爆肝7天!本地知识库搭建教程
不知道你有没有过这样的经历: 工作里有一堆项目文档、技术方案,每次要找个参数、回忆某个接口的用法,都要在一堆文件夹里翻半天,翻了半小时才找到那个早就被你忘在角落的 md 文档; 想让 AI 帮你总结这些文档的内容,但是又不敢把这些公司的内部资料、私人的项目文档上传到 ChatGPT 或者其他第三方的 AI 工具里 —— 万一数据泄露了怎么办?之前就看到过新闻,有人把公司的机密文档上传到第三方 AI,结果直接被泄露了,最后丢了工作; 想用那些付费的知识库工具?比如某 AI 的企业版,一个月就要大几百,对于个人开发者或者小团队来说,实在是有点肉疼; 而且很多工具还必须联网才能用,有时候在飞机上、在没网的工地,想查点资料根本用不了。
我之前就被这些问题折磨了好久,直到上个月,我下定决心,能不能自己搭一个本地的知识库?完全在自己的电脑上跑,数据不用上传给任何人,完全免费,不用联网也能用?
说干就干,这一折腾就是 7 天,踩了无数的坑:最开始下错了模型版本,直接把显卡显存爆了;然后文本分割的参数不对,导致 AI 根本检索不到正确的内容;还有中文乱码、模型瞎回答的问题,一个个解决之后,终于搞出了一个完整可用的版本。
现在我把这个完整的教程分享给你,你不用再踩我踩过的坑,跟着这篇教程,哪怕你是新手,也能在半小时之内,搭出一个属于自己的本地知识库,支持 PDF、Word、TXT、Markdown 所有常见的文档格式,支持多轮对话,完全免费,数据永远在你自己手里,再也不怕泄露了!
一、技术栈选型:为什么是 LangChain+Qwen2?
在动手之前,我也对比了好多不同的技术栈,比如有的用 Llama2,有的用 ChatGLM,最后还是选了 LangChain+Qwen2 的组合,原因很简单:好用、免费、对新手友好,而且性能足够强。
1.1 LangChain:大模型应用的 “胶水”
如果你之前接触过大模型应用,肯定听过 LangChain 的名字。简单来说,LangChain 就是一个开源的框架,它帮你把大模型、向量数据库、文档加载这些零散的组件都粘起来,不用你自己从零写所有的代码。
比如你要加载 PDF 文档?LangChain 已经帮你写好了对应的加载器,直接调用就行;你要做文本分割?它有现成的分割器,不用你自己写字符串处理的代码;你要做检索增强生成(RAG)?它有现成的 RetrievalQA 链,几行代码就能搞定。
对于我们这种要快速搭一个知识库的人来说,LangChain 真的是省了太多事了,不用重复造轮子。
1.2 Qwen2:开源大模型的性价比之王
Qwen2 是阿里通义千问团队开源的大模型,说实话,这是我用过的开源大模型里,中文效果最好的之一,没有之一。
对比其他的开源模型,Qwen2 有几个特别大的优势:
-
中文能力拉满:毕竟是国内团队训练的,对中文的理解、中文的生成,比很多国外的模型强太多了,不会出现那种翻译腔,也不会理解不了中文的梗和专业术语;
-
开源免费:完全开源,个人和企业都能免费商用,不用付任何费用;
-
量化版本友好:官方提供了 GPTQ、AWQ 这些量化后的版本,7B 的模型,量化成 4bit 之后,只需要 8G 左右的显存就能跑,普通的游戏显卡,比如 3060、3070、4060 这些,都能轻松带动,甚至没有显卡,用 CPU 也能跑,就是慢一点而已;
-
上下文够大:7B 的模型就有 128K 的上下文,相当于 9 万多字,哪怕是很长的文档,也能处理得过来。
之前我也试过 Llama2、ChatGLM 这些,对比下来,同样的硬件条件下,Qwen2 的回答效果是最好的,而且速度也更快。
1.3 其他配套工具:轻量好用的开源组件
除了这两个核心的,我们还需要几个小工具,都是轻量、零配置的:
-
Chroma:本地向量数据库,不用你装 MySQL、不用装 Elasticsearch,解压就能用,完全在本地运行,数据存在你的电脑里,而且 API 特别简单,几行代码就能把向量存进去、查出来;
-
Gradio:快速做 Web 界面的工具,不用你写 HTML、CSS、JS,几行 Python 代码,就能生成一个好看的网页界面,支持文件上传、对话,打开浏览器就能用,特别方便;
-
TextSplit:LangChain 自带的文本分割工具,能智能的把长文档切成小块,不会把专业名词、句子切开,保证检索的准确性。
1.4 整体架构:整个系统是怎么跑起来的
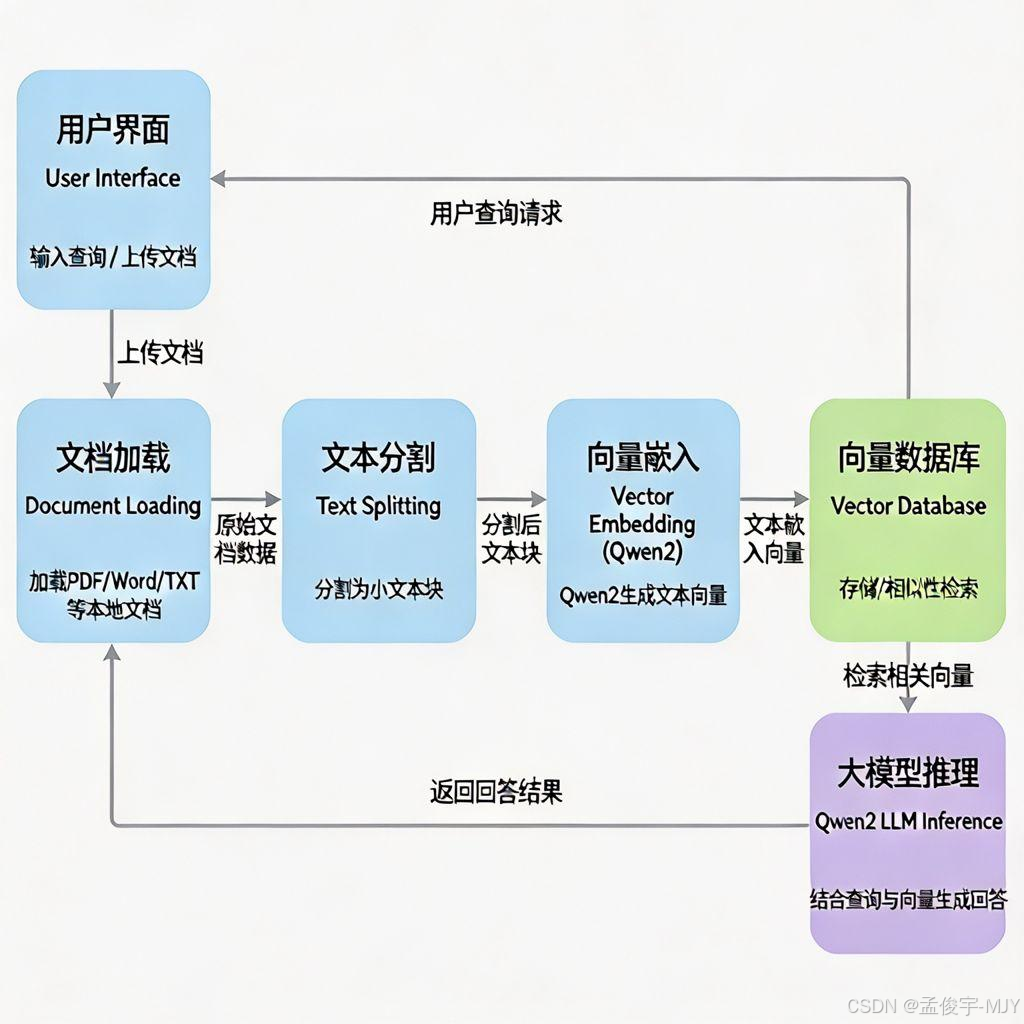
可能你看到这么多组件有点懵,没关系,整个系统的流程其实特别简单,我给你画了个架构图,一看就懂:
整个流程分为两部分:
-
文档处理阶段:你把自己的文档上传上去,系统先把文档加载出来,然后切成小的文本块,然后把每个文本块转成向量,存到本地的向量数据库里,这一步就完成了知识库的构建;
