【创意写作】WritingBench: A Comprehensive Benchmark for Generative Writing
paper: https://arxiv.org/abs/2503.05244
github: https://github.com/X-PLUG/WritingBench
简介
本文提出WritingBench,是面向大语言模型生成式写作的综合评测基准,覆盖6 大核心领域、100 个子领域共1000 条查询(中445/英555),创新采用查询依赖式评估框架,搭配微调的评判模型实现84% 人类对齐率,并通过该框架筛选高质量写作数据训练小模型(Qwen2.5-7B),使其写作能力超越GPT-4o,同时开源基准、评估工具与框架组件以推动 LLM 写作能力研究。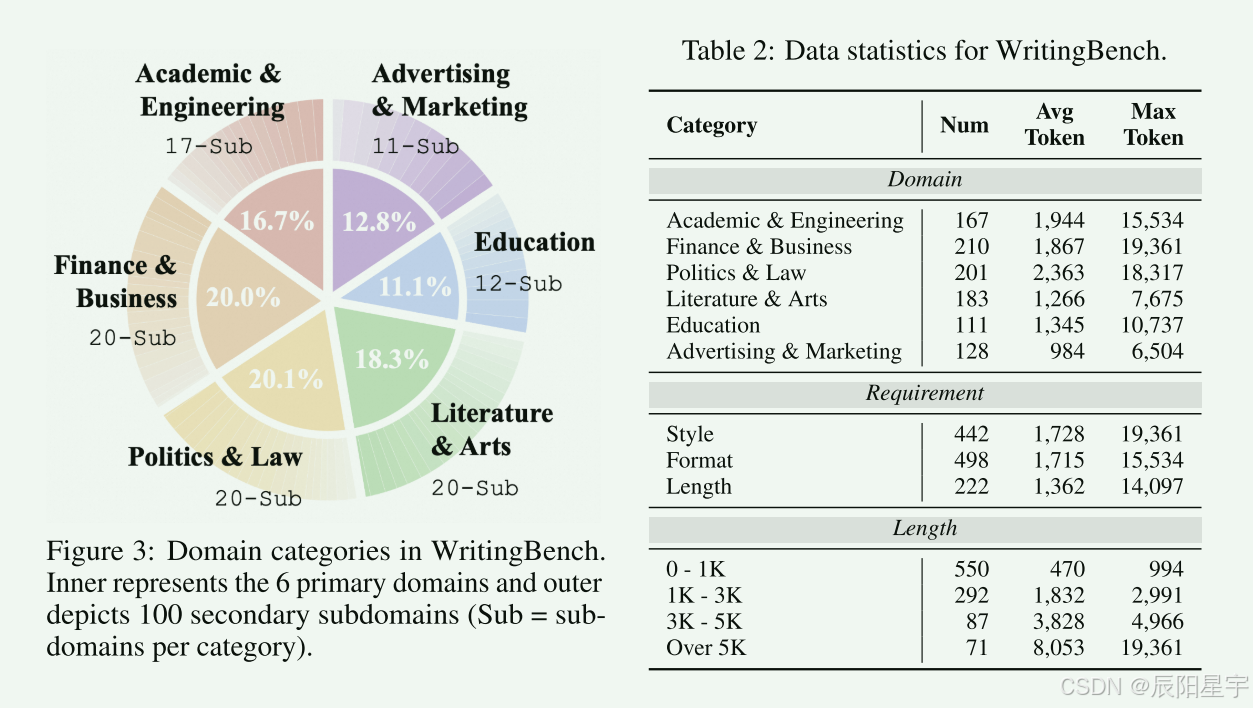
研究背景与问题
现有大模型写作评测基准存在两大核心缺陷:
- 任务范围局限:仅覆盖单一领域、指令模板简单,无法适配真实写作的复杂定制需求;
- 评估指标僵化:依赖固定通用标准,无法评估创意、论证、领域适配性等多维写作能力。
WritingBench 基准构建
领域体系采用两层分类,覆盖6 大主领域、100 个子领域,贴合真实写作场景: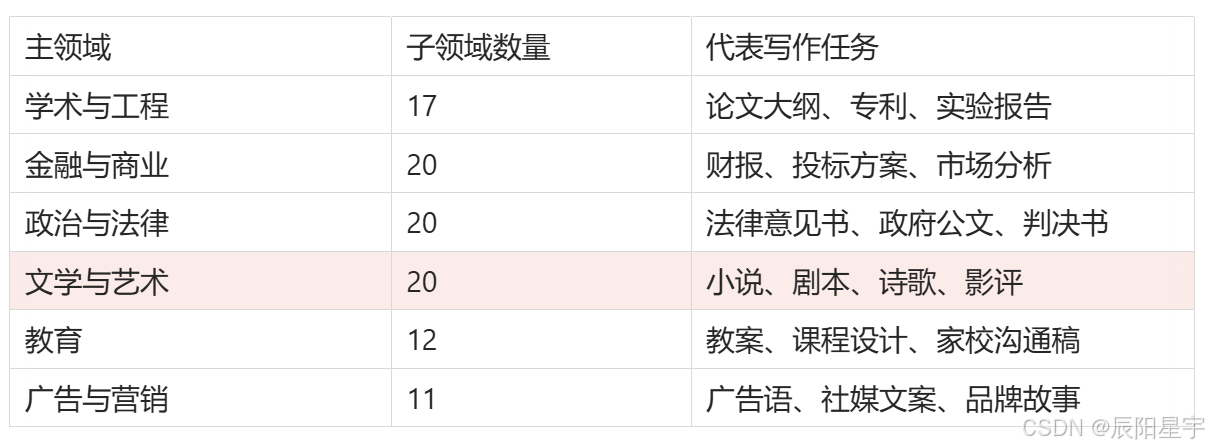

四阶段构建流程
模型辅助初始查询生成:用 GPT-4o、Claude-3.5-Sonnet 生成初稿;
- 查询多样化:
- 添加核心要求:风格、格式、长度
- 辅助维度:个性化、内容特异性、表达
- 人工闭环精炼:30 名标注员收集材料,5 名专家优化去噪;
- 最终数据:1000 条查询(中文 445 条、英文 555 条),输入 token 跨度数十至数万。
