【python因果库实战26】逆概率加权模型1

逆概率加权模型
逆概率加权是一种基本的方法,用于获得平均效应的估计。
它计算每个样本属于其所在组的概率,
并使用该概率的倒数作为该样本的权重:
w i = 1 Pr [ A = a i ∣ X i ] w_i=\frac1{\Pr[A=a_i|X_i]} wi=Pr[A=ai∣Xi]1
%matplotlib inline
from causallib.datasets import load_nhefs
from causallib.estimation import IPW
from causallib.evaluation import evaluate
from sklearn.linear_model import LogisticRegression
from matplotlib import pyplot as plt
数据:
戒烟对减肥效果的影响。
本数据示例取自 Hernan 和 Robins 的《因果推断》一书。
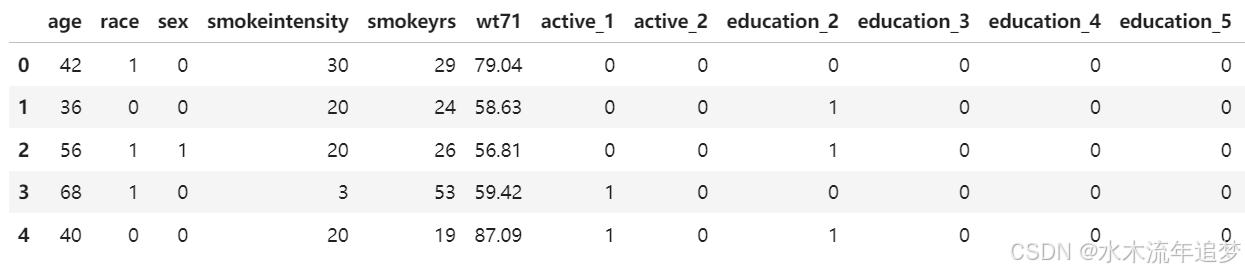
data = load_nhefs()
data.X.join(data.a).join(data.y).head()
模型:
因果模型的核心是一个机器学习模型,以 learner 参数的形式提供。这个 ML 模型将用于根据协变量预测戒烟的可能性。
这些可能性将用于获取 w i w_i wi。
然后,我们将使用 Horvitz-Thompson 估计器估计平均平衡结果:
E ^ [ Y a ] = 1 ∑ i : A i = a w i ⋅ ∑ i : A i = a w i y i \hat{E}[Y^a]=\frac1{\sum_{i:A_i=a}w_i}\cdot\sum_{i:A_i=a}w_iy_i E^[Ya]=∑i:Ai=awi1⋅∑i:Ai=awiyi
最后,我们将利用这些平均反事实结果来预测效应:
E ^ [ Y 1 ] − E ^ [ Y 0 ] \hat{E}[Y^1]-\hat{E}[Y^0] E^[Y1]−E^[Y0]
# Train:
learner = LogisticRegression(solver="liblinear")
ipw = IPW(learner)
ipw.fit(data.X, data.a)
IPW(clip_max=None, clip_min=None, use_stabilized=False, verbose=False,
learner=LogisticRegression(solver='liblinear'))
# We can now preict the weight of each individual:
ipw.compute_weights(data.X, data.a).head()
0 1.149089
1 1.198450
2 1.200264
3 1.959673
4 1.336338
dtype: float64
# Estimate average outcome
outcomes = ipw.estimate_population_outcome(data.X, data.a, data.y)
outcomes
0 1.750404
1 5.261713
dtype: float64
# Estimate the effect:
effect = ipw.estimate_effect(outcomes[1], outcomes[0])
effect
diff 3.511308
dtype: float64
非默认参数
我们刚刚看到了一个隐藏了许多模型参数的简单示例。
现在我们深入探讨每一阶段。
模型定义
机器学习模型:
任何 scikit-learn 模型都可以指定(甚至管道)
learner = LogisticRegression(penalty="l1", C=0.01, max_iter=500, solver='liblinear')
IPW 模型有两个额外参数:
clip_min,clip_max: 修剪非常小或非常大的概率的卡尺值stabilized: 是否按治疗流行病学比例调整权重
clip_min = 0.2
clip_max = 0.8
ipw = IPW(learner, clip_min=clip_min, clip_max=clip_max, use_stabilized=False)
ipw.fit(data.X, data.a);
权重预测选项
现在我们可以预测戒烟的概率(治疗值 = 1),并验证我们的截断是否有效:
probs = ipw.compute_propensity(data.X, data.a, treatment_values=1)
probs.between(clip_min, clip_max).all()
True
在“预测”阶段(即计算权重或概率时),
我们可以更改初始化时放置的参数:
probs = ipw.compute_propensity(data.X, data.a, treatment_values=1, clip_min=0.0, clip_max=1.0)
probs.between(clip_min, clip_max).all()
False
我们甚至可以预测稳定的权重。
然而,我们会收到警告。
这是因为治疗流行病学比例是对训练数据的估计。
在拟合时,当模型拥有初始值时,use_stabilized 为 False(默认值)。
所以现在计算权重时,模型会使用提供的数据来估计治疗流行病学比例。
这里这不是大问题,因为我们在用相同数据计算,但这并不总是这样。
(如果我们将 use_stabilized=True 并重新训练模型,则不会出现此警告)
stabilized_weights = ipw.compute_weights(data.X, data.a, treatment_values=1,
clip_min=0.0, clip_max=1.0, use_stabilized=True)
weights = ipw.compute_weights(data.X, data.a, treatment_values=1,
clip_min=0.0, clip_max=1.0)
stabilized_weights.eq(weights).all()
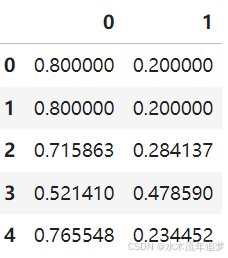
由于 IPW 利用概率,对于每个样本,我们可以为每个治疗值获得概率(或权重)。
# ipw.compute_weight_matrix(data.X, data.a).head()
ipw.compute_propensity_matrix(data.X, data.a).head()
效应估计选项
我们可以选择是希望得到加性(差值 diff)还是乘性(比率 ratio)效应
(如果结果 y 是概率,我们还可以要求得到几率比(or))
提供权重 w 是可选的,如果不提供,权重将简单地再次使用提供的 X 进行计算。
outcomes = ipw.estimate_population_outcome(data.X, data.a, data.y, w=weights)
effects = ipw.estimate_effect(outcomes[1], outcomes[0], effect_types=["diff", "ratio"])
effects
diff 2.753878
ratio 2.141800
dtype: float64

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)