计算机真的看懂图片了吗?从数据、张量到模型预测
上一篇我们讲了一个最基础的问题:
深度学习到底在学什么?
简单来说,深度学习不是让人把所有规则都写死,而是给模型很多数据,让模型自己从数据里总结规律。
但是说到“数据”,它其实有很多种形式。比如:
图片:猫狗图片、手写数字图片、布料缺陷图片
文本:评论、新闻、论文、聊天记录
语音:一句话、一段录音、语音指令
表格:学生成绩、房价数据、用户信息
视频:监控画面、自动驾驶道路视频
这些数据看起来完全不一样,但在进入深度学习模型之前,都要先变成计算机能处理的数字。
那为什么我们这个系列先从图片讲起呢?
原因很简单:图片最直观。
我们能直接看到一张图片,也能很容易理解“猫狗分类”“手写数字识别”“缺陷检测”这些任务。相比文本、语音、表格数据,图片更适合用来解释深度学习入门阶段最重要的几个概念,比如:像素、矩阵、张量、通道、Batch Size、模型输入、模型输出、分类预测等。
当然,这并不代表深度学习只能处理图片。文本、语音、表格、视频也都可以用深度学习处理。只是对于初学者来说,图片是最容易“看见”和“理解”的入口。
所以今天这篇文章,我们就先从图片开始,看看:
一张图片在电脑眼里到底是什么?
接下来我们会讲清楚三个问题:1. 一张图片在计算机眼中到底是什么?2.深度学习中经常提到的张量Tensor是什么?3.模型第一次预测为什么像是乱猜?
1.计算机看到的不是图片,而是数字
我们人看到一张猫的图片,会觉得:
这是一只猫,它有耳朵、眼睛、胡须、毛发。
