LLM系列之-奖励模型
当我们在做完 SFT 后,我们大概率已经能得到一个还不错的模型。
但我们回想一下 SFT 的整个过程:
我们一直都在告诉模型什么是「好」的数据,却没有给出「不好」的数据。
我们更倾向于 SFT 的目的只是将 Pretrained Model 中的知识给引导出来的一种手段,
而在SFT 数据有限的情况下,我们对模型的「引导能力」就是有限的。
这将导致预训练模型中原先「错误」或「有害」的知识没能在 SFT 数据中被纠正,
从而出现「有害性」或「幻觉」的问题。
为此,一些让模型脱离昂贵标注数据,自我进行迭代的方法被提出,比如:[RLHF],[DPO],
但无论是 RL 还是 DPO,我们都需要让告知模型什么是「好的数据」,什么是「不好的数据」。
RL 是直接告诉模型当前样本的(好坏)得分,DPO 是同时给模型一条好的样本和一条坏的样本。
而判断样本数据的「好坏」除了昂贵的人工标注之外,
那就是 Reward Model 大显身手的时候了。
3.1 利用偏序对训练奖励模型
在 OpenAI 的 [Summarization] 和 [InstructGPT] 的论文中,都使用了「偏序对」来训练模型。
偏序对是指:不直接为每一个样本直接打分,而是标注这些样本的好坏顺序。
直接打分:A句子(5分),B句子(3分)
偏序对标注:A > B
模型通过尝试最大化「好句子得分和坏句子得分之间的分差」,从而学会自动给每一个句子判分。
为什么要使用偏序对而不是直接打分可以看上面给出的文章链接。
我们可以来做一个简单实验,我们构造一批如下数据:
{
"prompt": "下面是一条正面的评论:",
"selected": "屯了一大堆,今年过年的话蛮富足的!到货很快的!",
"rejected": "对商品谈不上满意,但是你们店的信誉极度不满意,买了件衣服取消了订单,要求退款,结果退款过程进行一半就不进行了,真是因小失大啊"
