LoCoMo 与 LongMemEval:AI记忆领域的两大“高考“,为什么它们是业界公认的评测标准?
在研究AI记忆的过程中,你一定在各种论文、评测报告中反复看到这两个名词:LoCoMo 和 LongMemEval。
它们被称为AI记忆领域的"行业标尺",从Mem0到MemoryLake,从Supermemory到TiMem,几乎所有主流记忆系统都会用这两套benchmark来证明自己的性能。
它们具体评测了哪些内容?又为什么能够获得全行业的公认成为业界公认的评测标准?

一、LoCoMo:长对话记忆的"黄金标准"
LoCoMo是什么?
LoCoMo 全称是 Long-term Conversational Memory Benchmark,中文翻译为"长期对话记忆基准测试"。
它是由 UNC Chapel Hill(北卡罗来纳大学教堂山分校)、USC(南加州大学)和Snap Inc. 联合发布于2024年2月,是学术界首个系统性评测AI长期对话记忆能力的基准。
LoCoMo的评测理念
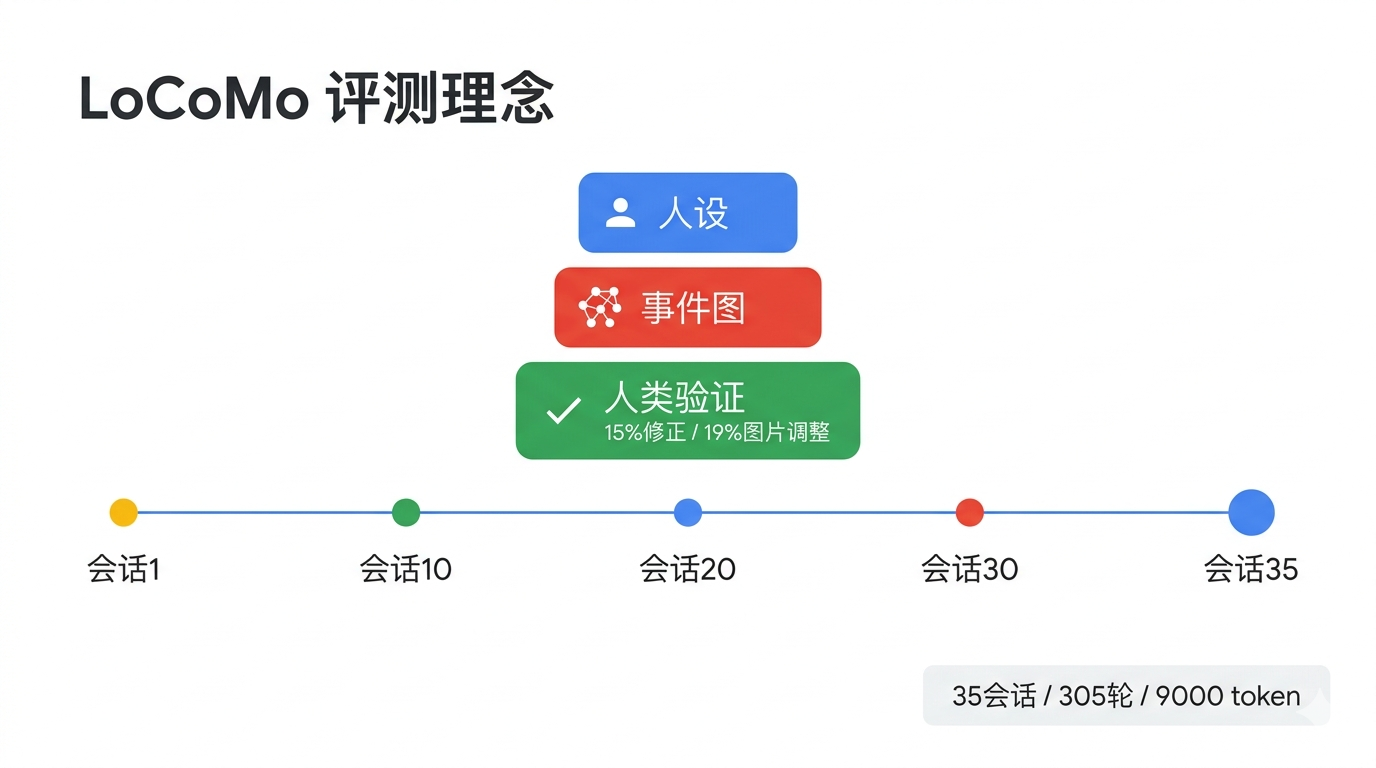
LoCoMo的核心设计理念非常简单:模拟真实人类的长期对话场景。
传统的对话评测通常只关注5个会话以内的短对话,但LoCoMo直接把尺度拉到了最多35个会话、平均305轮对话、约9000个token——相当于你和一个人连续聊了好几个月的记录。
更重要的是,LoCoMo不是简单生成长文本,而是基于"人设+事件图"的结构化生成:
-
每个对话的虚拟角色都有完整的persona(身份、习惯、人际关系)
-
每个角色都有一个包含25个因果关联的"人生事件图"
-
对话按时间推进,每个会话都与角色的事件时间线对齐
-
还加入了图片分享和反应的多模态元素
最后,所有生成的对话都会经过人类标注员验证和编辑,确保长程一致性和事件图对齐——据统计,约15%的话语需要修正,19%的图片需要调整。
这意味着LoCoMo评测的不仅仅是"AI能记住多少文字",而是"AI能否像人类一样在长周期的对话中保持逻辑一致性、理解因果关系、记住重要信息"。
LoCoMo评测哪些内容?
LoCoMo包含三大核心评测任务:
任务1:长上下文问答(QA)
这是最核心的评测项。评测提供完整的多组会话的对话历史,测试系统能否正确回答关于历史事实或事件的问题。
