跑分第一,不代表实战第一:我在Flutter开发里怎么选编程大模型
大家好,我是老刘
前段时间,GPT-5.5在多个编程能力评测里都拿了超高分,直接登顶。
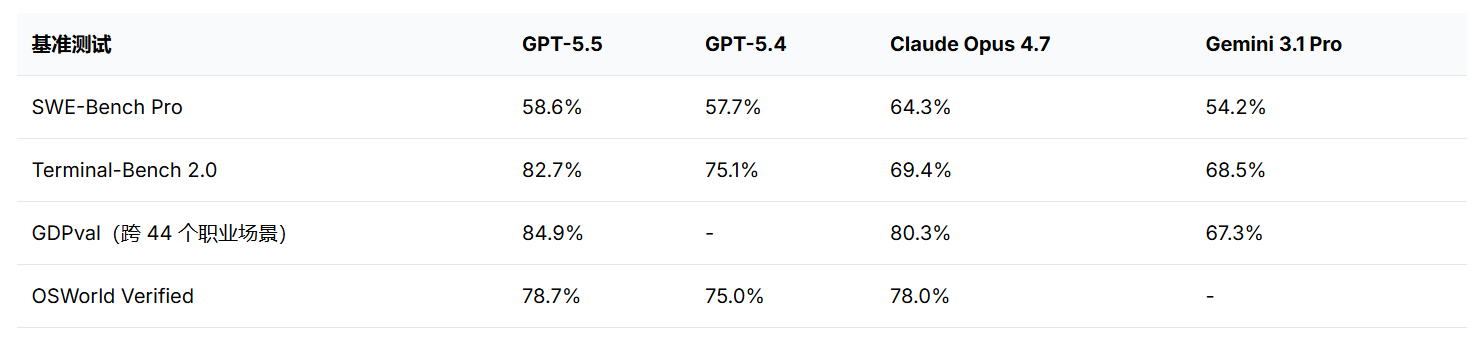
但媒体还没吹两天,就被质疑是过拟合。
说白了,就是怀疑它提前背了标准答案。
很多人看着各家大模型天天宣称自己第一,然后搭配一套评分最高的模型 + Claude Code的组合。结果一到实际项目里,该翻车还是翻车。
为啥你自己用AI开发的体验和自媒体宣传里那种能完全取代程序员的AI开发,完全不一样呢?
今天老刘就从日常Flutter商业项目实战的角度,聊聊我用主流大模型的真实体感,以及到底该怎么选、怎么用。
别盯着跑分选模型,小心开卷考试
现在的媒体里,三天两头就有新的模型登顶最强编程大模型。证据就是某一项测评得分最高。
但是如果这些测评是开卷考试,对我们评估模型的真实能力没有任何帮助。
比如在SWE-Bench Pro的评测中,模型能完美写出复杂的Bug修复方案。
但如果面对稍作修改、从未在网上出现过的同类逻辑问题时,表现就开始大幅下降。
这就是模型过度拟合了现有评测集的特征。
它学会了如何针对特定格式进行优化,但在真实多变的任务中无法泛化。
本质上,厂商为了刷榜,可能会针对提示词或后处理流程进行成千上万次的微调。
这种优化只在特定的测试环境下有效。
就像一个学生通过刷历年真题拿到了真题模拟考试的高分,但实际考试能力并没有同步提升。
那该怎么测模型的真实能力呢?
通常研究者会使用私有测试集来验证。如果模型在公开题库拿了高分,但在未公开的私有题库表现断崖式下跌,那么大概率就是针对性优化。
所以选模型别光看跑分,还要看落地表现。
主流大模型的实战体感(Flutter项目视角)
老刘的实战项目80%以上是企业项目。
就是那种有产品经理提需求、UI设计师出图、开发人员写代码、测试人员验收的项目。
这种场景下的开发体感,和很多独立开发者可能有一定差异,大家根据实际情况参考。
这里主要讨论模型本身的能力,暂不考虑不同开发工具的差异。
最稳的还是Claude:
在Flutter项目开发中,Claude表现最稳定。
- 很少犯错: 举个反例,上个月我尝试用Minimax M2.7给静态列表添加一行,结果它偷偷给我删了一行老内容。相对地,Claude很少出这种幺蛾子。
- 很少遗漏: 如果功能限制多,提示词里有十几条条件,很多模型大概率会遗漏几条。这方面Claude表现更好。
- 严格遵循规范: 当你需要模型完全遵循我们定义的开发规范生成代码时,Claude执行得更精致。其他模型或多或少会突破限制自由发挥。
- 不自作主张: 有的模型会偷偷帮你优化老代码。在工程中这点很危险,因为一段代码的Bug可能是系统正常运行的前提,修复这个Bug的代价你承受不起。
其实熟悉Harness的朋友可能发现了,这些不就是Harness的特征吗?所以总体来说Claude官方不管在模型训练还是在工程应用中都找到了更好的平衡点。
性价比之王Gemini与表现亮眼的GPT:
GPT系列5.4和5.5在实际开发中表现都很亮眼。生成的代码质量很高。
5.3-codex反应极快,我前一段时间大部分代码都是用它完成的。
目前在复杂逻辑的开发中,Gemini 3.1 Pro是我的主力模型。而在进行简单逻辑的开发,比如写个按钮或者对话框,Gemini 3 Flash是我的主力。
为什么以Gemini为主?
