数据结构队列和栈
栈是什么呢?
栈就好比一个弹夹,只能先进但是要后出
进入的·头叫做栈顶,弹夹的底座钢铁非常坚硬叫做栈的底;只有栈顶是可以动的,出入数据都要靠顶;只能在栈顶做两件事:
入栈(压栈):push 往栈顶放数据
出栈(弹栈):pop 从栈顶拿走数据v
不能随机访问元素,只能从栈顶按照顺序拿出;
···栈顶 ↓
3
2
1
栈底
···入栈后4在最顶层
4
3
2
1
···想要拿出那么粗来的第一个还是4
3
2
1
现在来看栈的几个基本代码实现原理
首先栈指向的位置可以是当前元素,也可以是下一位
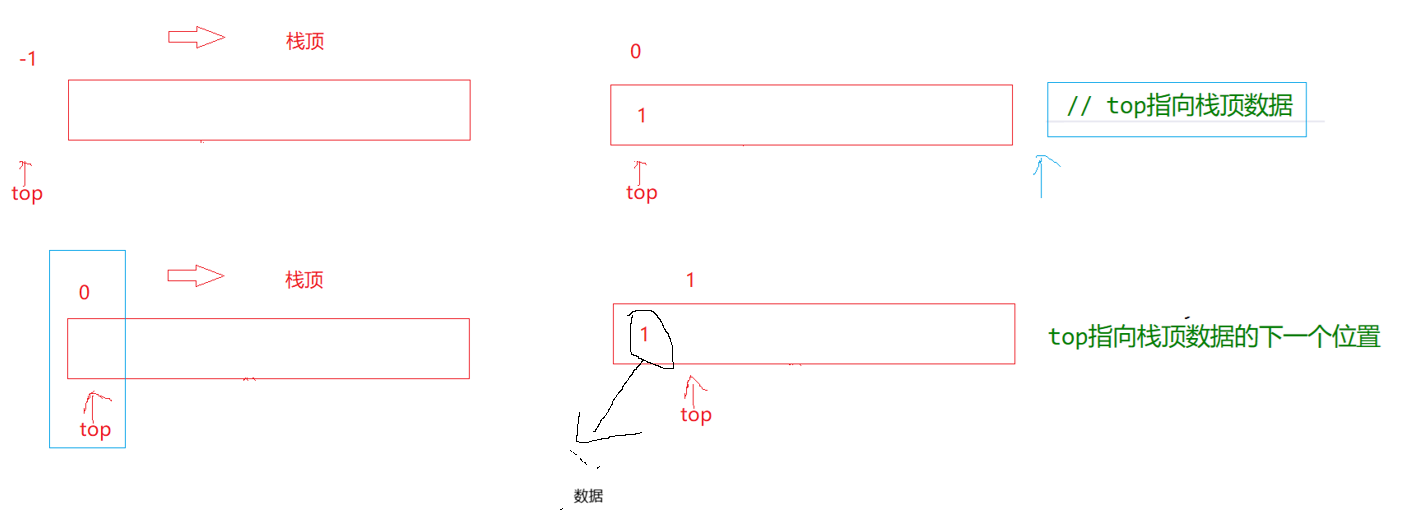
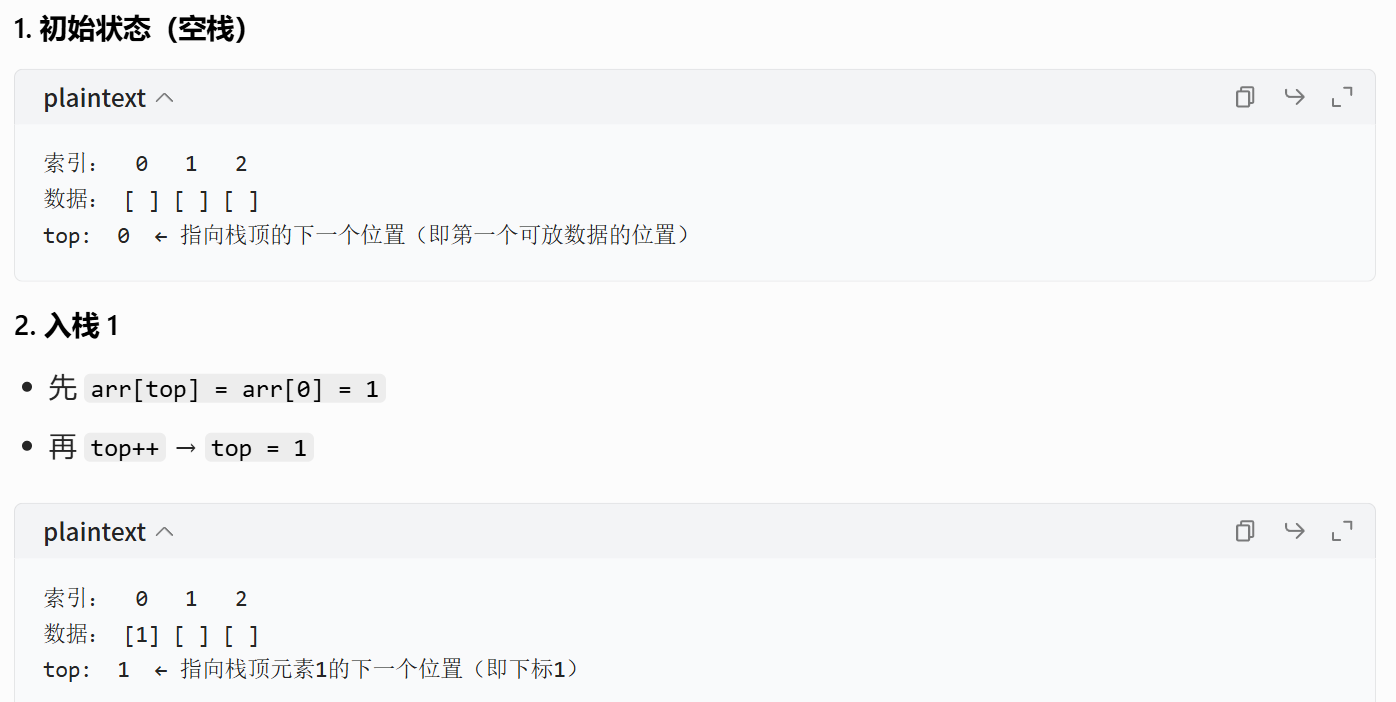
上方案初始化状态(空栈)
top = -1(数组下标从 0 开始,-1表示没有元素)- 空栈条件:
top == -1 -
