Shared Memory 与矩阵乘法分块优化实验
文章目录
摘要
本文围绕 CUDA 矩阵乘法中的 Shared Memory 优化展开,通过 Naive 矩阵乘法与 Shared Memory Tiled 矩阵乘法的对比实验,分析不同 TILE 大小对 kernel 性能的影响。
实验基于 Tesla T4,测试矩阵规模包括 1024、2048、4096,TILE 包括 8、16、32、64。
结果表明,Shared Memory 在大多数有效配置下能够明显加速矩阵乘法
1. Shared Memory
矩阵乘法是 GPU 编程里非常经典的优化案例。
假设有:
C = A × B
其中:
A: M × K
B: K × N
C: M × N
每个输出元素:
C[row][col]
都需要计算:
A 的第 row 行 与 B 的第 col 列 的点积
也就是:
for (int k = 0; k < N; ++k) {
sum += A[row * N + k] * B[k * N + col];
}
如果直接写最朴素的 CUDA kernel,每个线程负责一个 C[row][col],那么大量线程会不断从 Global Memory 读取 A 和 B。问题是,Global Memory 容量大,但访问延迟高、带宽宝贵。
Shared Memory 的优化思路就是:
不要每次都从 Global Memory 远距离取数据,而是先把一小块数据搬到 Shared Memory,再让同一个线程块里的线程反复使用。
2. Naive 矩阵乘法:直接从 Global Memory 读取
Naive kernel 的核心代码如下:
__global__ void matmul_naive(const float* A, const float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
这个版本非常直观:
一个线程 → 负责一个 C[row][col]
每个线程 → 自己去 Global Memory 读取 A 和 B
它的问题是:
1. A 和 B 的数据会被不同线程重复读取
2. Global Memory 访问次数巨大
3. 内存带宽压力很大
3. Shared Memory Tiled 版本:先搬一小块,再反复用
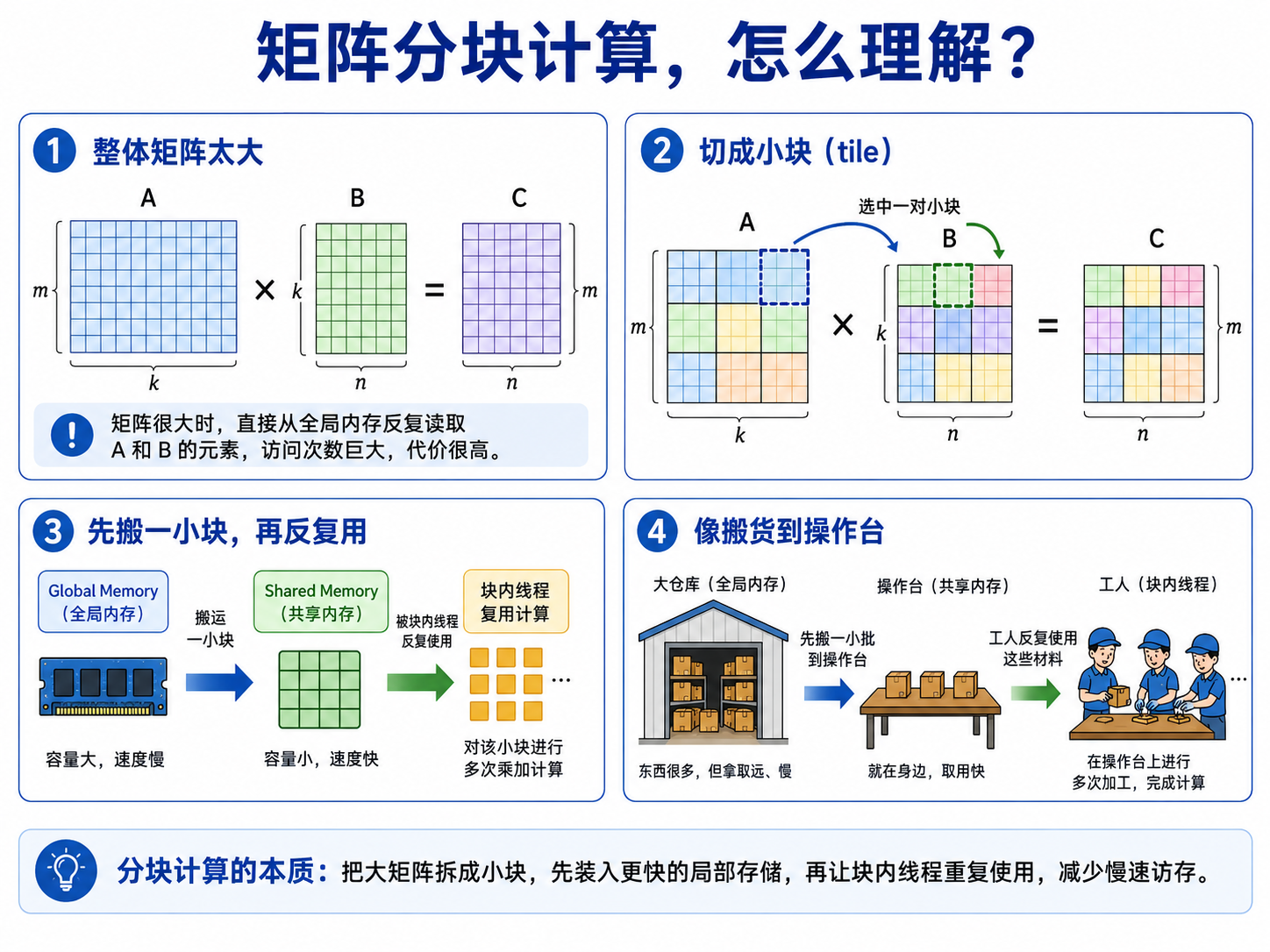
Shared Memory 版本的核心思想是 Tiling,也就是分块计算。
例如 TILE=16 时,一个线程块负责计算一个 16×16 的 C tile。每次从 A 和 B 中加载一小块:
A tile → Shared Memory
B tile → Shared Memory
然后这个 block 内的所有线程在 Shared Memory 上反复使用这些数据,完成一部分乘加。
核心代码如下
