基于深度正交增强生成模型的路面裂缝分割
https://www.sciencedirect.com/science/article/pii/S1569843225006351?via%3Dihub
文章信息
数据集链接: https://github.com/jeremy-2077/DORGM
关键词: 路面裂缝分割;生成模型;正交学习;贝叶斯聚类;深度学习
摘要
随着高分辨率路面图像为路面状况提供动态数字孪生,精准的裂缝分割成为构建智能养护系统的关键步骤。然而,大多数现有分割模型假设均匀采样条件并依赖固定参数,限制了其在多样化真实环境下的泛化能力。为应对这一挑战,我们提出一种深度正交增强生成模型(Deep Orthogonal-Enhanced Generative Model, DORGM)用于鲁棒的路面裂缝分割。所提出的框架引入两项关键创新:(1) 正交约束模块,在潜在空间中强制特征解耦,将条件特异性噪声与固有裂缝模式分离以减少干扰;(2) 软标签路由机制,自适应地将样本分配至专用通路,通过变分框架内的贝叶斯聚类捕捉细微的分布偏移。
这些模块可无缝集成至现有分割架构中,在无需额外重新训练的情况下提升适应性。在包括 DeepCrack、CRACK500、CFD 和 NHA12D 在内的基准数据集上进行的实验表明,与 PSPNet、DNLNet、PointRend、SegFormer 和 VPD 等基线方法相比,本方法在 mIoU 和 mDice 指标上均取得约 5% 的持续提升。通过在潜在空间中强制正交性,DORGM 有效解耦环境变化(如光照或天气引起的噪声)与核心裂缝特征,从而在异构数据源上实现稳定且可解释的分割结果。这种解耦进一步缓解了阻碍数字孪生应用的域偏移问题,使裂缝数据能够更可靠地与交通流、结构健康指标等其他城市图层进行融合。
1. 引言
在城市环境中,道路网络的功能对经济活动、公共出行和应急响应至关重要,系统且精准地量化路面裂缝可实现有针对性的养护干预,从而延长路面使用寿命、优化资产管理并最小化干扰。传统的路面状况评估主要依赖人工方式,劳动强度大,且受限于操作效率低、主观性强以及缺陷定位、记录和量化方面空间精度不足等问题(Dong 等,2022)。这些局限性在城市背景下尤为突出,因为道路网络的规模和运营复杂性需要更严谨、精准且基于计算机视觉的基础设施监测与养护规划方法(El Hakea 和 Fakhr,2023)。随着城市数字孪生技术的日益融合,道路基础设施的数字表征已成为实现城市资产实时数据驱动管理的关键(Cao 等,2023)。在此框架下,二维路面裂缝图像作为表面病害的微观数字表征,构成了路面数字孪生的基本要素,以可量化、可分析的方式反映道路表面的物理状况(Talaghat 等,2025)。
路面裂缝主要包括网状裂缝、横向裂缝、纵向裂缝、块状裂缝、错台、坑槽、斜向裂缝以及已密封裂缝等类型(Fan 等,2024)。弧形裂缝(形似弯曲椅状结构)也被认为是滑坡的重要指标,代表路面裂缝的一个重要类别(Collins,2008)。裂缝呈现出多种类型,每种类型在方向、宽度、连续性和表面粗糙度等几何属性上具有独特特征(图 1)。裂缝形态的固有变异性给自动检测与分类系统带来显著挑战,尤其在区分不同裂缝模式时。此外,裂缝图像的质量常因数据采集过程中的环境条件而受损。降水(Yoon 等,2024)、阴影(Fan 等,2023)和雾霾(Xia 等,2023)等不利因素会在采集图像中引入大量噪声和视觉失真。
图 1. 典型路面裂缝类型及其形态特征展示。
传统裂缝分割方法包括形态学操作、阈值分割和边缘检测技术。然而,这些方法易受复杂背景和光照变化的影响。随着全卷积网络(Fully Convolutional Networks, FCNs)(Long 等,2015)的引入,深度学习算法已广泛应用于裂缝分割任务(Wang 等,2022),实现了端到端的像素级分割,有效处理裂缝形态的复杂性。例如,U-Net 凭借其对称的编码器 - 解码器结构和跳跃连接,能够捕捉不规则、细长裂缝的局部特征(Ali 等,2024)。然而,在背景复杂或裂缝与周围对比度较低的场景中,其性能仍可能受限。近年来,Transformer 模型在视觉任务中的应用为裂缝分割提供了新的突破(Vaswani 等,2017)。Transformer 提取全局特征和建模长程依赖的能力已在裂缝分割任务中得到有效验证(Beyene 等,2023)。Vision Transformer(ViT)将图像划分为固定大小的图像块,并利用多头自注意力机制捕捉图像不同图像块之间的全局依赖关系(Eltouny 等,2024)。为同时增强局部裂缝特征学习和全局依赖建模,Yadav 等(2024)提出一种融合 CNN 与 ViT 的裂缝分割算法。此外,Chen 等(2024a)提出一种新型裂缝分割算法 PoolingCrack,将 U-Net-EB7 与 Transformer 架构相结合。这些研究表明,将自注意力机制集成到 CNN 和 FCN 中可显著提升裂缝分割精度并降低背景噪声的影响。
与 CNN 和 FCN 不同,Segment Anything Model(SAM)无需大量训练数据集,展现出强大的跨领域适用性,正日益应用于裂缝分割(Kirillov 等,2023;Naddaf-Sh 等,2025)。Transformer 架构与 CNN 模块的结合已成为当前裂缝分割研究的热点。例如,Wang 等(2024a)提出一种双路径裂缝分割算法,将轻量级 CNN 与改进的 Hilo 注意力机制相融合。类似地,Yu 等(2024)提出 CSTF 裂缝分割算法,将 Swin Transformer 与金字塔池化模块(Pyramid Pooling Module, PPM)相结合,显著提升了细长裂缝的分割精度。另一方面,通过修改 SAM 模型结构,Zhou 等(2024)提出一种基于 SAM 的轻量级裂缝分割框架。通过引入裂缝自适应层和稀疏提示生成方法,该方法同时提升了分割性能与效率。
尽管现有 Transformer 模型在提取裂缝全局信息方面表现有效,但仍存在显著局限。一个主要问题在于假设数据集采样均匀,而忽视了图像采集条件的固有差异。缺乏对此因素的考虑会导致模型分割性能下降。
为应对这一局限,本文提出一种新型深度正交约束生成模型。首先,构建特征正交模块,强制潜在空间中所有特征正交,从而分离不同条件下的特征。然后,我们将贝叶斯聚类方法扩展为即插即用模块,用于将不同条件的图像路由至不同的卷积层。基于此,设计一种新型基于软标签的路由机制以区分样本间的采样变化。随后,将这两个模块集成到深度生成框架中实现裂缝分割。在优化完整模型时,我们基于变分推断框架推导相应的模型优化算法。