操作 逻辑步骤 示例 入栈(push) 1. top++(先移动指针)2.arr[top] = value(再存数据)top=-1→ 入 1 →top=0,arr[0]=1出栈(pop) 1. value = arr[top](先取数据)2.top--(再移动指针)top=0→ 出 1 →top=-1栈顶元素 直接访问 arr[top]top=0→ 栈顶是arr[0]
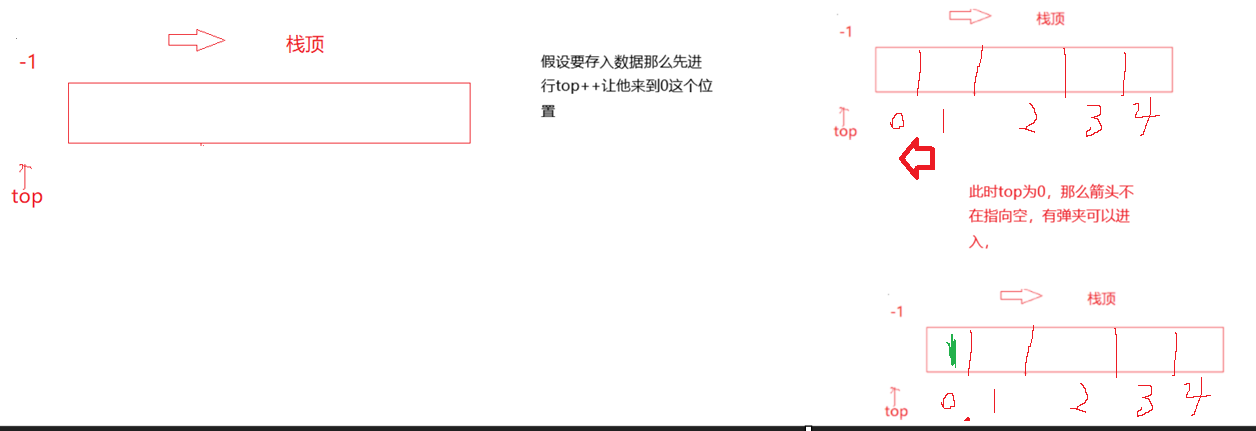
方式 B:top 指向栈顶元素的下一个位置
初始化状态(空栈)
top = 0(指向下标 0 的位置,还没存数据)- 空栈条件:
top == 0
| 操作 | 逻辑步骤 | 示例 |
|---|---|---|
| 入栈(push) | 1. arr[top] = value(先存数据)2. top++(再移动指针) |
top=0 → 入 1 → arr[0]=1,top=1 |
