Scaling and evaluating sparse autoencoders

OpenAI的SAE,奠基之作。
摘要
稀疏自编码器是一种极具潜力的无监督方法,它通过稀疏瓶颈层重构模型激活值,从而从语言模型中提取可解释特征。由于语言模型会习得海量语义概念,自编码器必须具备超大容量,才能完整还原所有相关特征。
然而,受两大因素制约,稀疏自编码器的规模缩放特性研究一直存在难点:一是需要在重构损失与稀疏性两个优化目标之间做权衡;二是模型中普遍存在死亡隐单元问题。本文引入k - 稀疏自编码器(Makhzani & Frey, 2013),可对稀疏度进行直接控制,既简化了调参难度,又提升了重构效果与稀疏性之间的最优权衡边界。此外,我们提出了若干结构改进方案,即便在实验采用的最大模型规模下,也能大幅减少死亡隐单元的数量。基于上述方法,我们得出了自编码器规模与稀疏度之间清晰的缩放规律。本文还提出多项全新的特征质量评估指标,从假设特征还原能力、激活模式可解释性、下游任务影响稀疏度三个维度开展评测。实验表明,这些评估指标整体表现均会随自编码器规模增大而稳步提升。
为验证本方法的可扩展性,我们基于400 亿 Token 的 GPT-4 模型激活数据,训练了一个拥有1600 万隐单元维度的超大稀疏自编码器。我们已开源适配开源模型的训练代码、预训练稀疏自编码器模型,同时发布了配套可视化工具。
介绍
稀疏自编码器(SAE)在挖掘大语言模型内部特征(Cunningham 等,2023;Bricken 等,2023;Templeton 等,2024;Goh,2016)与神经网络回路(Marks 等,2024)方面展现出巨大潜力。然而,由于其极强的稀疏性约束,这类模型训练难度较高,因此现有工作大多聚焦于在小规模语言模型上训练尺寸较小的稀疏自编码器。
本文提出一套顶尖水准的训练方案,可在任意语言模型的激活值上,稳定训练超宽维度、高稀疏性的自编码器,并将死亡隐单元数量控制在极低水平。我们系统探究了自编码器在稀疏度、模型规模、基座语言模型尺寸三个维度上的缩放规律。为验证方案的可扩展性,我们基于 GPT-4(OpenAI,2023)的残差流激活值,训练了一个包含1600 万隐单元的超大稀疏自编码器。
由于提升重构精度与稀疏性并非稀疏自编码器的最终目标,我们还探索了更有效的自编码器质量量化方法,重点衡量以下指标:
- 能否成功复现预设的假设特征
- 下游任务影响是否具备稀疏性
- 模型特征能否以高精确率与高召回率被解释
本文贡献:
- 在第 2 节中,提出一套顶尖的稀疏自编码器训练方法与流程。