该模型与城市数字孪生技术的融合进一步放大了其在智慧城市基础设施中的实际影响。城市数字孪生作为物理城市环境的动态高保真虚拟副本,整合多模态数据流——包括实时传感器输入、地理空间信息和预测模拟——以促进整体城市管理(Macatulad 和 Biljecki,2024;Lehtola 等,2022)。我们模型通过正交特征分离和自适应路由实现的鲁棒、条件无关的裂缝分割能力,与数字孪生的数据同化需求无缝契合。通过在潜在空间中强制正交性,模型将环境变化(如光照或天气引起的噪声)与固有裂缝特征解耦,确保即使在城市环境中典型的异构数据源下,分割输出仍保持一致且可解释。这种解耦缓解了常困扰数字孪生模型的域偏移问题,使裂缝数据能够更可靠地与交通流或结构健康指标等其他城市图层融合。
2. 框架与方法
在本节中,我们给出完整的分割框架(图 2)。为方便起见,我们将提出的深度正交生成模型命名为 DORGM。在常规分割框架中,数据集 X={xn}n=1NX=\{x_n\}_{n=1}^NX={xn}n=1N 中的样本采用相同的训练设置和模型参数。然而,不同条件下样本所需的分割模型参数可能存在冲突。
为解决此问题,我们的模型采用以下方案。首先,构建正交约束模块,强制不同条件下学习的特征正交。正交特征确保不同条件下的样本互不干扰,从而减少因模糊导致的分割误差。如图 3 所示,条件 A 和条件 B 的边界样本容易相互干扰。然而,由于边界差异微小,这种区分不易实现。如图 3 所示,通过应用正交约束,可显著增加边界样本之间的距离,从而降低相互干扰的可能性。
基于上述建立的正交特征,我们构建路由模块以处理不同条件下的裂缝分割。由于整个任务围绕裂缝分割展开,我们可以假设不同条件引入的变化较小。因此,可采用少量卷积层来表征这些差异,同时保持主分割网络不变。路由机制确保我们选择不同卷积层的能力。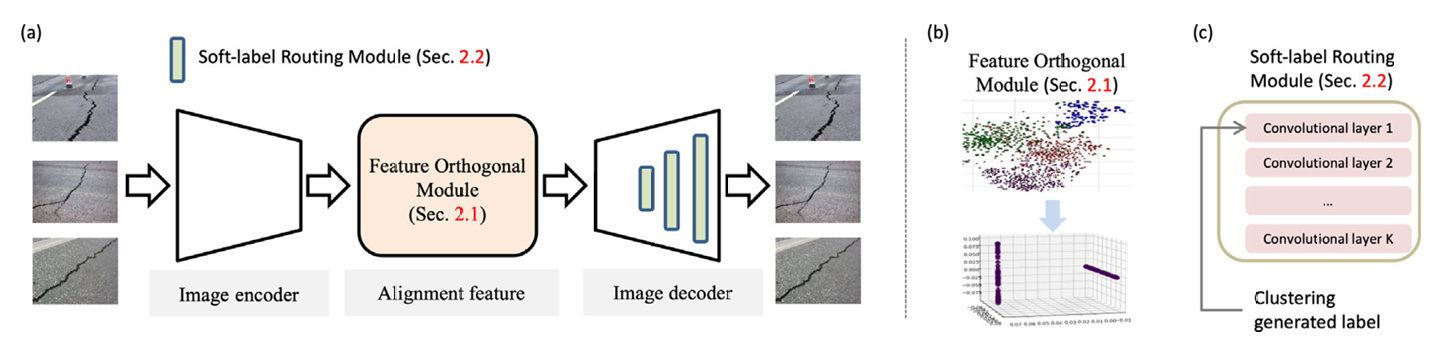
图 2. (a) 所提方法框架。我们的模型包含两个不同模块。第一个是特征正交模块,将隐藏空间中学习的特征转换为正交特征。第二个是软标签路由层,将给定样本路由至不同权重。(b) 特征正交模块将特征转换到正交空间。© 软标签路由层将样本路由至相应层。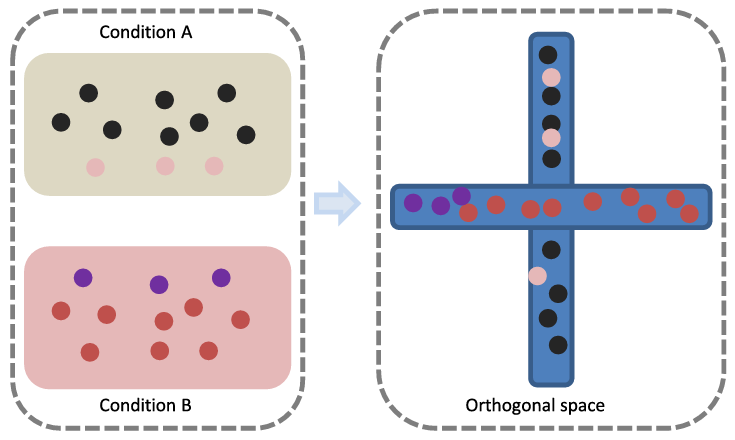
图 3. 如左图所示,边缘点的存在使得不同条件容易混淆;如右图所示,使用正交性可防止边缘点造成干扰。
2.1. 特征正交模块
给定隐藏层中学习的特征 {hl(xn)}n=1N\{h_l(x_n)\}_{n=1}^N{hl(xn)}n=1N,我们旨在实现正交特征。假设 hl(xi)h_l(x_i)hl(xi) 和 hl(xj)h_l(x_j)hl(xj) 来自相同条件,hl(xi)h_l(x_i)hl(xi) 和 hl(xk)h_l(x_k)hl(xk) 来自不同条件。在正交学习设定下,我们有:
hl(xi)Thl(xj)≠0,hl(xi)Thl(xk)=0 h_l(x_i)^T h_l(x_j) \neq 0, \quad h_l(x_i)^T h_l(x_k) = 0 hl(xi)Thl(xj)=0,hl(xi)Thl(xk)=0
但仅凭上述思路,优化仍然相当困难。问题如下:(1) 如何识别不同条件;(2) 如何确保学习到的特征正交。针对第一个问题,我们的模型很简单:利用聚类框架。但传统聚类不可微分,这意味着我们的模型无法将其集成到网络优化框架中。在下一小节中,我们采用贝叶斯学习来缓解此问题。
针对第二个问题,我们在隐藏层中引入线性映射。该层的权重固定,通过 QR 分解获得。即,给定隐藏特征 hl(xn)h_l(x_n)hl(xn),我们有:
LLT=QR([hl(xn)]T[hl(xn)])(1) LL^T = QR\left([h_l(x_n)]^T [h_l(x_n)]\right) \tag{1} LLT=QR([hl(xn)]T[hl(xn)])(1)
然后将线性层的权重设为 (L−1)T(L^{-1})^T(L−1)T。我们可以证明,通过该线性层学习到的特征 h^l(xn)\hat{h}_l(x_n)h^l(xn) 将满足正交约束:
[h^l(xn)]T[h^l(xn)]=[hl(xn)(L−1)T]T[hl(xn)(L−1)T]=L−1hl(xn)(L−1)Thl(xn)(L−1)T=L−1LLT(L−1)T=I(2) \begin{aligned} [\hat{h}_l(x_n)]^T [\hat{h}_l(x_n)] &= [h_l(x_n)(L^{-1})^T]^T [h_l(x_n)(L^{-1})^T] \\ &= L^{-1} h_l(x_n) (L^{-1})^T h_l(x_n) (L^{-1})^T \\ &= L^{-1} L L^T (L^{-1})^T = I \end{aligned} \tag{2} [h^l(xn)]T[h^l(xn)]=[hl(xn)(L−1)T]T[hl(xn)(L−1)T]=L−1hl(xn)(L−1)Thl(xn)(L−1)T=L−1LLT(L−1)T=I(2)
我们将带有正交约束模块的网络记为 OrNet(xn)\text{OrNet}(x_n)OrNet(xn)。
2.2. 软标签路由模块
在上一节中,我们将特征转换到正交空间,并利用聚类模型分离不同条件下的图像。但我们认为传统聚类方法总是不可微分的。因此,下文我们构建贝叶斯聚类框架来解决此问题,并将样本路由至不同条件,其中我们假设学习到的聚类指示器不再是离散值,而是软标签。
首先,我们的模型假设每个聚类服从高斯分布。但此假设与提出的正交约束不一致。为处理此问题,我们采用子空间聚类自表达方法(Peng 等,2016)并将其嵌入贝叶斯框架:
h^l(xn)=WnH^l(3) \hat{h}_l(x_n) = W_n \hat{H}_l \tag{3} h^l(xn)=WnH^l(3)
其中 h^l(xn)\hat{h}_l(x_n)h^l(xn) 是隐藏层 lll 中学习到的正交特征;H^l\hat{H}_lH^l 是正交特征的集合。在上述讨论中,我们建立了基于高斯模型的正交空间聚类方法。然而,上述模型仍存在一个问题:正交特征学习未考虑相关性。即,空间相似的样本可能满足正交性,但不一定满足相似性。为解决此问题,我们使用图约束生成过程。基于上述讨论,我们有以下生成过程:
- 对于 n∈{n}1∞n \in \{n\}_{1}^{\infty}n∈{n}1∞, θn∼G0(λ)\theta_n \sim G_0(\lambda)θn∼G0(λ)
- 对于 n∈{n}1Nn \in \{n\}_{1}^{N}n∈{n}1N, zn∼mult(α)z_n \sim \text{mult}(\alpha)zn∼mult(α)
