LangChain嵌入模型与向量数据库实战
·
接着上一篇的内容,今天主要说明的是嵌入模型、向量数据库以及检索器的内容。
1、文档嵌入模型 Text Embedding Models
1.1 句子的向量化(embed_query)
from langchain_openai import OpenAIEmbeddings
import os
import dotenv
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 初始化嵌入模型
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
#embeddings_model = OpenAIEmbeddings(model="text-embedding-3-large")
text = "How are you?"
embed_query = embeddings_model.embed_query(text = text)
print(len(embed_query)) #1536
print(embed_query)
1.2 文档的向量化(embed_documents)
对于文档的向量化,他接收的参数是字符串数组
示例1:
from langchain_openai import OpenAIEmbeddings
import numpy as np
import pandas as pd
import os
import dotenv
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 初始化嵌入模型
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 待嵌入的文本列表
texts =[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!" ]
# 生成嵌入向量
embeddings = embeddings_model.embed_documents(texts)
for i in range(len(texts)):
print(f"{texts[i]}:{embeddings[i][:3]}",end="\n\n")
示例2:
from langchain_community.document_loaders import CSVLoader
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(
model="text-embedding-3-large",
)
loader = CSVLoader("./asset/load/03-load.csv", encoding="utf-8")
docs = loader.load_and_split()
#print(len(docs))
# 存放的是每一个chunk的embedding。
embeded_docs = embeddings_model.embed_documents([doc.page_content for doc in docs])
print(len(embeded_docs))
# 表示的是每一个chunk的embedding的维度
print(len(embeded_docs[0]))
print(embeded_docs[0][:10])
2、向量数据库的使用
2.1 常用的向量数据库
| 向量数据库 | 描述 |
|---|---|
| Chroma | 开源、免费的嵌入式数据库 |
| FAISS | Meta出品,开源、免费,Facebook AI相似性搜索服务 |
| Milvus | 用于存储、索引和管理由深度神经网络和其他ML模型产生的大量嵌入向量的数据库 |
| Pinecone | 具有广泛功能的向量数据库 |
| Redis | 基于Redis的检索器 |
2.2 数据的存储
示例1:从TXT文件中加载数据,向量化后存入Chroma数据库
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
import os
import dotenv
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 1、创建一个TextLoader的实例,并将指定的文档加载
loader = TextLoader(
file_path = "./asset/load/09-ai1.txt",
encoding="utf-8"
)
docs = loader.load() # List[Document]
# 2、创建文本拆分器并拆分文档
text_split = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100
)
splitter_docs = text_split.split_documents(docs)
# 3、创建嵌入模型
embedding_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 4、将文档及嵌入模型传入到Chroma相关结构,进行数据存储
db = Chroma.from_documents(
documents=splitter_docs,
embedding=embedding_model,
)在上述代码的额第4步中,我们没有显式的指明存储位置的话,则将当前数据存储在内存,并且进行缓存。如果要指明具体的存储位置,需要设置参数persist_directory的值。如下所示:
db = Chroma.from_documents(
documents=splitter_docs,
embedding=embedding_model,
persist_directory = "./asset/chroma-1"
)当我们将向量存储到了向量数据库中时与此同时还存储了数据本身。
检索测试:
query = "人工智能的核心技术有哪些?"