需求分布
- 风格要求:442 条;格式要求:498 条;长度要求:222 条;
- 输出长度:0-1K 词(550 条)、1K-3K 词(292 条)、3K-5K 词(87 条)、5K 词以上(71 条)。
查询依赖式评估框架
- 核心设计摒弃静态标准,由 LLM动态为每条查询生成 5 条专属评估标准,包含名称、描述、分级评分规则。
- 评判模型基于Qwen-2.5-7B-Instruct微调,训练数据15.5 万条,实现 1-10 分精准评分与理由生成。
- 人类对齐效果表格评估方式评判模型对齐率静态全局标准GPT-4o69%静态领域标准GPT-4o40%动态查询依赖GPT-4o79%动态查询依赖本文评判模型84%
模型实验与结论
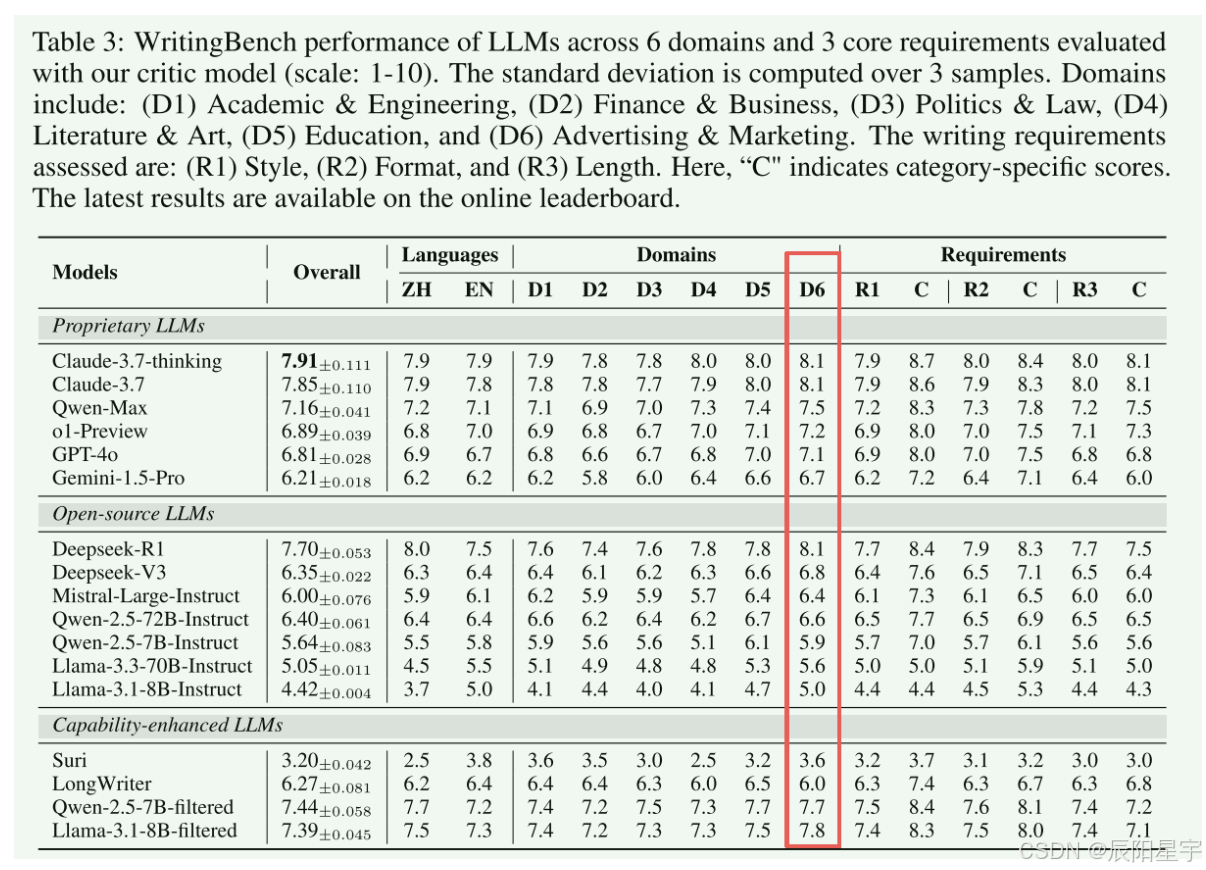
- 模型评测结果评测 17 款主流 LLM,Claude-3.7-thinking 以 7.91 分位居第一,开源模型中 Deepseek-R1(7.70 分)表现最优;学术 / 金融领域难度最高,教育 / 营销领域模型表现更好。
- 数据筛选与小模型增强用评估框架筛选12K 高质量数据,微调 Qwen-2.5-7B、Llama-3.1-8B:
- Qwen-2.5-7B-filtered:7.44 分,超越 Llama-3.3-70B、Qwen-2.5-72B 等大模型;
- Llama-3.1-8B-filtered:7.39 分,写作能力超越 GPT-4o。
- 关键发现
- CoT 推理显著提升文学艺术等创意领域写作效果;
- 模型普遍在长度约束上表现最差,长文本生成能力不足。Claude-3.7和Qwen-Max长文扩真能力优秀。
- 跨语言模型存在中英文性能不一致问题。
研究贡献与局限
- 核心贡献
