PT转RKNN模型(RK3399PRO)
-
- 模型转换
- 转换问题
- 模型转换
我们在进行PT→ONNX时,尽量使用官方的导出方法,因为NPU只负责推理,不负责后处理等功能,YOLOV8模型内部的DFL,NMS等操作会导致模型转换失败,使用官方导出方法,将后处理从模型中切除。
下面是我自己写的模型转换代码:
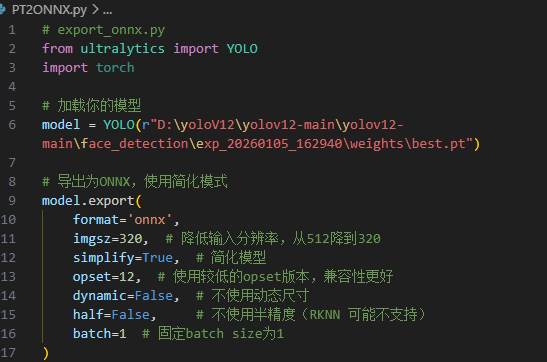
导致我最后生成的YOLO模型形状是(1,5,2100),导致最后即使把模型生成出来了,最后还是无法进行推理。

-
-
- 转换(PT→torchscript)
-
在转换时要使用瑞芯微官方提供的ultralytics_Yolov8文件(文件地址:
ultralytics_yolov8/RKOPT_README_zh.md at rk_opt_v1 · airockchip/ultralytics_yolov8 · GitHub)
不要和ultralytics官方文件搞混了。并且我们在下载文件时要注意分支:
因为我们的板子是RK3399PRO,所以要下载对应版本的文件
下载好之后,查看readme文件。
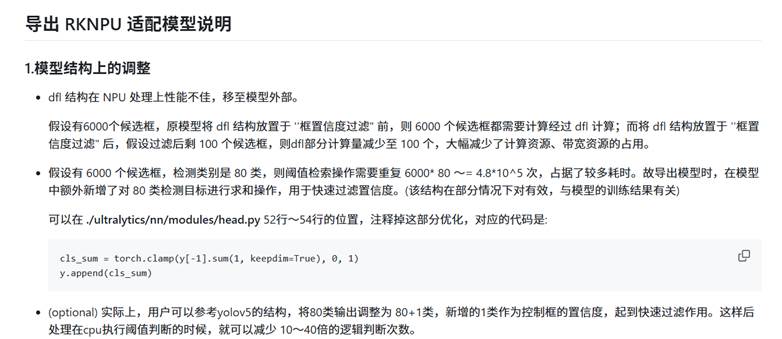

我们一步一步看,首先这个DFL,在YOLOv8模型中,DFL(Distribution Focal Loss) 是用于边界框回归的一种结构,它将每个坐标(如中心点、宽高)表示为一个概率分布,通过加权求和得到最终的坐标值。这种设计能更好地处理边界模糊或不确定的目标,但在 NPU(神经网络处理单元)上,DFL 涉及大量的张量运算(如 softmax、矩阵乘等),且需要遍历所有候选框,导致计算效率和带宽占用较高。
后面他让我们注释掉head.py中的代码,我们先找到他在文件中的位置:
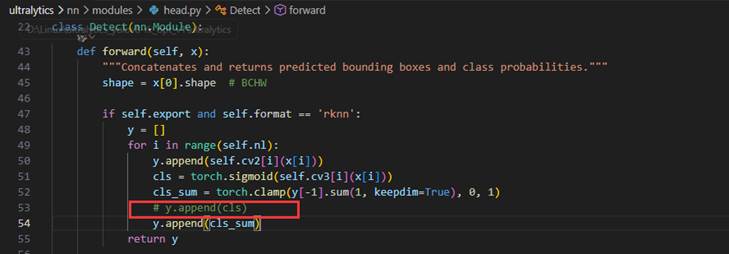
因为YOLOV8的检测头主要进行两类工作:1.坐标预测 2.类别预测
在正常推理时,这些原始输出还需要进行后处理(sigmoid归一化,NMS等)才能得到最终的检测框。由于我们后面用到的RKNPU只做最纯粹的卷积计算,其余后处理部分都交给CPU进行,所以注释掉这几段是为了避免这些操作不被NPU加速或者不支持。
配置文件的修改主要如下:
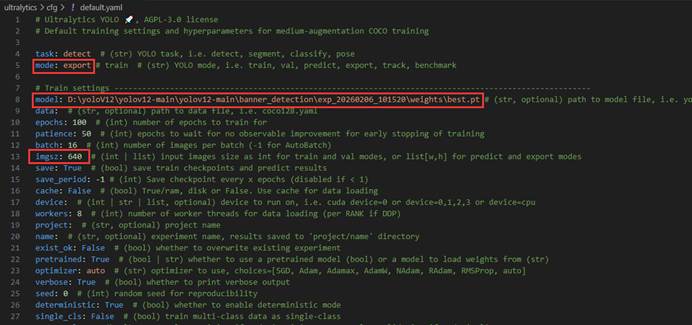
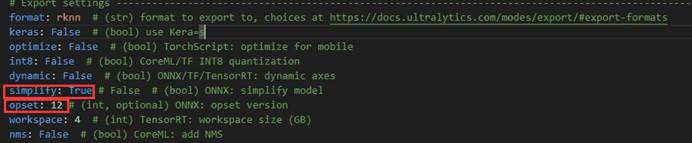
这里format不要改成onnx,因为在上面检测头的代码中,判断条件就是“format==rknn”。
其中图片大小的选择:如果追求精度可以将图片大小设大一点,如果追求推理速度可以将图片大小设小一点。
通过命令行导出,首先输入set PYTHONPATH=./ (回车)
再输入python ultralytics/engine/exporter.py (再回车)
如果失败的,需要确保自己在当前文件夹下,
![]()
