51万行源码背后的秘密:解析 Claude Code 的 AI Agent 架构艺术与工程落地
第一部分:引言与背景 —— 从“工程失误”到“降维打击”
1.1 泄漏:一次昂贵的“复盘”
-
事件定性:2026年3月31日,Anthropic 在发布 Claude Code 的 npm 包时,因
.npmignore配置失误,意外泄露了包含 51.2 万行 TypeScript 源码的.map文件。 -
工业级标杆:这不仅是 1,900 多个文件的泄露,更是向全球开发者展示了一个 $25 亿 ARR 级别、支持百万级并发调用的 AI Agent 产品,其代码架构是如何在“灵活性”与“确定性”之间平衡的。
1.2 震惊:开源的“成果”只是内部的“残影”
Anthropic 向社区发布的很多能力,看似是新技术,但从泄露源码看,它们其实只是内部系统的“简化版接口”。我们似乎正处于信息传递链的下游,社区每个月会更新一次技术,我们还来不及学习,但这些能力在优秀的团队早已落地。
Harness:
对外:
测试与评估框架,这在开源社区已经算比较先进的 Agent benchmark
众多IT从业者正在学习并考虑如何落地
对内:
Harness 在内部其实是一个 对抗性模拟系统,他们不是简单地测试 Agent,而是 主动攻击 Agent。
