刚刚,我让 AI 自己同步了 4 个平台草稿:工具调用才是下一场拐点
刚刚,我让 AI 自己同步了 4 个平台草稿:工具调用才是下一场拐点
晚上 8 点多,我让 AI 帮我选今天的文章题目。
如果这是 2023 年,它大概会在聊天框里列出十个标题,然后等我复制、筛选、再追问。
但这一次流程不太一样。
它先看了本地最近写过的文章,避开已经写过的 AI 史、Transformer、Agent 入门;又去查了最近的 OpenAI、NVIDIA、Anthropic 官方资料;然后挑出四个选题,把差异点、吸引点、参考来源一起发到飞书。
我没有按什么“审批格式”回复,只是随口回了一句:
4吧,但是我觉得你得考虑好差异点,吸引人的点,例子,专业性
AI 收到这句话后,没有结束对话,也没有让我重新把需求复制回聊天框。它继续沿着这个上下文往下走:确定选题、补资料、写草稿、检查图片、准备下一轮成稿确认。
这件事表面看只是“AI 帮我写文章”。
但真正值得注意的不是写文章,而是中间那条链路:它不再只是回答我,而是在工具之间移动,把一个真实流程往前推。
以前我们用软件,是人找工具。
写文章,你打开编辑器。查资料,你打开搜索。发公众号,你打开后台。同步到掘金、知乎、CSDN,你再打开一个个网页。中间遇到风险,比如标题要不要改、图片要不要换、要不要直接发布,你再切到微信或飞书问一句。
每一步都不难,但每一步都要人盯着。
而现在,真正有意思的事情开始发生了:AI 不只是回答“你该怎么做”,而是开始自己调用工具,把一段流程往前推。
它可以读本地文件,可以查网页,可以打开浏览器,可以调用同步工具,可以把草稿 URL 发到飞书等你确认,还可以根据你的回复继续做下一步。
这听起来像自动化,但它又不只是自动化。
传统自动化像一条固定流水线:第一步、第二步、第三步,条件写死,偏一点就失败。
工具调用时代的 AI 更像一个会看现场的执行者:它知道目标是什么,也知道自己手里有哪些工具;它会根据当前状态决定下一步;如果遇到边界,它会停下来找人对齐。
这就是今天这篇文章要讲的东西:AI 的关键变化,不是它更会聊天,而是它开始接入工具、状态、权限和人类确认,开始承担一段真实工作流。