可以输入cd /d D:\Linux\ultralytics_yolov8-rk_opt_v1
进入文件夹,将红色字体改成自己下载的文件地址。
导出的结果会默认保存在输入模型的地址。

3.2.2.1转换后的输出头
我们这里导出将format:onnx的结果:
![]()
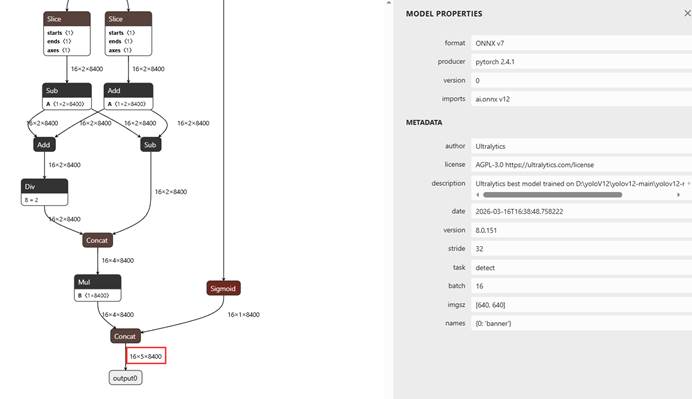
可以看到只有一个输出头。(16,5,8400)
我们再导出不注释掉检测头部分代码,且将format:rknn

((16, 64, 80, 80), (16, 1, 80, 80), (16, 1,
80, 80), (16, 64, 40, 40), (16, 1, 40, 40), (16, 1, 40, 40), (16, 64, 20, 20), (16, 1, 20, 20), (16, 1, 20, 20))
启用了“80+1”优化的模型。每个尺度(80x80, 40x40, 20x20)都对应三个输出:
1. 64通道的坐标输出 (cv2)
2. 1通道的类别得分输出 (cls),已经过sigmoid激活
3. 1通道的置信度总和输出 (cls_sum),用于快速过滤
接下来我们把之前框出来的检测头代码部分注释掉:
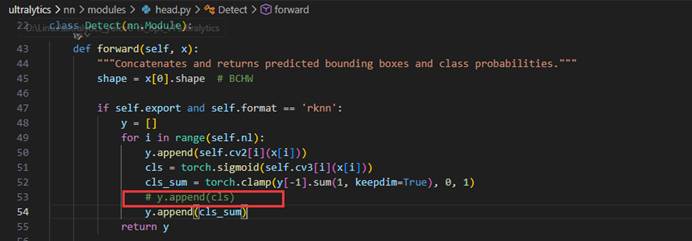

((16, 64, 80, 80), (16, 1, 80, 80), (16, 64, 40, 40), (16, 1, 40, 40), (16, 64, 20, 20), (16, 1, 20, 20))
只保留了每个检测头的原始坐标输出(cv2分支)。类别输出(cv3分支)和 cls_sum 分支都被移除了。NPU只做最纯粹的卷积,所有后处理(包括类别解析、sigmoid等)都交给CPU。
这里输出的通道中的1表示类别。
我们先采用注释后的三输出模型,因为3个输出对应三个尺度的原始坐标,结构非常清晰。
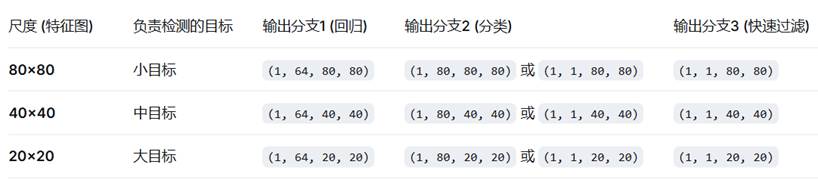
1. 回归输出分支 (1, 64, 80, 80)
- 它代表什么:这是边界框的“分布表示”,而不是我们熟悉的 (x, y, w, h) 具体坐标值。
- 为什么是 64 个通道:这是 YOLOv8 使用 DFL (Distribution Focal Loss) 策略的结果。为了精确预测边界框,模型对“左、上、右、下”四个边界的偏移量,分别预测一个概率分布,而不是一个单一数值。
- 64 = 4 × 16。4代表边界框的四个边(左、上、右、下),16代表 DFL 的分布长度(reg_max)。
- 后处理时,需要对这个分布进行 Softmax 和积分操作,才能解码出最终的偏移量。
2. 分类输出分支 (1, C, 80, 80)
- 它代表什么:每个网格点的类别得分。
- 通道数 C 的含义:
- 如果你检测的是 COCO 的 80 类,C = 80。
- 如果你只检测一个类(如横幅),C = 1。