__global__ void matmul_shared(const float* A, const float* B, float* C, int N) {
extern __shared__ float shared[];
int tile = blockDim.x;
float* As = shared;
float* Bs = shared + tile * tile;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = blockIdx.y * tile + ty;
int col = blockIdx.x * tile + tx;
float sum = 0.0f;
for (int t = 0; t < N; t += tile) {
int a_col = t + tx;
int b_row = t + ty;
As[ty * tile + tx] =
(row < N && a_col < N) ? A[row * N + a_col] : 0.0f;
Bs[ty * tile + tx] =
(b_row < N && col < N) ? B[b_row * N + col] : 0.0f;
__syncthreads();
for (int k = 0; k < tile; ++k) {
sum += As[ty * tile + k] * Bs[k * tile + tx];
}
__syncthreads();
}
if (row < N && col < N) {
C[row * N + col] = sum;
}
}
这里有几个关键点。
第一,使用了动态 Shared Memory:
extern __shared__ float shared[];
启动 kernel 时再指定 shared memory 大小:
matmul_shared<<<grid, block, shared_bytes>>>(d_A, d_B, d_C_shared, N);
其中:
size_t shared_bytes = 2ULL * tile * tile * sizeof(float);
因为需要两个 tile:
A tile: tile × tile
B tile: tile × tile
所以总 shared memory 大小是:
2 × TILE × TILE × sizeof(float)
第二,使用了两次同步:
__syncthreads();
第一次同步的作用是:
确保所有线程都已经把 A tile 和 B tile 装入 Shared Memory
第二次同步的作用是:
确保所有线程都已经用完当前 tile,再进入下一轮覆盖 Shared Memory
如果没有同步,就可能出现有些线程还没装载完,其他线程已经开始读;或者有些线程还没用完当前 tile,其他线程已经开始写下一块数据。
4. 分块计算可以怎么理解?