但是计算机不会这么理解。对计算机来说,一张图片其实是一堆像素点,而每个像素点又对应着数字。如果是一张灰度图,每个像素点通常可以用一个数字表示亮度。比如:
0 表示黑色
255 表示白色
中间的数字表示不同程度的灰色
所以一张简单的灰度图片,在电脑里可能长这样:
[
[ 0, 20, 35, 80],
[ 10, 60, 120, 200],
[ 30, 90, 180, 240],
[ 50, 100, 210, 255]
]
这看起来像不像一个表格?没错,灰度图本质上就可以理解成一个二维矩阵。也就是说:
图片=数字矩阵
只不过我们人类看到的是图像,电脑处理的是数字。

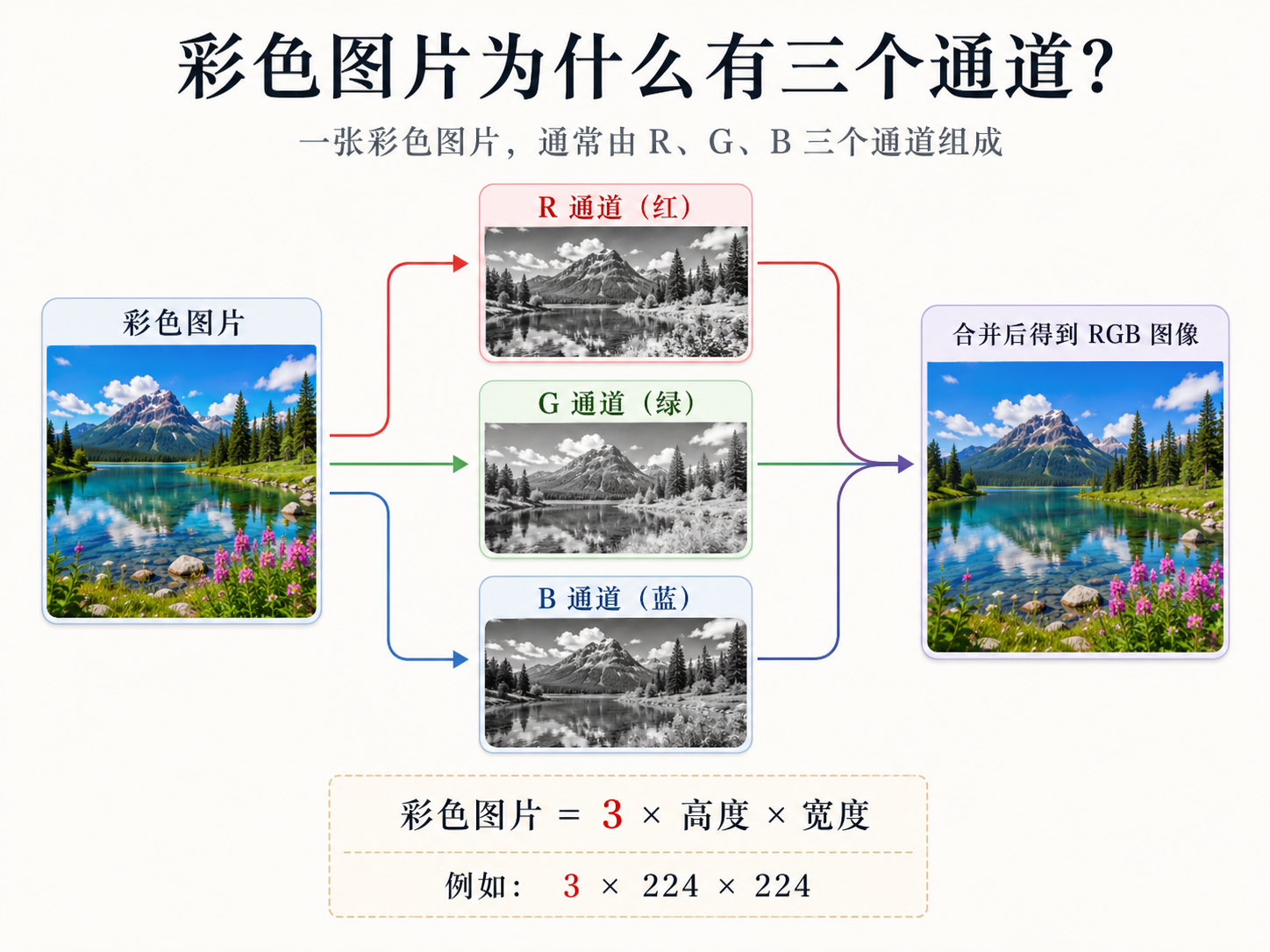
2. 彩色图片为什么有三个通道?
刚才讲的是灰度图,但是我们平时看到的大多数图片都是彩色图片。彩色图片通常由三个颜色通道组成:
R:Red,红色通道
G:Green,绿色通道
B:Blue,蓝色通道
也就是我们常说的RGB图片。一张彩色图片,可以理解成由三张灰度图叠在一起,三个通道合在一起,就形成了最终看到的彩色图片:
红色通道:记录每个像素有多少红色
绿色通道:记录每个像素有多少绿色
蓝色通道:记录每个像素有多少蓝色
例如一张大小为 224 × 224 的彩色图片,它在电脑里通常可以表示成:
3 × 224 × 223
这里的含义是:3:RGB3个通道,224:图片高度,223:图片宽度所以,对于深度学习模型来说,一张彩色图片不是“猫图”或者“狗图”,而是一个三维数字数组。
可以这样理解:
灰度图:高度 × 宽度
彩色图:通道数 × 高度 × 宽度
3. 张量 Tensor 到底是什么?