- 是否需要 Sigmoid:为了获得 [0,1] 之间的概率值,这个分支的输出需要经过 Sigmoid 激活函数。如果这个分支的输出值非常小(如 0.003),很可能是因为模型在导出时缺失了 Sigmoid 操作。
3. 快速过滤分支 (1, 1, 80, 80)
- 它代表什么:它是一个粗略但快速的“目标存在”得分。
- 如何计算:这个分支是通过对回归输出(64个通道)在通道维度上进行 sum 和 clip 操作生成的。
- 有什么作用:它的值域被限制在 [0, 1]。在后处理时,可以先用一个很低的阈值(如 0.1)快速扫描这个分支。那些得分低于阈值的网格点,可以直接被跳过,不再进行后续复杂的 DFL 解码和分类。这能有效减少 CPU 后处理的计算量。
YOLOv8 模型为了检测不同大小的目标,使用了三个不同分辨率的检测头。在输入图像尺寸为 640×640 时,经过模型的主干网络和特征金字塔(FPN/PAN),会得到三个下采样倍数不同的特征图:
80×80 对应 下采样 8 倍(640 / 8 = 80),感受野最小,擅长检测小目标。
40×40 对应 下采样 16 倍(640 / 16 = 40),感受野中等,检测中型目标。
20×20 对应 下采样 32 倍(640 / 32 = 20),感受野最大,检测大目标。
总结一下这三个输出方式:
|
导出方式 |
输出结构 |
输出数量 |
通道含义 |
来源 |
|
单输出 (format=onnx) |
(16, 5, 8400) |
1个 |
5 = [x, y, w, h, obj_conf](该框存在目标的置信度(已 sigmoid,值域0~1) |
官方标准导出,后处理(DFL解码、sigmoid)已固化到模型中 |
|
六输出 (注释代码后) |
(16,64,80,80), (16,1,80,80) |
6个 |
回归输出 (64,H,W):每个坐标的DFL分布参数(4×16) |
只保留原始检测头输出,后处理完全在CPU进行 |
|
九输出 (未注释代码) |
(16,64,80,80), (16,1,80,80), (16,1,80,80) |
9个 |
回归输出 (64,H,W):同上 |
瑞芯微官方优化版本,增加了两个辅助分支 |
-
-
- 转换(torchscript→RKNN)
-
我们现在得到了一个六输出的best_rknnopt.torchscript模型,现在需要在linux环境下,将它转换成RKNN模型。
PC端应瑞芯微要求开发环境需要在Linux下进行
3.2.3.1虚拟机安装(Linux环境配置)
方法一:安装Ubuntu
- 双系统:在您的电脑上划分磁盘空间,安装 Ubuntu 18.04/20.04。这是一个独立的系统,启动时可以选择进入 Windows 或 Ubuntu。
- 虚拟机:使用 VMware 或 VirtualBox 在 Windows 内安装一个虚拟的 Ubuntu 系统。这种方式性能略有损耗,但切换方便。
该设计采用通过在虚拟机内部安装ubuntu的方法:
具体流程参考:
1.安装虚拟机(VMware)保姆级教程(附安装包)_vmware虚拟机-CSDN博客
2.虚拟机VMware上安装Ubuntu系统(详细图文教程)_vm安装ubuntu-CSDN博客
可以通过比较自己下载的镜像源的ubuntu的哈希值和官方ubuntu的哈希值判断文件有没有损坏。
3. 虚拟机Ubuntu系统上安装Miniconda(详细图文教程)_ubuntu miniconda-CSDN博客
miniconda下载网址:/miniconda 的索引
简略步骤:在ubuntu桌面右键—在终端中打开,依次输入以下命令:
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh(下载Miniconda安装脚本(使用清华镜像源))
bash Miniconda3-latest-Linux-x86_64.sh -b()(运行安装脚本,刚刚只是下载了安装包,不运行安装脚本是不会进行安装的)
重启终端,关闭终端界面,右键重新打开一个终端,验证安装是否成功。
conda –-version
![]()
创建环境:conda create -n Apex python=3.8
查看环境:conda list
4. VMware虚拟机-Ubuntu设置共享文件夹(超详细)_vmware ubuntu共享文件夹-CSDN博客
5. ubuntu系统安装vscode教程_ubuntu安装vscode-CSDN博客
将下载的VScode安装包放到共享文件夹中,
在终端输入:
cd /mnt/hgfs/VMware_share_1(VMware_share_1是我创建的共享文件夹的名字)
sudo dpkg -i code_1.107.1-1765982436_amd64.deb(安装VSCODE,i后面换成自己安装包的名字+.deb)(dpkg只能用于安装 Debian 系统包(.deb 文件))
如果需要安装其他扩展名需要用pip
pip install /rknn_toolkit_lite-1.7.5-cp38-cp38-linux_x86_64.whl(一定记得加后缀,复制文件名之后)
在linux环境中复制粘贴是ctrl+shift+C/V
在准备好虚拟机并且在虚拟机上安装好ubuntu 之后,我们的linux环境就准备好了,下面需要在虚拟机上安装RKNN-Toolkit
虚拟机Ubuntu系统上安装rknn-toolkit(详细图文教程)_ubuntu rknn-CSDN博客
rknn-Toolkit下载地址:发行作品 ·Rockchip-linux/rknn-toolkit
pip install -r ./requirements.txt(安装依赖)
pip install /rknn_toolkit-1.7.5-cp38-cp38-linux_x86_64.whl(一定记得加后缀.whl,复制文件名之后)
别下错了![]() ,是rknn_toolkit 没有_lite
,是rknn_toolkit 没有_lite