- 对于 n∈{n}1Nn \in \{n\}_{1}^{N}n∈{n}1N, Wn,⋅∼N(Wn,⋅∥θzn)W_{n,\cdot} \sim \mathcal{N}(W_{n,\cdot} \| \theta_{z_n})Wn,⋅∼N(Wn,⋅∥θzn)
- 对于 n∈{n}1Nn \in \{n\}_{1}^{N}n∈{n}1N, x^n∼N(x^n∥0,σ^)\hat{x}_n \sim \mathcal{N}(\hat{x}_n \| 0, \hat{\sigma})x^n∼N(x^n∥0,σ^), X^={x^n}n=1N\hat{X} = \{\hat{x}_n\}_{n=1}^NX^={x^n}n=1N
- 对于 n∈{n}1Nn \in \{n\}_{1}^{N}n∈{n}1N, x^n∼N(x^n∥Wn,⋅X^,σ^)R(⋅∥0,σ^)\hat{x}_n \sim \mathcal{N}(\hat{x}_n \| W_{n,\cdot} \hat{X}, \hat{\sigma}) \mathcal{R}(\cdot \| 0, \hat{\sigma})x^n∼N(x^n∥Wn,⋅X^,σ^)R(⋅∥0,σ^)
- 对于 ln,jl_{n,j}ln,j: ln,j∼N(ln,j∥∥x^n−x^j∥22An,j,σ^)l_{n,j} \sim \mathcal{N}(l_{n,j} \| \|\hat{x}_n - \hat{x}_j\|_2^2 A_{n,j}, \hat{\sigma})ln,j∼N(ln,j∥∥x^n−x^j∥22An,j,σ^)
- 对于 k∈{k}1Kk \in \{k\}_{1}^{K}k∈{k}1K, F^n∼N(F^∥0,I)\hat{F}_n \sim \mathcal{N}(\hat{F} \| 0, I)F^n∼N(F^∥0,I)
- 对于 n∈{n}1Nn \in \{n\}_{1}^{N}n∈{n}1N, yn∼N(F^∥F(x^n)+F^zn(x^n),σ^)y_n \sim \mathcal{N}(\hat{F} \| F(\hat{x}_n) + \hat{F}_{z_n}(\hat{x}_n), \hat{\sigma})yn∼N(F^∥F(x^n)+F^zn(x^n),σ^)
其中 G0G_0G0 是参数为 λ={c0,v0,B0,u0}\lambda = \{c_0, v_0, B_0, u_0\}λ={c0,v0,B0,u0} 的 Wishart-正态分布。x^n\hat{x}_nx^n 是隐藏变量,由我们的模型假设,并将在下文讨论中与隐藏特征 h^l(xn)\hat{h}_l(x_n)h^l(xn) 建立联系。N(ln,j∥∥x^n−x^j∥22An,j,σ^)\mathcal{N}(l_{n,j} \| \|\hat{x}_n - \hat{x}_j\|_2^2 A_{n,j}, \hat{\sigma})N(ln,j∥∥x^n−x^j∥22An,j,σ^) 在我们的模型中引入图约束。N(x^n∥Wn,⋅X^,σ^)R(⋅∥0,σ^)\mathcal{N}(\hat{x}_n \| W_{n,\cdot} \hat{X}, \hat{\sigma}) \mathcal{R}(\cdot \| 0, \hat{\sigma})N(x^n∥Wn,⋅X^,σ^)R(⋅∥0,σ^) 给出自表达。N()\mathcal{N}()N() 表示具有不同参数的正态分布。σ^\hat{\sigma}σ^ 是正态分布的协方差,我们将其设为单位矩阵;Fzn(x^n)F_{z_n}(\hat{x}_n)Fzn(x^n) 是一个神经网络。
2.3. 模型推断与优化
基于给定模型,模型的关键任务是:(1) 将上述正交特征模块嵌入生成框架;(2) 提出相应的训练算法。在本节中,我们首先通过后验概率估计将正交特征模块引入模型优化过程。然后,通过在学习阶段最大化似然概率,提出模型的训练方法。注意,最大化似然函数可能引入难以处理的积分问题,即模型的归一化项变得过于复杂而无法计算。因此,我们引入一个下界函数:
log∏n=1Np(yn)≥∫q(Ω)logp(Y,Ω,α,λ) d(Ω)(4) \log \prod_{n=1}^N p(y_n) \geq \int q(\Omega) \log p(Y, \Omega, \alpha, \lambda) \, d(\Omega) \tag{4} logn=1∏Np(yn)≥∫q(Ω)logp(Y,Ω,α,λ)d(Ω)(4)
此处,我们定义 q(Ω)q(\Omega)q(Ω) 为变分后验分布,Ω={V,θ,Z,W,X^}\Omega = \{V, \theta, Z, W, \hat{X}\}Ω={V,θ,Z,W,X^} 为上述生成模型中的隐藏变量,p(X,Ω,α,λ)p(X, \Omega, \alpha, \lambda)p(X,Ω,α,λ) 是生成过程中给定潜在变量的联合概率。对于 Ω\OmegaΩ 的变分后验分布,我们有:
q(X,Ω,α,λ)=∏k=1Kqγk(F^)∏k=1Kqτk(θk)∏n=1N{qϕn(zn)qζn(x^n)qηn(Wn,⋅)} q(X, \Omega, \alpha, \lambda) = \prod_{k=1}^K q_{\gamma_k}(\hat{F}) \prod_{k=1}^K q_{\tau_k}(\theta_k) \prod_{n=1}^N \left\{ q_{\phi_n}(z_n) q_{\zeta_n}(\hat{x}_n) q_{\eta_n}(W_{n,\cdot}) \right\} q(X,Ω,α,λ)=k=1∏Kqγk(F^)k=1∏Kqτk(θk)n=1∏N{qϕn(zn)qζn(x^n)qηn(Wn,⋅)}
其中 qγk(vk)q_{\gamma_k}(v_k)qγk(vk) 定义为参数 γk={γk,1,γk,2}\gamma_k = \{\gamma_{k,1}, \gamma_{k,2}\}γk={γk,1,γk,2} 的高斯分布,作为变量 F^\hat{F}F^ 的后验;qτk(θn)q_{\tau_k}(\theta_n)qτk(θn) 是参数化为 τk={ck,uk,vk,Bk}\tau_k = \{c_k, u_k, v_k, B_k\}τk={ck,uk,vk,Bk} 的 Wishart-正态分布,作为 θn\theta_nθn 的后验;qϕn(zn)q_{\phi_n}(z_n)qϕn(zn) 定义为参数 ϕn={ϕn,k}k=1K\phi_n = \{\phi_{n,k}\}_{k=1}^Kϕn={ϕn,k}k=1K 的分类分布,作为 znz_nzn 的后验。qζn(x^n)q_{\zeta_n}(\hat{x}_n)qζn(x^n) 是由神经网络参数化的高斯分布,其中 ζn={ζn,1,ζn,2}\zeta_n = \{\zeta_{n,1}, \zeta_{n,2}\}ζn={ζn,1,ζn,2} 是神经网络的输出。qηn(Wn,⋅)q_{\eta_n}(W_{n,\cdot})qηn(Wn,⋅) 定义为高斯分布,其中分布参数为 ηn={ηn,1,ηn,2}\eta_n = \{\eta_{n,1}, \eta_{n,2}\}ηn={ηn,1,ηn,2}(ζn,1,ηn,1\zeta_{n,1}, \eta_{n,1}ζn,1,ηn,1 为均值;ζn,2,ηn,2\zeta_{n,2}, \eta_{n,2}ζn,2,ηn,2 为分布协方差)。