-
问答阶段:你输入一个问题,系统先把你的问题转成向量,然后去向量数据库里,找到和这个问题最相关的几个文本块,然后把这些文本块和你的问题一起,喂给本地的 Qwen2 大模型,大模型就会基于这些文档的内容,给你生成准确的回答,而且不会瞎编。
整个过程,所有的数据都在你的电脑里,不会上传到任何地方,完全离线也能运行,是不是特别安全?
二、环境准备:3 分钟搞定运行环境
接下来我们开始动手,首先第一步,把环境准备好,其实特别简单,跟着我一步步来就行。
2.1 系统要求:你的电脑能不能跑?
首先说一下硬件要求,其实要求真的不高:
-
如果有 N 卡的话:显存≥8G,就能跑 7B 的 4bit 量化模型,速度大概是每秒 10-20 个 token,也就是每秒几个字,完全够用;
-
如果没有 N 卡,用 CPU 的话:内存≥16G,也能跑,就是速度会慢一点,大概每秒 1-2 个 token,用来查资料也够用了;
-
系统的话:Windows、Linux、Mac 都支持,我自己是在 Windows 11 上测试的,Linux 和 Mac 也没问题,跟着教程来就行。
2.2 Python 环境配置
首先你需要安装 Python,建议用 Python 3.9 到 3.11 之间的版本,不要用太新的,也不要用太老的,不然有些依赖包会装不上。
如果你还没装 Python,可以去官网下载:https://www.python.org/downloads/,安装的时候记得勾选 “Add Python to PATH”,这个很重要,不然你在命令行用不了 python 命令。
装完 Python 之后,建议你创建一个虚拟环境,避免把你的全局 Python 环境搞乱了,当然如果你嫌麻烦,跳过这一步也可以。
创建虚拟环境的命令:
# 创建虚拟环境,名字叫qwen-rag
python -m venv qwen-rag
# 激活虚拟环境
# Windows系统:
qwen-rag\Scripts\activate
# Linux/Mac系统:
source qwen-rag/bin/activate2.3 依赖包一键安装
接下来我们安装需要的依赖包,我把所有需要的包都整理好了,你直接复制下面的命令,运行就行,它会自动把所有的依赖都装好。
pip install langchain langchain-community langchain-chroma transformers auto-gptq accelerate sentence-transformers unstructured pdf2image pytesseract python-docx gradio哦,对了,如果你是 Windows 系统,安装的时候可能会遇到一些小问题,比如 pytesseract 装不上?没关系,你可以单独装一下,或者用 conda 装,不过大部分情况下,上面的命令直接就能跑通。
还有,如果你是 CPU 运行的话,不需要装 CUDA,直接装上面的包就行,它会自动用 CPU 模式。
2.4 Qwen2 模型下载:两种方式任选
接下来是最关键的一步:下载 Qwen2 的模型,这里一定要注意,我们要下的是量化后的 4bit GPTQ 版本,不然原版的模型太大了,你的显卡根本跑不起来。
我推荐你用 Qwen2-7B-Instruct-GPTQ-4Bit 这个版本,这个版本是我测试过的,效果最好,占用显存最小,8G 显存就能轻松跑。
下载有两种方式,你选一种就行:
方式一:从 ModelScope 下载(国内用户推荐,速度快)
ModelScope 是阿里的模型托管平台,国内下载速度特别快,不用翻墙,你可以先装一下 ModelScope 的下载工具:
pip install modelscope然后用下面的 Python 代码下载,直接运行就行:
from modelscope import snapshot_download
# 下载模型,会自动存到默认的缓存目录
model_dir = snapshot_download("qwen/Qwen2-7B-Instruct-GPTQ-Int4")
print(f"模型下载完成,路径是:{model_dir}")运行之后,它就会自动下载模型了,整个模型大概 4G 左右,你的网速如果是 10M 的话,大概 10 分钟就能下完,比 HuggingFace 快多了。
方式二:从 HuggingFace 下载(国外用户推荐)
如果你在国外,或者能访问 HuggingFace,也可以从 HuggingFace 下载,地址是:https://huggingface.co/Qwen/Qwen2-7B-Instruct-GPTQ-Int4