主要还是因为穷。
Claude消耗Token太快,Gemini性价比相对来说最高。
另一方面也是因为潜意识里总觉得Google自家模型在Flutter方面表现会好一点。
国产大模型能打吗:
基本上每个国产模型号称登顶后,老刘都会尝试一下。但简单试用后通常还是会回到Gemini或GPT。
写按钮或对话框这种简单任务,用Kimi 2.6或千问表现都不错。但如果是复杂逻辑任务,或者需要严格遵循开发规范时,顶级大模型的表现确实更好一些。
改Bug啥模型都不好使
这里要单独说一下定位Bug的问题。
前面讲的写代码、开发新需求,大模型表现都不错。
但如果是定位Bug,所有大模型的表现都不那么让人满意。

如果Bug限制在一个函数范围内,你描述问题,大模型在这个范围内定位,表现还可以。
但如果Bug跨越多个模块,需要综合定位,
你只告诉大模型现象,它大概率会进行各种角度的反复尝试,
浪费大量Token后一无所获。
即使最后修复了,也有很大可能是规避了Bug,而不是真正找到根因再修复。
本质上,定位Bug和写代码是完全不同的任务。
写代码有很大的容错空间,比如实现一个快速排序算法有100种写法,跑通就行。
但定位Bug几乎没有容错空间,必须完全精准定位,否则很难有效修复。
这个过程仅靠大模型的概率预测,其实很难完成,
更多还是要依靠严密的逻辑推理。
现实解法:你来定位,告诉大模型Bug的位置,然后让它给你修复方案。把定位的任务自己做,修复的部分交给AI。
给开发者的3条实操建议
在实际的Flutter项目或者客户端项目中,老刘有几点不成熟的小建议:
拆分需求:
如果你有开发能力,把需求拆得越细,AI开发的效果越好。
比如开发一个商品详情页,拆分成UI和业务逻辑。
UI再拆分出商品描述、用户评价、购买按钮。
每个部分都用单独的上下文让AI开发。
业务逻辑和服务端的每一次交互,也用单独的上下文。
这样不仅省Token,最重要的是可靠,
能非常有效地防止模型幻觉让整个项目跑偏。
及时叫停:
现阶段的大模型不擅长解决需要严密逻辑推理的问题。
如果AI发现一个方案失败后,开始频繁切换方案、反复试错,你就应该立刻停止它。
通过烧Token撞大运来解决问题,概率并不高。
这时候有效的做法是尝试把问题拆小。比如前面说的把一个复杂的需求拆分成多个小的需求。每个小的需求用单独的上下文让AI开发。
如果是Bug,则可以尽可能增加日志打印,然后通过日志帮你自己,或者帮助模型缩小问题范围。
顶级模型兜底:
企业开发者有能力自己完成开发工作,AI可以帮他们提升效率,但是如果AI搞不定,他们也能自己上场完成。
或者由人来提供思路和方案,再交给AI执行。
但很多独立开发者不具备相关领域的开发能力,碰到解决不了的问题没法自己下场。这时候,一定要有顶级大模型和顶级AI开发工具配合兜底,比如Claude Code加上Claude 4.7 Opus,或者Codex加上GPT 5.5。
日常开发中碰到这种情况的概率并不高,但是老刘还是建议大家购买一定的顶级大模型的额度,以备不时之需。
总结
跑分没输过,实战没赢过,这恐怕是现阶段不少大模型宣发时的通病。
对咱们天天跟业务代码打交道的开发者来说,真不用太把评测榜单上的几分当回事。真正在工程里摸爬滚打过,你就会发现,稳定、听话、别偷偷加戏才是真正的刚需。
现阶段用AI开发,写新功能效率确实能起飞,但前提是你得把需求拆得足够细。
至于修Bug这种纯靠严密逻辑推理的活儿,还得指望咱们自己的基本功去精准定位,然后让AI去当个无情的打字机。
本质上,现代大模型仍然没有脱离概率预测的底层逻辑。让AI去做Bug精准定位这种没有任何容错空间的任务,还是有点难为它了。
最后,结合老刘自己在Flutter项目中的真实体感和我们复杂的网络环境,我觉得模型选择可以把开发新需求作为核心目标。
如果有能力对任务进行拆分,可以选择成本更低的国产模型。
如果没有自主开发能力,就一定要有顶级大模型兜底。
大家最近在实战里,用得最顺手的是哪个大模型?有没有遇到过被AI瞎改代码坑了的经历?欢迎在评论区留言吐槽。
🤝 如果看到这里的同学对客户端或者Flutter开发感兴趣,欢迎联系老刘,我们互相学习。
🎁 私信免费领老刘整理的《Flutter开发手册》,覆盖90%应用开发场景。可以作为Flutter学习的知识地图。
💬 : laoliu_dev
📂 老刘也把自己历史文章整理在GitHub仓库里,方便大家查阅。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)