基于式 (4) 给出的下界,我们可以使用基于梯度的方法更新下界,并得到以下更新规则:
uk=1ck(c0u0+Sk)(5) u_k = \frac{1}{c_k} (c_0 u_0 + S_k) \tag{5} uk=ck1(c0u0+Sk)(5)
ck=c0+Nk,vk=v0+Nk(6) c_k = c_0 + N_k, \quad v_k = v_0 + N_k \tag{6} ck=c0+Nk,vk=v0+Nk(6)
对于 BkB_kBk,我们有:
Bk−1=B0−1+∑n=1Nηn,2ϕn,k+∑n=1Nϕn,k×(uxn−1NkSk)T(uxn−1NkSk)+c0Nkc0+Nk(1NkSk−u0)T(1NkSk−u0)(7) B_k^{-1} = B_0^{-1} + \sum_{n=1}^N \eta_{n,2} \phi_{n,k} + \sum_{n=1}^N \phi_{n,k} \times \left(u_{x_n} - \frac{1}{N_k} S_k\right)^T \left(u_{x_n} - \frac{1}{N_k} S_k\right) + \frac{c_0 N_k}{c_0 + N_k} \left(\frac{1}{N_k} S_k - u_0\right)^T \left(\frac{1}{N_k} S_k - u_0\right) \tag{7} Bk−1=B0−1+n=1∑Nηn,2ϕn,k+n=1∑Nϕn,k×(uxn−Nk1Sk)T(uxn−Nk1Sk)+c0+Nkc0Nk(Nk1Sk−u0)T(Nk1Sk−u0)(7)
对于 ϕn,k\phi_{n,k}ϕn,k,我们有:
logϕn,k=ϕn,k×{−νkTr(Bkηn,2)−νk(ηn,1−uk)Bk(ηn,1−uk)T}(8) \log \phi_{n,k} = \phi_{n,k} \times \left\{ -\nu_k \text{Tr}(B_k \eta_{n,2}) - \nu_k (\eta_{n,1} - u_k) B_k (\eta_{n,1} - u_k)^T \right\} \tag{8} logϕn,k=ϕn,k×{−νkTr(Bkηn,2)−νk(ηn,1−uk)Bk(ηn,1−uk)T}(8)
NkN_kNk 和 SkS_kSk 定义为:
Nk=∑n=1Nϕn,k,Sk=∑n=1Nϕn,kηn,1 N_k = \sum_{n=1}^N \phi_{n,k}, \quad S_k = \sum_{n=1}^N \phi_{n,k} \eta_{n,1} Nk=n=1∑Nϕn,k,Sk=n=1∑Nϕn,kηn,1
对于参数 ζn,1\zeta_{n,1}ζn,1 和 ζn,2\zeta_{n,2}ζn,2,我们采用以下两阶段更新规则。首先,利用 LLL 的特征值分解获得初始值,并初始化正交约束 OrNet(xn)\text{OrNet}(x_n)OrNet(xn)。然后,使用以下损失函数进行更新:
min∑n=1N∑k=1K∥F(OrNet(xn))+ϕn,kF^(OrNet(xn))−yn∥22+∑n=1NTr{(ζn,1−ζ1ζn,1)(ζn,1−ζ1ζn,1)T−ζ1ηn,2ζ1T}(9) \min \sum_{n=1}^N \sum_{k=1}^K \left\| F(\text{OrNet}(x_n)) + \phi_{n,k} \hat{F}(\text{OrNet}(x_n)) - y_n \right\|_2^2 + \sum_{n=1}^N \text{Tr} \left\{ (\zeta_{n,1} - \zeta_1 \zeta_{n,1})(\zeta_{n,1} - \zeta_1 \zeta_{n,1})^T - \zeta_1 \eta_{n,2} \zeta_1^T \right\} \tag{9} minn=1∑Nk=1∑K F(OrNet(xn))+ϕn,kF^(OrNet(xn))−yn 22+n=1∑NTr{(ζn,1−ζ1ζn,1)(ζn,1−ζ1ζn,1)T−ζ1ηn,2ζ1T}(9)
其中 ∥⋅∥22\|\cdot\|_2^2∥⋅∥22 是 L2L_2L2 损失,xnx_nxn 是原始图像。为进一步提升模型性能,在实际训练中将 L2L_2L2 损失替换为交叉熵损失。
2.4. 分割模型
为评估所提贝叶斯聚类对提升路面裂缝分割的效果,我们选取五个基线方法进行对比研究。
(1) PSPNet(Pyramid Scene Parsing Network)旨在更好地捕获全局上下文信息(Zhao 等,2017a)。它引入金字塔池化模块(Pyramid Pooling Module, PPM),在多个网格尺度上应用池化以收集局部和全局特征,然后上采样并与原始特征图拼接。
(2) DNLNet(Disentangled Non-local Neural Network)是一种先进的神经网络架构,旨在捕获数据中的长程依赖关系,同时解耦复杂的高维交互(Yin 等,2020a)。通过扩展传统非局部操作(建模输入数据中远距离元素之间的关系),DNLNet 分离并聚焦最相关特征,忽略次要交互。
(3) PointRend(Point-based Rendering)将分割视为渲染问题(Kirillov 等,2019)。PointRend 不是均匀预测所有像素的标签,而是自适应采样一组点(主要位于不确定或边界区域),并使用细粒度特征和多层感知机(MLP)预测其标签。这种由粗到精的方法能够以更高效率实现锐利且详细的分割边界,尤其适合与 Mask R-CNN 或 DeepLab 等模型集成。
(4) SegFormer 结合 Transformer 的优势与轻量级设计原则,实现精准高效的像素级预测(Xie 等,2021a)。与传统依赖卷积骨干的分割模型不同,SegFormer 使用分层 Transformer 编码器捕获全局上下文和局部细节,无需位置编码。它采用简单的基于 MLP 的解码器,聚合编码器的多尺度特征以生成高分辨率分割图。
