即梦 Agent 后端编排逻辑深度拆解-设计可视化
即梦 Agent 后端编排逻辑深度拆解-设计可视化
一份面向产品 / 研发 / Agent 设计的逆向架构拆解。
核心结论:即梦 Agent 的本质不是“会生成内容的 LLM”,而是LLM 编排器 + 技能插件 + 执行引擎。
即梦 Agent 的后端更像一个三层编排系统:
- Layer 1:Router 路由层 —— 负责安全审核、意图识别、任务分类、技能分配
- Layer 2:Skill 技能层 —— 负责按需加载工作流规则与 SOP
- Layer 3:Execution 执行层 —— 负责真正提交图片 / 视频 / 文件类任务
1. 整体架构总览
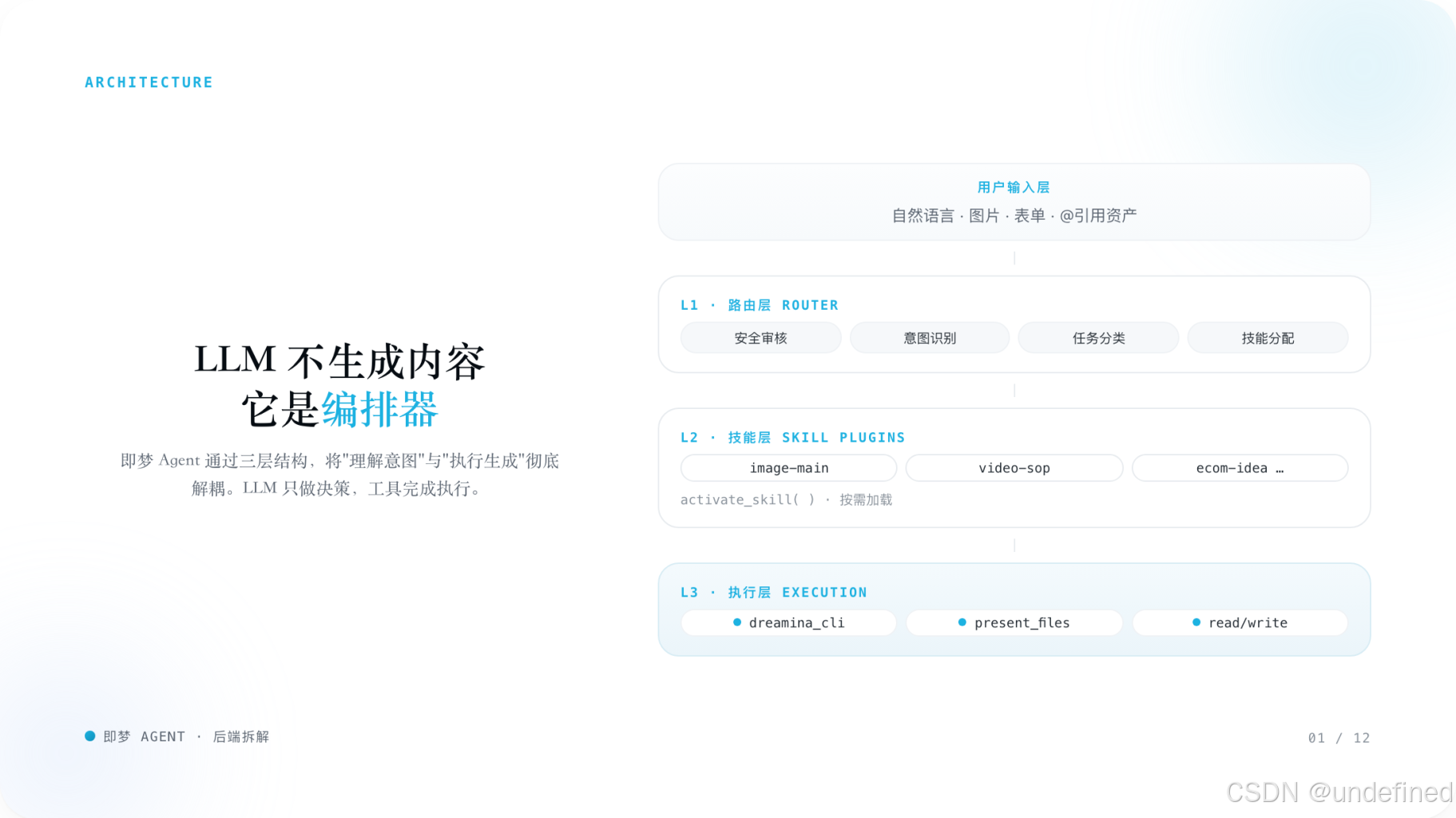
- LLM 负责理解与编排,不直接承担最终生成
- 真正的生产动作由底层工具执行
- 整体系统是一个典型的 Orchestrator 模式,不是单体 Prompt 模式
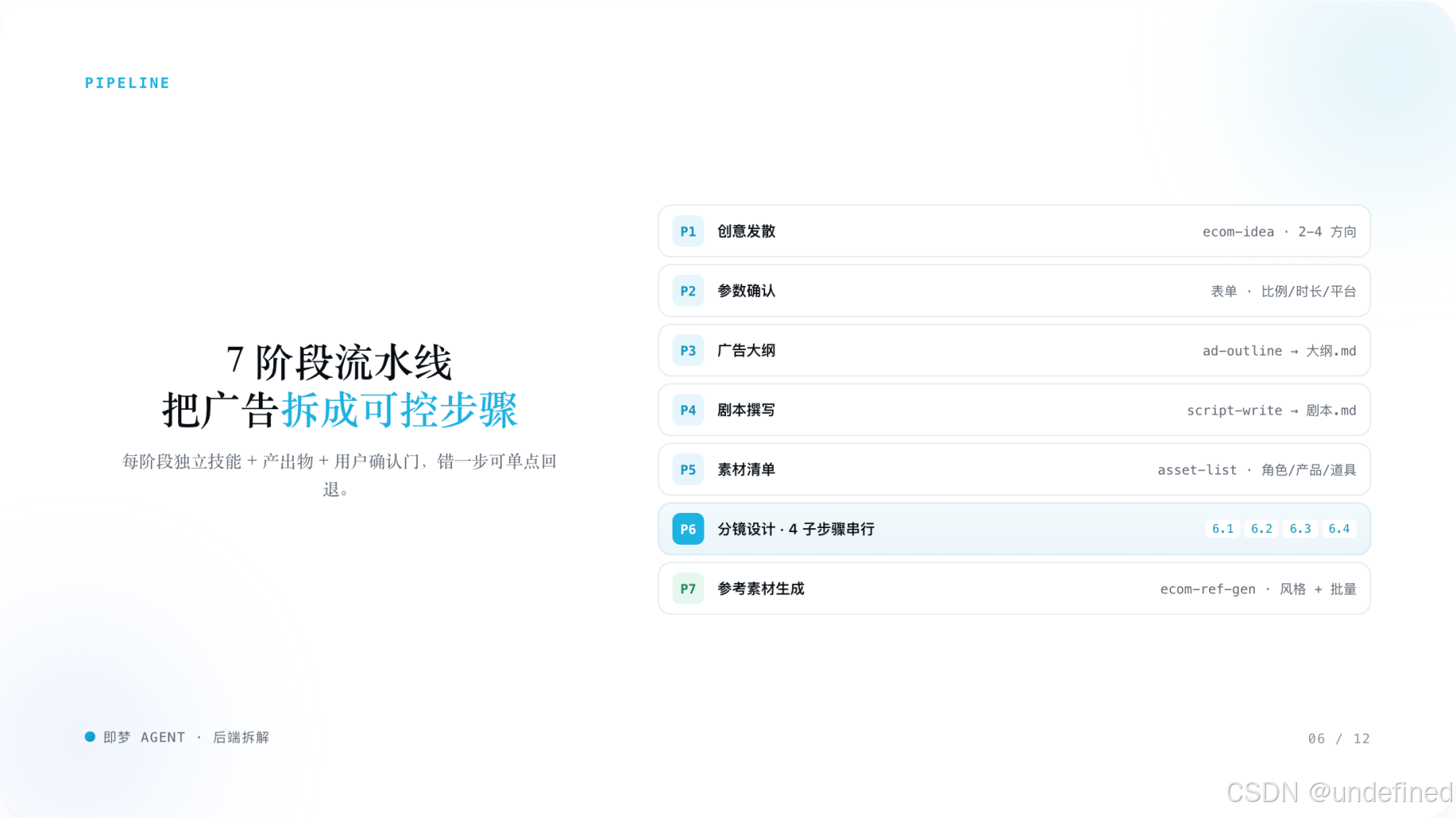
2. 七大核心工具
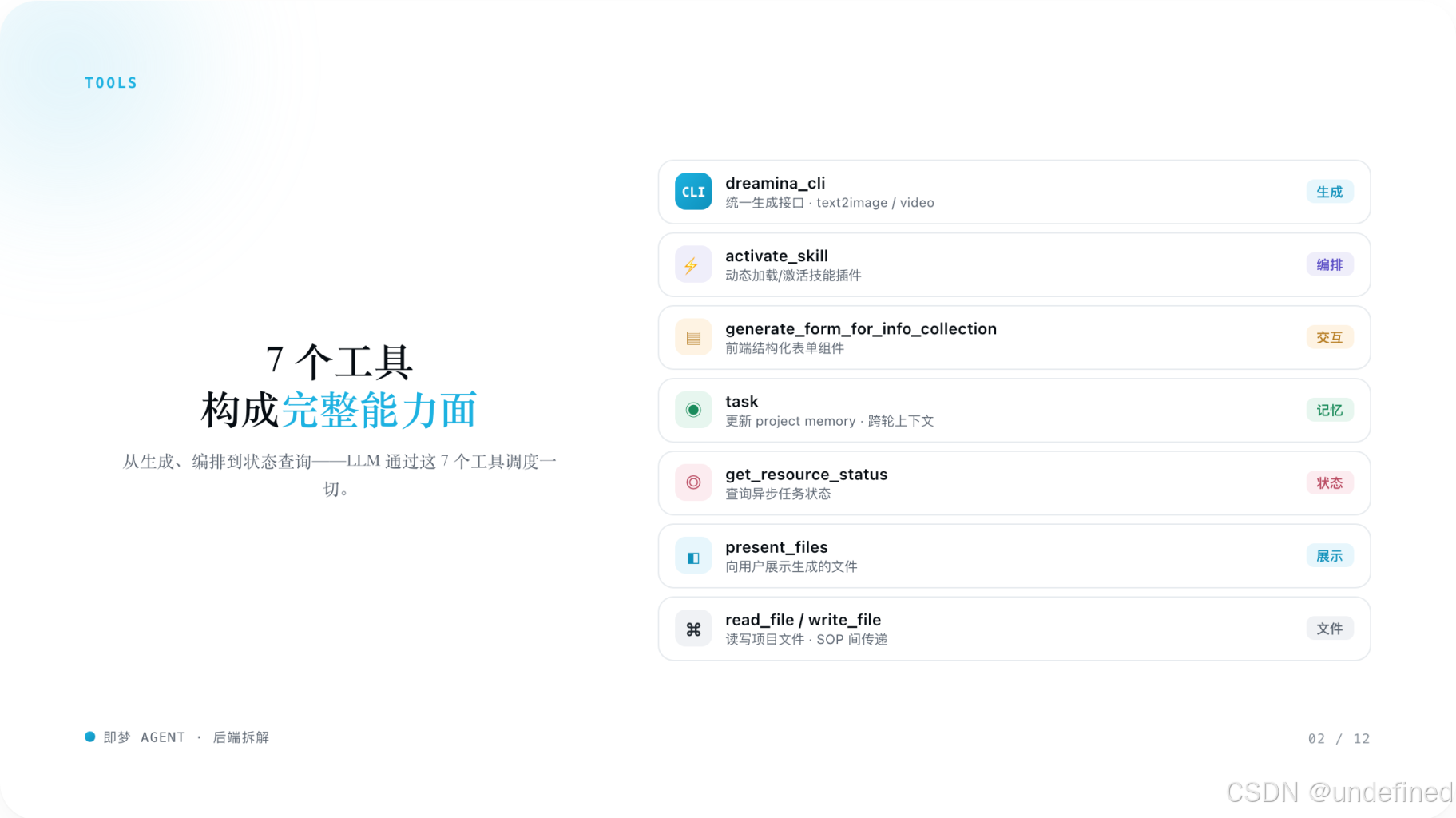
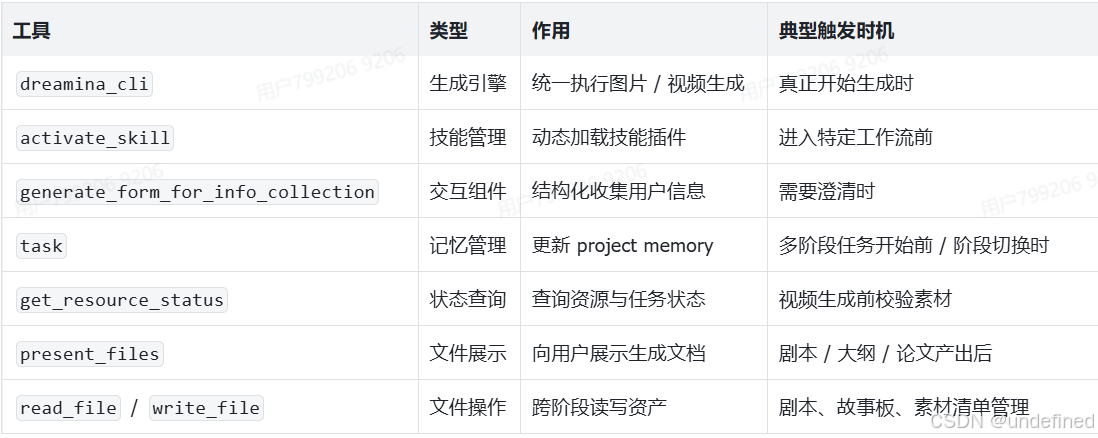
dreamina_cli 参数逻辑
- command: text2image
- prompt: Agent 自动扩写
- output_id: 语义化命名