可以把矩阵乘法想象成搬货。
Global Memory 像一个大仓库:
容量大,但距离远,取东西慢
Shared Memory 像工人旁边的小操作台:
容量小,但就在身边,取东西快
Naive 做法是:
每次需要材料,都跑去大仓库拿
Shared Memory Tiled 做法是:
先从大仓库搬一小批材料到操作台
然后工人们在操作台上反复使用这批材料
用完再换下一批
对应到 CUDA:
Global Memory → Shared Memory → 块内线程反复计算
它的本质是:
用更快的片上内存,减少对慢速 Global Memory 的重复访问。

5. 当前代码测量的是什么时间?
非常重要:当前实验中的 naive_ms 和 shared_ms 测的是 kernel 计算时间,不是端到端时间。
计时代码核心是:
template <typename Launch>
float time_kernel(Launch launch, int repeats) {
launch();
CUDA_CHECK(cudaDeviceSynchronize());
cudaEvent_t start, stop;
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&stop));
float total_ms = 0.0f;
for (int i = 0; i < repeats; ++i) {
CUDA_CHECK(cudaEventRecord(start));
launch();
CUDA_CHECK(cudaEventRecord(stop));
CUDA_CHECK(cudaEventSynchronize(stop));
float ms = 0.0f;
CUDA_CHECK(cudaEventElapsedTime(&ms, start, stop));
total_ms += ms;
}
CUDA_CHECK(cudaEventDestroy(start));
CUDA_CHECK(cudaEventDestroy(stop));
return total_ms / repeats;
}
正式计时只包住了:
launch();
而 launch() 里面只是启动 kernel:
matmul_naive<<<grid, block>>>(...);
或者:
matmul_shared<<<grid, block, shared_bytes>>>(...);
所以它不包含:
cudaMalloc
Host to Device 拷贝
Device to Host 拷贝
CPU 初始化
max_diff 校验
cudaFree
6. 实验环境与运行命令
本次实验环境:
GPU: Tesla T4
Max threads per block: 1024
Shared memory per block: 48 KB
运行命令:
./share_mem --n 1024,2048,4096 --tile 8,16,32,64 --repeat 3
测试内容:
矩阵规模 N:1024、2048、4096
TILE 大小:8、16、32、64
重复次数:3
7. 实验结果汇总
