OpenAI做了一次豪赌:不给任何指令,让模型自己学会所有任务

2019年2月,OpenAI发表了一篇论文。论文本身并不长,但它做了一件之前没有人敢认真尝试的事。
他们训练了一个15亿参数的语言模型,给它一个输入,不给任何额外的训练样本,不需要更新任何模型参数,只依靠输入的文本提示,它居然就能做翻译、做摘要、做问答。
这在当时叫zero-shot learning。模型从没见过这些任务的训练数据,但它就是会做。
OpenAI自己也吓了一跳。他们认为这个模型太强大了,可能被用来生成假新闻,所以最初只发布了小版本,完整模型后来才慢慢放出。这个决定本身又给GPT-2带来了巨大的关注度。
但抛开营销不谈,GPT-2真正重要的贡献是什么?它到底证明了什么?
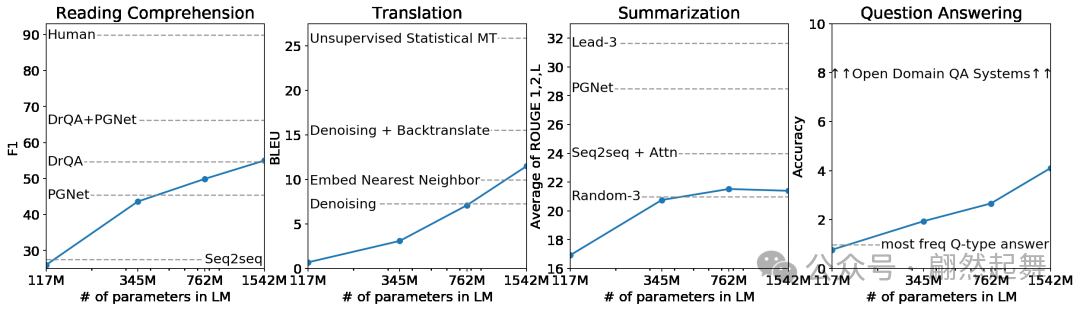
GPT-2的核心发现:随着模型规模增大,zero-shot能力在翻译、问答、摘要、常识推理等多个任务上持续提升。注意看每张小图的横轴(模型参数量)和纵轴(准确率),趋势几乎都是向上的(来源:原论文Figure 1)
一、"预测下一个词"到底有多强大?
让我们先想清楚一个最基本的问题。
GPT-2的训练目标只有一个:给一段文本,预测下一个词。就这么简单。
但仔细想想,要做好这件事,模型需要掌握什么?
给它一句"法国的首都是____",它需要知道地理知识。
给它一句"1+1等于____",它需要知道算术。
给它一句"他很生气,因为____",它需要理解情绪和因果关系。
给它一段新闻的前半段,让它续写,它需要了解新闻的写作风格和逻辑结构。
发现规律了吗?预测下一个词这个看似简单的目标,实际上要求模型学会世界上所有类型的知识。
因为如果你不懂语法,就预测不出语法正确的下一个词。如果你不懂常识,就预测不出合乎常理的续写。如果你不懂逻辑,就无法维持一段论述的一致性。
这就是语言模型最反直觉的地方:目标越简单,对能力的要求反而越全面。因为"正确预测下一个词"是一个几乎无限难的问题——你永远可以做得更好,只需要学更多的知识。
二、Zero-shot:不教就会?
GPT-2最让人惊讶的发现是zero-shot能力。
举个例子:给模型输入"Translate English to French: The cat is on the mat =“,它居然能输出法语翻译"Le chat est sur le tapis”。
模型从来没有被专门训练过翻译。它只是在海量文本上做了"预测下一个词"的训练。那它怎么就会翻译了?
答案是:训练数据中存在大量的翻译场景。
网页上经常出现"English: xxx / French: xxx"这样的双语对照。网页上经常出现双语对照的文档,或者论坛中包含提问和对应外语回答的文本。论坛上有人问"这句话法语怎么说?",下面有人回答。
GPT-2在预测下一个词的过程中,把这些模式全部学到了。当你给它"Translate English to French:"这个提示时,它识别出了这个模式,然后按照学到的模式续写。
这不就是"任务理解"吗?
模型不是在执行一个"翻译程序",而是在"延续一种文本模式"。但效果是一样的。这个洞察极其重要——它意味着,只要你给模型的提示足够清晰地定义了任务,模型就能用学到的模式来完成任务。
这个发现的影响是深远的。它直接导致了后来的prompt engineering——用自然语言描述任务,让模型理解并执行。到GPT-3的few-shot,再到ChatGPT的指令遵循,全部建立在这个发现之上。
三、字节级分词:消灭[UNK]这个毒瘤
在GPT-2之前,几乎所有的NLP模型都有一个尴尬的问题:遇到不认识的词怎么办?