- 在第 3 节中,验证了清晰的缩放定律,并将模型扩展至极大隐单元规模。
- 在第 4 节中,提出隐单元质量评估指标,实验表明:在该指标体系下,更大的稀疏自编码器通常表现更优。
我们开源了训练代码、全套 GPT-2 small 自编码器模型,以及适用于 GPT-2 small 与 1600 万隐单元 GPT-4 稀疏自编码器的特征可视化工具。
方法
2.1 实验设置 *
*输入数据**:我们在 GPT-2 small(Radford 等,2019)以及一系列与 GPT-4 共享架构和训练设置的不同规模模型(包含 GPT-4 本身,OpenAI,2023)的**残差流**上训练自编码器。 我们选取网络**靠后位置的层**,这类层包含丰富特征,且不会过度 specialize 于下一个词预测任务(详见附录 F.1)。
具体而言,GPT-4 系列模型选用整体网络 5/6 深度处的层,GPT-2 small 选用第 8 层(整体 3/4 深度处)。所有实验的上下文长度均为 64 个 token。 在输入自编码器前(或计算重构误差前),我们对所有输入减去模型维度 上的均值,并归一化至单位范数。
**评估指标**:训练完成后,我们从稀疏性 \(L_0\) 与重构均方误差(MSE)两方面评估自编码器。所有 MSE 均采用**归一化形式**,即除以“始终预测均值激活”这一基准的重构误差。 **超参数**:为简化分析,除非特别说明,否则不使用学习率预热与衰减。我们在小规模上扫参学习率,并外推得到大规模下的最优学习率趋势。其他优化细节见附录 A。
2.2 基线:ReLU 自编码器 对于来自残差流、维度为 的输入向量 x,以及n个隐层维度,我们采用 Bricken 等(2023)提出的基线 ReLU 自编码器。编码器与解码器定义如下:
其中。 训练损失定义为:
其中
为重构 MSE,
为促进隐层激活稀疏性的 \(L_1\) 正则项,
为需调优的超参数。
2.3 TopK 激活函数 我们采用 **k-稀疏自编码器**(Makhzani & Frey,2013),通过仅保留前 \(k\) 个最大激活、其余置零的 TopK 激活函数,**直接控制活跃隐单元数量**。编码器定义为: 解码器保持不变。训练损失仅保留重构损失:
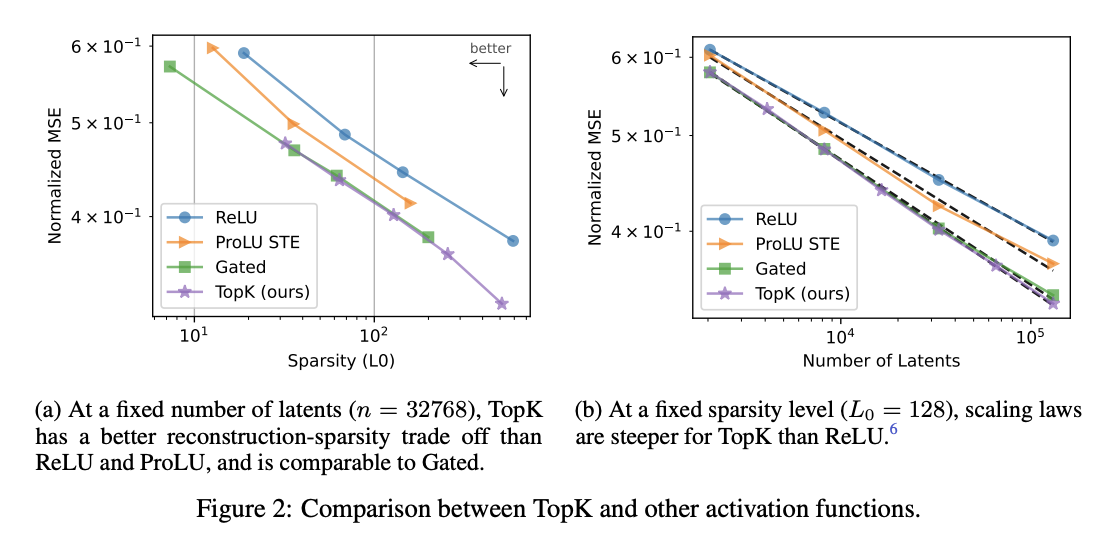
使用 k-稀疏自编码器的优势: - 无需 \(L_1\) 正则。\(L_1\) 是 \(L_0\) 的不完美近似,会引入将所有正激活向零收缩的偏差(见 5.1 节)。 - 可直接设定 \(L_0\),无需调节 \(L_1\) 系数 \(\lambda\),简化模型对比与快速迭代。可与任意激活函数搭配使用。 - 在稀疏性-重构权衡曲线上,效果显著优于基线 ReLU 自编码器(图 2a),且差距随模型规模扩大而增大(图 2b)。