(5) VPD 利用预训练扩散模型的生成能力,实现无需任务特定训练的鲁棒视觉感知任务,如检测和分割(Zhao 等,2023)。与依赖标注数据和微调骨干的传统感知模型不同,VPD 从 Stable Diffusion 等模型的去噪过程中提取感知特征,捕获隐含的语义和结构线索。它采用轻量级适配器将这些特征适配为零样本推理,提升数据稀缺场景下的效率和泛化能力。
3. 实验
为评估我们路面裂缝检测方法的性能,我们使用道路损伤检测研究中广泛采用的公开基准数据集进行实验验证(详见第 4.1 节)。这些数据集涵盖多种路面类型,包括城市道路、高速公路和乡村道路,包含不同光照条件、噪声干扰和裂缝形态的样本,有效验证了方法的鲁棒性。对于对比方法,我们选取深度学习方法的代表性研究成果(详见第 4.2 节)。
3.1. 数据集准备
深度学习模型用于路面裂缝检测的有效性取决于训练数据的质量和多样性。现有数据集众多,但在图像分辨率、条件、裂缝类型、材料(沥青、混凝土)和图像采集方法等方面差异显著。本研究使用多个公开数据集(DeepCrack Liu 等,2019;CRACK500 Yang 等,2020;CFD Shi 等,2016;NHA12D Huang 等,2022)对最先进的语义分割技术进行对比分析,以评估模型在这些多样化资源上的泛化能力。为便于进一步研究和结果可复现性验证,表 1 提供了数据源的详细信息,包括数据采集渠道、采集方法和相关参考文献,供研究人员获取并用于未来研究。
表 1. 裂缝检测数据集基本信息,包括挑战、参考文献和资源链接。
| 数据集 | 挑战 | 参考文献 | 资源链接 |
|---|---|---|---|
| DeepCrack | 裂缝宽度变化大 | Liu 等 (2019) | https://github.com/yhlleo/DeepCrack |
| CRACK500 | 显著病害 | Yang 等 (2020) | https://github.com/fyangneil/pavement-crack-detection |
| CFD | 光照不均和渗水 | Shi 等 (2016) | https://github.com/cuilimeng/CrackForest-dataset |
| NHA12D | 不同拍摄角度 | Huang 等 (2022) | https://github.com/ZheningHuang/NHA12D-Crack-De… |
DeepCrack 数据集是路面裂缝检测领域广泛认可的基准,其描绘的路面类型具有显著多样性,约 22% 的图像为沥青,78% 为混凝土。它还包括表面条件的变化,分类为脏污(22.4%)、粗糙(40%)和裸露(37.6%)。图像中裂缝宽度变化显著,范围从单像素到宽达 180 像素。CRACK500 数据集包含 3368 张裂缝检测图像,包括裂缝中存在显著病害的实例,如裂缝内存在碎石。CFD 数据集由 118 张北京城市路面裂缝图像组成,挑战在于部分图像存在光照不均和渗水现象。NHA12D 数据集由 80 张路面图像组成(40 张混凝土,40 张沥青),由数字检测车辆沿英国 A12 高速公路采集。
此外,为防止深度学习模型过拟合,训练数据应尽可能多样化。然而,直接采集路面裂缝图像成本可能过高。因此,我们采用数据增强方法模拟现实世界中可能遇到的场景。采用四种数据增强策略——光度失真、垂直翻转、水平翻转和旋转。这四种技术随机应用于数据集。
3.2. 对比研究
3.2.1. 对比方法
为严格评估所提方法的性能,我们将其与一组全面的五种最先进或代表性语义分割方法进行对比。这些方法涵盖多种架构范式,包括基于金字塔结构、注意力机制和高效设计的方法。
PSPNet(Zhao 等,2017b)通过利用金字塔池化概念捕获多尺度上下文信息,理解场景的更广泛上下文可显著提升像素级分类精度。DNLNet(Yin 等,2020b)引入解耦非局部块的概念以改进上下文建模。PointRend(Kirillov 等,2020)通过自适应选择稀疏、非均匀的点集(特别是位于物体边界或高不确定性区域的点)来高效"渲染"高质量标签图,在这些点上计算分割标签。SegFormer(Xie 等,2021b)将 Transformer 与轻量级多层感知机(MLP)解码器(混合变压器 MiT 编码器)统一。
3.2.2. 实现细节
实验设计严格遵循对比方法原作者提供的参数配置。所有实验在配备 PyTorch 1.11.0、Python 3.8 和 CUDA 11.3 的 Ubuntu 20.04 服务器(Intel® Xeon® Gold 6430, RTX 4090)上进行,使用 mmsegmentation 框架(Contributors, 2020)。
对于给定模型的变分参数,我们使用 [0,1][0, 1][0,1] 范围内均匀分布的随机值进行初始化。图使用 k=4k=4k=4 的 kkk-近邻方法初始化。我们采用 Adam 优化器进行模型训练。在某些情况下,过大的学习率可能导致训练过程中模型精度波动,而过小的学习率可能阻碍模型充分拟合数据。因此,通过试错法确定实验的优化器设置。对于 PSPNet、DNLNet 和 PointRend,在 DeepCrack 和 CFD 数据集上使用 Adam 优化器,学习率为 0.0003,betas 为 (0.9, 0.999),weight_decay 设为 0。在 CRACK500 上使用 SGD 优化器,学习率为 0.01,动量为 0.9,weight_decay 设为 0.0005。对于 SegFormer,在所有数据集上使用 AdamW 优化器,学习率为 0.0005,betas 为 (0.9, 0.999),weight_decay 设为 0.01。所有训练进行 1500 个周期。此外,我们使用调度器,前部分为 LinearLR,后部分为 PolyLR。
为应对我们 DORGM 模块的即插即用特性,我们将其与既定替代方案对比:集成到结合 CNN 和 Transformer 的双路径网络(Dncct)(Wang 等,2024b)中的全卷积高低频注意力(Zhang 等,2024)(FCHiLo)。我们将每个模块集成到选定的基线——Dncct 中,并在 DeepCrack 数据集上进行评估以应对额外的光照挑战。
3.2.3. 实验结果
表 2 报告了所提方法与其他对比方法在同一测试集上的裂缝分割性能。实验结果表明,与传统方法相比,我们的方法在大多数情况下持续提升了基线的分割精度。然而,存在某些局限性——例如,当在 CRACK500 数据集上使用 PSPNet 方法时,ACC 指标略有下降。这种微小下降主要源于 PSPNet 本身固有的优化挑战,集成我们的方法后进一步加剧(见图 10)。