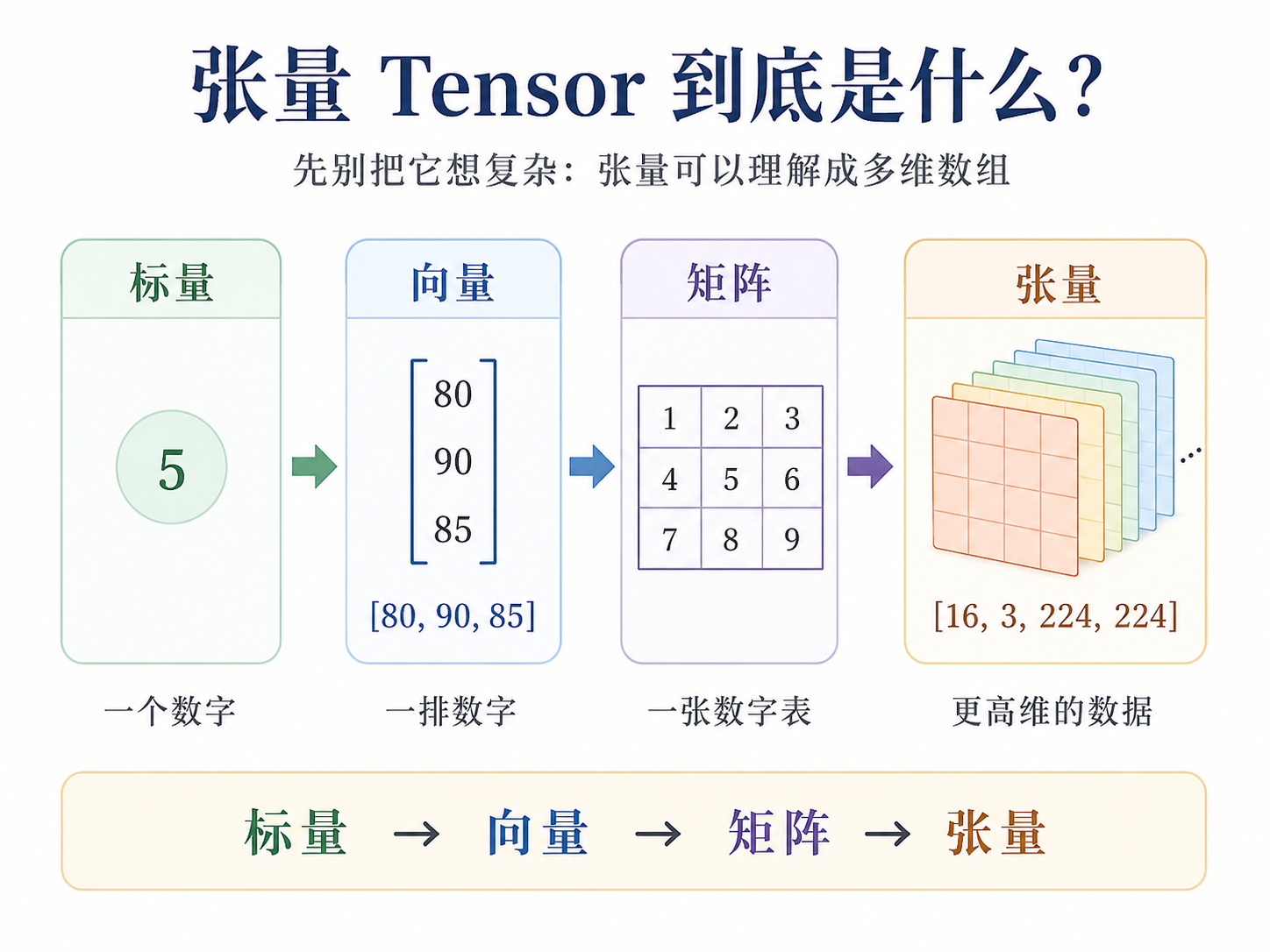
学深度学习时,我们经常会看到一个词:Tensor,张量。很多初学者第一次看到这个词,会觉得很抽象。其实先不用把它想得太复杂,在入门阶段,我们可以先把张量理解成:用来装数据的多维数组。我们可以从低维到高维慢慢看。
3.1 标量:一个数字
一个单独的数字叫标量。比如:5,3.14,100等,它没有方向,也没有维度,也就是一个数字。
3.2 向量:一排数字
一排数字可以叫向量。比如一个学生的三个成绩:[80, 90, 85],可以表示每一科的成绩,例如语文:80,数学:90,英语:85,这就是一维数据。
3.3 矩阵:一张数字表格
二维数字表格就是矩阵。比如
[
[80, 90, 85],
[70, 88, 92],
[95, 91, 89]
]
也是拿成绩举例,他可以表示多个学生的多门成绩,即第一个学生的三科成绩分别为80、90、85,第二个学生为70、88、92,第三个学生为95、91、89。在图像任务中,一张灰度图片也可以看成一个矩阵。
3.4 张量:更高维的数据
如果数据维度更高,就可以叫张量。例如一张彩色图片:
[3, 224, 224]
这就是一个三维张量。如果一次输入 16 张彩色图片:
[16, 3, 224, 224]
这就是一个四维张量。
可以先简单记住:
标量:一个数字
向量:一排数字
矩阵:一张数字表
张量:更高维的数字数组
4. 深度学习里常见的 [B, C, H, W] 是什么意思?