}其中,prompt 是要求模型续写一条好评,selected 是一条好的回答(A),rejected 是一条不好的回答(B)。
我们使用 [llama-2-7b] 作为基座模型训练,期望模型对于 A 回答能够给尽可能高的分,B 回答则尽可能低。

RM Loss Function
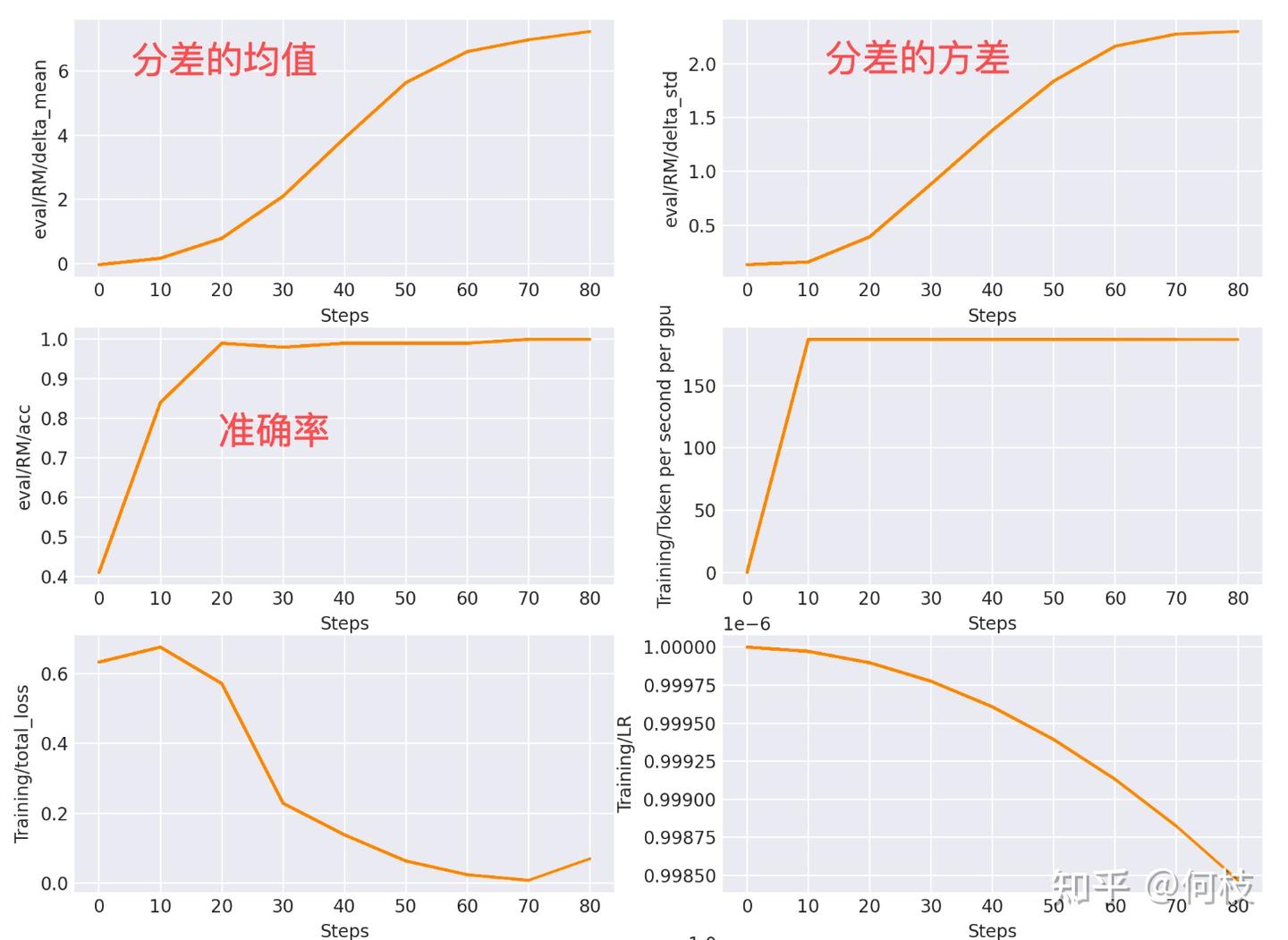
我们将训练过程中的「分差变化」绘制出来,
伴随着 loss 的降低,我们发现分差的均值和方差都呈上升的趋势:
Note:这里的分差是指 r(好答案) - r(坏答案) 的分差。
Reward Model 训练日志
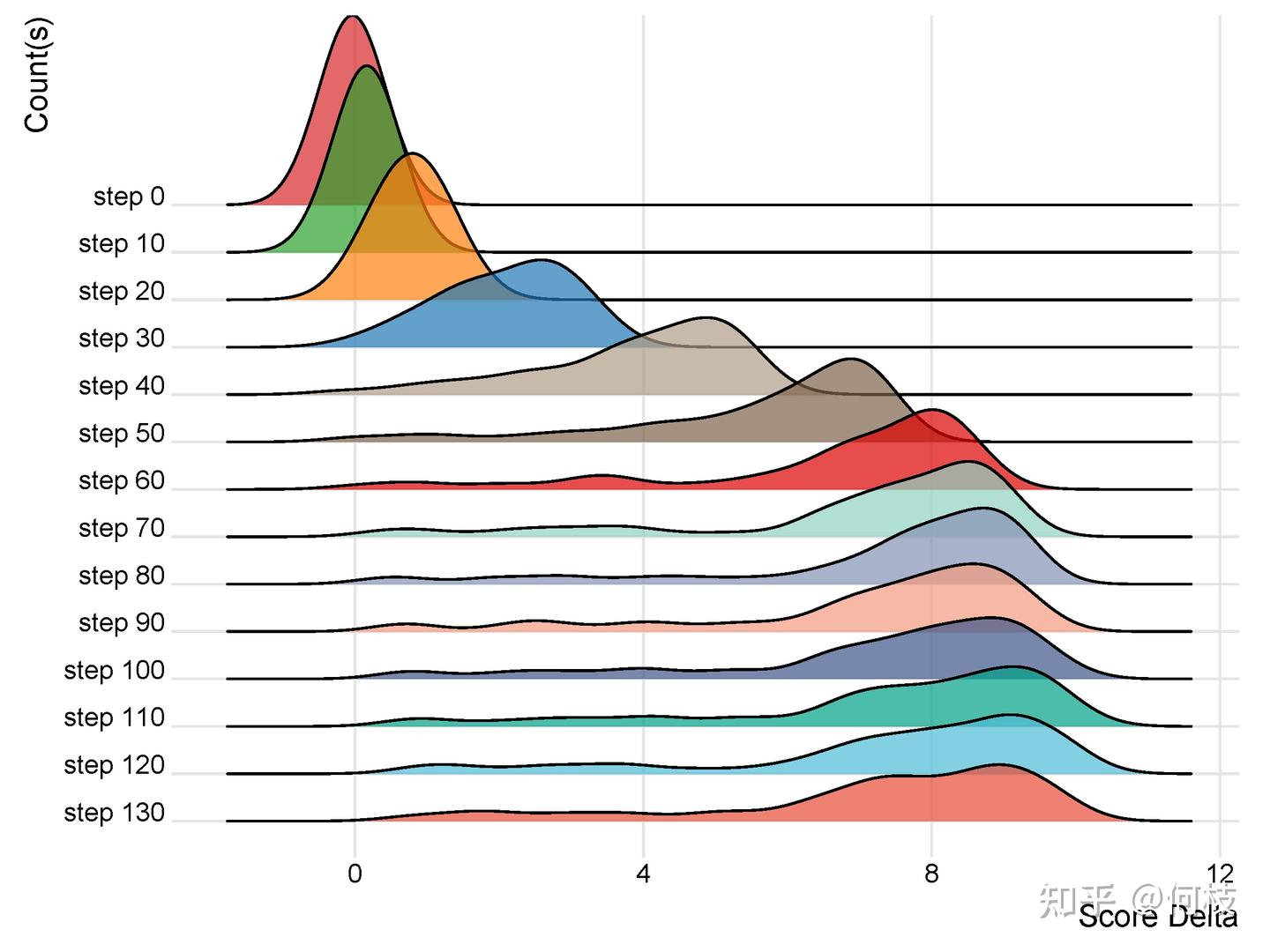
我们进一步的绘制出在 100 个评测样本的分差分布:
在 step 0(未训练)时,模型打出来的分差是一个近似均值为 0,方差为 0.1 的正态分布,
这说明初始模型无法区分数据的好坏(好数据 - 坏数据的得分有正有负)。
随着模型训练,分布均值从 0 开始逐渐增长,这证明模型开始逐渐让「好数据」 - 「坏数据」的分差越来越大。
到第 60 个 step 之后,分布的均值和方差开始趋于稳定。
分差进化图
至此,我们已经让 RM 学会了给「正向评论」打分更高,给「负向评论」打分更低。
但是由于偏序对本身「过于粗糙」,会导致 RM 的打分并不足够精准,
后续一些工作在标注偏序的时候不仅标注了 A 好于 B,还同时标注了 A 比 B 好多少。
还有一些工作会在 Reward Gap Loss 上添加 Prefered Samples 的 LM Loss:
编辑何枝:【RLHF】怎样让 PPO 训练更稳定?早期人类征服 RLHF 的驯化经验374 赞同 · 25 评论 文章
3.2 使用多少数据能够训练好一个RM?