- 通过将小激活有效置零,提升随机激活样本的**单语义性(monosemanticity)**(见 4.3 节)。 --2.4 死亡隐单元抑制 死亡隐单元是自编码器训练的另一核心难题。在更大规模的自编码器中,越来越多的隐单元会在训练中途完全停止激活。例如,Templeton 等(2024)训练的 3400 万隐单元自编码器仅有 1200 万存活单元;而在我们的消融实验中,无抑制策略时死亡隐单元占比可达 **90%**(图 15)。这会显著恶化 MSE,并造成计算资源浪费。 我们发现两种抑制死亡隐单元的关键手段: 1. 将编码器**初始化为解码器权重的转置** 2. 使用**辅助损失**,利用前 \(k_{\text{aux}}\) 个死亡隐单元建模重构误差(详见附录 A.2) 采用上述策略后,即使在最大规模(1600 万隐单元)的自编码器中,死亡隐单元占比也仅为 **7%**。
缩放定律
3.1 隐单元数量 由于 GPT-4 等前沿模型具备广泛的能力,我们推测:**想要忠实地表示模型状态,需要大量的稀疏特征**。我们采用两种主要方法来设定自编码器规模与令牌预算:
3.1.1 面向计算量-MSE前沿的训练(L(C)) 首先,参照 Lindsey 等(2024)的做法,在给定计算资源下,将自编码器训练至最优 MSE,不考虑是否完全收敛。该方法最初用于语言模型预训练(Kaplan 等,2020;Hoffmann 等,2022)。我们发现 MSE 随计算量呈现幂律关系 L(C),尽管最小模型会偏离该趋势(图 1)。
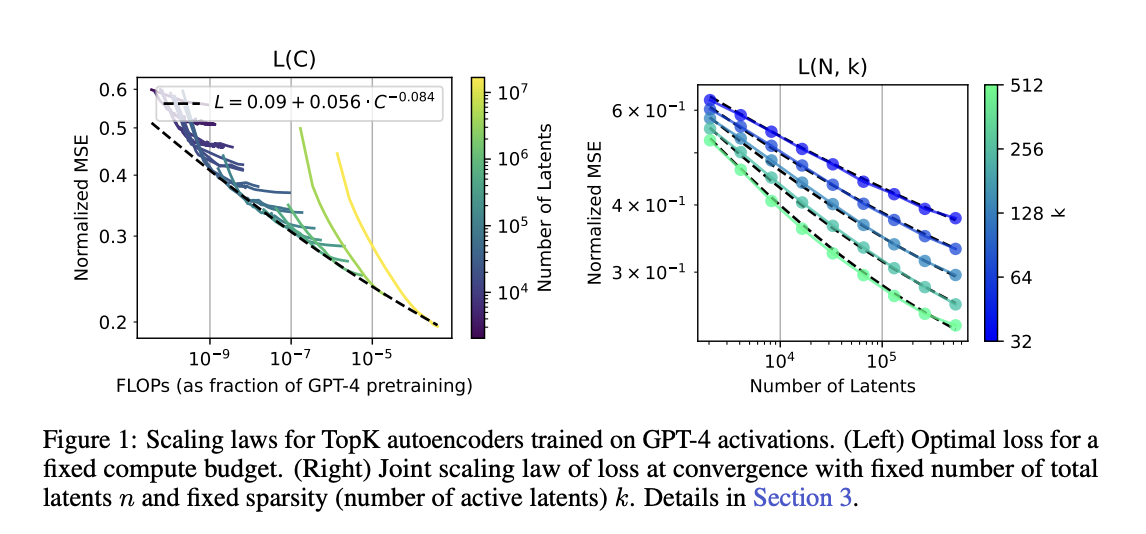
然而,隐单元才是训练的核心产物(而非重构预测),而语言模型通常只关注令牌预测。因此,直接比较不同 n 下的 MSE 并不公平——n 越大,隐单元构成的信息瓶颈越宽松,更容易获得更低的 MSE。所以该方法对于自编码器训练而言缺乏理论合理性。
3.1.2 收敛训练(L(N)) 我们同时将自编码器**训练至完全收敛**(在某个 ϵ 范围内)。该设置能给出不考虑计算效率时,训练方法可达到的最优重构上限。在实际应用中,理想训练目标介于 L(N) 与 L(C) 之间的令牌预算。 我们发现,能保证收敛的最大学习率随 **1/√n** 缩放(图 3)。
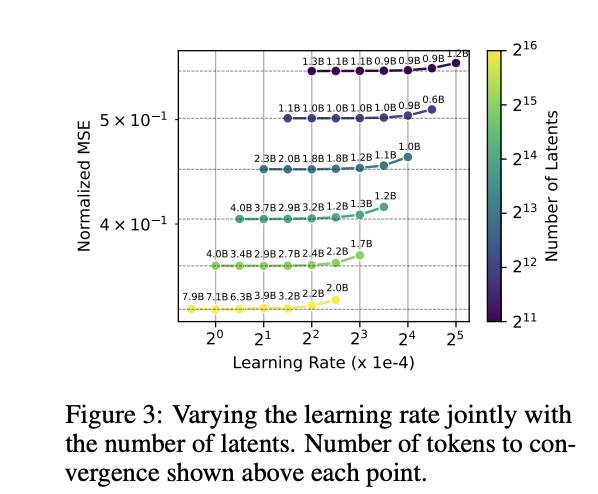
