【transformer前置篇-01】深入理解前馈神经网络的实现原理
深入理解神经网络的实现原理和作用
如需转载,请附上链接:https://zhenghuisheng.blog.csdn.net/article/details/160909017
一、什么是神经网络?
前面两篇文章聊了 AI 的大致发展史。我们知道,AI 大模型真正爆发,离不开 2017 年那篇著名论文《Attention Is All You Need》提出的 Transformer 架构;GPT 里的 “T”,指的也是 Transformer。
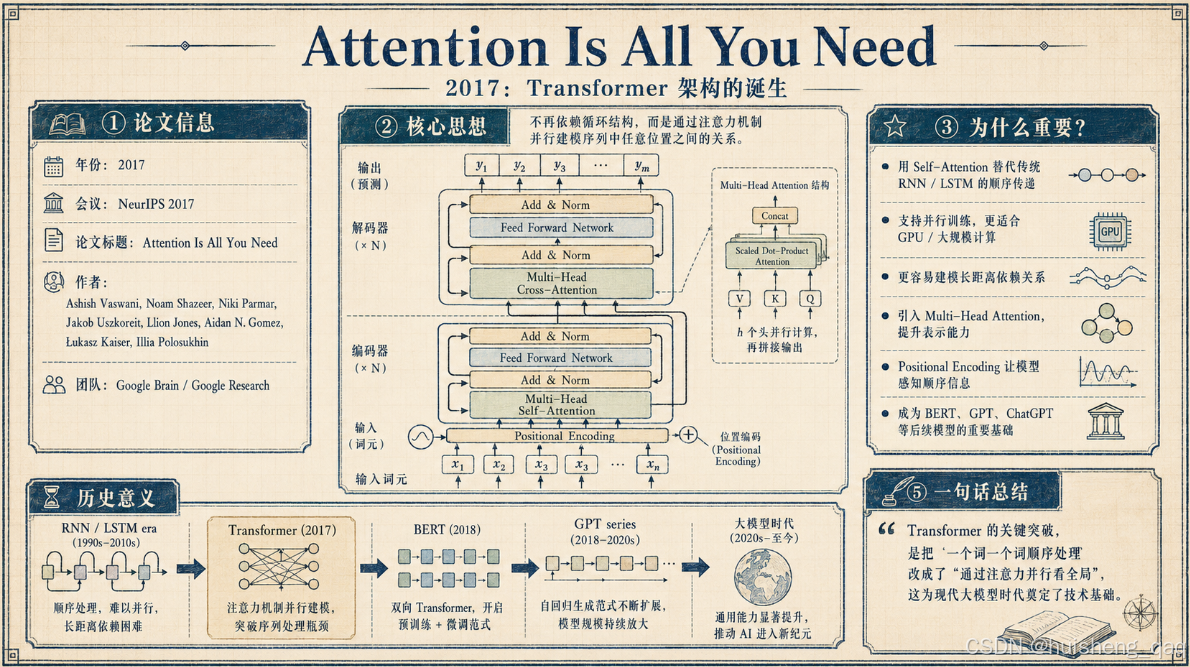
不过在进入 Transformer 之前,有几个更基础的问题需要先搞清楚:神经网络到底是什么?它是怎么从输入算到输出的?为什么它能"学会"规律?把这些基础打牢,后面再看 RNN、LSTM、Transformer 就会轻松很多。
1. 为什么要先讲神经网络?
你可能已经听过无数次 Transformer、GPT、大模型这些词了。但如果直接跳进去看它们的架构图,大概率会懵:什么是 Attention?什么是多头?前馈网络是啥?这就好比你直接看一部电影的大结局,前面的剧情全没看,虽然画面很震撼,但你不知道角色为什么做出那个选择。
所有这些模型的底层,其实都还是"神经网络"。不把神经网络这一层搞清楚,后面看 RNN、LSTM、Transformer 都会一直卡在一些基础概念上。
所以这一篇,我们只聚焦一件事:神经网络到底是什么,它是怎么把输入一步一步算成输出的。 RNN 和 Transformer 这些后来的结构,会在后续文章里专门讲。
本篇要回答的问题:
| 问题 | 简短回答 |
|---|---|
| 神经网络是什么? | 一套从数据中学规律的计算结构 |
| 它和传统程序有什么区别? | 传统程序靠人写规则,神经网络靠数据学规则 |
| 神经元、权重、偏置、激活函数是什么? | 神经网络的最小计算单元和核心组件 |
| 输入层、隐藏层、输出层分别做什么? | 分别负责接收数据、提取规律、给出结果 |
| 神经网络为什么能"学会"? | 通过前向传播 + 反向传播不断调整参数 |
| 它擅长什么,又不擅长什么? | 擅长固定长度、结构化数据;不天然适合语言 |
2. 神经网络是什么?
神经网络的本质是:**一套通过大量数据,自动学习输入和输出之间规律的计算结构。**它跟人脑的关系,大概相当于飞机和鸟的关系——灵感来源于此,但工作原理完全不同。
传统程序的逻辑就是"人先写规则,程序按规则跑"。比如:
if (score >= 60) {
return "及格";
} else {
return "不及格";
}
这种问题人类能把规则写清楚,所以 if else 就够了。但有些问题,人类自己都说不清规则到底是什么:
- 怎么判断一张图片里有没有猫?(你要怎么写 if else?说"耳朵是三角形"?三角形怎么写?)
- 怎么判断一句评论是夸奖还是抱怨?
- 怎么判断一个用户接下来会不会购买商品?
- 怎么判断一句话后面最可能接哪个词?
这些问题靠手写规则几乎做不完,规则太多、太模糊、还互相冲突。所以人们换了一种思路:**别让程序员把规则写死,而是给模型大量样本,让模型自己从数据里把规律找出来。**这就是神经网络在做的事。
2.1 神经网络不是写规则,而是学规则
理解神经网络最关键的一点,是先抓住它和传统程序的根本区别:
| 对比项 | 传统程序 | 神经网络 |
|---|---|---|
| 规则来源 | 程序员手写 | 模型从数据中学习 |
| 适合问题 | 规则明确的问题 | 规则复杂、难手写的问题 |
| 例子 | 分数判断、权限校验 | 图片识别、语音识别、文本理解 |
| 核心方式 | if else / 固定逻辑 | 数据 + 参数 + 计算 |
可以这样理解:
传统程序像是一本写好的菜谱,每一步都是固定的;
神经网络像是给厨师看了一万道菜,让他自己琢磨"什么样的食材组合大概率好吃"。
当然,神经网络也不是完全不需要人设计。模型结构、训练目标、数据质量仍然需要工程师设计和把控,只是具体的判断规则不再由人一条条手写。
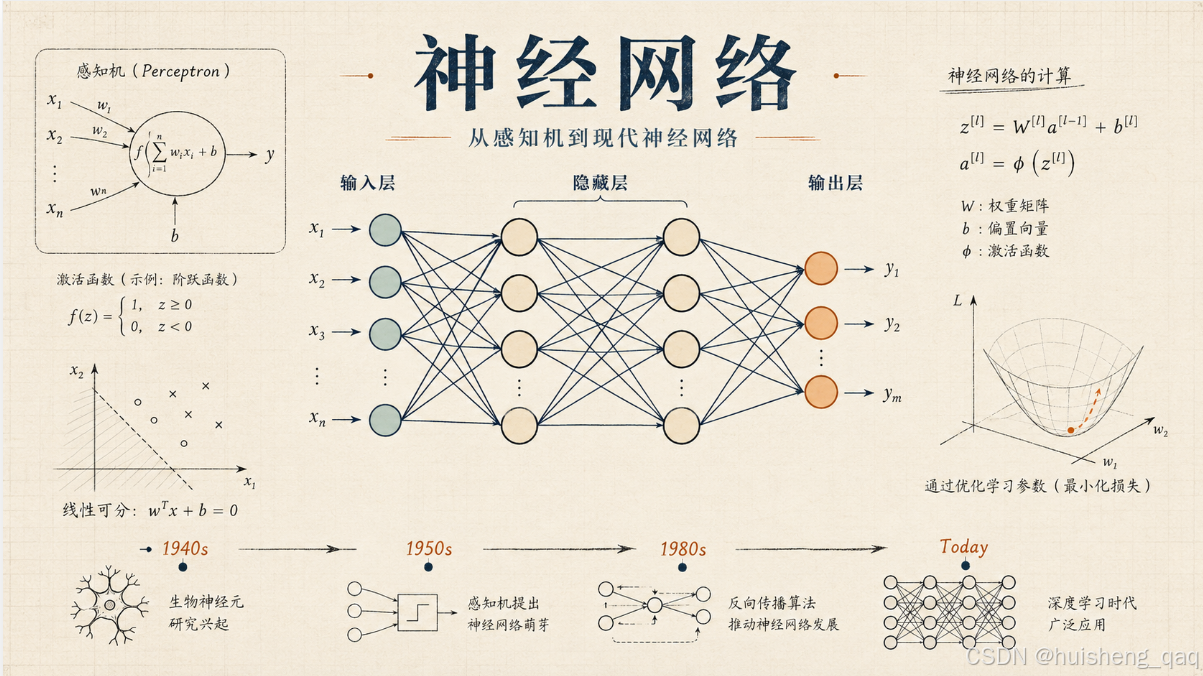
2.2 最小单元:神经元
神经网络是由大量"神经元"组成的,我们完全可以把神经元理解成一个小小的判断器。
每个神经元做的事情其实很机械:
输入1 ──┐
输入2 ──┤
输入3 ──┤──→ 加权求和 ──→ 加上偏置 ──→ 激活函数 ──→ 输出
... ──┤
输入n ──┘
拆开来看:
| 概念 | 作用 | 通俗理解 |
|---|---|---|
| 输入 | 神经元看到的特征 | 比如学历、经验、项目数 |
| 权重 | 每个输入有多重要 | 公司有多看重这一项 |
| 偏置 | 给整体判断加一个基础修正 | 整体录用门槛是高是低 |
| 激活函数 | 决定输出什么样的结果 | 综合分数最后怎么转成"录不录" |
| 输出 | 这个神经元给出的结论 | 推荐 / 不推荐 |
如果非要写一个最简单的伪公式,长这样:
输出 = 激活函数(输入1×权重1 + 输入2×权重2 + ... + 偏置)
举个面试的例子:
你去面试 Java 后端岗位。学历、工作经验、项目经历、表达能力是输入;公司对每项能力的重视程度是权重;这家公司整体门槛是偏置;最后综合一下,再过一道判断(激活函数),得出"要不要给 offer"。
一个神经元就是这么个东西——把一组数字,按一定的规则,揉成一个新的数字。
2.3 为什么需要权重?