传统的做法是用一个[UNK](unknown)token代替。但这就意味着模型完全无法处理这些词——它只知道"这里有个我不认识的词",除此之外一无所知。
对于人名、地名、术语、缩写、网络用语,这个问题尤其严重。互联网文本中充满了创造性的新词,你不可能把它们全部收录进词表。
GPT-2的解决方案非常优雅:不用词作为基本单位,用字节。
字节是什么?是计算机存储文本的最小单位。一个英文字符占1个字节,一个中文字符通常占3个字节。不管是什么词,什么语言,什么奇奇怪怪的符号,在计算机层面都是字节的序列。
用字节级分词的好处是:词表大小固定为256(字节的所有可能取值),永远不会遇到不认识的输入。
但纯字节的粒度太细了——"hello"被拆成5个字节,太碎片化。所以GPT-2用了Byte-level BPE(Byte Pair Encoding):先用字节表示所有文本,然后用BPE算法把经常一起出现的字节合并成更大的单元。
BPE的原理非常直觉:扫描整个训练语料,找出最频繁出现的相邻字节对,合并成一个新token。重复这个过程,直到词表达到你想要的大小。
比如"th"经常一起出现,就合并成一个token。"the"经常出现,再合并。最终,常见单词是完整的token,罕见单词会被拆成字节级的子串。
这个设计的精妙之处在于:它同时解决了一词一token(词表太大)和一字符一token(太碎片化)的两个极端问题。今天几乎所有的大模型都在用某种形式的BPE。
四、LayerNorm的位置:一个小调整,影响了整个行业
原始Transformer中,Layer Normalization的位置是在残差连接之后(Post-LN):
output = LayerNorm(x + Sublayer(x))
GPT-2改成了在子层之前(Pre-LN):
output = x + Sublayer(LayerNorm(x))
看起来只是换了个位置,为什么这么重要?
要先理解LayerNorm到底做了什么。对于输入向量x,它做了四步操作:
1. 算均值:mu = mean(x)
2. 算方差:sigma = std(x)
3. 标准化:x_hat = (x - mu) / sigma
4. 缩放平移:y = gamma * x_hat + beta(gamma和beta是可学习的参数)
本质上就是把输入拉到均值为0、方差为1的分布上,再用可学习的参数调整到合适的范围。
为什么Pre-LN更稳定?
在Post-LN中,残差连接的输出直接进入LayerNorm。如果子层的输出数值很大,LayerNorm的梯度会变得很小(因为除以了很大的标准差)。这就导致了深层网络中梯度消失的问题——越深越严重。
在Pre-LN中,先对输入做标准化,保证进入子层的数值始终在合理范围内。而残差连接的直通通道(+x)完全不受LayerNorm影响,梯度可以无障碍地传播。
打个比方:Post-LN相当于在高速公路上设了一个收费站,虽然能保证通过的车辆速度合理,但也降低了通行效率。Pre-LN相当于在上高速之前先检查一遍,上了高速就一路畅通。
后来的研究发现,用Pre-LN训练深层Transformer时,可以不用learning rate warmup(学习率预热),训练更稳定。这个小小的改动,使得GPT系列能够堆叠到几十层甚至近百层。
五、规模化的信仰:更大就一定更好吗?
GPT-2有15亿参数。在当时这是一个很大的数字,但跟今天的千亿参数模型相比微不足道。
但GPT-2最重要的遗产不是模型本身,而是一个信念:只要继续增大模型和数据,语言模型就会不断涌现出新的能力。
这个信念不是凭空产生的。GPT-2的论文中,OpenAI展示了明确的证据:更大的模型在zero-shot任务上表现更好。从1.17亿参数到15亿参数,翻译、摘要、问答的性能都在稳步提升。
当然,GPT-2本身的能力还很粗糙。它的翻译远不如专业翻译系统,摘要经常跑题,问答经常答非所问。但它证明了一个方向性的判断:规模化是通向更强AI的一条可行路径。
正是这个判断,驱动OpenAI投入巨资训练GPT-3(1750亿参数),然后是GPT-4。也驱动了整个行业走上了"scaling up"的不归路。
回头看,GPT-2的论文标题"Language Models are Unsupervised Multitask Learners"(语言模型是无监督多任务学习者)本身就是最大的洞察:语言模型不是在学语言,它是在通过语言学世界。当你给它足够大的模型和足够多的数据,它学到的就不只是语法和词汇,而是翻译、推理、知识、逻辑——所有嵌入在人类语言中的智慧。
这是GPT-2留给我们最重要的遗产。
论文链接:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
kk的大模型论文学习笔记 · 第4篇 · GPT-2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)