如果你开始看 PyTorch 代码,经常会看到这样的形状:
[16, 3, 224, 223]或者[32, 1, 28, 28]
这几个数字到底是什么意思?
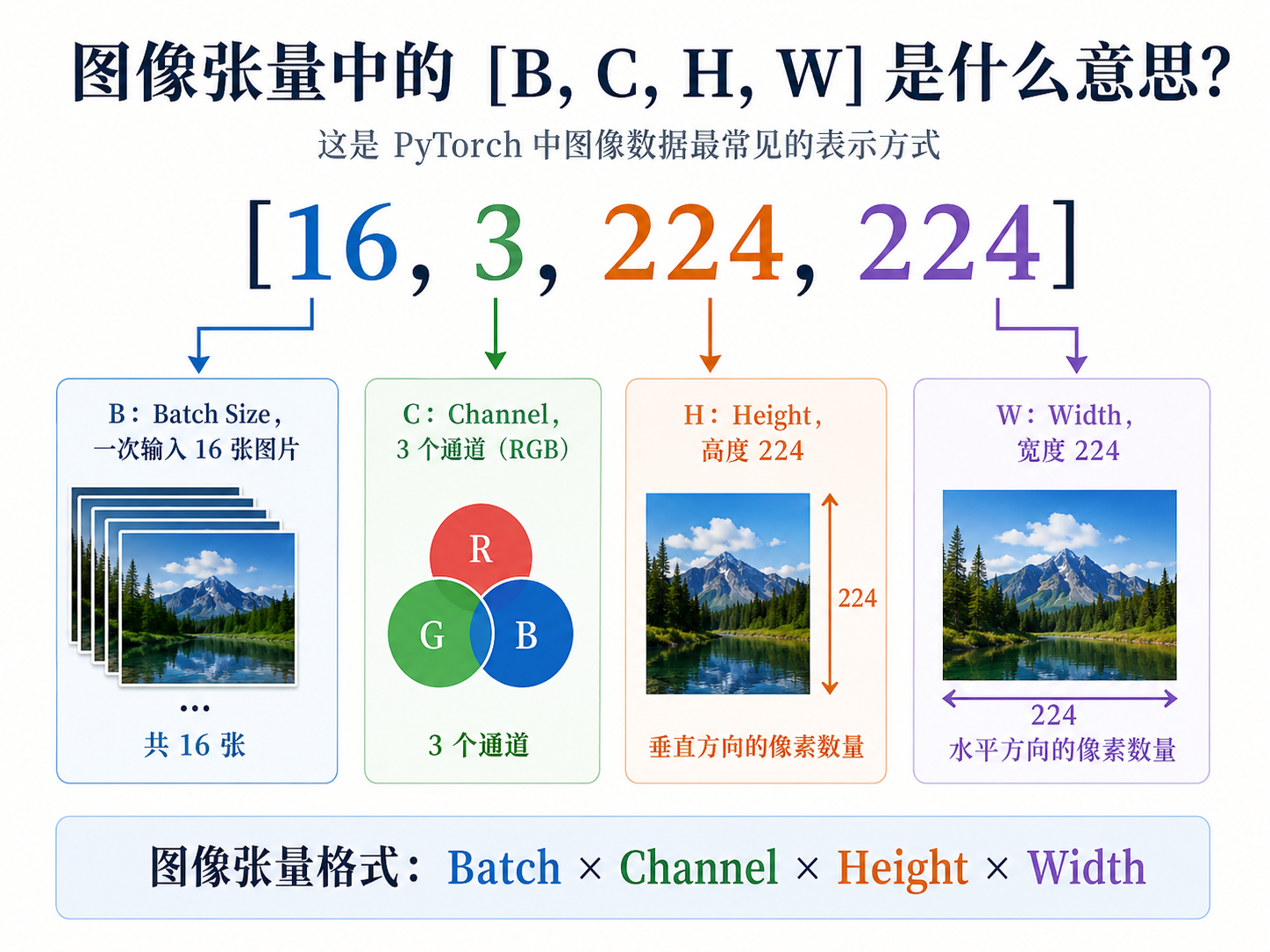
在图像任务中,PyTorch 里常见的图片张量格式是:
[B, C, H, W]
分别表示:
B:Batch Size,一次输入多少张图片
C:Channel,通道数
H:Height,图片高度
W:Width,图片宽度
例如[16, 3, 224, 224]的意思就是一次输入16张图片,每张图片有3个颜色通道,也就是RGB,图片的高度是224,图片的宽度是223。
5. 什么是 Batch Size?
刚才我们提到了一个词:Batch Size。他的意思是一次迭代进模型的样本数量。比如你有 1000 张图片,如果每次只送 1 张图片给模型,训练会比较慢,也不够稳定。所以通常我们会把数据分成一批一批。
比如:
总共有 1000 张图片
batch size = 100
那么每次送 100 张图片进入模型。这样完整训练一遍数据集,就需要:1000/100=10次,也就是10个iteration。可以把他类比成吃饭,我们不会一次把一整锅饭全塞进嘴里,而是一口一口吃。训练模型也是一样,不会一次把整个数据集全塞进去,而是一批一批送进去。
所以,Batch Size = 每次喂给模型多少个样本。
Batch Size 太小,训练可能比较慢,结果波动也可能比较大。
Batch Size 太大,占用显存会更多,普通电脑可能跑不动。
对于初学者来说,可以先记住:
显存小:batch size 设置小一点
显存大:batch size 可以适当调大
6. 用代码看一眼图片张量的形状
下面我们用一小段 PyTorch 代码来模拟一批图片。这里的前提是你已经学会了安装Pytorch,网上安装Pytorch的方法有很多,我这里先不具体写,如果以后有空我会再单独写,为了安装方便,可以先安装CPU版本的Pytorch,和CUDA版本相比没有那么多坑,但是后续训练模型最好还是要用CUDA。
import torch
x = torch.randn(16, 3, 224, 224)
print(x.shape)输出结果是:
torch.Size([16, 3, 224, 224])这表示我们创建了一个形状为 [16, 3, 224, 224] 的张量。也就是16张图片,每张图片3个通道,每张图片高度为224,宽度为224。这里的torch.randn()会生成一些随机的数字。虽然这些数字不是真实图片,但他的形状和一批真实图片是一样的。
7. 模型输入和输出是什么?