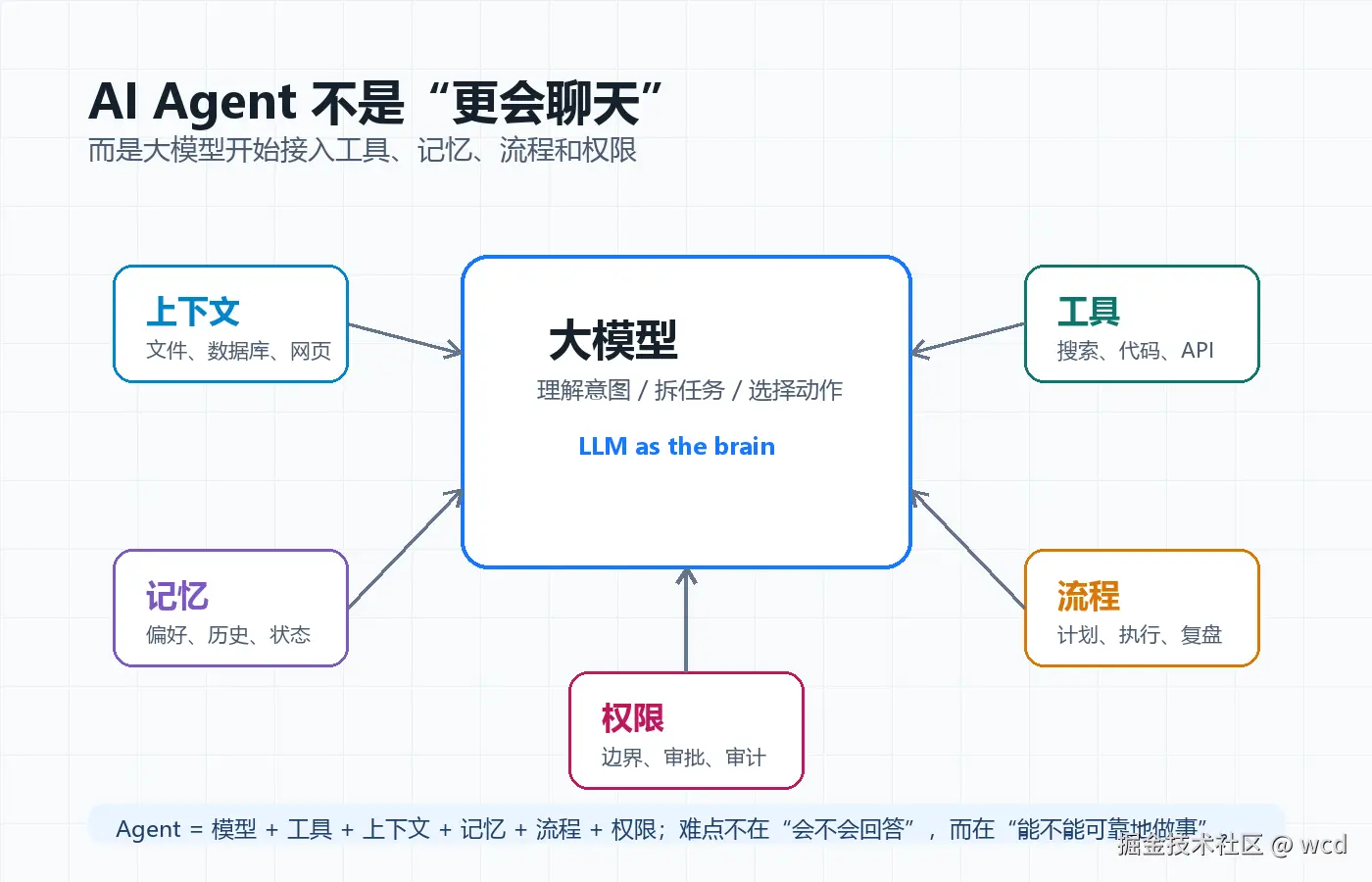
图:本文自制。一个能干活的 AI 系统,不只有模型,还包括工具、上下文、流程、权限和人类确认。
先讲一个真实场景
假设我要写一篇文章,然后发布到几个平台。
如果只用普通聊天 AI,流程大概是这样:
我问它:“今天写什么?”
它给我十个选题。
我再问:“哪个更好?”
它分析一通。
我说:“写吧。”
它生成一篇文章。
然后剩下的所有脏活都回到我身上:查资料是否可靠、改标题、找图片、保存 Markdown、打开同步工具、登录平台、同步草稿、检查封面、点发布、再去每个平台确认是不是发出去了。
这个阶段,AI 是一个文案助手。
但如果它接上工具,流程会变成另一种样子:
它先看本地已经写过哪些文章,避免选题撞车;再去查最近的权威来源,判断今天哪些热点有价值;然后把 3 到 5 个选题发到飞书,让我随便回一句;等我回“写第 4 个,但要有差异点、例子、专业性”,它继续写大纲和成稿;成稿前再发我对齐;发布前先用同步工具生成草稿 URL,再把草稿链接发给我;我确认后,它才继续最终发布。
这就不是“问一句答一句”了。
这是一个小型工作系统。
中间有搜索,有文件读写,有浏览器,有内容同步,有飞书消息,有人工确认,有发布验收。AI 不再只是坐在聊天框里给建议,而是在软件之间移动。
这个变化,才是工具调用真正重要的地方。
工具调用到底是什么
大模型本身不会打开网页,不会操作你的电脑,不会查数据库,也不会点击发布按钮。
大模型擅长的是理解语言、生成文本、推理下一步。它能判断“我现在需要查资料”“我应该读这个文件”“这里需要用户确认”,但它不能凭空完成这些动作。
工具调用就是把“模型的判断”接到“真实动作”上。
比如模型看到一句话:
帮我查一下这篇文章有没有发到掘金,如果没有就同步草稿。
没有工具时,它只能告诉你步骤:
你可以先登录掘金后台,然后检查草稿箱……
有工具时,它可以拆成动作:
这里的关键不是“AI 会调用一个函数”这么简单,而是它从语言世界跨进了操作世界。
过去,AI 的输出是答案。
现在,AI 的输出可以是动作。
为什么这比普通自动化更重要
很多人会说:这不就是自动化脚本吗?