这项评测的问题被细分为5种类型,层层递进:
|
问题类型 |
评测目标 |
难度 |
|---|---|---|
|
单跳推理(Single-hop) |
直接回忆某句话中的具体信息 |
⭐ |
|
多跳推理(Multi-hop) |
需要关联多个不同时间点的信息才能回答 |
⭐⭐⭐ |
|
时序推理(Temporal) |
需要理解日期、先后顺序、时间间隔 |
⭐⭐⭐⭐ |
|
开放域/常识(Open-domain) |
需要结合世界知识和对话内容 |
⭐⭐⭐ |
|
对抗性问题(Adversarial) |
问题答案不在对话中,考察模型是否会"幻觉" |
⭐⭐⭐⭐⭐ |
举个时序推理的例子:用户在5月8日的对话中提到"我昨天去了GBS支持小组",然后系统被问到"Caroline哪天去的支持小组?"
正确答案应该是是"5月7日",但很多系统会错误回答"5月8日"——因为它们能记住这句话,但无法理解"昨天"这个相对时间概念。
评分方式:F1分数,越高越好。
任务2:事件图总结(Event Graph Summarization)
测试系统能否从长篇对话中正确的抽取出因果关系和时间关联,重构出角色的完整事件图。
这项评测考察的不仅仅是"记忆",而是"理解和归纳"——系统需要理解哪些事件是因果相关的,哪些事件是独立的,哪些事件只是噪音。
任务3:多模态对话生成(Multi-modal Dialog Generation)
测试系统在生成回复时,能否正确利用从过去对话中回忆起的相关上下文,保持与整体叙事的一致性。
这项评测尤其考察的是图片相关的问题——系统不能只看图说,还要结合历史上下文来理解图片的真正含义。
为什么LoCoMo能成为业界标准?
主要是以下四个核心原因:
-
学术权威性:评测标准来自顶级高校和企业的联合研究,论文被大量引用
-
场景真实性:所有测试任务基于人设+事件图的生成,再经人类验证,最大限度的模拟了真实对话
-
评测维度完整:从单跳推理到多跳推理,从时序推理到对抗性问题,覆盖了记忆系统的各个层面
-
历史积累丰富:2024年发布至今,几乎所有的主流记忆系统都在LoCoMo上跑过分,形成了完整的"性能坐标系"
二、LongMemEval:长期记忆检索的"终极考验"
LongMemEval是什么?