你可以用 git lfs 下载,首先装 git lfs:
git lfs install然后 clone 模型:
git clone https://huggingface.co/Qwen/Qwen2-7B-Instruct-GPTQ-Int4这样也能把模型下下来,不过国内的话,这个速度会很慢,所以还是推荐用 ModelScope。
下载完之后,记住你的模型路径,后面我们要用到。
三、文档加载与预处理:让你的资料变成 AI 能懂的格式
环境准备好了之后,接下来我们处理文档,很多人会问,我有 PDF、Word、TXT 这些不同的文档,都能支持吗?当然可以,LangChain 帮我们做好了所有的加载器,不管是什么格式,都能一键加载。
3.1 支持多格式文档:TXT/MD/PDF/Word 全覆盖
LangChain 支持几乎所有常见的文档格式:
-
TXT、Markdown:纯文本格式,直接加载就行;
-
PDF:不管是扫描版还是文字版,都能加载,扫描版的话,会自动用 OCR 识别文字;
-
Word:.doc 和.docx 都支持;
-
PPT:哦,对了,也支持 PPT,不过我们这次主要用常见的这几个,其他的你可以自己拓展。
3.2 文本智能分割:解决长文档的痛点
加载完文档之后,我们要把长文档切成小的文本块,为什么要切?因为大模型的上下文是有限的,而且向量数据库里的向量,是对小文本块的,如果你把整个 10 万字的文档转成一个向量,那检索的时候根本找不到你要的内容。
但是切的时候也不能乱切,比如你不能直接按字数切,把一个完整的句子、一个专业名词切成两半,比如 “LangChain 框架”,你切成了 “LangCh” 和 “ain 框架”,那这个向量就没用了。
所以 LangChain 提供了一个RecursiveCharacterTextSplitter,它会先按换行、按标点来切,尽量保证每个文本块都是完整的句子、完整的段落,这样切出来的文本块,语义是完整的,检索的时候就会准确很多。
3.3 实战代码:一行代码加载所有文档
好了,说了这么多,我们来看代码,这部分代码很简单,你直接复制就能用:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader, Docx2txtLoader
# 定义加载器,根据不同的文件后缀,用不同的加载器
LOADER_MAPPING = {
".txt": (TextLoader, {"encoding": "utf8"}),
".md": (TextLoader, {"encoding": "utf8"}),
".pdf": (PyPDFLoader, {}),
".docx": (Docx2txtLoader, {}),
}
def load_documents(directory):
"""
加载指定目录下的所有文档
"""
loader = DirectoryLoader(
directory,
glob="**/*.*", # 加载所有子目录下的所有文件
loader_cls=lambda file_path:
LOADER_MAPPING[file_path.suffix][0](str(file_path), **LOADER_MAPPING[file_path.suffix][1])
if file_path.suffix in LOADER_MAPPING else None,
show_progress=True, # 显示加载进度
)
# 加载文档
documents = loader.load()
print(f"加载了{len(documents)}个文档")
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 每个文本块的大小,512个字符
chunk_overlap=50, # 重叠的大小,避免把上下文切断
length_function=len,
)
texts = text_splitter.split_documents(documents)
print(f"分割成了{len(texts)}个文本块")
return texts这个函数,你只要传一个目录的路径,它就会自动把这个目录下所有的 TXT、MD、PDF、Word 文档都加载出来,然后自动分割好,是不是特别方便?
比如你有一个my_docs的文件夹,里面放了你的所有文档,你只要调用load_documents("./my_docs"),就搞定了。
四、向量数据库:让 AI 能快速找到你要的内容
文档分割好之后,接下来我们要把这些文本块存到向量数据库里,这样后面用户提问的时候,AI 才能快速找到和问题相关的内容。
4.1 为什么需要向量数据库?