不是。
脚本适合稳定流程:每天 9 点拉数据,生成报表,发邮件。输入格式固定,输出格式固定,中间路径固定。
但真实工作经常不是这样。
写文章时,今天选题可能要根据热点调整;资料来源可能有真有假;平台可能突然风控;公众号可能要扫码;知乎可能发布成功但公开页打不开;CSDN 可能没带封面;掘金可能要求分类和标签。
这些情况很难靠一条死脚本兜住。
工具调用的价值,是让模型在执行中“看见现场”:
- 看到登录状态失效,就停下来让用户登录。
- 看到平台只生成草稿,就不要谎称已经发布。
- 看到封面没上传,就回到编辑页补封面。
- 看到发布前需要确认,就把草稿 URL 发给用户。
- 看到用户回复“标题再尖锐一点”,就先改标题,而不是继续发布。
这类能力不是传统脚本擅长的。
传统脚本执行流程;AI 工具调用执行意图。
MCP 为什么突然重要
工具一多,就会出现另一个问题:每个工具都要单独适配。
今天接 GitHub,明天接 Slack,后天接数据库,再接浏览器、文件系统、飞书、发布工具。每接一个系统,就写一套接口。最后你会得到一堆碎片化连接器,很难维护,也很难让不同 AI 客户端复用。
这就是 MCP 这类协议出现的背景。
Anthropic 在 2024 年发布 Model Context Protocol 时,给出的定位很直接:它是一个连接 AI 助手和数据、业务工具、开发环境的开放标准,目标是把碎片化集成变成统一接口。官方介绍里提到,MCP 允许开发者把数据源暴露成 MCP server,也允许 AI 应用作为 MCP client 连接这些 server。
你可以把 MCP 理解成 AI 时代的“工具插座”。
模型不需要知道每个工具内部怎么实现。它只要知道:
- 这个工具叫什么;
- 它能做什么;
- 输入参数是什么;
- 返回结果是什么;
- 哪些动作需要权限或确认。
这样,AI 才能从“只在一个 App 里回答问题”,走向“跨多个系统完成任务”。
这也是为什么我觉得 MCP 的重要性常被低估。
它不是一个给开发者玩的新接口而已。它背后真正的问题是:如果 AI 要接管一段流程,谁来描述工具,谁来管理权限,谁来记录结果,谁来决定什么时候必须问人?
真正难的不是调用工具,而是知道什么时候停下来
很多工具调用演示都喜欢秀“AI 自动完成任务”。
但真正在工作里用,最关键的反而不是自动,而是边界。
比如发文章。
AI 可以写稿,可以同步草稿,可以检查图片,可以填标签。但要不要最终发布,最好不要让它自己悄悄决定。
因为发布不是一个技术动作,而是一个责任动作。
标题是否过火,观点是否准确,图片版权是否合适,平台是否会误判,是否要带某个链接,这些都不是模型单独承担得起的。
所以好用的 Agent 系统,不是一路狂奔,而是会在关键节点停下来。
它应该把问题列清楚:
- 我现在做到哪一步;
- 哪些地方不确定;
- 需要你帮我确认什么;
- 我下一步准备做什么;
- 如果你同意,我会继续到哪里。
然后等人类普通回复一句。
不需要固定格式,不需要“批准 ID”,不需要像审批系统那样僵硬。你回“可以,继续”,它继续;你回“标题再狠一点”,它改标题;你回“先别发知乎”,它就停掉知乎。
这才是更自然的人机协作。
工具调用让 AI 有了手;人类确认让这双手不乱伸。
为什么 Agent 时代会变贵
工具调用还有一个容易被忽略的现实问题:成本。