同时,L(N) 的最优学习率约为 L(C) 最优学习率的 1/4。 实验表明,收敛所需令牌数: - GPT-2 small 近似按 Θ(n^0.6) 增长 - GPT-4 近似按 Θ(n^0.65) 增长(图 11) 该规律终将失效——若令牌预算次线性增长,每个隐单元能获得梯度更新的令牌数会趋近于零。
3.1.3 不可约损失 缩放定律有时会包含**不可约损失项 e**,形式为 y = αx^β + e(Henighan 等,2020)。我们发现,加入不可约损失项能显著提升 L(C) 与 L(N) 的拟合质量。 最初我们并不清楚为何存在非零不可约损失。一种可能是激活中包含其他类型结构;极端情况下,激活中的无结构噪声极难建模,会使得指数接近 0(附录 G)。无结构噪声的存在可以解释幂律曲线的弯曲现象。 ### 3.1.4 稀疏度联合拟合(L(N,K)) 我们发现 MSE 随**隐单元数量 n**与**稀疏度 k**呈现**联合缩放定律**(图 1b)。由于当 k 接近模型维度 d_model 时,重构会变得无关紧要,因此该缩放定律仅在小 k 区间成立。 我们在 GPT-4 自编码器上拟合的联合缩放定律为: L(n,k) = exp(α + β_k log(k) + β_n log(n) + γ log(k)log(n)) + exp(ζ + η log(k)) 其中: α = −0.50,β_k = 0.26,β_n = −0.017,γ = −0.042,ζ = −1.32,η = −0.085 可以看出: - γ 为负 → **k 越大,L(N) 的缩放曲线越陡** - η 为负 → **k 越大,不可约损失越小**
3.2 基座模型尺寸 L_s(N) 由于语言模型规模会持续扩大,我们希望探究稀疏自编码器如何随基座模型尺寸缩放。 实验发现:**固定 k 时,更大的基座模型需要更大的自编码器才能达到相同 MSE,且缩放指数更差**(图 4)。
4 评估
我们在第 3 节证明了,更大规模的自编码器在均方误差(MSE)与稀疏性方面表现出良好的缩放特性(另见第 5.2 节的激活函数对比)。然而,自编码器的最终目标并非单纯提升稀疏 - 重构权衡边界(该边界在极限下会趋于退化),而是挖掘对机制可解释性等下游应用有价值的特征。因此,我们采用以下指标评估自编码器质量:
- 下游损失(Downstream loss):将残差流中的隐向量替换为自编码器的重构结果后,语言模型的损失表现如何?(第 4.1 节)
- 探针损失(Probe loss):自编码器能否恢复我们预期存在的特征?(第 4.2 节)