如果没有权重,所有输入会被一视同仁地相加。但现实里不同特征的重要性差别很大。
还是拿 Java 后端岗位举例:
| 特征 | 重要性 |
|---|---|
| Java 基础 | 很重要 |
| Spring Boot 项目经验 | 很重要 |
| MySQL / Redis 能力 | 很重要 |
| 会不会唱歌 | 基本不重要 |
| 喜欢什么颜色 | 基本不重要 |
权重就是模型用来表达"哪些特征更重要、哪些特征没那么重要"的方式。重要的特征权重大,对结果影响就大;不重要的特征权重接近 0,几乎不影响结果。
需要注意的是:这些权重一开始是随机的,模型会在训练过程中不断调整它们
2.4 为什么需要偏置?
偏置(bias)这个词听起来玄乎,其实可以理解成一个基础门槛或者基础倾向。
继续用面试的例子:
- 一线大厂门槛高,同样的能力可能还差点意思;
- 中小公司门槛没那么高,同样的能力就能通过;
- 急招岗位门槛会临时降低,普通能力也可能录用。
哪怕几个候选人能力一模一样(输入相同、权重相同),不同公司、不同时期给出的录用结论也可能不一样。这种"整体偏移"就是偏置在起的作用。
一句话总结:权重决定每个输入的影响力,偏置决定整体往哪边偏。
2.5 为什么需要激活函数?
如果一个神经元只做"输入 × 权重 + 偏置",那它本质上就是个线性函数。哪怕你叠很多层这种神经元,整体效果还是等价于一个线性模型——表达能力非常有限。
但现实问题大多不是一条直线能分清的。
比如判断"该不该录用":
- 不是简单的"学历越高越好"——学历普通但项目硬核的人也可能很厉害;
- 也不是简单的"经验越长越好"——干了十年但项目都很水的也大有人在;
- 各种特征之间还会互相影响——经验少但学历高、有大厂背景,又是另一种判断。
这种弯弯绕绕的关系,线性模型搞不定。
激活函数的作用,就是让神经网络具备表达复杂非线性关系的能力。
可以这样记:
没有激活函数,多层网络叠起来仍然只是一个加强版的线性模型;
有了激活函数,模型才有能力学习更复杂的规律。
至于常见的 ReLU、Sigmoid、Tanh 这些具体激活函数长啥样、各自适合什么场景,本文不展开,先有这个概念就够了。
2.6 用一个完整例子理解神经元:用户会不会下单?
前面讲了神经元的五个组成部分:输入、权重、偏置、激活函数、输出。概念铺完了,但多数人第一次看,脑子里这几个东西还是散的,拼不起来。下面用一个后端程序员熟悉的场景——电商系统判断用户这次访问是否有较高概率下单,把单个神经元怎么工作的从头到尾算一遍。
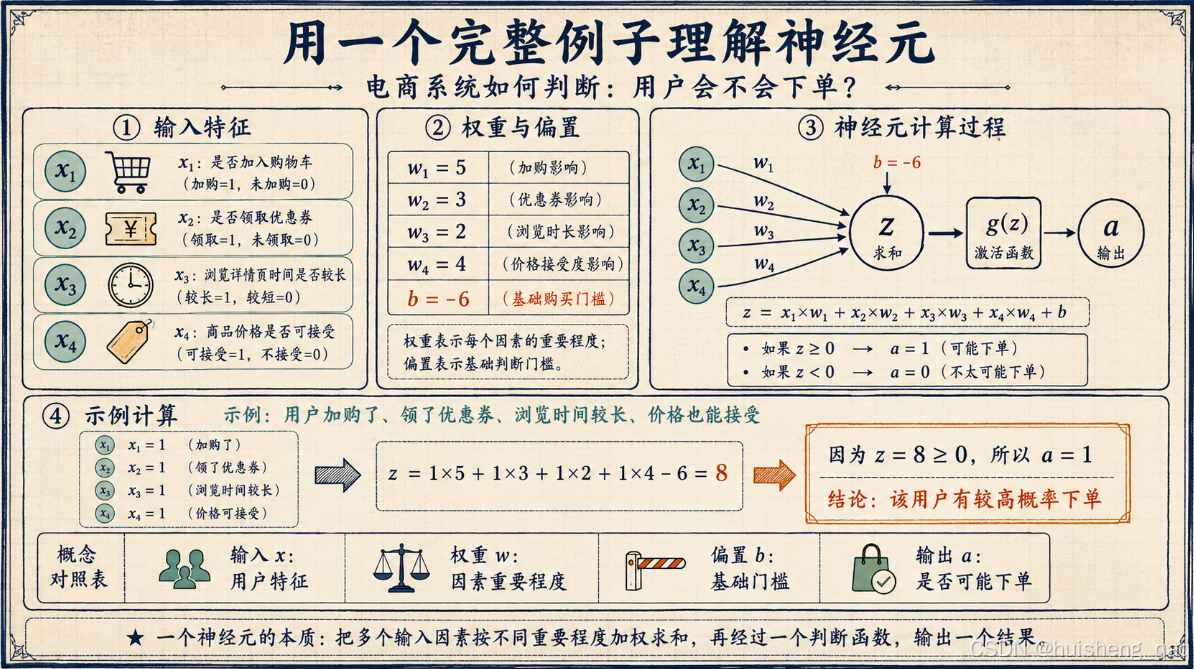
场景设定
假设我们手上有一个简化版的"下单预测神经元",只看四个特征:
| 输入 | 含义 | 取值 |
|---|---|---|
| x1 | 用户是否加入购物车 | 加购 = 1,未加购 = 0 |
| x2 | 用户是否领取优惠券 | 领取 = 1,未领取 = 0 |
| x3 | 浏览详情页时间是否较长 | 较长 = 1,较短 = 0 |
| x4 | 商品价格是否在用户可接受范围内 | 可接受 = 1,不接受 = 0 |
每个特征对"会不会下单"的影响是不一样的。假设经过训练之后,这个神经元得到了下面这组权重:
| 权重 | 含义 | 数值 |
|---|---|---|
| w1 | 加购对下单的影响 | 5 |
| w2 | 优惠券对下单的影响 | 3 |
| w3 | 浏览时长对下单的影响 | 2 |
| w4 | 价格接受度对下单的影响 | 4 |
再给一个偏置:
b = -6
偏置为什么是负的?因为现实里大多数用户打开详情页其实并不会立刻下单,模型默认应该保守一点——没有足够强的正向信号,就先判定为"不下单"。b = -6 就相当于给这个神经元设了一个"基础门槛"。
计算公式
一个神经元的计算其实就两步:
第一步:z = x1×w1 + x2×w2 + x3×w3 + x4×w4 + b
第二步:a = g(z)
这里激活函数 g(z) 用最简单的版本(阶跃函数):
如果 z >= 0 → a = 1,表示"可能下单"
如果 z < 0 → a = 0,表示"不太可能下单"
下面来算四种真实场景。
情况 1:加购了,领了券,浏览时间长,价格也能接受
这是"下单概率非常高"的用户。
x1 = 1 (加购了)
x2 = 1 (领了券)
x3 = 1 (浏览时间长)
x4 = 1 (价格能接受)
z = 1×5 + 1×3 + 1×2 + 1×4 + (-6) = 5 + 3 + 2 + 4 - 6 = 8
z >= 0 → a = 1
结论:可能下单。 四个正向因素全部拉满,综合分数远超门槛。
情况 2:没加购,但领了券、看得久、价格能接受
用户还在犹豫阶段,没有把商品放进购物车,但其他信号都还不错。
x1 = 0 (没加购)
x2 = 1 (领了券)
x3 = 1 (浏览时间长)
x4 = 1 (价格能接受)
z = 0×5 + 1×3 + 1×2 + 1×4 + (-6) = 0 + 3 + 2 + 4 - 6 = 3
z >= 0 → a = 1
结论:可能下单。 虽然少了"加购"这个强信号,但券、时长、价格三个因素加起来仍然能越过门槛。
情况 3:没加购、没领券、只看了一会儿,但价格能接受
这是典型的"随便逛逛"用户。
x1 = 0 (没加购)
x2 = 0 (没领券)
x3 = 0 (浏览时间短)
x4 = 1 (价格能接受)
z = 0×5 + 0×3 + 0×2 + 1×4 + (-6) = 0 + 0 + 0 + 4 - 6 = -2
z < 0 → a = 0
结论:不太可能下单。 只有"价格能接受"这一个正向信号,分量不够,连基础门槛都没过。
情况 4:加购了,但价格超出接受范围,也没领券
用户加购表达了兴趣,但价格是个硬门槛。
x1 = 1 (加购了)
x2 = 0 (没领券)
x3 = 0 (浏览时间短,看到价格后很快离开)
x4 = 0 (价格超出接受范围)
z = 1×5 + 0×3 + 0×2 + 0×4 + (-6) = 5 + 0 + 0 + 0 - 6 = -1
z < 0 → a = 0
结论:不太可能下单。 加购贡献了 +5,但在价格不合适、没有券缓冲、停留又短的组合下,依然过不了 -6 的基础门槛。
把概念对应起来
回过头看,刚才那堆 x、w、b、z、a,每个都能在这个例子里找到对应:
| 神经网络概念 | 在例子中对应什么 |
|---|---|
| x1、x2、x3、x4 | 加购、领券、浏览时长、价格接受度 |
| w1、w2、w3、w4 | 每个因素对下单的影响程度 |
| b | 基础购买门槛(一个负数,表示默认不下单) |
| z | 综合购买意愿分数 |
| g(z) | 判断这个分数有没有超过下单门槛 |
| a | 最终输出:可能下单 / 不太可能下单 |
一个神经元本质上就是在做一件事:**把多个输入因素按照不同重要程度加权求和,再经过一个判断函数,最后输出一个结果。**当然,真实的电商下单预测不会只看这 4 个特征,真实的神经网络也不会只有 1 个神经元——会有成千上万个神经元组成多层网络,分别负责不同维度的判断。
还有一个关键问题先不展开:w1~w4 和 b 这组参数到底是怎么来的? 本章假设它们已经被训练好了。至于这些权重具体是怎么一步步从数据里学出来的,留到下一章"神经网络为什么能学习"里讲。
2.7 多个神经元为什么要组成多层网络?