docs = db.similarity_search(query)
print(docs[0].page_content)
2.3 数据的检索
示例:包含构建Chroma向量数据库以及向量检索的代码
# 1.导入相关依赖
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
# 2.定义文档
raw_documents = [
Document(
page_content="葡萄是一种常见的水果,属于葡萄科葡萄属植物。它的果实呈圆形或椭圆形,颜色有绿色、紫色、红色等多种。葡萄富含维生素C和抗氧化物质,可以直接食用或酿造成葡萄酒。",
metadata={"source": "水果", "type": "植物"}
),
Document(
page_content="白菜是十字花科蔬菜,原产于中国北方。它的叶片层层包裹形成紧密的球状,口感清脆微甜。白菜富含膳食纤维和维生素K,常用于制作泡菜、炒菜或煮汤。",
metadata={"source": "蔬菜", "type": "植物"}
),
Document(
page_content="狗是人类最早驯化的动物之一,属于犬科。它们具有高度社会性,能理解人类情绪,常被用作宠物、导盲犬或警犬。不同品种的狗在体型、毛色和性格上有很大差异。",
metadata={"source": "动物", "type": "哺乳动物"}
),
Document(
page_content="猫是小型肉食性哺乳动物,性格独立但也能与人类建立亲密关系。它们夜视能力极强,擅长捕猎老鼠。家猫的品种包括波斯猫、暹罗猫等,毛色和花纹多样。",
metadata={"source": "动物", "type": "哺乳动物"}
),
Document(
page_content="人类是地球上最具智慧的生物,属于灵长目人科。现代人类(智人)拥有高度发达的大脑,创造了语言、工具和文明。人类的平均寿命约70-80年,分布在全球各地。",
metadata={"source": "生物", "type": "灵长类"}
),
Document(
page_content="太阳是太阳系的中心恒星,直径约139万公里,主要由氢和氦组成。它通过核聚变反应产生能量,为地球提供光和热。太阳活动周期约为11年,会影响地球气候。",
metadata={"source": "天文", "type": "恒星"}
),
Document(
page_content="长城是中国古代的军事防御工程,总长度超过2万公里。它始建于春秋战国时期,秦朝连接各段,明朝大规模重修。长城是世界文化遗产和人类建筑奇迹。",
metadata={"source": "历史", "type": "建筑"}
),
Document(
page_content="量子力学是研究微观粒子运动规律的物理学分支。它提出了波粒二象性、测不准原理等概念,彻底改变了人类对物质世界的认知。量子计算机正是基于这一理论发展而来。",
metadata={"source": "物理", "type": "科学"}
),
Document(
page_content="《红楼梦》是中国古典文学四大名著之一,作者曹雪芹。小说以贾、史、王、薛四大家族的兴衰为背景,描绘了贾宝玉与林黛玉的爱情悲剧,反映了封建社会的种种矛盾。",
metadata={"source": "文学", "type": "小说"}
),
Document(
page_content="新冠病毒(SARS-CoV-2)是一种可引起呼吸道疾病的冠状病毒。它通过飞沫传播,主要症状包括发热、咳嗽、乏力。疫苗和戴口罩是有效的预防措施。",
metadata={"source": "医学", "type": "病毒"}
)
]
# 3. 创建嵌入模型
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
# 4.创建向量数据库
db = Chroma.from_documents(
documents=raw_documents,
embedding=embedding,
persist_directory="./asset/chroma-3",
)有了基于raw_documents的向量数据库后现在进行检索:
2.3.1 相似性检索(similarity_search)
# 5. 检索示例(返回前3个最相关结果)
query = "哺乳动物"
docs = db.similarity_search(query, k=3) # k=3表示返回3个最相关文档
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
2.3.2 支持直接对问题向量查询(similarity_search_by_vector)
