【AAAI2026】EccoMamba 如何修复 Mamba 的空间感知短板?

近年来,Mamba 在视觉任务中的热度持续上升。相比 Transformer,Mamba 具备线性复杂度的长程建模优势,因此被越来越多地用于医学图像分割。但问题也很明显:医学图像不是普通序列。器官边界、病灶轮廓、心脏结构、腹部多器官区域,往往高度依赖二维空间连续性和多尺度解剖结构。传统 Mamba 在处理图像时,通常需要把二维特征展平成一维序列,这会不可避免地削弱图像原有的空间关系。
本文介绍AAAI2026上一篇名为 EccoMamba: Enhanced Cross-hierarchical Continuity Orthogonal Mamba for Medical Image Segmentation 的论文,改论文提出了一种面向医学图像分割的 Mamba 改进框架。本文就其模型思想进行拆解,并将源码中复杂的依赖拆除,构建出核心模块的可插拔模块,方便读者研究和复用。
1. 论文要解决的核心问题
这篇论文的出发点很明确:Mamba 很适合做长程依赖建模,但它原本是序列模型。放到图像分割里,通常要把二维图像展平成一维序列,这会带来三个问题:
第一,二维空间连续性被破坏。医学图像中的器官边界、病灶轮廓、心脏结构等高度依赖局部连续的二维几何关系。展平成 1D 后,原本相邻的像素或区域在序列中不一定保持自然邻接。
第二,方向偏置明显。传统 Mamba 的序列扫描往往带有固定方向,模型更容易沿某些方向捕捉依赖,而对水平、垂直或对称结构的感知不够均衡。论文特别指出,这会影响心脏亚结构、肿瘤边界等对空间对称性和连续性敏感的区域。
第三,缺少显式多尺度机制。医学图像里既有大器官,也有小病灶、细边界和低对比结构。单一尺度或隐式尺度建模不足,容易导致小结构漏分、大结构边界粗糙。
EccoMamba 的设计基本就是围绕这三个问题展开:HAE 解决多尺度与语义增强问题,SCO 解决方向偏置与空间连续性问题,VSS/Mamba 负责长程依赖建模。
2. 方法总体结构:一个增强版 Mamba U-Net