一个神经元能表达的判断非常有限——它就是把一堆输入揉成一个数。但很多神经元堆在一起、再分成多层,事情就变得有意思了:
- 一个神经元:判断一个小特征
- 一层神经元:并行判断一组特征
- 多层神经元:一层一层把简单特征组合成复杂特征
例 1:判断一张图是不是猫(这是一个示意性的层次划分,真实网络的分工没有这么整齐,但思路是对的):
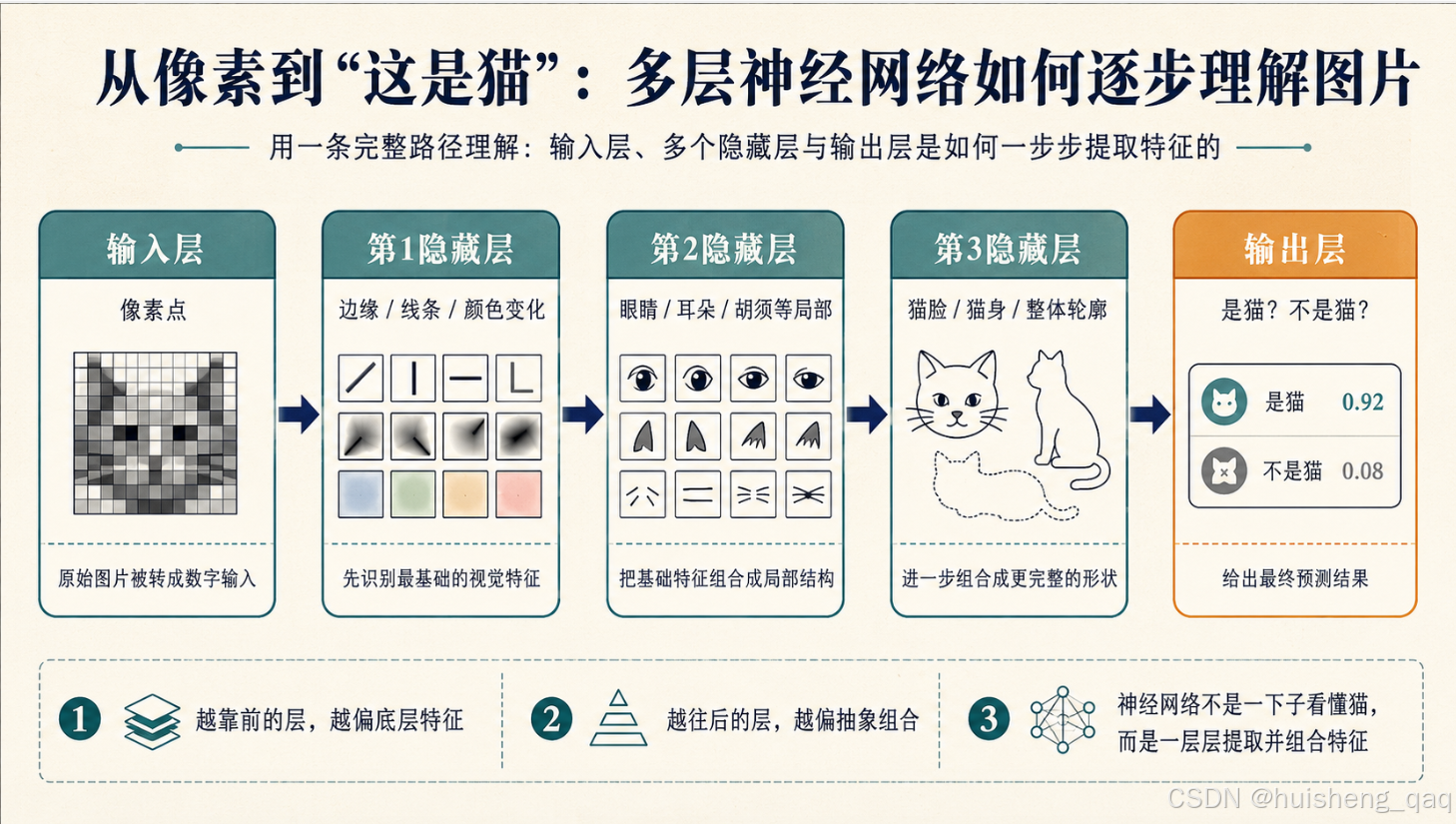
模型不是一下子"看懂猫"的,而是:
- 先从一堆原始像素里识别出最简单的图案(边缘、颜色变化)
- 再把这些简单图案组合成局部特征(眼睛、耳朵、胡须)
- 再把局部特征组合成更高层的概念(猫脸、猫身体)
- 最后输出层给出"是不是猫"的判断
例 2:回到电商下单预测
2.6 里那个"下单预测神经元"只是一个神经元,只能综合 4 个特征给出一个粗糙的判断。如果把网络扩成多层,就可以做得更精细:
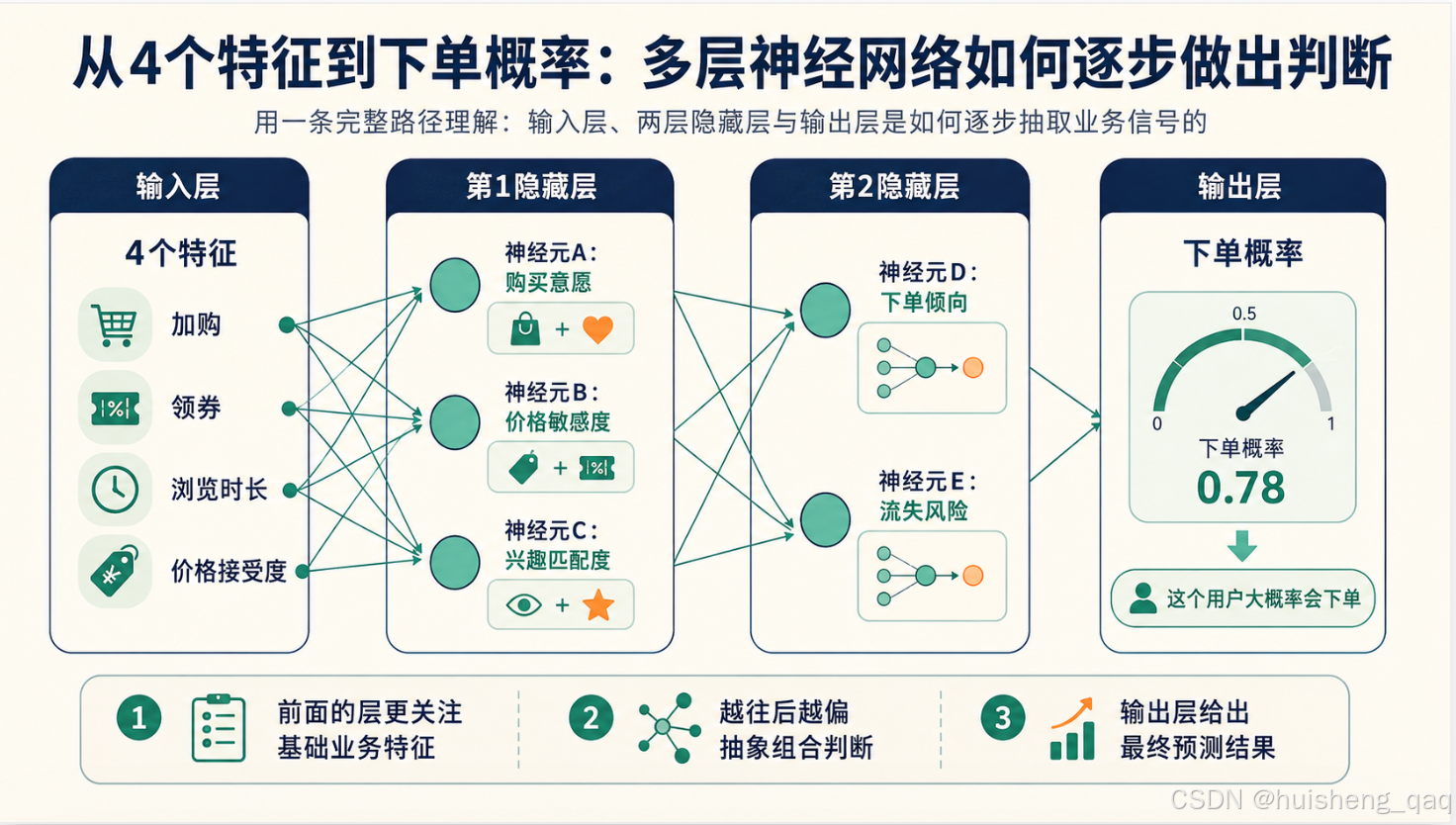
可以这样理解:
- 第 1 隐藏层里的几个神经元各自看同一组输入,但侧重点不同。A 更看重加购和浏览时长(算购买意愿),B 更看重价格和优惠券(算价格敏感度),C 更看重浏览时长和加购(算兴趣匹配度)
- 第 2 隐藏层不再直接看原始特征,而是在 A、B、C 的输出之上再做一轮组合,得到更高层的判断(下单倾向、流失风险)
- 输出层把这些中间判断汇总成最终的下单概率
一个明显的变化是:越往后的隐藏层,特征越抽象——从"加没加购"这种原始信号,一步步变成"下单倾向"这种业务概念。这和猫图识别里"边缘 → 眼睛 → 猫脸"的思路是一样的,只是换了领域。
每多一层,模型就能表达更抽象、更复杂的特征。这就是为什么需要"多层",也是"深度学习"里"深度"两个字的由来。
2.8 输入层、隐藏层、输出层分别做什么?