在 OpenAI Summarize 的任务中,使用了 [6.4w 条] 偏序对进行训练。
在 InstructGPT 任务中,使用了 3.2w 条 [4~9] 偏序对进行训练。
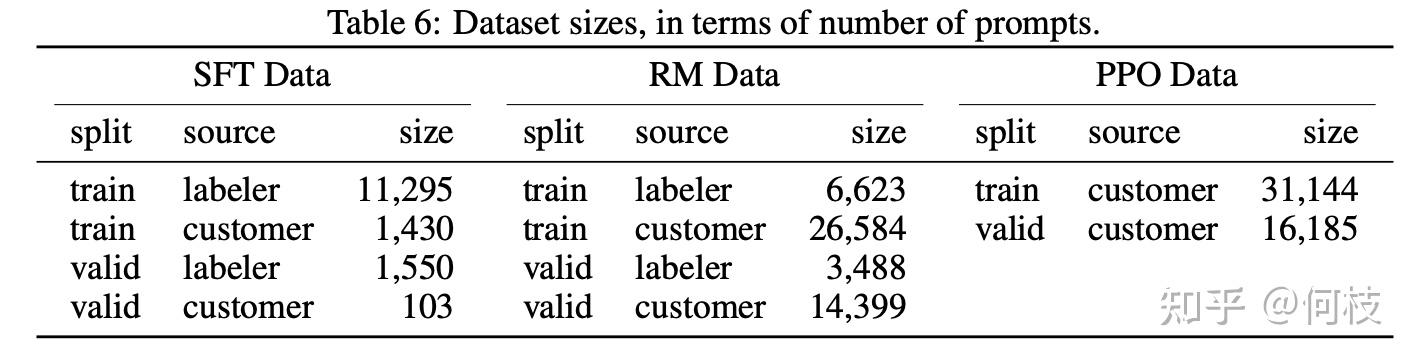
InstructGPT page 33
在 [StackLlama] 任务中,使用了 10w 条 [Stack Exchange] 偏序对进行训练。
从上述工作中,我们仍无法总结出一个稳定模型需要的最小量级,这取决于具体任务。
但至少看起来,5w 以上的偏序对可能是一个相对保险的量级。
关于 Reward Model 的 Scaling Law 讨论可以看看 OpenAI 的论文:
编辑何枝:RLHF 训练中,如何挑选最好的 checkpoint?88 赞同 · 0 评论 文章
3.3 RM 模型的大小限制?
Reward Model 的作用本质是给生成模型的生成内容进行打分,所以 Reward Model 只要能理解生成内容即可。
关于 RM 的规模选择上,目前没有一个明确的限制:
Summarize 使用了 6B 的 RM,6B 的 LM。
InstructGPT 使用了 6B 的 RM,175B 的 LM。
DeepMind 使用了 70B 的 RM,70B LM。
不过,一种直觉的理解是:判分任务要比生成认为简单一些,因此可以用稍小一点的模型来作为 RM。
体验大模型:
# 通过claude code方式,使用deepseek-v4-flash来体验
# 通过https://teniuapi.online,的令牌管理,新建自己的TENIU API Key
# 替换`TENIUAPI_API_KEY` 为您新建的 TENIU API Key
{
"env": {
"ANTHROPIC_BASE_URL": "https://teniuapi.online",
"ANTHROPIC_AUTH_TOKEN": "TENIUAPI_API_KEY",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_MODEL": "deepseek-v4-flash",
"ANTHROPIC_SMALL_FAST_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "deepseek-v4-flash",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-v4-flash"
}
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)