| N | TILE | naive_ms | shared_ms | speedup | max_diff | status |
|---|---|---|---|---|---|---|
| 1024 | 8 | 5.351 | 4.120 | 1.299x | 0.000 | OK |
| 1024 | 16 | 3.903 | 3.065 | 1.274x | 0.000 | OK |
| 1024 | 32 | 3.176 | 3.285 | 0.967x | 0.000 | OK |
| 1024 | 64 | - | - | - | - | SKIP |
| 2048 | 8 | 64.543 | 48.388 | 1.334x | 0.000 | OK |
| 2048 | 16 | 39.200 | 32.632 | 1.201x | 0.000 | OK |
| 2048 | 32 | 27.944 | 26.431 | 1.057x | 0.000 | OK |
| 2048 | 64 | - | - | - | - | SKIP |
| 4096 | 8 | 535.433 | 391.150 | 1.369x | 0.000 | OK |
| 4096 | 16 | 319.544 | 261.740 | 1.221x | 0.000 | OK |
| 4096 | 32 | 232.351 | 205.859 | 1.129x | 0.000 | OK |
| 4096 | 64 | - | - | - | - | SKIP |
TILE=64 被跳过的原因是:
TILE × TILE = 64 × 64 = 4096 threads/block
而 Tesla T4 单个 block 最大线程数是:
1024 threads/block
因此 TILE=64 是非法 block 配置。
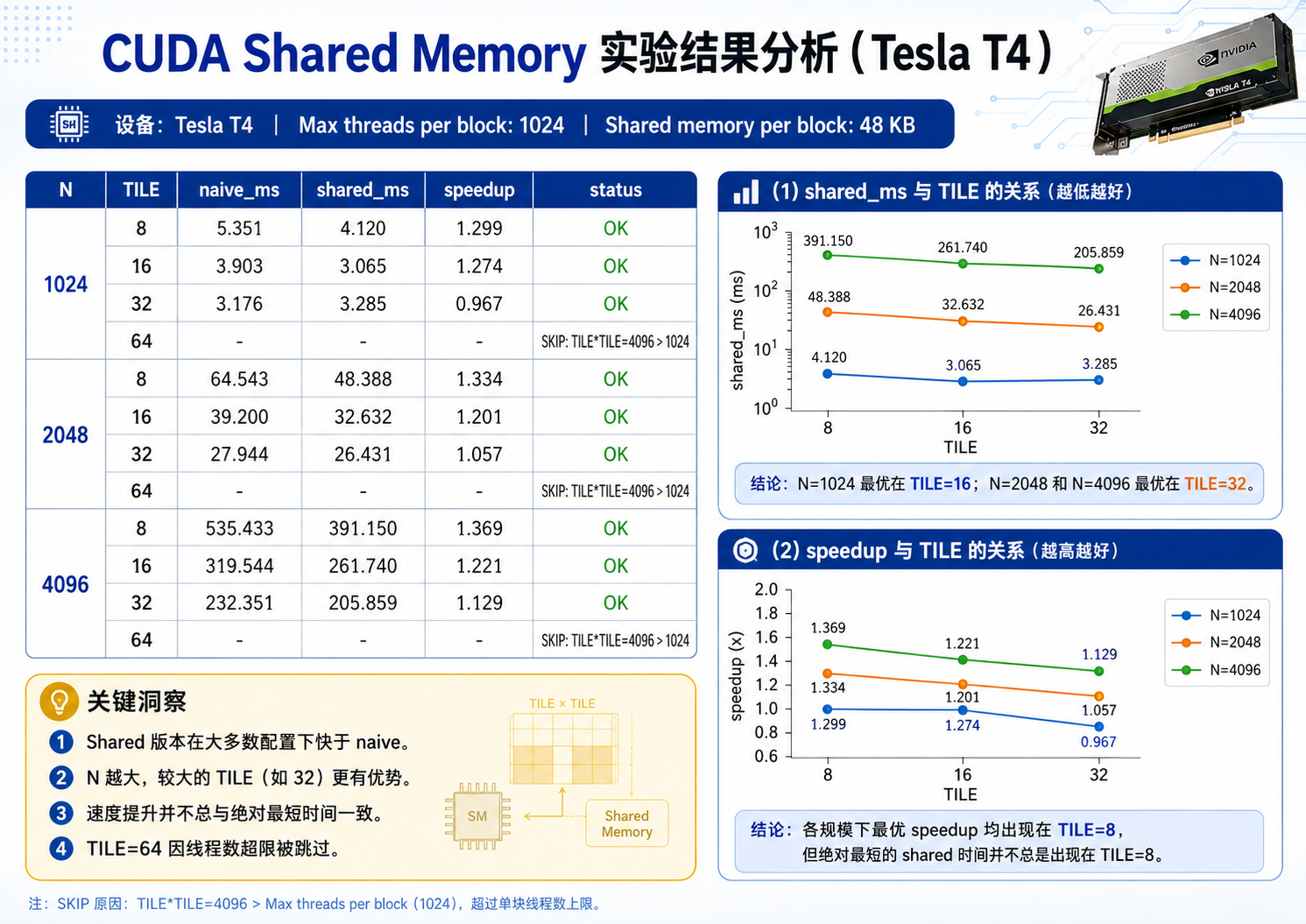
为什么 Naive 版本也会随 TILE 变化?
这是本实验中非常关键的点。
在代码中,Naive 和 Shared 版本使用了同一个 block 配置:
dim3 block(tile, tile);
dim3 grid((N + tile - 1) / tile, (N + tile - 1) / tile);
然后分别启动:
matmul_naive<<<grid, block>>>(...);
matmul_shared<<<grid, block, shared_bytes>>>(...);
这意味着:
TILE 改变时,不只是 Shared Memory 的 tile 大小改变了
Naive kernel 的 block 大小也改变了
例如:
| TILE | block 配置 | threads/block |
|---|---|---|
| 8 | 8×8 | 64 |
| 16 | 16×16 | 256 |
| 32 | 32×32 | 1024 |
| 64 | 64×64 | 4096,非法 |
所以 TILE 会影响 Naive 版本的:
block 大小
warp 组织
block 数量
...