如果觉得一直通过终端输入代码,复制文件很麻烦可以输入下面的代码,在虚拟机上创建共享文件夹,这个共享文件夹就是和windows端互通的,直接点击就可以很方便。
ln -s /mnt/hgfs/VMware_share_1/ ~/桌面/我的共享文件夹
这样我们在主机上将文件放入共享文件夹后,可以直接在虚拟机桌面接收到。
mnt/hgfs在上面的创建共享文件夹博客中有说明,这里不再赘述。
VMware_share_1是我在windows上创建的共享文件夹的名字(换成自己创建的就行)
我们将刚刚转换的best_rknnopt.torchscript模型放入共享文件夹中。
-
-
- Torchscript→RKNN
-
环境配置好之后,准备再次进行模型转换,打开链接,下载官方提供的代码示例库文件:
GitHub - airockchip/rknn_model_zoo at v1.5.0 · GitHub
选择对应版本的分支,因为我们使用的是rk3399pro,所以下载v1.5.0版本。
下载好之后,按照下面文件的路径打开readme文件
按照指示打开[RKNN_model_convert]
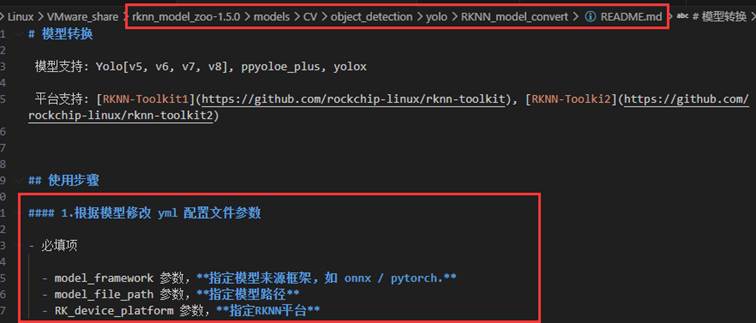
找到配置文件,查看参数设置(预编译pre_compile设置成offline):
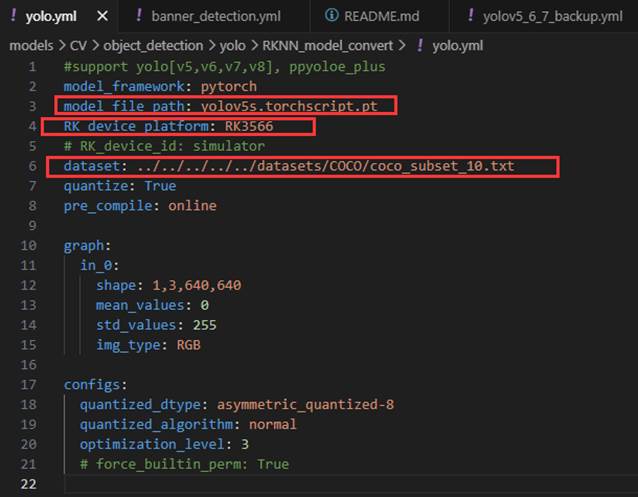
主要修改圈出的几个参数,这个dataset是校准文件,校准文件的核心作用是为模型量化提供数据参照,以确定浮点参数转换为整数时的最佳缩放比例,从而在保证精度的前提下大幅提升模型在NPU上的推理速度并减少内存占用。(只需要图片,不需要标注,让AI生成脚本将校准文件中的图片大小调整到和模型训练时设置的imgsz一样)
我们就从训练集中选100张图片放到共享文件夹中。
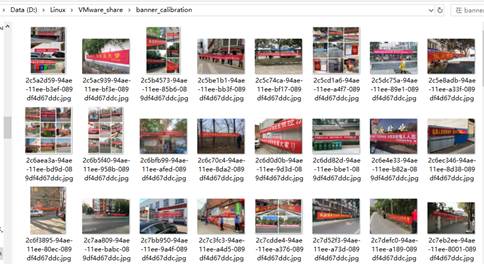
下面我们进入虚拟机中
将共享文件夹中的图片保存到我们的项目文件中,并让AI生成一个图片尺寸转换脚本,将图片批量转换尺寸。
再让AI生成提取文件路径的脚本(生成绝对路径),得到dataset.txt。形式如下:
再在虚拟机中打开rknn_model_zoo-1.5.0文件,
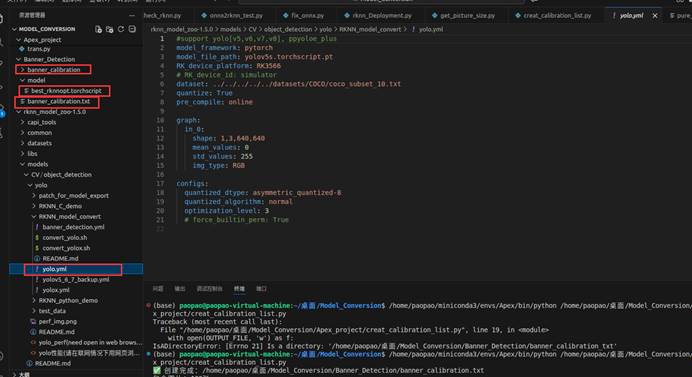
我们在虚拟机中打开VSCODE,主要检查以下几个文件,第一个就是我们的校准图片,第二个是校准图片的路径(是一个.txt的文档),第三个就是我们之前转化的best_rknnopt.torchscript模型,第四个就是我们rknn_model_zoo-1.5.0文件。
现在我们打开rknn_model_zoo-1.5.0的RKNN_model_covert中的yolo.yml配置文件进行修改。
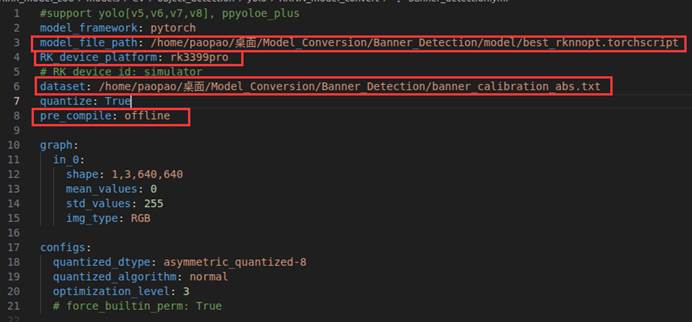
设置好之后我们在终端输入命令行代码开始转换:
python /home/paopao/桌面/Model_Conversion/rknn_model_zoo-1.5.0/common/rknn_converter/rknn_convert.py --yml_path /home/paopao/桌面/Model_Conversion/rknn_model_zoo-1.5.0/models/CV/object_detection/yolo/RKNN_model_convert/banner_detection.yml --python_api_test --capi_test
标红的路径依据自己的文件进行修改。
3.2.4.1 报错
运行之后发生报错,

这是由于common/capi_simply_executor/commond_executor/toolkit1_capi.py文件中的代码要求路径列表(realpath)中必须包含元素 'rknn_model_zoo',才能截取到该目录之前的路径。
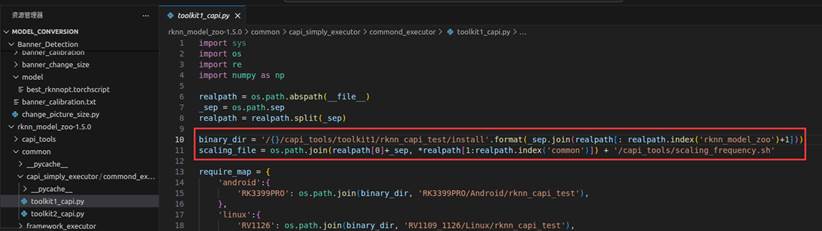
现在只有将rknn_model_zoo-1.5.0改名正rknn_model_zoo,并将路径重新替换。
python /home/paopao/桌面/Model_Conversion/rknn_model_zoo/common/rknn_converter/rknn_convert.py --yml_path /home/paopao/桌面/Model_Conversion/rknn_model_zoo/models/CV/object_detection/yolo/RKNN_model_convert/banner_detection.yml --python_api_test --capi_test
重新开始运行,运行结果: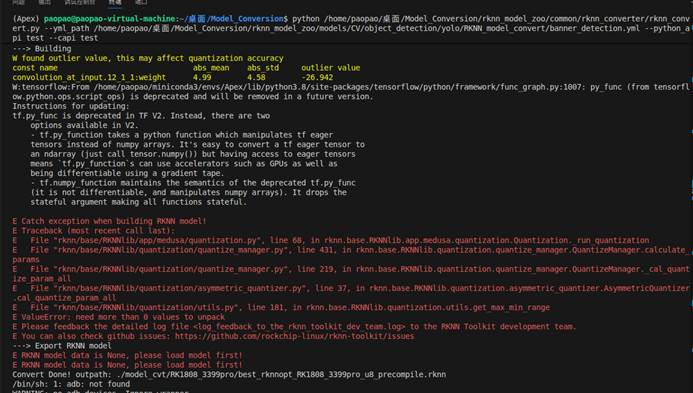
可以看到一直在报量化错误,我们将量化功能先关闭。
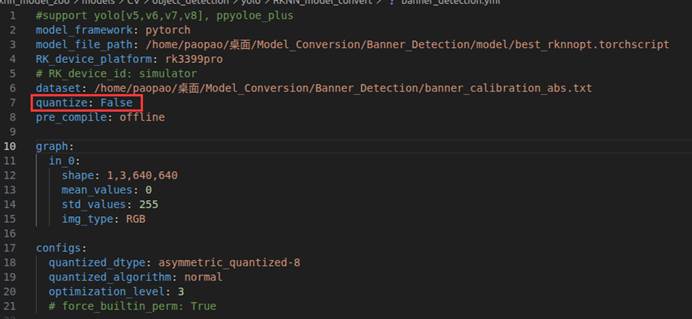
此时发现没有报错:
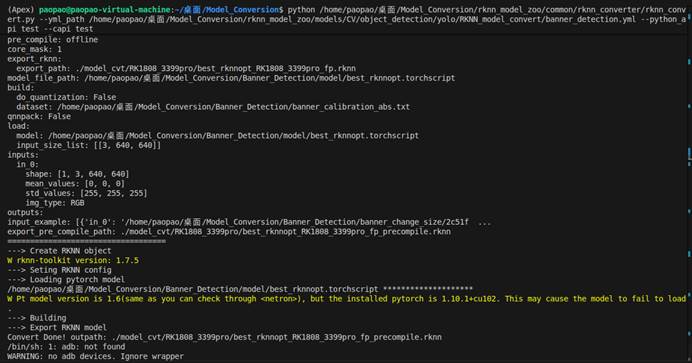
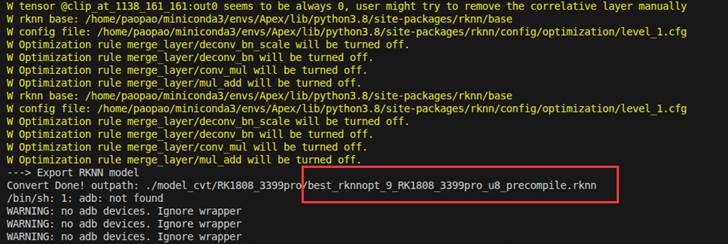
文件生成在
这个路径是相对于我们执行命令时的当前文件目录,由于我们当前的目录是 ~/桌面/Model_Conversion,所以生成的模型就在/home/paopao/桌面/Model_Conversion/model_cvt/RK1808_3399pro/best_rknnopt_RK1808_3399pro_fp_precompile.rknn中
3.2.4.2 报错分析
通过询问,
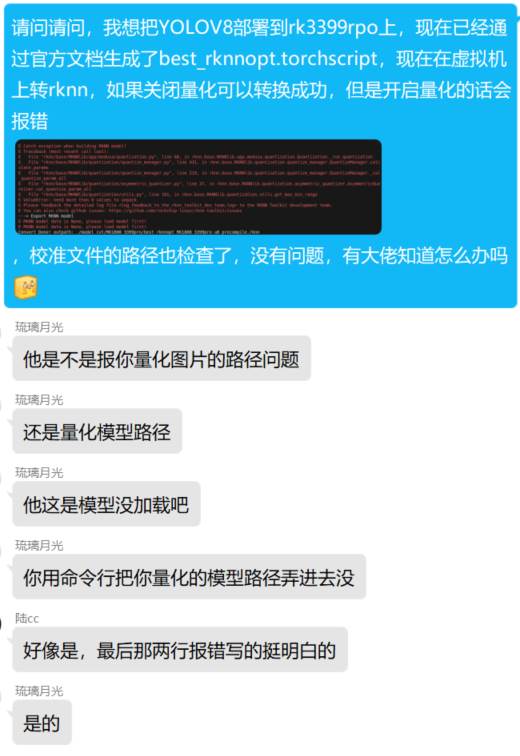
我们再次查看错误信息:
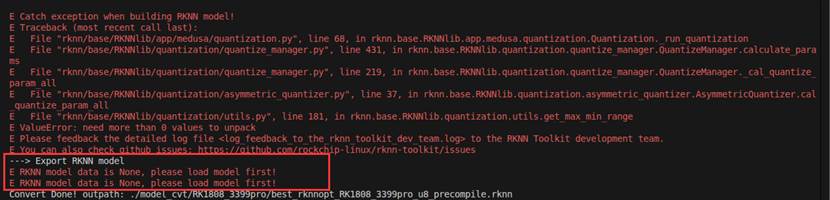
这里显示的模型不存在,是指的是我们量化之后的模型没有存在,所以不能将量化之后的模型导出成rknn模型。但是我都量化失败了哪来的量化模型呢?