把整个网络的结构画出来,是这样:
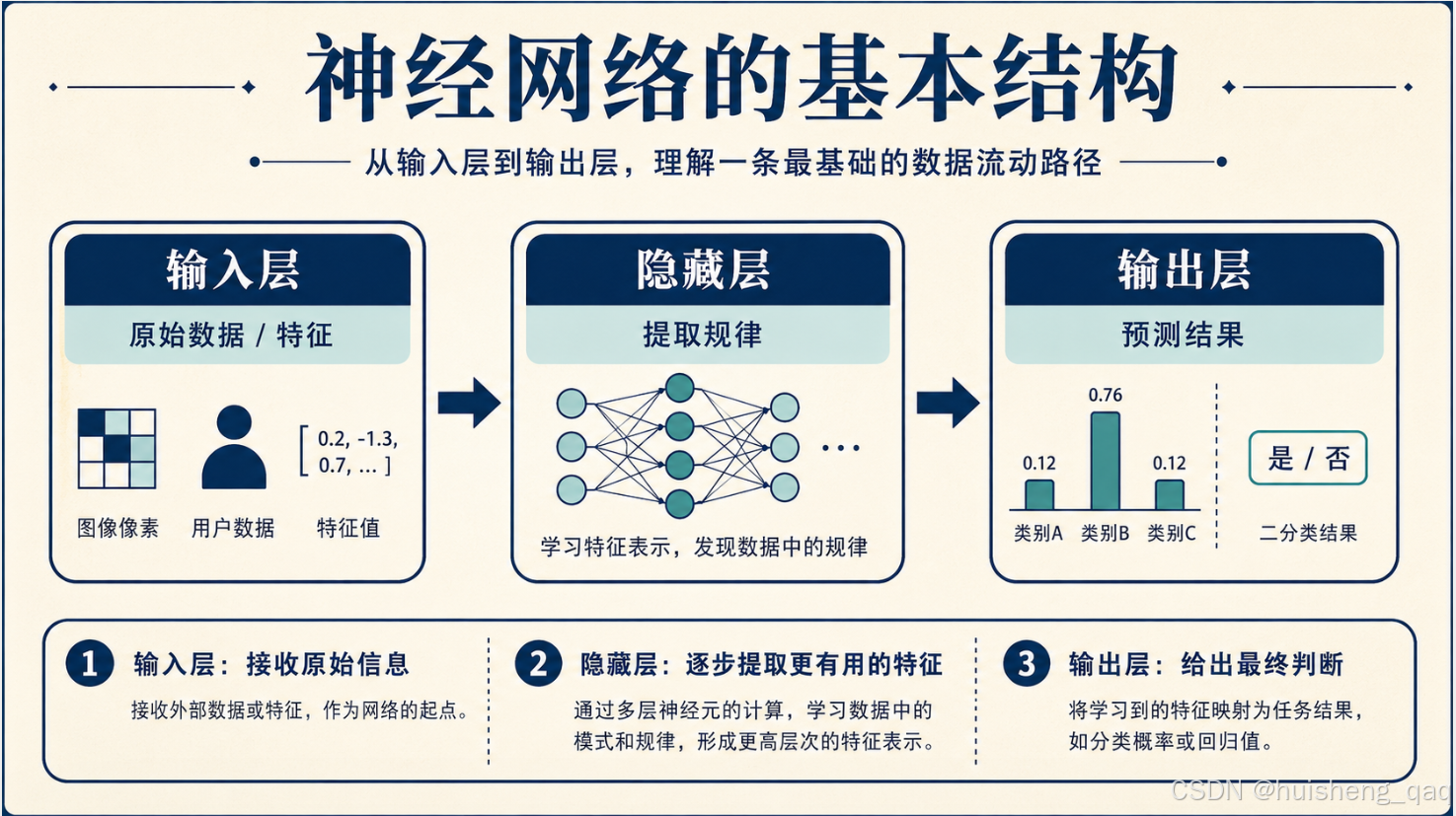
每一层的职责:
| 层级 | 作用 | 例子 |
|---|---|---|
| 输入层 | 接收原始数据 | 图片像素、用户年龄、文本向量 |
| 隐藏层 | 提取特征、组合规律 | 边缘、轮廓、局部特征、抽象概念 |
| 输出层 | 给出最终结果 | 是猫 / 不是猫,正面 / 负面 |
放到我们前面一直用的两个例子里,每一层具体做什么就更直观了:
| 层级 | 猫图识别 | 电商下单预测 |
|---|---|---|
| 输入层 | 图片的所有像素(几十万个数字) | 加购、领券、浏览时长、价格接受度 |
| 隐藏层 | 从边缘 → 局部器官 → 猫脸 | 从原始特征 → 购买意愿/价格敏感度 → 下单倾向 |
| 输出层 | 是猫 / 不是猫 | 下单 / 不下单(或下单概率) |
可能有人会问:为什么中间那些层叫"隐藏层"?因为它既不直接面对原始输入(不像输入层),也不直接给用户看结果(不像输出层),而是夹在中间默默做大量计算。从"使用者"视角看不到它在干什么,所以叫隐藏(hidden)。
但其实模型真正"学到东西"的地方,恰恰就在隐藏层里。
2.9 把整个流程串起来
把前面所有内容串起来,我们用两个例子分别走一遍"从输入到输出"的完整过程。
例 1:判断一张图是不是猫

例 2:判断这次访问的用户会不会下单

两个例子的领域完全不同,一个是图像,一个是业务数据,但本质上都是在做同一件事:把原始输入一层一层变成越来越抽象的特征,最后在输出层给出一个判断。
在整个过程里,没有人给程序写过"猫长什么样"的规则,也没有人写过"什么样的用户会下单"的规则。模型里那些权重和偏置,全部是从大量样本中学出来的。
至于这些参数到底怎么学出来的——下一节就讲这件事。
2.10 小结
简单回顾一下本节的关键点:
- 神经网络不是人脑复制品,而是一套从数据中学习规律的计算结构;
- 它和传统程序的根本区别是:传统程序靠程序员手写规则,神经网络靠数据学规则;
- 神经元是最小计算单元,核心包括输入、权重、偏置、激活函数、输出;
- 多层神经元连接起来,可以从简单特征一步步组合出复杂特征;
- 本节只讲了"输入怎么一步步算到输出",至于这些参数是怎么学出来的,下一节再讲。
理解了神经网络的基本结构,下一个自然的问题就是:这些权重和偏置,到底是怎么学出来的?
3. 神经网络为什么能学习?
上一节我们在电商下单预测那个例子里,直接给出了一组参数:w1=5、w2=3、w3=2、w4=4、b=-6。当时用一句"假设这组参数已经训练好了"暂时略过了这个问题。
但真正让人好奇的问题其实是:这些数字到底是从哪来的? 总不会是某位算法工程师拍脑袋写出来的——"加购权重定 5 比较合适"这种话。如果参数真是靠人拍脑袋决定的,那神经网络和传统 if else 也就没什么本质区别了。
这些权重和偏置,其实是模型通过大量数据自己慢慢调出来的。这一节就把这件事讲清楚:神经网络是怎么"从错误里改正自己"的。
3.1 训练过程:像考试一样反复练
神经网络的学习过程,本质上就是一个学生反复刷题的过程。没有天才,只有错题本。
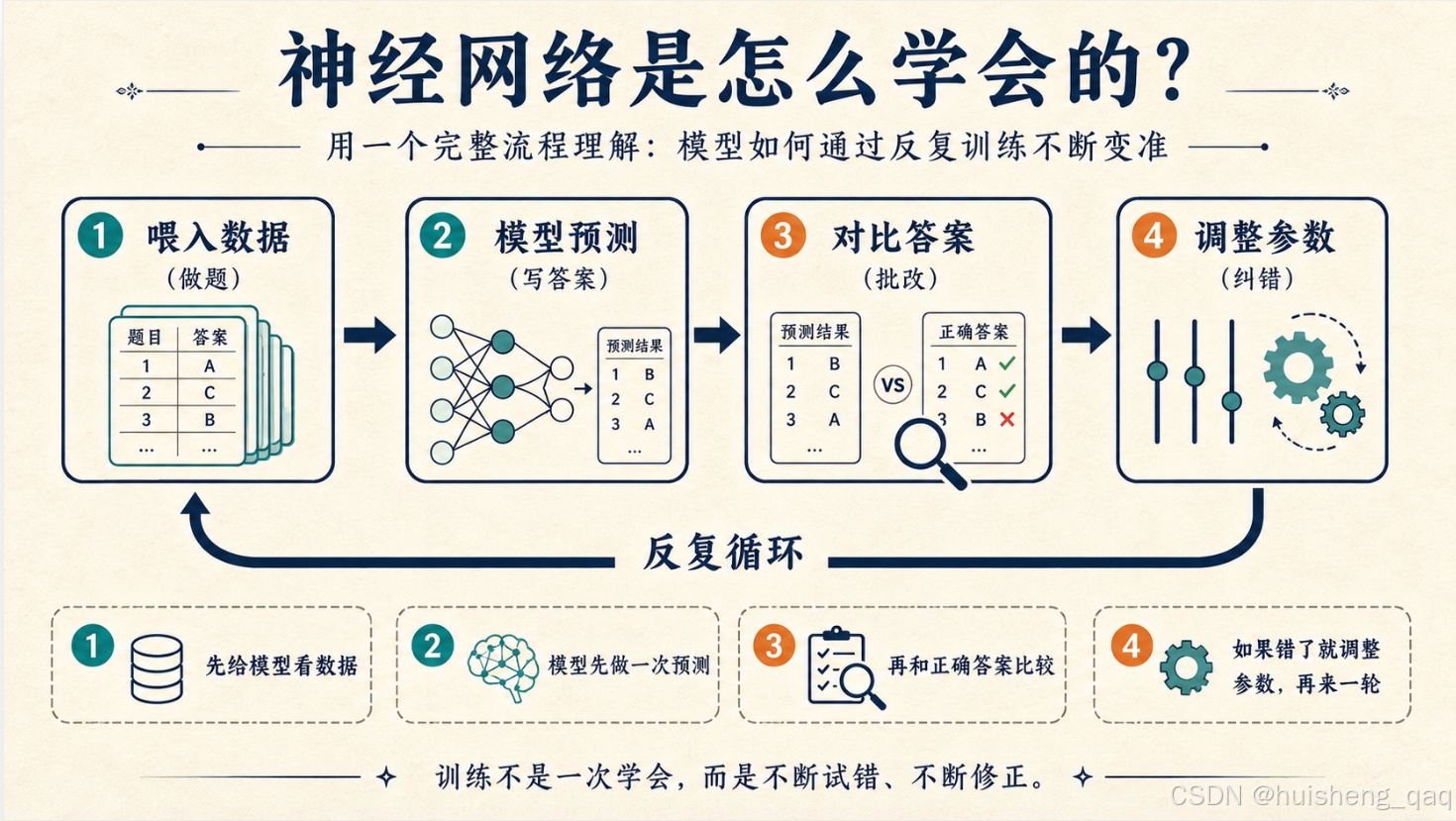
| 步骤 | 类比 | 技术术语 |
|---|---|---|
| 喂入数据 | 老师出题 | 输入训练样本 |
| 模型预测 | 学生写答案 | 前向传播 |
| 对比答案 | 老师批改 | 计算损失函数 |
| 调整参数 | 学生纠错 | 反向传播 + 梯度下降 |
| 反复循环 | 刷题一万遍 | 多轮训练(Epoch) |