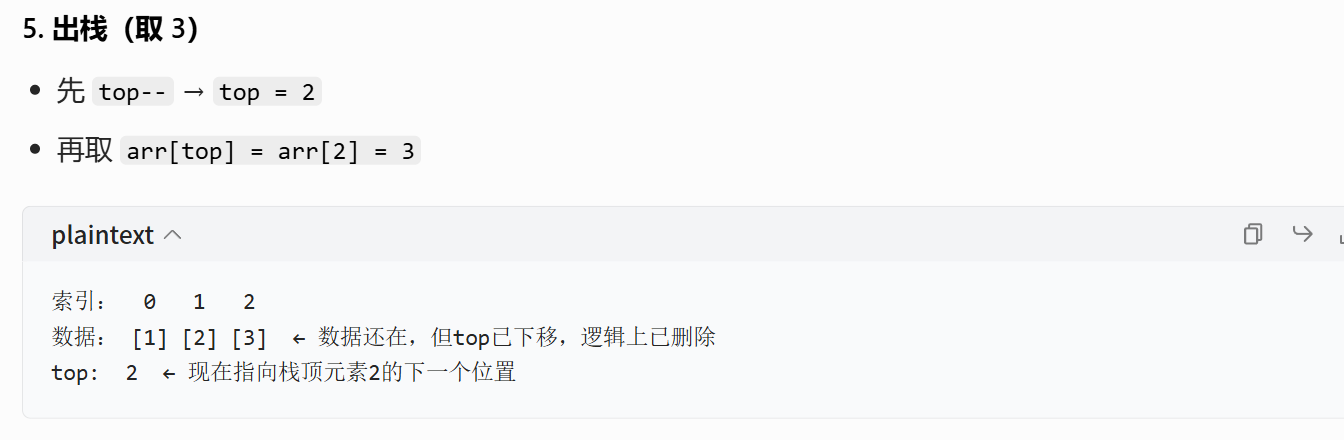
| 出栈(pop) | 1. top--(先移动指针)2. value = arr[top](再取数据) |
top=1 → 出 1 → top=0,取 arr[0] |
| 栈顶元素 | 访问 arr[top - 1] |
top=1 → 栈顶是 arr[0] |
| 阶段 | 方式 A(指向栈顶元素) | 方式 B(指向下一个位置) |
|---|---|---|
| 空栈 | top = -1 |
top = 0 |
| 入栈 | 先移动top,再放数据 |
先放数据,再移动top |
| 出栈 | 先取数据,再移动top |
先移动top,再取数据 |
| 栈顶元素 | arr[top] |
arr[top - 1] |
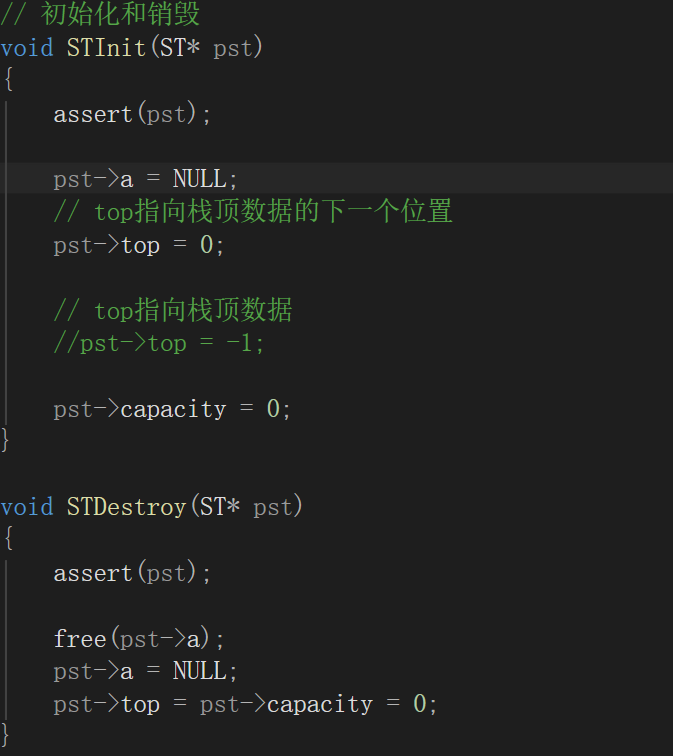
首先创建栈的时候是让初始化位置指向一开始的下一个
所以销毁时候先帮数据进行释放然后再置空