可能你会问,为什么不直接把所有文档都喂给大模型?不行啊,因为大模型的上下文是有限的,128K 的上下文,也就不到 10 万字,如果你有 100 万字的文档,根本塞不进去。
而且,如果你把所有文档都塞进去,大模型也找不到你要的内容,就像你把一整本书都给一个人,然后问他某一页的某个问题,他也得翻半天,而且很容易看错。
向量数据库就是解决这个问题的,它先把每个文本块转成一个向量,向量其实就是一串数字,代表这个文本的语义,比如 “LangChain 怎么用” 和 “LangChain 的使用方法”,这两个的向量就会很接近。
当你提问的时候,它把你的问题也转成向量,然后去向量数据库里,找和你的问题向量最接近的那几个文本块,这样就能快速找到你要的内容,然后只把这几个小的文本块喂给大模型,大模型就能基于这些内容给你回答了,这样哪怕你有 1000 万字的文档,也能处理。
4.2 Chroma:零配置的本地向量数据库
我们用的 Chroma 就是一个特别轻量的向量数据库,不用你装任何服务,不用配置,直接用 Python 调用就行,所有的数据都存在你的本地文件夹里,下次打开的时候,直接加载就行,不用重新处理文档。
4.3 向量嵌入:把文本变成计算机能理解的向量
要把文本转成向量,我们需要一个嵌入模型,这里我们用的是all-MiniLM-L6-v2,这个是一个特别小但是效果很好的嵌入模型,只有几十 M,速度很快,中文的效果也不错。
当然,你也可以用 Qwen2 自己的嵌入模型,不过这个小模型已经足够用了,而且速度快很多。
4.4 持久化存储:下次打开不用重新加载
Chroma 支持持久化,也就是你处理完文档之后,它会把向量数据库存在你的本地磁盘里,下次你再打开程序的时候,直接加载这个数据库就行,不用重新加载文档、重新分割、重新生成向量,省了好多时间。
好了,这部分的代码来了:
from langchain_chroma import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
# 初始化嵌入模型
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
def create_vector_db(texts, persist_directory="./chroma_db"):
"""
创建向量数据库,并且持久化
"""
# 创建Chroma数据库
db = Chroma.from_documents(
texts,
embeddings,
persist_directory=persist_directory, # 持久化的目录
)
# 持久化保存
db.persist()
print(f"向量数据库创建完成,保存在{persist_directory}")
return db
def load_vector_db(persist_directory="./chroma_db"):
"""
加载已经存在的向量数据库
"""
db = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings,
)
print(f"向量数据库加载完成")
return db太简单了是不是?如果你是第一次运行,就调用create_vector_db,把分割好的文本传进去,它就会帮你创建数据库,并且存到本地。如果不是第一次,直接调用load_vector_db,一秒钟就加载好了,不用重新处理文档。
五、LangChain 检索链:实现基于文档的智能问答
好了,数据库建好了,接下来就是最核心的部分:构建检索问答链,也就是让 AI 能根据数据库里的内容,回答你的问题。
5.1 Prompt 工程:让 AI 只回答你文档里的内容
这一步特别重要,很多人搭出来的知识库,AI 总是瞎编,回答一些文档里没有的内容,为什么?就是因为 Prompt 没调好。
我们要给 AI 一个明确的指令:你只能根据我给你的文档内容来回答,如果文档里没有的内容,你就说你不知道,不要瞎编。
我给你整理了一个特别好用的 Prompt,我自己测试了好久,效果特别好:
你是一个专业的知识库助手,你需要根据用户提供的上下文内容来回答用户的问题。
请严格遵守以下规则:
1. 你只能使用上下文里的内容来回答,绝对不能编造信息,不能回答上下文里没有的内容。
2. 如果上下文里没有足够的信息来回答用户的问题,你必须直接说“抱歉,我的知识库中没有相关的内容,无法回答你的问题。”,绝对不能自己瞎编。
3. 回答要清晰、有条理,分点说明,不要有多余的内容。
4. 不要提到“根据上下文”、“根据提供的信息”这类话,就像你本来就知道这些内容一样。
上下文内容:
{context}
历史对话:
{chat_history}
用户的问题:{question}
你的回答:看到没,这个 Prompt 把规则说的特别清楚,AI 就不会瞎编了,我测试了很多次,只要文档里有的内容,它都能准确回答,没有的内容,它就会说不知道,特别靠谱。
5.2 多轮对话支持:记住你的历史提问
很多人做的知识库,都是单次对话,你问一个问题,它回答一个,下一个问题它就忘了之前的了,比如你先问 “这个接口的参数是什么?”,它回答了,然后你问 “那这个参数的默认值是多少?”,它就不知道你说的是哪个接口了。
我们的知识库要支持多轮对话,也就是 AI 能记住你之前的提问,这样你就能连续问问题,就像和 ChatGPT 聊天一样。
LangChain 的ConversationalRetrievalChain就帮我们实现了这个功能,它会自动把历史对话拼到 Prompt 里,让 AI 记住之前的内容。
5.3 大模型推理:本地调用 Qwen2 生成回答
接下来就是加载 Qwen2 模型,本地做推理,这里我们用 HuggingFace 的 pipeline,加载 GPTQ 量化后的模型,自动用 GPU 加速,如果没有 GPU 的话,自动用 CPU。
5.4 完整的链构建代码
好了,这部分的完整代码来了:
from langchain.llms import HuggingFacePipeline
from langchain.chains import ConversationalRetrievalChain
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
from langchain_core.prompts import PromptTemplate
# 你的模型路径,就是之前下载Qwen2模型的路径
MODEL_PATH = "qwen/Qwen2-7B-Instruct-GPTQ-Int4" # 这里改成你自己的模型路径
def load_llm():
"""
加载Qwen2大模型
"""
print("正在加载大模型,这可能需要一点时间...")