- ratio: 自动推断
- resolution_type: 默认 4K
- model: 默认 5.0
- command: text2video / image2video
- prompt: 视频描述或分镜脚本
- duration: 4-15 秒
- ratio: 默认 16:9
- resolution: 默认 720P
- model: 默认 seedance2.0_vip
- ref_images: 风格 / 角色 / 产品 / 道具
ref_images 顺序规则:风格图 → 角色 → 产品 → 道具

3. 技能调度机制:按需加载,而不是预加载
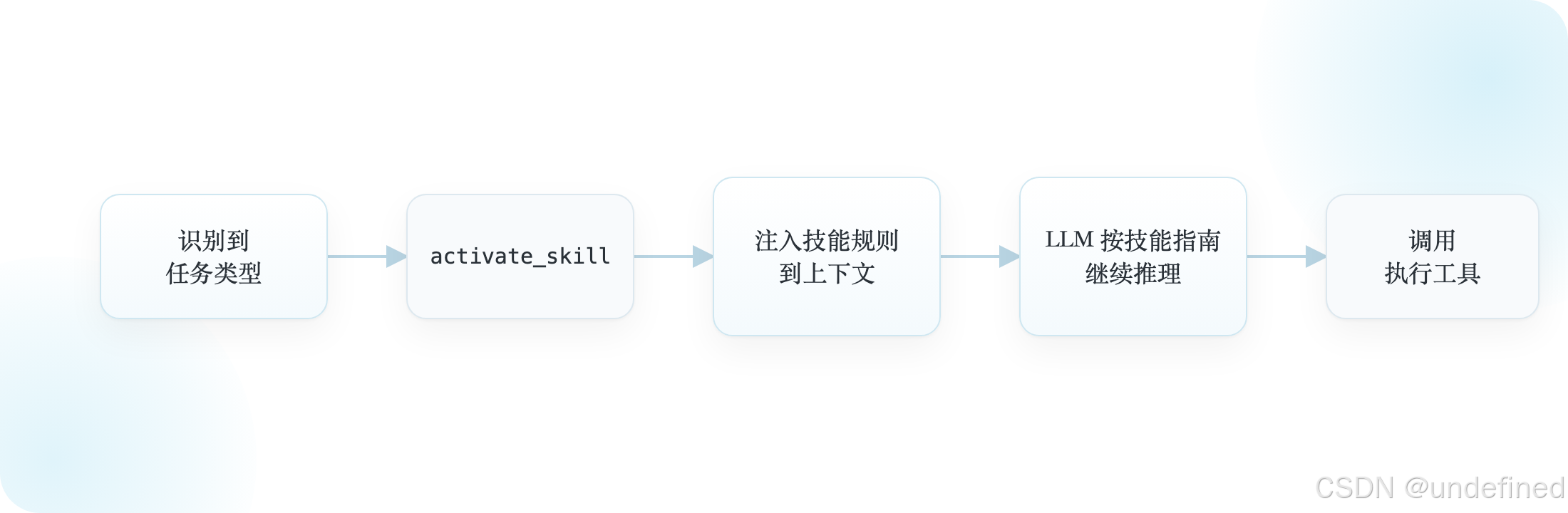