我们再详细查看上面的报错信息:
|
E Catch exception when building RKNN model! E Traceback (most recent call last): E File "rknn/base/RKNNlib/app/medusa/quantization.py", line 68, in rknn.base.RKNNlib.app.medusa.quantization.Quantization._run_quantization E File "rknn/base/RKNNlib/quantization/quantize_manager.py", line 431, in rknn.base.RKNNlib.quantization.quantize_manager.QuantizeManager.calculate_params E File "rknn/base/RKNNlib/quantization/quantize_manager.py", line 219, in rknn.base.RKNNlib.quantization.quantize_manager.QuantizeManager._cal_quantize_param_all E File "rknn/base/RKNNlib/quantization/asymmetric_quantizer.py", line 37, in rknn.base.RKNNlib.quantization.asymmetric_quantizer.AsymmetricQuantizer.cal_quantize_param_all E File "rknn/base/RKNNlib/quantization/utils.py", line 181, in rknn.base.RKNNlib.quantization.utils.get_max_min_range E ValueError: need more than 0 values to unpack E Please feedback the detailed log file <log_feedback_to_the_rknn_toolkit_dev_team.log> to the RKNN Toolkit development team. E You can also check github issues: https://github.com/rockchip-linux/rknn-toolkit/issues ---> Export RKNN model E RKNN model data is None, please load model first! E RKNN model data is None, please load model first! |
第一步:quantization.py line68 开始量化
第二步:quantize_manager.py line431 & 219 量化过程的核心管理模块,负责协调计算每一层网络在量化后需要的参数
第三步:asymmetric_quantizer.py line37 调用具体的“非对称量化器”为某一层计算量化参数
第四步:utils.py line181 ‘get_max_min_range’这是发生错误的具体函数,它的任务是从某一层网络的输出数据中找出最大值和最小值,以便确定量化范围。包括最后“ValueError: need more than 0 values to unpack”这个错误说明:函数期待最少获取到一个最大值和一个最小值,但实际上他收到的数据是空“0”values。
这说明在量化过程中,RKNN工具在分析校准图片时,输出的都是“空”数据。