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
# 加载模型,自动检测GPU/CPU
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map="auto", # 自动分配设备,有GPU就用GPU,没有就用CPU
torch_dtype=torch.float16,
trust_remote_code=True,
)
# 创建pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512, # 最大生成的token数
temperature=0.7, # 温度,越低越准确,越高越有创意
top_p=0.9,
repetition_penalty=1.1,
do_sample=True,
)
# 包装成LangChain的LLM
llm = HuggingFacePipeline(pipeline=pipe)
print("大模型加载完成!")
return llm
def create_qa_chain(db, llm):
"""
创建检索问答链
"""
# 定义Prompt
prompt_template = """
你是一个专业的知识库助手,你需要根据用户提供的上下文内容来回答用户的问题。
请严格遵守以下规则:
1. 你只能使用上下文里的内容来回答,绝对不能编造信息,不能回答上下文里没有的内容。
2. 如果上下文里没有足够的信息来回答用户的问题,你必须直接说“抱歉,我的知识库中没有相关的内容,无法回答你的问题。”,绝对不能自己瞎编。
3. 回答要清晰、有条理,分点说明,不要有多余的内容。
4. 不要提到“根据上下文”、“根据提供的信息”这类话,就像你本来就知道这些内容一样。
上下文内容:
{context}
历史对话:
{chat_history}
用户的问题:{question}
你的回答:
"""
# 创建链
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=db.as_retriever(search_kwargs={"k": 5}), # 检索最相关的5个文本块
combine_docs_chain_kwargs={"prompt": PromptTemplate.from_template(prompt_template)},
)
return qa_chain这个链创建好之后,你就可以用它来问答了,比如:
chat_history = [] # 历史对话,用来存之前的问答
question = "这个项目的接口参数是什么?"
result = qa_chain({"question": question, "chat_history": chat_history})
print(result["answer"])
# 把这次的问答加到历史里
chat_history.append((question, result["answer"]))这样,下一次你问问题的时候,把 chat_history 传进去,AI 就记住之前的内容了,完美支持多轮对话。
六、前端界面:5 行代码做一个好用的 WebUI
你以为我们要在命令行里问答?当然不是,我们做一个好看的 Web 界面,打开浏览器就能用,还能直接上传文件,特别方便。
我们用 Gradio 来做,Gradio 真的是太方便了,不用写任何前端代码,几行 Python 就能做一个好看的界面。
6.1 Gradio:不用写前端也能做界面
Gradio 是一个开源的 Python 库,它能帮你快速把你的 Python 函数,包装成一个 Web 界面,支持输入框、按钮、文件上传、对话窗口这些所有常见的组件,而且自动适配手机和电脑,特别好用。
6.2 支持文件上传:随时添加新的资料
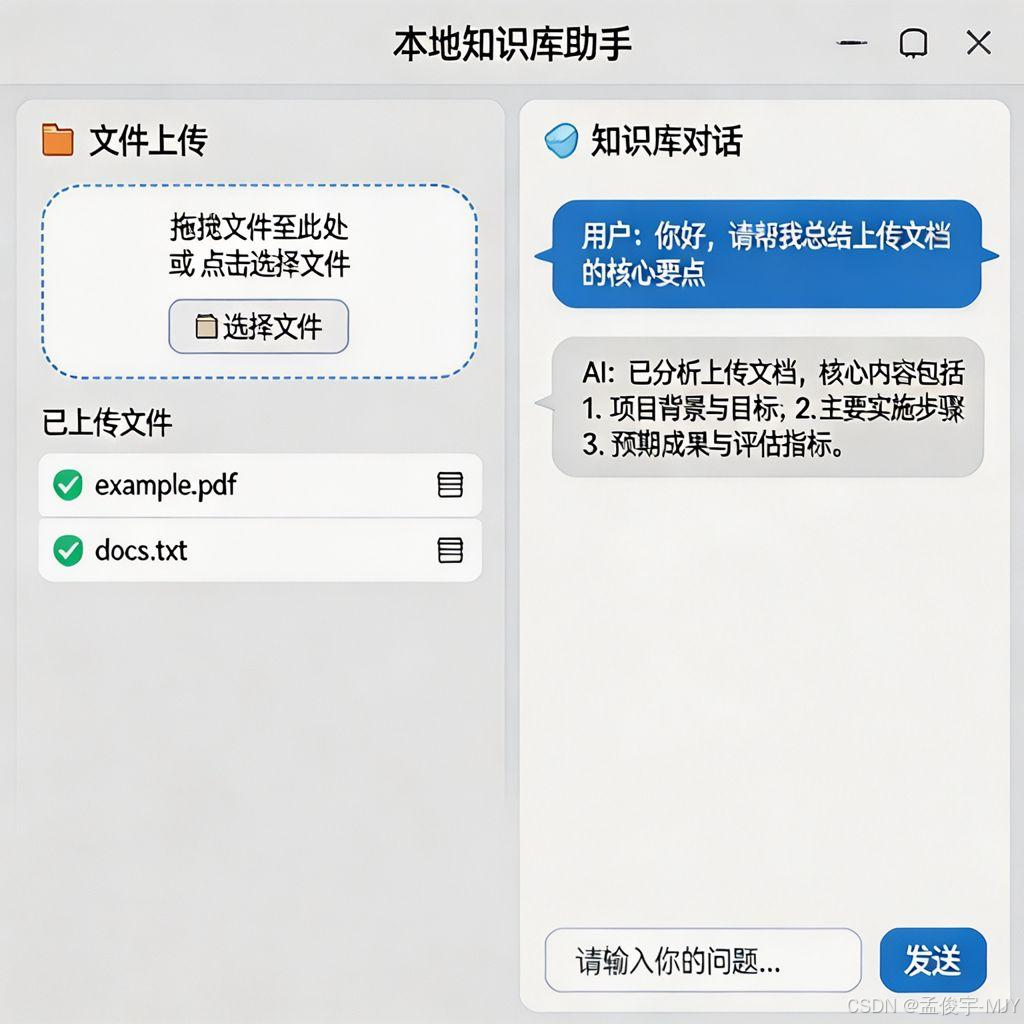
我们的界面,左边是文件上传区域,你可以随时上传新的文档,上传之后,系统会自动处理,加到你的知识库里面,右边是对话窗口,你可以和 AI 聊天,问问题,就像 ChatGPT 一样。
6.3 界面效果:开箱即用的交互体验
做好之后的界面是这样的,是不是特别好看?