EccoMamba 是一个 U-shaped encoder-decoder 框架,整体继承了医学分割中非常常见的 U-Net 范式:左侧编码器逐步降采样,右侧解码器逐步恢复分辨率,中间通过 skip connection 传递浅层空间信息。它的关键变化在于:编码器每一层不是简单堆卷积或 Transformer,而是包含:
- HAE 模块:增强多尺度局部与层级语义特征;
- VSS Block:利用视觉 Mamba / state space mechanism 建模长程依赖;
- SCO 模块:放在 skip connection 上,对编码器传给解码器的特征做空间连续性修正。
论文图 1 是理解模型的关键:左侧展示整体 U 型结构,中间展示 HAE,右侧展示 SCO,下方展示 Axial Shifts 的水平/垂直正交移位机制。
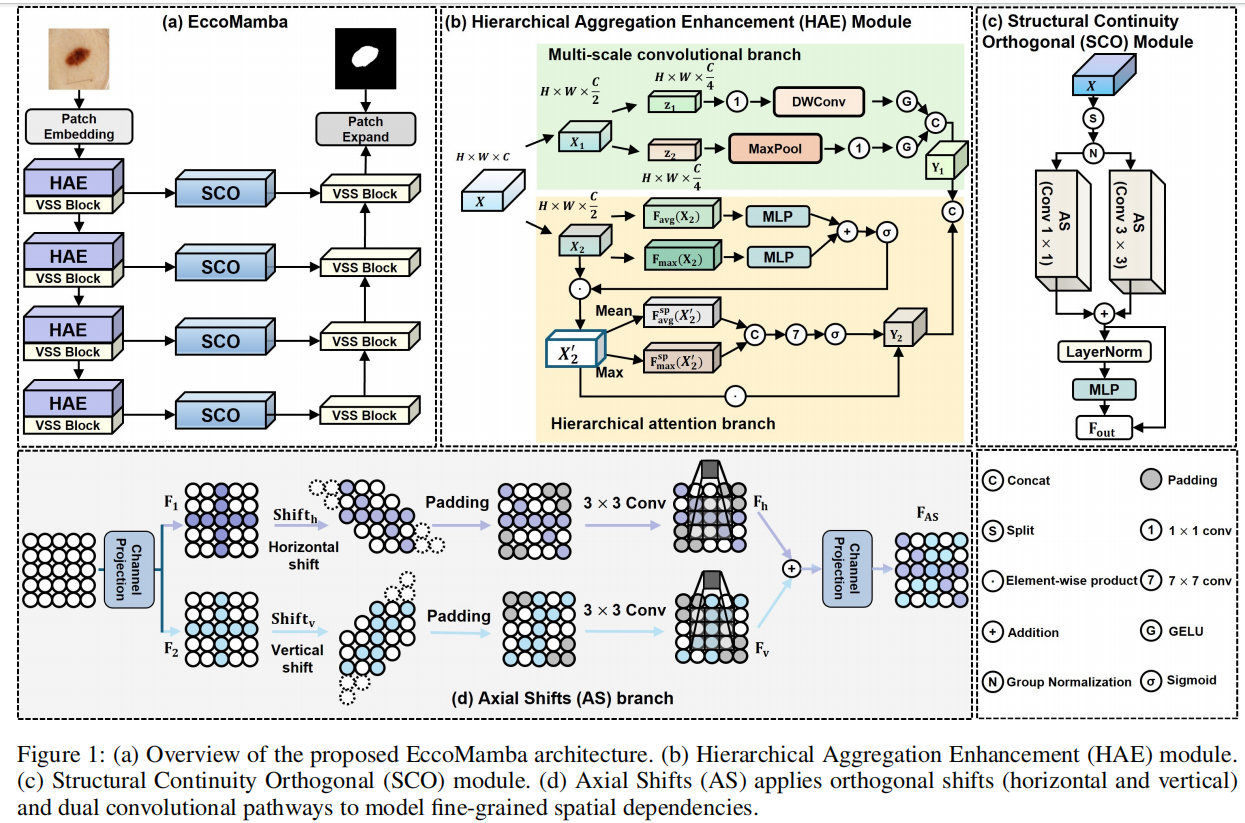
这套结构的思路可以概括为:
Mamba 负责“看得远”,HAE 负责“看得多尺度”,SCO 负责“看得连续且方向均衡”。
3. HAE 模块:解决多尺度解剖结构建模不足
HAE,全称 Hierarchical Aggregation Enhancement,是论文第一个核心模块。
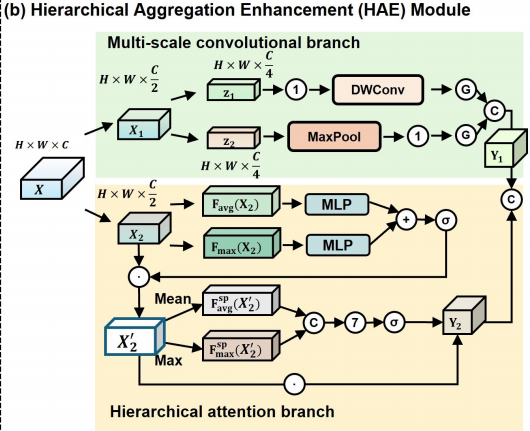
它把输入特征 X 沿通道维度一分为二:
- 一半走 多尺度卷积分支;
- 一半走 层级注意力分支。
多尺度卷积分支
这一支又分成两个路径:
一个路径用 1×1 conv + depthwise 3×3 conv + GELU,偏向提取细粒度局部纹理,例如病灶边界、器官细小轮廓。
另一个路径用 3×3 max pooling + 1×1 conv + GELU,偏向聚合更粗尺度上下文,例如病灶整体区域、器官主体形状。
这相当于在编码阶段显式加入“细节 + 上下文”的多尺度融合。
层级注意力分支
另一半特征先经过 channel attention,再经过 spatial attention。Channel attention 使用全局平均池化和最大池化,再经 MLP 得到通道权重。它回答的是:**哪些语义通道更重要?**Spatial attention 使用通道维度上的平均池化和最大池化,再经 7×7 conv 得到空间权重。它回答的是:图像中哪些位置更值得关注?