定性对比:在图 7、8、9 和 10 中,我们展示了 DeepCrack、CRACK500、CFD 和 NHA12D 数据集的真实分割结果。对于每个数据集,我们选取一张代表性图像。结果表明,与现有方法结合时,我们的方法持续提升了分割精度。
表 3 总结了包括 IoU、Acc 和 Dice 在内的各项指标性能。在 mIoU、mAcc 和 mDice 上,DORGM 比 FCHiLo 提升约 2%(在 IoU、Acc 和 Dice 上分数将翻倍),尤其在 DeepCrack 等数据集上,因为 DORGM 比注意力机制更适合多样化数据。这凸显了 DORGM 对不同条件的优越适应性。
表 2. 各方法在不同数据集上基于交并比和像素准确率的性能对比。
| 方法 | DeepCrack | CRACK500 | CFD | NHA12D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | mAcc | mDice | mIoU | mAcc | mDice | mIoU | mAcc | mDice | mIoU | mAcc | mDice | |
| PSPNet | 84.23 | 89.76 | 88.93 | 79.47 | 87.92 | 87.75 | 75.00 | 84.65 | 84.05 | 70.06 | 80.4 | 78.72 |
| PSPNet+DORGM | 86.91 | 91.64 | 91.36 | 81.28 | 88.67 | 88.11 | 77.40 | 86.13 | 85.68 | 73.62 | 82.90 | 80.33 |
| DNLNet | 84.67 | 91.66 | 92.14 | 79.80 | 87.36 | 88.35 | 75.16 | 85.38 | 85.61 | 70.67 | 81.33 | 79.33 |
| DNLNet+DORGM | 86.99 | 92.58 | 90.97 | 80.50 | 89.46 | 89.96 | 77.52 | 85.66 | 86.95 | 73.98 | 82.98 | 81.07 |
| PointRend | 85.70 | 91.33 | 89.84 | 79.42 | 87.07 | 85.70 | 76.39 | 85.03 | 84.21 | 74.78 | 88.68 | 83.20 |
| PointRend+DORGM | 86.32 | 90.56 | 91.23 | 80.19 | 88.23 | 87.49 | 78.41 | 88.26 | 85.17 | 77.62 | 90.01 | 88.13 |
| Segformer | 84.58 | 90.63 | 86.33 | 77.71 | 85.46 | 81.42 | 76.00 | 87.09 | 86.78 | 72.47 | 81.87 | 81.07 |
| Segformer+DORGM | 87.06 | 92.32 | 90.81 | 80.15 | 87.17 | 84.50 | 77.70 | 86.19 | 83.26 | 73.55 | 85.07 | 83.30 |
| VPD | 82.24 | 93.92 | 89.43 | 77.43 | 86.33 | 86.34 | 71.00 | 91.10 | 80.09 | 64.47 | 76.84 | 72.61 |
| VPD+DORGM | 82.99 | 94.77 | 90.25 | 77.91 | 89.77 | 89.77 | 73.47 | 89.65 | 82.41 | 69.97 | 79.30 | 78.14 |
表 3. Dncct 骨干网络上即插即用模块的对比(数据集平均)。
| 模块 | mIoU | mAcc | mDice |
|---|---|---|---|
| None (基线) | 85.38 | 93.10 | 91.16 |
| FCHiLo | 86.26 | 94.37 | 90.14 |
| DORGM (Ours) | 87.93 | 95.22 | 93.19 |
3.3. 泛化性与鲁棒性分析
为证实我们关于在具有变化条件(如光照、噪声和环境因素)的真实数据上提升泛化能力的主张,我们进行了跨数据集评估和在模拟扰动下的鲁棒性测试。
3.3.1. 跨数据集泛化
为模拟真实场景中遇到的域偏移,我们在 DeepCrack 数据集上训练模型,并在 GAPs384 上测试,后者是德国沥青路面病害的高分辨率数据集,涵盖多种路面损伤类型(如坑槽和修补),旨在测试模型区分不同病害类型的能力(Yang 等,2019)。表 4 报告了结果。
我们集成 DORGM 的模型表现出更小的泛化差距(例如,与基线相比,mIoU 下降约少 10%),这归因于正交约束和路由机制能够适应条件变化,如 CRACK500 中的碎石噪声或 CFD 中的不均匀光照。
表 4. 跨数据集性能 (mIoU)。在 DeepCrack 上训练。
| 模型 | DeepCrack | GAPs384 | 差距 (%) |
|---|---|---|---|
| DNLNet | 84.67 | 8.37 | 76.30 |
| DNLNet+ DORGM | 86.99 | 20.82 | 66.17 |
| Segformer | 84.58 | 5.17 | 79.41 |
| Segformer+ DORGM | 87.06 | 16.36 | 70.70 |
3.3.2. 对扰动的鲁棒性
我们对测试集应用了受真实世界启发的增强(亮度变化、高斯噪声、模糊)。表 5 显示了定量改进,其中 DORGM 在噪声下更好地保留了裂缝边界。定量上,DORGM 在扰动下减少了更少的 mIoU 性能下降,证实了其对退化真实世界数据的鲁棒性。
表 5. 扰动下的分割:基线对比 DORGM (mIoU)。
| 模型 | 原始 | 扰动 | 差距 (%) |
|---|---|---|---|
| DNLNet | 84.67 | 78.89 | 5.78 |
| DNLNet+ DORGM | 86.99 | 82.37 | 4.62 |
| Segformer | 84.58 | 79.16 | 5.42 |
| Segformer+ DORGM | 87.06 | 83.19 | 3.87 |
3.4. 消融实验
为验证不同模块对路面裂缝分割精度的影响,我们在样本集上进行了消融实验(表 2 和 6)。如表 2 所示,在所提网络的消融研究中,特征正交模块和贝叶斯聚类模块均对裂缝分割结果有一定影响。这表明数据集的聚类和潜在特征的正交分解在分割精度中均发挥重要作用。特征正交模块对分割性能的影响相对更大,这可归因于裂缝在空间维度上呈现不同场景(高级语义),正交分离便于模型更有效地学习。