例如:模拟环境包括:用户输入模糊需求、用户给错误路径、文件权限异常。
Skill:
对外:
prompt的优化版,渐进式披露设计巧妙。
目前社区普遍认为skill是API的另一种形式。
对内:
仅仅是claude code架构中的一环。认为Skill ≠ 工具,Skill = 微型工作流。包括:读取文件、生成 patch、应用 patch、验证语法、验证编译、失败自动回滚。
总结
Anthropic 抛给社区的 Skill 概念,是一种架构层面的降维打击。MCP 让模型学会调用工具,而 Skill 则让模型具备完成复杂工程任务的能力。
当社区还在研究如何让 Agent 调用工具时,他们已经在构建完整的 Agent 工程运行体系,这种架构思维明显领先当前业内一个代际。
1.3 工业级设计
-
不仅仅是代码量:51.2 万行代码中,很大一部分比例并非业务逻辑,而是防御性编程。
-
架构思维的领先:通过源码可以看到,Anthropic 领先于行业 1-2 个版本的思考——当大家还在讨论 Prompt Engineering 时,他们已经在构建 “Agent OS”(代理操作系统)了。
第二部分:核心架构与技术栈 —— 代理操作系统的基石
2.1 不走寻常路的技术选型:追求极致的响应与确定性
2.1.1 CLI UI: React + Ink 的“降维打击”