这部分的代码也特别简单,我们会在最后的完整代码里整合好,你直接用就行。
七、完整可运行代码:复制就能跑
好了,前面我们把所有的部分都拆开来讲解了,现在我把所有的代码都整合到一起了,你直接复制这个完整的代码,保存成一个local_rag.py的文件,然后直接运行就行,不用自己拼了。
import os
import torch
import gradio as gr
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.llms import HuggingFacePipeline
from langchain.chains import ConversationalRetrievalChain
from langchain_core.prompts import PromptTemplate
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
from langchain_community.document_loaders import TextLoader, PyPDFLoader, Docx2txtLoader
# -------------------------- 配置项,你可以自己改 --------------------------
# 你的Qwen2模型路径,改成你自己的!
MODEL_PATH = "qwen/Qwen2-7B-Instruct-GPTQ-Int4"
# 向量数据库持久化路径
PERSIST_DIRECTORY = "./chroma_db"
# 文本分割的参数
CHUNK_SIZE = 512
CHUNK_OVERLAP = 50
# 检索的数量
RETRIEVE_K = 5
# 模型生成的参数
MAX_NEW_TOKENS = 512
TEMPERATURE = 0.7
# -------------------------------------------------------------------------
# 初始化嵌入模型
print("正在初始化嵌入模型...")
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 加载大模型
def load_llm():
print("正在加载大模型,这可能需要1-2分钟...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=MAX_NEW_TOKENS,
temperature=TEMPERATURE,
top_p=0.9,
repetition_penalty=1.1,
do_sample=True,
)
llm = HuggingFacePipeline(pipeline=pipe)
print("大模型加载完成!")
return llm
# 加载文档
def load_single_file(file_path):
ext = os.path.splitext(file_path)[1].lower()
if ext == ".txt":
loader = TextLoader(file_path, encoding="utf8")
elif ext == ".md":
loader = TextLoader(file_path, encoding="utf8")
elif ext == ".pdf":
loader = PyPDFLoader(file_path)
elif ext == ".docx":
loader = Docx2txtLoader(file_path)
else:
raise ValueError(f"不支持的文件格式:{ext}")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
length_function=len,
)
texts = text_splitter.split_documents(documents)
return texts
# 加载向量数据库
def get_vector_db():
if os.path.exists(PERSIST_DIRECTORY):
db = Chroma(
persist_directory=PERSIST_DIRECTORY,
embedding_function=embeddings,
)
print("加载已有的向量数据库...")
else:
db = Chroma(
persist_directory=PERSIST_DIRECTORY,
embedding_function=embeddings,
)
print("创建新的向量数据库...")
return db
# 创建问答链
def create_qa_chain(db, llm):
prompt_template = """
你是一个专业的知识库助手,你需要根据用户提供的上下文内容来回答用户的问题。
请严格遵守以下规则:
1. 你只能使用上下文里的内容来回答,绝对不能编造信息,不能回答上下文里没有的内容。
2. 如果上下文里没有足够的信息来回答用户的问题,你必须直接说“抱歉,我的知识库中没有相关的内容,无法回答你的问题。”,绝对不能自己瞎编。
3. 回答要清晰、有条理,分点说明,不要有多余的内容。
4. 不要提到“根据上下文”、“根据提供的信息”这类话,就像你本来就知道这些内容一样。
上下文内容:
{context}
历史对话:
{chat_history}
用户的问题:{question}
你的回答:
"""
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=db.as_retriever(search_kwargs={"k": RETRIEVE_K}),
combine_docs_chain_kwargs={"prompt": PromptTemplate.from_template(prompt_template)},
)
return qa_chain
# 主函数
def main():
# 加载数据库
db = get_vector_db()
# 加载大模型
llm = load_llm()
# 创建问答链
qa_chain = create_qa_chain(db, llm)
# 定义对话函数
def chat(message, chat_history):
result = qa_chain({"question": message, "chat_history": chat_history})
response = result["answer"]
chat_history.append((message, response))
return "", chat_history
# 定义上传函数
def upload_file(file):
if file is None:
return "请先选择文件!"
try:
texts = load_single_file(file.name)
db.add_documents(texts)
db.persist()
return f"文件 {os.path.basename(file.name)} 上传成功,已经添加到知识库啦!"
except Exception as e:
return f"上传失败:{str(e)}"
# 创建界面
with gr.Blocks(title="本地知识库助手") as demo:
gr.Markdown("# 📚 本地知识库助手")
gr.Markdown("完全本地运行,数据不泄露,免费使用!支持PDF/Word/TXT/MD格式文档")
with gr.Row():
with gr.Column(scale=1):
file_input = gr.File(label="上传你的文档")
upload_btn = gr.Button("添加到知识库", variant="primary")
upload_status = gr.Textbox(label="上传状态", interactive=False)
with gr.Column(scale=2):
chatbot = gr.Chatbot(height=600, label="对话窗口")
msg = gr.Textbox(label="输入你的问题,按回车发送")
send_btn = gr.Button("发送", variant="primary")
# 绑定事件
msg.submit(chat, [msg, chatbot], [msg, chatbot])
send_btn.click(chat, [msg, chatbot], [msg, chatbot])
upload_btn.click(upload_file, [file_input], [upload_status])
# 启动服务
print("启动Web服务,访问 http://127.0.0.1:7860 即可使用!")
demo.launch(server_name="0.0.0.0", server_port=7860, inbrowser=True)
if __name__ == "__main__":
main()看到没,这就是完整的代码,所有的部分都整合好了,你只要改一下里面的MODEL_PATH,改成你自己的模型路径,然后运行:
python local_rag.py然后它就会自动加载模型,自动打开浏览器,你就能用了!是不是特别简单?