一句话概括:模型先猜一个答案,然后根据对错调整自己,下次再猜得准一点。 猜一万次之后,它就"学会"了。
下面我们把这四个步骤拆开,继续用第 2.6 的电商下单预测例子一步一步走。
3.2 第一步:前向传播,模型先做一次预测
前向传播这个名字听着挺唬人,其实就一件事:数据从输入层进来,一路往前算,最后输出层吐出一个预测结果。 往前流,不回头。
还是那个下单预测神经元。假设现在来了一个用户,他的行为是这样的:
| 输入 | 含义 | 取值 |
|---|---|---|
| x1 | 是否加购 | 1(加了) |
| x2 | 是否领券 | 0(没领) |
| x3 | 浏览时长 | 1(看得挺久) |
| x4 | 价格接受度 | 0(嫌贵) |
此时模型手里的参数是(注意:这是训练某一刻的参数,不是最终版,后面还会被调):
w1 = 5, w2 = 3, w3 = 2, w4 = 4, b = -6
前向传播算一遍:
z = 1×5 + 0×3 + 1×2 + 0×4 + (-6)
= 5 + 0 + 2 + 0 - 6
= 1
z >= 0 → a = 1,模型判断:这个用户大概率会下单
模型给出的预测是:会下单。
小提示:前面为了方便理解,我们用了最简单的阶跃函数(z>=0 输出 1,否则输出 0)。但严格来说,阶跃函数在 z=0 处不可导,并不适合直接做反向传播训练。真实神经网络里,通常会用 Sigmoid、Softmax、ReLU 等更适合优化的激活函数,让模型可以平滑地计算误差并反向调整参数。这里先不展开数学细节,只理解训练流程即可。
记住这一步的核心:前向传播就是模型用当前参数,对一个样本做一次预测。 至于这个预测对不对,那是下一步的事。
3.3 第二步:计算误差,看看预测得有多离谱
模型预测完了,输出的结论是"这个用户会下单"。但翻开数据集看一眼真实结果:
y = 0,这个用户看了半天,最终什么也没买,关掉页面就走了。
模型这次预测错了,而且是过于乐观——把一个本来不会下单的用户判成了会下单。
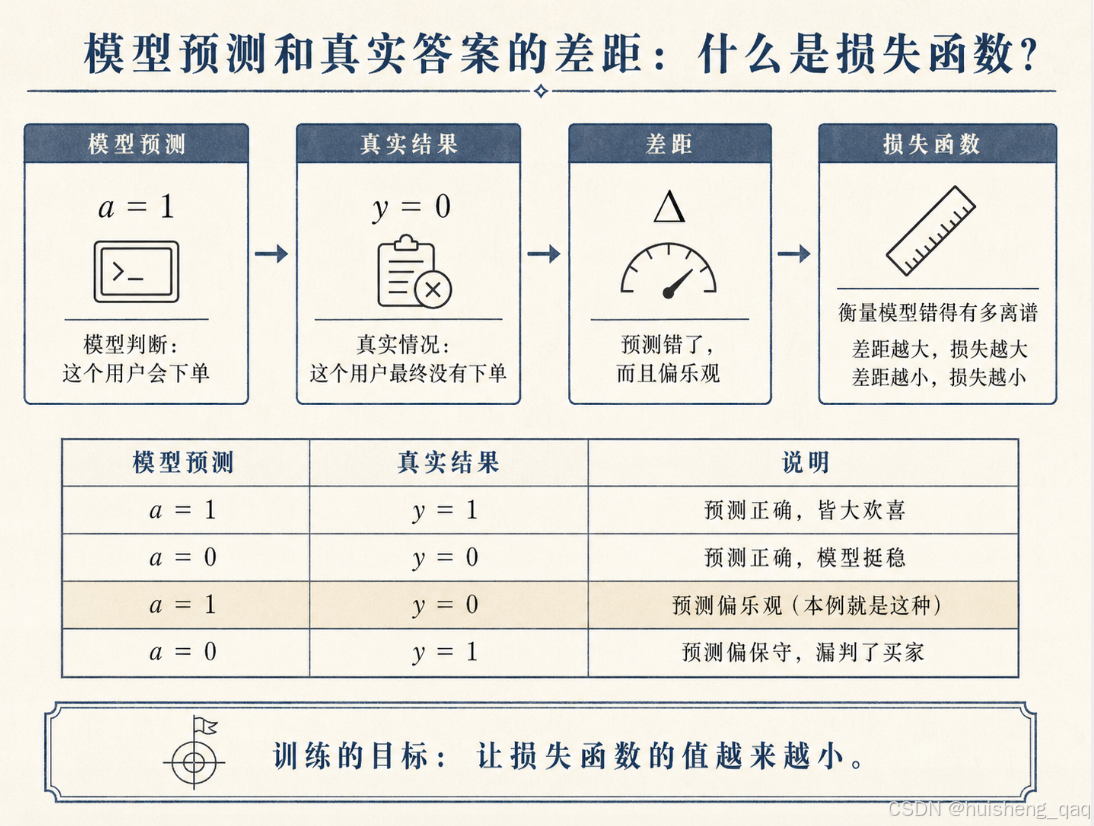
这种"预测和真实答案的差距",在神经网络里有一个专门的术语,叫损失函数(Loss Function)。
你不用去背它的公式,只需要记住它的直觉:
损失函数就是一把尺子,用来衡量"模型错得有多离谱"。
预测越接近真实答案 → 损失越小 → 模型越准;
预测越偏离真实答案 → 损失越大 → 模型需要被修正。
四种典型情况:
| 模型预测 | 真实结果 | 说明 |
|---|---|---|
| a = 1 | y = 1 | 预测正确,皆大欢喜 |
| a = 0 | y = 0 | 预测正确,模型挺稳 |
| a = 1 | y = 0 | 预测偏乐观(本例就是这种) |
| a = 0 | y = 1 | 预测偏保守,漏判了买家 |
模型训练的目标,说白了就是一句话:让损失函数的值越来越小。
3.4 第三步:反向传播,把错误传回去
知道自己错了还不够,关键是要搞清楚——到底是哪些参数导致了这次错误?
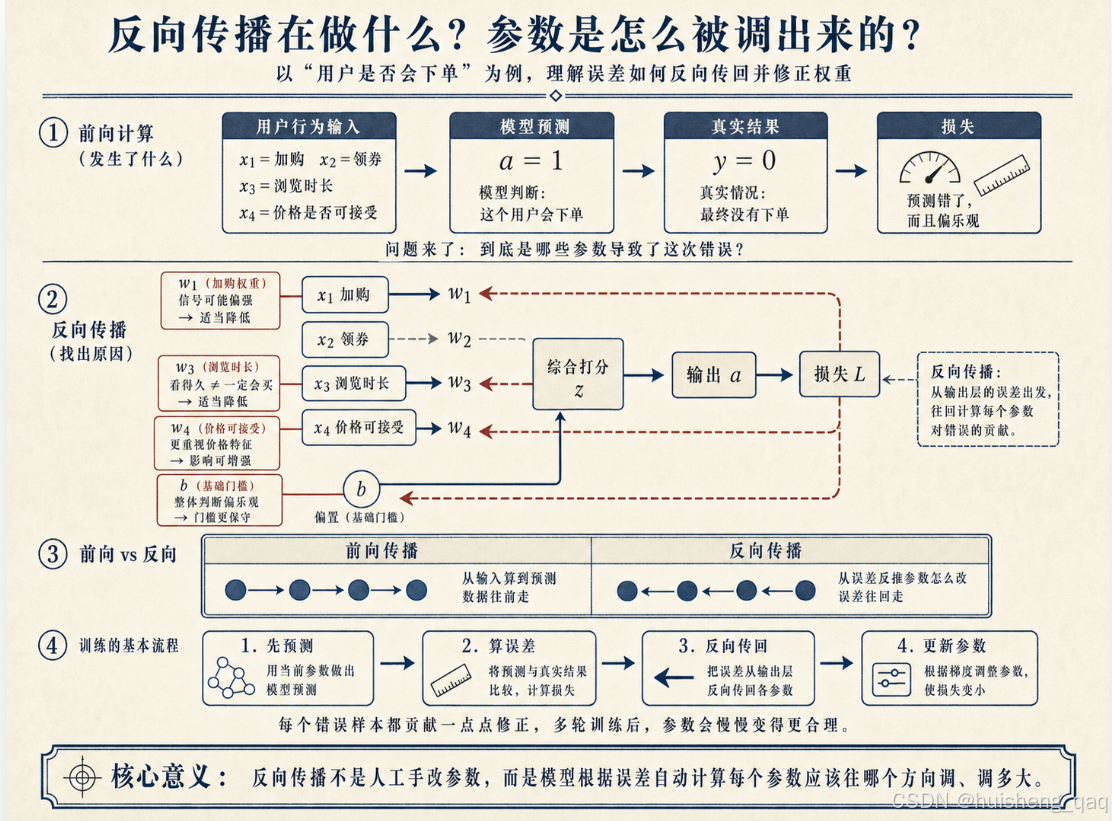
你可以把模型想象成一个项目出了 bug 的团队。Leader(损失函数)说:"这次预测错了,错得还挺严重。"光说没用,得复盘:
- w1(加购权重)是不是定得太高了,看见加购就直接判"会买"?
- w3(浏览时长)是不是也有点太乐观了,看得久 ≠ 真的要买?
- w4(价格接受度的权重)是不是不够大,没能体现出"价格能接受"这个正向信号的真实分量?
- b(基础门槛)是不是不够保守,应该再压低一点?