很多人认为终端界面(CLI)就是简单的 console.log,但 Claude Code 引入了 Ink。
-
原理:Ink 是一个将 React 渲染到命令行终端的库。它把字符串拼接变成了 组件树管理。
-
亮点:
-
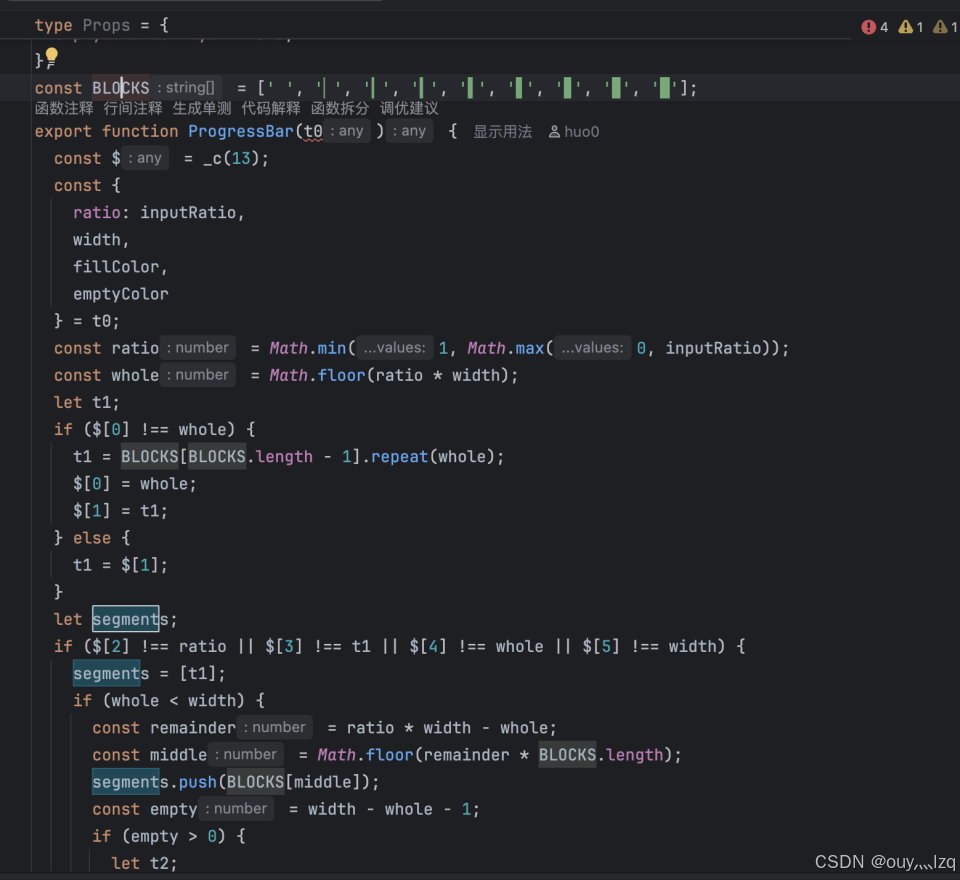
状态驱动的 UI:当 Agent 正在思考、运行 Shell 命令或等待用户确认时,UI 的切换不是通过清屏重绘,而是通过 React 的状态(State)更新实现的。这保证了复杂交互(如动态进度条、折叠面板)的流畅度。
-
组件复用:源码中定义了标准的
ToolResponse、Thinking、ProgressBar组件。这种**原子设计(Atomic Design)**思想,让 Agent 的每一个输出动作都有标准化的视觉规范。
-
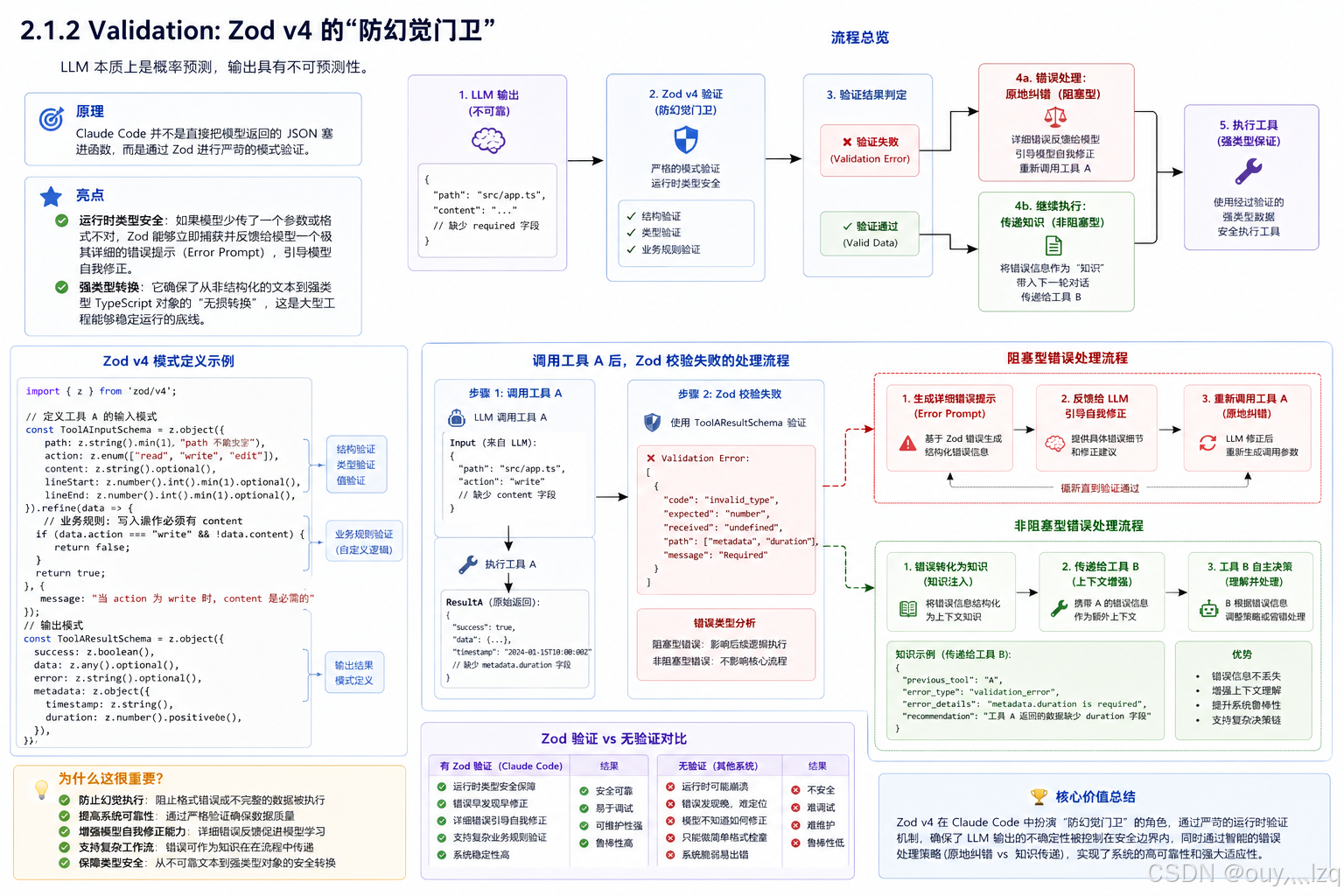
2.1.2 Validation: Zod v4 的“防幻觉门卫”
LLM 本质上是概率预测,输出具有不可预测性。
-
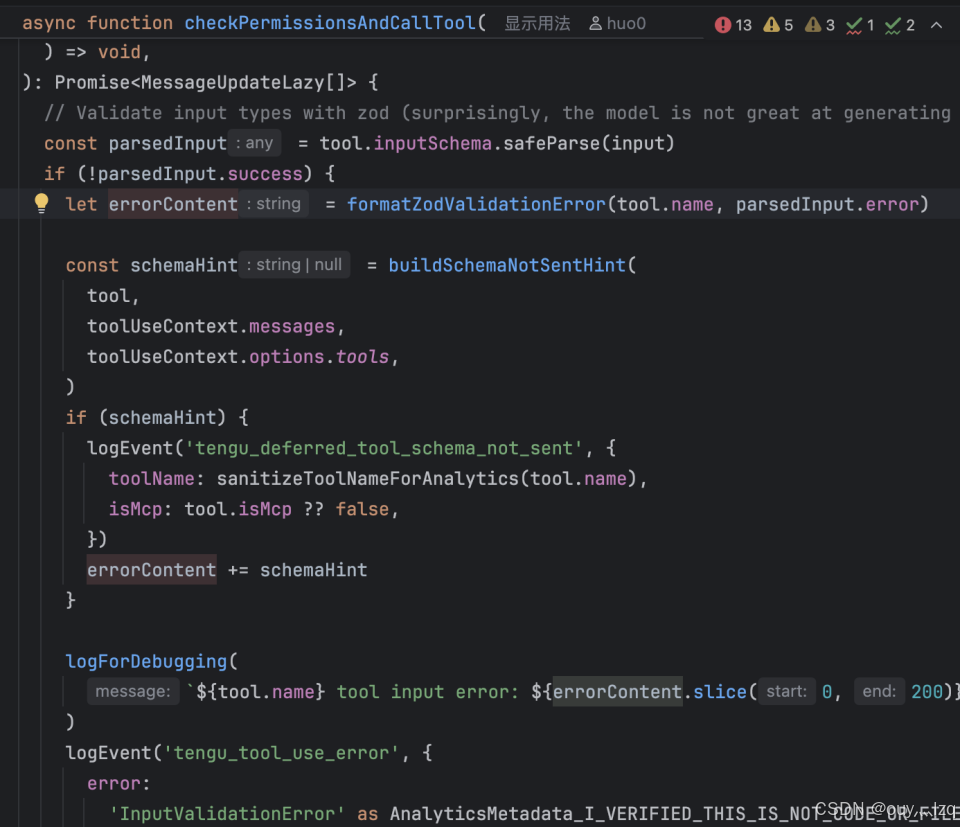
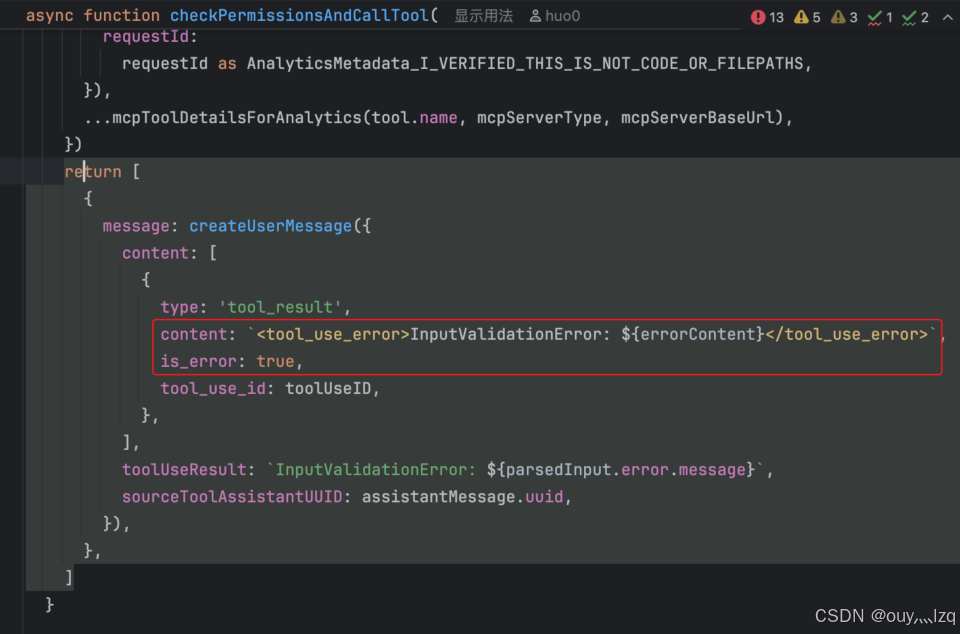
原理:Claude Code 并不是直接把模型返回的 JSON 塞进函数,而是通过 Zod 进行严苛的模式验证。
-
亮点:
-
运行时类型安全:如果模型少传了一个参数或格式不对,Zod 能够立即捕获并反馈给模型一个极其详细的错误提示(Error Prompt),引导模型自我修正。
-
强类型转换:它确保了从非结构化的文本到强类型 TypeScript 对象的“无损转换”,这是大型工程能够稳定运行的底线。
-
代码实现:
原理:

2.2 记忆可读性:
Claude Code 的强大不在于它的智商,而在于它记得住和找得到。
claude.md + memory.md:长期上下文的沉淀
-
特点:人类可读的“笔记”。
-
原理:每当完成一个重大任务(如重构某个模块),Agent 会自动更新项目根目录下的
memory.md。它记录了架构决策、避坑指南和历史逻辑。 -
亮点:这解决了 Agent 在长对话后的“记忆漂移”问题。当上下文达到极限时,Agent 可以抛弃对话历史,只读精炼的
memory.md。
claude.md:
通常是由开发者编写,或者是 Agent 根据项目初始化时扫描到的信息生成的“固定规范”。
# CLAUDE.md
This file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.