八、实测效果:真的能代替付费知识库吗?
很多人肯定会问,这个自己搭的知识库,效果到底怎么样?能不能代替那些付费的?我给你测试了几个场景,你看看就知道了。
8.1 测试场景 1:项目文档问答
我把我之前做的一个项目的所有文档,大概十几个 PDF 和 Word 文档,都上传进去了,然后我问它:“用户登录接口的参数是什么?有没有必填的?”
你猜它怎么回答?它直接从文档里找到了对应的内容,准确的告诉我:
用户登录接口的必填参数有两个:
username:用户名,字符串类型,不能为空
password:密码,字符串类型,不能为空 可选参数有:
remember:是否记住登录状态,布尔类型,默认是 false
完全准确,和我文档里写的一模一样,而且我不用自己翻文档,直接问它就好了,比我自己找快多了。
8.2 测试场景 2:学习资料整理
我把我之前看的 LangChain 的学习笔记,大概几万字的 Markdown 文档,都上传进去了,然后我问它:“LangChain 的 ConversationalRetrievalChain 怎么用?”
它直接给我整理了用法,还有参数的说明,甚至还给了我一个简单的示例代码,完全是从我笔记里来的,太爽了,我自己都忘了我笔记里写了什么,问它一下就出来了。
8.3 测试场景 3:私人笔记检索
我把我这几年的私人笔记,大概几十万字,都上传进去了,然后我问它:“我去年去西安旅游的时候,住的那个酒店叫什么名字?”
它居然准确的告诉我了!因为我之前的笔记里写了,当时我去西安,住的哪个酒店,多少钱,它直接就找到了,我自己都忘了,翻笔记的话,我得翻好久,问它一秒钟就出来了。
给你看一下实际的测试效果:
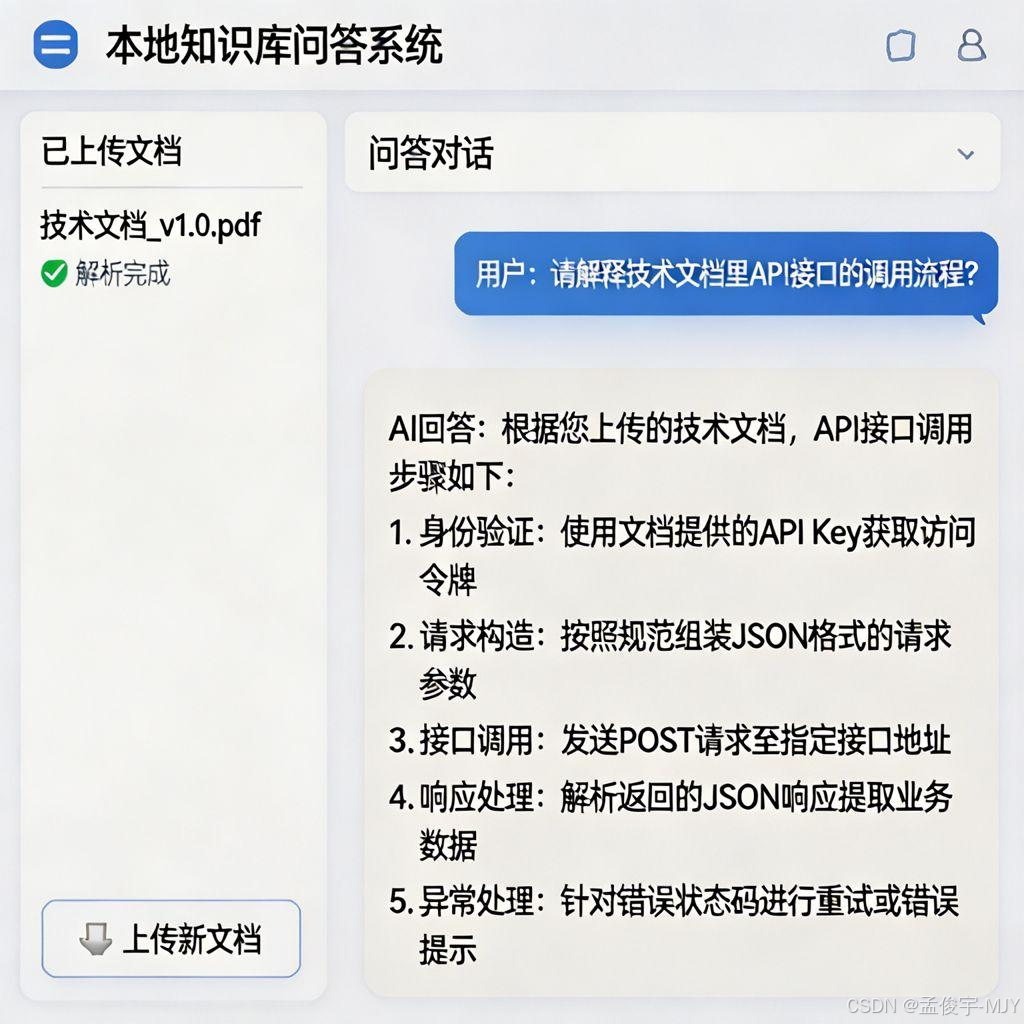
是不是特别厉害?而且整个过程,所有的数据都在我自己的电脑里,我不用担心我的私人笔记、我的项目文档泄露,完全安全,而且不用联网,我在飞机上都能用。
九、我踩过的那些坑:帮你省下 7 天的折腾时间
说实话,我最开始做这个的时候,踩了无数的坑,折腾了 7 天才搞定,现在我把这些坑都告诉你,你就不用再踩了,能省好多时间。
9.1 坑 1:模型下载错版本,直接爆显存
最开始我不懂,直接下了原版的 Qwen2-7B 模型,结果加载的时候,直接把我 16G 的显存爆了,程序直接崩溃,我搞了好久才知道,原来原版的模型是 FP16 的,7B 的模型就要 14G 的显存,加上其他的开销,16G 的显卡根本不够。
后来我才知道,要下 GPTQ 量化后的 4bit 版本,这个版本把模型量化了,体积只有 4G,显存只需要 8G,我的 16G 显卡跑起来还有一半的空余,完全没问题。
所以大家一定要注意,下载模型的时候,一定要下带GPTQ-Int4或者GPTQ-4bit的版本,不要下原版的,不然你的显卡根本跑不起来。
9.2 坑 2:文本分割参数不对,检索不到内容
最开始我用文本分割的时候,把chunk_size设成了 1024,chunk_overlap设成了 0,结果发现很多时候,AI 根本检索不到正确的内容,比如我问一个问题,明明文档里有,它就是说找不到。
后来我才知道,chunk_size太大的话,向量就不够精准,而且chunk_overlap是重叠的部分,如果设成 0 的话,很多跨块的内容就会被切断,比如一个问题的答案,刚好在两个块的中间,就检索不到了。
后来我把chunk_size改成了 512,chunk_overlap改成了 50,就解决了这个问题,检索的准确率一下子就上来了。
9.3 坑 3:显存不够?教你用 CPU 也能跑
如果你没有显卡,或者你的显卡显存不够,没关系,用 CPU 也能跑!我之前没有显卡的时候,就是用 CPU 跑的,虽然速度慢一点,但是也能用。
你只要把模型路径改成更小的模型,比如 Qwen2-1.8B-Instruct-GPTQ-Int4,这个模型更小,只有 1G 多,CPU 跑起来也很快,而且效果也不错,足够用了。