- 构建覆盖 6 大领域、100 子领域的1000 条写作评测基准;
- 提出查询依赖式动态评估框架,人类对齐率达84%;
- 验证框架可高效筛选高质量数据,让小模型写作能力超越大模型;
- 开源基准、评估工具、评判模型与增强模型。
- 主要局限
- 仅用 SFT 训练,未探索更优优化策略;
- 复杂长度约束评估精度不足;
- 人工标注存在主观偏好偏差。
关键问题与答案
问题 1:WritingBench 相比现有写作评测基准的核心优势是什么?
答案:核心优势有三点,一是领域覆盖更广,包含 6 大主领域、100 个子领域共 1000 条查询,远超单一领域基准;二是需求更贴合真实场景,集成风格、格式、长度等多维约束,支持数十至数万 token 的长上下文输入;三是评估更精准,采用查询依赖式动态标准,人类对齐率达 84%,显著优于静态标准。
问题 2:WritingBench 的查询依赖式评估框架是如何运作的?
答案:框架分两阶段运行,第一阶段动态标准生成,由 Claude-3.7 为每条写作查询自动生成 5 条专属评估标准,包含名称、描述与 1-10 分分级规则;第二阶段评分执行,用基于 Qwen-2.5-7B 微调的评判模型,依据标准对生成内容打分并给出理由,最终取 5 条标准平均分作为总分。
问题 3:如何通过 WritingBench 框架提升小模型的写作能力?
答案:先利用框架的数据筛选能力,用评估框架对生成的写作数据打分,选取每个子领域前 50% 的高质量样本(12K 条);再用这些高质量数据微调 Qwen-2.5-7B、Llama-3.1-8B 等小模型,最终微调后的小模型写作得分大幅提升,甚至超越 GPT-4o、Llama-3.3-70B 等更大参数模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)