query = "哺乳动物"
embedding_vector = embedding.embed_query(query) # 将查询转换为嵌入向量
docs = db.similarity_search_by_vector(embedding_vector, k=3)
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
2.3.3 相似性检索,支持过滤元数据
query = "哺乳动物"
docs = db.similarity_search(
query=query,
k=3,
filter={"source": "动物"}
)
print(f"查询:'{query}'中的动物:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")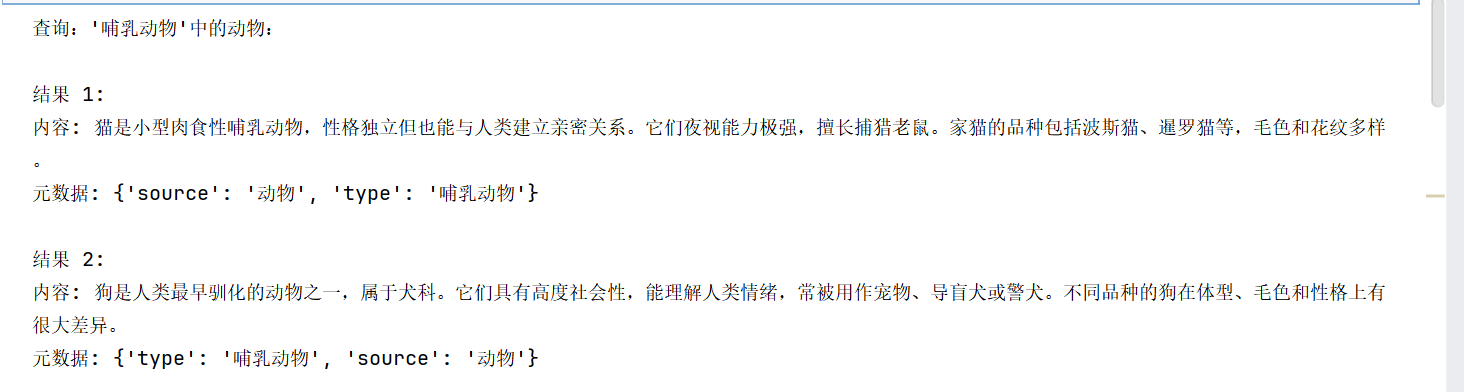
由于有filter过滤元数据,因此结果中只有元数据为动物的结果。
2.3.4 通过L2距离分数进行搜索(similarity_search_with_score)
距离分数值越小,检索到的文档与问题越相似。取值范围:[0,正无穷]
docs = db.similarity_search_with_score(
"量子力学是什么?"
)
for doc, score in docs:
print(f" [L2距离得分={score:.3f}] {doc.page_content} [{doc.metadata}]")
2.3.5 通过余弦相似度分数进行搜索(_similarity_search_with_relevance_scores)
分数值越接近于1,检索到的文档与问题越相似
docs = db._similarity_search_with_relevance_scores(
"量子力学是什么?"
)
for doc, score in docs:
print(f"✅️ [余弦相似度得分={score:.3f}] {doc.page_content} [{doc.metadata}]")
2.3.6 MMR(最大边际相关性)max_marginal_relevance_search
这是一种平衡相关性与多样性的检索策略,可以避免返回高度相似的冗余结果
参数范围0-1:(0:多样性 1:相关性)
docs = db.max_marginal_relevance_search(
query="量子力学是什么",
lambda_mult=0.8, # 侧重相似性
k = 3
)
print("🔍 关于【量子力学是什么】的搜索结果:")
print("=" * 50)
for i, doc in enumerate(docs):
print(f"\n📖 结果 {i + 1}:")
print(f"📌 内容: {doc.page_content}")
print(f"🏷 标签: {', '.join(f'{k}={v}' for k, v in doc.metadata.items())}")
3、检索器 Retrievers
检索器不需要存储文档,只需要返回文档即可。
检索器的执行步骤:
- 将输入查询转换为向量表示;
- 在向量存储中搜索与查询向量最相似的文档向量(余弦相似度或欧几里得距离等);
- 返回与查询最相关的文档或文本片段,以及他们的相似度得分。
3.1 基础使用
# 1.导入相关依赖
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
import os
import dotenv
dotenv.load_dotenv()
# 2.定义文档加载器
loader = TextLoader(file_path='./asset/load/09-ai1.txt', encoding="utf-8")
# 3.加载文档
documents = loader.load()
# 4.定义文本切割器
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
# 5.切割文档
docs = text_splitter.split_documents(documents)
# 6.定义嵌入模型
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large"
)
# 7.将文档存储到向量数据库中
db = FAISS.from_documents(
documents=docs,
embedding=embeddings,
)
# 8.从向量数据库中得到检索器
retriever = db.as_retriever()
# 9.使用检索器检索
docs = retriever.invoke("深度学习是什么?")