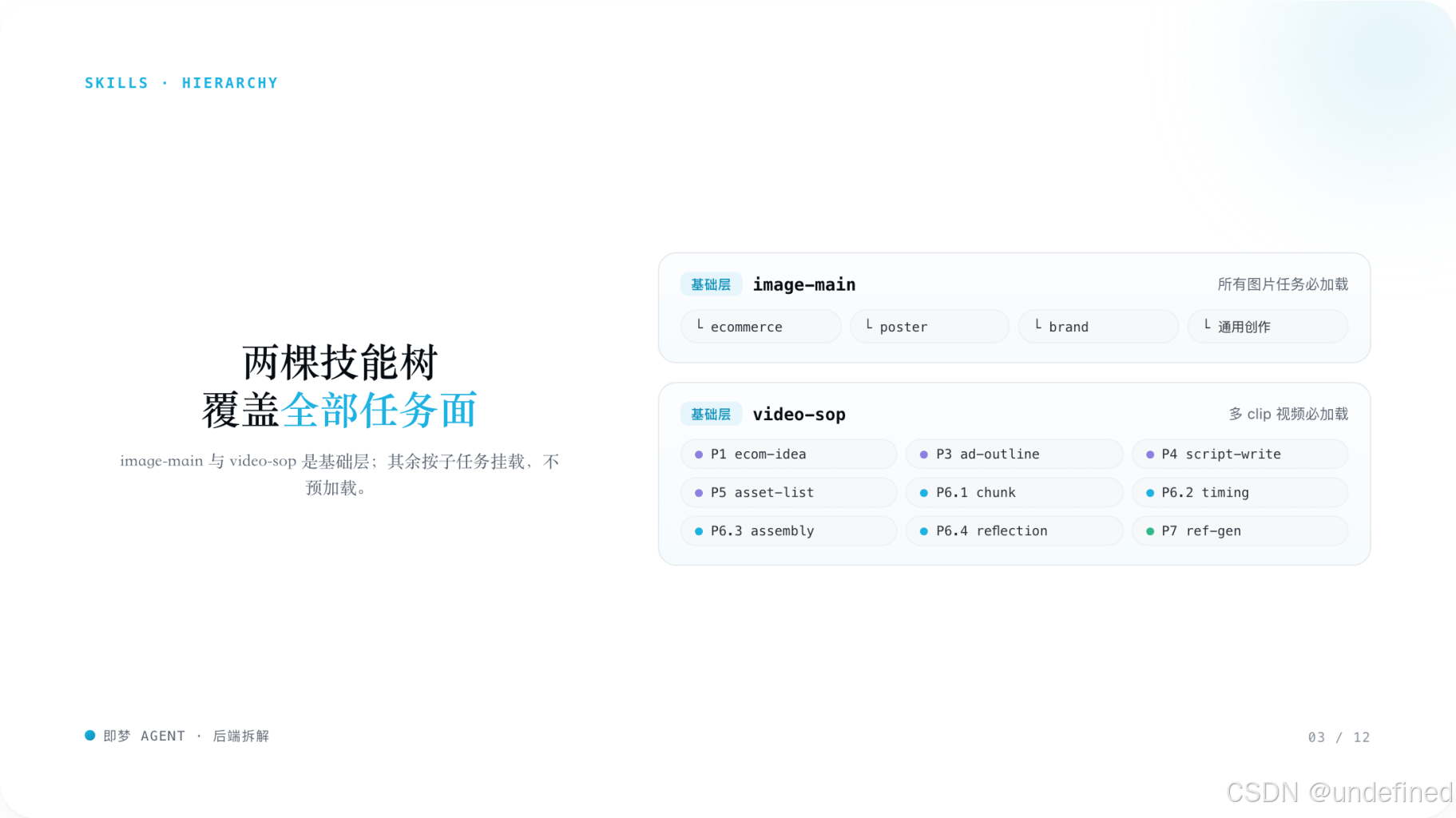
- 技能不是固定写死在全局 prompt 中
- 而是任务到来后 动态注入规则片段
- 可以按需加载,也可以并行加载多个技能
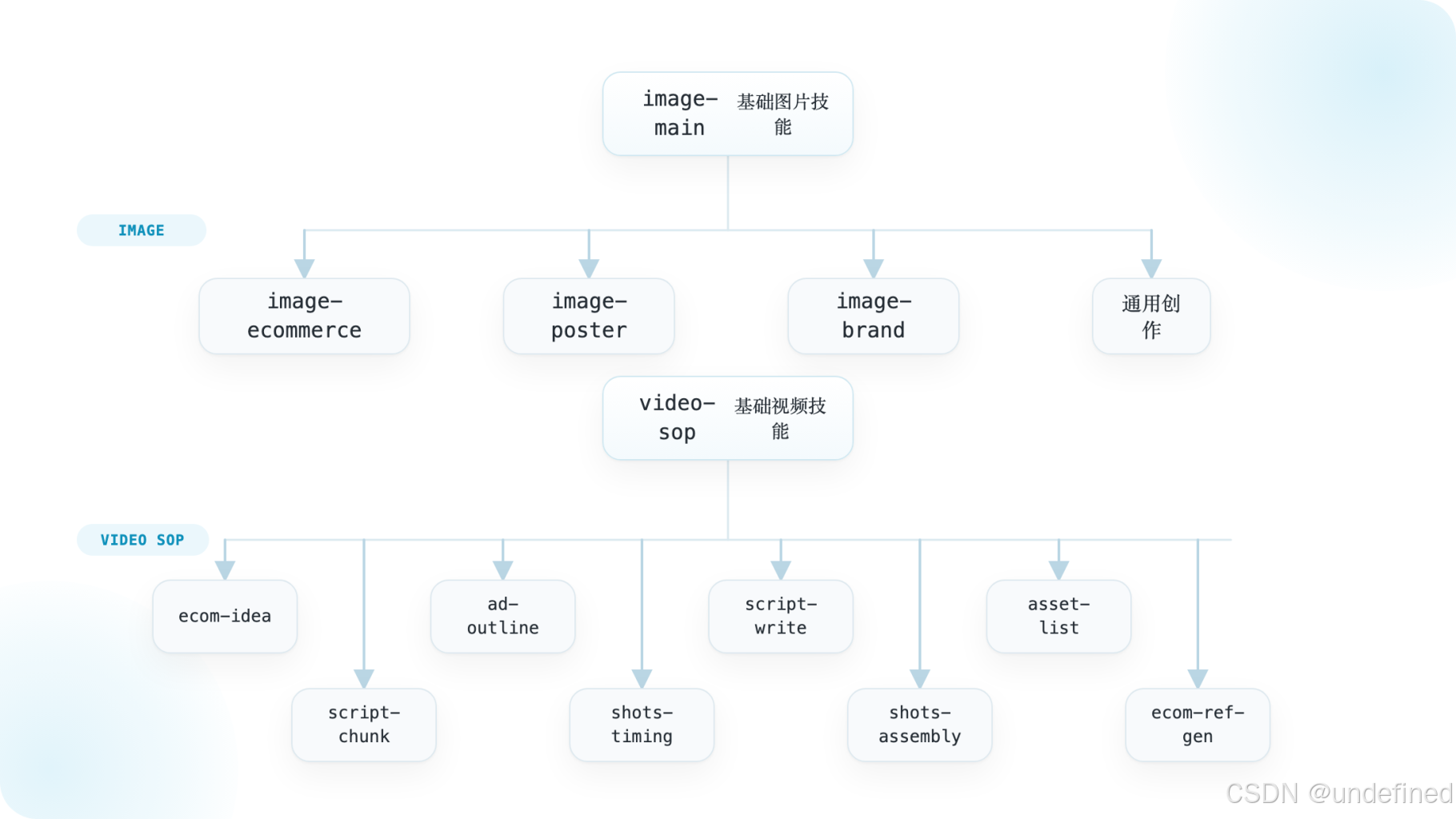
这意味着技能的本质,更像是可热插拔的工作流规则模块。
对 AdsTurbo 来说,这一点非常值得直接借鉴。
4. 状态机:Agent 是如何一步步跑起来的
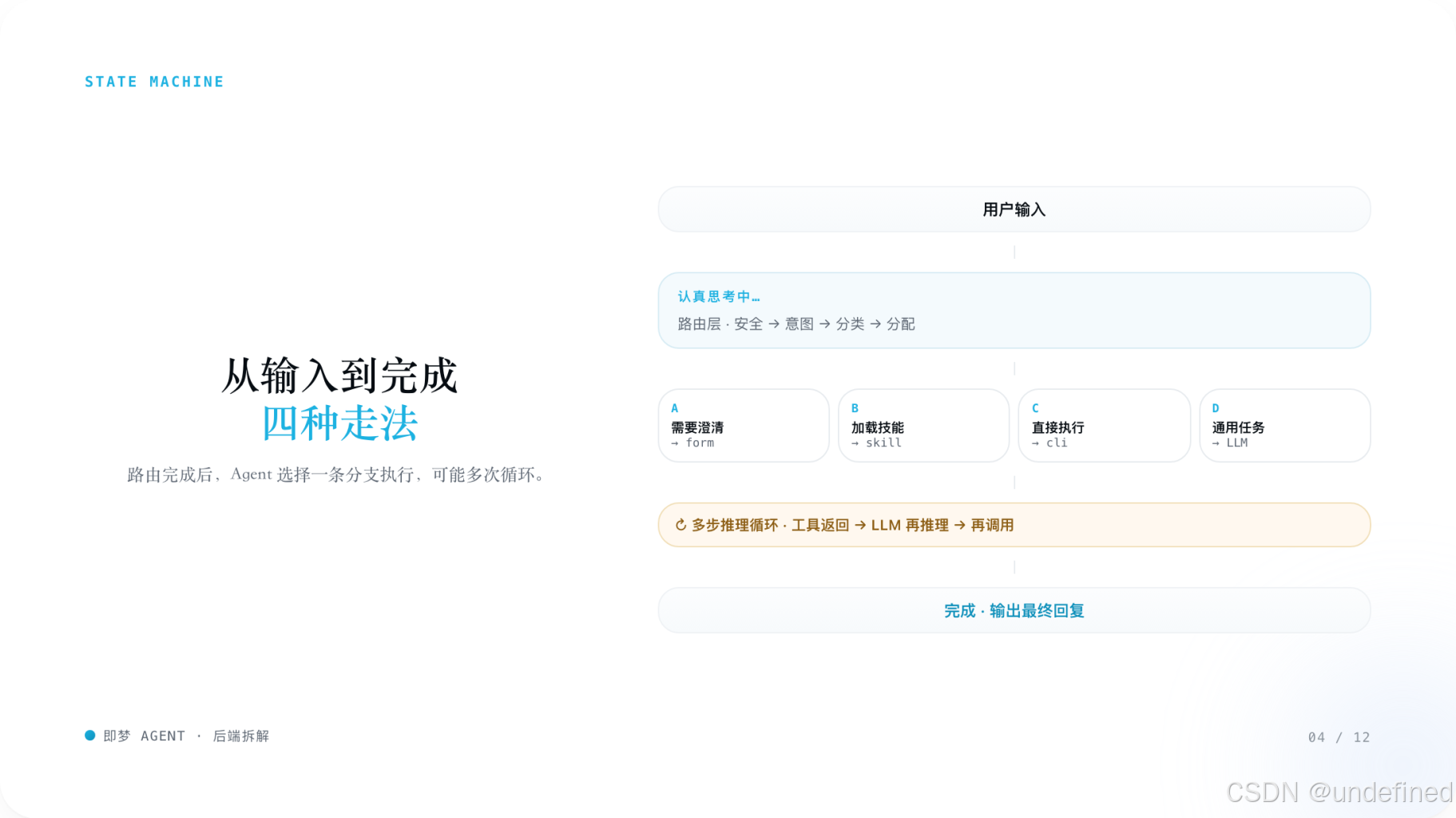
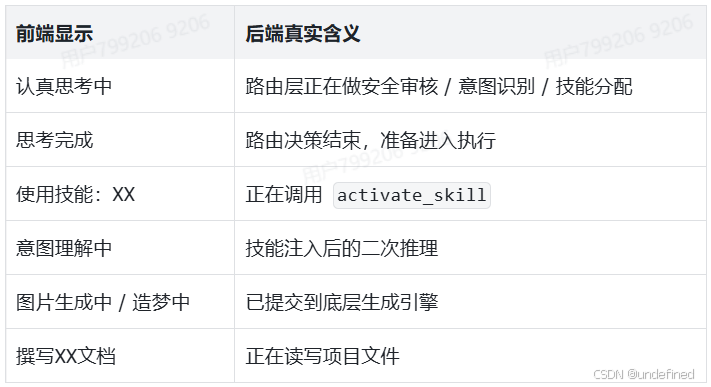
5. 路由决策树
