影刀RPA + LLM:重构拼多多与TEMU店群的“AI智能客服与售后调度中枢”
大家好,我是林焱。
在前面的系列文章中,我们从“多浏览器并发调度”、“底层COM接口数据交互”一路聊到了“可执行文件的加密防泄密”。很多技术同仁在评论区留言,表示通过多节点并发和物理沙盒,确实解决了店群铺货、核价和打单的效率瓶颈。
但这仅仅是电商链路的前半段。当你的拼多多或 TEMU 店群真正跑起来,达到 50 家甚至 100 家的规模时,另一个巨大的黑洞会瞬间吞噬你所有的利润和精力——海量的客服咨询与售后纠纷。
拼多多有严苛的“3分钟回复率”考核;TEMU 虽然是托管模式,但后端的质检工单、售后申诉同样需要高频处理。传统的做法是买几套客服聚合软件,配上几十个“关键词自动回复”。但这在如今的电商环境下等同于“自杀”:死板的自动回复极易激怒买家,导致纠纷率飙升,进而触发平台降权。
今天,我们将探讨店群自动化的“深水区”:如何利用 “影刀RPA(作为执行手臂) + 大语言模型LLM(作为决策大脑)”,构建一套具备上下文理解能力的智能客服与售后调度中枢。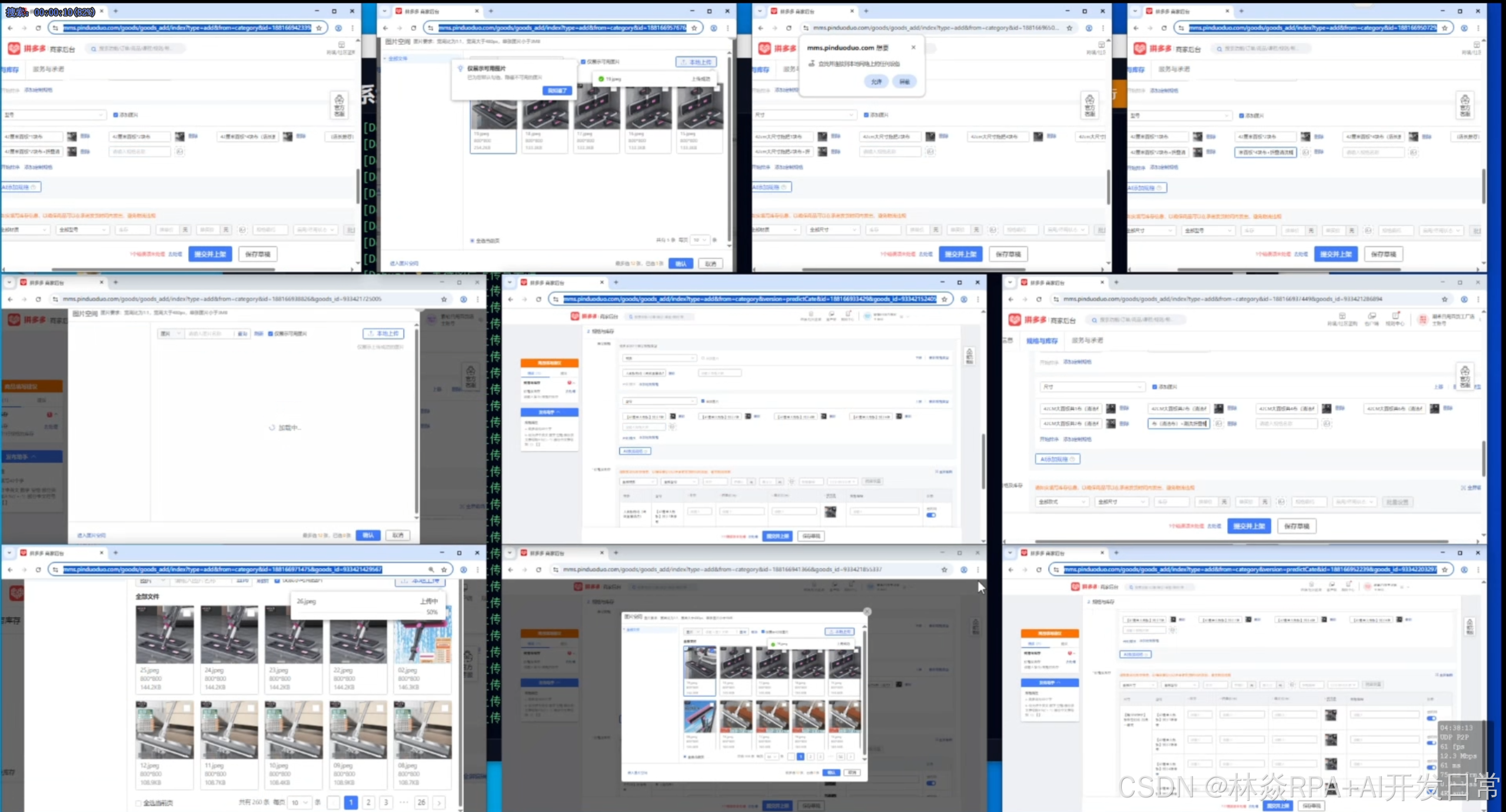
一、 传统规则引擎的失效与“RPA+LLM”范式的崛起
在过去,客服机器人的底层逻辑是 If-Else 规则引擎。买家发送“发货”,系统匹配关键词,回复“亲,48小时内发货哦”。
但真实的买家语言是极其非标准化的:
-
“老板,我昨天拍的那个红色的怎么还没动静?”(催发货)
-
