linux学习进展 mysql索引详解
一、索引基础认知
1. 什么是索引
索引是 MySQL 中一种特殊的数据结构(类似书籍的目录),存储在表空间(.ibd文件)中,用于快速定位数据,避免全表扫描。简单说:无索引→逐行扫全表(慢);有索引→走目录定位(快)。
2. 索引的核心作用
加速查询:千万级数据查询从O(n)降至O(log₂n),3-4 次磁盘 I/O 即可定位。
优化排序 / 分组:索引本身有序,避免ORDER BY/GROUP BY临时表排序。
保证唯一性:主键、唯一索引强制数据不重复。
减少 I/O:索引体积小,优先加载内存,减少磁盘访问。
3. 索引的缺点(必记)
占存储空间:索引是独立数据结构,会额外占用磁盘空间。
降低写入速度:INSERT/UPDATE/DELETE需同步更新索引,写频繁场景需权衡。
维护成本:数据变更频繁时,索引碎片增多,需定期维护。
二、索引底层原理(InnoDB 核心)
1. 主流存储结构:B + 树
InnoDB 默认用B + 树(多路平衡查找树),而非二叉树、哈希表,核心优势适配磁盘存储:
层级低:非叶子节点仅存索引键,千万级数据仅 3 层,查询仅 3 次 I/O。
叶子有序链表:所有数据存叶子节点,双向链表串联,支持高效范围查询(BETWEEN/ORDER BY)。
查询稳定:所有查询落叶子节点,路径固定,优化器成本预估准。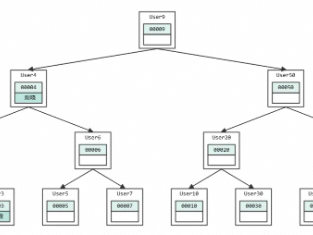
2. 聚簇索引 vs 二级索引(InnoDB 核心)
(1)聚簇索引(Clustered Index)
即主键索引,一张表唯一(无主键时 InnoDB 自动生成隐藏主键)。
叶子存整行数据:索引和数据聚合存储,.ibd文件中数据按主键顺序排列。
查询流程:主键查询→直接定位叶子节点→返回整行数据。
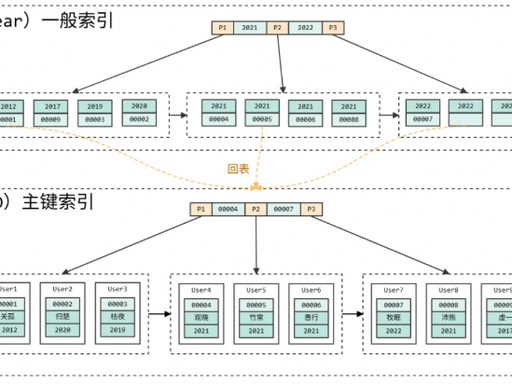
(2)二级索引(Secondary Index)
即普通索引 / 唯一索引 / 联合索引,一张表可多个。
叶子存主键值:不存整行数据,仅存索引列 + 主键,体积小、查询快。
查询流程:二级索引查询→定位叶子节点→拿主键→回表查聚簇索引→返回数据(回表)。
三、索引分类与实操(SQL 示例)
1. 按功能分类(常用)
(1)主键索引(PRIMARY KEY)
特点:唯一 + 非空 + 聚簇,一张表唯一,自动创建 B + 树。
-- 创建表时指定
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引
username VARCHAR(50) NOT NULL
);
-- 已有表添加
ALTER TABLE user ADD PRIMARY KEY (id);(2)唯一索引(UNIQUE)
特点:唯一 + 可空(多列时组合唯一),二级索引,避免重复数据。
-- 直接创建
CREATE UNIQUE INDEX uk_username ON user(username);
-- 创建表时指定
CREATE TABLE user (
id INT PRIMARY KEY,
email VARCHAR(50) UNIQUE -- 唯一索引
);(3)普通索引(INDEX)
特点:最基础索引,无唯一性约束,仅加速查询,二级索引。
-- 直接创建
CREATE INDEX idx_age ON user(age);
-- 修改表添加
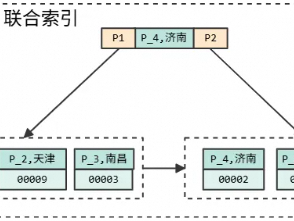
ALTER TABLE user ADD INDEX idx_age (age);(4)联合索引(复合索引)
特点:多列组合索引,遵循最左前缀原则,二级索引。
-- 创建联合索引(age, gender)
CREATE INDEX idx_age_gender ON user(age, gender);- 生效规则(最左前缀):
- ✅
WHERE age=20(匹配最左列) - ✅
WHERE age=20 AND gender=1(全匹配) - ❌
WHERE gender=1(不匹配最左列,索引失效)
- ✅
- 特点:文本内容检索(长文本如文章、评论),InnoDB5.6.4 + 支持,不支持中文分词(需插件)。
-
(5)全文索引(FULLTEXT)
-- 创建全文索引(content列)