## Scope
**改动范围仅限 `agent/skills/deploy-env/`**,不要修改其他任何 skill、agent 或脚本。
## 改动规范
1. **不清楚就反问**:遇到不确定的业务逻辑、字段含义、参数取值时,必须反问用户,不要自己假设或随意添加。
2. **先读源码再改**:修改前必须 Read 相关上下游源码,不要凭空猜测接口参数或返回格式。
- env-setup Go 源码:`env-setup/code/`
- server-environment-route:`copilot/all/server-environment-route/scripts/`
2. **Mock 必须标注**:无法调用真实 API 时,mock 代码上方加 `# MOCK: <原因>` 和 `# RISK: <影响范围>`,并告知用户。
3. **禁止硬编码示例值用于真实调用**(如 `env_id=842978`、`arrange_id=2215`)。
4. **脚本输出 JSON,流程在 GUIDE.md 中编排**,不要在 Python 脚本中实现多步骤流程逻辑。
5. **新增业务线**通过添加 `config/product_lines/<name>.json`,格式参考 `payment.json`。memory.md
由 Agent 自动维护的。记录随着项目推进而产生的“增量信息”。
第三部分:工程设计的精妙之处
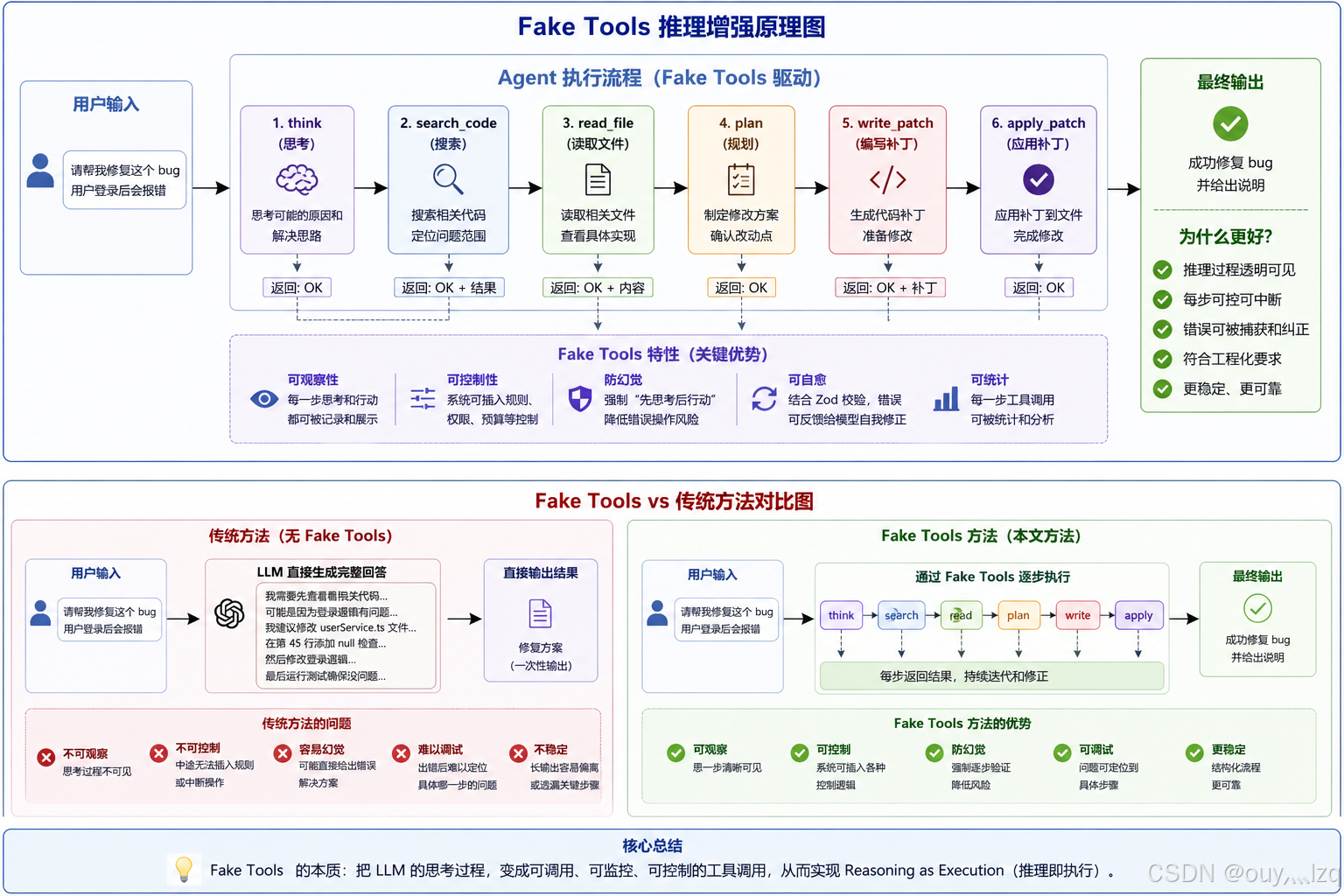
3.1 “Fake Tools” 策略:
-
现象: 部分工具没有具体用途,没有任何调用。
{
name: "think",
description: "Use this tool to reason about the task.",
input_schema: {
type: "object",
properties: {
thought: {
type: "string"
}
}
}
}- 解析源码中的工具调用防护机制,如何通过模拟工具反馈来引导模型进行更深层的推理。作用有二:
- 反蒸馏:客户端会在发送给服务端的API请求结构中动态插入虚构的fake_tools(假工具定义)。这种污染训练集的毒化策略,将导致那些不加甄别直接蒸馏其通信数据的行为吸收大量的错误逻辑噪音。