print(len(docs))
# 10.得到结果
for doc in docs:
print(f"⭐{doc}", end="\n" + "*" * 50 + "\n")
3.2 不同的检索策略
# 1.导入相关依赖
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# 2.定义文档
document_1 = Document(
page_content="经济复苏:美国经济正在从疫情中强劲复苏,失业率降至历史低点。!",
)
document_2 = Document(
page_content="基础设施:政府将投资1万亿美元用于修复道路、桥梁和宽带网络。",
)
document_3 = Document(
page_content="气候变化:承诺到2030年将温室气体排放量减少50%。",
)
document_4 = Document(
page_content=" 医疗保健:降低处方药价格,扩大医疗保险覆盖范围。",
)
document_5 = Document(
page_content="教育:提供免费的社区大学教育。。",
)
document_6 = Document(
page_content="科技:增加对半导体产业的投资以减少对外国供应链的依赖。。",
)
document_7 = Document(
page_content="外交政策:继续支持乌克兰对抗俄罗斯的侵略。",
)
document_8 = Document(
page_content="枪支管制:呼吁国会通过更严格的枪支管制法律。",
)
document_9 = Document(
page_content="移民改革:提出全面的移民改革方案。",
)
document_10 = Document(
page_content="社会正义:承诺解决系统性种族歧视问题。",
)
documents = [
document_1,
document_2,
document_3,
document_4,
document_5,
document_6,
document_7,
document_8,
document_9,
document_10,
]
# 3.创建向量存储
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large"
)
# 4.将文档向量化,添加到向量数据库索引中,得到向量数据库对象
db = FAISS.from_documents(documents, embeddings)3.2.1 默认检索器使用相似性策略
# 获取检索器
retriever = db.as_retriever(search_kwargs={"k": 3}) #这里设置返回的文档数
docs = retriever.invoke("经济政策")
for i, doc in enumerate(docs):
print(f"\n结果 {i + 1}:\n{doc.page_content}\n")
3.2.2 分数阈值查询
相似度超过这个值才会被召回
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.1} # 只有相似度大于0.1才会被召回
)
docs = retriever.invoke("经济政策")
for doc in docs:
print(f"📌 内容: {doc.page_content}")
# output:📌 内容: 经济复苏:美国经济正在从疫情中强劲复苏,失业率降至历史低点。!3.2.3 MMR搜索
retriever = db.as_retriever(
search_type="mmr",
search_kwargs={"fetch_k":2}
)
docs = retriever.invoke("经济政策")
print(len(docs))
for doc in docs:
print(f"📌 内容: {doc.page_content}")
3.3 结合大模型使用
示例1:不使用RAG技术
# 情况1:不用RAG给LLM灌输上下文数据
from langchain_openai import ChatOpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 创建大模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 调用
response = llm.invoke("北京有什么著名的建筑?")
print(response.content)
示例2:使用RAG给大模型灌输数据
# 1. 导入所有需要的包
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
import os
import dotenv
dotenv.load_dotenv()
# 2. 创建自定义提示词模板
prompt_template = """请使用以下提供的文本内容来回答问题。仅使用提供的文本信息,如果文本中没有相关信息,请回答"抱歉,提供的文本中没有这个信息"。
文本内容:{context}
问题:{question}
回答:
"
"""
prompt = PromptTemplate.from_template(prompt_template)
# 3. 初始化模型
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0
)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# 4. 加载文档
loader = TextLoader("./asset/load/10-test_doc.txt", encoding='utf-8')
documents = loader.load()
# 5. 分割文档
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
)
texts = text_splitter.split_documents(documents)
#print(f"文档个数:{len(texts)}")
# 6. 创建向量存储
vectorstore = FAISS.from_documents(
documents=texts,
embedding=embedding_model
)
# 7.获取检索器
retriever = vectorstore.as_retriever()
docs = retriever.invoke("北京有什么著名的建筑?")
# 8. 创建Runnable链
chain = prompt | llm
# 9. 提问
result = chain.invoke(input={"question": "北京有什么著名的建筑?", "context": docs})
print("\n回答:", result.content)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)