CREATE FULLTEXT INDEX idx_content ON article(content);
-- 查询
SELECT * FROM article WHERE MATCH(content) AGAINST('linux');2. 按数据结构分类
- B + 树索引:默认,支持等值 / 范围 / 排序,90% 场景首选。
- 哈希索引:仅 Memory 引擎支持,等值查询极快,不支持范围 / 排序,易哈希冲突。
- 全文索引:如上,文本检索专用。
3. 索引管理实操
-- 1. 查看索引
SHOW INDEX FROM user;
-- 2. 删除索引
DROP INDEX idx_age ON user;
ALTER TABLE user DROP INDEX idx_age;
-- 3. 查看索引使用情况(优化用)
SHOW STATUS LIKE 'Handler_read%';四、索引优化核心(避坑 + 提速)
1. 索引设计黄金法则
选择性优先:选择性 = 唯一值数 / 总行数,>0.1 才建索引(如性别选择性 0.5,低,不建议;用户 ID 选择性 1,高,必建)。
联合索引遵循最左前缀:高频查询列放左边,避免中间断列。
覆盖索引优先:查询字段全在索引中,避免回表(如SELECT age FROM user WHERE age=20,索引含 age 即可)。
前缀索引优化长文本:URL / 长字符串取前 20-50 字符建索引,减少空间,保持选择性。
避免过度索引:索引多→写慢,只建高频查询索引。
2. 索引失效场景(高频坑)
模糊查询左通配:LIKE '%linux'/LIKE '%linux%'(索引无序,全表扫);✅ LIKE 'linux%'(生效)。
字段类型隐式转换:WHERE username=123(字符串 vs 数字,索引失效);✅ WHERE username='123'。
OR 无索引:WHERE age=20 OR gender=1(两列无索引,失效);✅ 两列都建索引或用UNION。
NOT/<>/IS NULL:WHERE age<>20/WHERE name IS NULL(范围大,优化器选全表扫)。
联合索引不满足最左:WHERE gender=1(无 age 条件,失效)。
3. 进阶优化:索引下推(ICP)
- MySQL5.6 + 特性:遍历索引时过滤索引字段条件,减少回表次数。
- 示例:联合索引
(age, name),查询WHERE age>20 AND name LIKE 'li%',直接在索引过滤 name,不回表。
五、Linux 下索引实操与维护
1. 查看索引磁盘占用(Linux 命令)
# 进入MySQL数据目录(默认/var/lib/mysql/数据库名)
cd /var/lib/mysql/linux_net
# 查看表空间文件大小(.ibd含索引+数据)
ls -lh user.ibd2. 索引碎片整理(定期维护)
-- 整理user表碎片(InnoDB)
ALTER TABLE user ENGINE=InnoDB;
-- 查看碎片情况
SHOW TABLE STATUS LIKE 'user'\G3. 慢查询日志定位低效索引
# 开启慢查询(/etc/mysql/mysql.conf.d/mysqld.cnf)
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2 # 超过2秒为慢查询
# 重启MySQL生效
sudo systemctl restart mysql
# 查看慢日志,定位无索引/索引失效SQL
tail -f /var/log/mysql/slow.log六、总结与实践建议
- 核心本质:索引是 B + 树结构(InnoDB),聚簇索引存数据,二级索引存主键,查询优先走索引减少 I/O。
- 分类选型:主键必建,高频查询建普通 / 联合索引,长文本用前缀索引,文本检索用全文索引。
- 优化关键:遵循最左前缀、避免失效场景、优先覆盖索引、定期维护碎片。
- 实践建议:Linux 环境下,开发阶段用
EXPLAIN分析 SQL(EXPLAIN SELECT * FROM user WHERE age=20),上线前开启慢查询日志,持续优化索引。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)