这和 CBAM 类似,但放在 Mamba 医学分割框架里,重点是补偿 Mamba 对局部结构和边界显著性的不足。
HAE 的作用
HAE 的核心价值不是单纯“加注意力”,而是把三类能力组合起来:
- 小尺度边界细节;
- 大尺度上下文;
- 通道与空间上的语义筛选。
从消融结果看,Base 的 ISIC 2018 DSC 是 88.52%,加 HAE 后提升到 90.42%,提升 1.90 个百分点,说明多尺度增强确实是主要增益来源之一。
4. SCO 模块:解决 Mamba 的方向偏置和空间不连续
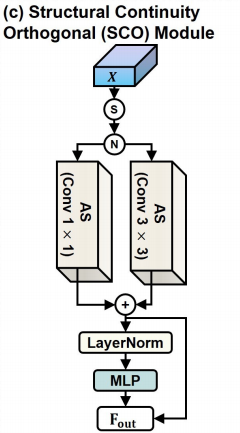
SCO,全称 Structural Continuity Orthogonal,是论文第二个核心模块,也是这篇论文相对更有特色的部分。它被放在 skip connection 上,而不是主干中。这一点很重要,因为 skip connection 主要传递浅层空间信息、边缘信息和定位信息。如果这些特征带有空间断裂或方向偏置,解码器恢复出的 mask 就容易边界错位或形状不连续。SCO 的主要操作是 Axial Shifts,轴向移位:
- 一部分特征做水平 shift;
- 一部分特征做垂直 shift;
- shift 后经过卷积;
- 水平与垂直结果融合;
- 再通过
1×1与3×3两条卷积分支进行细化。
论文里的公式可以简化理解为:
水平方向建模 + 垂直方向建模 → 正交融合 → MLP 细化 → 输出结构连续特征。
它的设计意图是让模型显式感知二维图像的两个正交方向,而不是依赖 Mamba 的一维扫描顺序。从消融看,Base 加 SCO 后 DSC 从 88.52% 提升到 90.22%,提升 1.70 个百分点。虽然略低于 HAE 单独提升,但它对结构连续性和边界一致性很关键。HAE+SCO 同时使用时达到 91.18%,说明两者互补。
5. 实验结果
整体性能强,但也有几个细节需要谨慎看待
论文在四个数据集上验证:
- ISIC 2018 / ISIC 2017:皮肤病灶分割;
- ACDC:心脏 MRI 分割;
- Synapse:腹部多器官 CT 分割。
ISIC 皮肤病灶分割
EccoMamba 在 ISIC 2018 上取得:Sens:90.84、Spec:96.82、Acc:95.17、DSC:91.18
在 ISIC 2017 上取得:Sens:88.60、Spec:98.29、Acc:96.84、DSC:89.39
这说明模型对病灶轮廓有较强捕捉能力,尤其是 DSC 表现突出。论文也通过可视化展示 EccoMamba 的轮廓更贴近 ground truth,红色预测边界与蓝色真实边界重合更好。Xu 等 - 2026 - EccoMamba Enhance…
不过这里有一个值得注意的文本问题:论文正文说 EccoMamba 在 ISIC 2018 上比 previous best 88.98% 高 2.20 个百分点,但表 1 中 MSCD-VM-UNet 的 DSC 是 90.21%,CC-ViM 是 90.06%。如果以表格为准,EccoMamba 相比最佳基线应是 91.18 - 90.21 = 0.97 个百分点,不是 2.20。这可能是论文中的表述错误。
ACDC 心脏分割
ACDC 上,EccoMamba 的平均 DSC 是 91.83%,优于 VM-UNet 和 MixFormer 的 91.04%。三个结构中:RV:89.91、MYO:89.71、LV:95.87
这说明模型对心脏结构的整体分割能力很强,尤其在 MYO 和 LV 上表现较好。但也要注意,HD95 并不是最优。EccoMamba 的 HD95 是 1.37,而 VM-UNet 是 1.30,Swin-UNet 是 1.32。所以如果只看 DSC,EccoMamba 最好;如果看边界最坏距离指标 HD95,它不是第一。
Synapse 多器官分割
Synapse 上,EccoMamba 平均 DSC 为 81.51%,是表中最高。器官级表现包括:
- Gallbladder:72.01,最好;
- Liver:95.29,最好;
- Spleen:90.18,接近最好;
- Stomach:81.67,最好;
- Pancreas:60.64,不是最好;
- Aorta:87.43,也不是最好。
这说明 EccoMamba 对大器官和形态复杂区域表现较强,但对一些小器官或低对比结构并非全面领先。同样,Synapse 的 HD95 是 22.02,不是表中最优。LeViT-UNet-384 的 HD95 是 16.84,UNetR 是 18.59,SWMA-UNet 是 18.30。因此更准确的评价是:
EccoMamba 在平均 DSC 上最强,但在 HD95 边界距离指标上不是最优。
6. 消融实验说明了什么
论文的消融实验很清晰:
| 模型 | DSC |
|---|---|
| Base | 88.52 |
| Base + HAE | 90.42 |
| Base + SCO | 90.22 |
| EccoMamba | 91.18 |
这组结果说明:HAE 和 SCO 都有效,而且 HAE 的单独贡献略大。HAE 更偏向提升语义和多尺度表达,SCO 更偏向提升结构连续性。最终组合后不是简单相加,但仍有进一步提升,说明两个模块确实解决的是不同瓶颈。