另一个关键影响因素是聚类数 KKK。我们在图 4 中评估了此参数的效果。在本实验中,我们将 KKK 的值从 1 变化到 5。结果表明,在 DeepCrack 数据集上,最优 KKK 值为 5。在 CRACK500 数据集上,按 IoU 衡量时最佳 KKK 值为 3,但按 ACC 衡量时为 5。对于 CFD 数据集,最优 KKK 值为 4。KKK 值变化的主要原因可能在于数据复杂性和成像条件的差异,这需要更复杂的模型进行准确表征(见表 6)。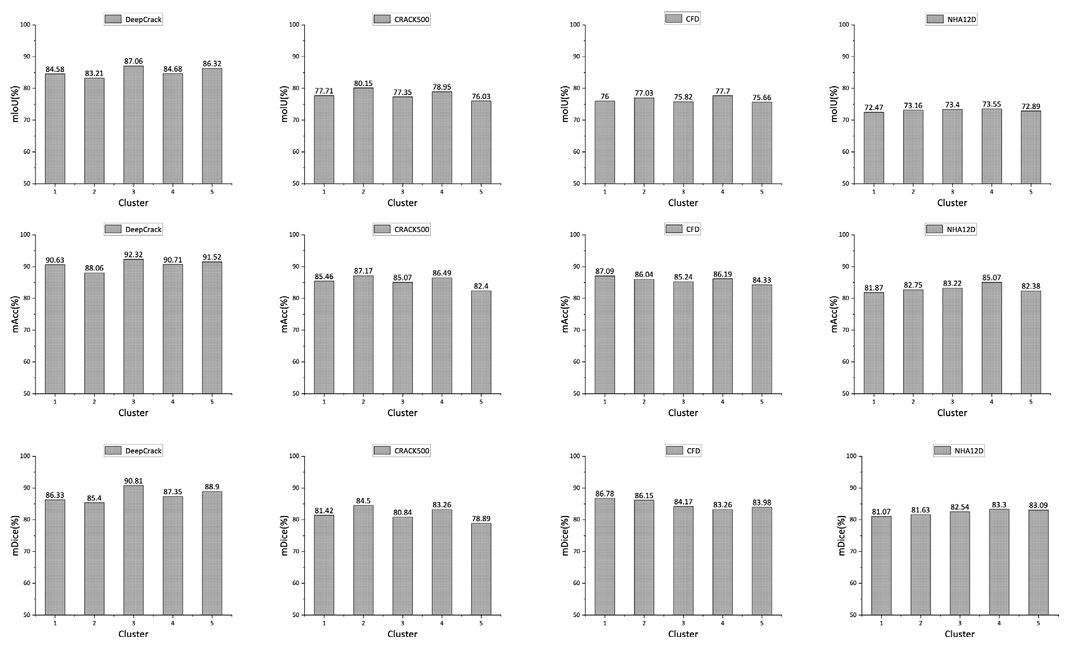
图 4. 聚类数 KKK 对整体聚类影响的分析。顶行显示 IoU 随 KKK 值的变化,底行显示 ACC 随 KKK 值的变化。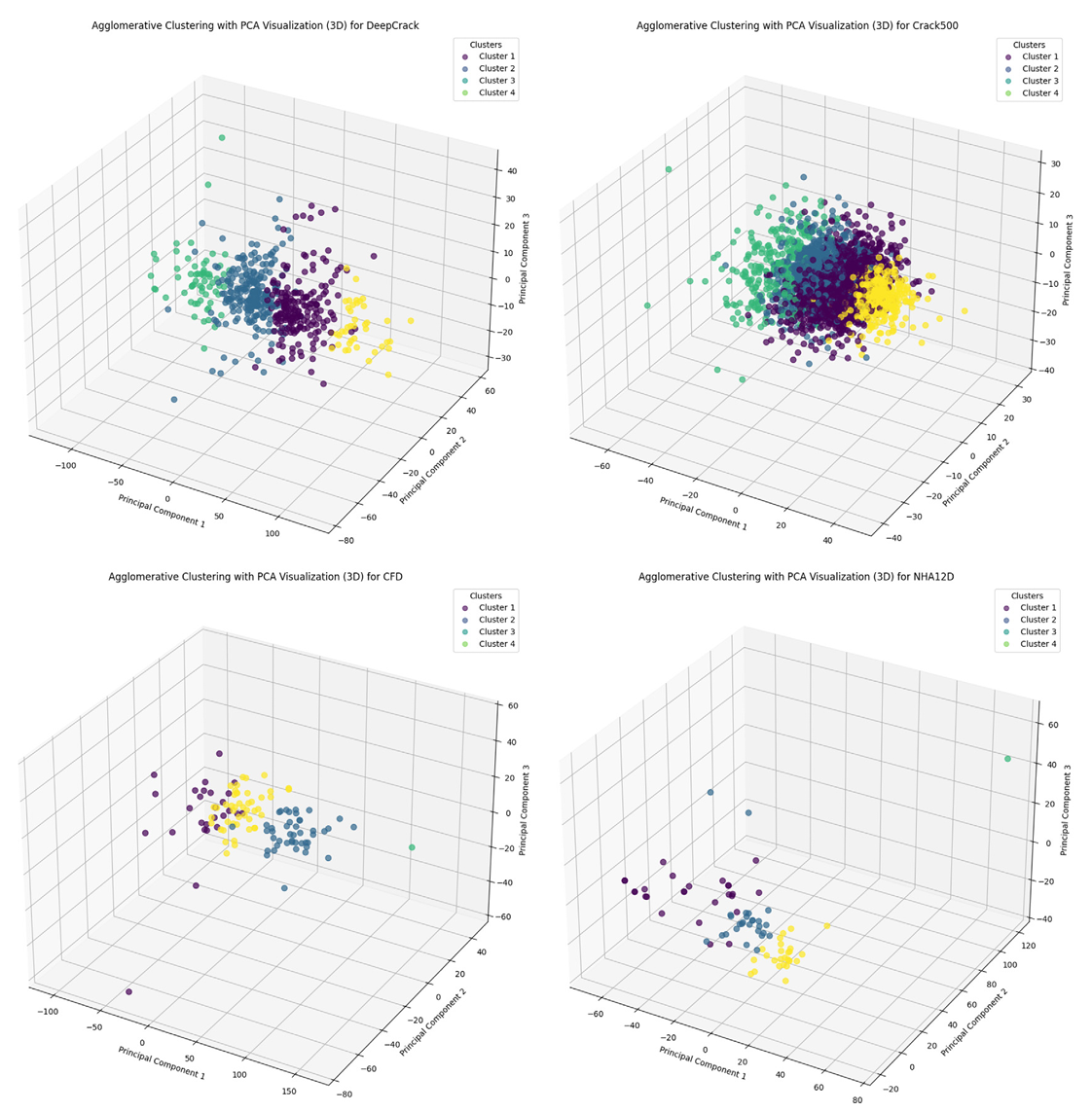
图 5. 原始数据集在 PCA 上的分布。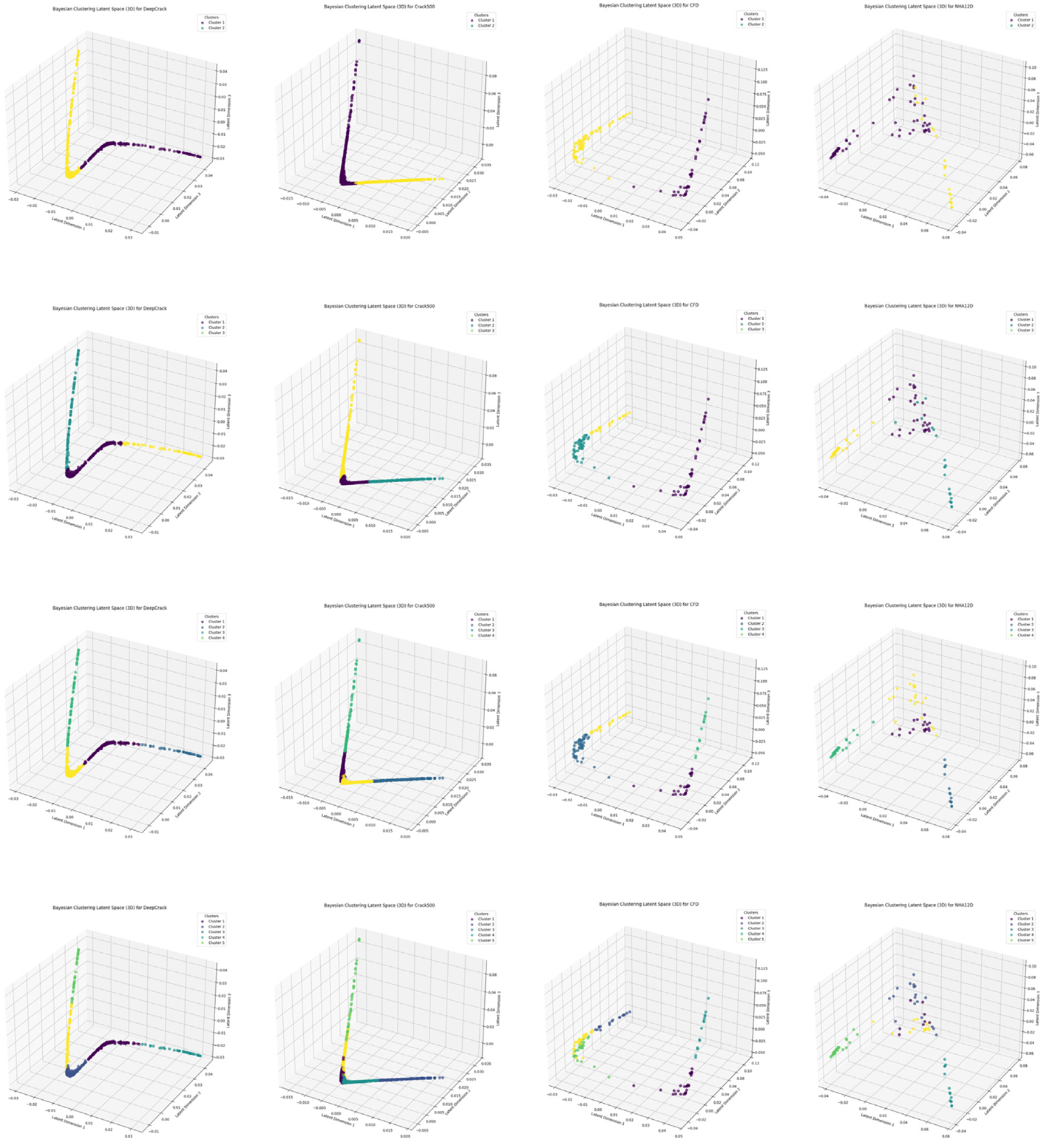
图 6. 第 1 至 4 行分别表示 2 至 5 个聚类的条件。第 1 至 4 列分别表示 DeepCrack、CRACK500、CFD 和 NHA12D 数据集。
表 6. 各方法在不同数据集上基于 mIoU、mAcc 和 mDice 的性能对比。
| 方法 | DeepCrack | CRACK500 | CFD | NHA12D | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | mAcc | mDice | mIoU | mAcc | mDice | mIoU | mAcc | mDice | mIoU | mAcc | mDice | |
| PSPNet | 84.23 | 89.76 | 88.93 | 79.47 | 87.92 | 87.75 | 75.00 | 84.65 | 84.05 | 70.06 | 80.4 | 78.72 |
| PSPNet w/ orth | 85.29 | 90.00 | 89.87 | 80.20 | 87.61 | 87.91 | 76.38 | 85.26 | 84.15 | 71.59 | 80.90 | 78.63 |
| PSPNet w/ dorg | 86.91 | 91.64 | 91.36 | 81.28 | 88.67 | 88.11 | 77.40 | 86.13 | 85.68 | 73.62 | 82.90 | 80.33 |
| DNLNet | 84.67 | 91.66 | 92.14 | 79.80 | 87.36 | 88.35 | 75.16 | 85.38 | 85.61 | 70.67 | 81.33 | 79.33 |
| DNLNet w/ orth | 85.04 | 91.47 | 91.40 | 80.22 | 88.53 | 87.10 | 75.94 | 86.59 | 85.24 | 71.84 | 82.01 | 79.32 |
| DNLNet w/ dorg | 86.99 | 92.58 | 90.97 | 80.50 | 89.46 | 89.96 | 77.52 | 85.66 | 86.95 | 73.98 | 82.98 | 81.07 |
| PointRend | 85.70 | 91.33 | 89.84 | 79.42 | 87.07 | 85.70 | 76.39 | 85.03 | 84.21 | 74.78 | 88.68 | 83.20 |
| PointRend w/ orth | 85.12 | 91.29 | 89.88 | 80.17 | 87.72 | 85.06 | 76.99 | 86.37 | 84.13 | 73.18 | 89.95 | 85.32 |
| PointRend w/ dorg | 86.32 | 90.56 | 91.23 | 80.19 | 88.23 | 87.49 | 78.41 | 88.26 | 85.17 | 77.62 | 90.01 | 88.13 |
| Segformer | 84.58 | 90.63 | 86.33 | 77.71 | 85.46 | 81.42 | 76.00 | 87.09 | 86.78 | 72.47 | 81.87 | 81.07 |
| Segformer w/ orth | 85.31 | 91.28 | 86.25 | 76.14 | 84.41 | 82.19 | 76.75 | 86.21 | 86.96 | 73.58 | 82.47 | 81.99 |
| Segformer w/ dorg | 87.06 | 92.32 | 90.81 | 80.15 | 87.17 | 84.50 | 77.70 | 86.19 | 83.26 | 73.55 | 85.07 | 83.30 |
| VPD | 82.24 | 93.92 | 89.43 | 77.43 | 86.33 | 86.34 | 71.00 | 91.10 | 80.09 | 64.47 | 76.84 | 72.61 |
| VPD w/ orth | 82.24 | 94.07 | 89.41 | 78.29 | 87.14 | 87.52 | 71.61 | 90.02 | 80.13 | 66.28 | 77.70 | 74.88 |
| VPD w/ dorg | 82.99 | 94.77 | 90.25 | 77.91 | 89.77 | 89.77 | 73.47 | 89.65 | 82.41 | 69.97 | 79.30 | 78.14 |
4. 讨论与结论
4.1. 模型性能分析
DeepCrack、CRACK500 和 CFD 数据集各具特点。在 DeepCrack 中,裂缝宽度变化显著,需要模型能够捕获多尺度特征。CRACK500 数据集包含存在于碎石和其他岩石表面的裂缝,其中裂缝常与背景视觉上难以区分,要求模型具备强大的判别能力。而 CFD 数据集主要包含在不同光照和湿度条件下的窄裂缝,这要求模型具备鲁棒的环境泛化能力。
通过对可视化结果的定性分析,可以明显看出,集成我们的模块增强了模型的多尺度适应性、抗噪能力和边缘对齐精度。
4.2. 模块分析
正交约束模块旨在缓解裂缝分割任务中由异构条件引起的特征干扰。如原始数据在 PCA 空间中的特征分布所示(图 5),不同条件的样本表现出显著耦合,导致模型在不同场景下的泛化能力受损,这是性能下降的主要原因。通过强制不同条件(如表面材料、光照变化或环境噪声)下提取的潜在特征正交,该模块确保学习到的表征去相关且条件不变。数学上,该约束最大化潜在空间中不同条件特征向量之间的角度分离,有效将其内积降至零。如 DeepCrack 数据集的潜在空间可视化所示(图 6),若无正交正则化,沥青和混凝土表面的边界样本表现出显著重叠。然而,应用约束后,这些聚类被显式解耦,其质心之间的欧氏距离增加。这种分离最小化了因条件引起的歧义(如相似裂缝形态出现在不同基底上)导致的误分类风险。