- 可解释性(Explainability):是否存在既必要又充分的简单解释,能说明自编码器隐单元的激活逻辑?(第 4.3 节)
- 消融稀疏性(Ablation sparsity):消融单个隐单元对下游模型输出(logits)的影响是否具有稀疏性?(第 4.5 节)
这些指标共同表明,随着隐单元总数的增加,自编码器的整体表现普遍提升。而活跃隐单元数(L0)的影响则更为复杂:增大 L0 会降低基于 token 模式的解释质量,但会改善探针损失与消融稀疏性。当 L0 接近模型维度 dmodel 时,所有上述趋势都会失效,此时隐单元的激活也会变得非常稠密(详见附录 E.5 的详细讨论)。
4.1 下游损失
存在重构误差的自编码器,可能无法成功建模与模型行为最相关的特征(Braun 等,2024)。为衡量自编码器是否有效建模了语言建模相关特征,我们参照前人工作(Bills 等,2023;Cunningham 等,2023;Bricken 等,2023;Braun 等,2024),采用下游 KL 散度(Kullback-Leibler divergence)与交叉熵损失作为评估指标。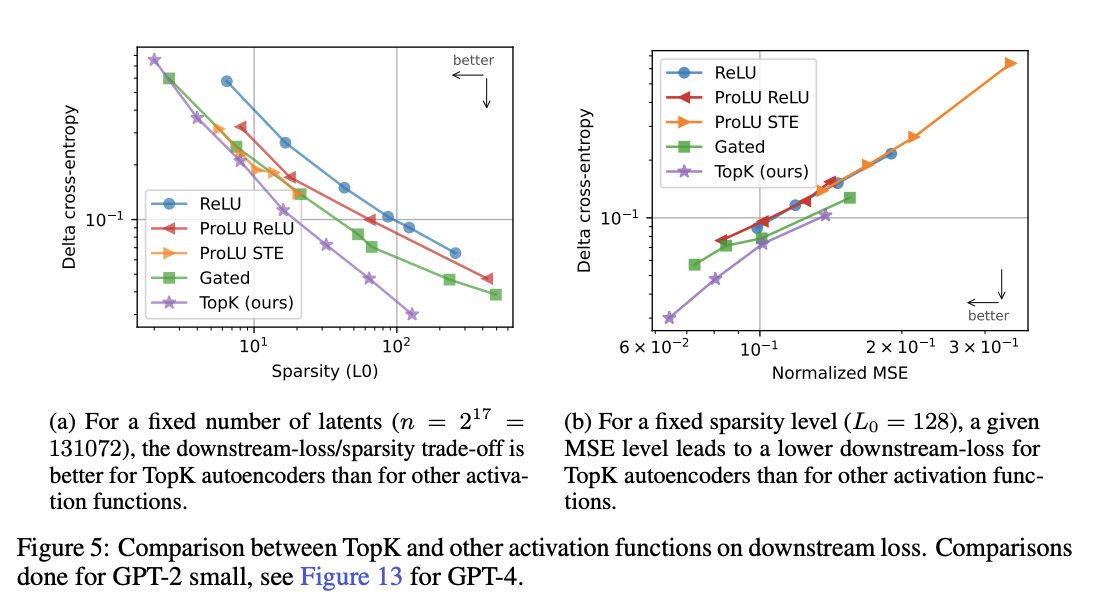
两种指标的测试方式一致:在前向传播过程中,将残差流中的原始激活替换为自编码器的重构结果,观察其对下游预测结果的影响。我们发现,相比传统方法,k - 稀疏自编码器在下游损失上的提升幅度,比其在 MSE 上的提升更为显著(图 5a)。
同时,当保持稀疏度 L0 固定、仅改变自编码器规模时,MSE 与 KL 散度、交叉熵损失差值之间均呈现清晰的幂律关系(图 5b)。需注意的是,尽管在我们训练的自编码器中该趋势稳定,但在测试阶段调整 k 值时,也可能观察到趋势失效的情况(见第 5.3 节)。
此外,直接解读损失数值本身存在困难 —— 我们需要一种绝对意义上的评估方式。此前的研究(Bricken 等,2023;Rajamanoharan 等,2024)常以 “将激活消融至零的损失” 作为基准,计算自编码器从该基准中恢复的损失占比。但由于将残差流消融至零会导致极高的下游损失,这种方法会使得即使解释效果很差的模型,也能获得较高的分数。
因此,我们认为更合理的指标是:计算 “训练一个与自编码器替换后下游损失相当的语言模型,所需的预训练计算量” 的相对比例。例如,当我们将 1600 万隐单元的自编码器替换进 GPT-4 模型时,得到的语言建模损失,仅对应 GPT-4 预训练计算量的 10%。
4.2 利用一维探针恢复已知特征
