各有适用场景:
|
存储引擎 |
特点 |
适用场景 |
|---|---|---|
|
InnoDB |
支持事务、行级锁、外键 |
默认选择,高并发事务 |
|
MyISAM |
表级锁、不支持事务 |
读多写少,全文搜索 |
|
Memory |
内存存储、速度快 |
临时表、缓存表 |
|
Archive |
高压缩、只支持INSERT/SELECT |
日志归档、历史数据 |
-- 查看支持的存储引擎
SHOW ENGINES;
-- 创建表时指定存储引擎
CREATE TABLE log_data (
id INT PRIMARY KEY,
content TEXT
) ENGINE=ARCHIVE;6.3 InnoDB存储引擎架构
对于默认的InnoDB引擎,数据获取流程:
执行器 → InnoDB引擎接口 → Buffer Pool检查 → 磁盘读取(如需要)Buffer Pool机制:
-
内存缓存池,减少磁盘I/O
-
默认大小128MB
-
使用改进的LRU算法管理
-
数据以16KB页为单位读取
七、性能优化实践建议
7.1 连接层优化
-
合理设置
max_connections,避免连接数不足 -
使用连接池,减少连接建立开销
-
监控连接数,防止连接泄露
7.2 查询优化重点
-
避免全表扫描:确保WHERE条件使用索引
-
合理使用索引:避免过多索引影响写性能
-
减少数据传输:只SELECT需要的列
-
避免复杂嵌套查询:尽量使用JOIN优化
7.3 存储引擎选择策略
-
默认使用InnoDB,兼顾事务与性能
-
只读场景考虑MyISAM+全文索引
-
临时数据使用Memory引擎
-
归档数据使用Archive引擎
八、总结
MySQL SELECT语句的执行是一个精心设计的流水线过程,每个组件各司其职:
-
连接层管理客户端通信,是查询的起点
-
解析器确保SQL语法正确,构建查询结构
-
优化器是智能核心,决定查询执行路径
-
执行器+存储引擎协作获取实际数据
理解这一流程对于:
-
诊断慢查询问题
-
设计高效数据库Schema
-
编写性能优化的SQL语句
-
合理配置MySQL服务器参数
具有至关重要的意义。掌握SELECT执行流程,是成为MySQL性能优化专家的第一步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)