正交约束的有效性通过跨数据集分析进一步验证。例如,在 CFD 数据集中,不均匀光照和渗水引入虚假相关性,降低分割精度。该模块通过将特征投影到正交子空间来抑制这些伪影,其中光照变化(与潜在维度 1 对齐)和水致失真(潜在维度 3)被解耦。类似地,在 CRACK500 中,裂缝内碎石的存在产生混淆传统模型的虚假边界。正交正则化将与碎石相关的特征隔离到专用子空间,防止其干扰裂缝特定模式。值得注意的是,NHA12D 数据集仅包含在正常条件下采集的混凝土和沥青样本。图 5 显示,NHA12D 的原始数据分布已相对清晰,表现出较低的特征耦合。因此,如表 2 所示,基线模型在该数据集上已实现较好的性能。此外,图 6 中 NHA12D 特征空间中较弱的正交性可归因于其固有的条件异质性缺乏。实验结果表明,该方法在所有三个数据集上提升了鲁棒性,尤其在极端条件下(如 DeepCrack 中的宽裂缝或 CFD 中的低对比度样本)。通过将条件特异性变化显式建模为正交方向,该模块使分割网络能够聚焦于固有裂缝特征,同时抑制外在噪声——这对于具有多样且不可预测环境因素的真实应用至关重要。
4.3. 潜在应用
所提出的深度正交增强生成模型(DORGM)在集成到真实世界系统(尤其是城市道路养护和基础设施监测)方面具有显著潜力(Liu 等,2025)。通过提供鲁棒、条件自适应的裂缝分割,它可部署在自动化路面评估平台中,如车载成像系统或无人机巡检,实现实时缺陷量化。例如,在智慧城市倡议中,DORGM 可与物联网传感器(Li 等,2025)接口,生成优先养护计划,通过精准裂缝定位聚焦高风险区域的修复,从而降低成本和停机时间。其即插即用特性允许无缝集成到现有工作流程中,如使用移动应用(Alfarrarjeh 等,2018)进行现场检查,其中变化的环境条件(如天气或光照)是常见挑战。
除道路基础设施外,该模型的正交约束和软标签路由机制在更广泛的计算机视觉任务中具有应用前景。在遥感领域,它可增强卫星图像分析(Wu 等,2024;Chen 等,2024b),用于检测地质断层或环境退化,适应多样地形和大气干扰。在医学成像中,类似原理可改进 MRI 扫描中血管结构或肿瘤的分割(Karri 等,2024),其中患者特异性变化(如组织密度)模拟了路面裂缝中的条件异质性。此外,将 DORGM 与边缘计算设备集成可促进资源受限环境(如自动驾驶车辆或工业机器人)中的设备端处理(Urrea 和 Velez,2025),推动制造和能源等行业预测性维护的可扩展应用。这些扩展利用了模型在泛化和精度方面的已验证改进,如我们在多样化数据集上的实验所示,为复杂真实场景中的数据驱动决策铺平道路。
4.4. 局限性与未来工作
尽管所提出的深度正交约束生成模型在裂缝分割方面取得了有希望的结果,但仍存在若干局限。虽然在裂缝特定数据集上得到验证,但模型架构假设了领域特定先验(如基础设施中的裂缝形态)。将其扩展到其他缺陷类型(如腐蚀或分层)需要从头重新训练,因为正交约束和路由逻辑是针对裂缝几何定制的。此外,该模型缺乏对多样化数据集固有特征粒度变化的适应性。例如,当应用于表现出同质条件的数据集(如 NHA12D)时,特征正交模块难以执行有意义的特征解耦。这导致与更简单基线相比性能提升有限,因为施加的约束未能有效划分固有低变异性特征空间。这与强调通用特征提取器用于多样物理现象的 AI for Science 框架形成对比。
为解决此问题,未来工作将聚焦于动态、层次感知的特征分解,解耦通用缺陷模式与领域特定属性,同时实现自适应知识迁移。当前正交约束显式强制潜在空间中的特征分离,但这引入了计算开销,并假设对领域特异性变化(如 DeepCrack 中的裂缝宽度分布)和特征粒度要求的先验知识。为克服此问题,未来架构应纳入对数据异质性敏感的动态特征分解机制。未来模型可通过自监督任务(如掩码特征重建或对比学习)以隐式解耦替代显式约束。例如,利用动量对比(MoCo)(He 等,2020)可鼓励模型学习领域不变的边缘/纹理特征,而无需预定义正交规则。这与 ReduNet 启发的白盒架构(Chan 等,2021)的最新进展一致,其中特征解耦从数据驱动优化而非刚性数学约束中涌现。
4.5. 结论
本文提出一种新型裂缝分割网络。在我们的模型中,我们通过正交约束和软标签路由模块转换隐藏特征来提升分割精度。具体而言,正交模块可用于增加不同条件之间的距离,从而减少它们之间的干扰;而软标签路由模块将不同样本路由至不同的网络组件,实现多样化条件的建模。根据实验结果,在三个数据集上,集成两个模块(即 DORGM)后,四种不同神经网络模型的性能均得到提升。关键评估指标(如分类准确率 ACCACCACC 和交并比 IoUIoUIoU)的最大提升可达 5%。值得注意的是,所提模型展现出即插即用特性,可灵活集成到各种神经网络架构中,这证明了其强大的泛化能力和实用性。这种设计不仅结构简单,而且计算高效,进一步验证了其在真实世界应用中的潜力和优势。

图 7. (a) 展示从 DeepCrack 数据集中选取的四张示例图像;(b)、©、(d)、(e) 和 (f) 分别展示 PSPNet、DNLNet、PointRend、SegFormer 和 VPD 获得的分割结果(第一行),以及集成我们提出模块的相应模型结果(第二行)。

图 8. (a) 展示从 CRACK500 数据集中选取的四张示例图像;(b)、©、(d)、(e) 和 (f) 分别展示 PSPNet、DNLNet、PointRend、SegFormer 和 VPD 获得的分割结果(第一行),以及集成我们提出模块的相应模型结果(第二行)。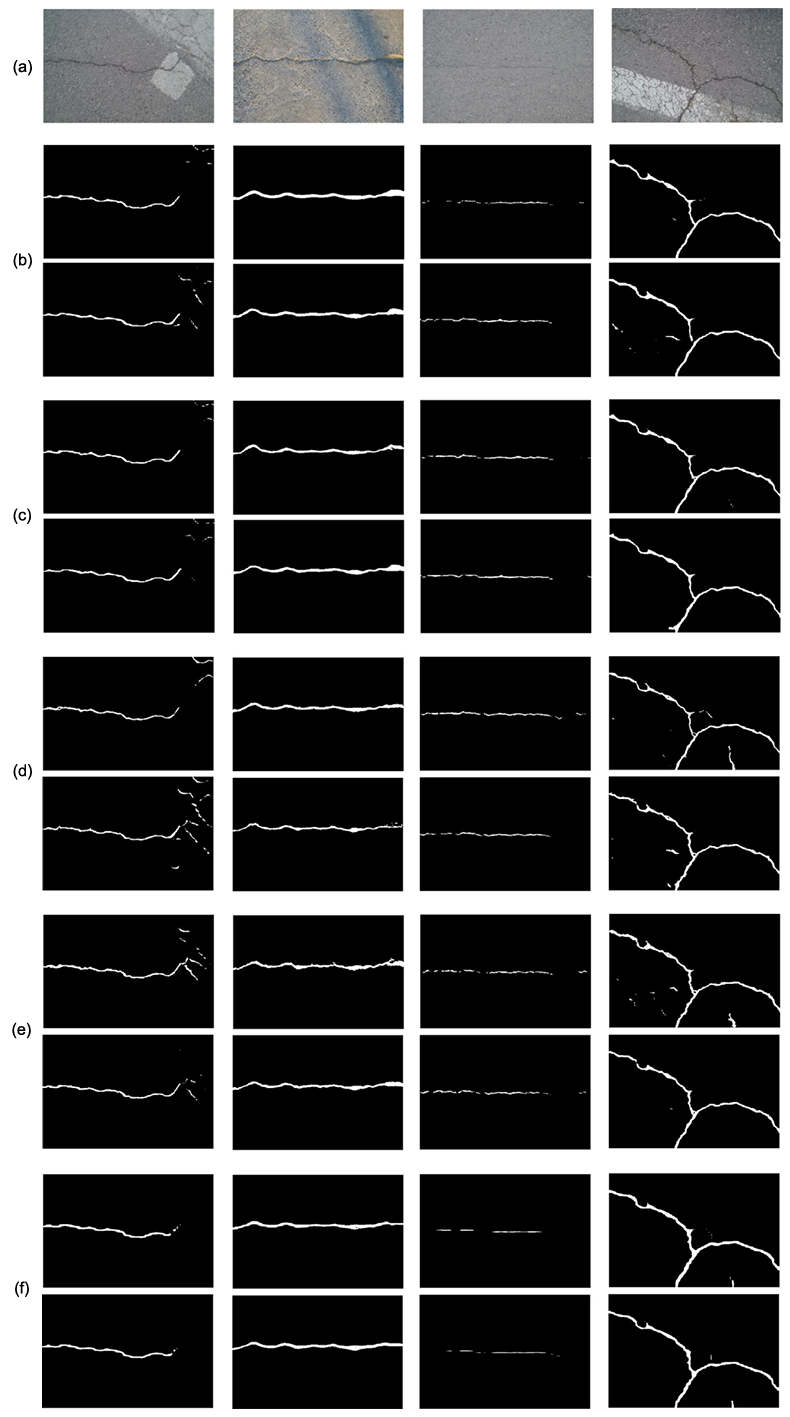
图 9. (a) 展示从 CFD 数据集中选取的四张示例图像;(b)、©、(d)、(e) 和 (f) 分别展示 PSPNet、DNLNet、PointRend、SegFormer 和 VPD 获得的分割结果(第一行),以及集成我们提出模块的相应模型结果(第二行)。
图 10. (a) 展示从 NHA12D 数据集中选取的四张示例图像;(b)、©、(d)、(e) 和 (f) 分别展示 PSPNet、DNLNet、PointRend、SegFormer 和 VPD 获得的分割结果(第一行),以及集成我们提出模块的相应模型结果(第二行)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)