现在我们知道了,图片进入模型之前会变成张量。那么模型会输出什么?这取决于任务类型。如果是猫狗分类,模型可能输出两个分数:
猫:2.1
狗:0.5
如果是 10 类手写数字识别,模型可能输出 10 个分数:
数字 0:0.1
数字 1:2.3
数字 2:-0.5
数字 3:1.2
数字 4:0.0
数字 5:-1.1
数字 6:0.4
数字 7:3.2
数字 8:1.0
数字 9:0.7
这 10 个数并不是最终概率,而是模型对每个类别的原始打分。一般来说,分数越高,模型越倾向于认为图片属于这个类别。比如上面的例子中,数字 7 的分数最高,所以模型可能认为这张图片最可能是数字7。
8. Softmax:把分数变成概率
刚才说模型输出的是一组分数。但是我们更习惯看到这种形式:
猫:86%
狗:14%
这个时候就会用到常说的Softmax,他的作用可以先简单理解为把一组类别分数转换成一组概率。转换之后,所有类别的概率加起来等于 1。例如模型输出两个分数:猫:2.1,狗:0.5经过Softmax之后,可能就变成猫:83%,狗:17%。就更容易理解了。
但是要注意一点:Softmax 输出的是模型认为的概率,不一定代表它真的预测对了。比如一张猫图,模型可能输出:
猫:10%
狗:90%
这说明模型很自信地认为它是狗,但真实答案是猫。所以模型是否真的好,还要看预测结果和真实标签之间的差距。这个差距,就是下一篇要讲的 损失函数 loss。
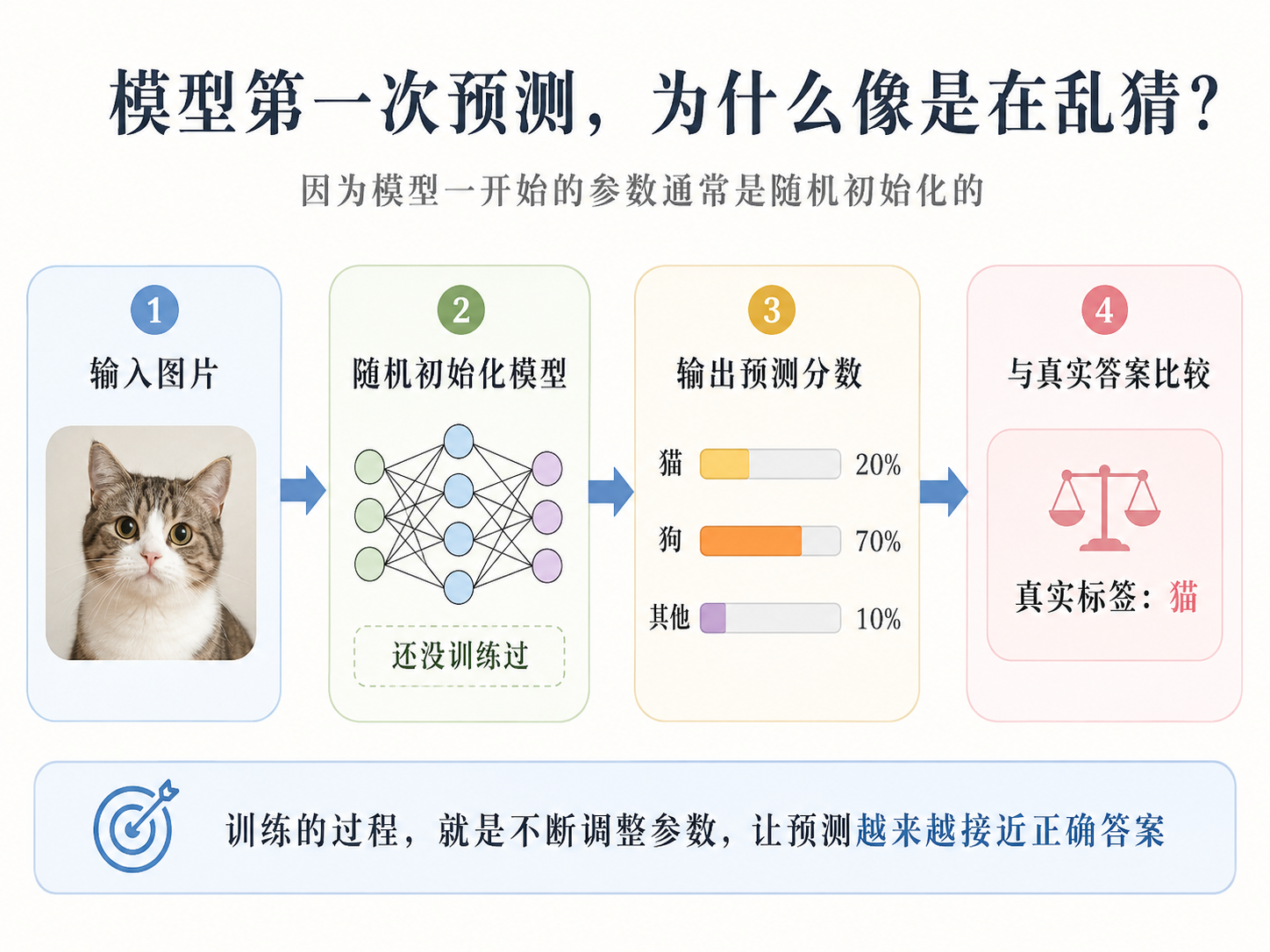
9. 模型第一次预测为什么像是在乱猜?