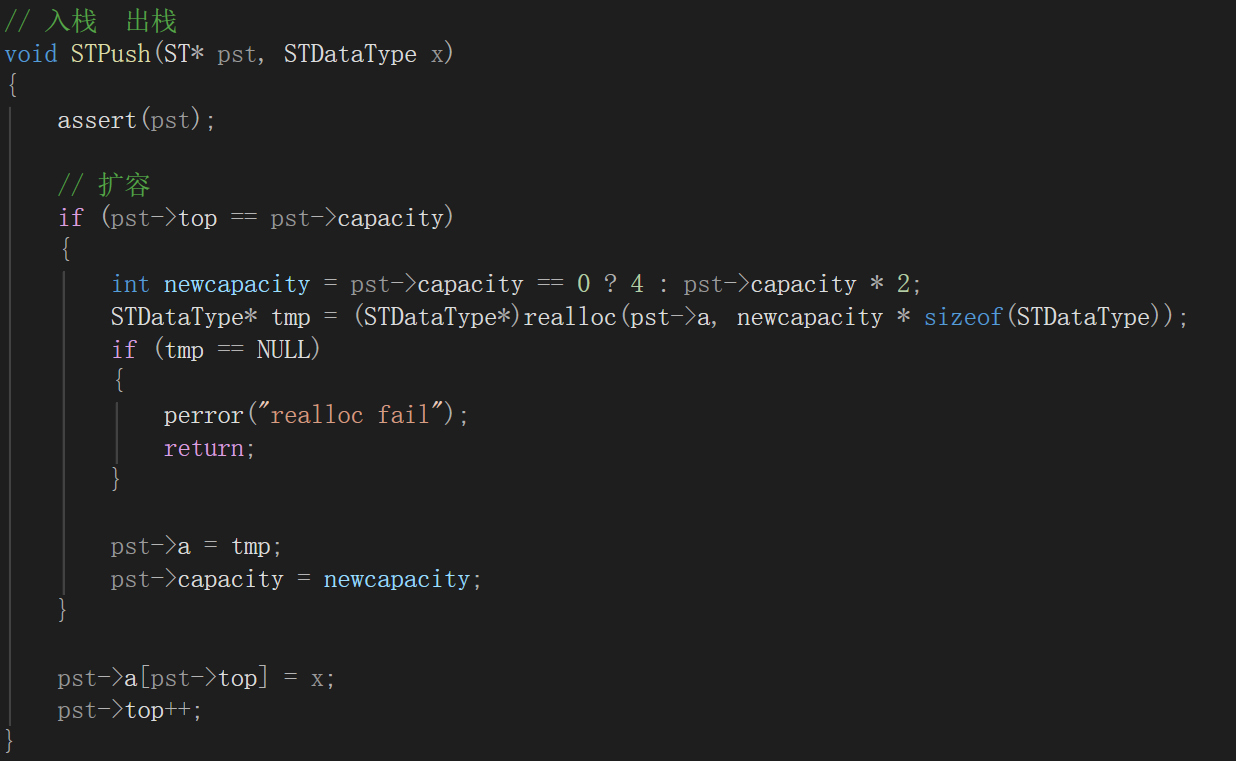
首先先进行第一个if语句进行判断是否满
如果满了那么创建新的一个变量,判断原来的容量是否为0,如果为0那么先变为4,不然就变成原来的两倍;开辟一个新的空间tmp,然后将新的空间赋给原来的栈。
入栈的原理很简单就是都找到顶部,插入,然后top++让他向后走就行。
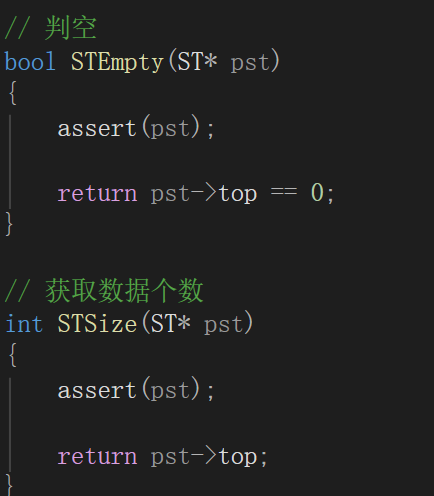
1. 两个 assert 的作用
assert(pst):防止传入空指针,比如STPop(NULL)这种非法调用,在 Debug 模式会直接报错,方便定位问题。assert(pst->top > 0):防止 “空栈出栈”(栈下溢)。- 因为你的
top是「栈顶元素的下一个位置」,所以top == 0代表栈里没有任何元素,此时出栈是非法操作。
- 因为你的
2. pst->top-- 为什么能实现出栈?