论文还做了 HAE 放置位置分析:
- Encoder + Decoder:ISIC 2018 DSC 90.51,ISIC 2017 DSC 88.55;
- Decoder only:ISIC 2018 DSC 89.48,ISIC 2017 DSC 88.76;
- Encoder only:ISIC 2018 DSC 91.18,ISIC 2017 DSC 89.39。
这个结果很合理:医学图像分割中,编码器阶段负责抽象语义与多尺度结构建模,早期增强有助于后续所有层级;而在 decoder 才增强,可能已经错过了最佳语义组织时机。
7. 复杂度与效率:不是轻量模型,而是性能-成本折中
EccoMamba 的复杂度为:
- 参数量:38.30M
- FLOPs:6.22G
- 显存:0.63GB
它比 nnFormer、TransUNet 这类重模型轻很多,但比 VM-UNet、H-VmUNet、ULVM-UNet 明显更重。例如 ULVM-UNet 只有 0.18M 参数和 0.06G FLOPs。Xu 等 - 2026 - EccoMamba Enhance…
所以这篇论文的效率定位不是“极致轻量”,而是:在可接受的计算开销下,用 HAE 和 SCO 换取更高分割精度和更好的结构一致性。
如果部署在临床边缘设备或移动端,EccoMamba 可能不如 ultra-light 模型合适;但如果目标是服务器端高精度分割,它的复杂度是可以接受的。
8. 论文的主要创新价值
这篇论文最值得关注的地方不是“又提出一个 U-Net 变体”,而是它对 Mamba 图像化应用的两个针对性修补:
第一,没有盲目相信 Mamba 的长程建模能力。作者明确承认 Mamba 对 2D 医学图像结构存在缺陷,然后用 HAE 和 SCO 补足。
第二,SCO 放在 skip connection 上是比较聪明的设计。很多方法把增强模块堆在 encoder 或 bottleneck,但 skip connection 才是 U-Net 保留空间细节的关键通道。对 skip feature 做方向均衡和连续性增强,能直接影响 decoder 的边界恢复质量。
第三,HAE 的设计符合医学图像特点。医学图像中目标尺寸跨度大、边界模糊、背景干扰多,单纯 Mamba 或单纯卷积都不够。HAE 的多尺度卷积 + 通道注意力 + 空间注意力是一个比较稳健的组合。
9. 不足与可质疑点
这篇论文也有一些需要谨慎看待的地方。
首先,部分实验表述和表格存在不一致。例如 ISIC 2018 的“previous best 88.98%”与表格中 MSCD-VM-UNet 90.21% 不一致。
其次,HD95 指标并不全面领先。ACDC 和 Synapse 上 EccoMamba 的 DSC 最好,但 HD95 不是最优。医学场景中边界距离有时比平均重叠更重要,尤其用于术前规划或器官风险区评估时。
第三,统计显著性描述不够充分。论文说做了 paired t-test 且 p < 0.01,但没有展示每个数据集、每个 baseline、每个器官的详细统计结果,也没有说明是否做多重比较校正。
第四,缺少更深入的模块可解释性分析。比如 SCO 的水平/垂直 shift 到底改善了哪些类型的错误?HAE 的注意力是否真的聚焦病灶区域?论文主要靠最终指标和可视化说明,还不够细。
第五,复杂度不算低。EccoMamba 参数量和显存均高于不少 Mamba 轻量模型,因此不能简单说它兼具最高效率和最高精度。
10. 一句话总结
EccoMamba 是一篇围绕 Mamba 医学图像分割缺陷进行结构性修补的论文:用 HAE 增强多尺度语义与边界表达,用 SCO 修复方向偏置和空间不连续,在多个医学分割数据集上取得了较强 DSC 表现;但它并非所有指标全面领先,尤其 HD95 和轻量化方面仍有改进空间。
11.可插拔模块制作
EccoMamba 的核心创新主要集中在用于提升多尺度和局部特征聚合的分层聚合增强 (HAE) 模块,以及用于缓解一维扫描方向性偏差、保持空间连续性的结构连续性正交 (SCO) 模块 。 下面我将这两个核心模块提取为独立、即插即用的 PyTorch 代码。以下代码无需依赖复杂的外部库(只需 torch 和 torch.nn),可以直接将其插入到现有的 U-Net 或其他架构的编码器/解码器中。
import torch
import torch.nn as nn
import torch.nn.functional as F
class HAE_Module(nn.Module):
"""
Hierarchical Aggregation Enhancement (HAE) Module
提取自 EccoMamba 编码器下采样路径
"""
def __init__(self, in_channels):
super(HAE_Module, self).__init__()
self.half_c = in_channels // 2
self.quarter_c = in_channels // 4