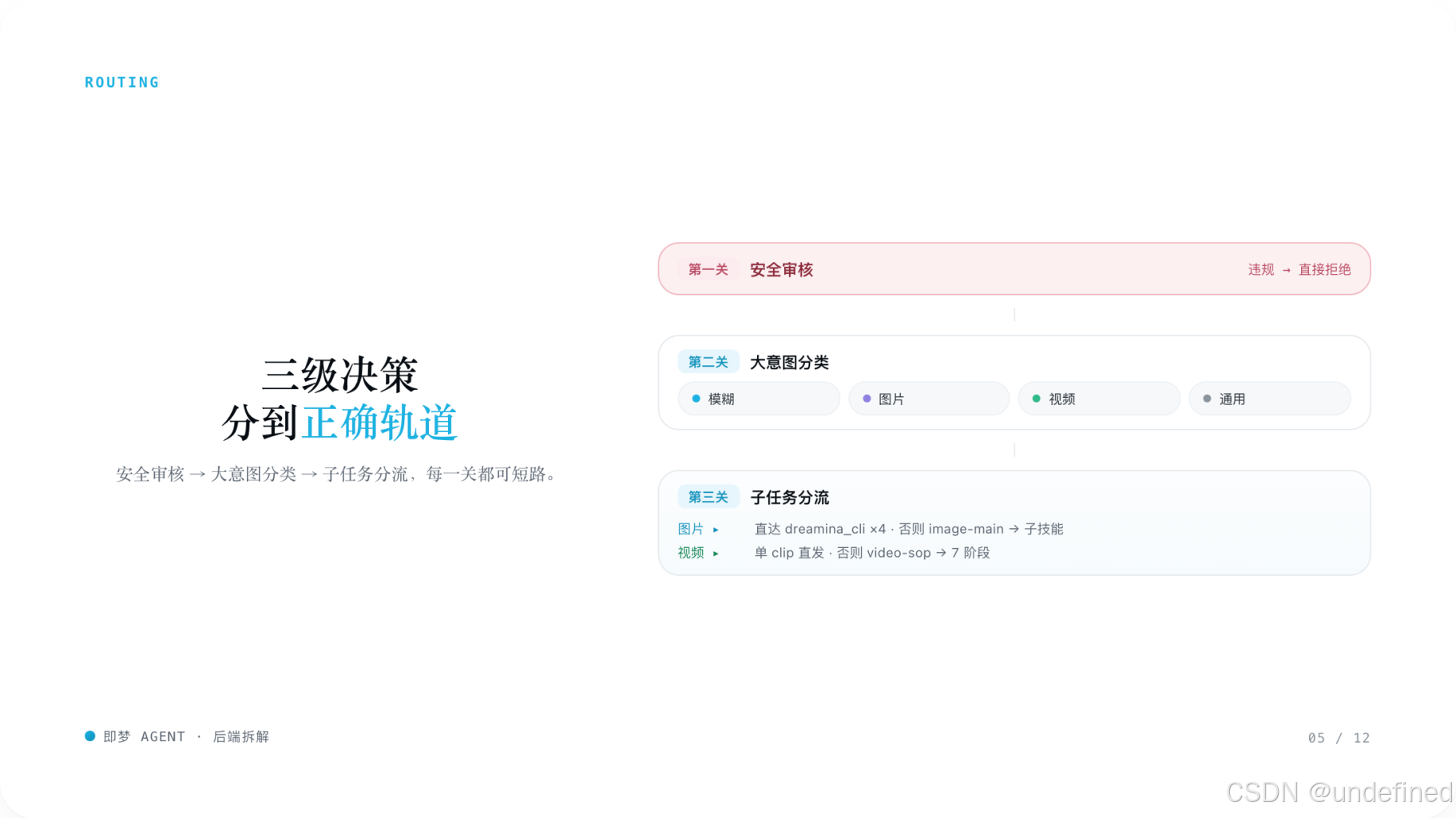
两条最关键分支
- 能直接执行:直接调 text2image
- 常规需求:先加载 image-main
- 再继续分流到电商套图 / 海报 / 品牌 / 通用创作
- 单 Clip、明确、4-15 秒:直接生成
- 成片、多阶段、需求复杂:进入 video-sop
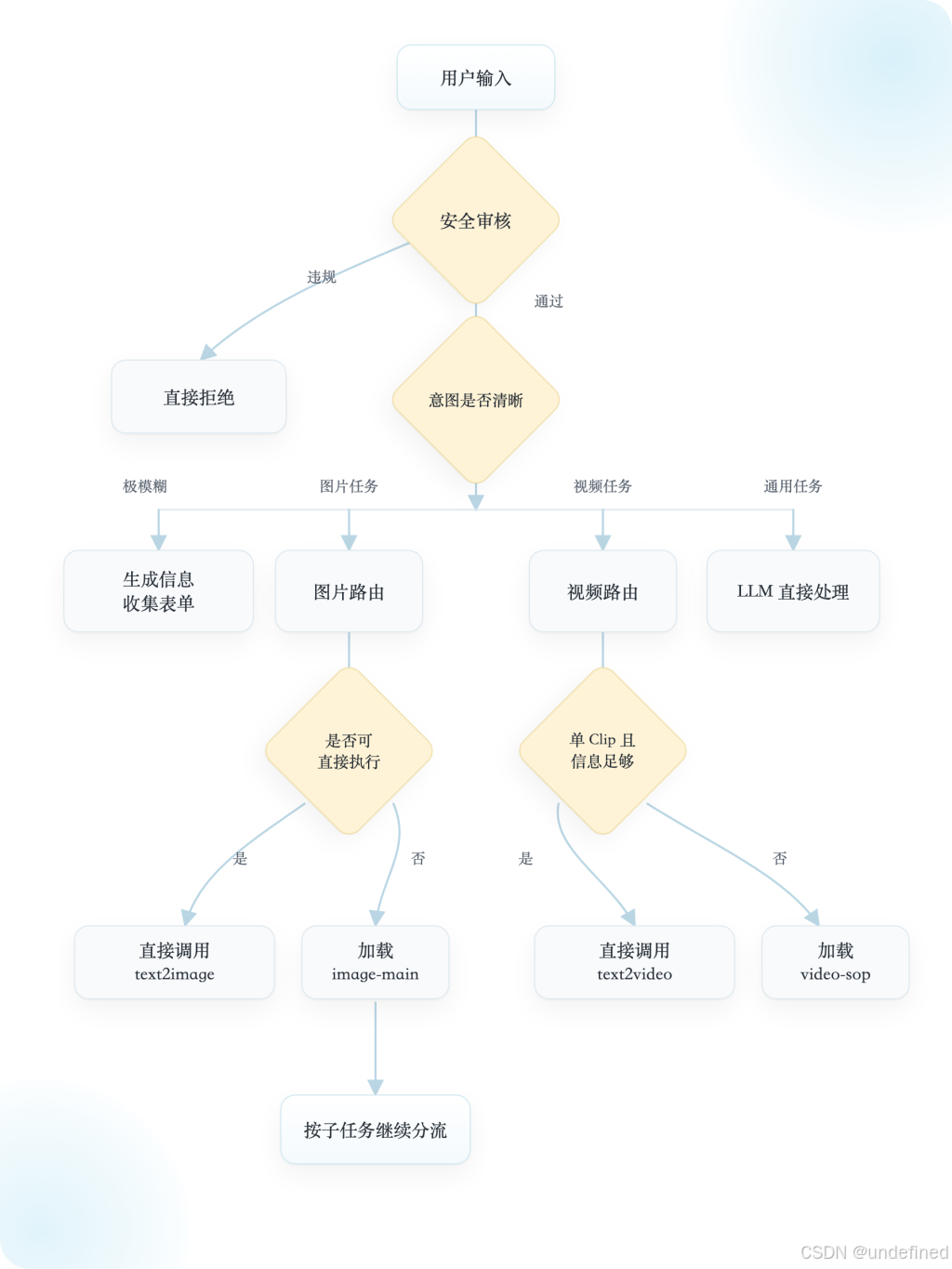
6. Video-SOP:最有价值的编排资产
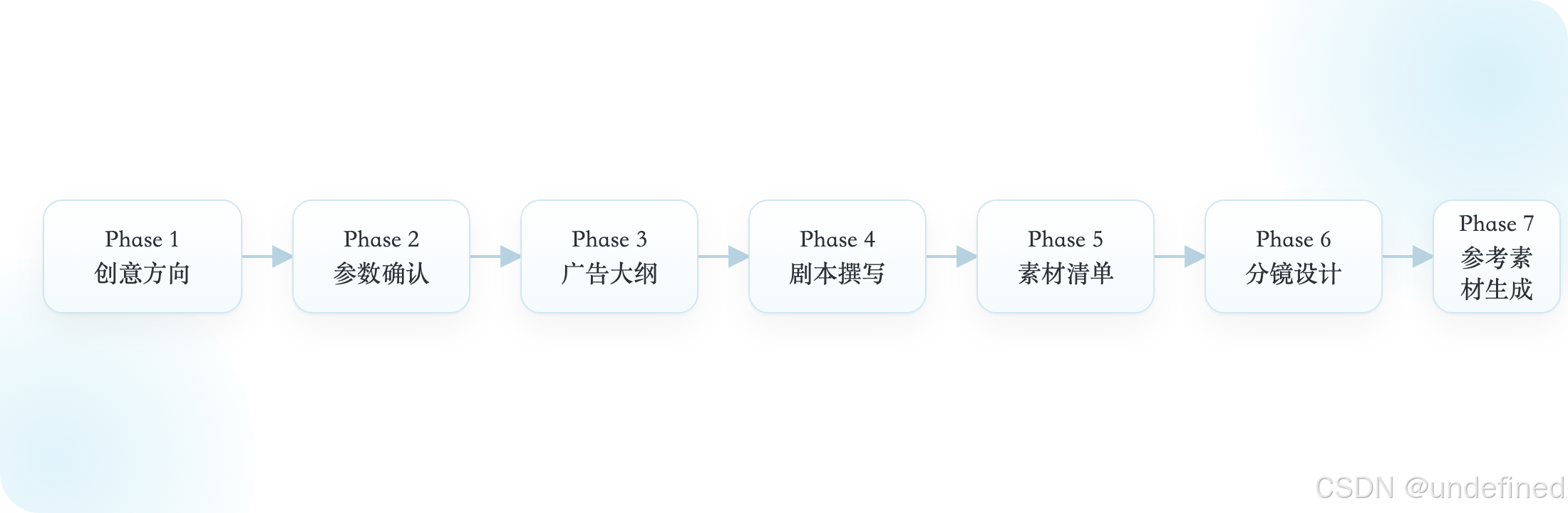

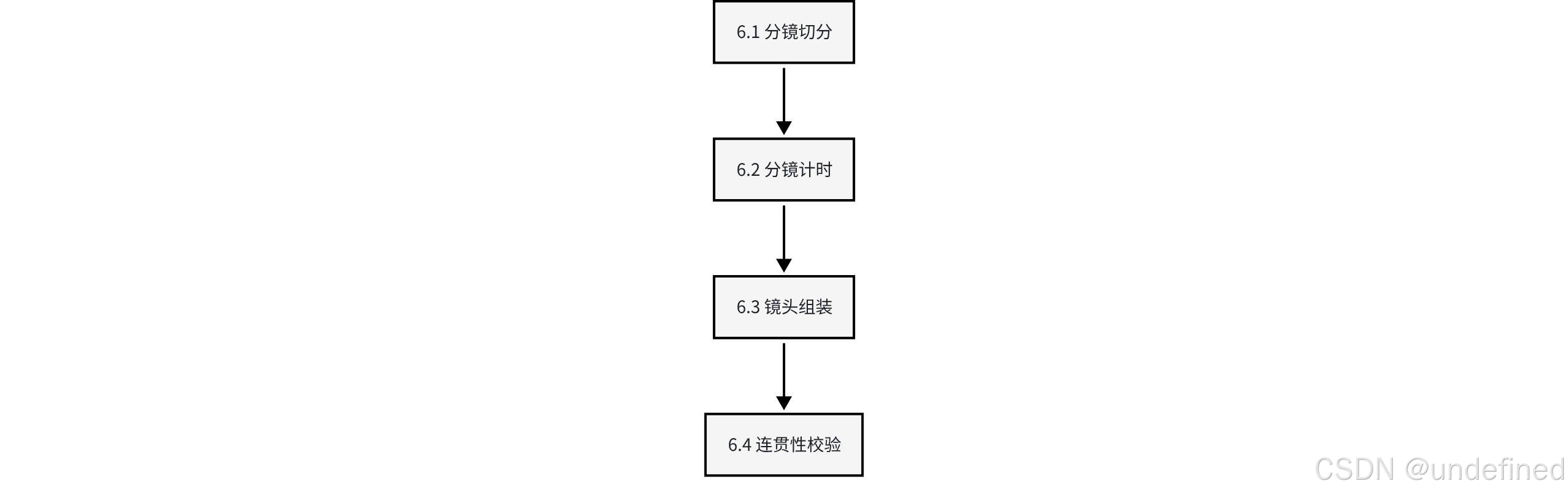