结合你之前的 STPush 逻辑来看:
- 入栈时:
pst->a[pst->top] = x; pst->top++;数据先存到top指向的位置,再让top往后走一步。 - 出栈时:直接
pst->top--;让top往回退一步,指向原来的栈顶元素,逻辑上这个元素就被 “删除” 了。
注意:这里并没有真的修改数组里的值,只是通过移动
top指针,让这个位置的数据变成 “无效数据”,后续入栈时会直接覆盖它。
三、和 STPush 的配套逻辑
表格
| 操作 | 步骤 | top 变化 |
|---|---|---|
| 空栈 | 初始状态 | top = 0 |
| 入栈 1 | a[0]=1; top++ |
top = 1 |
| 入栈 2 | a[1]=2; top++ |
top = 2 |
| 出栈 | top-- |
top = 1 |
| 再出栈 | top-- |
top = 0(回到空栈) |

为什么要 pst->top - 1?
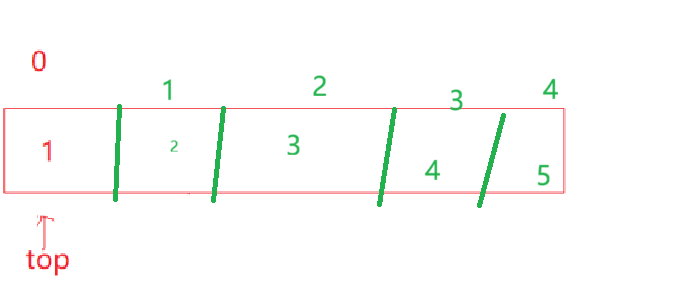
结合你这套栈的设计:top 指向「栈顶元素的下一个位置」
- 入栈时:数据存在
pst->a[pst->top],然后top++ - 所以栈顶元素的实际下标是
top - 1
举个例子:
- 栈里有
[1, 2, 3],此时top = 3 - 栈顶元素
3存在下标2,也就是top - 1的位置 - 直接返回
pst->a[top-1]就能拿到栈顶元素
队列详解
队列是什么?如果说栈是先进后出的弹夹,那么队列就是先进先出的厕所。
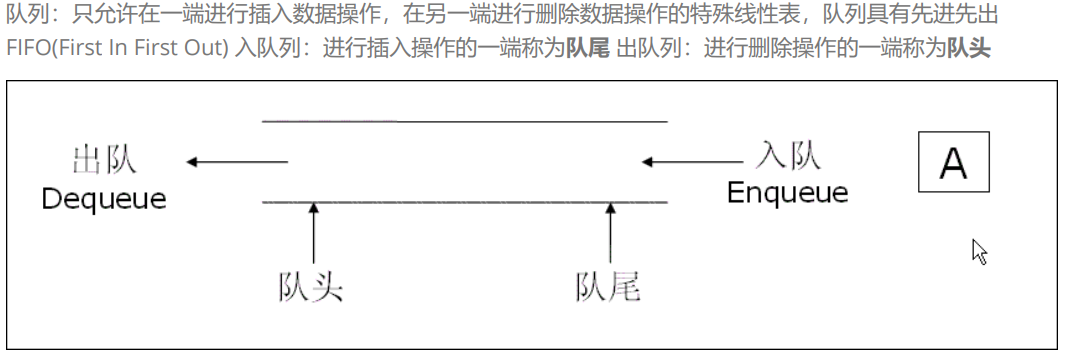
- 队尾 (rear):只能入队(添加元素)
- 队头 (front):只能出队(删除元素)口诀:先进先出,先来先走
- 队头front 队尾rear ↓ ↓ [ 1 ] [ 2 ] [ 3 ] [ 4 ] 出队从左边走 入队从右边加
// 链表节点
typedef int QDataType;
typedef struct QNode
{
QDataType val;
struct QNode* next;
}QNode;
// 队列管理结构
typedef struct Queue
{
QNode* phead; // 队头指针
QNode* ptail; // 队尾指针
int size; // 节点个数
}Queue;队列的初始化部分
void QueueInit(Queue* pq)
{
assert(pq); // 确保pq不为空
pq->phead = NULL; // 队头为空
pq->ptail = NULL; // 队尾为空
pq->size = 0; // 元素个数为0
}先将队列改为空队列
- 没有节点 → 头尾都为空
- 没有元素 → size=0
-