# --- Multi-scale convolutional branch (处理 X1) ---
# z1 path: 1x1 conv -> DWConv -> GELU
self.conv_z1_1x1 = nn.Conv2d(self.half_c, self.quarter_c, kernel_size=1)
self.dwconv_z1 = nn.Conv2d(self.quarter_c, self.quarter_c, kernel_size=3, padding=1, groups=self.quarter_c)
self.gelu = nn.GELU()
# z2 path: MaxPool 3x3 -> 1x1 conv -> GELU
self.maxpool_z2 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.conv_z2_1x1 = nn.Conv2d(self.half_c, self.quarter_c, kernel_size=1)
# --- Hierarchical attention branch (处理 X2) ---
# Channel Attention
self.ca_mlp = nn.Sequential(
nn.Linear(self.half_c, self.half_c // 2),
nn.ReLU(),
nn.Linear(self.half_c // 2, self.half_c)
)
# Spatial Attention
self.sa_conv = nn.Conv2d(2, 1, kernel_size=7, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# Split input along channel dimension
x1, x2 = torch.split(x, self.half_c, dim=1)
# --- Multi-scale convolutional branch ---
z1 = self.gelu(self.dwconv_z1(self.conv_z1_1x1(x1)))
z2 = self.gelu(self.conv_z2_1x1(self.maxpool_z2(x1)))
y1 = torch.cat([z1, z2], dim=1) # 融合形成 Y1
# --- Hierarchical attention branch ---
# Channel Attention
ca_avg = F.adaptive_avg_pool2d(x2, 1).view(x2.size(0), -1)
ca_max = F.adaptive_max_pool2d(x2, 1).view(x2.size(0), -1)
ca_weight = self.sigmoid(self.ca_mlp(ca_avg) + self.ca_mlp(ca_max))
x2_prime = x2 * ca_weight.unsqueeze(2).unsqueeze(3)
# Spatial Attention
sa_avg = torch.mean(x2_prime, dim=1, keepdim=True)
sa_max, _ = torch.max(x2_prime, dim=1, keepdim=True)
sa_concat = torch.cat([sa_avg, sa_max], dim=1)
sa_weight = self.sigmoid(self.sa_conv(sa_concat))
y2 = x2_prime * sa_weight
# Concat and Residual connection
out = torch.cat([y1, y2], dim=1)
return out + x
class AxialShift(nn.Module):
"""
Axial Shifts (AS) Component for SCO Module
"""
def __init__(self, in_channels, conv_type='1x1'):
super(AxialShift, self).__init__()
self.proj1 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
# Dual pathways with 3x3 conv
self.conv_h = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.conv_v = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
# 决定使用 1x1 还是 3x3 进行特征组合
if conv_type == '1x1':
self.combine = nn.Conv2d(in_channels, in_channels, kernel_size=1)
else:
self.combine = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
def forward(self, x):
f_proj = self.proj1(x)