反向传播做的就是这件定位误差来源的事:从输出层的误差出发,一路往回推,算出每个参数对这次错误贡献了多少,然后告诉每个参数应该朝哪个方向调、调多大力度。
一句话对比:
前向传播:从输入算到预测(数据往前走)。
反向传播:从误差反推参数该怎么改(误差往回走)。
这里有一点需要强调:反向传播不是人手动说"把 w1 改成 4.8",而是数学上自动计算出每个参数的调整方向。 工程师只负责搭好网络、准备数据,参数怎么动,是模型根据误差自己算出来的。
回到电商的例子:如果训练数据里大量出现"加购了但最终没买"的样本——比如用户加购只是为了凑满减、或者只是先收藏一下、或者加完购看了眼价格就默默退出——模型就会逐渐学到:
- 加购这个信号没那么强,w1 该降一点;
- 浏览时间长也未必就是买家,可能只是在纠结,w3 可以小一点;
- 价格是否可接受是一个相当关键的特征,模型可能会更加重视这个特征的影响(注意:在我们目前这个简化编码里,x4=0 并不会直接产生负分,只是"少了一份正向加分"。如果想让"价格不可接受"成为更明确的负向信号,通常需要在特征工程里额外设计,比如新增一个 x5=价格不可接受,或者把价格特征改成连续值/带符号的特征。);
- 整体门槛 b 应该更保守一点,别那么容易输出"会下单"。
这些调整不是一次到位的,而是每个错误样本都贡献一点点修正,慢慢把参数推向更合理的位置。
3.5 第四步:梯度下降,沿着"错误变小"的方向挪一步
反向传播告诉了每个参数"你应该往哪边调",但具体怎么调、调多少,靠的是另一个机制:梯度下降(Gradient Descent)。这名字也很玄乎,但本质就一句话:下山找最低点。
想象这么个画面:你现在蒙着眼睛站在一座山上,目标是走到山谷最低处(也就是损失最小的地方)。你看不见全局地图,但你能用脚感知——当前位置往哪边迈一步会更低。于是你就朝着更低的方向挪一小步;到新位置再感知一下,再挪一小步;如此反复,总会走到一个比较低的地方。
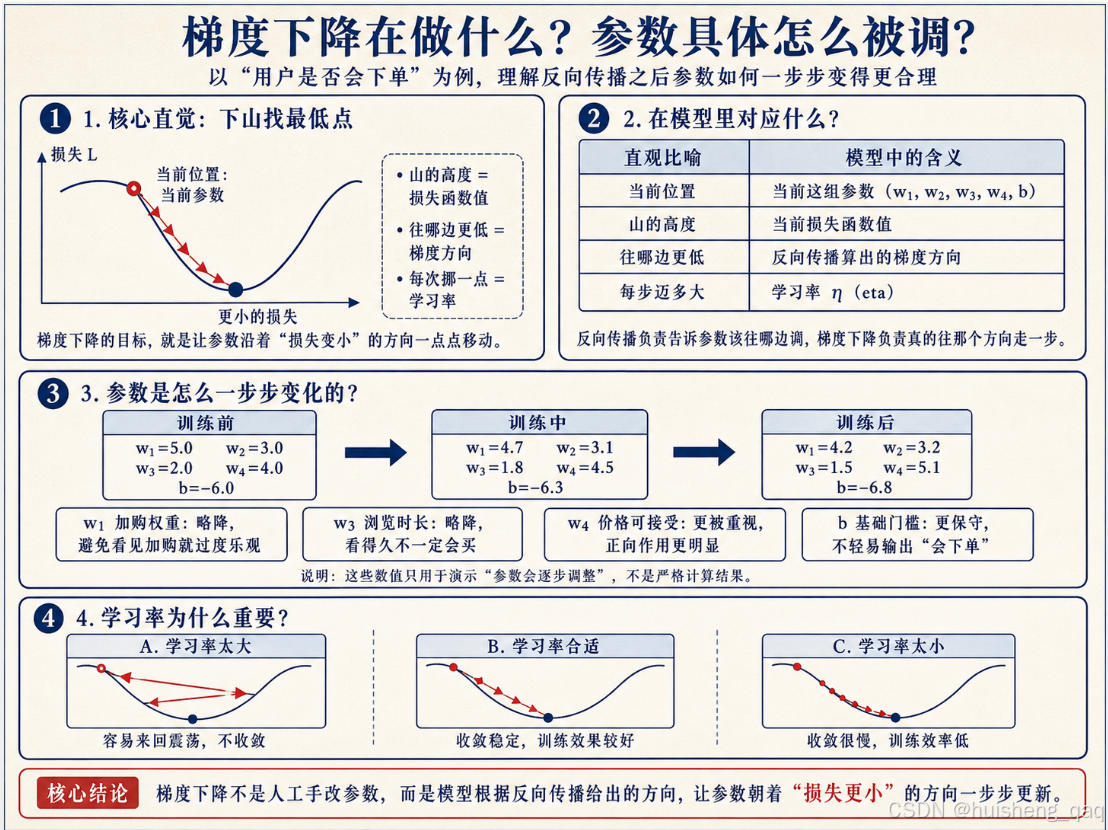
神经网络调参数就是这个逻辑:
- 当前位置 = 当前这组参数;
- 山的高度 = 损失函数的值;
- 往哪边走会更低 = 反向传播算出来的梯度方向;
- 每步迈多大 = 学习率(learning rate),一个超参数。
学习率这个超参数挺关键:迈太大容易一脚跨过山谷跳到对面山坡上(震荡不收敛),迈太小则训练效率会很低。学习率调节是训练中很常见的问题,工程师通常需要根据实际情况反复调整。
继续电商的例子,训练若干轮之后,参数可能会朝这个方向变化:
训练前: w1=5, w2=3, w3=2, w4=4, b=-6
训练中: w1=4.7, w2=3.1, w3=1.8, w4=4.5, b=-6.3
训练后: w1=4.2, w2=3.2, w3=1.5, w4=5.1, b=-6.8
(注意:上面的数字只是为了直观展示"参数会慢慢调整"这件事,并不是严格的计算结果。)
趋势上可以看到:加购和浏览时长的权重被压低了一点,价格接受度的权重被抬高了一点(说明模型更加重视这个特征),基础门槛变得更保守。模型不再那么容易"一看到加购就输出会下单"。
实际业务里,如果想让模型更精确地捕捉价格因素,往往还会通过特征工程引入更细的价格敏感度特征(比如价格档位、相对均价的偏差等),让模型有更明确的信号可学。
3.6 多轮训练:不是一次学会,而是反复纠错
你可能会问:看一个错样本就能学到这些吗?
当然不能。一个样本的信息量太小了,模型从一条数据里学到的东西,很可能只是噪声。 就像你不能因为见过一个戴眼镜的人是程序员,就下结论"戴眼镜的都是程序员"。
真实训练中,模型要看成千上万甚至上亿条样本。电商场景里这些情况都会混在一起:
- 有人加了购,真的下单了;
- 有人加了购,纯粹是凑满减运费,根本没打算买;
- 有人领了券就下单,奔着优惠来的;
- 有人领了券,也只是囤着以防万一;
- 有人浏览了半小时,下单,是深思熟虑型;
- 有人浏览了半小时,没下单,是纠结型;
- 有人价格合适也不买,纯属随便逛逛;
- 有人价格贵出一倍也照样买,刚需 + 品牌忠诚度。
所有这些样本一起喂给模型,模型在海量矛盾信号里,慢慢摸出那个能平均起来"预测得还不错"的参数组合。
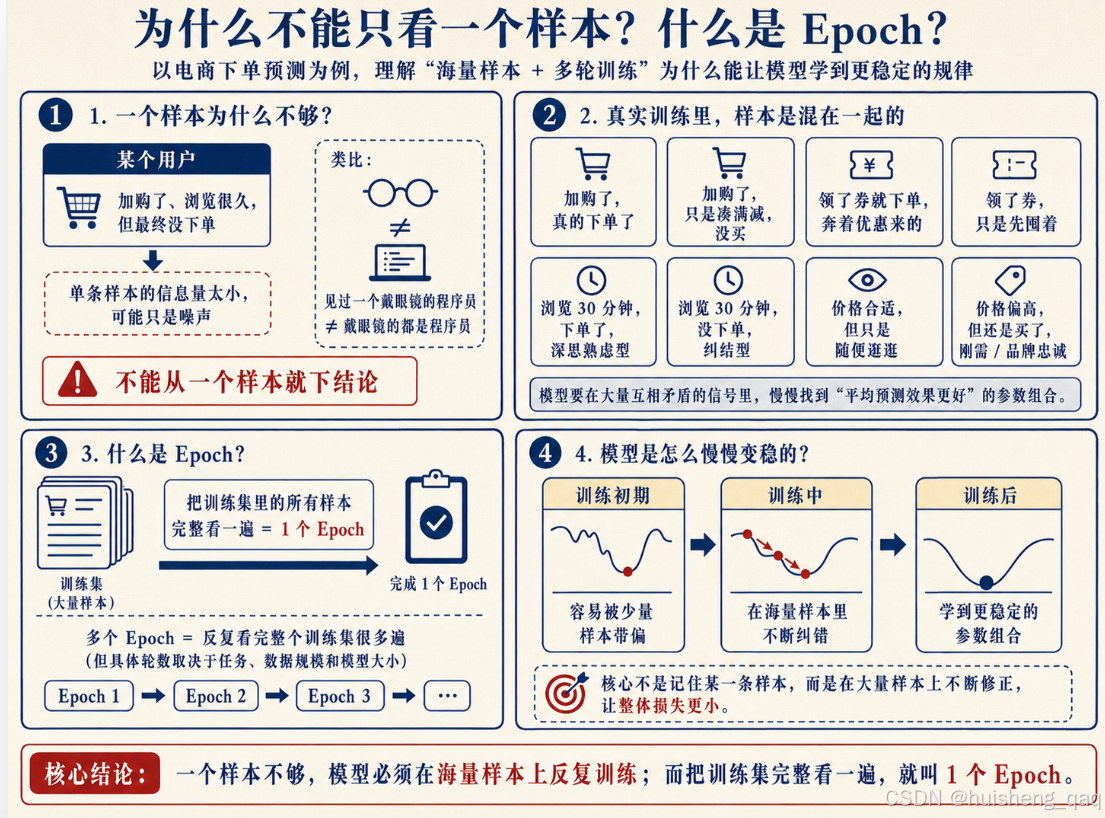
这里再补一个名词——Epoch(训练轮次):
模型把训练集里所有样本完整过一遍,就算一个 Epoch。
真实训练需要多少个 Epoch,取决于数据规模、模型大小和任务难度。有些任务需要很多轮才能让模型收敛,而在大规模训练里(比如数据量极大时)可能并不会反复遍历训练集太多次,但核心都是一样的:不断让参数朝着损失更小的方向调整,直到模型表现稳定,或者工程师认为已经足够好。
3.7 小结:所谓"学习",本质就是不断调整参数
回头看,神经网络的"学习"其实一点都不神秘,没有顿悟,没有灵光一闪,就是个非常机械的循环:
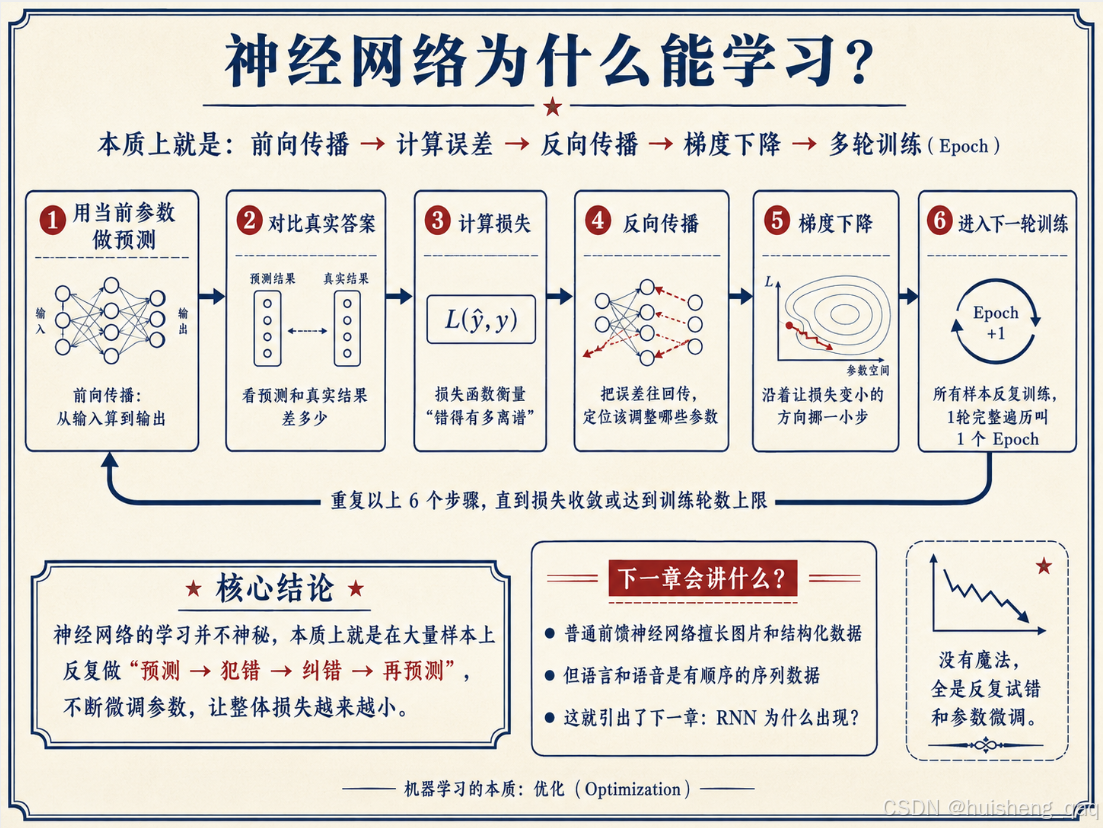
- 用当前参数,对一个样本做预测(前向传播);
- 把预测和真实答案对比,算出差距(损失函数);
- 把误差往回传,搞清楚每个参数该往哪调(反向传播);
- 沿着让损失变小的方向挪一小步(梯度下降);
- 换下一个样本,继续循环;
- 所有样本过一遍算一轮(Epoch),再来下一轮,直到模型够用为止。
所以你会发现——所谓训练神经网络,本质就是在几百万个参数上,反复做"微调 + 试错",一直调到损失足够小为止。 没有魔法,全是苦功夫。
到这里,神经网络"怎么从输入算到输出"和"怎么从错误里学到东西"这两件事就都讲完了。不过还有个问题等着我们:普通的前馈神经网络,虽然能学规律,但它处理一张图片、一条结构化数据很在行,处理一句话、一段语音就开始露怯了。
为啥?因为语言是有顺序的,而普通神经网络天然不关心顺序。这正是下一章要聊的事。
4. 前期神经网络的不足
4.1 普通前馈神经网络擅长什么?