void QueueDestroy(Queue* pq) { assert(pq); QNode* cur = pq->phead; // 从队头开始遍历 while (cur) // 只要不为空就一直删 { QNode* next = cur->next; // 先保存下一个节点 free(cur); // 释放当前节点 cur = next; // 走到下一个 } pq->phead = pq->ptail = NULL; pq->size = 0; }作用:释放整个队列所有节点,防止内存泄漏。步骤:
- 从队头开始遍历
- 每次先保存下一个节点,再释放当前
- 最后把队列置空
-
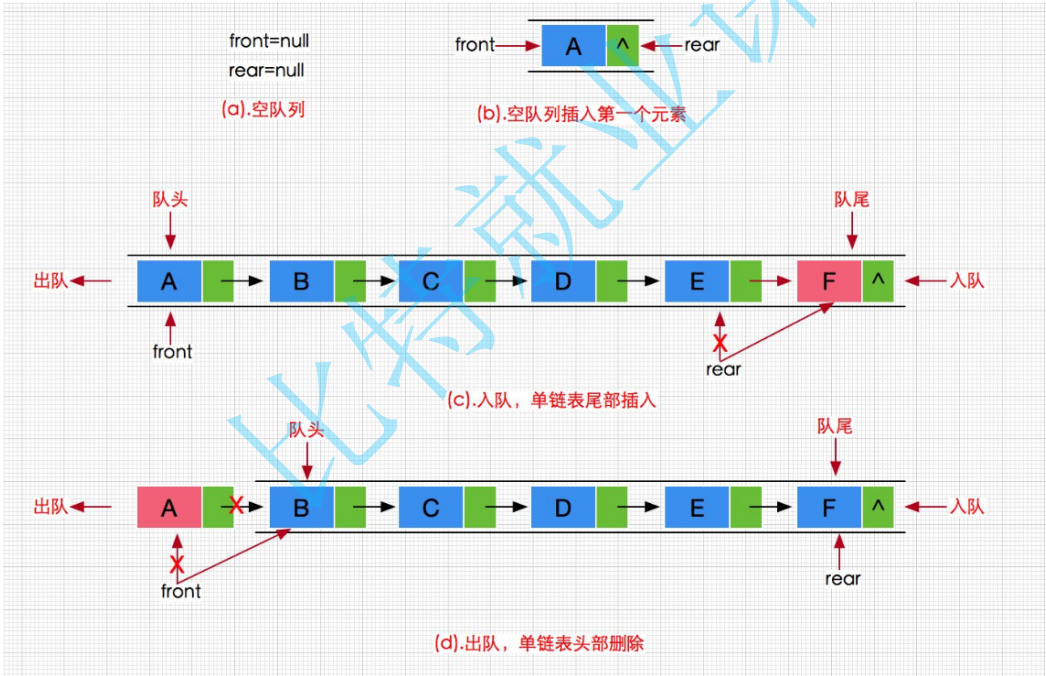
void QueuePush(Queue* pq, QDataType x) { assert(pq); // 1. 创建新节点 QNode* newnode = (QNode*)malloc(sizeof(QNode)); if (newnode == NULL) { perror("malloc fail"); return; } newnode->next = NULL; newnode->val = x; // 2. 分情况插入 if (pq->ptail == NULL) // 空队列 { pq->phead = pq->ptail = newnode; } else // 非空队列 { pq->ptail->next = newnode; pq->ptail = newnode; } pq->size++; }队尾插入的核心是创建一个新的节点,我们用画图来理解
-
pq 指向队列整体 [phead:NULL] [ptail:NULL] [size:0]
-
newnode → [ val:1 | next:NULL ]
假设原来队列为空
判断:if (pq->ptail == NULL)执行:
运行
pq->phead = pq->ptail = newnode;
赋值后内存图:
plaintext
phead
↓
[1|NULL]
↑
ptail
[phead:地址1] [ptail:地址1] [size:0]
关键点空队列第一次插:队头、队尾 都指向这唯一一个新节点。
然后 pq->size++,size 变成 1。
情况二:队列已有节点,再插第二个元素
现在队列已有 1,现在再 Push(2)
- 先新建节点:
plaintext
newnode → [2|NULL]
- 此时
pq->ptail不为空,走 else
c
运行
pq->ptail->next = newnode;
pq->ptail = newnode;
第一步:pq->ptail->next = newnode
原来队尾是节点 1,让节点 1 的 next 指向新节点 2:
plaintext
phead
↓