“这衣服拿到手怎么有一股味儿啊,能退点钱补偿吗?”(质量问题+仅退款暗示)
传统的 RPA 抓取到这些文本后,规则引擎直接瘫痪。
技术重构思路:
我们将 RPA 的角色收缩为纯粹的“感知与操作”层(负责轮询各个店铺的聊天窗口、抓取 DOM 文本、点击发送按钮或退款按钮)。
而将业务判断的逻辑,全部剥离并 API 化,交给后端的大语言模型(如 GPT-4o、DeepSeek 或是本地部署的 Qwen)来处理。
RPA + LLM 的工作流如下:
-
RPA 监听: 轮询并发沙盒中的 50 个店铺聊天窗口。
-
上下文捕获: 抓取买家的历史聊天记录、当前订单状态(已发货/未发货)。
-
Prompt 组装: 将上述信息打包为 JSON,附带系统的 System Prompt(客服人设与售后规则),发送给 LLM。
-
意图判定与动作生成: LLM 不仅生成回复话术,还输出结构化的动作指令(如:
{"action": "reply", "text": "..."}或{"action": "refund", "amount": 5.0})。 -
RPA 执行: RPA 接收 JSON,执行打字回复或点击退款流程。
二、 核心架构代码抽象(概念性演示)
为了让大家更清晰地理解这套架构的流转逻辑,我抽象了一段 Python 核心调度代码。
(注:以下代码为架构思维演示,旨在展示 AI 决策与 RPA 执行的解耦机制,已隐去真实平台的 DOM 元素定位规则。)
Python
店群矩阵自动化突破运营极限!