我们前面讲的这种结构,专业一点的叫法是前馈神经网络(Feedforward Neural Network)。"前馈"两个字的意思是:数据从输入层一路往前流到输出层,中间不绕回头,也没有任何"记住上一次输入"的机制。 它就像一条单向流水线,进料 → 加工 → 出货,做完一单就忘掉一单。
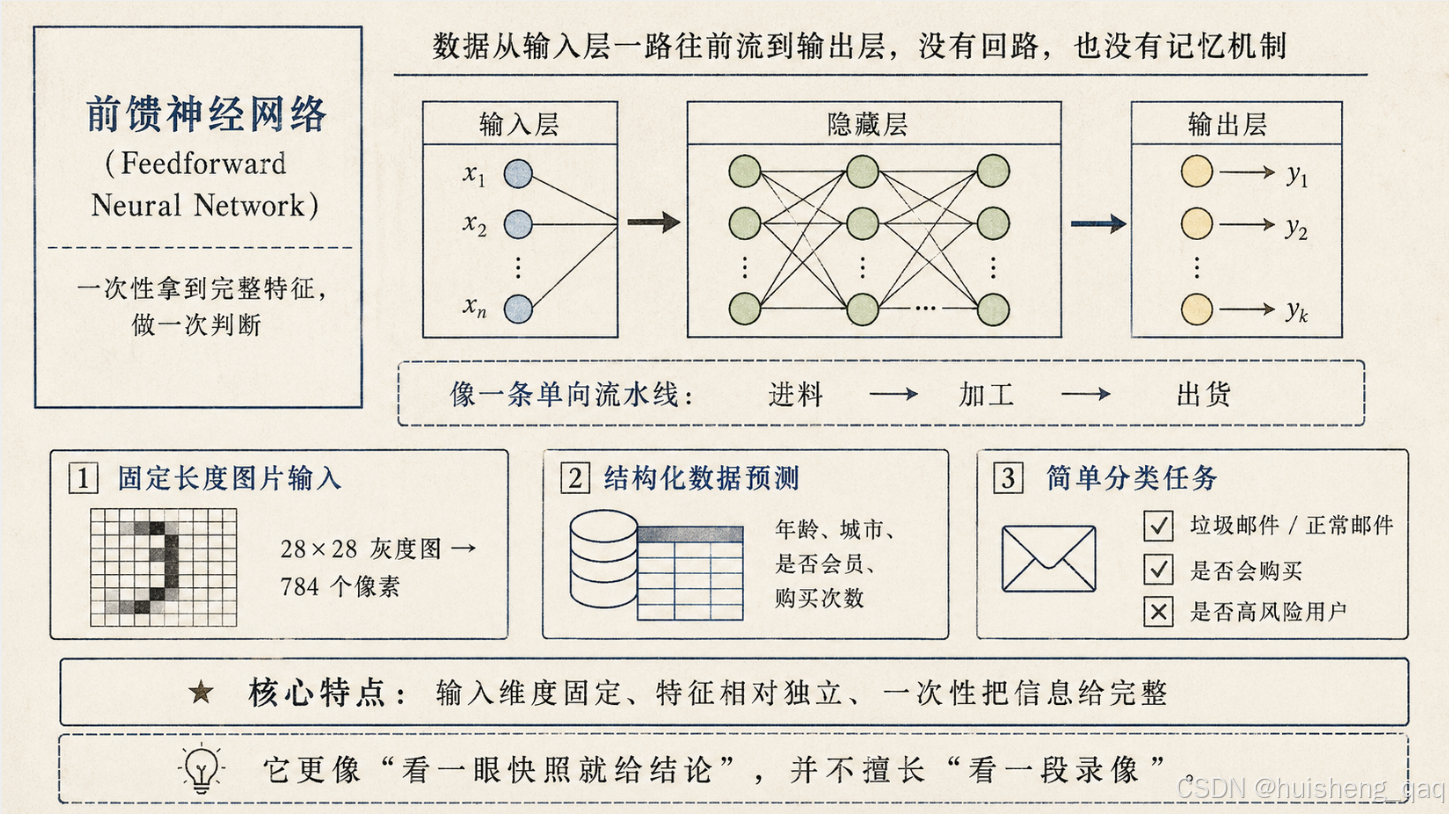
这种结构特别适合"输入维度固定、特征相对独立、一次性把信息给完整"的任务,比如:
- 固定长度的图片输入:一张 28×28 的灰度图,永远可以展平成 784 个像素,喂给模型;
- 结构化数据预测:用户年龄、所在城市、是否会员、历史购买次数等等,这些字段一行 SQL 就能查出来,长度固定;
- 简单分类任务:垃圾邮件 / 正常邮件、是否会购买、是否高风险用户。
这些任务有一个共同点:模型在做判断时,可以一次性拿到所有特征。 比如第 2.6 节那个电商下单预测的例子,加购、领券、浏览时长、价格接受度这四个特征可以整理成一个长度为 4 的固定向量,直接送进前馈网络,模型基于这一组特征算出一个结果就行了。
可以这么类比:前馈神经网络更像一个"看一眼快照就给结论"的判断器,并不擅长"看一段录像"。
4.2 它的核心限制:没有天然的"顺序感"
普通前馈神经网络在处理输入时,更像是把输入看成一组特征,而不是一段按时间展开的序列。它可以处理固定位置上的特征——比如 x1 永远表示加购、x2 永远表示领券、x3 永远表示浏览时长——这一点没问题。但它不会天然理解"哪个信息先发生、哪个信息后发生"。如果想让它理解顺序,就需要我们额外把顺序信息设计成特征(比如手动加上"加购在领券之前还是之后"这种字段)。
但有些任务里,顺序本身就是关键信息。如果模型不关心顺序,就会丢掉很重要的语义。
最典型的就是语言。
需要强调的是:普通前馈神经网络并不是完全不能处理语言。 通过人工特征工程、固定窗口(n-gram)、词袋模型这些办法,它也能解决一部分文本分类、情感分析任务。只不过它的结构本身不天然适合建模词序和上下文——一旦任务对顺序、对上下文、对长距离依赖敏感,前馈网络就开始吃力了。
下面我们具体看四个常见的"它不太擅长"的场景。
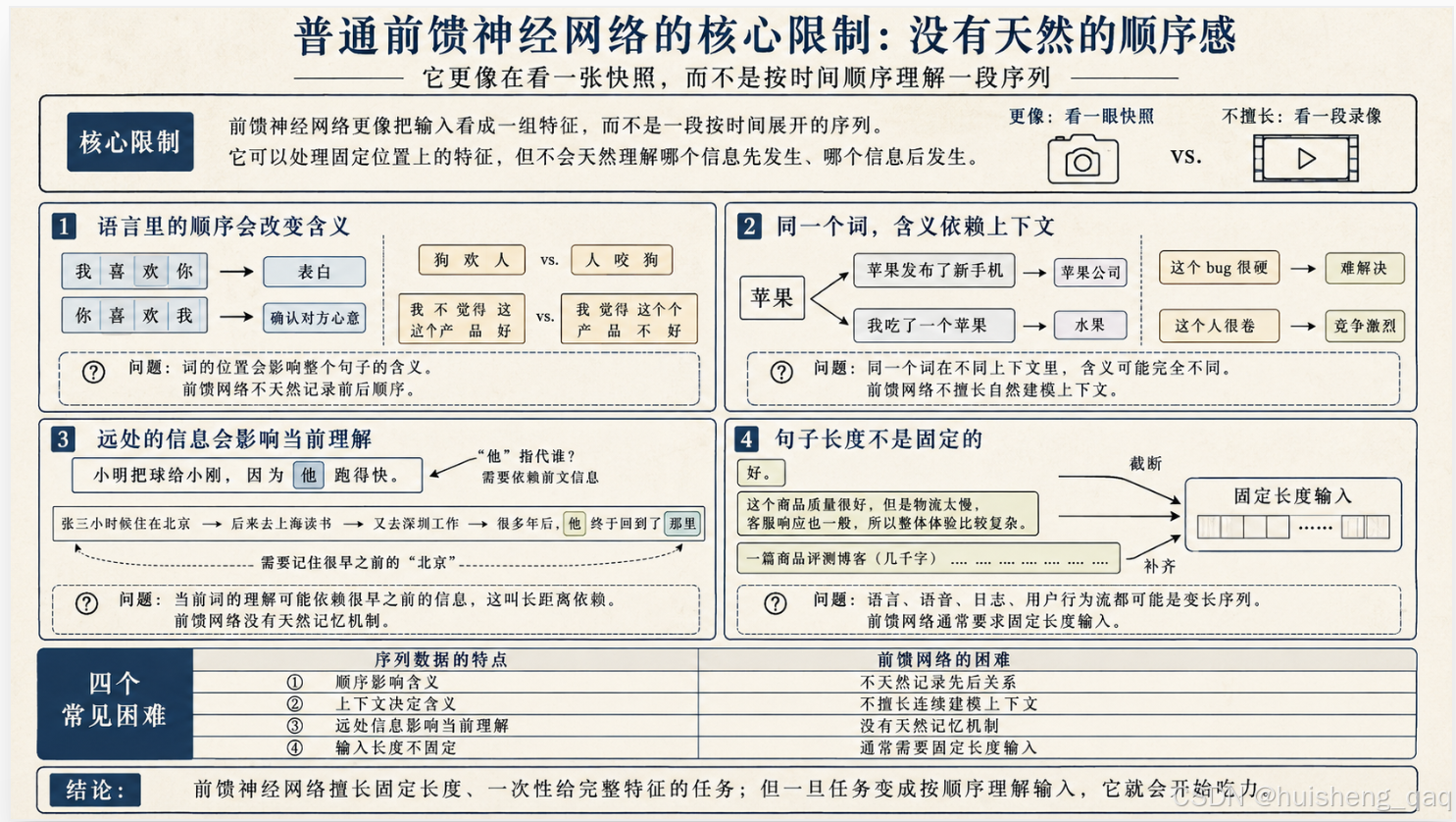
4.2.1 问题一:语言里的顺序会改变含义
最直观的例子:
- “我喜欢你” → 表白
- “你喜欢我” → 确认对方心意
同样三个字,换个顺序,意思就完全不同了。
再看两个:
- “狗咬人” 是日常情况;“人咬狗” 是新闻头条;
- “我不觉得这个产品好” 是中性偏负面;“我觉得这个产品不好” 是直接差评。一个"不"字位置不同,语气和倾向也完全不同。
在语言里,词不是孤立的符号,它的位置会直接影响整个句子的含义。普通前馈网络如果只是把每个词当成独立的特征塞进去,不天然记录"哪个词在前、哪个词在后",就很容易丢掉这种顺序信息。
4.2.2 问题二:同一个词,含义依赖上下文
同一个词,放在不同的句子里,意思可能完全不一样:
- “苹果发布了新手机” → 这里的苹果是公司;
- “我吃了一个苹果” → 这里的苹果是水果。
再来两个互联网行业更熟悉的:
- “这个 bug 很硬” → 这里的"硬"不是物理坚硬,而是问题难解决;
- “这个人很卷” → 这里的"卷"也不是物理上卷起来,而是竞争激烈、加班拼命。
词的含义不是固定死的,而是由上下文决定的。 普通前馈网络如果没有上下文建模能力,就容易把同一个词在不同句子里当成同一个含义来处理,自然就容易判断错。
4.2.3 问题三:远处的信息会影响当前理解
来看一个经典例子:
“小明把球给小刚,因为他跑得快。”
这个"他"指的是谁?小明还是小刚?答案得结合前文("把球给"这个动作)才能判断。
再来一个跨度更大的例子:
“张三小时候住在北京,后来去了上海读书,又去了深圳工作。很多年后,他终于回到了那里。”
这个"那里"很可能指北京——因为是"小时候住的地方"。但要弄明白这件事,得记住一句话开头的信息,跨过中间一长串内容。
