免费使用商汤 SenseNova U1:新一代端到端统一多模态生图模型深度解析
模型仓库:https://github.com/OpenSenseNova/SenseNova-U1
HuggingFace:https://huggingface.co/sensenova/SenseNova-U1-8B-MoT
官方文档:https://platform.sensenova.cn/docs
在线体验:https://unify.light-ai.top/
许可证:Apache-2.0
一、模型概览
SenseNova U1 是商汤科技于 2026 年 4 月 28 日发布并开源的新一代原生多模态大模型,基于自研 NEO-Unify 架构,在单一架构内统一了多模态理解、推理与生成能力。它标志着多模态 AI 从"模态拼接"到"真正统一"的根本性范式转变——不再依赖适配器在模态间翻译,而是让语言和视觉在同一架构内原生协同思考与行动。
sensenova-u1-fast 是 SenseNova U1 在商汤日日新平台上的快速推理版本,针对高吞吐、低延迟场景优化,通过 API 即可调用,适合生产环境集成。

1.1 NEO-Unify 核心架构
NEO-Unify 从第一性原理出发设计,彻底消除了传统多模态模型中的视觉编码器(VE)和变分自编码器(VAE),让像素-词语信息在端到端训练中深度关联:
- 端到端统一建模:语言和视觉信息作为统一复合体建模,消除模态间的翻译损耗
- 语义与像素兼得:在保持像素级视觉保真度的同时保留语义丰富性
- 原生 MoT 高效推理:通过原生 Mixture-of-Token 机制实现跨模态高效推理,最小化模态冲突
1.2 开源模型矩阵
| 模型 | 参数量 | 说明 |
|---|---|---|
| SenseNova-U1-8B-MoT-SFT | 8B MoT | SFT 版本(×32 下采样比) |
| SenseNova-U1-8B-MoT | 8B MoT | 最终版本(经 T2I RL 训练) |
| SenseNova-U1-8B-MoT-LoRA-8step-V1.0 | 0.4B | LoRA 微调权重 |
| SenseNova-U1-A3B-MoT-SFT | A3B MoT | MoE 架构 SFT 版本 |
| SenseNova-U1-A3B-MoT | A3B MoT | MoE 架构最终版本 |
二、核心能力
2.1 文生图(Text-to-Image)
SenseNova U1 不仅能生成高质量的通用图像,还具备独特的推理生图能力。模型在生成图像前会先进行显式推理——理解指令、分析物理规律、建立构图框架、设定光影配色、锁定风格——然后才输出最终图像。

例如输入"一只雄孔雀试图吸引雌性",模型会推理出雄孔雀通过展开尾羽进行求偶展示,然后生成一张尾羽完全展开的孔雀照片,而非简单地绘制一只孔雀。
2.2 交错图文生成(Interleaved Generation)
SenseNova U1 可在单次生成中产出文本与图像交错排列的连贯内容,适用于图文教程、旅行日记、信息图表等场景。例如"给我一份番茄炒蛋的新手图解教程",模型会生成步骤文字配合对应插图。

2.4 高密度信息图渲染
模型在信息图(Infographic)生成方面表现尤为突出,可生成知识插画、海报、演示文稿、漫画、简历等高密度视觉布局,在 BizGenEval 和 IGenBench 等信息图基准上达到开源 SOTA。