很多人以为 AI 成本就是“问一次多少钱”。但 Agent 不是问一次。
一个真正执行任务的 Agent,可能要连续调用模型几十次:读文件一次,分析一次,调用工具一次,读结果一次,改方案一次,再执行下一步。每一轮都带着上下文,每一轮都可能调用外部工具。
NVIDIA 在关于 Dynamo 的技术文章里提到,Claude Code、Codex 这类工具在一次编码会话里可能会发起数百次 API 调用,每次都携带完整对话历史。文章还用 KV cache 解释了 Agent 推理的特点:系统提示词和不断增长的上下文被反复复用,形成“写一次、读很多次”的访问模式。
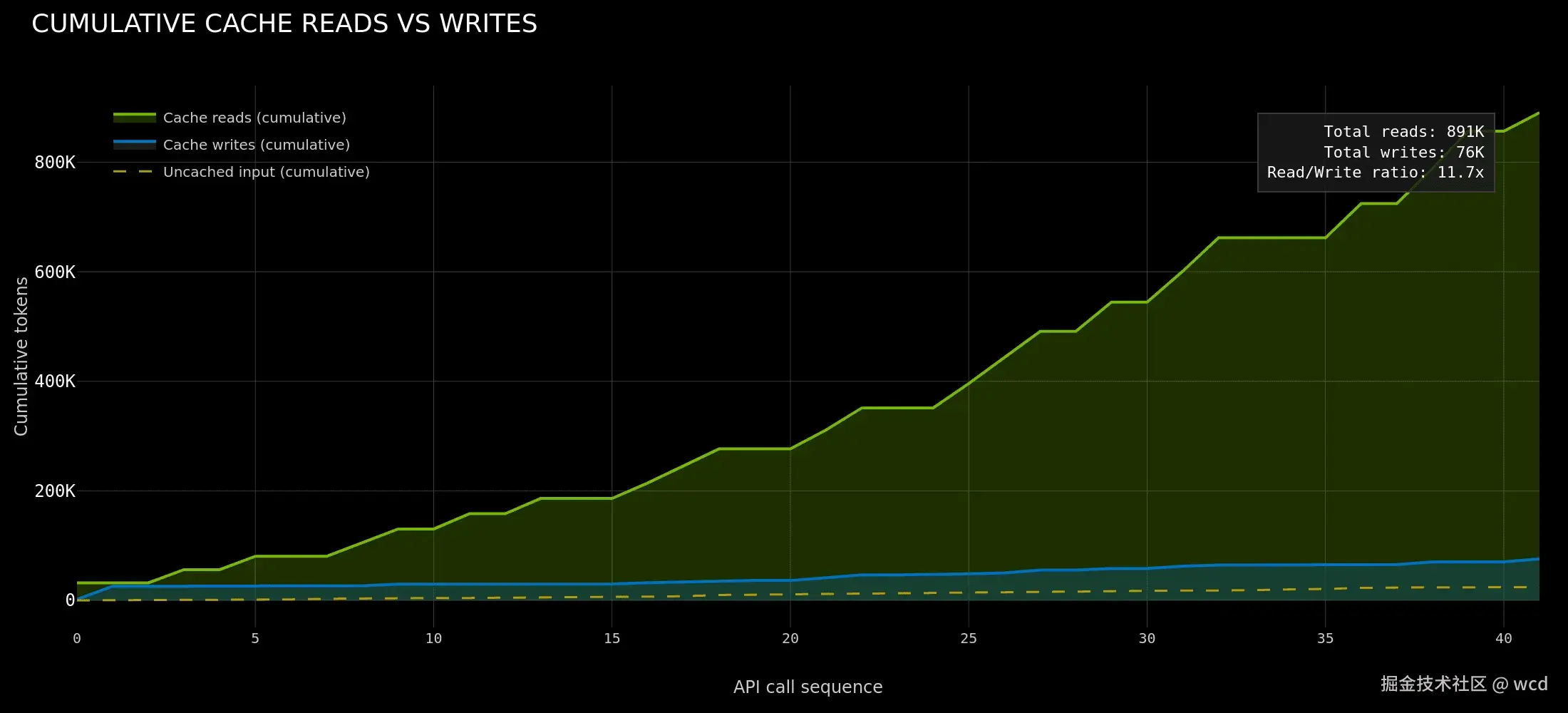
图源:NVIDIA Technical Blog, Full-Stack Optimizations for Agentic Inference with NVIDIA Dynamo, 2026-04-17。图中展示了 agentic inference 中 KV cache reads 明显快于 writes 的现象。
这张图说明了一个非常现实的趋势:AI 从聊天变成干活之后,压力不只在模型本身,还在推理系统。
以前你问一句,模型答一句。
现在一个 Agent 要长时间保持上下文,来回调用工具,等待用户确认,恢复任务现场,还要尽量少重复计算。这背后需要新的路由、缓存、调度和推理架构。
所以未来 AI 产品竞争,不只是“谁的模型更聪明”,还包括:
- 谁能更稳定地接工具;
- 谁能更便宜地跑长任务;
- 谁能保住上下文;
- 谁能处理用户中途修改;
- 谁能在关键动作前停下来问人;
- 谁能把执行过程留下可审计记录。
这就是为什么 NVIDIA 会把 Dynamo 这种推理基础设施讲成 AI 工厂的一部分。Agent 越普及,推理就越像电网和物流系统:平时用户看不见,但一旦它慢、贵、不稳定,整个体验都会崩。
语音会让工具调用更像“派活”
还有一个变化正在靠近:语音。
OpenAI 在 2026 年 5 月 7 日发布新的实时语音模型时,重点不只是“声音更自然”。官方介绍强调的是:实时语音模型要能在对话中理解上下文、调用工具、处理打断和修正,并把语音从简单问答推进到能实际完成任务。
这很关键。
因为键盘时代,我们和 AI 的交互像写工单:把需求打出来,等它处理。
语音时代更像派活:
这篇文章先别发公众号,掘金可以发,但封面换成第二张。知乎如果还风控就算了,明天再试。
这种话很自然,但里面包含多个动作、条件和边界:
- 公众号暂停;
- 掘金继续;
- 封面换图;
- 知乎遇到风控就停止;
- 明天再处理。
如果 AI 只是聊天,它只能复述。
如果 AI 接上工具,它就可以把这句话拆成执行计划。
语音不是简单输入方式变化。语音会让“人给 AI 派任务”这件事变得更自然,也会让工具调用进入更多普通人的工作流。
但别把工具调用神化
工具调用很重要,但它不是万能药。
它会带来新的问题。
第一,工具描述可能不清楚。模型以为工具能做 A,实际只能做 B,就会选错工具。
第二,权限边界可能不清楚。一个能读文件、发消息、点发布的 Agent,如果没有确认机制,风险会很大。
第三,工具结果可能不可靠。网页可能加载失败,平台可能返回假成功,接口可能超时,浏览器可能登录失效。