这种情况叫长距离依赖(long-range dependency):当前词的理解,依赖于很早之前出现的某个信息。
普通前馈网络没有天然的"记忆"机制——它每次处理输入,都是从零开始。要让它处理这种跨距离的依赖关系,要么靠人工设计特征,要么把整段文本一股脑塞进去当成一个大向量,效果都不太理想。
4.2.4 问题四:句子长度不是固定的
前馈神经网络通常要求输入长度固定。这一点对结构化数据很友好:
- 图片可以统一成 224×224×3;
- 电商特征可以固定成 x1、x2、x3、x4;
但语言不一样。看看下面这三个"句子":
- “好。”(1 个字)
- “这个商品质量很好,但是物流太慢,客服响应也一般,所以整体体验比较复杂。”(30 多个字)
- 一篇商品评测博客,可能几千字。
它们都是合法的输入,但长度差几十倍甚至几千倍。
普通前馈网络要处理这种数据,通常得强行截断或者补齐到固定长度——长的截掉、短的补 0。这种做法要么丢失信息,要么引入大量噪声,效果都不太理想。变长输入不是语言独有的问题——语音、用户行为流、日志等等,本质都是"长度不固定的序列"。
4.3 不只是语言,很多数据都是序列
讲到这里你会发现,"有顺序的数据"远不止自然语言。很多业务场景里都有这种特点:
| 序列类型 | 例子 | 为什么顺序重要 |
|---|---|---|
| 文本序列 | 一句话、一篇文章 | 词序影响含义 |
| 语音序列 | 一段语音波形 | 前后音素影响识别 |
| 用户行为序列 | 浏览 → 加购 → 领券 → 下单 | 行为先后影响转化判断 |
| 时间序列 | 股票价格、温度变化 | 当前状态依赖历史趋势 |
| 日志序列 | 系统调用链、错误日志 | 前后事件决定问题原因 |
这些任务有一个共同点:模型不能只看当前这一个点,还得理解"之前发生了什么"。
比如电商场景里,光看"用户当前在浏览详情页"这一个状态意义不大,更有用的信息其实是:他在这之前是从哪里点过来的?是搜索来的,还是从首页推荐来的?是不是已经看了同类商品好几个?是不是刚刚加过购物车? 这一连串行为的先后顺序,往往比单一时刻的特征更能反映用户意图。
4.4 核心问题总结
把前面四个问题汇总一下:
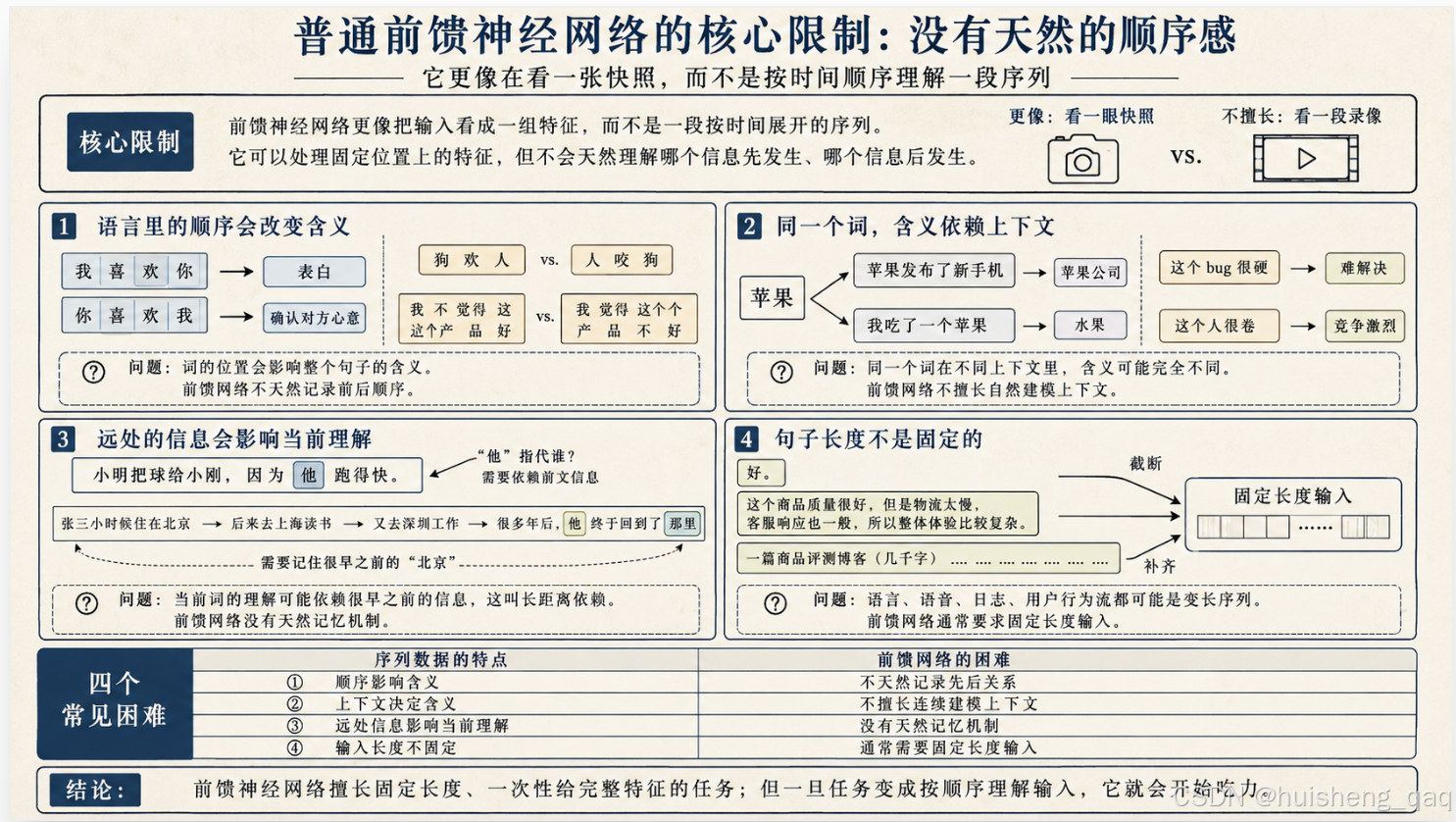
| 序列数据的特点 | 普通前馈网络的困难 |
|---|---|
| 顺序影响含义 | 不天然记录词与词之间的先后关系 |
| 上下文决定含义 | 不擅长连续建模上下文 |
| 远处信息影响当前判断 | 没有天然的记忆机制 |
| 输入长度不固定 | 通常需要固定长度输入 |
| 当前状态依赖历史 | 不能自然保留历史状态 |
要说清楚的是:这并不是说普通前馈网络没用。 它在固定输入、一次性判断的任务上仍然非常有效——图片识别、结构化分类、推荐打分这些场景,前馈式结构以及 CNN 等网络结构仍然非常重要。
只是当任务变成**“按时间一步步理解一段序列”**时,我们就需要一种新的网络结构了。
4.5 自然引出下一篇
到这里,我们可以做一个小小的总结:
普通前馈神经网络已经解决了一个很重要的问题——让模型从数据中学习规律。
但它没有天然解决另一个问题——如何处理有顺序的数据。
回想一下这一节出现过的那些场景:
- 语言不是一堆词的简单集合,而是一串按顺序出现的信息;
- 语音不是一堆声音片段,而是一段连续变化的波形;
- 用户行为不是一堆孤立动作,而是一个按时间发生的过程;
- 股价、日志、对话……都是序列。
这就引出了下一篇要讲的序列模型:
如果神经网络也能按照顺序一步一步读取输入,并在读取过程中保留前面的信息,是不是就更适合处理语言、语音和用户行为序列?
下一篇,我们再专门讲 RNN(循环神经网络):在 Transformer 出现之前,AI 是怎么尝试"一个词一个词读句子"的。
如需转载,请附上链接:https://zhenghuisheng.blog.csdn.net/article/details/160909017

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)