2.5 视觉理解(VQA)
除生成能力外,SenseNova U1 同时具备强大的视觉理解能力,可对图像进行深度问答分析,实现理解与生成的真正统一。
三、本地部署教程
3.1 环境准备
# 克隆仓库
git clone https://github.com/OpenSenseNova/SenseNova-U1.git
cd SenseNova-U1
# 使用 uv 安装依赖(推荐)
uv pip install -e .
3.2 文生图推理
python examples/t2i/inference.py \
--model_path sensenova/SenseNova-U1-8B-MoT \
--prompt "一只金色的凤凰在日出时飞翔" \
--width 2048 --height 2048 \
--cfg_scale 4.0 \
--cfg_norm none \
--timestep_shift 3.0 \
--num_steps 50 \
--output output.png \
--profile
默认分辨率为 2048×2048(1:1),支持多种宽高比。高质量信息图生成建议先进行 Prompt 增强。
3.3 图像编辑推理
python examples/editing/inference.py \
--model_path sensenova/SenseNova-U1-8B-MoT \
--prompt "Change the animal's fur color to a darker shade." \
--image examples/editing/data/images/1.webp \
--cfg_scale 4.0 --img_cfg_scale 1.0 \
--cfg_norm none --timestep_shift 3.0 \
--num_steps 50 --output output_edited.png \
--profile --compare
💡 建议先将输入图片预缩放至约 2048×2048 分辨率以获得最佳质量。
3.4 交错图文生成
python examples/interleave/inference.py \
--model_path sensenova/SenseNova-U1-8B-MoT \
--prompt "我想学做番茄炒蛋,请给我一份新手友好的图解教程。" \
--resolution "16:9" \
--output_dir outputs/interleave/ \
--stem demo --profile
3.5 消费级显卡方案:GGUF 量化 + VRAM 模式
对于单张消费级 GPU 用户,两种方案可组合使用以降低显存占用:
GGUF 量化(Q3/Q4/Q5/Q6/Q8 多种精度):
uv pip install -e ".[gguf]"
python examples/t2i/inference.py \
--model_path sensenova/SenseNova-U1-8B-MoT \
--gguf_checkpoint /path/to/SenseNova-U1-8B-MoT-Merger-Q4_K_M.gguf \
--prompt "A male peacock trying to attract a female" \
--output output.png
VRAM 模式(CPU-GPU 分层卸载):
| 模式 | 行为 | 适用场景 |
|---|---|---|
full(默认) |
全部在 GPU | 显存充足,速度最快 |
low |
同步逐层 CPU↔GPU 交换 | 最低显存占用 |
balanced |
异步预取,重叠 H2D 拷贝与计算 | 显存紧张但需兼顾速度 |
# 推荐:Q4 量化 + balanced 模式,适合 10-12GB 消费级显卡
python examples/t2i/inference.py \
--model_path sensenova/SenseNova-U1-8B-MoT \
--gguf_checkpoint /path/to/SenseNova-U1-8B-MoT-Merger-Q4_K_M.gguf \
--vram_mode balanced \
--prompt "..." --output output.png
四、API 调用
4.1 商汤日日新平台 API
通过 SenseNova 平台 调用 sensenova-u1-fast,无需本地 GPU:
import openai
client = openai.OpenAI(
api_key="YOUR_SENSENOVA_API_KEY",
base_url="https://api.sensenova.cn/v1"
)
# 文生图
response = client.images.generate(
model="sensenova-u1-fast",
prompt="一只金色凤凰在日出时飞翔,中国水墨画风格",
size="1024x1024",
n=1
)
image_url = response.data[0].url
print(f"Generated image: {image_url}")
完整 API 文档参见:https://platform.sensenova.cn/docs
4.2 API 参数说明
| 参数 | 说明 | 示例 |
|---|---|---|
model |
模型名称 | sensenova-u1-fast |
prompt |
生成提示词 | 中文/英文均可 |
size |
图像尺寸 | 1024x1024、1536x1024、1024x1536 |
n |
生成数量 | 1-4 |
response_format |
返回格式 | url 或 b64_json |
五、Agent 接入
5.1 OpenClaw 接入(SenseNova-Skills)
商汤官方提供了 SenseNova-Skills 插件,支持 OpenClaw 代理直接调用 SenseNova U1 的生成能力:
# 安装 OpenClaw 技能插件
openclaw skill add sensenova-u1
安装后,代理可通过自然语言触发生图:"用 SenseNova U1 生成一张关于 AI 发展的信息图"。
5.2 MCP Server 接入
通过 MCP 协议接入,任何 MCP 兼容客户端(Claude Code、Cursor、Cline 等)均可调用:
{
"mcpServers": {
"sensenova-u1": {
"command": "npx",
"args": ["-y", "@sensenova/mcp-server-u1"],
"env": {
"SENSENOVA_API_KEY": "YOUR_API_KEY"
}
}
}
}
5.3 自定义 Agent 集成
基于 OpenAI 兼容接口,任何支持 OpenAI API 格式的 Agent 框架均可快速接入:
from openai import OpenAI
def generate_image_for_agent(prompt: str, agent_context: str = ""):
"""Agent 调用生图工具的封装函数"""
client = OpenAI(
api_key="YOUR_SENSENOVA_API_KEY",
base_url="https://api.sensenova.cn/v1"
)
enhanced_prompt = f"{agent_context}\n{prompt}" if agent_context else prompt
response = client.images.generate(
model="sensenova-u1-fast",
prompt=enhanced_prompt,
size="1024x1024",
n=1
)
return response.data[0].url
六、在线网站体验
6.1 Light-AI Unify
🔗 https://unify.light-ai.top/
Light-AI Unify 提供了 SenseNova U1 的第三方在线体验入口,主打"理解·生成·统一"理念,支持智能生成工作台和信息图制作功能。