如果说LoCoMo是学术界的“行业标尺”,那么LongMemEval就是工业界的“高考”。
它是目前最严苛、最贴近于真实生产环境的AI长期记忆基准测试,被业内称为"AI记忆的终极考核"。
与LoCoMo不同,LongMemEval更侧重检索质量——即在极端长上下文、信息混乱、矛盾重叠的真实场景中,系统能否准确的找到需要的信息。
LongMemEval的评测理念
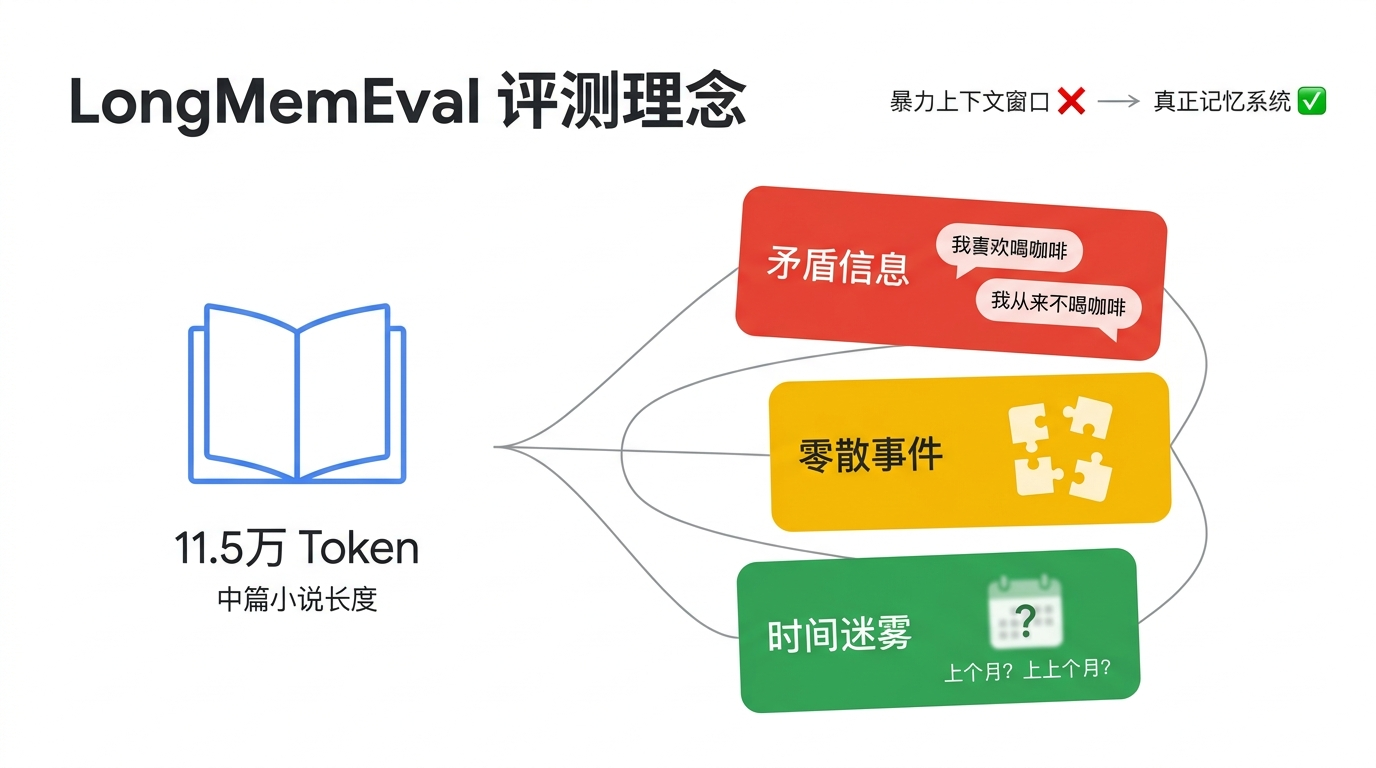
LongMemEval的设计哲学是:真实世界的记忆从来不是干净、有序的。
人类的记忆充满了:
-
矛盾的信息(你今天说"我喜欢喝咖啡",上周却说"我从来不喝咖啡")
-
零散的事件(信息散落在几十个不同的会话中,需要拼起来)
-
时间的迷雾("这件事到底是上个月还是上上个月发生的?")