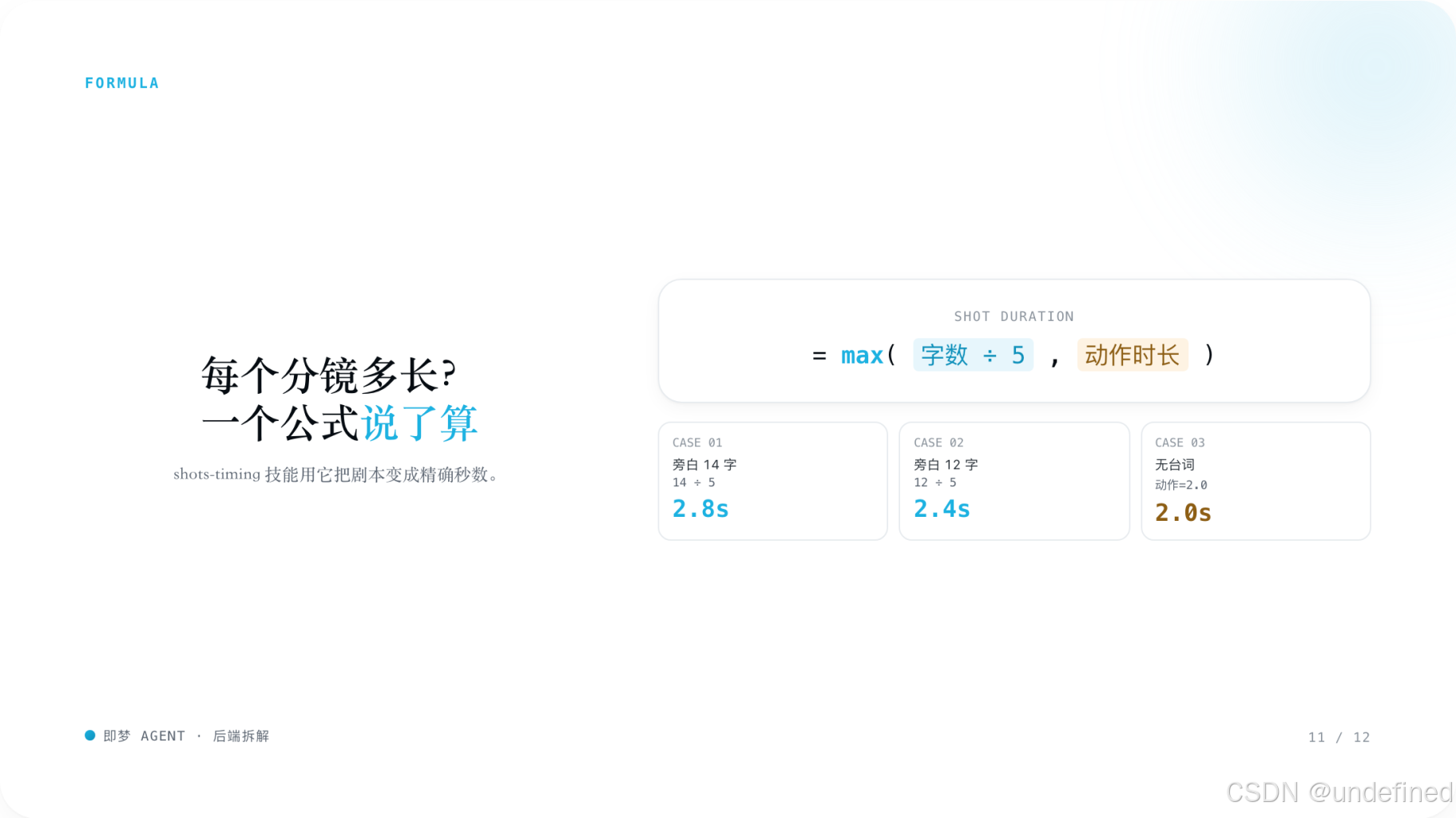
这说明它不是纯感性创作,而是把脚本拆分进一步计算化、规则化、可执行化。
7. Project Memory:跨轮次上下文管理
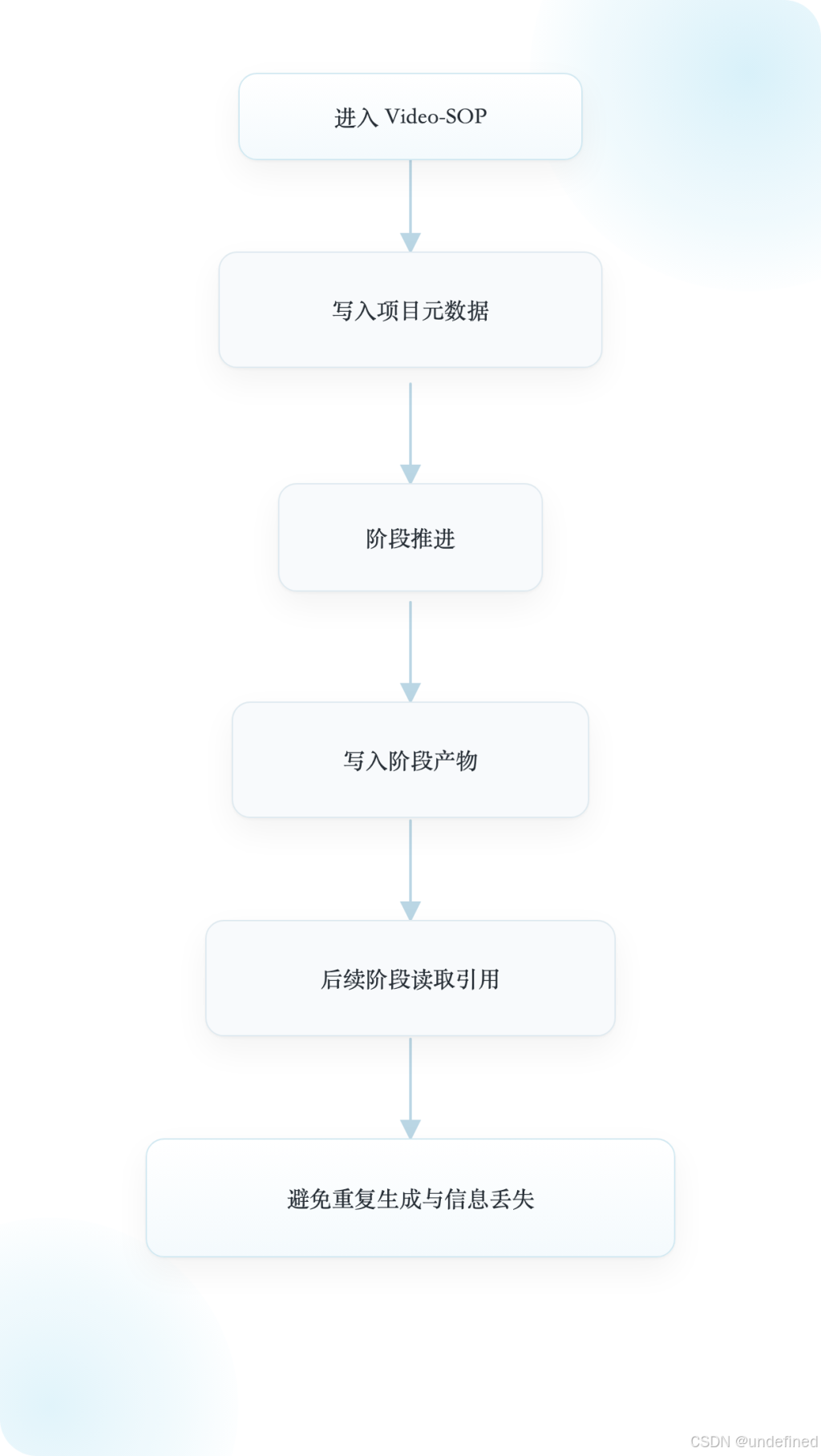
存储产品、目标用户、平台、当前阶段
存储大纲、剧本、故事板等阶段产物
存储已生成资源状态
支撑跨轮次连续对话与工作流推进
|
JSON |

8. 并发与异步:它为什么显得“像个成熟系统”
图片默认 4 张并行生成
多个视频 Clip 可并行生成
跨模态任务也可并行提交
Agent 提交后不阻塞等待
不主动轮询
结果由前端推送刷新
用户感知更流畅