很多初学者会以为,模型刚创建出来就应该有一点识别能力。但实际上,模型一开始通常是没有训练过的。它里面的参数大多是随机初始化的。也就是说,刚开始的模型并不知道什么是猫,什么是狗。我们可以把模型内部的参数理解成一堆“可调旋钮”。一开始,这些旋钮的位置是随机的。所以模型第一次预测时,结果往往也是不靠谱的。比如给它一张猫的图片,它可能输出:
猫:20%
狗:70%
其他:10%
这就是我们说的:模型一开始更像是在“乱猜”。训练的过程,就是不断调整这些参数,让模型从乱猜变成越来越会猜,最后逐渐学会正确分类。
10. 用代码模拟一次“模型预测”
下面我们用一个非常简单的模型来模拟预测过程。假设我们现在有一个输入数据,它有 4 个特征。模型要判断它属于 3 个类别中的哪一个。
import torch
import torch.nn as nn
# 定义一个最简单的线性模型
model = nn.Linear(4, 3)
# 模拟一个样本,包含4个特征
x = torch.randn(1, 4)
# 得到模型输出
output = model(x)
print(output)你可能会得到类似这样的输出:
tensor([[ 0.2314, -0.5821, 1.0345]], grad_fn=<AddmmBackward0>)这里输出了 3 个数字,分别表示模型对 3 个类别的打分。如果我们想把它变成概率,可以加 Softmax:
import torch.nn.functional as F
prob = F.softmax(output, dim=1)
print(prob)可能输出:
tensor([[0.2671, 0.1184, 0.6145]], grad_fn=<SoftmaxBackward0>)这表示模型认为:
类别 0:26.71%
类别 1:11.84%
类别 2:61.45%
所以模型会倾向于预测为类别 2。不过要注意:这个模型还没有训练过,所以现在的预测没有实际意义。它只是根据随机初始化的参数算出了一个结果。这也正好说明了一个关键问题:模型不是天生就会分类。模型需要通过训练,才能逐渐学会分类。
11.今日小结
今天只需要记住下面几个核心点:
1. 电脑不能像人一样直接“看懂”图片,它看到的是像素数字。
2. 灰度图可以理解成二维矩阵。
3. 彩色图通常由 R、G、B 三个通道组成。
4. 张量可以先理解成多维数组。
5. PyTorch 中常见的图片格式是 [B, C, H, W]。
6. Batch Size 表示一次送进模型的样本数量。
7. 模型输出的是类别分数,Softmax 可以把分数变成概率。
8. 未训练的模型第一次预测通常不靠谱,因为参数还是随机的。
12.下一节讲什么
今天我们知道了:
图片进入模型后,其实是一堆数字组成的张量,模型会根据这些数字输出预测结果。
但是新的问题来了:
如果模型预测错了,它怎么知道自己错得有多离谱?
比如一张猫的图片,模型却预测成狗。这时候我们就需要一个东西来衡量:
模型预测结果和真实答案之间到底差了多少
这个东西就是深度学习里非常重要的概念:损失函数 Loss Function,下一篇我们就来讲损失函数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)