LongMemEval就是要模拟这种"混乱"。
它的测试集基于11.5万Token的超长对话历史——相当于一本中篇小说的长度。在这个规模下,任何依赖暴力上下文窗口的方法都会失效,必须依靠真正的记忆系统。
LongMemEval评测哪些内容?
LongMemEval主要评测三大核心难点,每一项都是真实生产环境中经常遇到的痛点:
难点1:矛盾信息处理
问题描述:用户在不同时间说了相互矛盾的话,系统能否正确识别哪条是最新的、应该采信的。
例子:
-
1月:"我不喜欢吃辣"
-
3月:"我最近爱上了重庆火锅"
系统需要理解"偏好会随时间改变",并正确采信最新的信息。
难点2:跨会话零散事件召回
问题描述:一个完整事件的线索散落在10个不同的会话中,每次只提到一点点,系统能否把它们拼起来?
例子:
-
Session 1:"我打算今年去日本旅游"
-
Session 5:"机票订好了,7月15日出发"
-
Session 12:"酒店选了东京的一家民宿"
-
Session 20:"签证下来了"
问题:"用户的日本旅行计划是什么时候出发?住哪里?"
这需要系统能把分散在不同时间点的碎片信息整合起来。
难点3:深度时间推理
问题描述:需要对多个时间点进行比较、计算、排序才能回答。
LongMemEval专门设计了大量需要进行时间推理的问题,这是很多记忆系统的死穴。
为什么LongMemEval是业界公认的"高考"?
-
真实到残酷:11.5万Token、矛盾信息、零散事件——这就是生产环境会遇到的真实问题,而不是实验室的理想数据
-
淘汰率高:传统RAG系统在LongMemEval上通常只有60%以下的准确率,甚至更低
-
全民参与:从开源项目到商业产品,几乎所有记忆系统都会参与并公布自己的LongMemEval成绩
-
成绩区分度好:不同架构的性能差异在LongMemEval上体现得淋漓尽致
三、LoCoMo和LongMemEval的区别与互补
看到这里,很多人可能会问:为什么需要两套评测?一套不够吗?
因为它们考察的是记忆系统完全不同的两个维度:
|
维度 |
LoCoMo |
LongMemEval |
|---|---|---|
|
核心定位 |
长对话理解与推理能力 |
长期记忆检索质量 |
|
测试规模 |
~9K token / 35会话 |
11.5万token |
|
评测重点 |
推理能力、时序理解、因果关系 |
检索准确率、矛盾处理、信息整合 |
|
评分方式 |
F1分数(答案质量) |
Recall@5(检索召回率) |
|
发布背景 |
学术界 |
工业界 |
|
适用场景 |
对话助手、长期陪伴Agent |
知识库、文档回忆、个人记忆系统 |
简单来说:
-
LoCoMo考的是"脑子灵不灵活"——记住了之后会不会用、能不能推理
-
LongMemEval考的是"记性好不好"——能不能在海量信息中准确找到需要的内容
一个优秀的记忆系统,需要在两套评测上都取得好成绩。
四、写在最后
评测标准从来不是目的,而只是推动技术进步的手段。
LoCoMo和LongMemEval的真正价值,不在于它们把记忆系统分成了三六九等,而在于它们给整个行业指明了方向:
-
记忆不是简单的"存和取",而是理解、推理、归纳的综合能力
-
真实场景的记忆需要处理矛盾、理解时序、整合碎片
-
好的记忆系统应该在保证准确率的同时,也要保证效率
同时他们的意义也是给予了记忆系统一个量化指标,毕竟如果一个AI记忆系统你无法衡量它,你就无法改进它。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)