这也是为什么 Naive 的时间不是固定的。
总结:
Shared Memory 的本质,是把“重复从慢速 Global Memory 取数据”,变成“先搬一小块到快速片上内存,再在 block 内反复复用”;但真正的 CUDA 调优必须同时考虑 TILE 大小、block 形状、occupancy、硬件限制和结果正确性。
答疑
附代码
%%writefile share_mem.cu
#include <cuda_runtime.h>
#include <algorithm>
#include <cmath>
#include <cstdlib>
#include <iomanip>
#include <iostream>
#include <sstream>
#include <string>
#include <vector>
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
std::cerr << "CUDA Error: " << cudaGetErrorString(err) \
<< " at " << __FILE__ << ":" << __LINE__ << std::endl; \
std::exit(1); \
} \
} while (0)
__global__ void matmul_naive(const float* A, const float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
__global__ void matmul_shared(const float* A, const float* B, float* C, int N) {
extern __shared__ float shared[];
int tile = blockDim.x;
float* As = shared;
float* Bs = shared + tile * tile;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = blockIdx.y * tile + ty;
int col = blockIdx.x * tile + tx;
float sum = 0.0f;
for (int t = 0; t < N; t += tile) {
int a_col = t + tx;
int b_row = t + ty;
As[ty * tile + tx] = (row < N && a_col < N) ? A[row * N + a_col] : 0.0f;
Bs[ty * tile + tx] = (b_row < N && col < N) ? B[b_row * N + col] : 0.0f;
__syncthreads();
for (int k = 0; k < tile; ++k) {
sum += As[ty * tile + k] * Bs[k * tile + tx];
}
__syncthreads();
}
if (row < N && col < N) {
C[row * N + col] = sum;
}
}
std::vector<int> parse_list(const std::string& text) {
std::vector<int> values;
std::stringstream ss(text);
std::string item;
while (std::getline(ss, item, ',')) {
if (!item.empty()) {
values.push_back(std::stoi(item));
}
}
return values;
}
void print_help(const char* program) {
std::cout << "Usage: " << program
<< " [--n 512,1024,2048] [--tile 8,16,32,64] [--repeat 3]\n";
}
template <typename Launch>
float time_kernel(Launch launch, int repeats) {
launch();
CUDA_CHECK(cudaDeviceSynchronize());
cudaEvent_t start, stop;
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&stop));
float total_ms = 0.0f;
for (int i = 0; i < repeats; ++i) {
CUDA_CHECK(cudaEventRecord(start));
launch();
CUDA_CHECK(cudaEventRecord(stop));
CUDA_CHECK(cudaEventSynchronize(stop));
float ms = 0.0f;
CUDA_CHECK(cudaEventElapsedTime(&ms, start, stop));
total_ms += ms;
}
CUDA_CHECK(cudaEventDestroy(start));
CUDA_CHECK(cudaEventDestroy(stop));
return total_ms / repeats;
}
float max_abs_diff(const float* d_x, const float* d_y, size_t count) {
std::vector<float> h_x(count), h_y(count);
size_t bytes = count * sizeof(float);
CUDA_CHECK(cudaMemcpy(h_x.data(), d_x, bytes, cudaMemcpyDeviceToHost));
CUDA_CHECK(cudaMemcpy(h_y.data(), d_y, bytes, cudaMemcpyDeviceToHost));
float max_diff = 0.0f;
for (size_t i = 0; i < count; ++i) {
max_diff = std::max(max_diff, std::fabs(h_x[i] - h_y[i]));
}
return max_diff;
}
int main(int argc, char** argv) {
std::vector<int> Ns = {512, 1024, 2048};
std::vector<int> tiles = {8, 16, 32, 64};
int repeats = 3;
for (int i = 1; i < argc; ++i) {
std::string arg = argv[i];
if (arg == "--help" || arg == "-h") {
print_help(argv[0]);
return 0;
} else if (arg == "--n" && i + 1 < argc) {
Ns = parse_list(argv[++i]);
} else if (arg == "--tile" && i + 1 < argc) {
tiles = parse_list(argv[++i]);
} else if (arg == "--repeat" && i + 1 < argc) {