- 控制推理粒度:ReAct思想的一种实现,边执行边推理
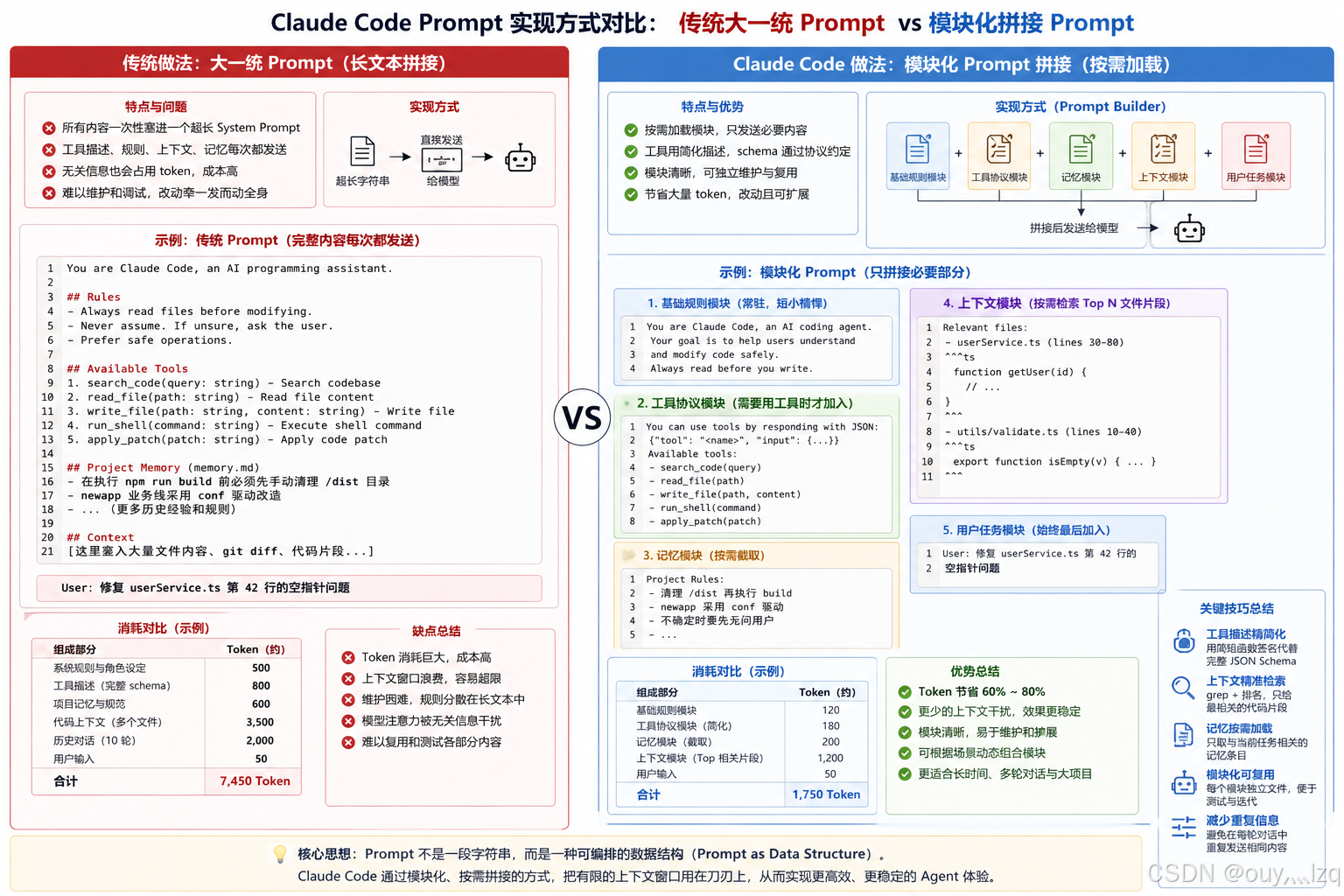
3.2 prompt拼接策略:
Claude Code 的 Prompt 设计本质是一种“结构化拼接策略”:将系统规则、工具协议、上下文状态和任务指令拆解为多个独立模块,在运行时按需动态组合,从而既降低 Token 消耗,又显著提升 Agent 行为的可控性与稳定性。
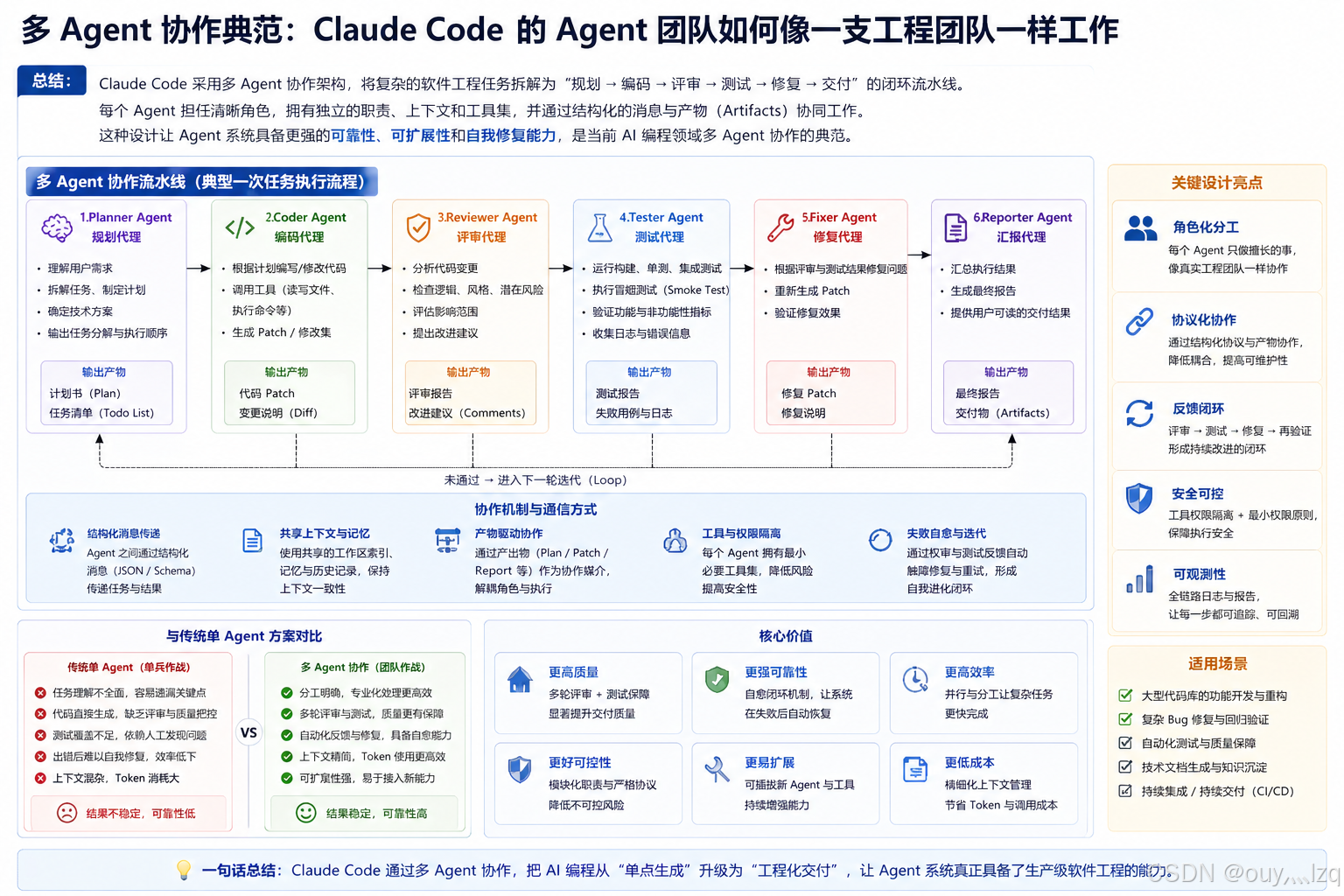
3.3 多Agent协作典范
第四部分:对 AI 开发者启示
-
Agent调优:模型预训练->Agent设计:同等模型水平情况下,不同的Agent设计带来的效果完全不同。
-
Agent 的未来方向:从“补全插件”转向“全能代理”的必然性。即不要想着做一个问答机器,而是做一个AI驱动的操作系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)