对每个SAE的隐特征zi都加一个二分类任务,看看哪个的效果最好,哪个酒醉有可能是负责该任务的专属神经元
如果我们预期某个特定特征(如情感倾向、语种识别)能被高质量的自编码器挖掘出来,那么检验这些特征是否存在,就可以作为衡量自编码器质量的一项指标。基于这一思路,我们构建了包含**61个二分类数据集**的评测集合(详情见表1)。
针对每个任务,我们使用**牛顿-拉夫逊法**在每个隐特征上训练一个**一维logistic探针**来预测任务标签,并记录所有隐特征中的最优交叉熵损失。公式如下:
其中 是自编码器第 i个预激活隐特征,y 为二分类标签。 GPT-2 small 上的结果见图6a。
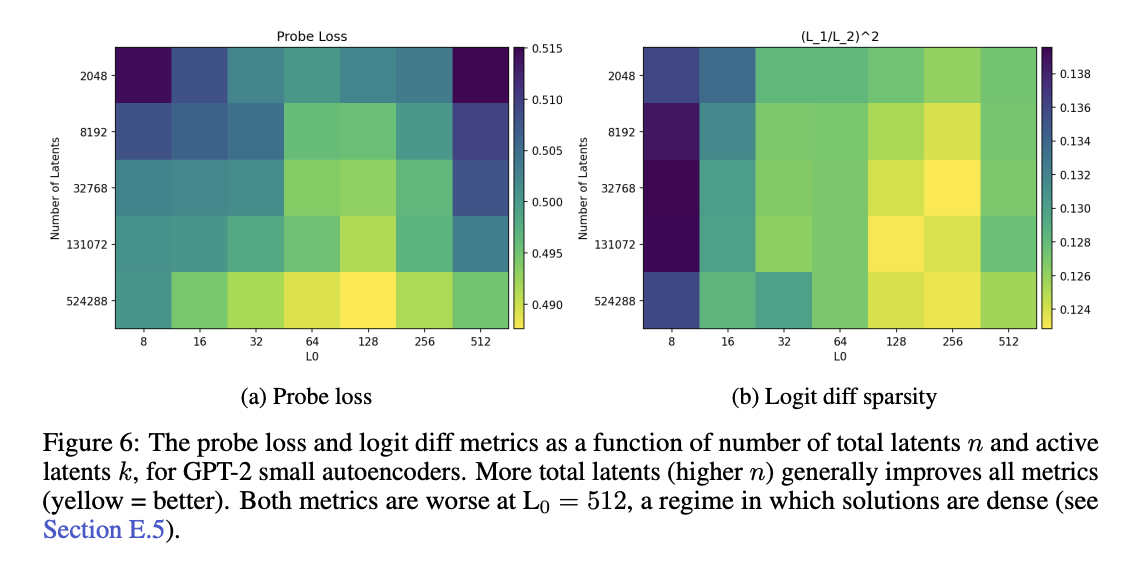 实验发现:**探针分数随 k 增大先升后降**;**TopK 方法的探针效果普遍优于 ReLU**(图23),且两者都远好于直接使用残差流通道。图32展示了多个 GPT-4 自编码器的结果:尽管没有监督信号,该指标仍随训练持续提升,并且超过了直接使用残差流通道的基线。图33为按任务拆分的分数。 该指标的优点是**计算成本低**,但存在明显局限:**强烈依赖“哪些特征是自然特征”的先验假设**
实验发现:**探针分数随 k 增大先升后降**;**TopK 方法的探针效果普遍优于 ReLU**(图23),且两者都远好于直接使用残差流通道。图32展示了多个 GPT-4 自编码器的结果:尽管没有监督信号,该指标仍随训练持续提升,并且超过了直接使用残差流通道的基线。图33为按任务拆分的分数。 该指标的优点是**计算成本低**,但存在明显局限:**强烈依赖“哪些特征是自然特征”的先验假设**
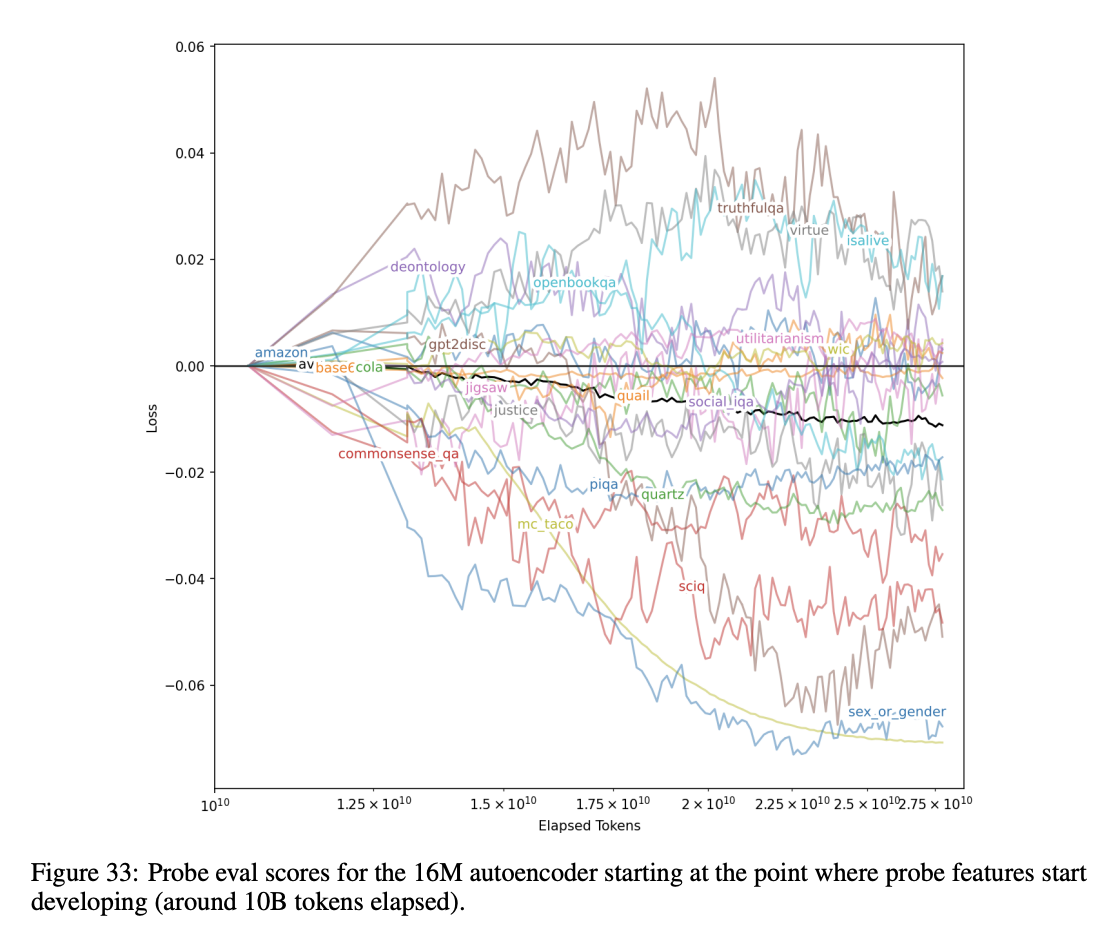
- SAE 的特征学习是 “无监督自发形成” 的:虽然没有任何监督信号,但随着训练推进,探针评估分数整体变好,证明 SAE 确实在从残差流中分解出有意义的语义特征。
- 不同特征的学习难度不同:简单、高频的特征(如性别、情感、常识)更容易被拆解,而复杂、抽象的特征(如道德判断、真实性)则更难被单语义化。
- 训练 token 数对 SAE 质量至关重要:只有训练足够久,SAE 才能把这些特征稳定地拆解出来。
4.3 为特征寻找简洁解释