# Horizontal shift (shift right by 1) and pad
f_h_shifted = F.pad(f_proj[:, :, :, :-1], (1, 0, 0, 0))
f_h = self.conv_h(f_h_shifted)
# Vertical shift (shift down by 1) and pad
f_v_shifted = F.pad(f_proj[:, :, :-1, :], (0, 0, 1, 0))
f_v = self.conv_v(f_v_shifted)
# Combine
f_as = self.combine(f_h + f_v)
return f_as
class SCO_Module(nn.Module):
"""
Structural Continuity Orthogonal (SCO) Module
提取自 EccoMamba 跳跃连接路径
"""
def __init__(self, in_channels):
super(SCO_Module, self).__init__()
self.half_c = in_channels // 2
self.as_1x1 = AxialShift(self.half_c, conv_type='1x1')
self.as_3x3 = AxialShift(self.half_c, conv_type='3x3')
self.norm = nn.GroupNorm(1, in_channels) # Using GroupNorm equivalent to LayerNorm for spatial data
self.mlp = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=1),
nn.GELU(),
nn.Conv2d(in_channels, in_channels, kernel_size=1)
)
def forward(self, x):
# Split along channel dimension
x1, x2 = torch.split(x, self.half_c, dim=1)
f_as_1x1 = self.as_1x1(x1)
f_as_3x3 = self.as_3x3(x2)
# Fused features
f_fused = torch.cat([f_as_1x1, f_as_3x3], dim=1)
# Context aggregation
f_out = self.mlp(self.norm(f_fused)) + f_fused
return f_out
12.几个可以考虑的改进点
个人思考,未进行尝试
(1)Boundary-aware SCO,专门优化边界和 HD95
EccoMamba 的 SCO 主要解决 skip connection 中的空间连续性问题,当前实现本质是“identity 半通道 + SCO refine 半通道”的跳连增强,我提取的可插拔模块也是按这个逻辑封装的。但它没有显式利用 边界监督。医学分割里 Dice 高不代表边界一定好,尤其 HD95 会被少量边界偏移、毛刺、断裂严重影响。可以改成:
Encoder feature
→ SCO
→ Boundary prediction head
→ Boundary-guided gate
→ Refined skip feature
也就是在 SCO 后加一个轻量边界分支:
(2)把固定 HAE 改成动态 HAE:Adaptive HAE / Dy-HAE
现在 HAE/MSC2 的分支比例是固定的:一部分走 max-pooling 粗尺度上下文,一部分走 attention,一部分走 depthwise conv 局部纹理;我提取的模块里也保留了这种固定拆分和残差输出方式。题是,不同任务需要的尺度不同:ISIC 病灶边界模糊,可能更需要 attention + 局部纹理;Synapse 大器官更需要粗尺度上下文;pancreas、gallbladder 这类小器官更需要细粒度结构。所以可以把 HAE 改成 动态分支加权:
Branch1: coarse context
Branch2: attention enhancement
Branch3: local detail
→ global descriptor
→ softmax branch weights
→ weighted fusion
(3)把 SCO 从水平/垂直扩展到多方向或可学习偏移
论文里的 SCO 主要通过水平和垂直 Axial Shift 缓解 Mamba 的方向偏置。但医学结构并不总是水平/垂直的,很多病灶边界、心肌轮廓、腹部器官边缘都是斜向、弯曲、不规则的。可以做三个版本:
在原有 horizontal / vertical shift 外加入两条对角线方向
Multi-scale SCO;
Deformable-SCO,更激进一点,可以把固定 shift 改成可学习 offset,接近 deformable convolution 的思路;
(4)现在创新主要在 encoder 和 skip,decoder 仍有提升空间

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)