提交成功后,Agent 只负责告知“已提交”,而不是自己卡在等待里。
这件事对 AdsTurbo 非常重要,因为它会直接影响:
对话流畅度
任务并发能力
前后端职责边界
用户对“专业感”的判断
9. 错误处理与安全机制
- 工具格式错了,Agent 会自我修正再重试
- 高级工具失败,会自动降级到基础工具
- 重复请求时,会先检查状态,减少浪费
- 第一层:路由层拦截违规请求
- 第二层:系统规则禁止暴露内部实现
这个双层安全结构说明:即梦并不是把安全压在最终输出上,而是前置到了编排入口。
10. 完整调用时序图
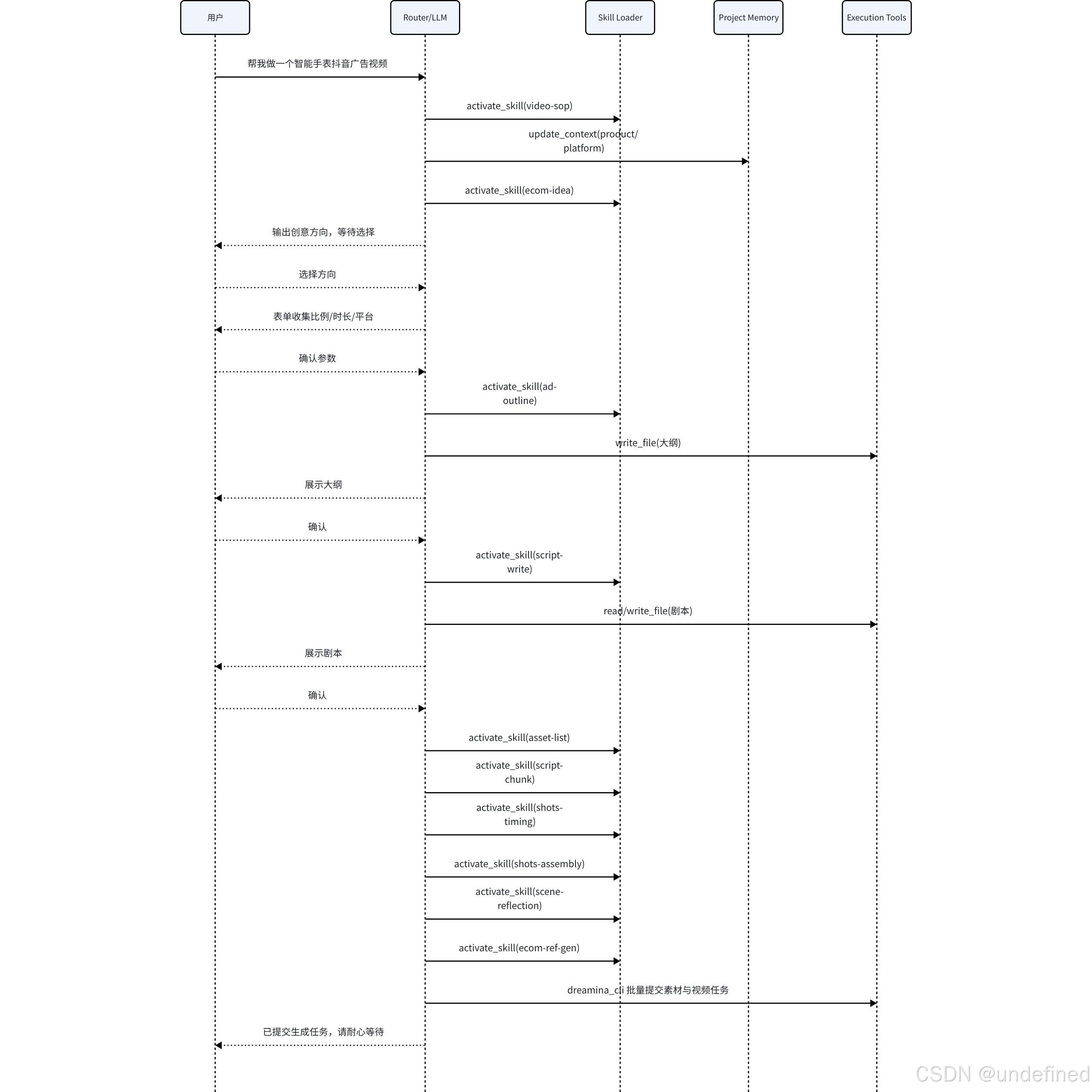
11. 对 Agent 的直接启发

不硬编码在大 system prompt 中
独立维护、独立迭代
可做 A/B 测试
可减少上下文冗余
每一阶段有独立输入输出
关键节点允许用户确认
阶段间依靠 project memory 传递上下文
提交到任务队列
Agent 立即回复“已提交”
前端通过 WebSocket / SSE 推送结果
前端自动刷新展示
12. 最后总结
即梦 Agent 最强的地方,不是单点模型能力,而是它把技能、状态、任务、记忆、异步执行串成了一条完整可控的生产链路。
最直接的结论,那就是:
先做编排,不要先卷生成
先做阶段流,不要先做全自动一步到位
先把技能模块化,再谈规模化扩展

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)