三、Explain详解与索引实践
Explain工具介绍:使用Explain关键字,可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈。在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL。
注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中。
explain中的列 :
接下来我们将展示 explain 中每个列的信息。
-
id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。 -
select_type 表示对应行是简单还是复杂的查询。
· simple:简单查询。查询不包含子查询和union
· subquery:包含在 select 中的子查询(不在 from 子句中)
· derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义) -
table列
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。 -
partitions列
如果查询是基于分区表的话,partitions 字段会显示查询将访问的分区。 -
type列
这一列表示 MySQL 访问表数据的方式 。也可以理解成:MySQL 查数据时“扫描范围有多大”。范围越小,性能通常越好。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以
单独查找索引来完成,不需要在执行时访问表。
· system
是最优的情况。表示这张表只有一行数据,MySQL 可以直接拿到。
· const
通过主键索引或唯一索引,一次就能定位到一条数据。
例如:SELECT * FROM user WHERE id = 1;
· eq_ref
eq_ref 常见于 多表关联查询。 连表条件是主键或者唯一索引 精确匹配一行
· ref
使用了普通索引进行等值查询,可能匹配多行。
例如: SELECT * FROM user WHERE age = 18;
· range
使用索引做范围查询。
例如:
WHERE age > 18
WHERE age BETWEEN 18 AND 30
WHERE create_time >= ‘2026-01-01’
WHERE id IN (1, 2, 3)
range 说明 MySQL 没有扫描全表,而是在索引树上找一段范围。
· index
index 表示:扫描整个索引树。
例如:SELECT name FROM user;
如果 name 字段有索引,MySQL 可能直接扫描 name 索引,而不是扫描整张表。
· All
ALL 表示:全表扫描
例如: SELECT * FROM user WHERE name = ‘张三’;
如果 name 没有索引,那么 MySQL 只能从第一行扫到最后一行。这就是最差的情况。
如果表数据量很大,ALL 很容易导致慢查询。
-
possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。 -
key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。 -
key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
举例来说,film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成,并且每个int是4字节。通过
结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。 -
rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
索引失效场景:
· %like 左模糊查询
· 隐式类型转化
· 联合索引不符合最左前缀原则
· 对索引加函数处理,例如 date(index) 、substring(index)
· in( ) 范围很大 可能也不走索引
· is null 或 is not null 可能也不走索引
· or 关键字
索引使用总结: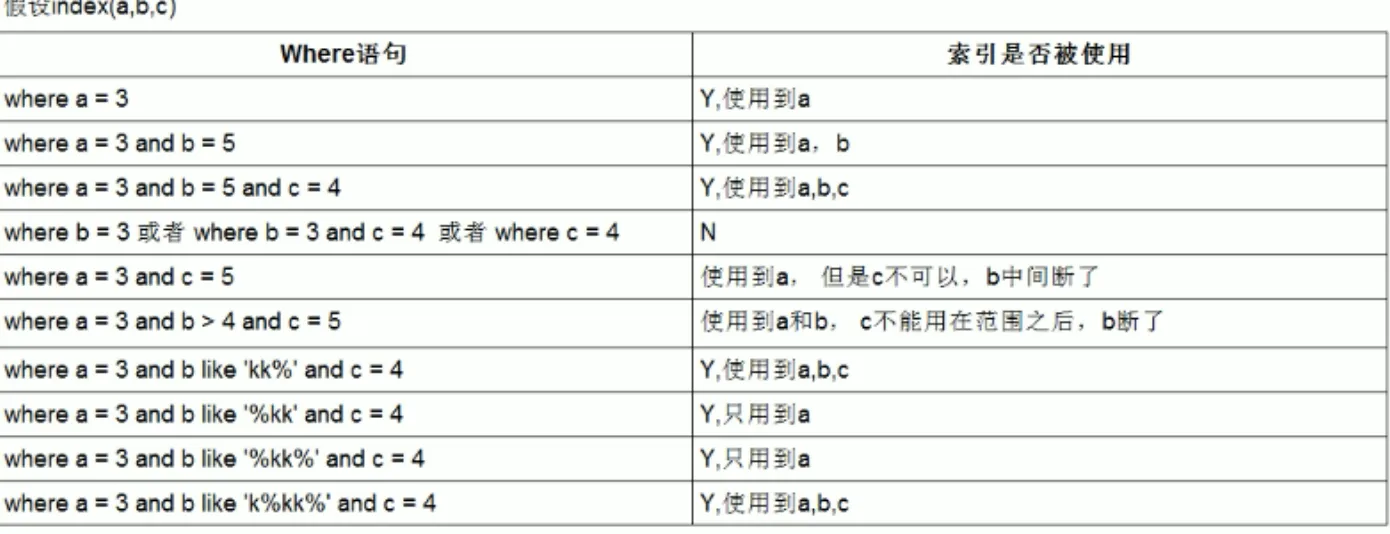

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)