[1 | next] → [2 | NULL]
↑
ptail
第二步:pq->ptail = newnode
把队尾指针移到新节点上:现在:
- phead 依然指向 1(队头不变)
- ptail 改成指向 2(新队尾)
结构图:
plaintext
phead
↓
[1] → [2]
↑
ptail
然后 size++,size 变成 2。
再插第三个元素 Push (3) 一模一样流程
新建节点 [3|NULL]
执行:
pq->ptail->next = newnode当前队尾是 2,让 2 的 next 指向 3
plaintext
[1]→[2]→[3|NULL]
pq->ptail = newnode队尾指针挪到 3:
plaintext
phead→[1]→[2]→[3]←ptail
size 变成 3。原来的队尾的 next 指向新节点然后把队尾更新为新节点
核心逻辑一句话总结
- 队列为空:phead 和 ptail 全部指向新节点
- 队列不为空:
- 老队尾节点的 next 连上新节点
- 把 ptail 指针挪到新节点,做新队尾
- 每次插入 size 加一空:
- phead=NULL ptail=NULL
- 插 1:phead→[1]←ptail
- 插 2:phead→[1]→[2]←ptail
- 插 3:phead→[1]→[2]→[3]←ptail
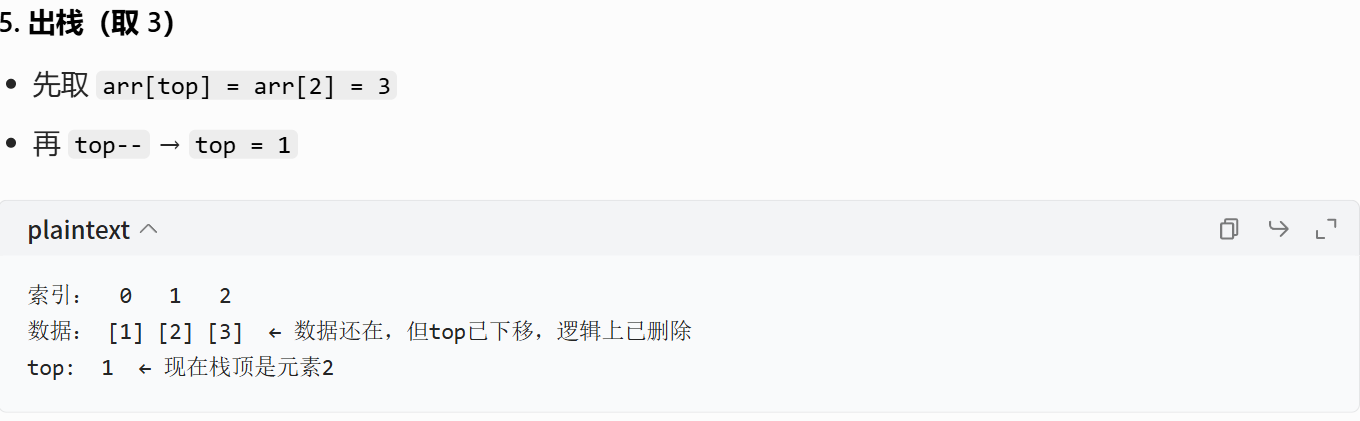
因为队列只能头部删除,所以我们只展示头删
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->size != 0); // 不能删空队列
// 一个节点
if (pq->phead->next == NULL)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else // 多个节点
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}单个节点直接释放再NULL
多个节点先保存下一个节点再释放,让phead走向下一个节点
队列:1 → 3 →5 删1: 3 →5 phead→3
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->phead); // 队列不能为空
return pq->phead->val;
}获取队尾元素
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}获取元素个数
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}进行判空

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)