import json
import requests
class AIOperationsDispatcher:
def __init__(self, llm_api_key, system_prompt):
self.api_key = llm_api_key
self.system_prompt = system_prompt
self.api_endpoint = "https://api.your-llm-provider.com/v1/chat/completions"
def analyze_intent_and_decide(self, buyer_message, order_status):
"""
[大脑层] 调用大模型进行意图识别与决策
"""
prompt = f"""
买家消息: "{buyer_message}"
当前订单状态: "{order_status}"
请判断买家意图,并返回严格的JSON格式:
{{"action": "reply"|"refund"|"escalate", "response_text": "...", "refund_amount": 0}}
"""
headers = {"Authorization": f"Bearer {self.api_key}"}
payload = {
"model": "deepseek-chat", # 店群高频调用推荐高性价比模型
"messages": [
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": prompt}
],
"response_format": {"type": "json_object"}
}
response = requests.post(self.api_endpoint, json=payload, headers=headers)
return json.loads(response.json()['choices'][0]['message']['content'])
def rpa_execution_node(self, store_session):
"""
[手臂层] 影刀RPA单节点的轮询与执行逻辑
"""
# 1. RPA 抓取当前未读消息与订单信息(底层封装影刀指令)
unread_msg = store_session.get_latest_message()
order_info = store_session.get_order_status()
if unread_msg:
# 2. 传递给 LLM 大脑进行决策
decision = self.analyze_intent_and_decide(unread_msg, order_info)
# 3. RPA 根据决策路由执行具体物理动作
if decision['action'] == 'reply':
store_session.type_and_send(decision['response_text'])
print(f"[RPA] 已发送AI回复: {decision['response_text']}")
elif decision['action'] == 'refund':
# 例如:买家要求小额补偿,AI判定符合利润红线,RPA自动走仅退款流程
store_session.click_refund_button()
store_session.input_refund_amount(decision['refund_amount'])
store_session.submit()
print(f"[RPA] 已自动处理售后补偿: {decision['refund_amount']}元")
elif decision['action'] == 'escalate':
# 遇到极端客诉或职业打假人,AI判定超出权限,打标签转人工
store_session.tag_conversation("需人工介入")
print("[RPA] 高危会话,已转交人工客服池。")
三、 工程落地中的“踩坑与避坑”
在真实的百店矩阵中跑通这套逻辑,远比写一段 API 调用复杂得多。以下是我在实战中总结的三个核心优化点:
1. Token 成本黑洞与本地化部署 (Ollama)
50 个店铺每天可能有上万条咨询。如果全部走闭源大模型(如 GPT-4),API 账单会吃掉你一半的利润。
实战解法: 对于简单的催发货、尺码咨询,我们强烈建议在局域网内使用高配主机(如搭载 RTX 4090),通过 Ollama 本地部署 Qwen2.5-7B 或 Llama3-8B。只有遇到逻辑极其复杂的售后定损工单,再通过代码路由(Router)转发给云端的千亿参数大模型。
2. LLM 的“幻觉”控制(防超额退款)
大模型在计算金额时偶尔会产生幻觉。如果买家要求退 100 元,大模型抽风同意了,这会导致严重资损。
实战解法: 在 RPA 执行层(上述代码的 rpa_execution_node)必须加一层硬编码的熔断规则。无论 LLM 输出多少退款金额,只要超过订单总金额的 15% 或绝对值超过 20 元,RPA 强制拦截并转人工。不要完全信任 AI 的数值计算,安全网必须用代码写死。
3. 情绪安抚的延时策略
AI 处理速度太快了。如果买家刚发完一大段抱怨,系统 1 秒钟就回复了一大段安抚的话,买家立刻就能察觉这是机器人,反而会更加愤怒。
实战解法: 在 RPA 执行 type_and_send 之前,加入基于字数的随机延时(例如:每生成 10 个字延迟 0.8 秒),并在 UI 层模拟“对方正在输入中...”的状态,将 AI 的“机器感”降到最低。
四、 总结
将大语言模型的认知能力,注入到高并发的多浏览器 RPA 架构中,是目前电商店群自动化最前沿的探索方向之一。
它不仅解决了传统店群模式中“客服人效极低”的痛点,更重要的是,它将售后处理从一种“体力劳动”升级为了“数据驱动的智能调度”。随着开源小模型的能力不断逼近 GPT-4,这种“私有化 LLM + 独立端 RPA”的架构,必将成为头部店群卖家的标配。
大家在将 LLM 接入业务流水线时,遇到过哪些奇葩的模型幻觉或者并发问题?欢迎在评论区留言,我们下一期深入探讨底层的内存级防封杀技术。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)