repeats = std::max(1, std::stoi(argv[++i]));
} else {
std::cerr << "Unknown or incomplete argument: " << arg << "\n";
print_help(argv[0]);
return 1;
}
}
cudaDeviceProp prop;
CUDA_CHECK(cudaGetDeviceProperties(&prop, 0));
std::cout << "GPU: " << prop.name << "\n";
std::cout << "Max threads per block: " << prop.maxThreadsPerBlock << "\n";
std::cout << "Shared memory per block: " << prop.sharedMemPerBlock / 1024 << " KB\n\n";
std::cout << std::left
<< std::setw(8) << "N"
<< std::setw(8) << "TILE"
<< std::setw(14) << "naive_ms"
<< std::setw(14) << "shared_ms"
<< std::setw(12) << "speedup"
<< std::setw(14) << "max_diff"
<< "status\n";
for (int N : Ns) {
if (N <= 0) {
std::cerr << "Skip invalid N=" << N << "\n";
continue;
}
size_t count = static_cast<size_t>(N) * static_cast<size_t>(N);
size_t bytes = count * sizeof(float);
std::vector<float> h_A(count), h_B(count);
for (size_t i = 0; i < count; ++i) {
h_A[i] = static_cast<float>((i * 17 + 13) % 100) / 100.0f;
h_B[i] = static_cast<float>((i * 31 + 7) % 100) / 100.0f;
}
float *d_A = nullptr, *d_B = nullptr, *d_C_naive = nullptr, *d_C_shared = nullptr;
CUDA_CHECK(cudaMalloc(&d_A, bytes));
CUDA_CHECK(cudaMalloc(&d_B, bytes));
CUDA_CHECK(cudaMalloc(&d_C_naive, bytes));
CUDA_CHECK(cudaMalloc(&d_C_shared, bytes));
CUDA_CHECK(cudaMemcpy(d_A, h_A.data(), bytes, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_B, h_B.data(), bytes, cudaMemcpyHostToDevice));
for (int tile : tiles) {
std::cout << std::left << std::setw(8) << N << std::setw(8) << tile;
int threads_per_block = tile * tile;
size_t shared_bytes = 2ULL * tile * tile * sizeof(float);
if (tile <= 0) {
std::cout << std::setw(54) << "" << "SKIP: TILE must be positive\n";
continue;
}
if (threads_per_block > prop.maxThreadsPerBlock) {
std::cout << std::setw(54) << ""
<< "SKIP: TILE*TILE=" << threads_per_block
<< " > maxThreadsPerBlock=" << prop.maxThreadsPerBlock << "\n";
continue;
}
if (tile > prop.maxThreadsDim[0] || tile > prop.maxThreadsDim[1]) {
std::cout << std::setw(54) << "" << "SKIP: block dimension exceeds device limit\n";
continue;
}
if (shared_bytes > static_cast<size_t>(prop.sharedMemPerBlock)) {
std::cout << std::setw(54) << "" << "SKIP: shared memory exceeds device limit\n";
continue;
}
dim3 block(tile, tile);
dim3 grid((N + tile - 1) / tile, (N + tile - 1) / tile);
auto launch_naive = [&]() {
matmul_naive<<<grid, block>>>(d_A, d_B, d_C_naive, N);
CUDA_CHECK(cudaGetLastError());
};
auto launch_shared = [&]() {
matmul_shared<<<grid, block, shared_bytes>>>(d_A, d_B, d_C_shared, N);
CUDA_CHECK(cudaGetLastError());
};
float naive_ms = time_kernel(launch_naive, repeats);
float shared_ms = time_kernel(launch_shared, repeats);
float diff = max_abs_diff(d_C_naive, d_C_shared, count);
std::cout << std::fixed << std::setprecision(3)
<< std::setw(14) << naive_ms
<< std::setw(14) << shared_ms
<< std::setw(12) << naive_ms / shared_ms
<< std::setw(14) << diff
<< (diff <= 1e-2f * N ? "OK" : "CHECK") << "\n";
}
CUDA_CHECK(cudaFree(d_A));
CUDA_CHECK(cudaFree(d_B));
CUDA_CHECK(cudaFree(d_C_naive));
CUDA_CHECK(cudaFree(d_C_shared));
}
return 0;
}
// # 自定义多组实验:按需修改 N/TILE 列表
// !./share_mem --n 1024,2048,4096 --tile 8,16,32,64 --repeat 3

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)