有点没招了。
3.2.4.3 解决方案
1.我尝试了把校准文件路径全部换成中文的还是没用。
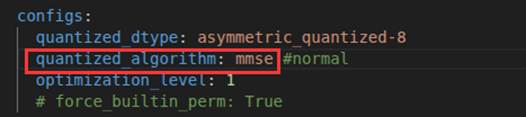
2.将quantized_algorithm改成mmse
3.在瑞芯微官网issue中也没找到有类似问题的解决方法。
4.在配置文件中输入verbose:true,打印转换日志,想看看在哪一个转换步骤出错。
5. 用官方YOLOv8模型和COCO子集跑通全流程,确认是模型问题还是工具链问题。
先去ultralytics官网下载YOLOV8n官方预训练权重模型,然后再找到官方COCO图片来当校准数据集。
http://images.cocodataset.org/zips/val2017.zip
按照之前的步骤,我们将YOLOV8n转换成.torchscript模型,然后对他开启量化进行转化。结果竟然成功了。
那矛头直指我们训练的模型,我们需要查看我们训练的模型和官方的预训练权重模型的区别是什么。
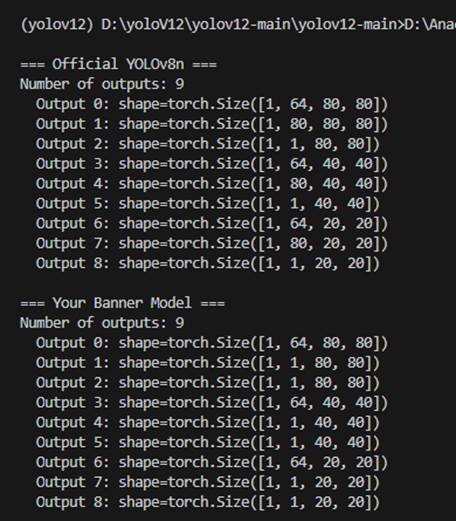
这里我们将官方的YOLOv8n转换成torchscript时,设置的是9输出通道,可以看到我们自己训练的权重模型和官方的权重模型输出的通道是一样的,虽有有一个是80有一个是1,那只是分类通道数的不同,我们的模型只检测横幅这一类,官方的模型检测80类。
因此我们回去将我们自己训练的横幅检测模型重新生成,将输出通道改成9通道数的torchscript,再次进行转换,发现转换成功了
通过询问得知:
总结一句话:就是我们上面说的将模型导出成6输出是错的,需要导出成9输出的torchscript模型才可以😄。
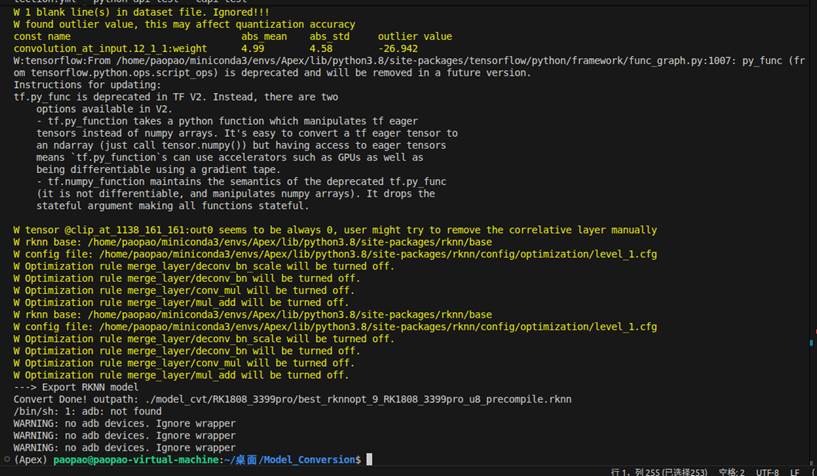
不过在转换模型时,出现了问题,根据提示可以看到我们的某个clip层在校准图片上的输出一直是0,虽然我们成功转换了rknn模型,但这个分支很可能没有被激活,从而影响后续模型部署的检测结果。
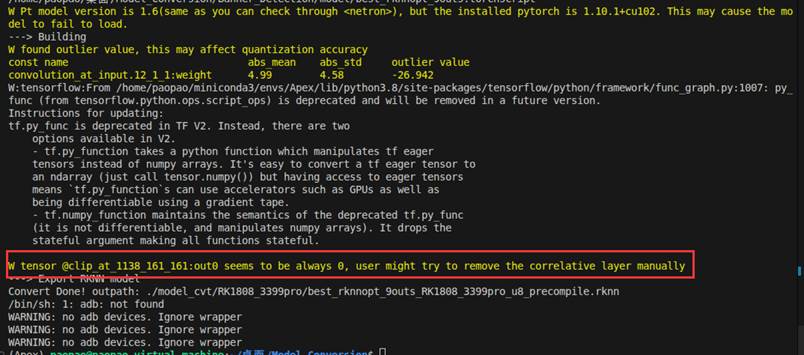
这通常是由于校准数据中的图片缺少某一尺度导致的,我提供的校准图片中的横幅的图片,大多是中等偏大目标的图片,很少有小目标的图片所以可能导致对应尺度的检测头没有被激活,输出始终为负,经过clip(0,1)后全为0。
但是由于是在没有无人机俯拍的横幅图片,没有小目标,所以我尝试将VisDrone的俯拍图片选择几十张放入校准文件中,看能不能起作用,虽然其中没有横幅,但是占比不高,只是为了激活一下小目标检测头。
我们将自己横幅训练的230张图片和COCO官方验证集的300张图片混合进行校准。
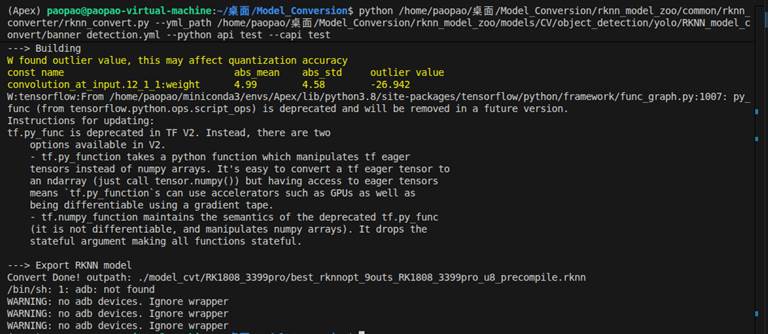
可以看到最后没有在报0输出的错误了,但是实际效果还要看在板子上推理的结果。
现在我们总共有四个模型:
从上到下依次是
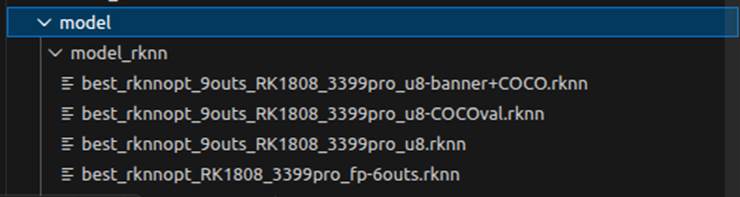
九输出-横幅+COCO校准-int8量化
九输出-COCO校准-int8量化
九输出-横幅-int8量化
六输出-横幅-fp32无量化
3.2.4.4 量化作用分析
这里解释一下量化的作用,为什么这么执着于量化:对于边缘设备,计算资源和功耗都有限,如果使用没有量化的FP32(32位浮点数)模型,NPU无法发挥最大效能,推理会很慢,无法满足实时性的要求,而INT8(8位整数)是将FP32模型压缩并加速的关键技术。FP32依赖CPU/GPU,INT8充分利用NPU,由于RK3399PRO上,INT8模型才能发挥NPU的并行计算能力,实现低延迟,低功耗推理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)