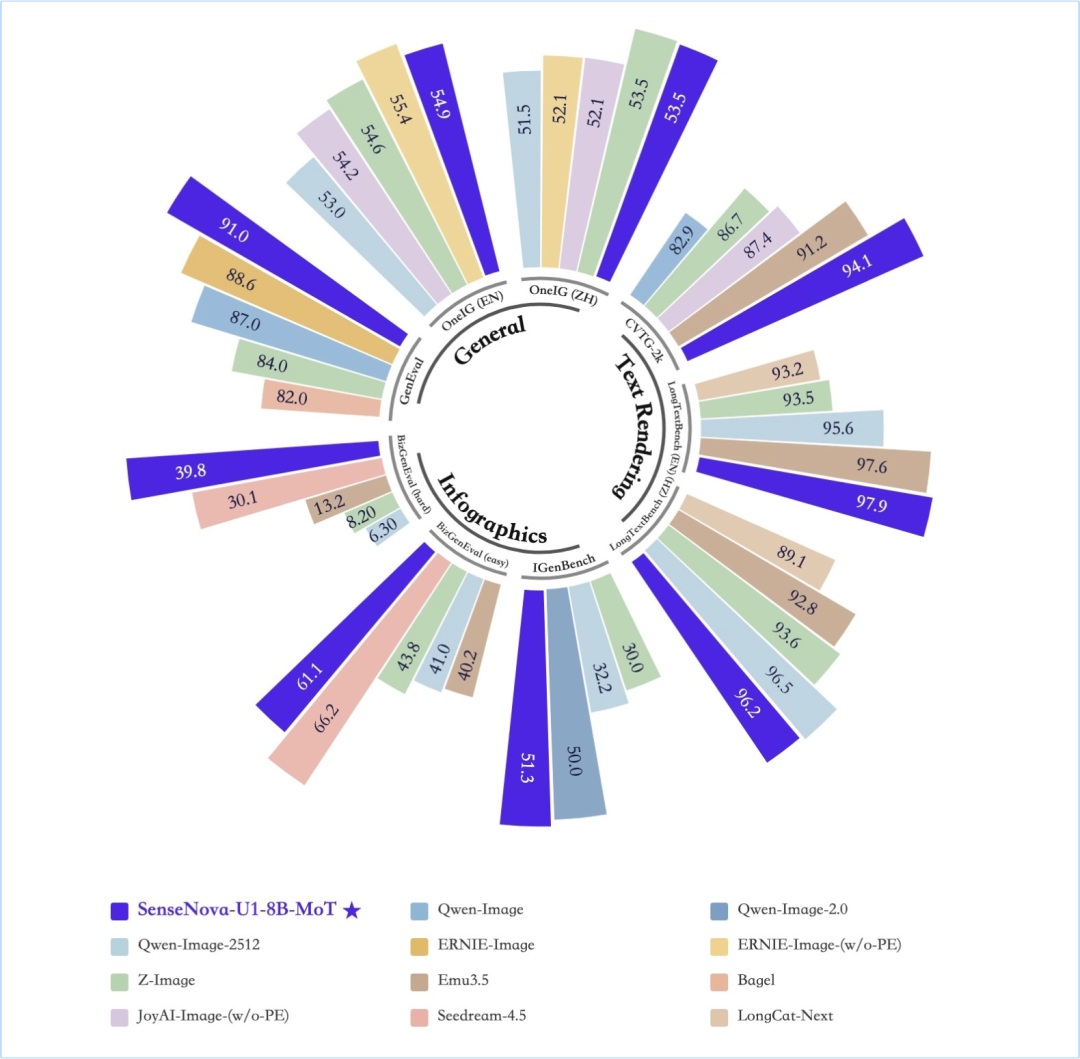
七、性能与基准
SenseNova U1 在多个基准上达到开源 SOTA:
- 文生图:OneIG(中英文)、LongText(中英文)、CVTG 等基准上的性能-延迟比领先
- 信息图:BizGenEval(Easy/Hard)、IGenBench 上达到开源最优
- 理解+生成统一:单一模型同时登顶理解和生成榜单,此前需要分别使用专用模型
以 8B 参数量实现媲美商业模型的效果,成本效率极高。
八、总结
SenseNova U1 凭借 NEO-Unify 架构实现了多模态理解与生成的真正统一,在文生图、图像编辑、交错图文、信息图渲染等任务上均达到开源 SOTA 水平。通过 GGUF 量化 + VRAM 分层卸载,10-12GB 消费级显卡即可本地运行;通过日日新平台 API 和 MCP 协议,可快速集成到 Agent 工作流中;通过 SenseNova Studio 和 Light-AI Unify,零门槛即可在线体验。无论你是开发者、设计师还是内容创作者,SenseNova U1 都提供了适合的接入路径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)