经验表明,我们的自编码器能学到大量**激活模式清晰、易于解释**的特征(见附录E.1)。但这可能造成**可解释性幻觉**(Bolukbasi et al., 2021):解释过于宽泛,召回率高但精确率极低。例如,Bills等人(2023)提出的自动化可解释性评分就过度依赖召回率:某个特征在“don’t stop / can’t stop”结尾激活,但若解释为“所有包含stop的情况”,也能拿到高分。随着自编码器规模扩大、特征更稀疏更具体,这类问题会更加严重。 然而,像 Bills 等人那样用 GPT-4 做仿真来评估精确率**成本极高**。因此本文先采用改进版**神经元到图(N2G)**方法(Foote et al., 2023):表达能力有限但成本很低,输出带通配符的n-gram集合作为解释。未来我们计划拓展到更通用的英文解释并高效评估精确率。 构建N2G解释的流程:
1. 取能激活该隐特征的若干序列;
2. 对每条序列找到**最短仍能激活的后缀**;
3. 尝试在n-gram任意位置插入通配符(padding);
4. 检查是否与绝对位置相关;
5. 用最多16个非零激活构建图,再用16个计算召回率。
GPT-2 small结果见图25a/25b。
越稀疏的特征越容易被 N2G 解释 总隐单元数更多(n 大)、活跃隐单元数更少(k 小)的 SAE,特征更稀疏、模式更窄,N2G 更容易生成精准的解释。
稠密激活的特征解释难度低,但没意义比如
n=2048, k=512的 SAE,隐单元激活非常稠密,随便给个宽泛的解释就能覆盖大部分情况,但这种解释毫无价值,因为特征本身就不聚焦。TopK 的假阳性更少,解释质量更高在相同规模和稀疏度下,TopK 方法的假阳性激活比 ReLU 更少,N2G 生成的解释:
- 召回率比 ReLU 高 1.5 倍以上
- 精确率只轻微下降(>0.9 倍)
- 整体 F1 分数更高,说明解释更准、更可靠。
注意:**稠密激活模式极易解释**,因此 $n=2048, k=512$ 的隐特征平均解释难度很低(大量隐特征稠密激活,见E.5)。总体而言:**总隐特征更多、激活隐特征更少(更稀疏)**的自编码器最容易用N2G建模。 我们还发现:**相同 $n$、相近 $L_0$ 下,TopK比ReLU的假阳性激活更少**,N2G解释的**召回率提升超1.5倍**,精确率仅轻微下降(>0.9倍),F1更高(图24)。
4.4 解释重构
当我们追求模型激活的可解释性时,一个关键问题是:**如果只使用模型里可解释的部分,会牺牲多少性能?** 下游损失衡量我们保住了多少性能(但特征可能不可解释);基于解释的指标衡量特征是否单语义(但可能无法解释模型主体)。因此我们将两者结合:**用解释来仿真自编码器隐特征,再解码并计算下游损失**。该指标能同时合理衡量精确率与召回率,且对更稠密激活的隐特征更看重召回率。 我们基于N2G解释做了实验:N2G根据前缀树节点输出仿真值,再做缩放以最小化方差偏差,计算 ($s$ 为仿真值,$a$ 为真实值)。