第四,模型可能过度自信。它可能把“草稿已保存”误当成“文章已发布”,把“打开编辑器 URL”误当成“公开 URL 可访问”。
所以一个成熟的工具调用系统,必须包含验收。
不是调用命令成功就算成功,而是要按用户真实路径验证。
发文章,就要打开公开 URL,看标题、正文、图片、封面是否正常。
改代码,就要跑测试,最好按真实启动路径验收。
查资料,就要给来源,区分事实、推断和观点。
工具调用让 AI 能做事,但验收决定它做的事靠不靠谱。
未来的软件,可能会变成“给 AI 用的”
过去的软件界面主要给人用。
按钮、菜单、表单、弹窗,都是围绕人的手和眼睛设计的。
但当 AI 开始调工具,软件会出现另一层接口:给 AI 用的接口。
这层接口不一定是 UI,也不一定是传统 API。它可能是 MCP server,可能是浏览器自动化能力,可能是一个本地 CLI,可能是一个带权限控制的工作流节点。
以后一个工具好不好用,可能不只看人用起来顺不顺,还要看 AI 能不能安全、稳定、可审计地调用它。
这会改变很多产品设计:
- 文档要更清楚,因为 AI 要读。
- API 要更语义化,因为 AI 要选。
- 错误信息要更可恢复,因为 AI 要根据错误继续。
- 权限要更细,因为 AI 不能什么都能做。
- 审计日志要更完整,因为人要知道 AI 做过什么。
这也是为什么“工具调用”不是一个小功能。
它会让软件从“人直接操作”变成“人设目标,AI 操作软件,人负责关键确认”。
这件事的真正分水岭
我觉得判断一个 AI 产品是否进入下一阶段,可以看一个简单标准:
它是在回答你,还是在替你推进事情?
回答你,当然有价值。
但推进事情,价值完全不同。
因为现实中的工作不是一条问题,而是一串状态。
今天写什么?资料是否可靠?标题怎么定?图片从哪里来?草稿是否同步?封面是否正常?平台有没有风控?要不要发布?发布后公开页能不能打开?
当 AI 能在这串状态里持续移动,它就不再只是“更强的搜索框”。
它开始像一个工作伙伴。
当然,这个伙伴还不成熟。它会误判,会卡住,会需要人类兜底。越是让它接近真实动作,越要设计权限、验收和对齐机制。
但方向已经很清楚。
过去十年,AI 的核心问题是:它能不能理解世界?
接下来几年,更关键的问题会变成:它能不能在世界里可靠地做事?
而工具调用,就是这道门。
参考资料
- OpenAI, Introducing GPT-5.5, 2026-04-23。
- OpenAI, Advancing voice intelligence with new models in the API, 2026-05-07。
- Anthropic, Introducing the Model Context Protocol, 2024-11-25。
- NVIDIA Technical Blog, Full-Stack Optimizations for Agentic Inference with NVIDIA Dynamo, 2026-04-17。
- NVIDIA Technical Blog, How NVIDIA Dynamo 1.0 Powers Multi-Node Inference at Production Scale, 2026-03-16。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)