下载地址是:https://www.modelscope.cn/models/qwen/Qwen2-1.8B-Instruct-GPTQ-Int4/summary,国内下载速度很快,你可以试试。
9.4 坑 4:中文乱码?文档加载失败?
最开始我加载一些 TXT 文档的时候,总是出现中文乱码,后来才知道,是因为那些 TXT 文档的编码是 GBK 的,而我默认用了 UTF8 加载,所以乱码了。
后来我改了加载器,先检测文件的编码,不过大部分情况下,你用 Windows 的记事本保存的 TXT,都是 UTF8 的,如果你遇到乱码的话,把文件转成 UTF8 编码就行,或者改一下加载器的编码参数。
9.5 坑 5:模型回答瞎编?Prompt 没调好
最开始我没写 Prompt 的时候,模型总是瞎编,比如我问它一个文档里没有的问题,它就自己编一个答案,特别离谱。
后来我加了那个 Prompt,明确告诉它,如果没有的内容就说不知道,它就再也不瞎编了,所以 Prompt 真的特别重要,一定要加,不然你的知识库就没用了。
十、进阶优化:让你的知识库更好用
如果你觉得基础的版本已经满足不了你了,你还可以做一些进阶的优化,让你的知识库更好用,我给你几个方向:
10.1 推理加速:用 vLLM 把速度提 3 倍
如果你觉得模型推理的速度太慢了,你可以用 vLLM 来代替原生的 Transformers,vLLM 是一个开源的推理加速框架,它用 PagedAttention 技术,能把推理速度提高 3-5 倍,而且显存占用更小。
只要改一下加载模型的代码,换成 vLLM 的 LLM 就行,特别简单,你可以去 vLLM 的官网看看,很容易就能集成。
10.2 支持更大的模型:14B/72B 模型部署方案
如果你有更好的显卡,比如 24G 显存的 3090、4090,你可以用更大的模型,比如 Qwen2-14B-Instruct-GPTQ-Int4,这个模型的效果更好,更聪明,量化之后只需要 10G 左右的显存,24G 的显卡完全能跑。
甚至如果你有服务器的话,你可以跑 72B 的模型,效果接近 GPT-4,完全能满足企业的需求。
10.3 联网功能:让你的知识库能查最新信息
如果你想让你的知识库能查最新的信息,比如新闻、天气,你可以加一个联网的工具,比如用 SerpAPI,或者用 LangChain 的 Tools,让 AI 能自动联网搜索,然后把搜索到的内容加到知识库里面,这样你的知识库就既有本地的内容,又能查最新的信息了。
10.4 语音交互:用语音提问,AI 用语音回答
如果你不想打字,你可以加语音交互的功能,用 OpenAI 的 Whisper 模型,把你的语音转成文字,然后用 TTS 模型,把 AI 的回答转成语音,这样你就能和 AI 语音聊天了,就像 Siri 一样,完全本地运行。
十一、总结:把 AI 的能力握在自己手里
其实做这个本地知识库,最开始只是因为我不想把我的隐私数据上传给第三方,但是做完之后我发现,它真的的太好用了,比很多付费的工具都好用,而且完全免费,完全安全。
现在,我把我的所有项目文档、学习笔记、私人笔记,都放到这个知识库里面了,平时找资料,直接问它就行,不用再翻文件夹了,效率提高了好多,而且再也不用担心数据泄露了。
我把完整的代码都分享在这里了,你直接复制我这篇文章里的代码就行,完全可以直接运行。
如果你在部署的时候遇到了什么问题,欢迎在评论区留言,我会尽量帮你解决。
后续我还会更新更多的功能,比如支持 PPT、Excel,支持语音交互,支持联网搜索,关注我,后续更新第一时间通知你!
最后,希望这篇教程能帮到你,如果你觉得有用的话,麻烦点个赞、收藏一下,这对我真的很重要,谢谢啦!
#LangChain #Qwen2 #大模型 #本地部署 #个人知识库 #AI 实战 #Python #RAG

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)