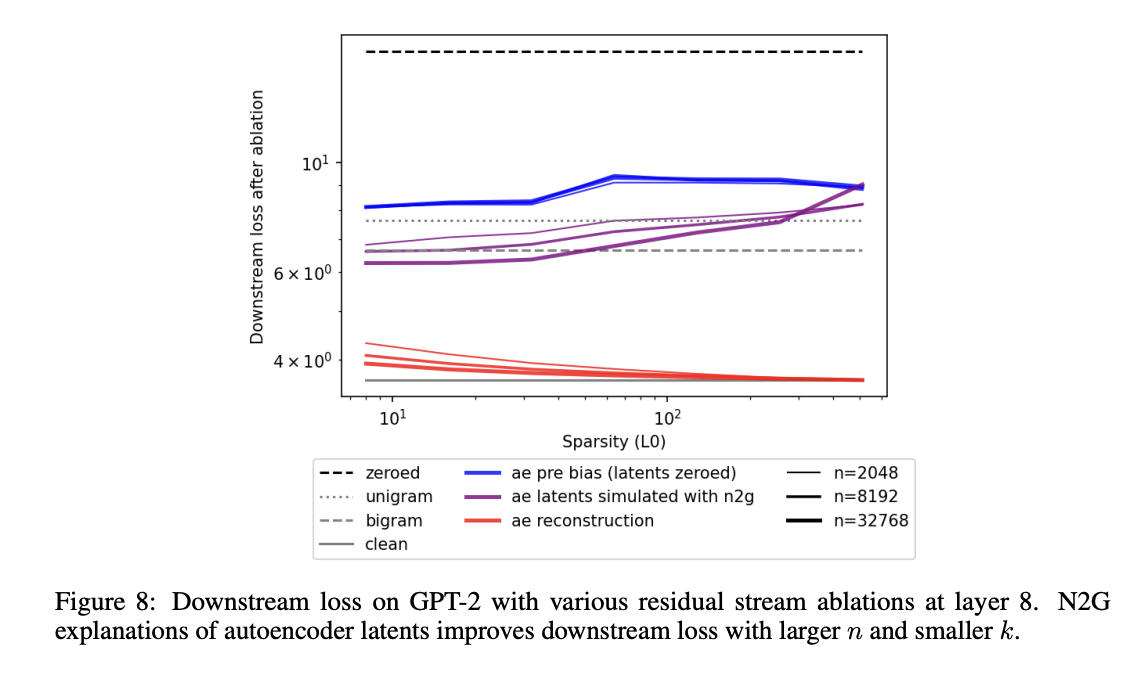
GPT-2结果见图8:相比只解释双词组合,我们能解释更多GPT-2 small行为;**更大、更稀疏的自编码器对应的下游损失更低**。
4.5 消融效应的稀疏性
若语言模型所学习的底层计算具有稀疏性,那么可以提出一个假设:**自然特征不仅在激活值上具备稀疏性,在下游影响上同样具备稀疏性**(Olah 等人,2024)。从实际观测来看,我们发现消融产生的影响通常具备可解释性(详见可视化工具)。 为此,我们设计了一种指标,用于衡量隐单元对输出对数概率(logits)下游影响的稀疏程度。 在某个特定词元位置上,首先获取残差流中的隐单元表征;随后**逐个消融每一个自编码器隐单元**,对比消融前后模型输出的对数概率差异。 每次消融、每个受影响词元都会产生 V 个对数概率差值,其中 $V$ 为词表大小。 由于所有对数概率上的恒定差值不会影响 Softmax 后的概率分布,因此我们在每个词元维度上减去对数概率差值的中位数。 最后,将未来 T 个词元(消融位置及后续位置)对应的差值向量拼接,得到长度为 的一维向量。 我们采用
作为稀疏度度量,该指标等价于**实际受影响的有效词表数量**。 再以
做归一化,得到取值在 0~1 之间的系数,**数值越小代表消融影响越稀疏**。 本文基于 GPT-2 small 模型第8层 MLP 输出后的残差流,训练多款自编码器并开展实验,设置 $T=16$,实验结果见图6b。
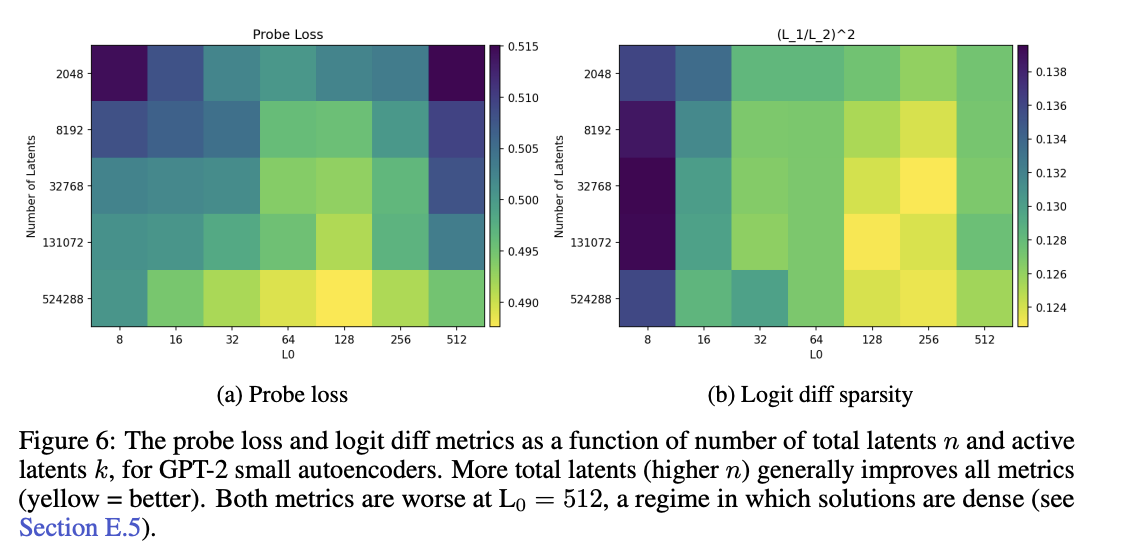
实验发现:在一定范围内,增大稀疏激活数 $k$ 会让隐单元的下游影响更稀疏;但当 $k=512$ 时趋势发生反转。 这说明当 $k$ 逐渐逼近模型维度 $d_\text{model}=768$ 时,自编码器学到的隐单元可解释性会变差。 从绝对稀疏度来看,自编码器隐单元的 $(L_1/L_2)^2$ 仅为 **10%~14%**; 而直接消融原始残差流通道的该指标高达 60%(略优于随机向量约 $2/\pi$ 的理论值)。
消融稀疏度结果表明,删除一个SAE 隐单元仅 10%~14%,远优于原始残差流通道的 60%,证明稀疏自编码器能够拆解出更独立、影响更局部化的可解释特征。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)